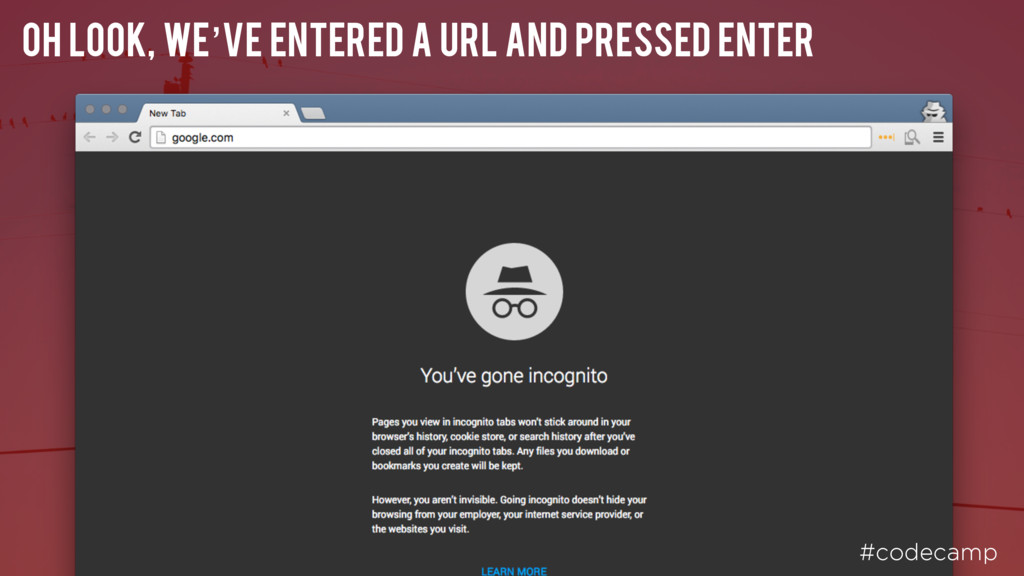
#codecamp If there are invalid characters, the browser will use Punycode to make the URL valid. bücher.com xn--bcher-kva.com/ büücher.com xn--bcher-kvaa.com/ münchen.com xn--mnchen-3ya.com/
https? #codecamp There’s an internal cache of sites that have requested to only be communicated with https, not http HTTP Strict Transport Security LISt
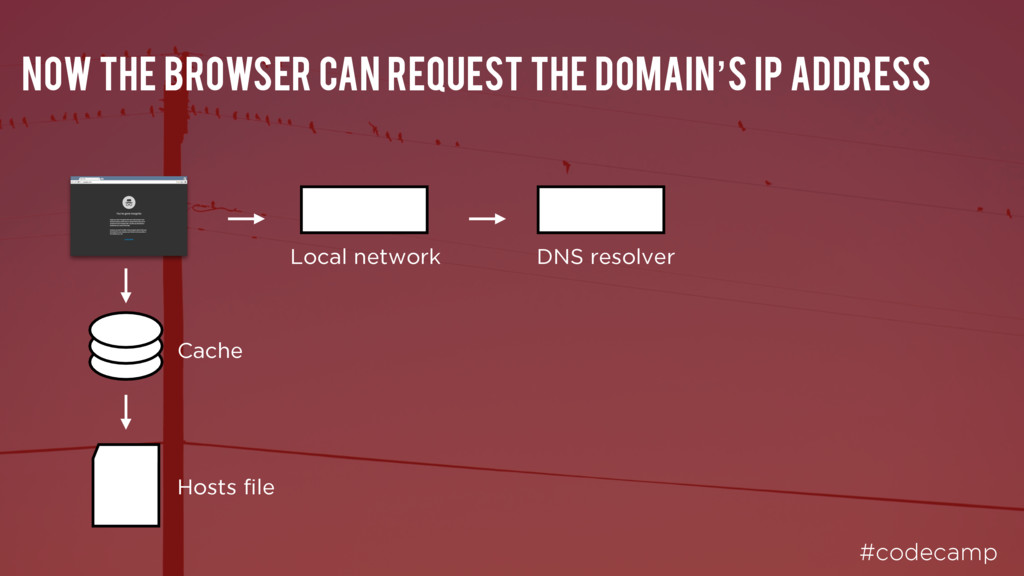
I have the IP address for www.google.com?” “Don’t have it - try xxx.xxx.xxx.xxx” “Don’t