Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Ad-DS Paper Circle #1
Search
Yusuke Kaneko
March 30, 2025
Research
7.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Ad-DS Paper Circle #1
広告輪読会第一回スライド
Yusuke Kaneko
March 30, 2025
More Decks by Yusuke Kaneko
See All by Yusuke Kaneko
Ad-DS Paper Circle #2
ykaneko1992
0
4.5k
Ad-DS Paper Circle #3
ykaneko1992
0
4.2k
Ad-DS Paper Circle #4
ykaneko1992
0
4.1k
Ad-DS Paper Circle #5
ykaneko1992
0
3.8k
Ad-DS Paper Circle #6
ykaneko1992
0
3.5k
Ad-DS Paper Circle #7
ykaneko1992
0
3.4k
Ad-DS Paper Circle #8
ykaneko1992
0
3.3k
Ad-DS Paper Circle #9
ykaneko1992
0
3.2k
Ad-DS Paper Circle Intro
ykaneko1992
0
7.6k
Other Decks in Research
See All in Research
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
330
AIで最適化を解けるか?
mickey_kubo
0
140
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
230
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
140
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
610
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
280
Data Visualization Tools in the Age of AI
flekschas
0
170
LLM Compute Infrastructure Overview
karakurist
2
1.5k
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
310
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
660
Cross-Media Human-Information Interaction
signer
PRO
0
120
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
Featured
See All Featured
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
How to train your dragon (web standard)
notwaldorf
97
6.7k
Marketing to machines
jonoalderson
1
5.6k
Odyssey Design
rkendrick25
PRO
2
730
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
Transcript
