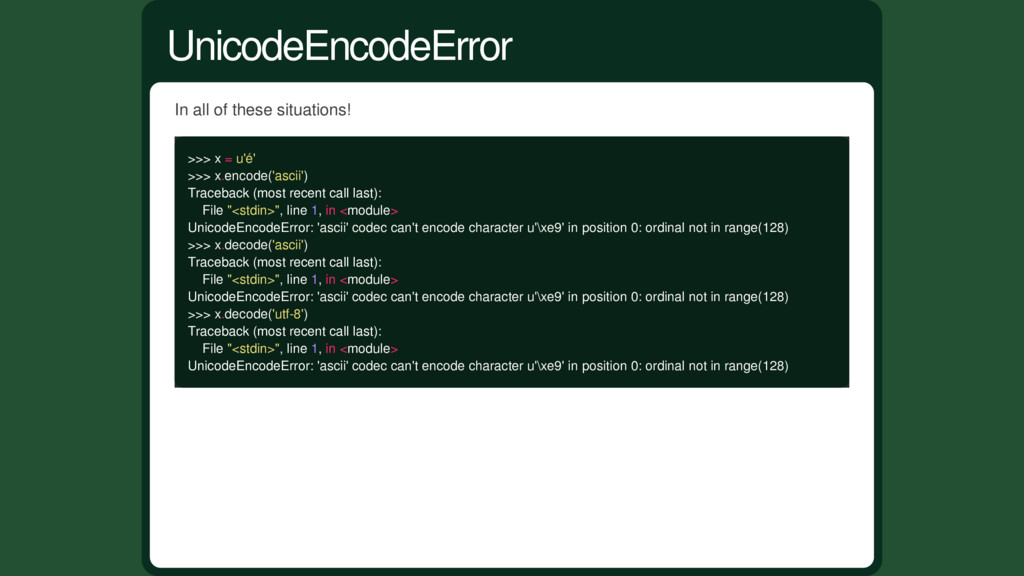
can't encode character When doing .encode('ascii') When doing .decode('ascii') When doing .decode('utf-8') In all of theses situations 2. UnicodeEncodeError
x.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode character u'\xe9' in position 0: ordinal not in range(128) >>> x.decode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode character u'\xe9' in position 0: ordinal not in range(128) >>> x.decode('utf-8') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode character u'\xe9' in position 0: ordinal not in range(128) UnicodeEncodeError
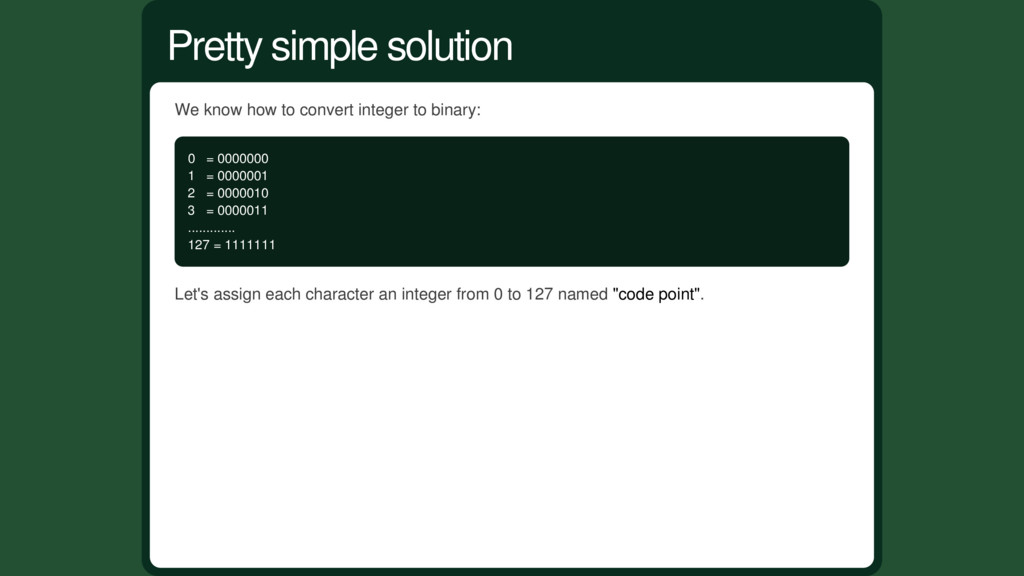
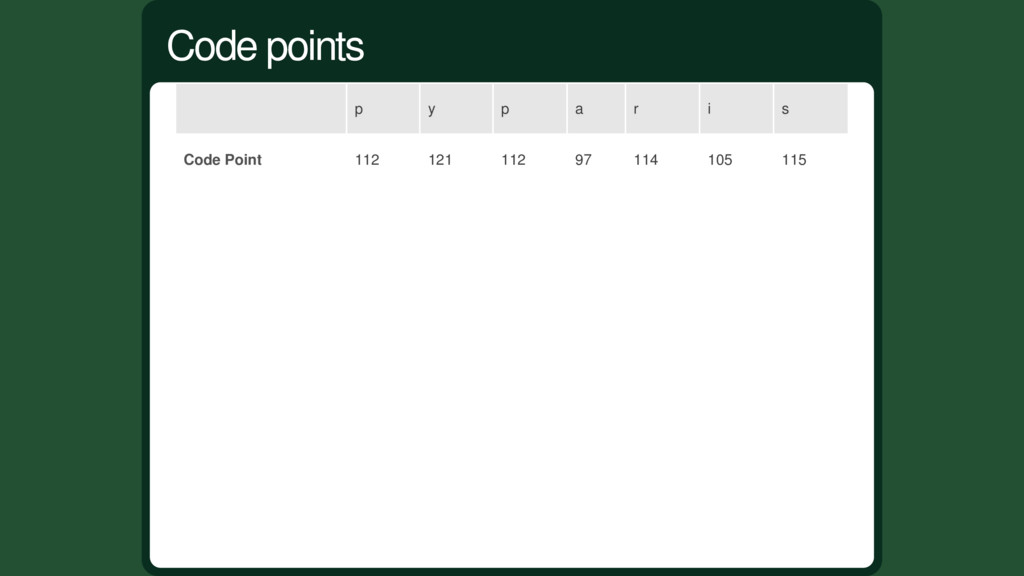
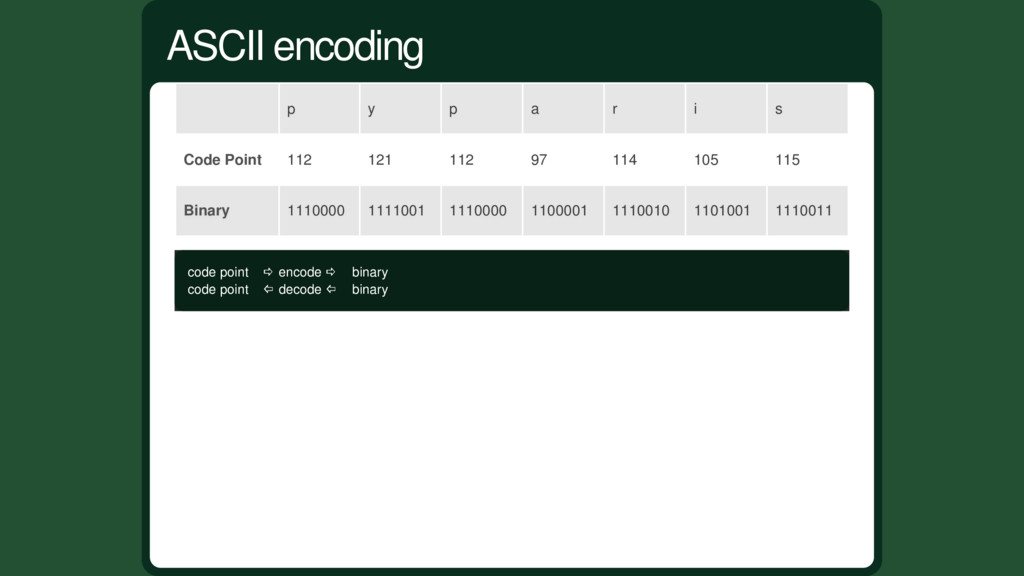
0000000 1 = 0000001 2 = 0000010 3 = 0000011 ............. 127 = 1111111 Let's assign each character an integer from 0 to 127 named "code point". Pretty simple solution
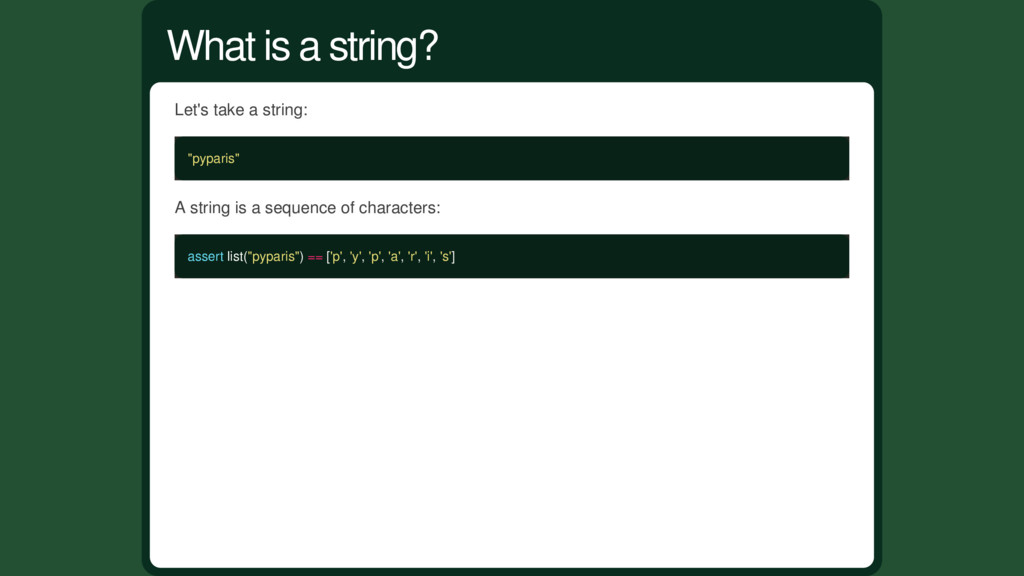
character (from the Greek χαρακτήρ "engraved or stamped mark" on coins or seals, "branding mark, symbol") is a sign or symbol. — Wikipedia A character is basically anything. It could represents be a letter, a digit or even an emoji. What is character