have it - try xxx.xxx.xxx.xxx” TLD resolver “Hey, can I have the IP address for www.google.com?” Domain resolver “Hey, can I have the IP address for www.google.com?” Sure, it’s -xxx.xxx.xxx.xxx”
<date>19980901</date> <title>New coffee maker</title> <body> The new coffee maker has been installed! Operation is simple: put a cup in the opening and press the red button. </body> </memo>
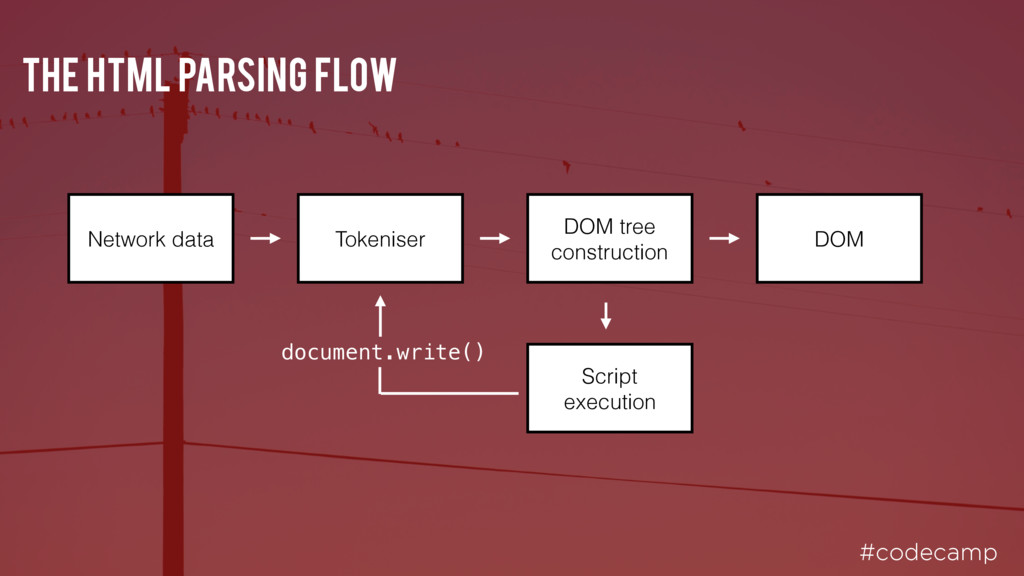
the HTML as it is being parsed. This can add extra tokens to the HTML. Think about a