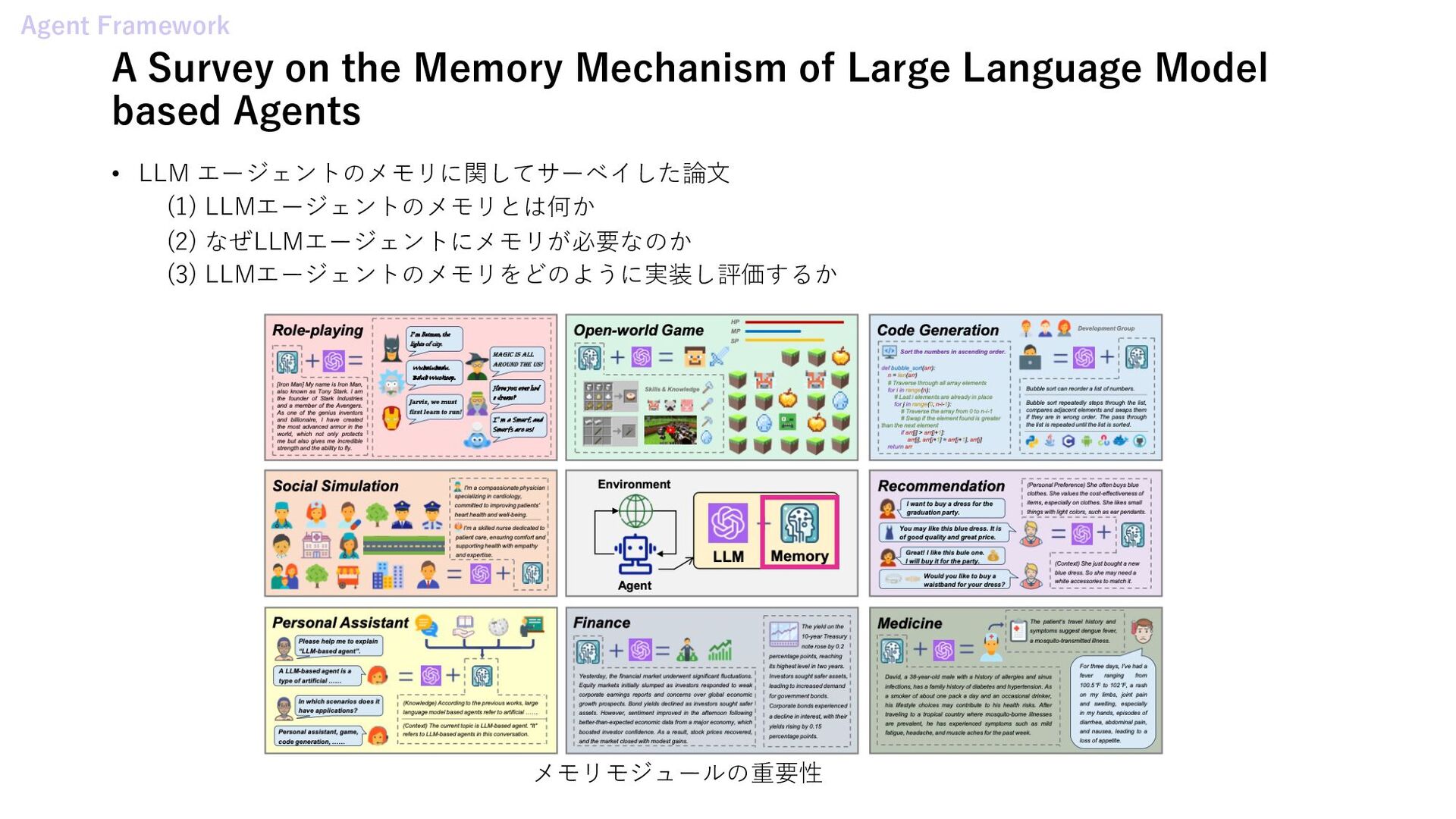
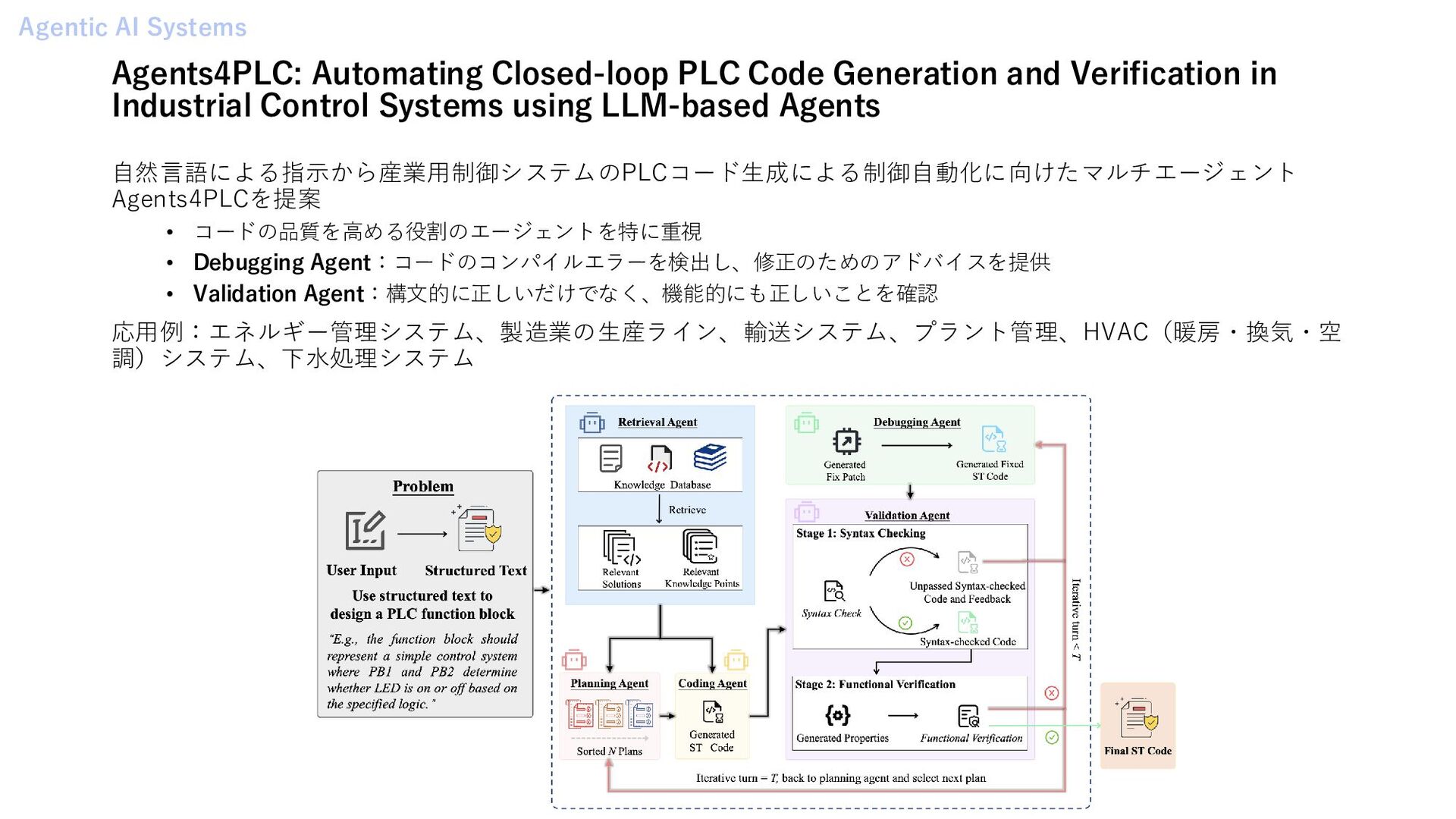
Threats and Countermeasures 学習 • ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning • A Survey on the Optimization of Large Language Model-based Agents ツール • Advanced Tool Learning and Selection System (ATLASS): A Closed-Loop Framework Using LLM 評価 • WritingBench: A Comprehensive Benchmark for Generative Writing • Large Reasoning Models in Agent Scenarios: Exploring the Necessity of Reasoning Capabilities メモリ • In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents • AI-native Memory 2.0: Second Me Agent Framework • API Agents vs. GUI Agents: Divergence and Convergence