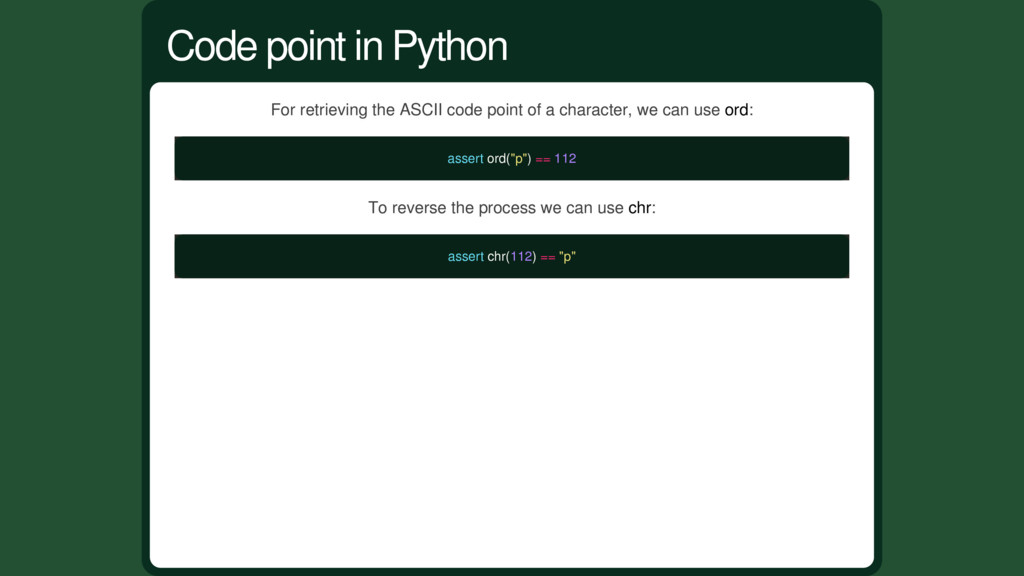
string = 'abc' bytes = bytes.encode('ascii') assert hex(bytes) == '616263' decode is meant to transform some bytes into a string: bytes = unhex('616263') string = bytes.decode('ascii') assert string == 'abc' Each of these methods accepts an encoding parameter for the name of the conversion algorithm to use. Encode vs Decode
to add support for accents for example, like Latin1 that defines the character É with the code point 201. Some other, were not compatible at all, like EBCDIC, used on IBM mainframes, where the 1001011 (code point 75) code point represent the punctuation mark "." while in ASCII it represent "A". Of course they were not all cross-compatible... Other standards
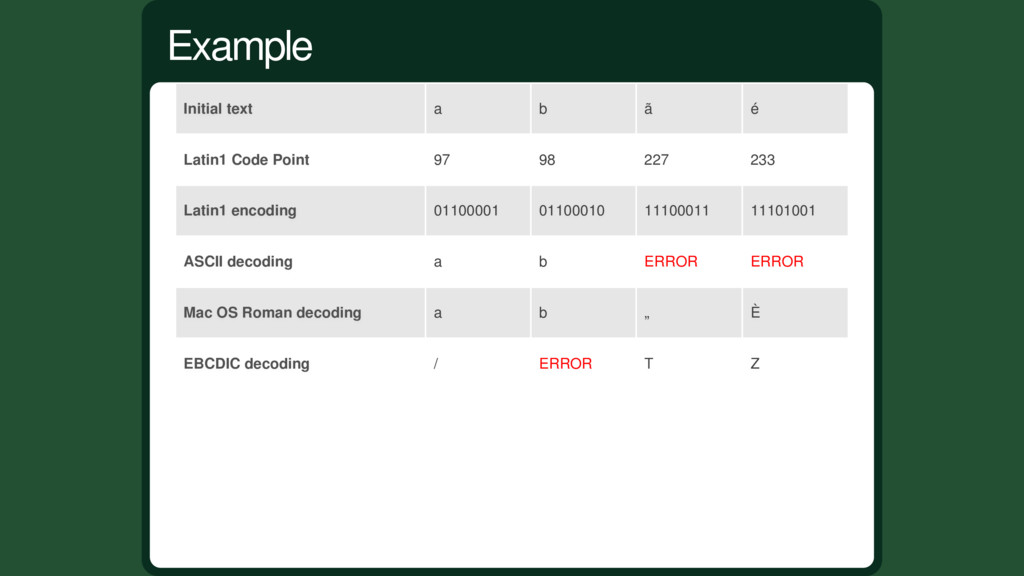
98 227 233 Latin1 encoding 01100001 01100010 11100011 11101001 ASCII decoding a b ERROR ERROR Mac OS Roman decoding a b „ È EBCDIC decoding / ERROR T Z Example
