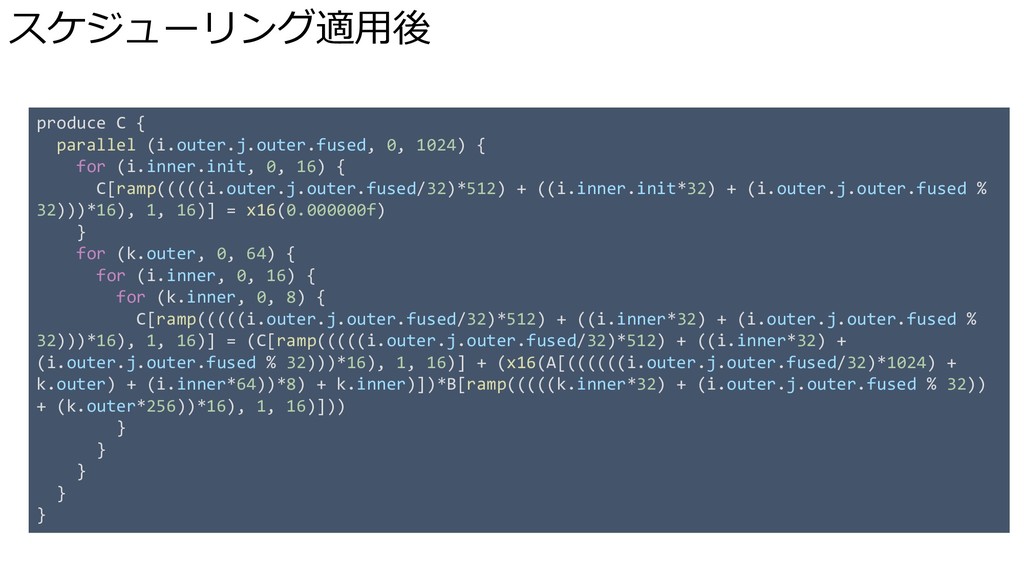
phi float [ 0.000000e+00, %entry ], [ %147, %for_body ] %indvars.iv = phi i64 [ 0, %entry ], [ %indvars.iv.next, %for_body ] tail call void @llvm.amdgcn.s.barrier() %84 = trunc i64 %indvars.iv to i32 %85 = add i32 %9, %84 %86 = shl i32 %85, 4 %87 = add nsw i32 %86, %6 %88 = sext i32 %87 to i64 %89 = getelementptr inbounds float, float addrspace(1)* %1, i64 %88 %90 = bitcast float addrspace(1)* %89 to i32 addrspace(1)* %91 = load i32, i32 addrspace(1)* %90, align 4, !tbaa !8 store i32 %91, i32 addrspace(3)* %18, align 4, !tbaa !11 %indvars.iv.tr = trunc i64 %indvars.iv to i32 %92 = shl i32 %indvars.iv.tr, 10 %93 = add i32 %19, %92 %94 = shl i32 %93, 4 %95 = add nsw i32 %94, %6 %96 = sext i32 %95 to i64 %97 = getelementptr inbounds float, float addrspace(1)* %2, i64 %96 %98 = bitcast float addrspace(1)* %97 to i32 addrspace(1)* %99 = load i32, i32 addrspace(1)* %98, align 4, !tbaa !14 store i32 %99, i32 addrspace(3)* %21, align 4, !tbaa !17 tail call void @llvm.amdgcn.s.barrier() %100 = load float, float addrspace(3)* %22, align 16, !tbaa !11 %101 = load float, float addrspace(3)* %23, align 4, !tbaa !17 %102 = tail call float @llvm.fmuladd.f32(float %100, float %101, float %.promoted) %103 = load float, float addrspace(3)* %25, align 4, !tbaa !11 %104 = load float, float addrspace(3)* %27, align 4, !tbaa !17 %105 = tail call float @llvm.fmuladd.f32(float %103, float %104, float %102) %106 = load float, float addrspace(3)* %29, align 8, !tbaa !11 %107 = load float, float addrspace(3)* %31, align 4, !tbaa !17 %108 = tail call float @llvm.fmuladd.f32(float %106, float %107, float %105) ..... BB0_1: v_add_u32_e32 v11, vcc, s6, v0 v_ashrrev_i32_e32 v12, 31, v11 v_ashrrev_i32_e32 v10, 31, v9 v_lshlrev_b64 v[11:12], 2, v[11:12] v_lshlrev_b64 v[13:14], 2, v[9:10] v_mov_b32_e32 v1, s1 v_add_u32_e32 v10, vcc, s0, v11 v_addc_u32_e32 v11, vcc, v1, v12, vcc v_mov_b32_e32 v15, s3 v_add_u32_e32 v12, vcc, s2, v13 v_addc_u32_e32 v13, vcc, v15, v14, vcc flat_load_dword v1, v[10:11] flat_load_dword v10, v[12:13] s_waitcnt vmcnt(0) lgkmcnt(0) s_barrier s_add_u32 s6, s6, 16 s_addc_u32 s7, s7, 0 v_add_u32_e32 v9, vcc, 0x4000, v9 s_cmp_lg_u64 s[6:7], s[4:5] ds_write_b32 v6, v1 ds_write_b32 v5, v10 s_waitcnt lgkmcnt(0) s_barrier ds_read2_b32 v[18:19], v8 offset1:16 ds_read2_b64 v[10:13], v7 offset1:1 ds_read2_b64 v[14:17], v7 offset0:2 offset1:3 s_waitcnt lgkmcnt(1) v_mac_f32_e32 v4, v10, v18 v_mac_f32_e32 v4, v11, v19 ds_read2_b32 v[10:11], v8 offset0:32 offset1:48 s_waitcnt lgkmcnt(0) v_mac_f32_e32 v4, v12, v10 v_mac_f32_e32 v4, v13, v11 ds_read2_b32 v[10:11], v8 offset0:64 offset1:80 ds_read2_b32 v[12:13], v8 offset0:96 offset1:112 ds_read2_b32 v[18:19], v8 offset0:128 offset1:144 s_waitcnt lgkmcnt(2) v_mac_f32_e32 v4, v14, v10 v_mac_f32_e32 v4, v15, v11 s_waitcnt lgkmcnt(1) .....