Advances and Applications • BannerAgency: Advertising Banner Design with Multimodal LLM Agents • MDocAgent: A Multi-Modal Multi-Agent Framework for Document Understanding • MAP : Multi-user Personalization with Collaborative LLM-powered Agents Data Agents • OR-LLM-Agent: Automating Modeling and Solving of Operations Research Optimization Problem with Reasoning Large Language Model • AIDE: AI-Driven Exploration in the Space of Code • Exploring LLM Agents for Cleaning Tabular Machine Learning Datasets • DatawiseAgent: A Notebook-Centric LLM Agent Framework for Automated Data Science • DAgent: A Relational Database-Driven Data Analysis Report Generation Agent Digital Agents • Pokemon Red via Reinforcement Learning Research Agents • ReviewAgents: Bridging the Gap Between Human and AI-Generated Paper Reviews Multi Agent Systems • Why Do Multi-Agent LLM Systems Fail? • A Comprehensive Survey on Multi-Agent Cooperative Decision-Making: Scenarios, Approaches, Challenges and Perspectives
of Operations Research Optimization Problem with Reasoning Large Language Model ORは資源配分、生産計画、サプライチェーン管理などに幅広く適用されているが、専門家による数学的モデリン グとプログラミングが必要であり、高コストかつ開発サイクルが長い。 ORの標準的な教科書から83個の実問題を収集し評価した結果、o3-mini単体より精度が8.4%向上 3月24日 更新分 Data Agents (o3-mini)
trained • Leave it to Manus • Model Context Protocol (MCP): Integrating Azure OpenAI for Enhanced Tool Integration and Prompting • アドビが一挙10種類の「AIエージェント」発表。