A Bag of Tricks for Scaling CPU-based Deep FFMs to
more than 300m Predictions per Second 〜 アドテクDS勉強会第一回 〜 AI事業本部 Dynalyst 大塚皇輝
1. 自己紹介 2. 事前知識 3. 論文紹介 a. オンライン施策 i. Deep
FFM ii. 学習高速化 b. オフライン施策 i. キャッシュ戦略 ii. 実行最適化 iii. 量子化 iv. 差分更新 4. 感想
大塚 皇輝 • Dynalyst 24 新卒 • 趣味 ◦ ツーリング(日本一周した)
◦ 散歩 • 好きな食べ物 ◦ トムヤムクン
1. 自己紹介 2. 背景 3. 論文紹介 a. オンライン施策 i. Deep
FFM ii. 学習高速化 b. オフライン施策 i. キャッシュ戦略 ii. 実行最適化 iii. 差分更新 iv. 量子化 4. 感想
背景 • 推薦や広告といった分野で Factorizatioin Machineベース 手法が未だに 一般的 ◦ 主にスケーラビリティ起因 •
GPU利用を前提としてモデル 多いが、CPU利用前提 モデル 少なく、今 回 後者にフォーカス
モチベーション 推しポイントそ 1 CPUによる深層学習モデル 実装 推しポイントそ 2 推論制約 突破 数々
手法紹介
1. 自己紹介 2. 背景 3. 論文紹介 a. オンライン施策 i. Deep
FFM ii. 学習高速化 b. オフライン施策 i. キャッシュ戦略 ii. 実行最適化 iii. 差分更新 iv. 量子化 4. 感想
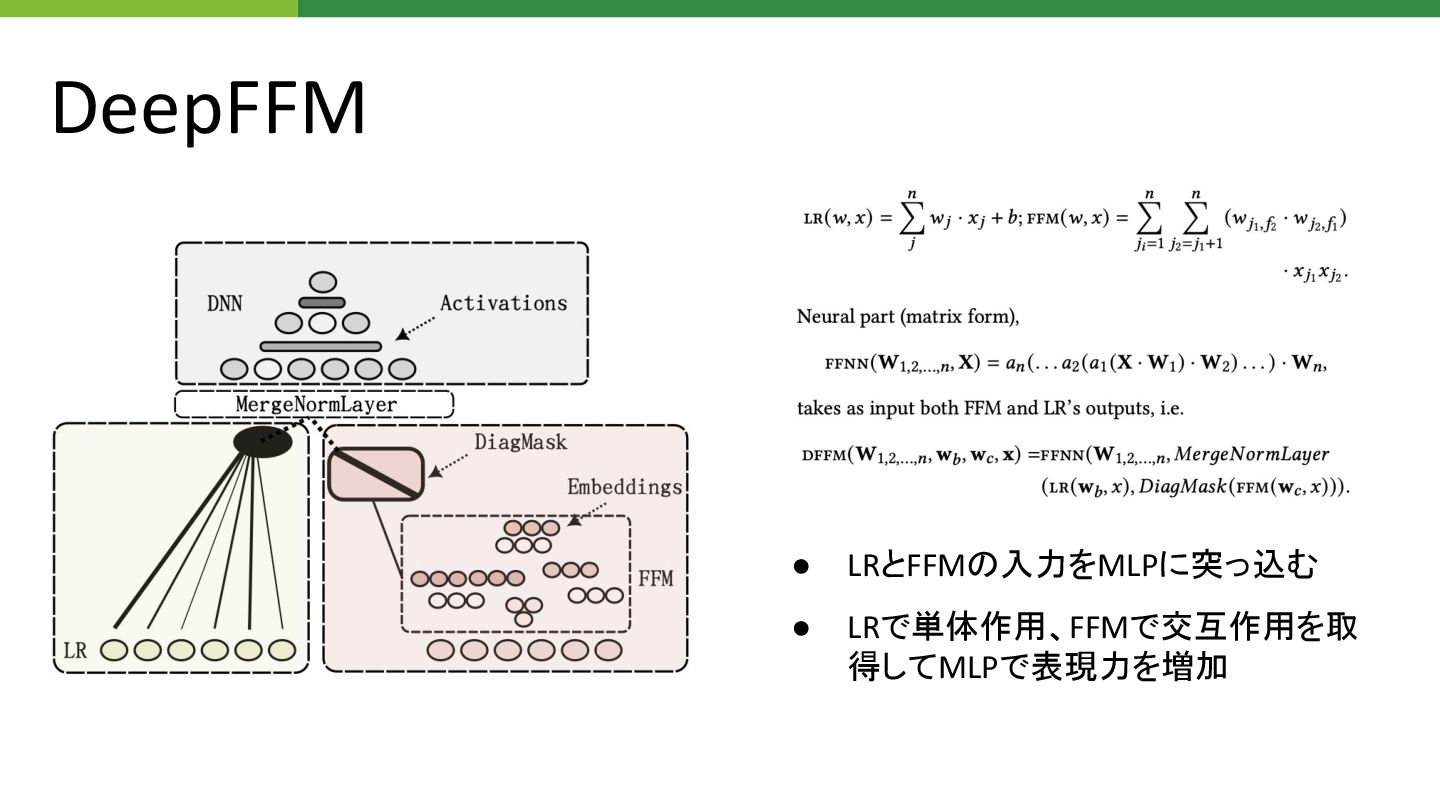
FFM (Field-aware Factorization Machine) • 特徴量 潜在ベクトル同士 組み合わせを用いる事で計算量を削減 • 交互作用を考慮するため2つ