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![共有メモリの利用 num_thread = 16 k, = s[C].op.reduce_axis ko, ki =](https://files.speakerdeck.com/presentations/f3c6a6b865a74183a91b57070d6f3cd4/slide_18.jpg){kind=link}
![共有メモリの利用 produce C { // attr [iter_var(blockIdx.y, , blockIdx.y)] thread_extent](https://files.speakerdeck.com/presentations/f3c6a6b865a74183a91b57070d6f3cd4/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[WIP] Graph level Auto Tuning • AutoTVM によって, オペレータ (ノード)](https://files.speakerdeck.com/presentations/f3c6a6b865a74183a91b57070d6f3cd4/slide_46.jpg){kind=link}
![[WIP] Relay – NNVM IR v2 • 詳細は LT にて,](https://files.speakerdeck.com/presentations/f3c6a6b865a74183a91b57070d6f3cd4/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
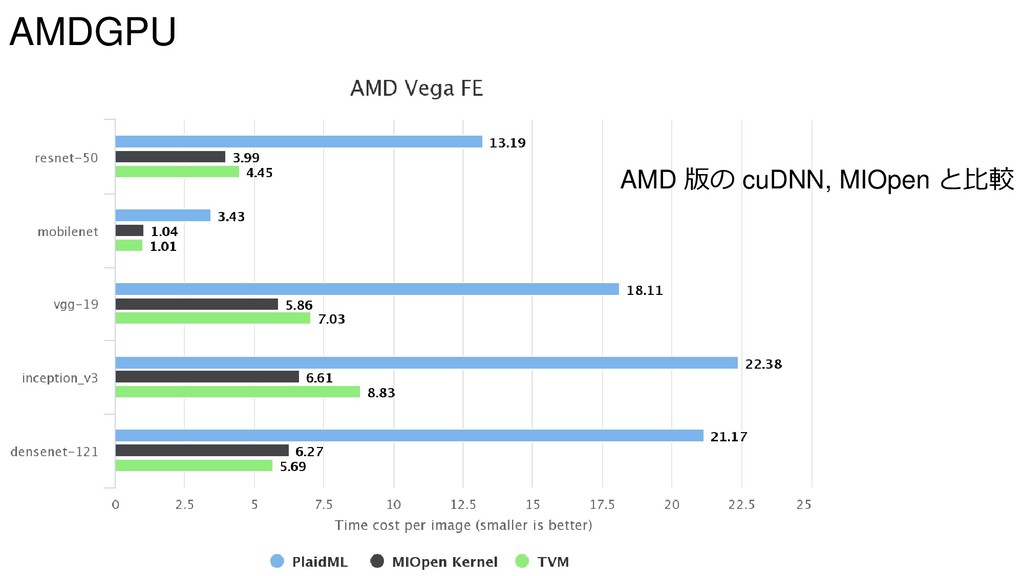{kind=link}
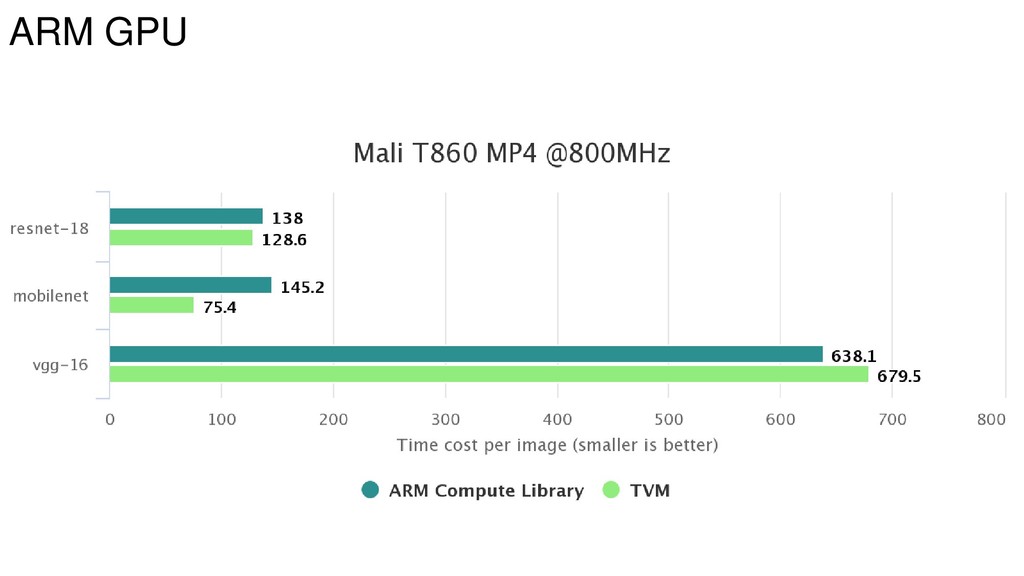{kind=link}
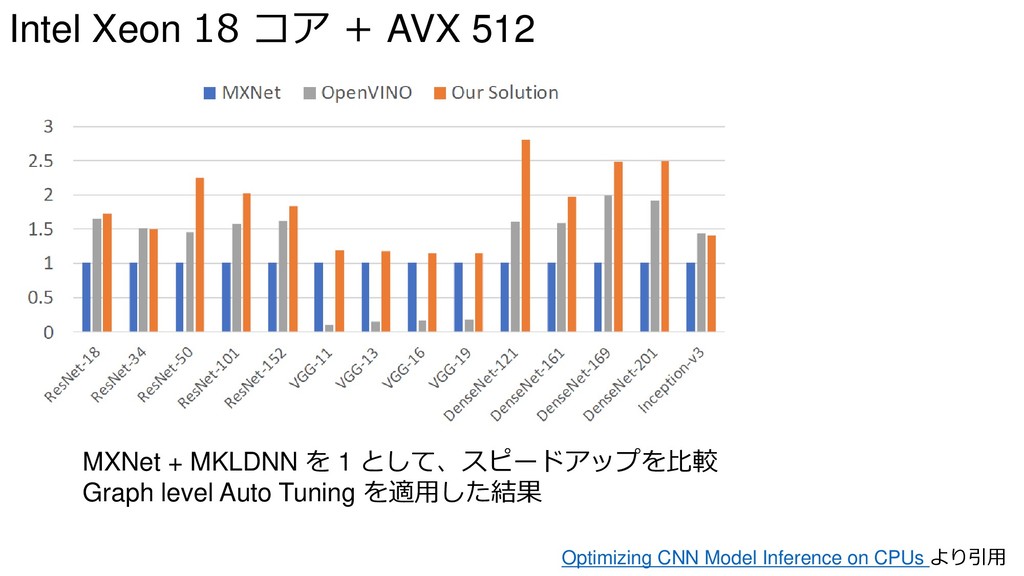{kind=link}
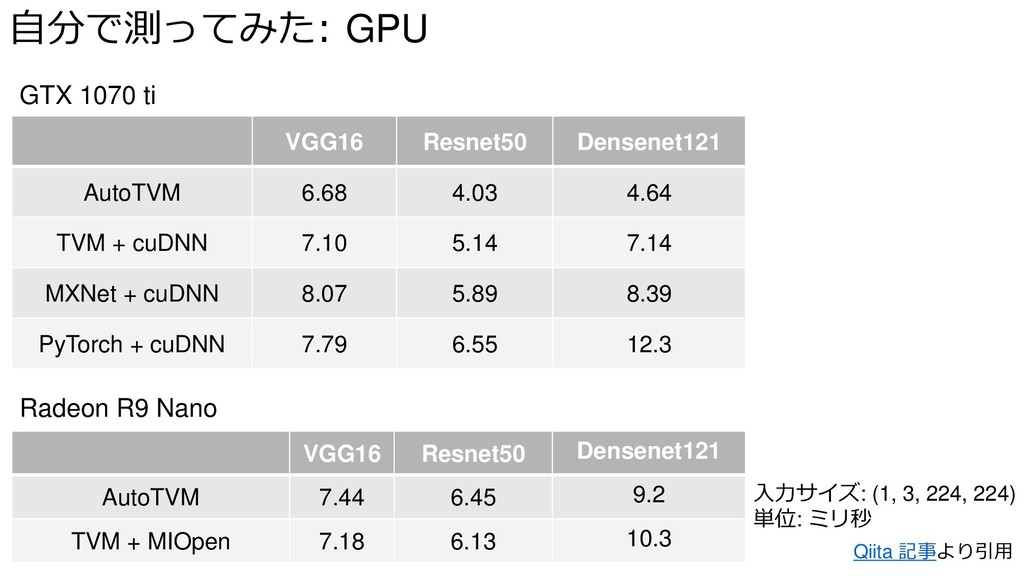{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TVM とコミュニティ • コントリビュータやユーザーを主体としたコミュニティづくりを重視 より詳しくは, TVM Community Structure, [RFC] Community](https://files.speakerdeck.com/presentations/f3c6a6b865a74183a91b57070d6f3cd4/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}