高まる企業の生成AI需要に応える • Advanced Large Language Model Agents @MOOC, Spring 2025 • Long-Term Agentic Memory with LangGraph @DeepLearning.AI
Inference-Time Techniques for LLM Reasoning • Learning to reason with LLMs • On Reasoning, Memory, and Planning of Language Agents • Open Training Recipes for Reasoning in Language Models • Coding Agents and AI for Vulnerability Detection • Multimodal Autonomous AI Agents • Multimodal Agents – From Perception to Action https://llmagents-learning.org/sp25
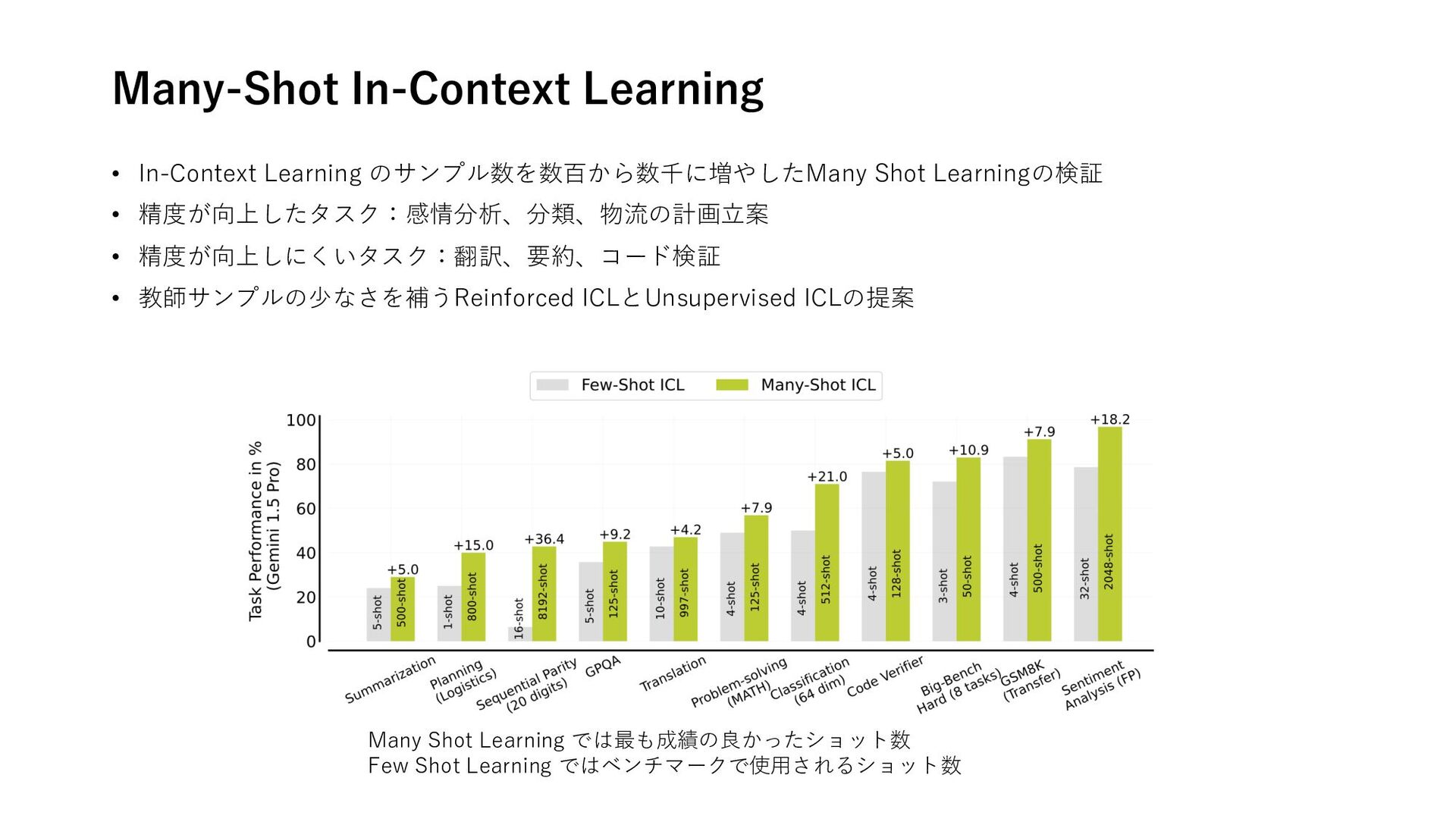
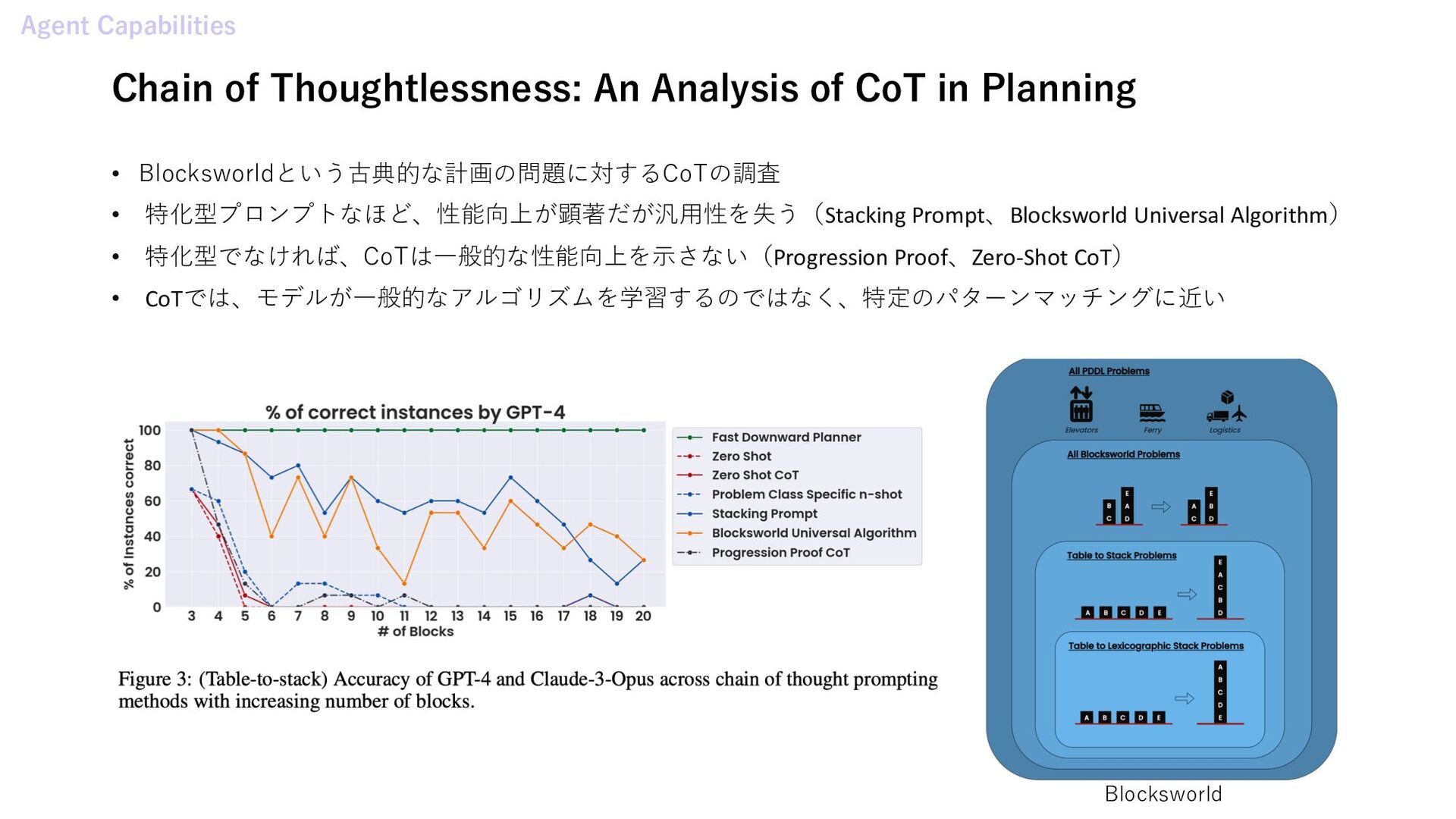
Planning and Reasoning Trajectories for Complex Problem Solving • Conversational Planning for Personal Plans 推論 • Code