representation, and handling of text expressed in most of the world's writing systems. — Wikipedia It all started in 1987-1988 as a coordination between Joe Becker from Xerox and Lee Collins and Mark Davis from Apple. The unicode code points are fortunately for us ASCII compatible. What is Unicode?
characters covering 135 modern and historic scripts, as well as multiple symbol sets. — Wikipedia ASCII was defining 127 characters, so Unicode defines 1000 times more characters. It defines several blocks: Basic Latin: ab...XYZ Greek, Aramaic, Cherokee: ΔעᏗ Right to left scripts, Cuneiform, hieroglyphs: Mahjong Tiles, Domino Tiles, Playing cards: Emoticons, Musical notations: Unicode size
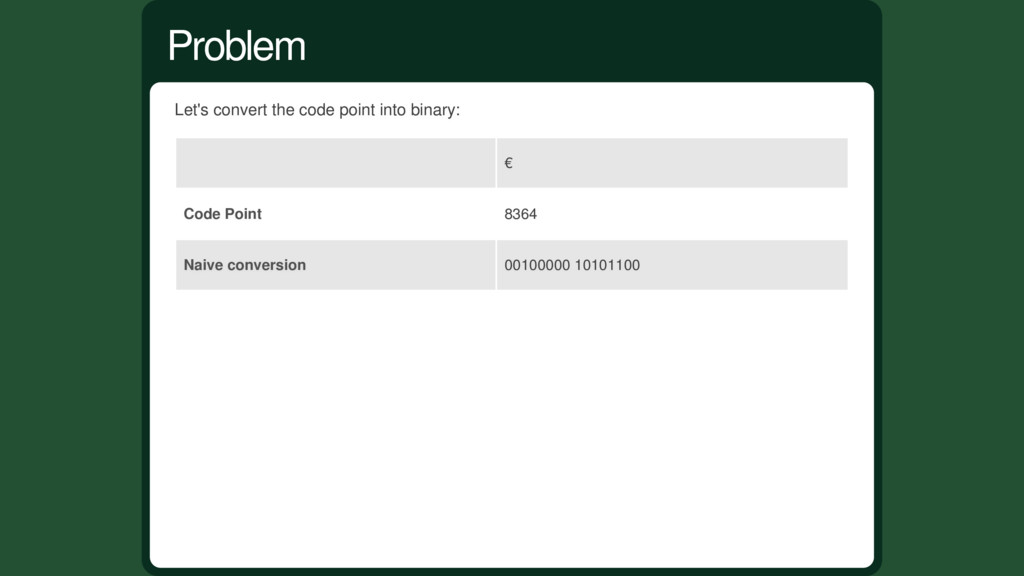
of your python source file as utf-8: # -*- coding: utf-8 -*- Then, you can write it this way: u'€' Or: u'\u20AC' Its code point is 8364: ord(u'€') == 8364 How to write Unicode in Python
start using more than 1 bytes are multiple and annoying: How to order the bytes, Big And Little Endian problems anyone? How to recognize which byte you are reading in a file or stream? How to detect and correct transmission errors where only some bytes were missing? 8364 into binary takes two bytes. Unicode characters code points goes well beyond 1 000 000 (because of non allocated yet), taking up to 3 bytes. Multi-bytes
