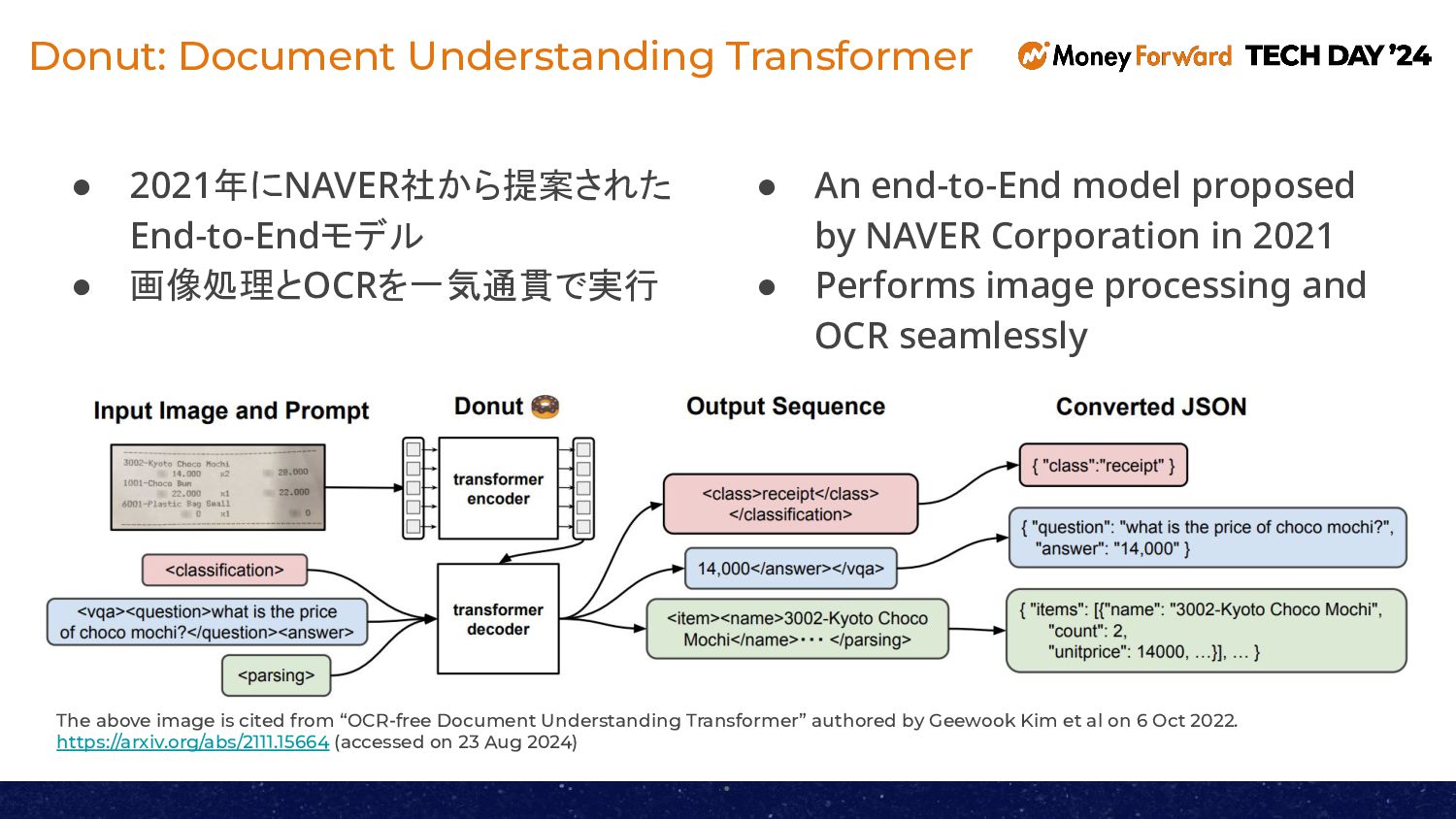
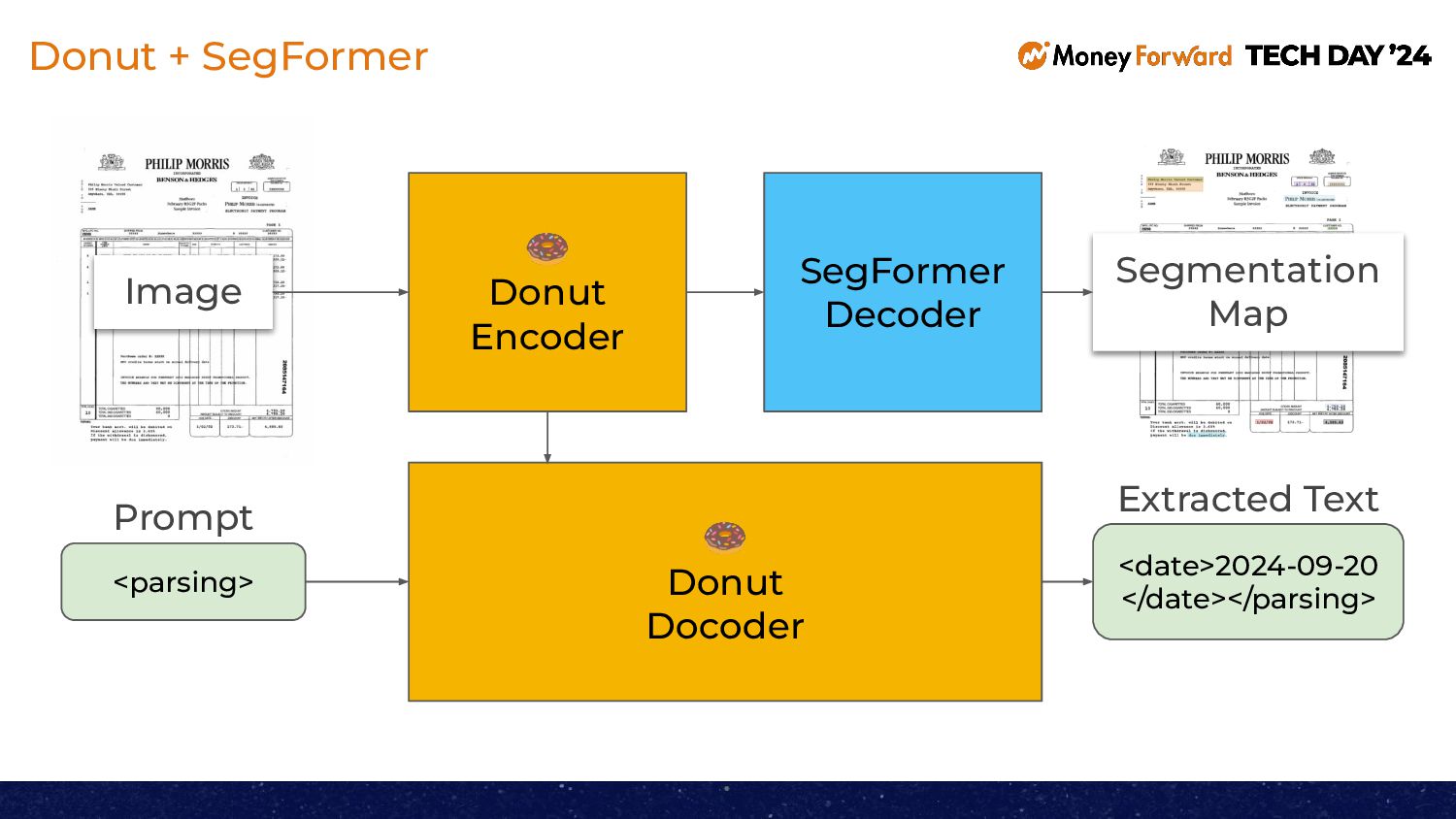
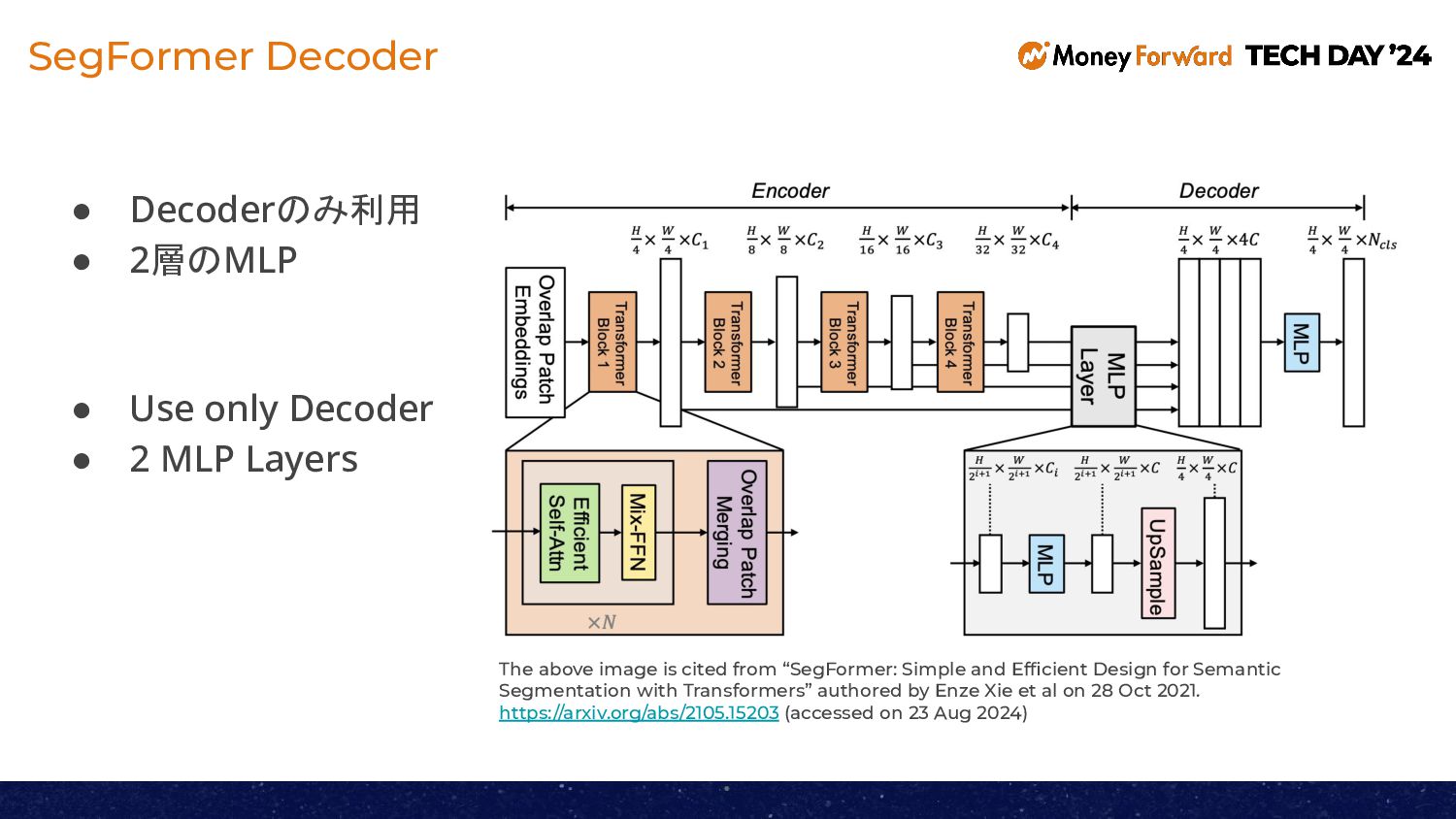
Donut is a machine learning model that can extract information such as billing amounts and account numbers from documents like invoices. We conducted an experiment to enhance Donut by integrating a position estimation model called SegFormer. In this session, we will share the results of this experiment.
請求書などの文書から請求金額や口座番号などの情報を読み取ることができる機械学習モデルであるDonut。このDonutにSegFormaerという位置推定モデルの機能を追加する実験を行いましたので、その結果をご紹介いたします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}