to Think, Think to Code: A Survey on Code-Enhanced Reasoning and Reasoning-Driven Code Intelligence in LLMs • The Relationship Between Reasoning and Performance in Large Language Models -- o3 (mini) Thinks Harder, Not Longer 学習 • Training a Generally Curious Agent • ATLAS: Agent Tuning via Learning Critical Steps 自己修正 • Multi-Agent Verification: Scaling Test-Time Compute with Multiple Verifiers ツール • ToolFuzz - Automated Agent Tool Testing • From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions
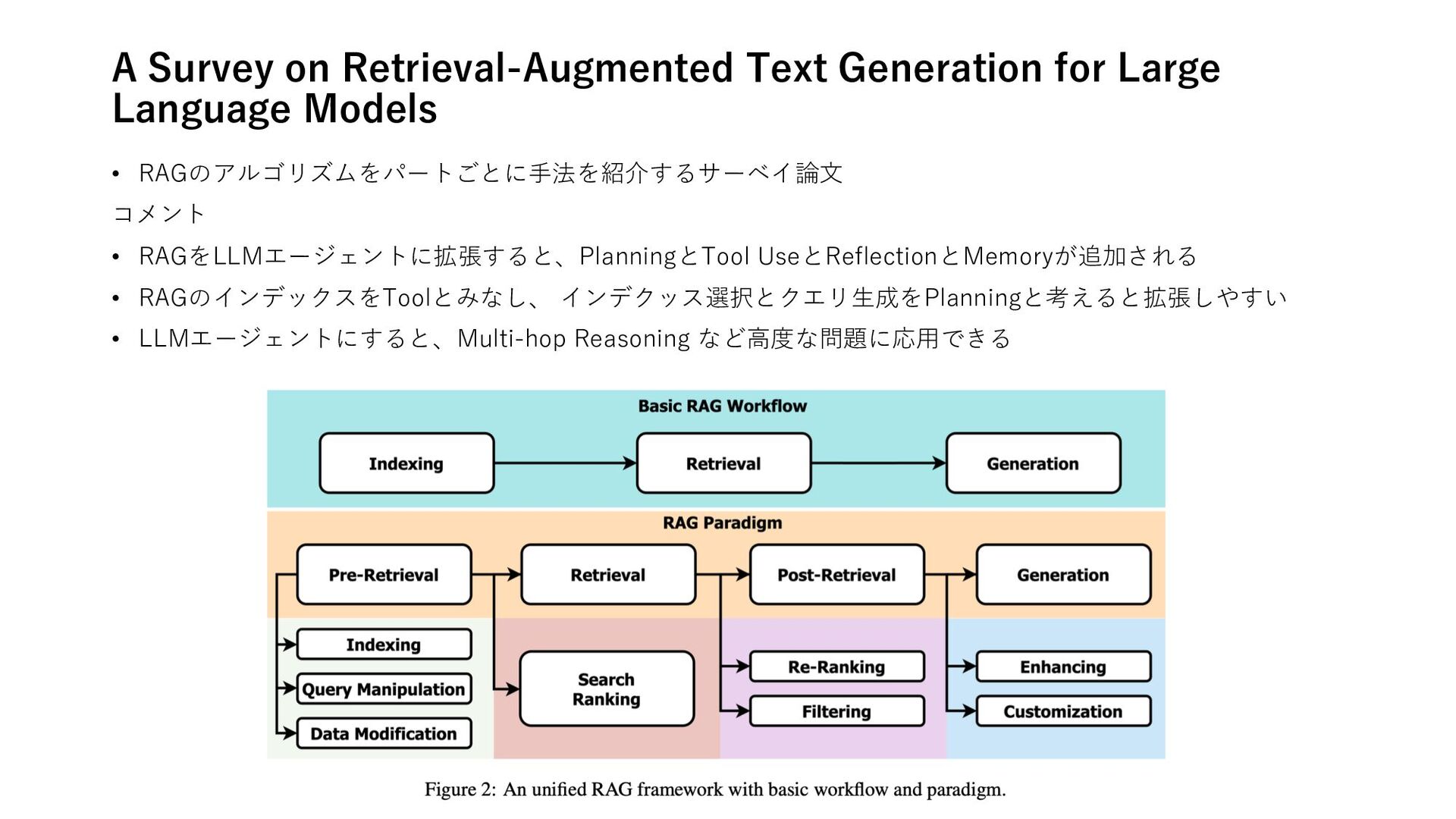
Optimization Techniques • Automatic Prompt Optimization via Heuristic Search: A Survey メモリ • A Practical Memory Injection Attack against LLM