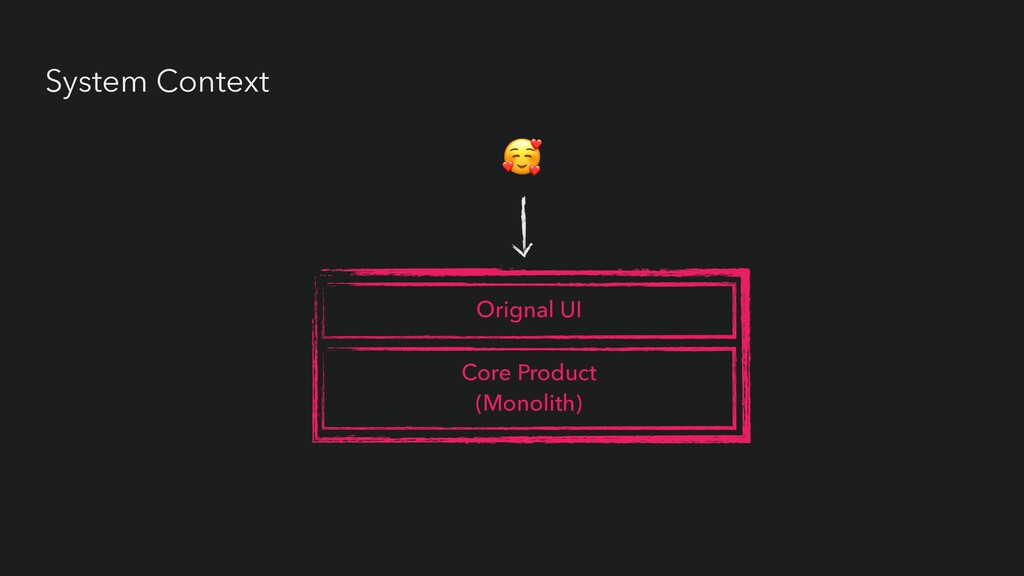
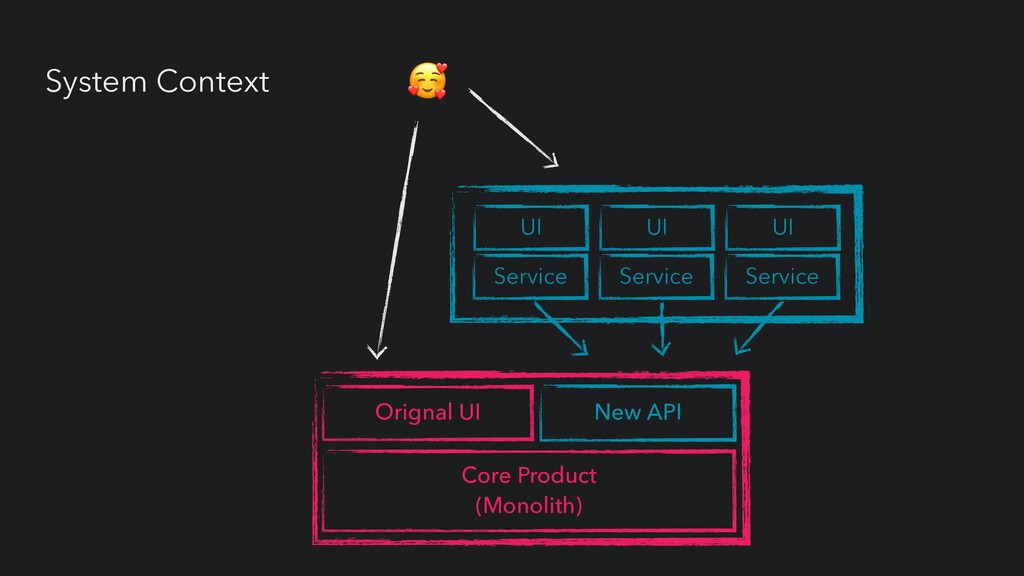
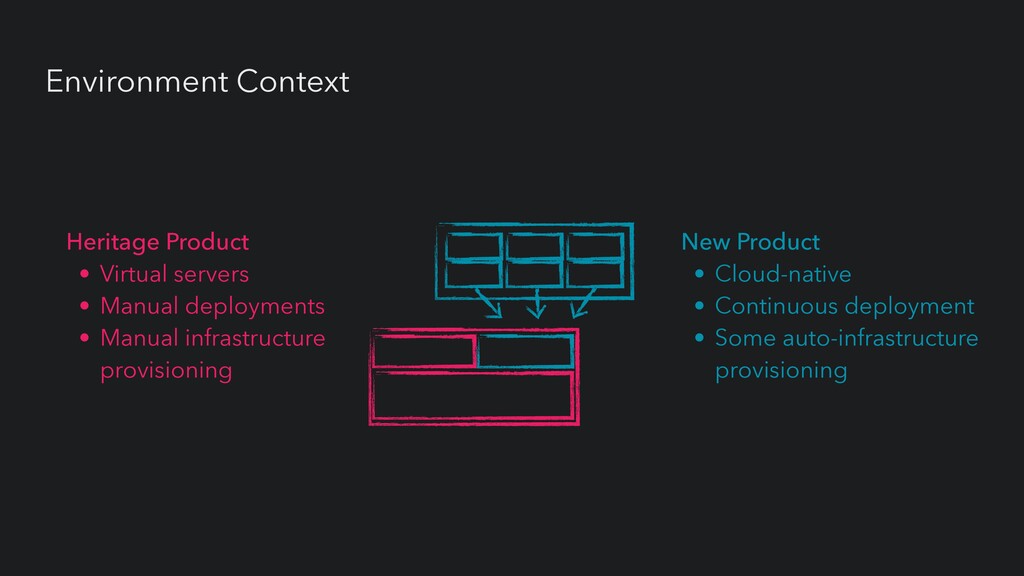
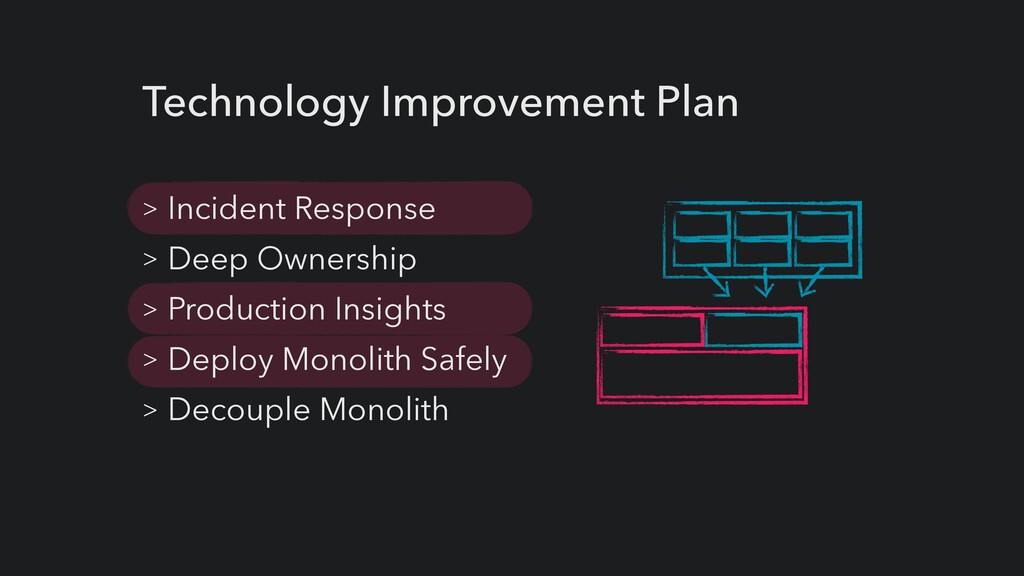
UI Service Service Service Core Product (Monolith) • Agile delivery • Low test-automation • Incidents highly disruptive • Reliance on long-tenured engineers • Traditional ops team (HIGH TOIL)
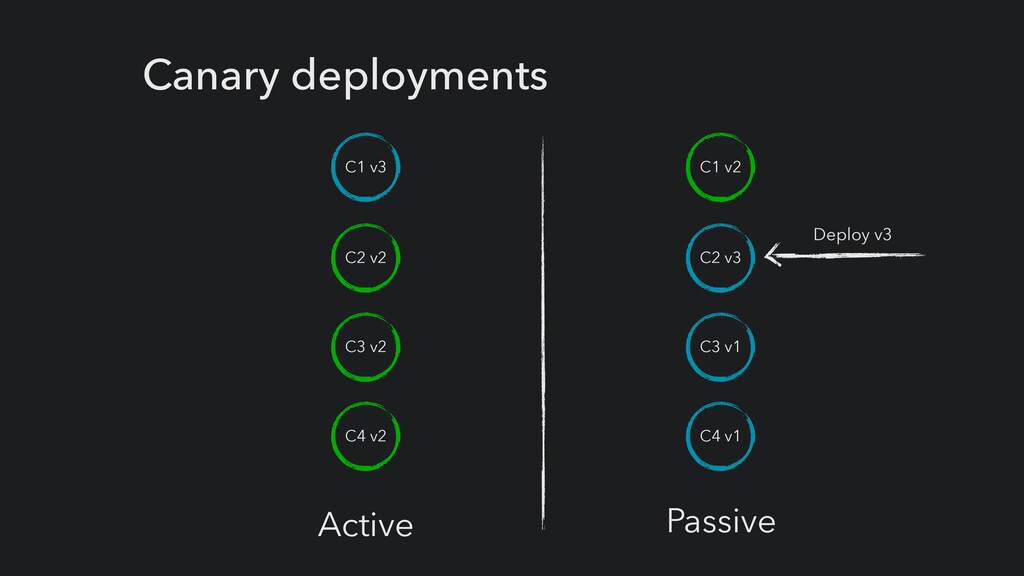