特徴量 組み合わせごと 重みを使用
DeepFFM • LRとFFM 入力をMLPに突っ込む • LRで単体作用、FFMで交互作用を取 得してMLPで表現力を増加
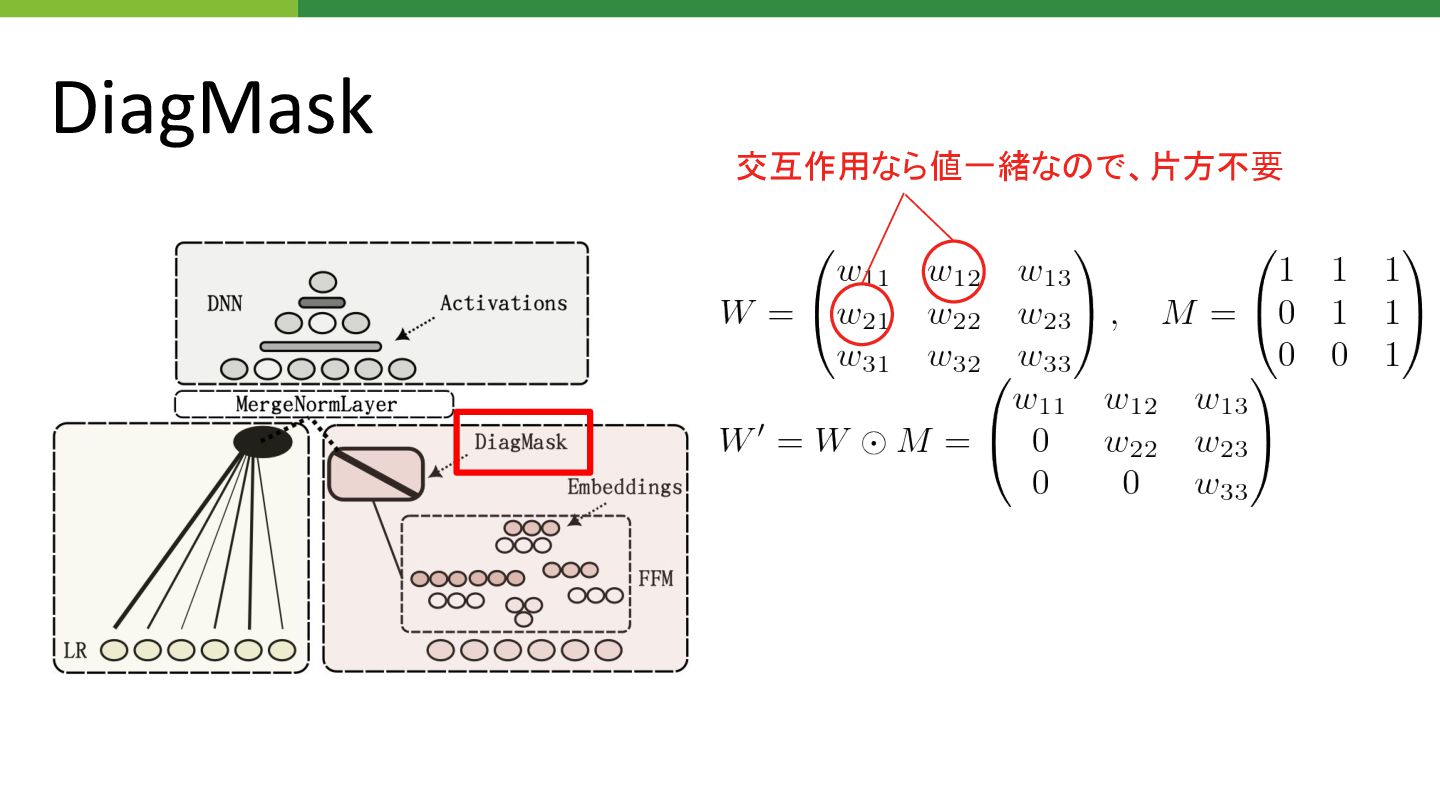
DiagMask 交互作用なら値一緒な で、片方不要
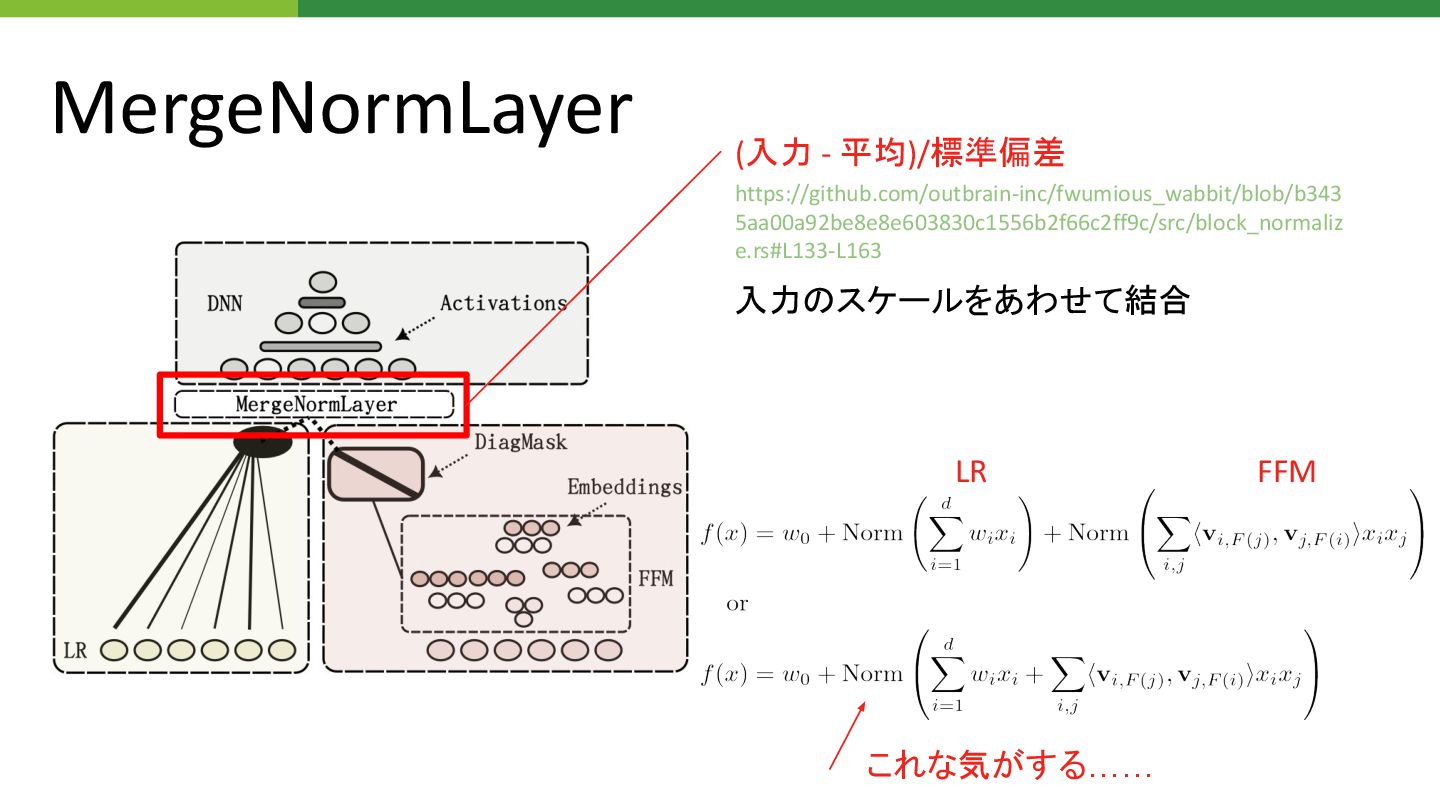
MergeNormLayer (入力 - 平均)/標準偏差 https://github.com/outbrain-inc/fwumious_wabbit/blob/b343 5aa00a92be8e8e603830c1556b2f66c2ff9c/src/block_normaliz e.rs#L133-L163 LR FFM これな気がする……
入力 スケールをあわせて結合
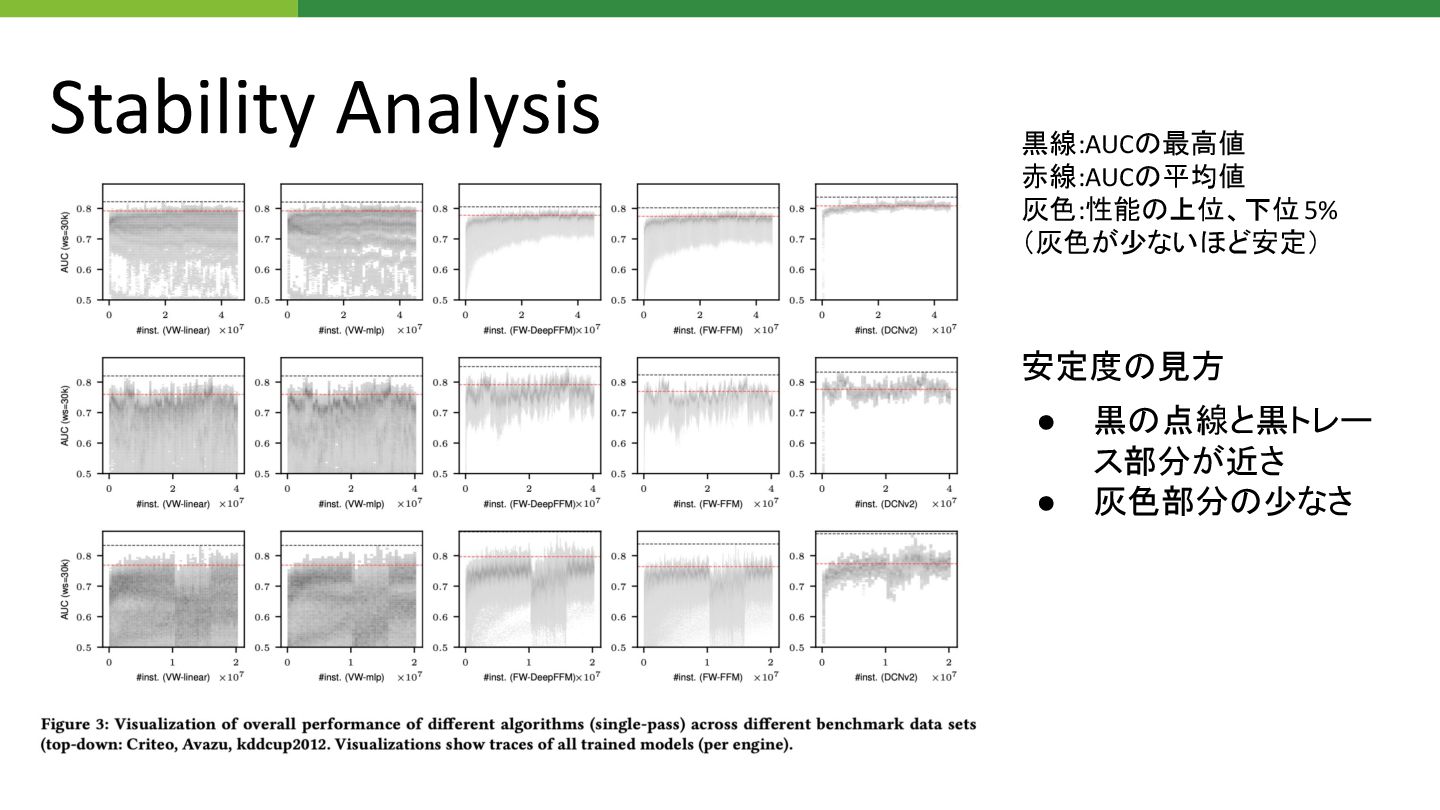
Stability Analysis • タスク設定 CTR予測 • 評価指標 AUC • 期間ごとに異なるハイパラで実験
期間A 期間B パフォーマンスがど 期間でも 安定すること確認する実験 …… 設定A 設定B : 設定A 設定B :
Stability Analysis 黒線:AUC 最高値 赤線:AUC 平均値 灰色:性能 上位、下位5% (灰色が少ないほど安定) •
黒 点線と黒トレー ス部分が近さ • 灰色部分 少なさ 安定度 見方
1. 自己紹介 2. 背景 3. 論文紹介 a. オンライン施策 i. Deep
FFM ii. 学習高速化 b. オフライン施策 i. キャッシュ戦略 ii. 実行最適化 iii. 差分更新 iv. 量子化 4. 感想
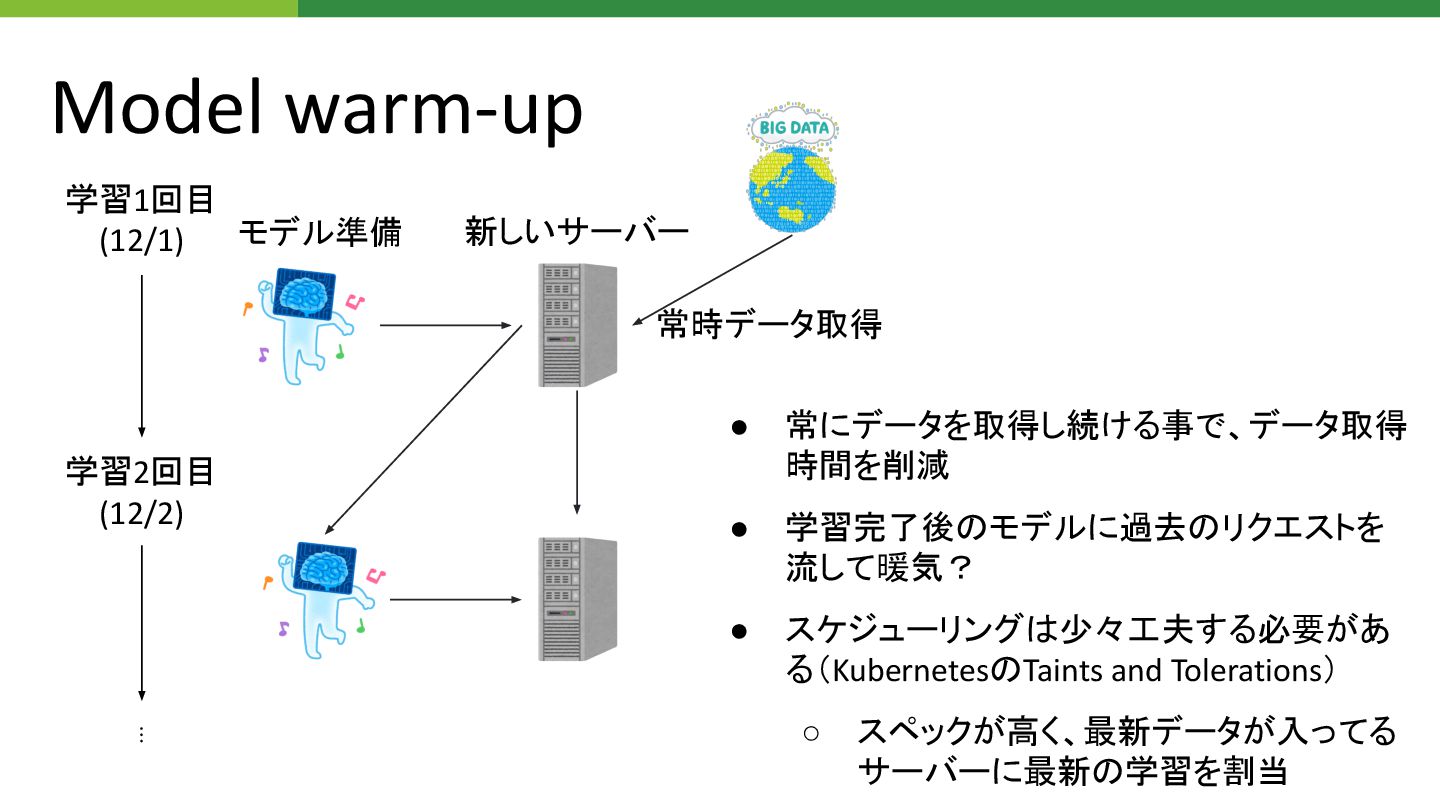