Agents Agent Framework • FLOWAGENT: Achieving Compliance and Flexibility for Workflow Agents • AutoAgent: A Fully-Automated and Zero-Code Framework for LLM Agents Data Agents • METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling Embodied Agents • Magma: A Foundation Model for Multimodal AI Agents Multi Agent Systems • Beyond Self-Talk: A Communication-Centric Survey of LLM-Based Multi-Agent Systems
use via hierarchical summarization • AIをシステム開発に活かすコツ、全部書く • CLINEに全部賭けろ • Clineに全部賭ける前に 〜Clineの動作原理を深掘り〜 • 法令 Deep Research ツール Lawsy を OSS として公開しました • Top 15 AI Agent Papers from February 2025 shaping their future • AIエージェントを開発するために注力すべきポイント • 生成AIのAIエージェントを大手3社(AWS、Azure、Google Cloud)で徹底比較してみた • OpenAI’s Deep Research Team on Why Reinforcement Learning is the Future for AI Agents • Tips for building AI agents • AI Engineer Summit 2025: Agent Engineering (Day 1) • AI Engineer Summit 2025: Agent Engineering (Day 2)
On The Fly • EvoAgent: Agent Autonomous Evolution with Continual World Model for Long-Horizon Tasks • Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research • Agency Is Frame-Dependent Agentic AI Systems • A Survey on LLM-powered Agents for Recommender Systems Research Agents • Towards an AI co-scientist Multi Agent Systems • AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society • Flow-of-Action: SOP Enhanced LLM-Based Multi-Agent System for Root Cause Analysis