rollback effortless > Reduce configuration change risk > Make it easy to setup a new environment > Make it easy to analyse and troubleshoot problems > Give everyone the skills to fix problems > Handle production outages cool, calm and controlled
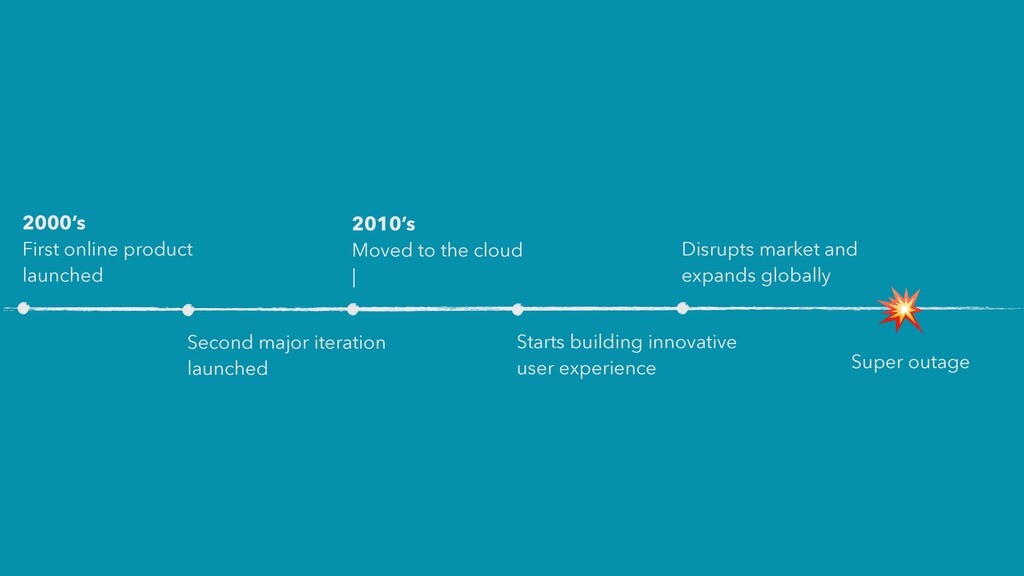
Proposed a stop to delivery to focus on resilience > Ended up securing about 1/5 of engineering capacity https://www.wired.com/2013/04/linkedin-software-revolution/
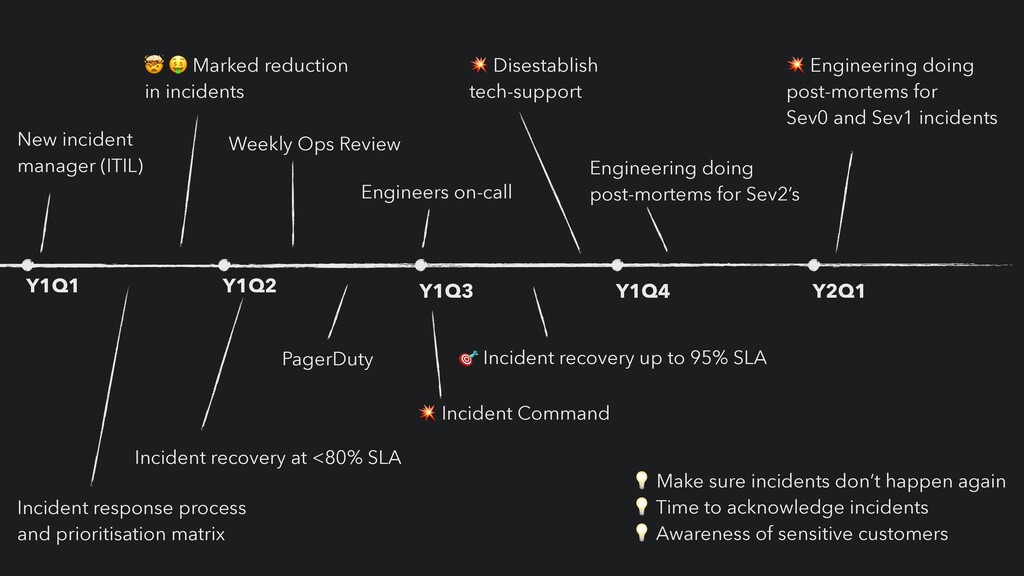