Model warm-up
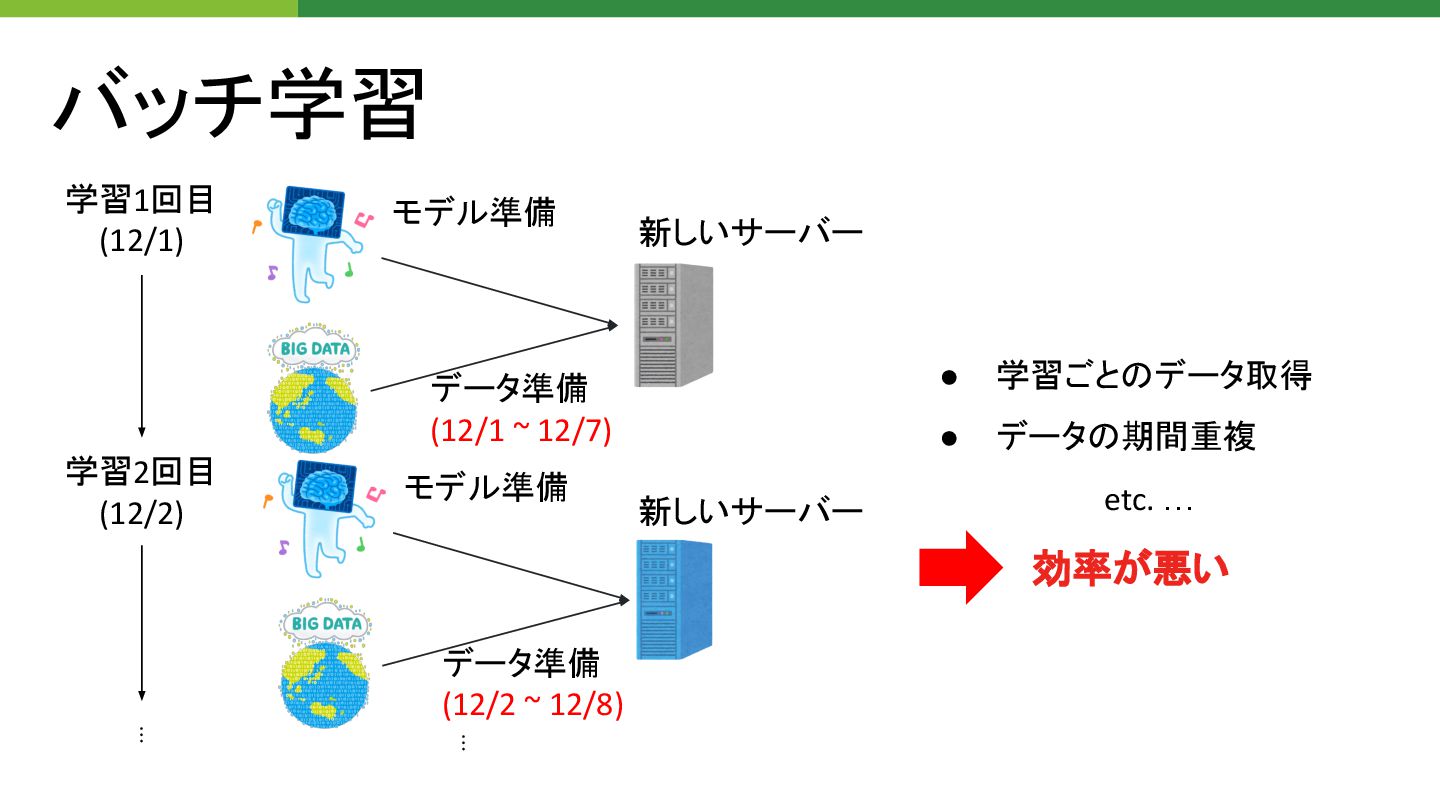
バッチ学習 学習1回目 (12/1) 学習2回目 (12/2) モデル準備 データ準備 (12/1 ~ 12/7)
モデル準備 データ準備 (12/2 ~ 12/8) ⋮ ⋮ 新しいサーバー 新しいサーバー • 学習ごと データ取得 • データ 期間重複 etc. … 効率が悪い
Model warm-up モデル準備 新しいサーバー 常時データ取得 • 常にデータを取得し続ける事で、データ取得 時間を削減 • 学習完了後
モデルに過去 リクエストを 流して暖気? • スケジューリング 少々工夫する必要があ る(Kubernetes Taints and Tolerations) ◦ スペックが高く、最新データが入ってる サーバーに最新 学習を割当 学習1回目 (12/1) 学習2回目 (12/2) ⋮
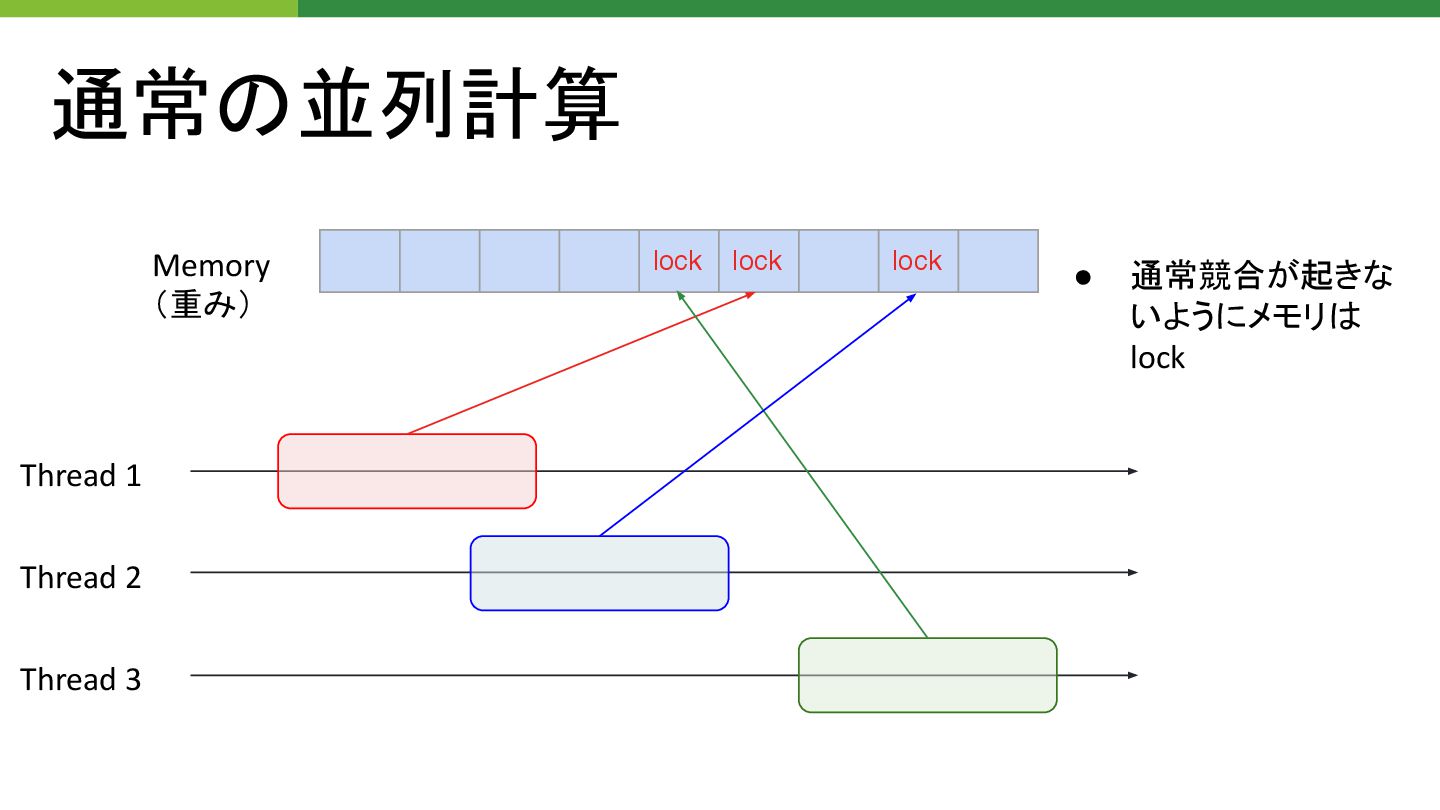
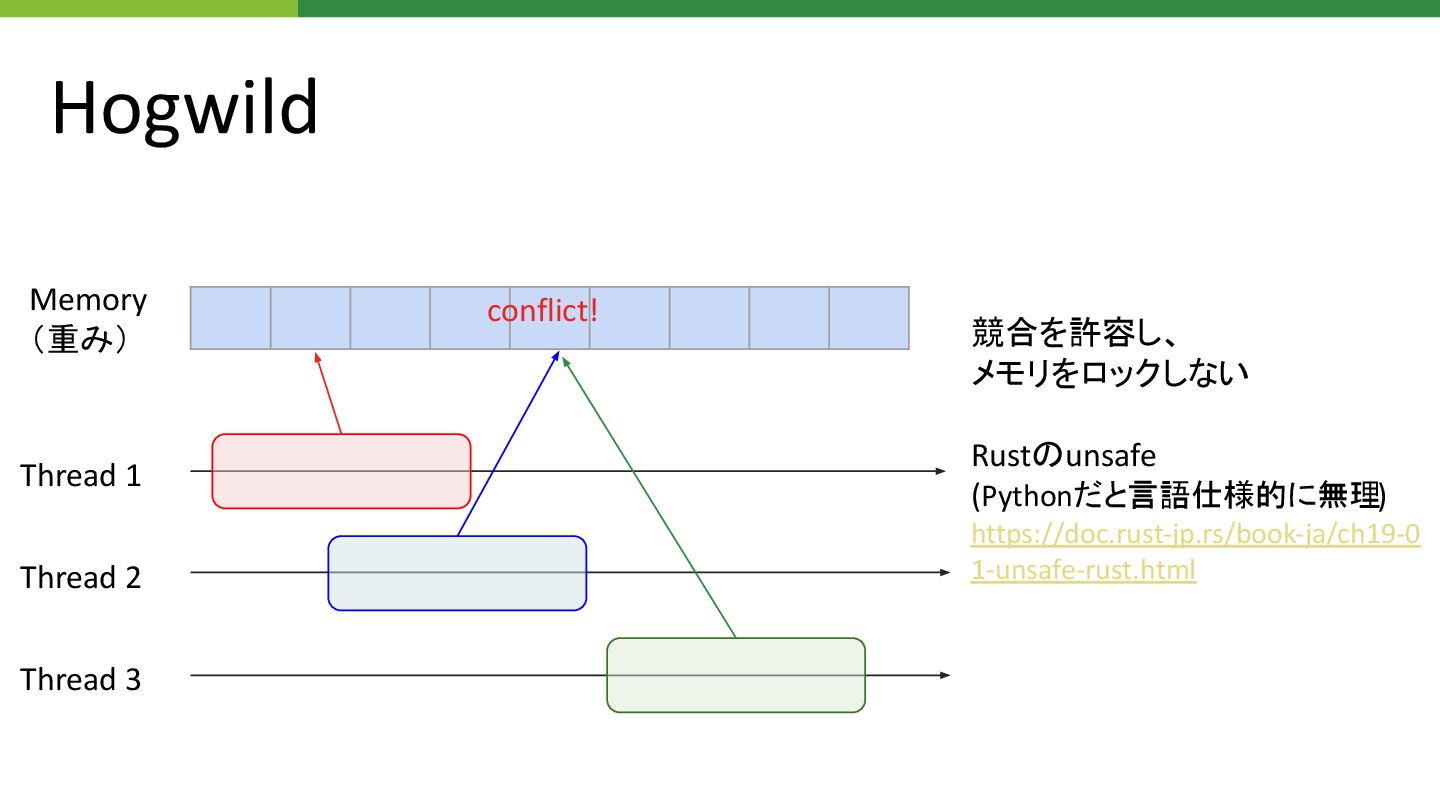
Hogwild
通常 並列計算 lock lock lock Memory (重み) Thread 1 Thread
2 Thread 3 • 通常競合が起きな いようにメモリ lock
Hogwild Memory (重み) Thread 1 Thread 2 Thread 3 競合を許容し、
メモリをロックしない Rust unsafe (Pythonだと言語仕様的に無理) https://doc.rust-jp.rs/book-ja/ch19-0 1-unsafe-rust.html conflict!
Hogwild • 単純に並列化してる分早い • メモリロック等 オーバーヘッドが無い で早い • 性能(Revenue Per
