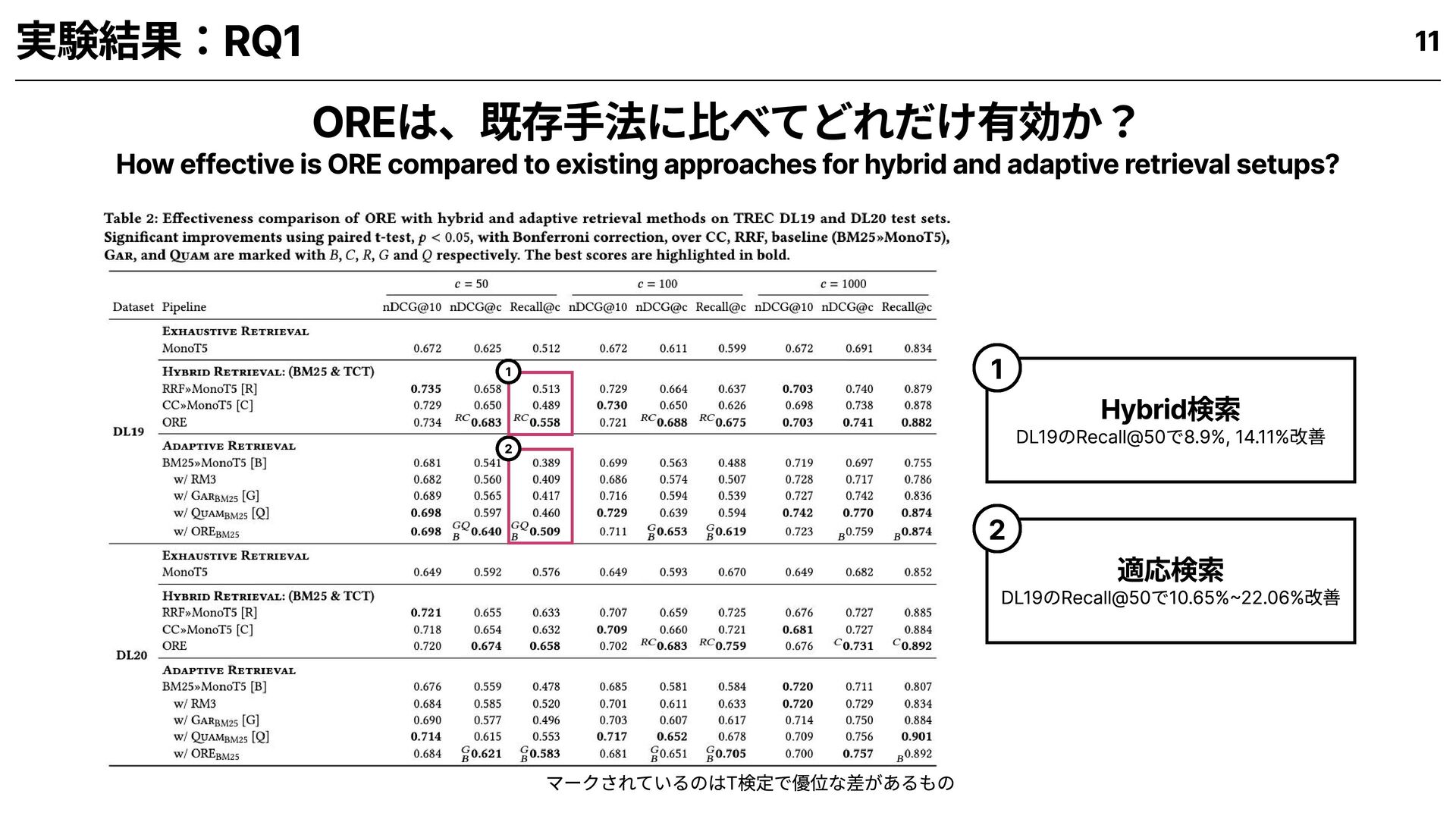
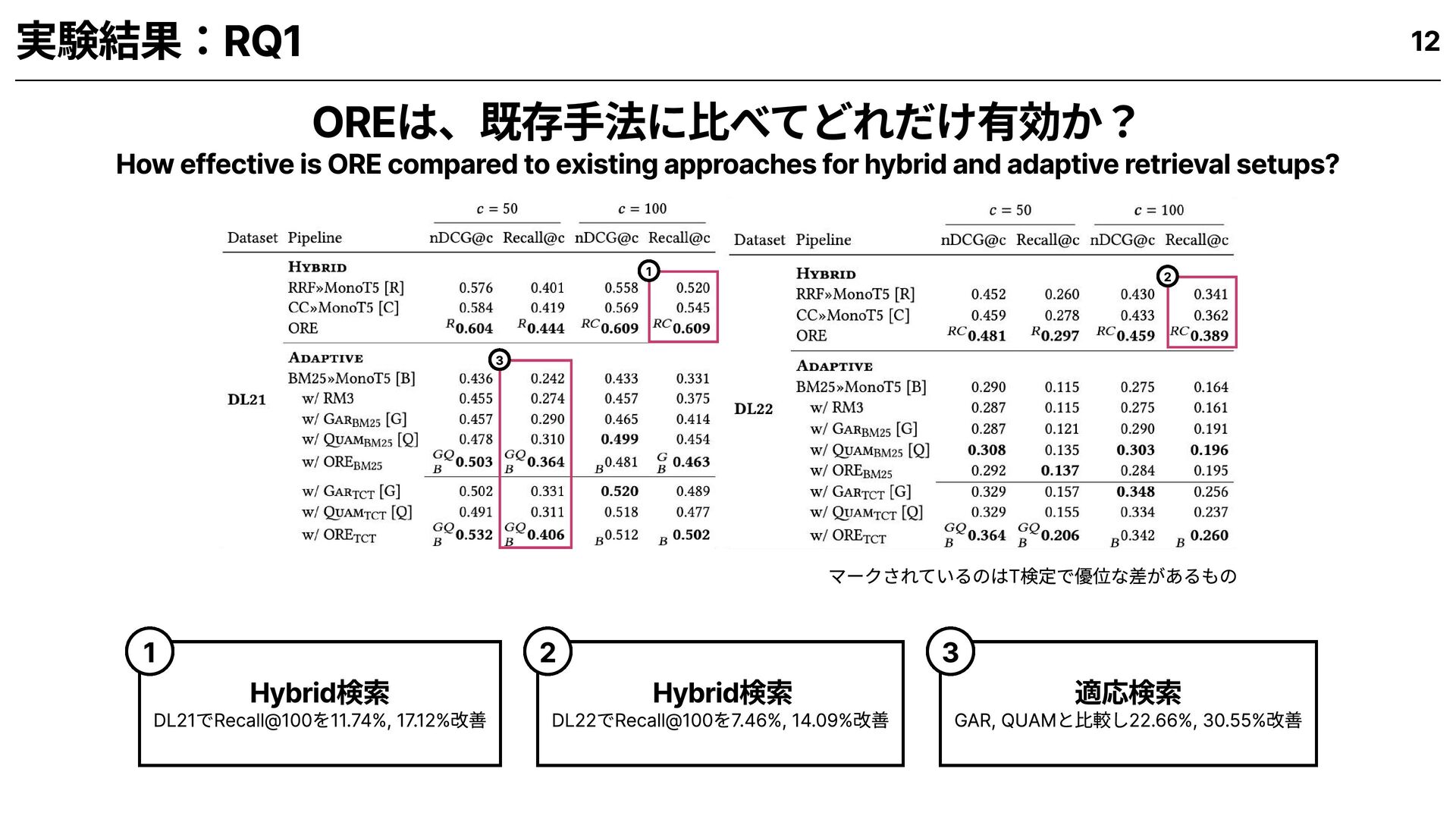
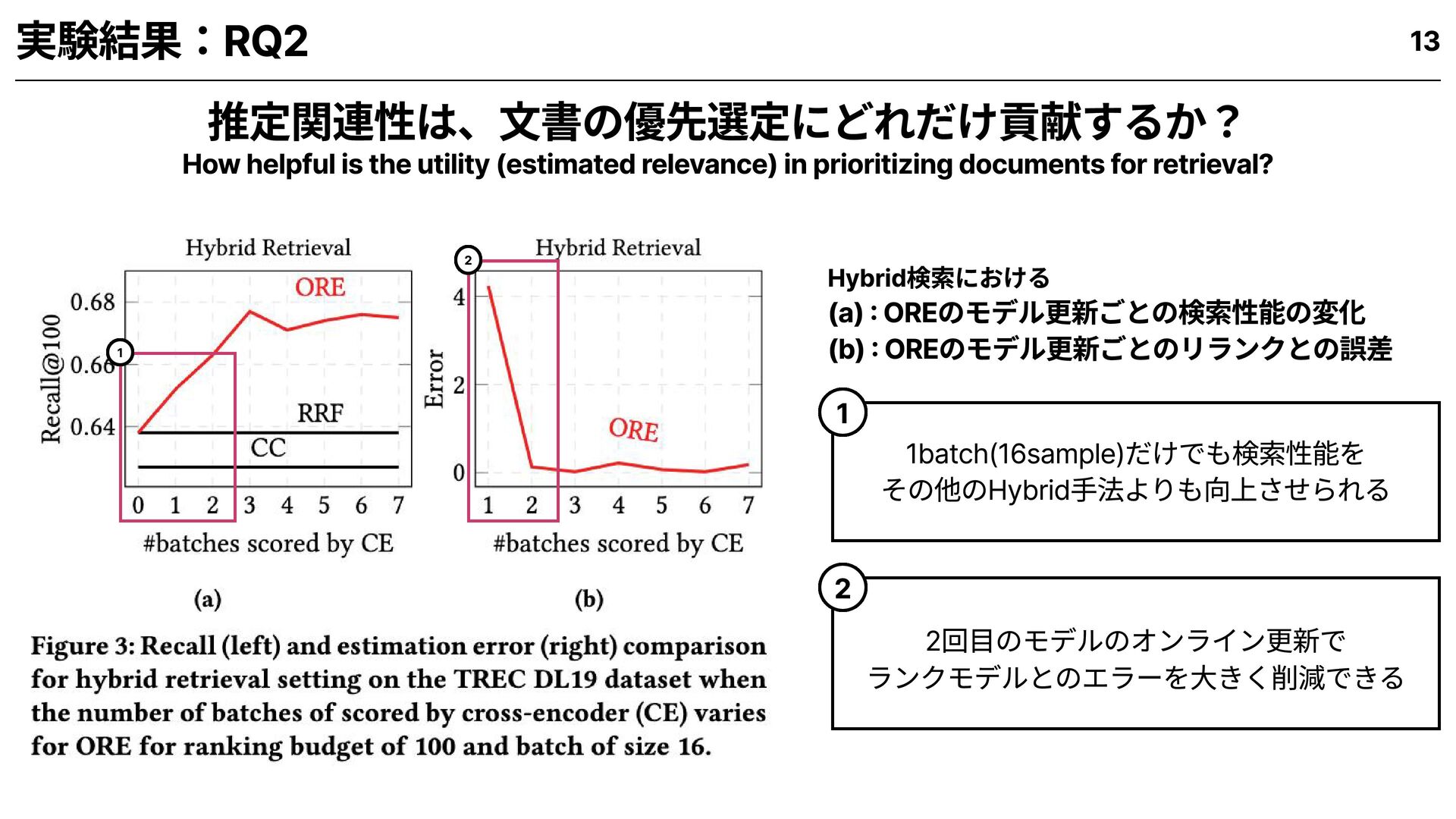