script tag that gets evaluated in the middle of the input which contains a document.write call
html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html }
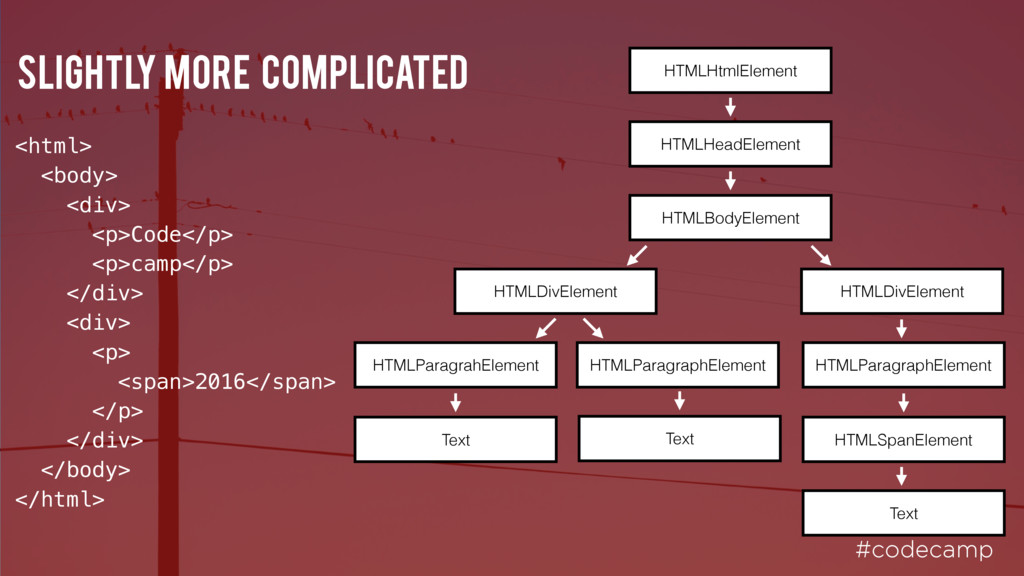
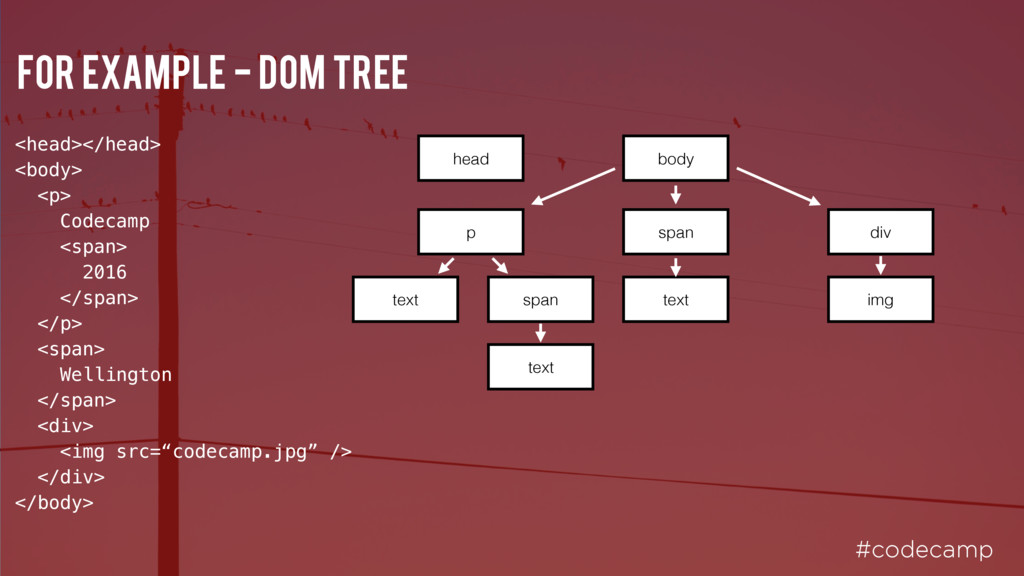
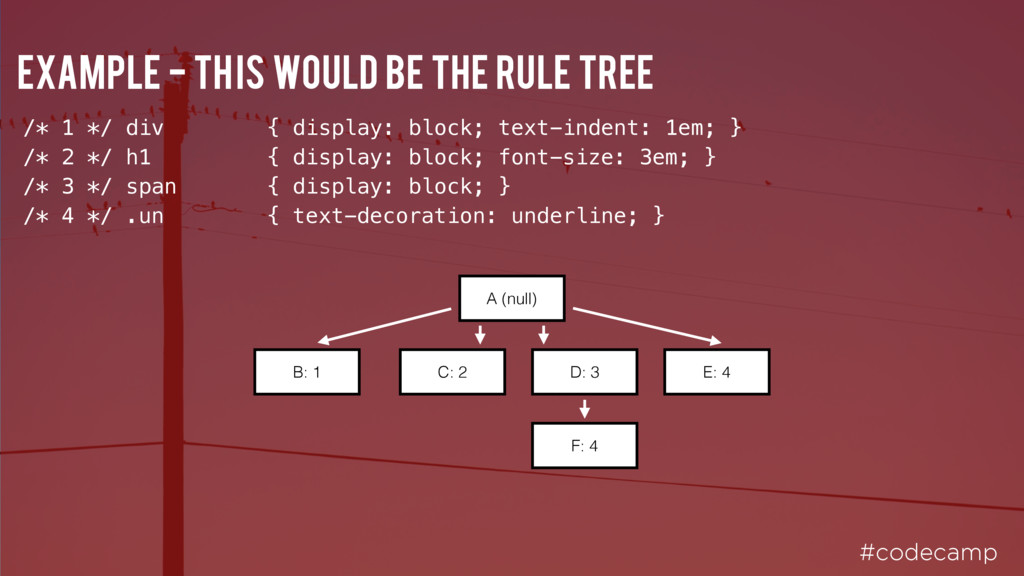
First, the root document node is created and all other nodes will be added to this. For each token, the spec defines which DOM element is relevant. These elements are added both to the DOM tree and also to the stack of open elements.