Mille)に関して 、ABテスト実施した結果著しい低下 ない ※RPM (Revenue Per Mille) : 1000 Impressionあたり 収益
Sparse weight update
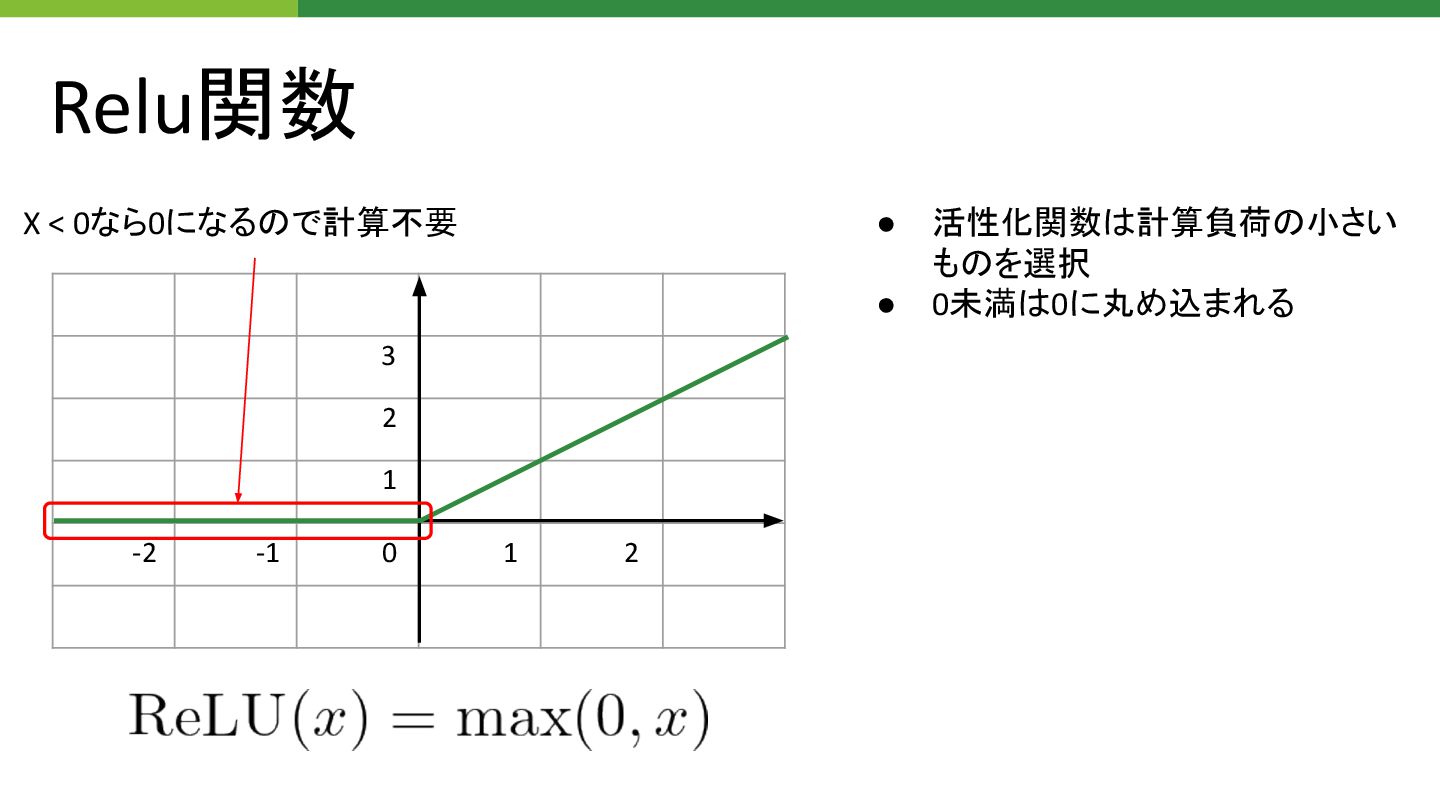
Relu関数 0 1 2 -1 -2 1 2 3 X
< 0なら0になる で計算不要 • 活性化関数 計算負荷 小さい も を選択 • 0未満 0に丸め込まれる
Sparse weight update … X ・W 活性化関数 … … 0
ReLU: 0 if x < 0 ReLU関数によって0未満 入力 0になる で、 予め0未満 入力となってるノードから分岐している重 み 計算不要
1. 自己紹介 2. 背景 3. 論文紹介 a. オンライン施策 i. Deep
FFM ii. 学習高速化 b. オフライン施策 i. キャッシュ戦略 ii. 実行最適化 iii. 差分更新 iv. 量子化 4. 感想
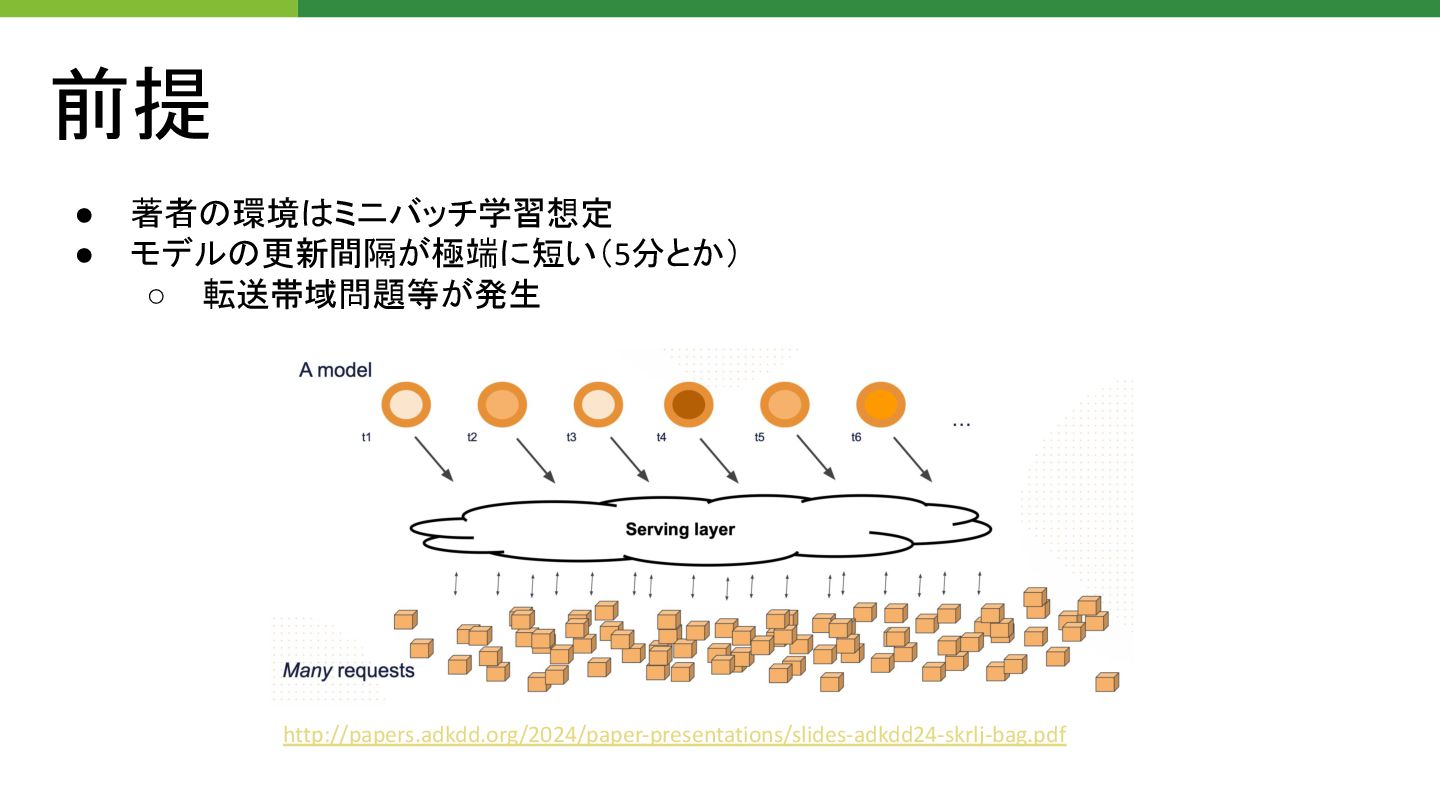
前提 • 著者 環境 ミニバッチ学習想定 • モデル 更新間隔が極端に短い(5分とか) ◦ 転送帯域問題等が発生
http://papers.adkdd.org/2024/paper-presentations/slides-adkdd24-skrlj-bag.pdf
キャッシュ戦略
Context cache • Requestからくる内容 うち、不変なも をキャッシュ ◦ ユーザー情報、ブラウザ情報等 • 恐らくfield情報
潜在ベクトルをキャッシュしておき、ユーザー情報分 計算が不 要になる? predict_with_cache関数 https://github.com/outbrain-inc/fwumious_wabbit/blob/b3435aa00a92be8e8e603830c1556b2f66c2ff9c/src/lib.rs#L110 