response process and prioritisation matrix Engineers on-call PagerDuty 🤯 🤑 Marked reduction in incidents 💥 Incident Command Weekly Ops Review 💥 Disestablish tech-support 🎯 Incident recovery up to 95% SLA Incident recovery at <80% SLA Engineering doing post-mortems for Sev2’s 💥 Engineering doing post-mortems for Sev0 and Sev1 incidents 💡 Make sure incidents don’t happen again 💡 Time to acknowledge incidents 💡 Awareness of sensitive customers
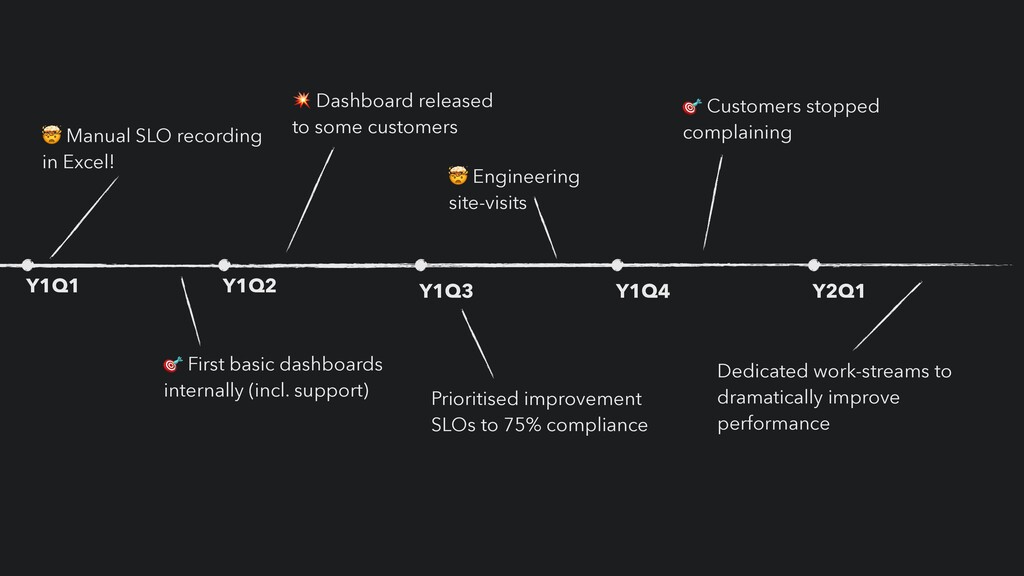
• We started detecting issues before out customers! • Incidents resolved within SLA (improved from 80% to 95%+) • Mostly automated deployment and provisioning on our monolith • Reducing the impact of bad deployments • Rollback within minutes instead of hours (or even days) • Enabled modernisation roadmap • Happy customers!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}