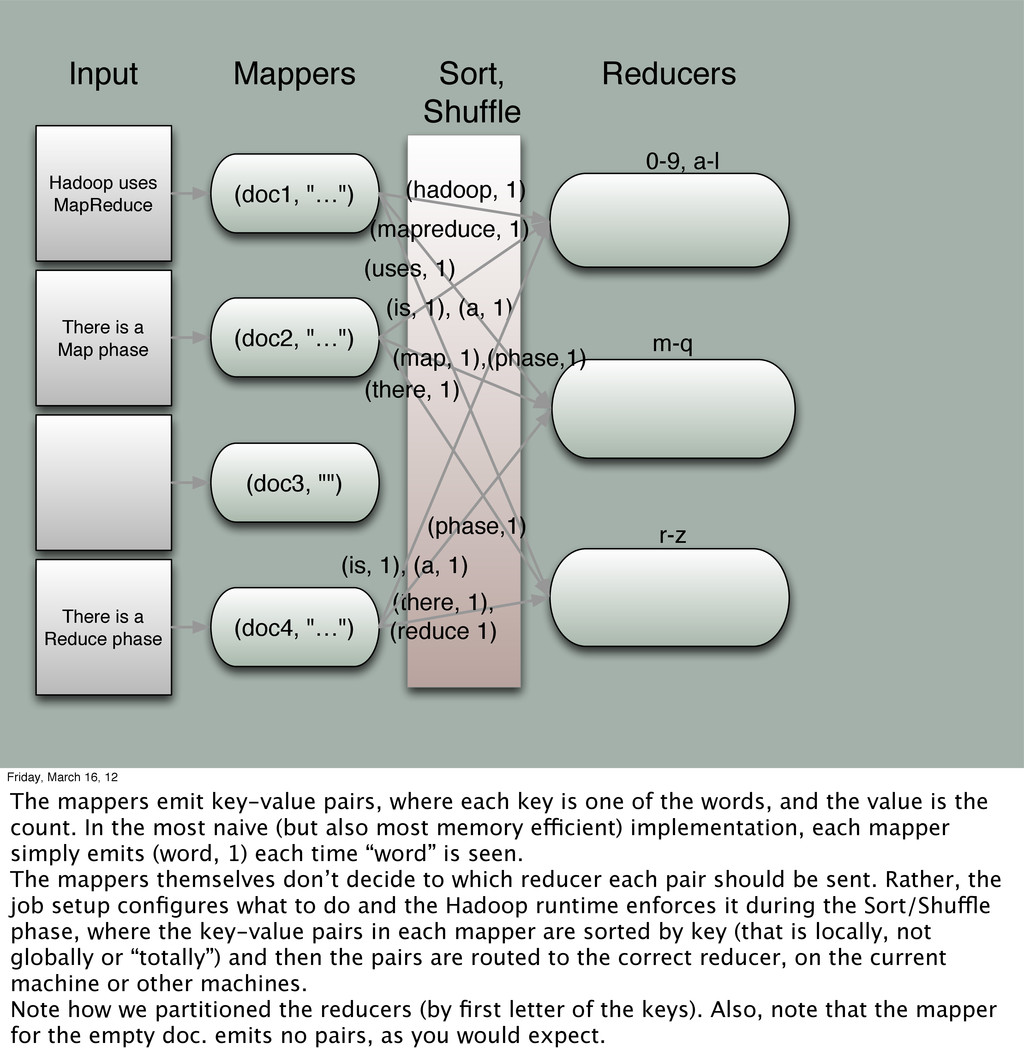
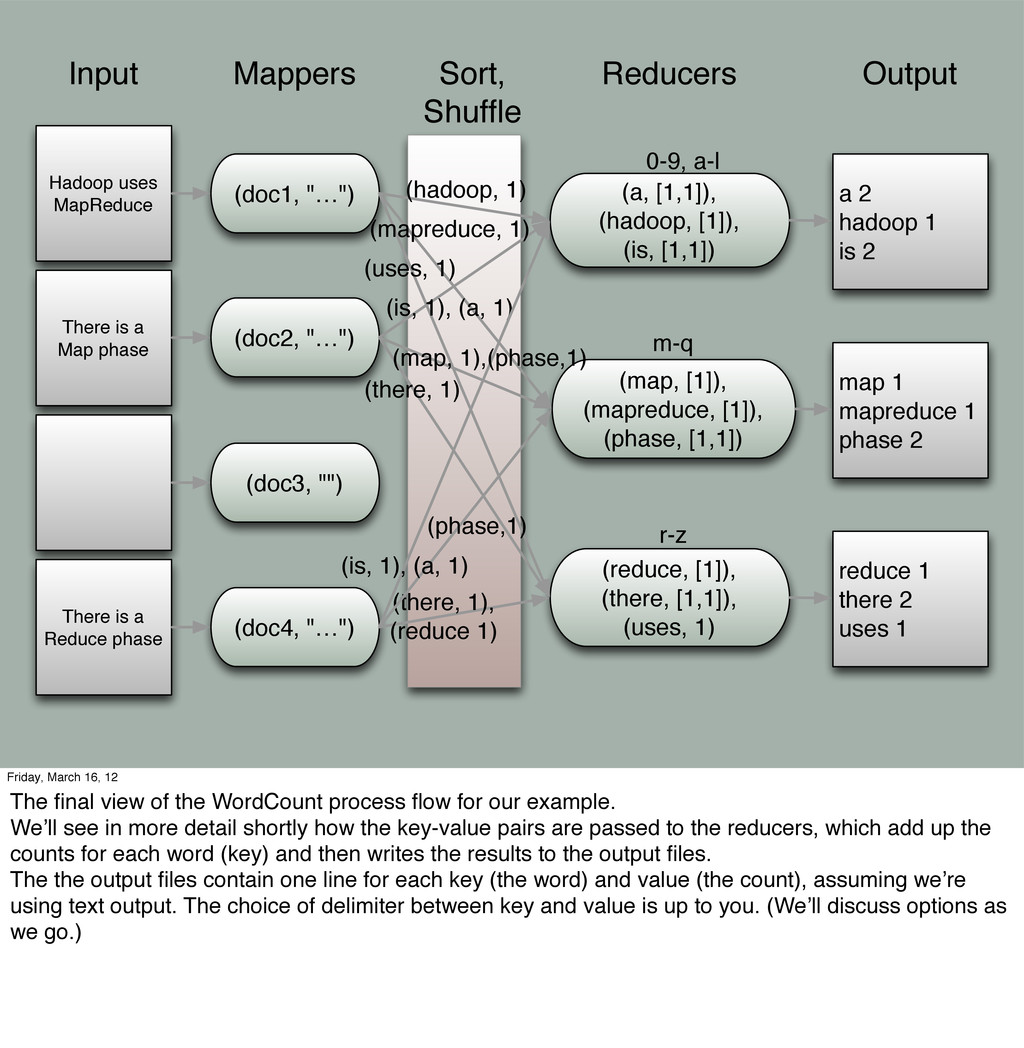
"…") (doc2, "…") (doc3, "") Mappers Sort, Shuffle (a, [1,1]), (hadoop, [1]), (is, [1,1]) (map, [1]), (mapreduce, [1]), (phase, [1,1]) Reducers There is a Reduce phase (doc4, "…") (reduce, [1]), (there, [1,1]), (uses, 1) (hadoop, 1) (uses, 1) (mapreduce, 1) (is, 1), (a, 1) (there, 1) (there, 1), (reduce 1) (phase,1) (map, 1),(phase,1) (is, 1), (a, 1) 0-9, a-l m-q r-z Friday, March 16, 12 The mappers emit key-value pairs, where each key is one of the words, and the value is the count. In the most naive (but also most memory efficient) implementation, each mapper simply emits (word, 1) each time “word” is seen. The mappers themselves don’t decide to which reducer each pair should be sent. Rather, the job setup configures what to do and the Hadoop runtime enforces it during the Sort/Shuffle phase, where the key-value pairs in each mapper are sorted by key (that is locally, not globally or “totally”) and then the pairs are routed to the correct reducer, on the current machine or other machines. Note how we partitioned the reducers (by first letter of the keys). Also, note that the mapper for the empty doc. emits no pairs, as you would expect.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}