Fields キャッシュ https://github.com/outbrain-inc/fwumious_wabbit/blob/b3435aa00a92be8e8e603830c1556b2f66c2ff9c/src/block_ffm.rs#L475
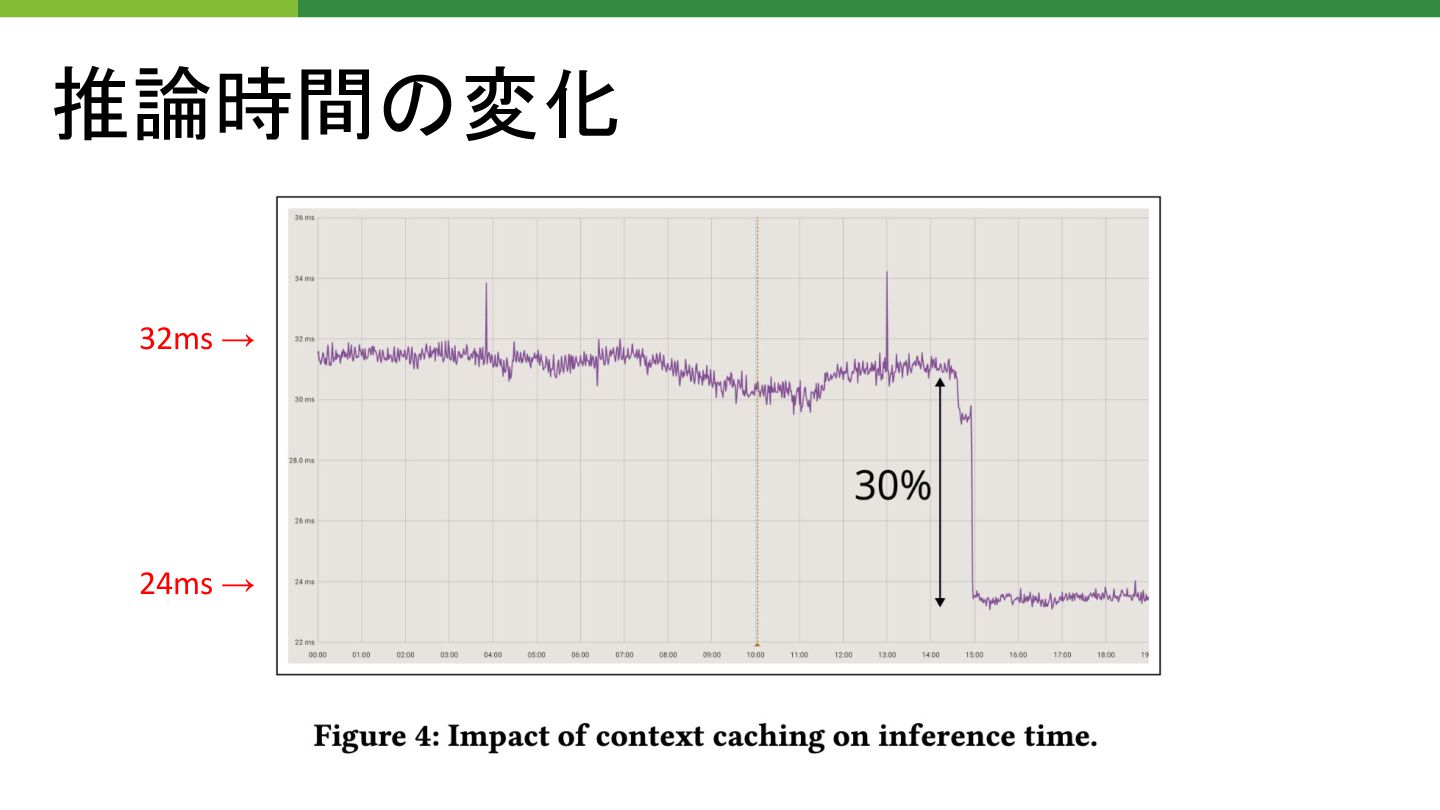
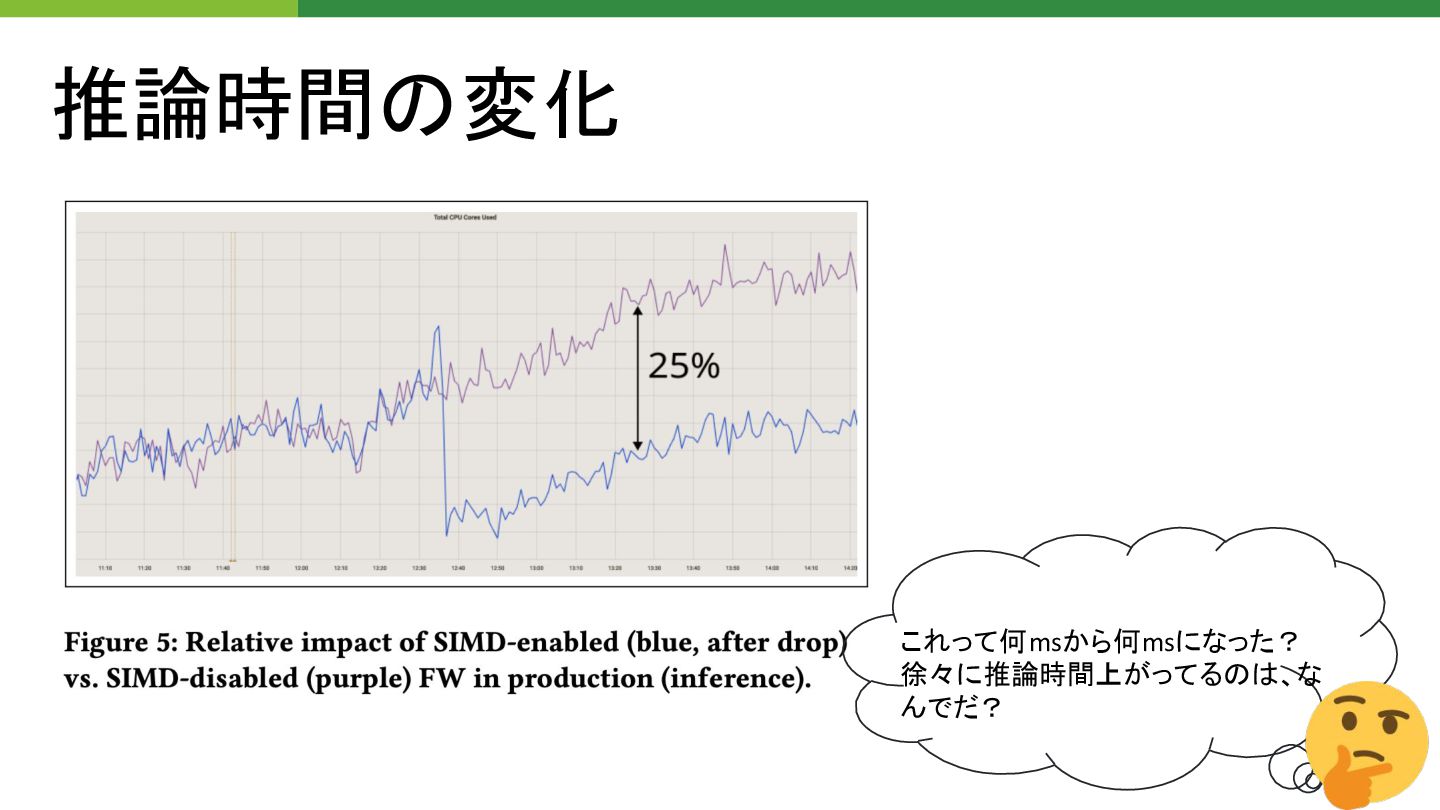
推論時間 変化 32ms → 24ms →
実行最適化
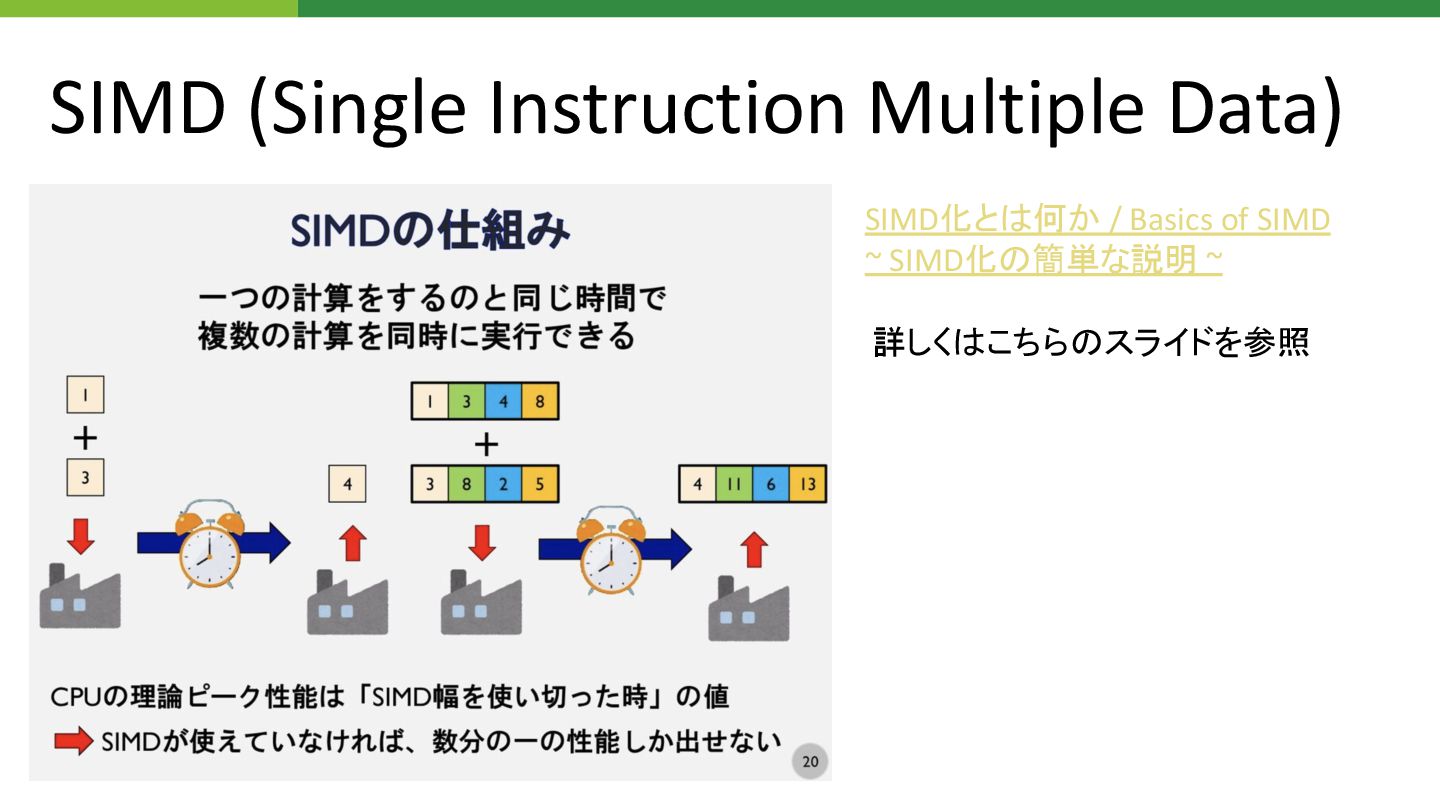
SIMD (Single Instruction Multiple Data) • 単一 命令で複数 データを一括処理できるコンパイラ 機能
• 低レベル言語(Rust, C++とか)だと実行できるがPythonだとできない • Rust 場合 ビルド時 feature flagによって使用有無を決定 • CPU バージョンによって演算器 設定が異なる で、設定時 要注意 ↓実行時引数 SIMD設定 https://github.com/outbrain-inc/fwumious_wabbit/blob /b3435aa00a92be8e8e603830c1556b2f66c2ff9c/buil d.sh#L13 個別 関数に み設定する場合 デコレータ的なも で設定すると for文がSIMDで実行される→
SIMD (Single Instruction Multiple Data) SIMD化と 何か / Basics of
SIMD ~ SIMD化 簡単な説明 ~ 詳しく こちら スライドを参照
推論時間 変化 これって何msから何msになった? 徐々に推論時間上がってる 、な んでだ?