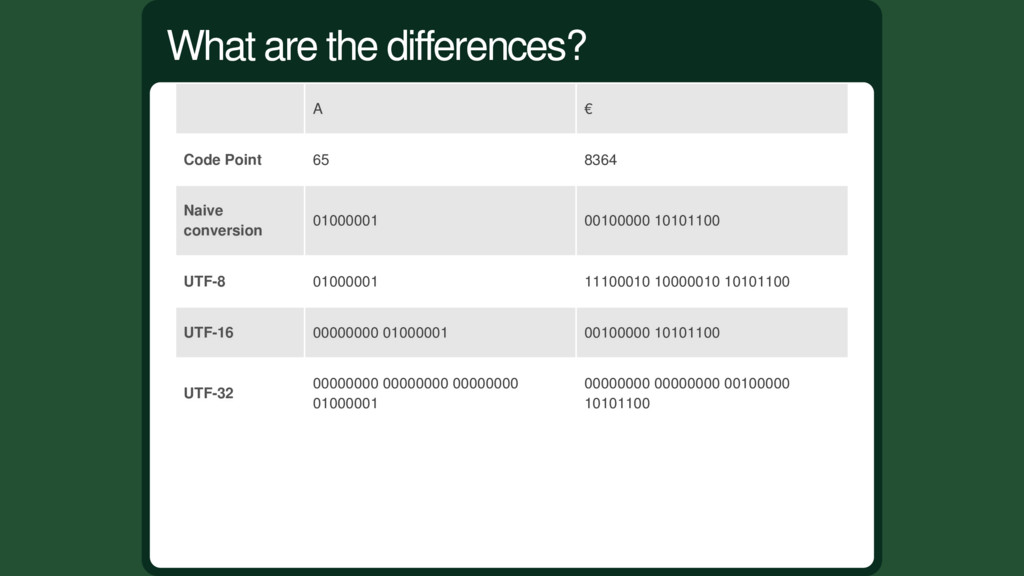
was straightforward. But the presence of high code point characters in Unicode complexify the process. There are multiple ways of doing it, called encodings: UTF-8 UTF-16 UTF-32 Multiple encoding
compatible with every characters, works well most of the time and solved multi-bytes related problems Elegantly. If you process more Asian characters than Latin, use UTF-16 so you use less space and memory. If you need to interact with another program, use the default other program encoding (CSV anyone?). Comparison of Unicode encodings - Wikipedia Choose an encoding
string into some bytes: hex(u'é'.encode('utf-8')) == 'c3a9' decode is meant to transform some bytes into an unicode string: unhex('c3a9').decode('utf-8') == u'é' Encode vs Decode
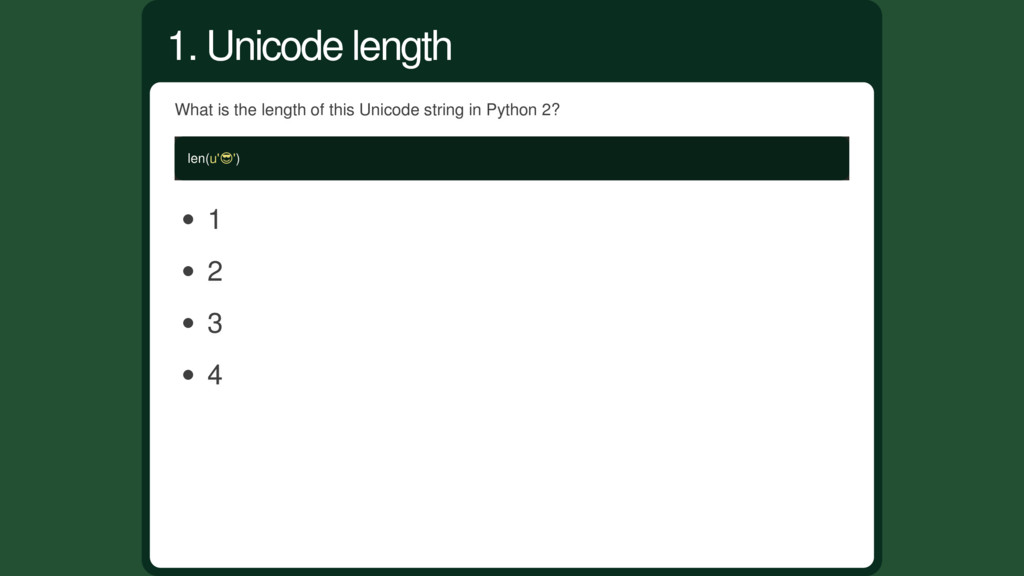
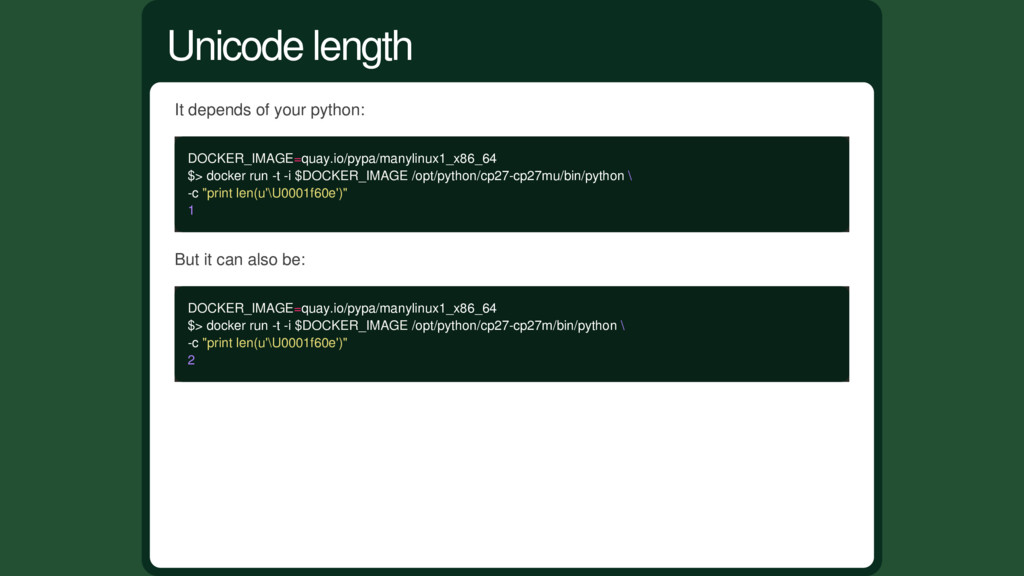
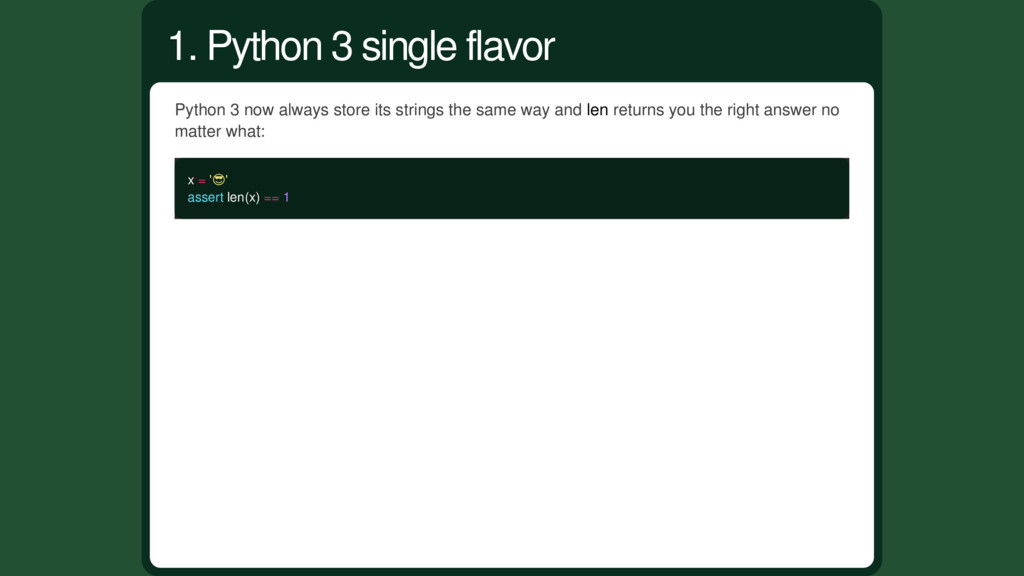
the number of bytes! But it's much more harder with Unicode strings. Python 2 tries hard to get you a correct answer. Let's take back our example: . Its code point is 128526. 1. String length