of Human Behaviors and Society シミュレーション用のLLMエージェントには認知、感情、欲求機能を持つ • 記憶、計画、意思決定機能を備え、状況に応じた社会的行動を行う 応用分野 • 日常行動、意見の極化、扇動的メッセージの拡散による炎上の再現 • ベーシックインカム(UBI)による消費増加、貧困層の精神的健康の向上、ハリケーンによる住民の移動変化 • 各種政策(税制改革、環境政策、社会福祉)の影響をシミュレーション • パンデミックや災害時の人間行動をシミュレーション • AIと人間の共存社会をシミュレーション 2月24日 更新分 Multi-Agent System
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
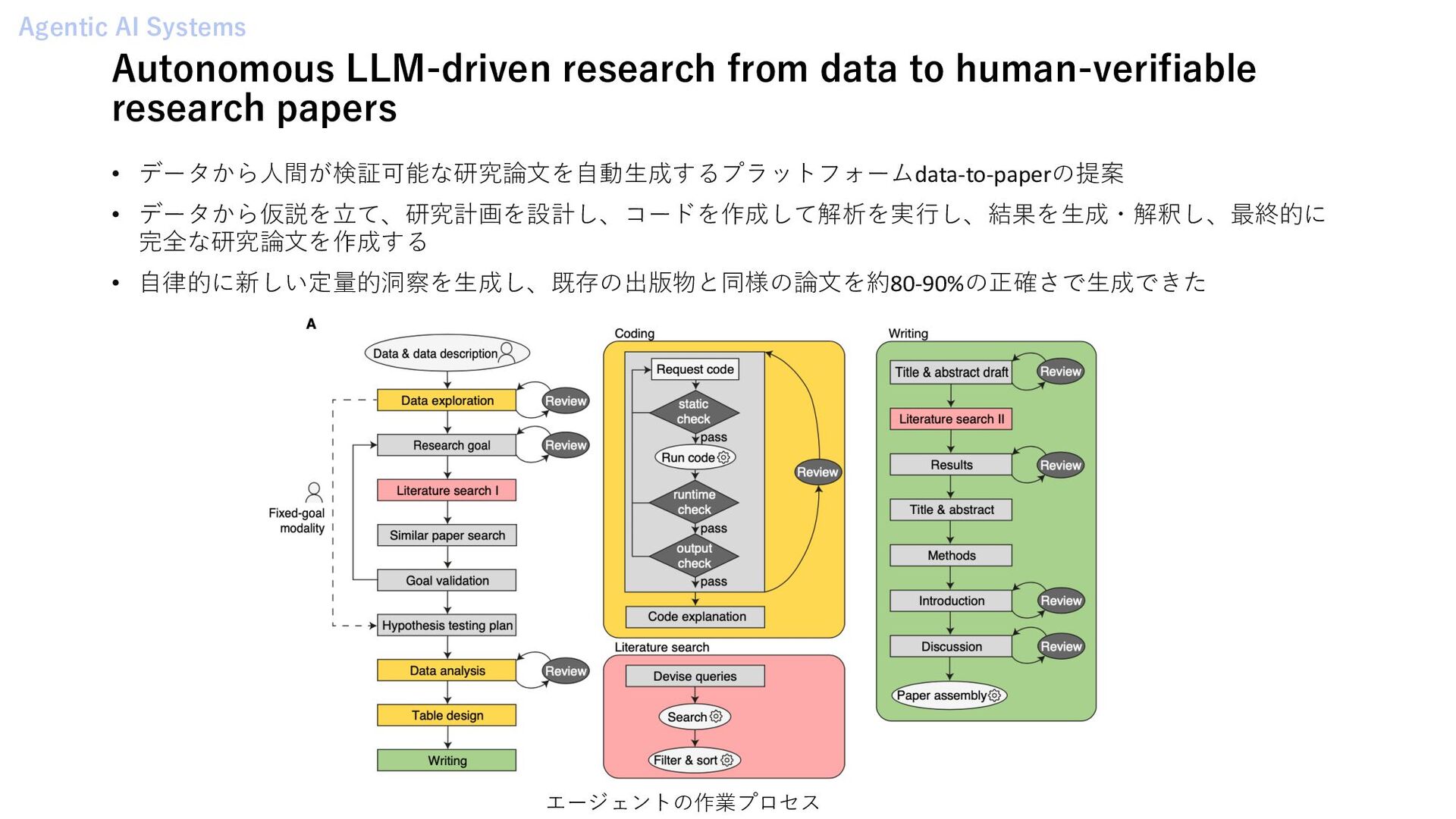{kind=link}
{kind=link}
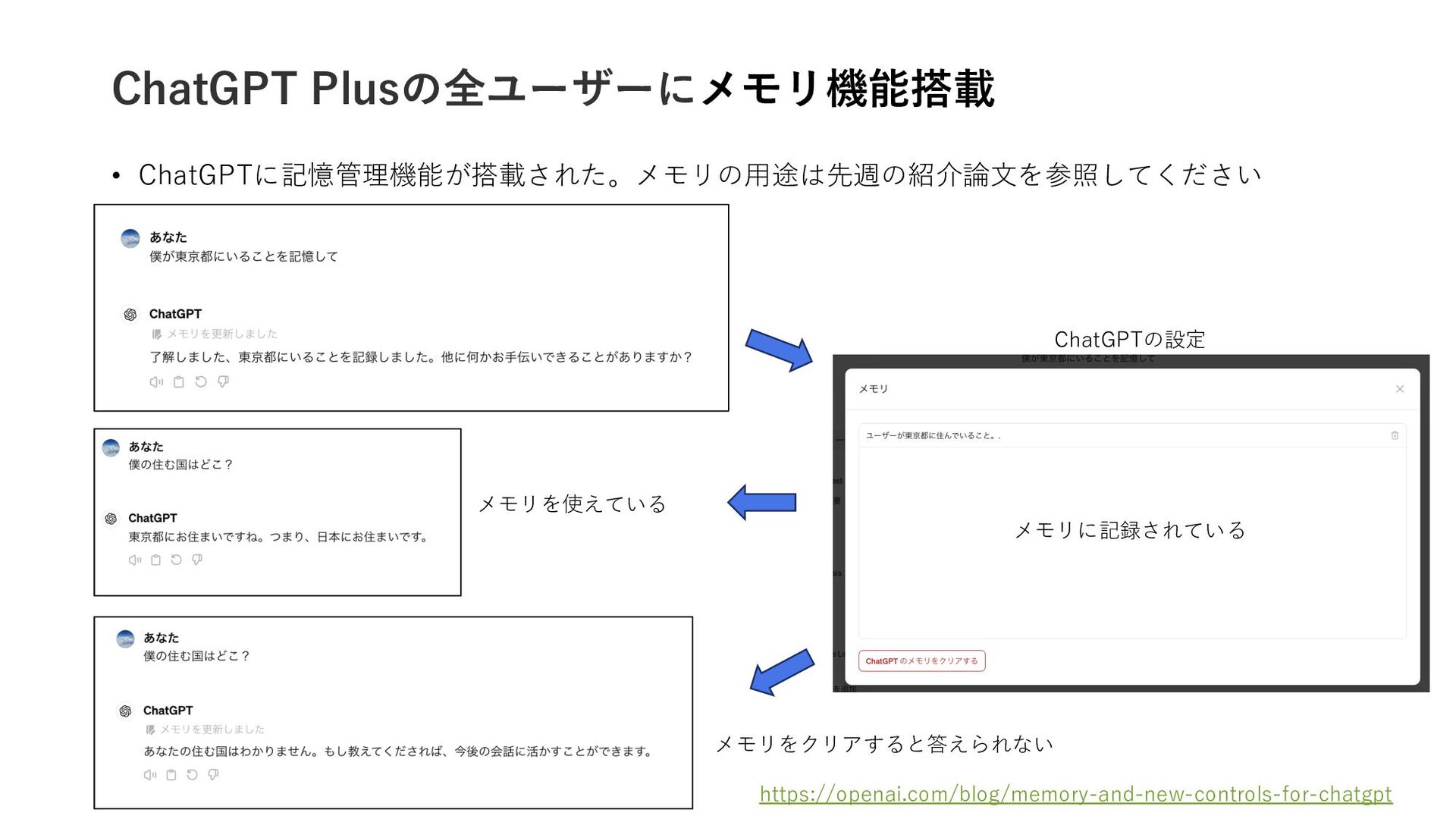{kind=link}
{kind=link}
{kind=link}
{kind=link}
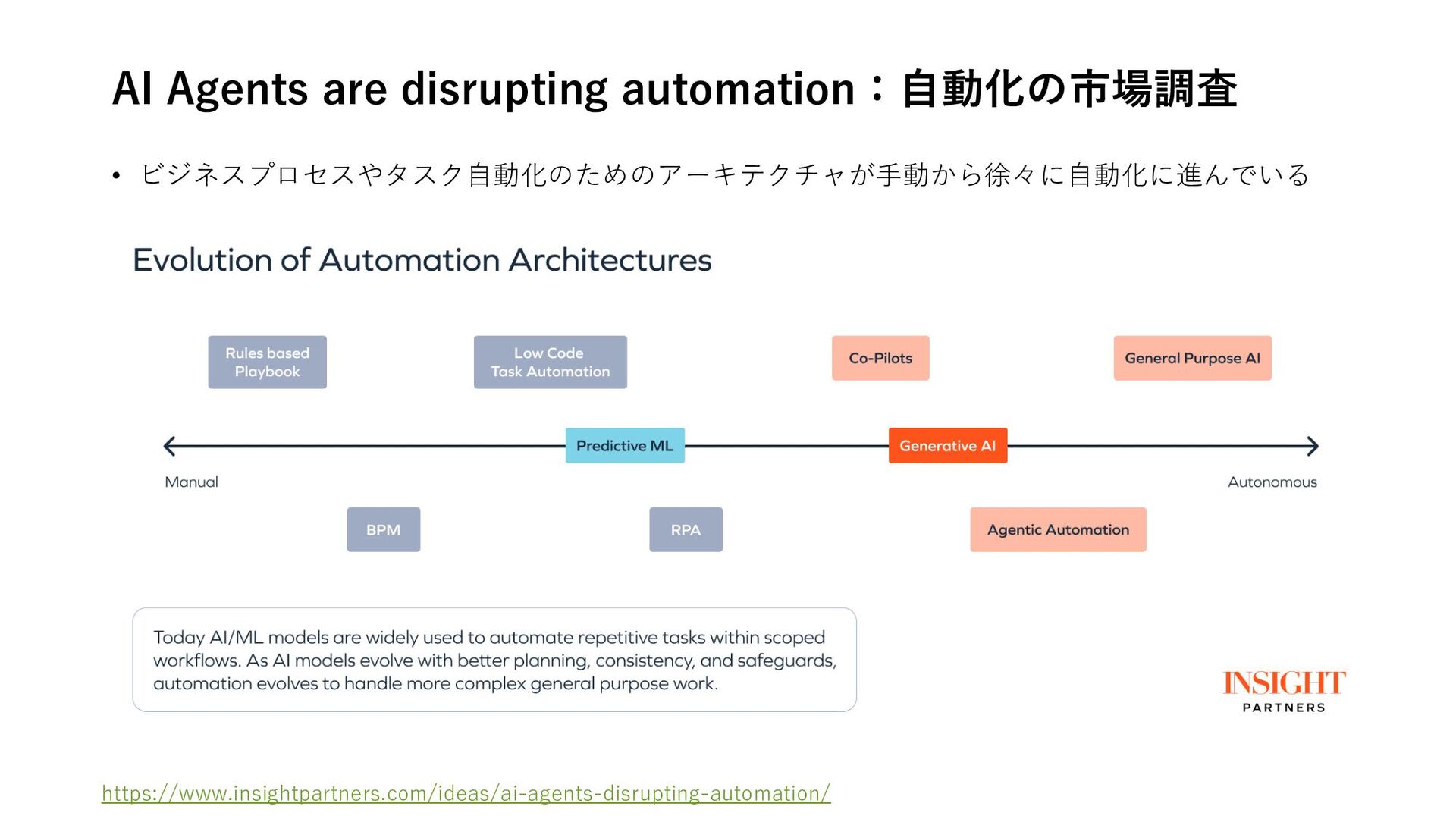{kind=link}
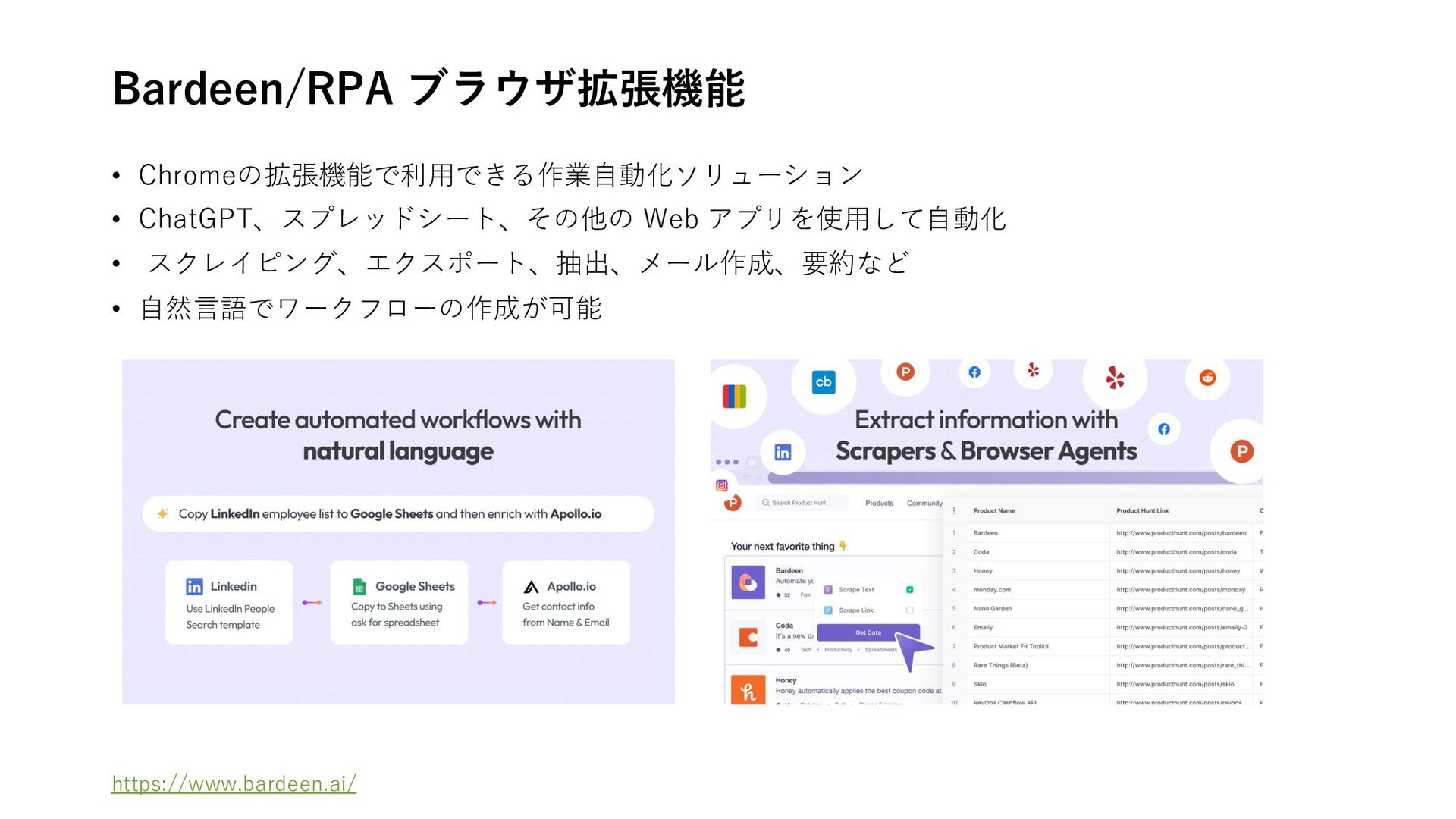{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}