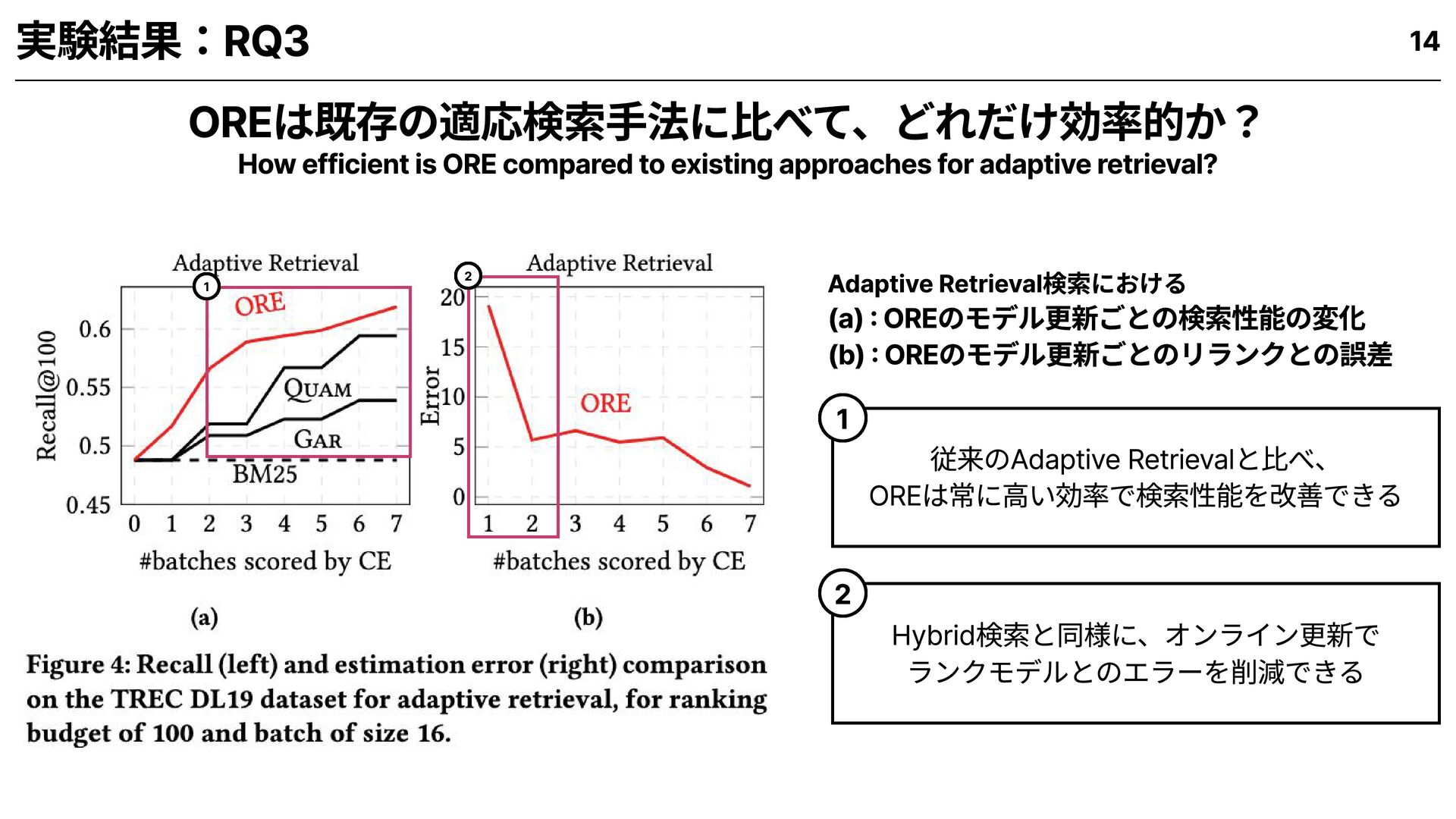
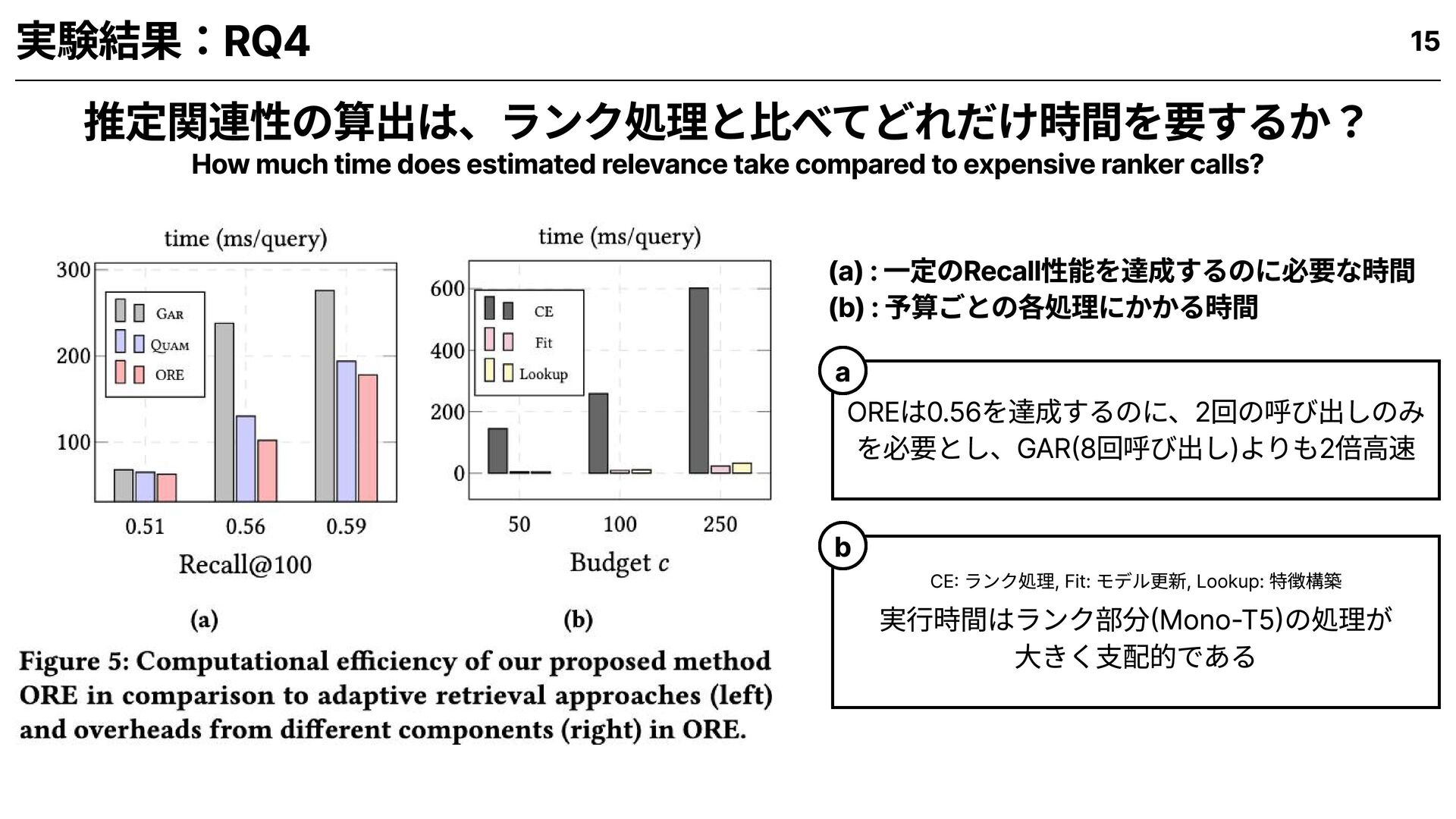
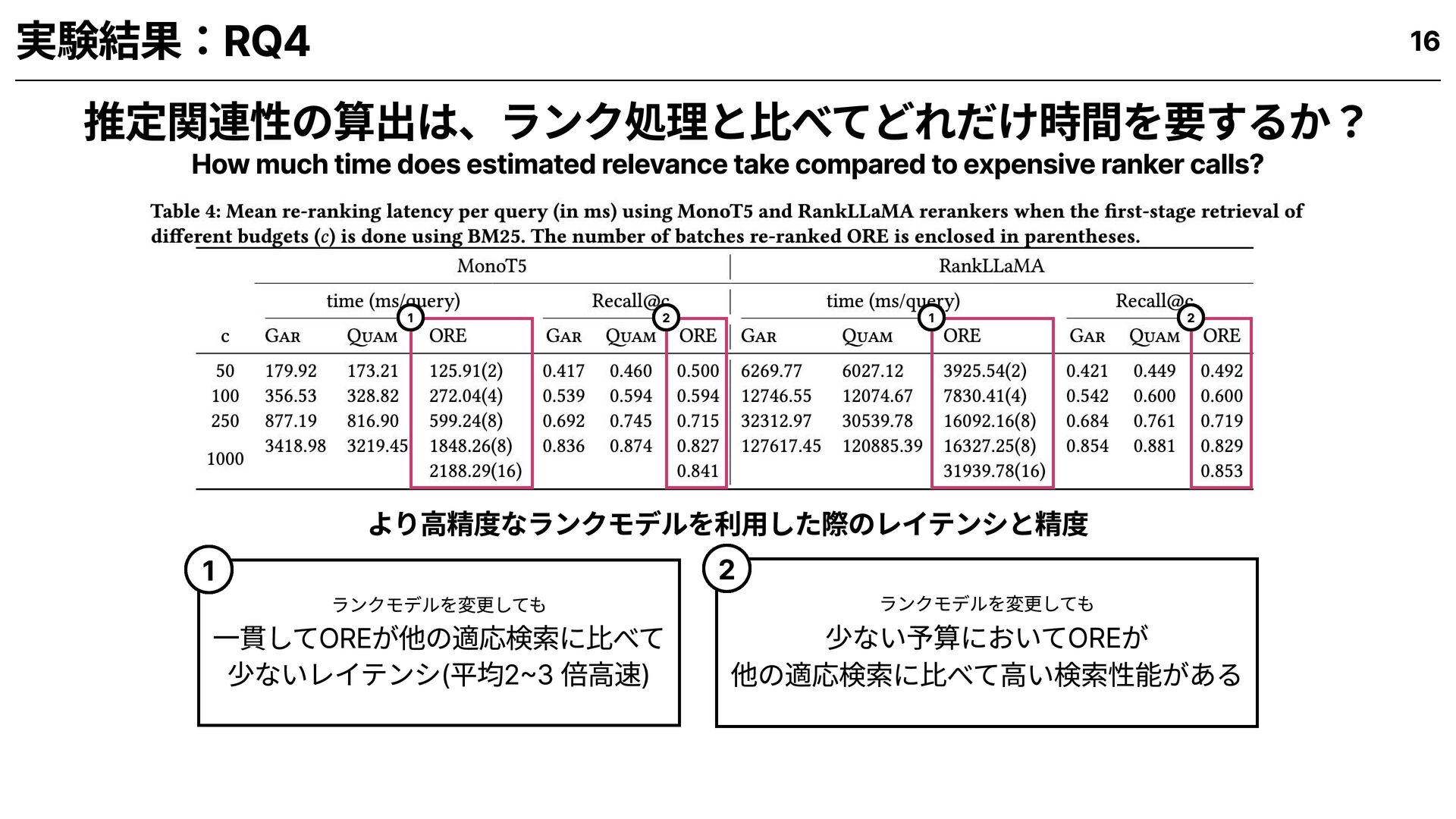
for hybrid and adaptive retrieval setups? OREは、既存手法に比べてどれだけ有効か? 1 How helpful is the utility (estimated relevance) in prioritizing documents for retrieval? 推定関連性は、文書の優先選定にどれだけ貢献するか? 2 How efficient is ORE compared to existing approaches for adaptive retrieval? OREは既存の適応検索手法に比べて、どれだけ効率的か? 3 How much time does estimated relevance take compared to expensive ranker calls? 推定関連性の算出は、高精度ランカー呼び出しと比べてどれだけ時間を要するか? 4 9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}