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: Initial
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: Before html HTMLHtmlElement
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: Before head HTMLHtmlElement HTMLHeadElement
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: In head HTMLHtmlElement HTMLHeadElement
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: After head HTMLHtmlElement HTMLHeadElement
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: In body HTMLHtmlElement HTMLHeadElement HTMLBodyElement
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: In body HTMLHtmlElement HTMLHeadElement HTMLBodyElement Text
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: In body HTMLHtmlElement HTMLHeadElement HTMLBodyElement Text
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: After body HTMLHtmlElement HTMLHeadElement HTMLBodyElement Text
start-tag { name: html } start-tag { name: body } character { data: C } character { data: o } character { data: d } character { data: e } character { data: c } character { data: a } character { data: m } character { data: p } end-tag { name: body } end-tag { name: html } State: After after body HTMLHtmlElement HTMLHeadElement HTMLBodyElement Text
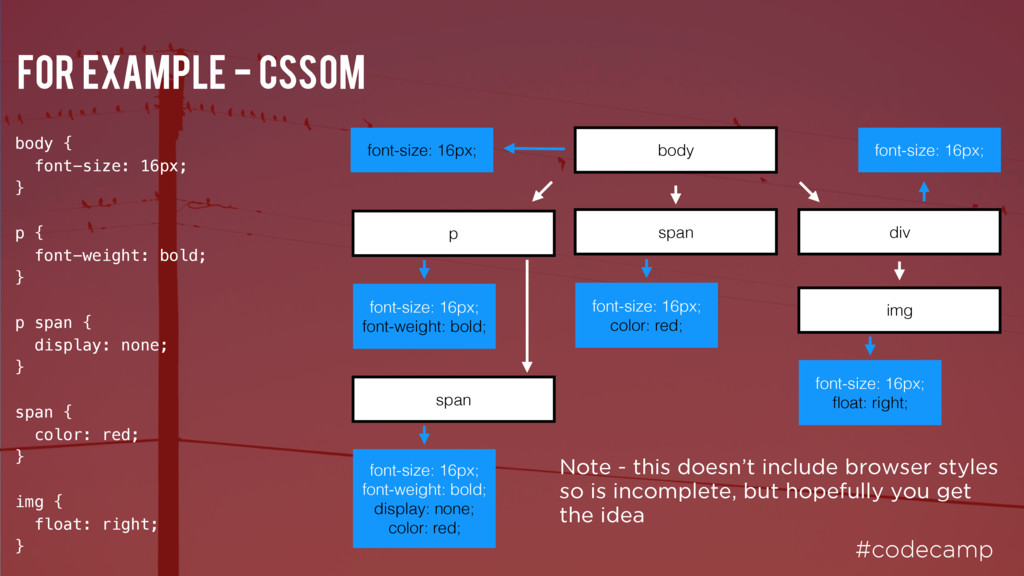
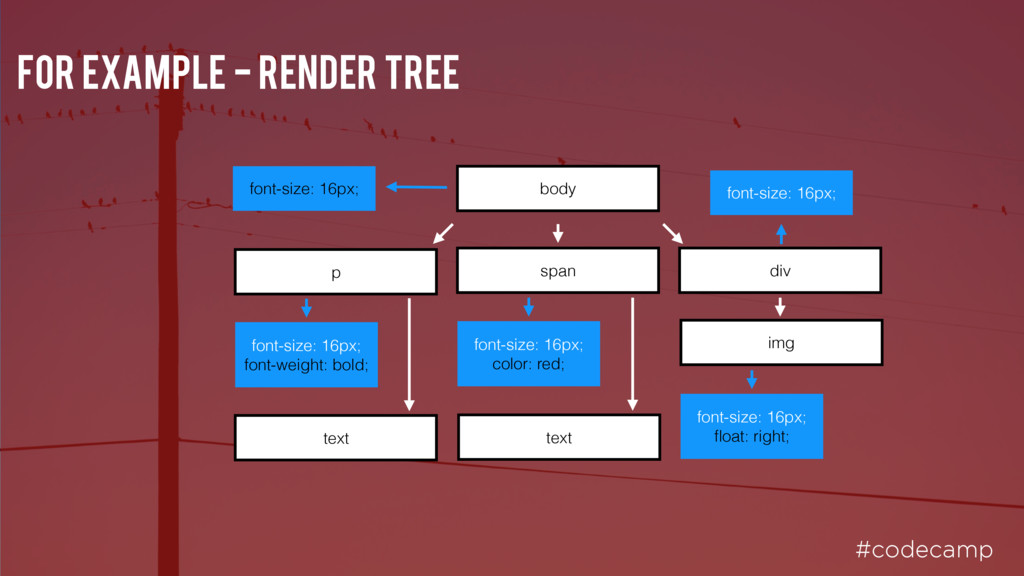