Unicode. Its either a narrow build or a wide build. It basically change how Python stores its strings. For code point < 65535, everything works the same, Python store each character separately and only one character. For code point > 65535, it differs. The wide build character size is enough for all Unicode code points. But the narrow build character size is not big enough for code point > 65535, so it store upper code points as a pair of characters. The narrow build use less memory but it explains why the narrow build returns 2 for len(u' '), it's because Python 2 actually store two characters. Multiple flavors of Python 2
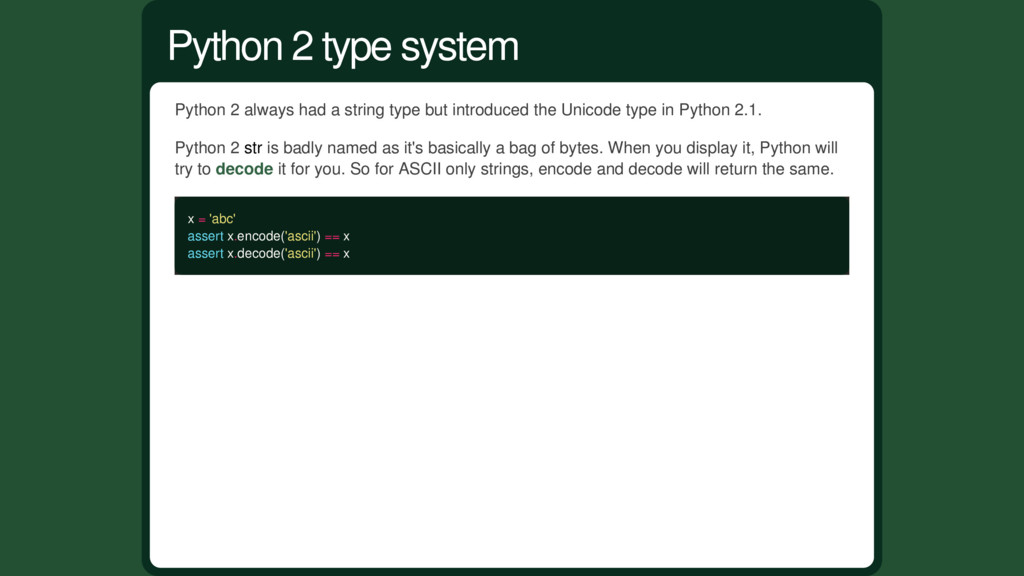
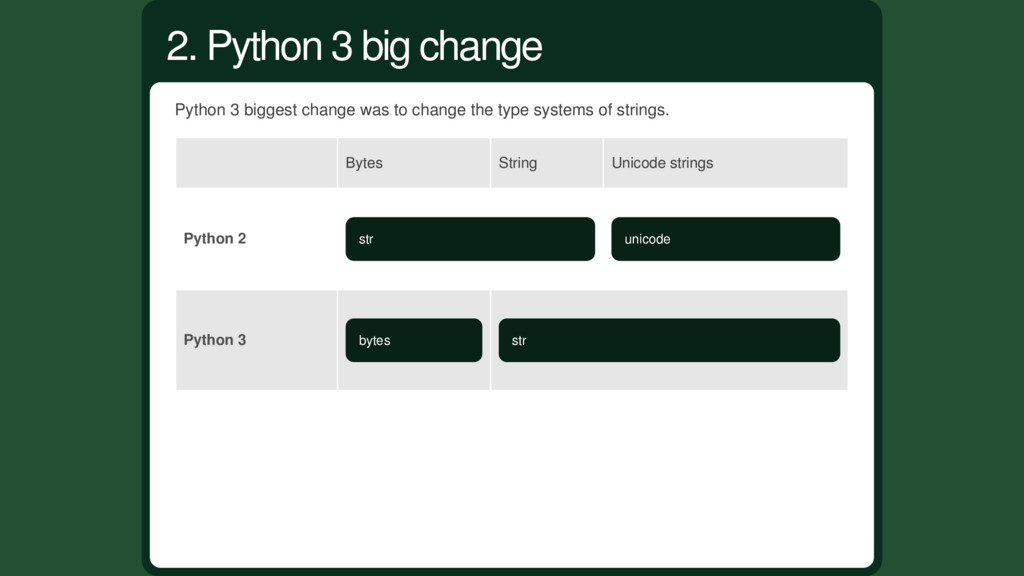
Unicode type in Python 2.1. Python 2 str is badly named as it's basically a bag of bytes. When you display it, Python will try to decode it for you. So for ASCII only strings, encode and decode will return the same. x = 'abc' assert x.encode('ascii') == x assert x.decode('ascii') == x Python 2 type system