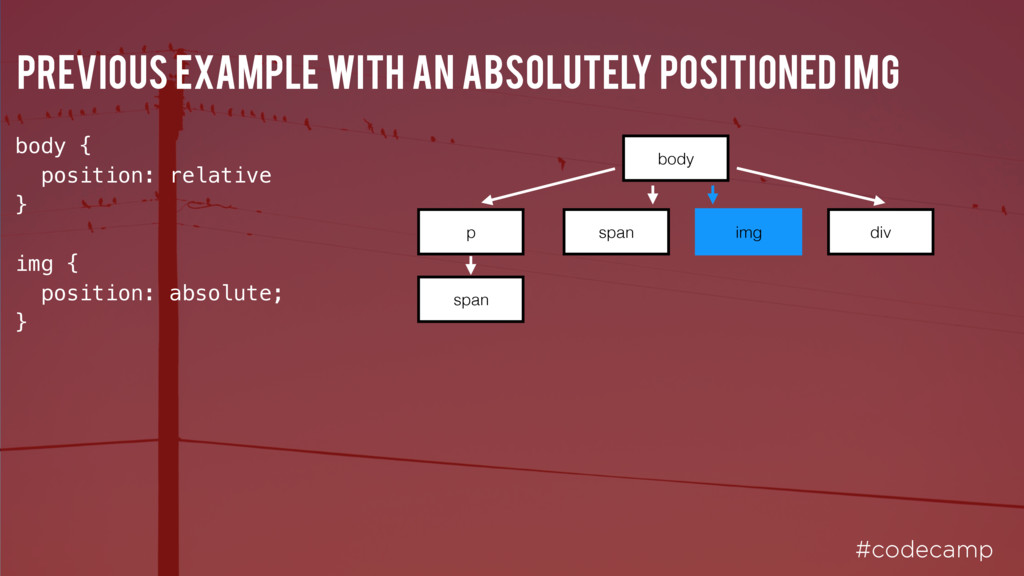
p { font-weight: bold; } p span { display: none; } span { color: red; } img { float: right; } img p span body span font-size: 16px; font-weight: bold; font-size: 16px; font-size: 16px; font-weight: bold; display: none; color: red; font-size: 16px; color: red; font-size: 16px; float: right; Note - this doesn’t include browser styles so is incomplete, but hopefully you get the idea div font-size: 16px;
out the exact position of each node in the render tree, we start at the root and traverse it to compute the geometry of all nodes. <body> <main style=“width:50%”> <div style=“width:50%”> Hello! </div> </main> </body> Hello! Viewport (size = device width) div (50%) div (50%)
width 2. Over all the nodes children: 1. A child x and y positions set 2. Layout is called on the child if necessary 3. The parent uses the childs accumulated height to determine it’s own height
(from 2011, but very in depth) http://www.html5rocks.com/en/tutorials/internals/howbrowserswork Google’s BlinkOn internal talks https://www.youtube.com/channel/UCIfQb9u7ALnOE4ZmexRecDg Google Developers https://developers.google.com/web/fundamentals/performance Mozilla - Gecko overview https://wiki.mozilla.org/Gecko:Overview
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}