coerce types behind your back: '012' + 3 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: cannot concatenate 'str' and 'int' objects But it's not respecting this property with strings. Remember that decode convert bytes into an Unicode string in Python? x = u'é' x.decode('utf-8') As decode is called on an Unicode instance, it isn't bytes. So python tries to makes some bytes out of the string and does: x = u'é' x.encode('ascii').decode('utf-8') That's way you can see an UnicodeEncodeError error while trying to decode an Unicode Python 2 type coercing
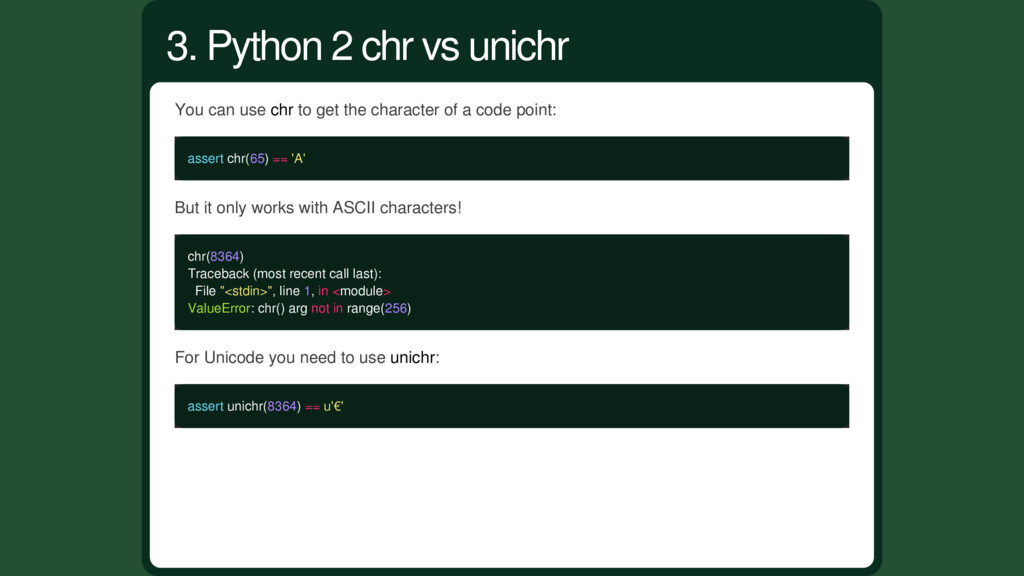
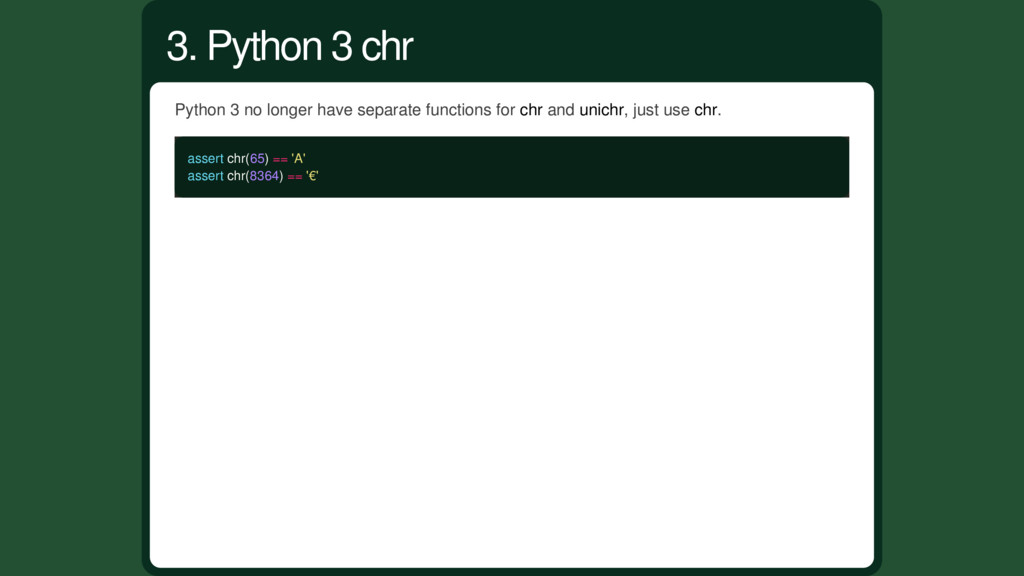
code point: assert chr(65) == 'A' But it only works with ASCII characters! chr(8364) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: chr() arg not in range(256) For Unicode you need to use unichr: assert unichr(8364) == u'€' 3. Python 2 chr vs unichr
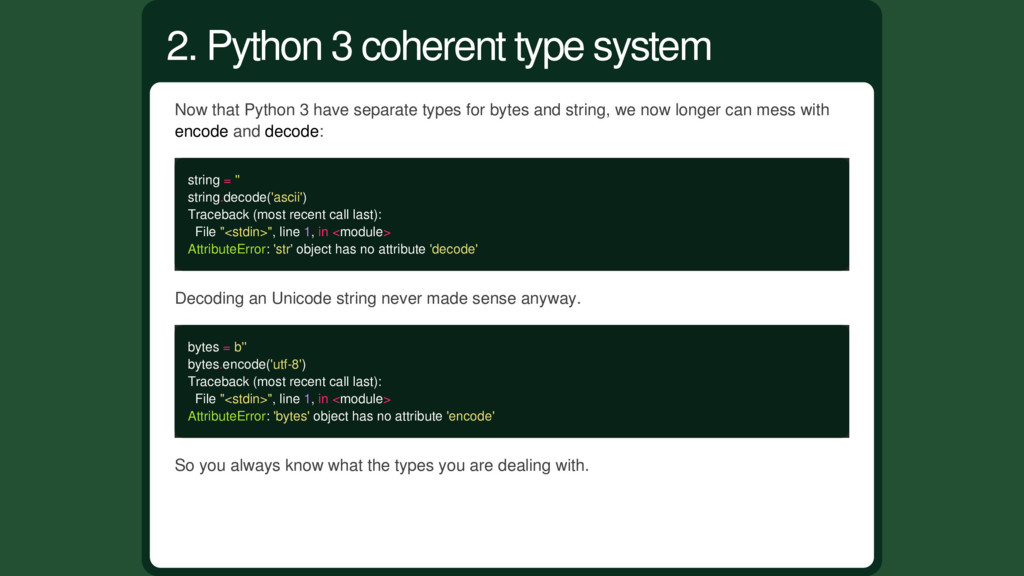
string, we now longer can mess with encode and decode: string = '' string.decode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'str' object has no attribute 'decode' Decoding an Unicode string never made sense anyway. bytes = b'' bytes.encode('utf-8') Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'bytes' object has no attribute 'encode' So you always know what the types you are dealing with. 2. Python 3 coherent type system
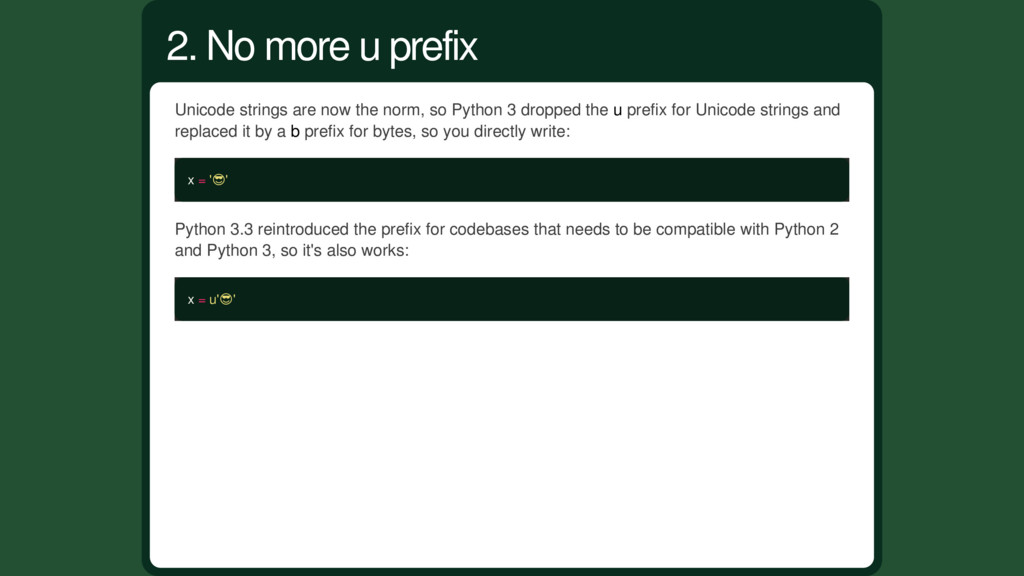
the u prefix for Unicode strings and replaced it by a b prefix for bytes, so you directly write: x = ' ' Python 3.3 reintroduced the prefix for codebases that needs to be compatible with Python 2 and Python 3, so it's also works: x = u' ' 2. No more u prefix
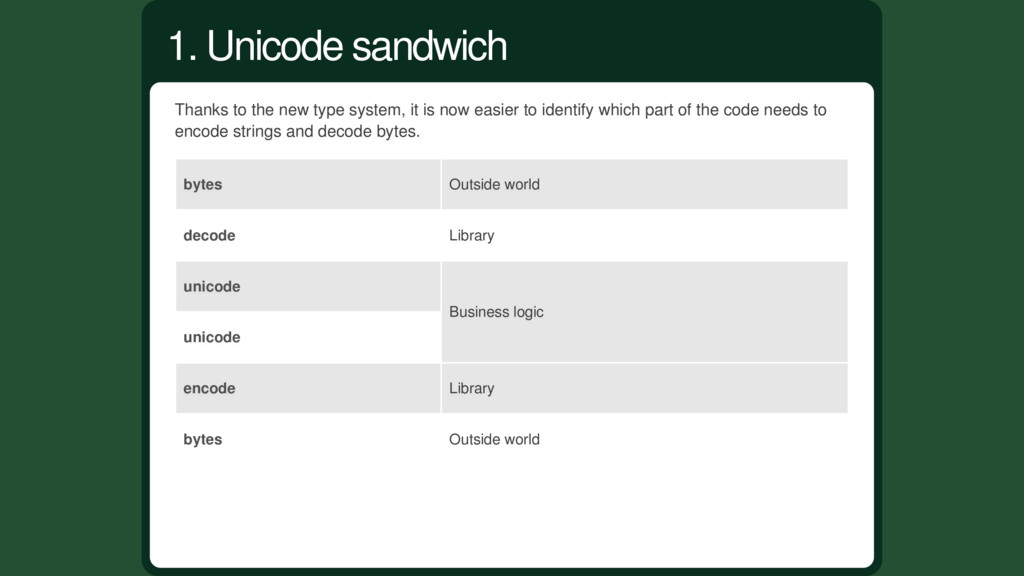
to identify which part of the code needs to encode strings and decode bytes. bytes Outside world decode Library unicode Business logic unicode encode Library bytes Outside world 1. Unicode sandwich
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" /> <?xml version="1.0" encoding="UTF-8" ?> # -*- coding: iso8859-1 -*- If you really really really really need to guess the encoding, you can use chardet, but remember, it's a best effort scenario. 2. Use declared encoding
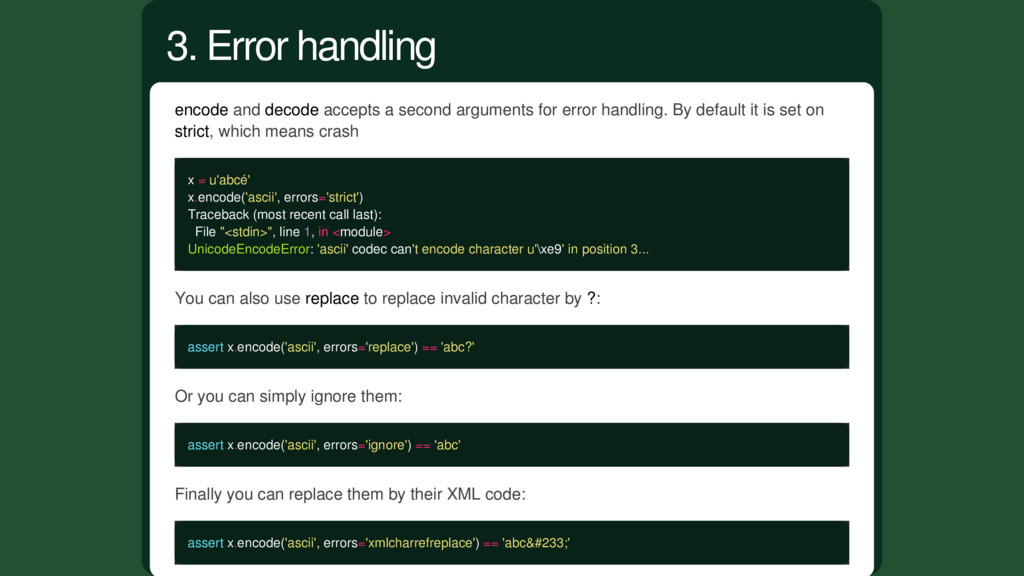
By default it is set on strict, which means crash x = u'abcé' x.encode('ascii', errors='strict') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode character u'\xe9' in position 3... You can also use replace to replace invalid character by ?: assert x.encode('ascii', errors='replace') == 'abc?' Or you can simply ignore them: assert x.encode('ascii', errors='ignore') == 'abc' Finally you can replace them by their XML code: assert x.encode('ascii', errors='xmlcharrefreplace') == 'abcé' 3. Error handling
and decode str in Python 2, it might solves bugs in your code and ease Python 3 conversions. Unicode sandwich. Never guess an encoding! Use error handling. Conclusion
About Unicode and Character Sets (No Excuses!) Pragmatic Unicode Unicode In Python, Completely Demystified What every programmer absolutely, positively needs to know about encodings and character sets to work with text Holy batman Reddit on unicode References
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![assert type("pyparis"[0]) == <type 'str'> assert len("pyparis"[0]) == 1 A](https://files.speakerdeck.com/presentations/ce960addd6e74c199f475bc12b82cf5d/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}