差分更新
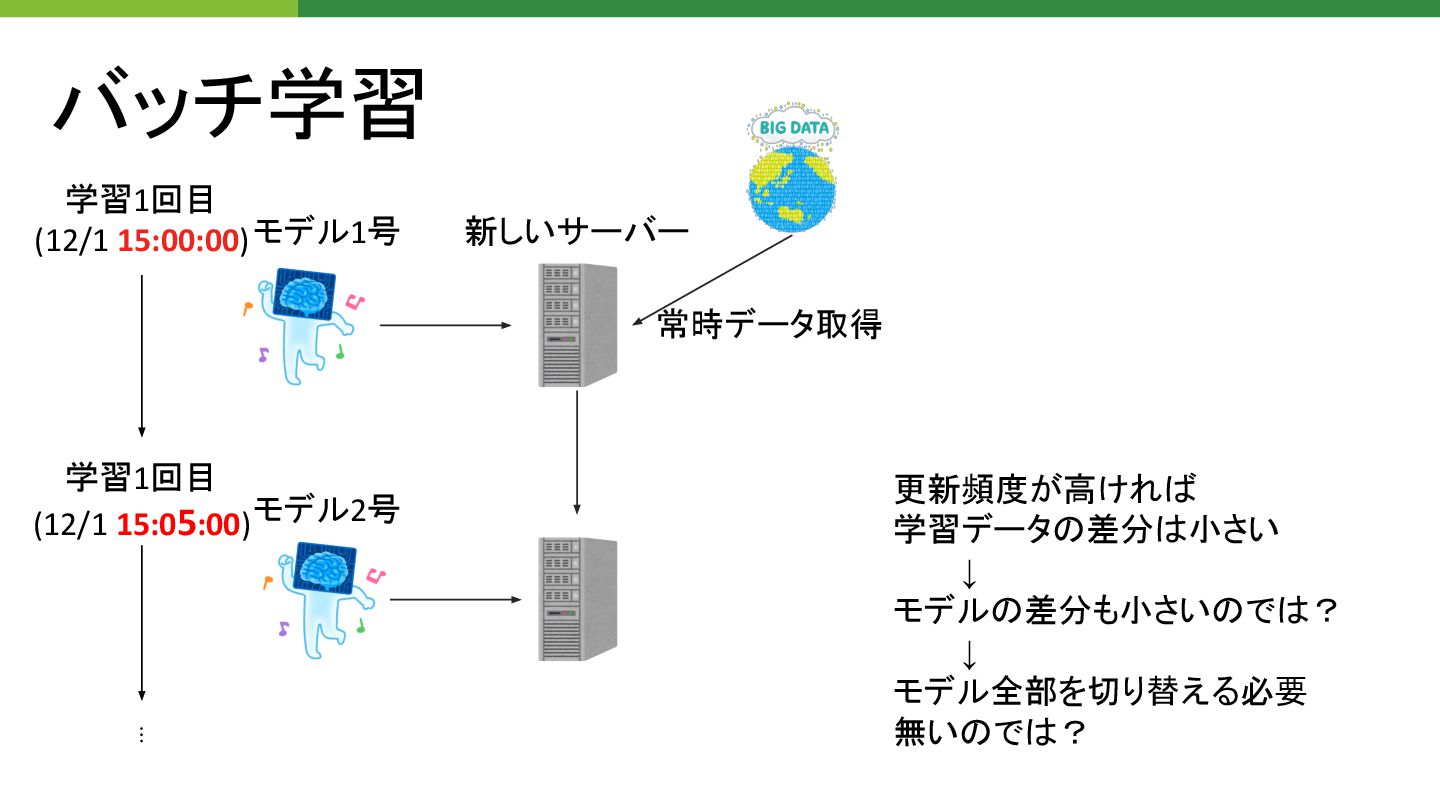
バッチ学習 新しいサーバー 常時データ取得 学習1回目 (12/1 15:00:00) ⋮ 学習1回目 (12/1 15:05:00)
モデル1号 モデル2号 更新頻度が高けれ 学習データ 差分 小さい ↓ モデル 差分も小さい で ? ↓ モデル全部を切り替える必要 無い で ?
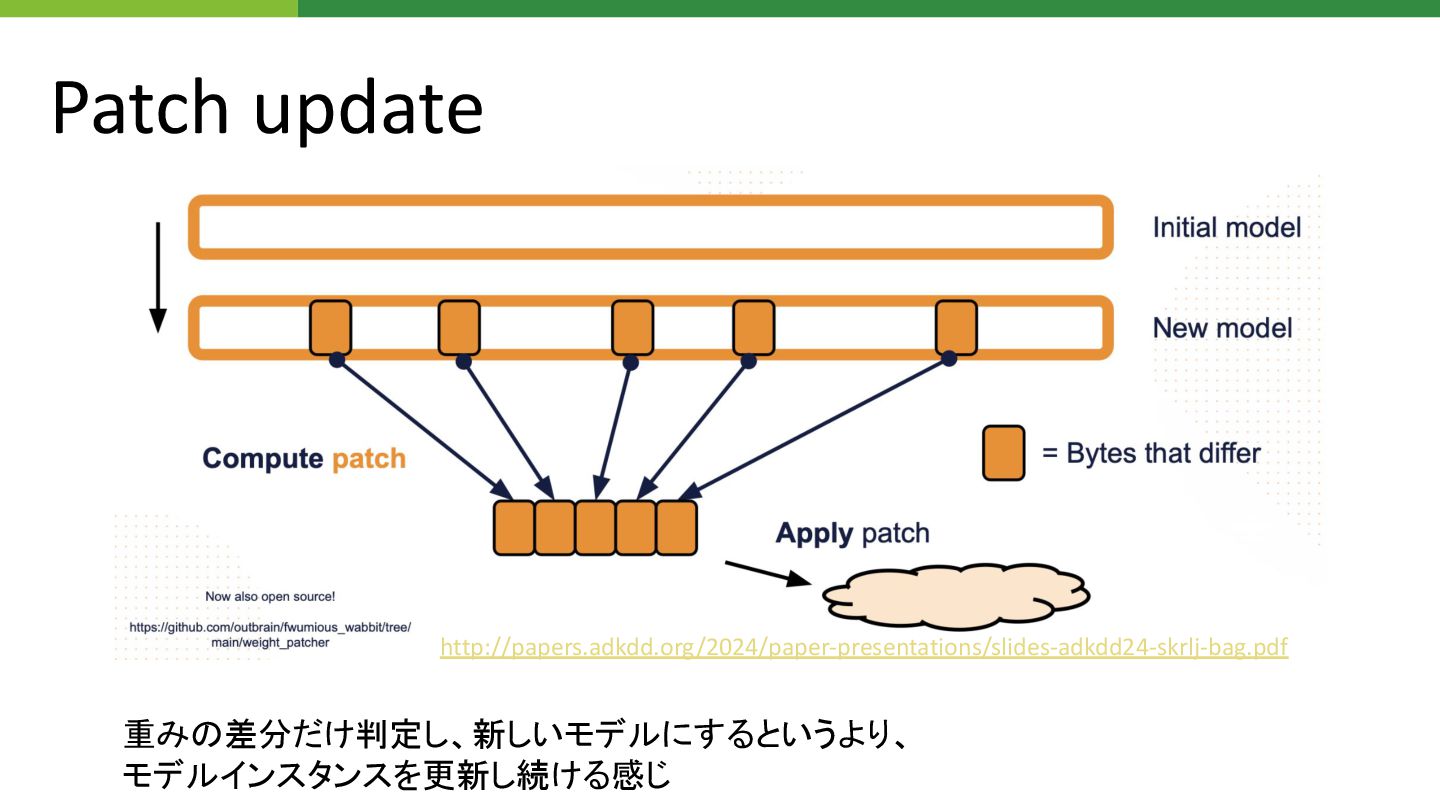
Patch update http://papers.adkdd.org/2024/paper-presentations/slides-adkdd24-skrlj-bag.pdf 重み 差分だけ判定し、新しいモデルにするというより、 モデルインスタンスを更新し続ける感じ
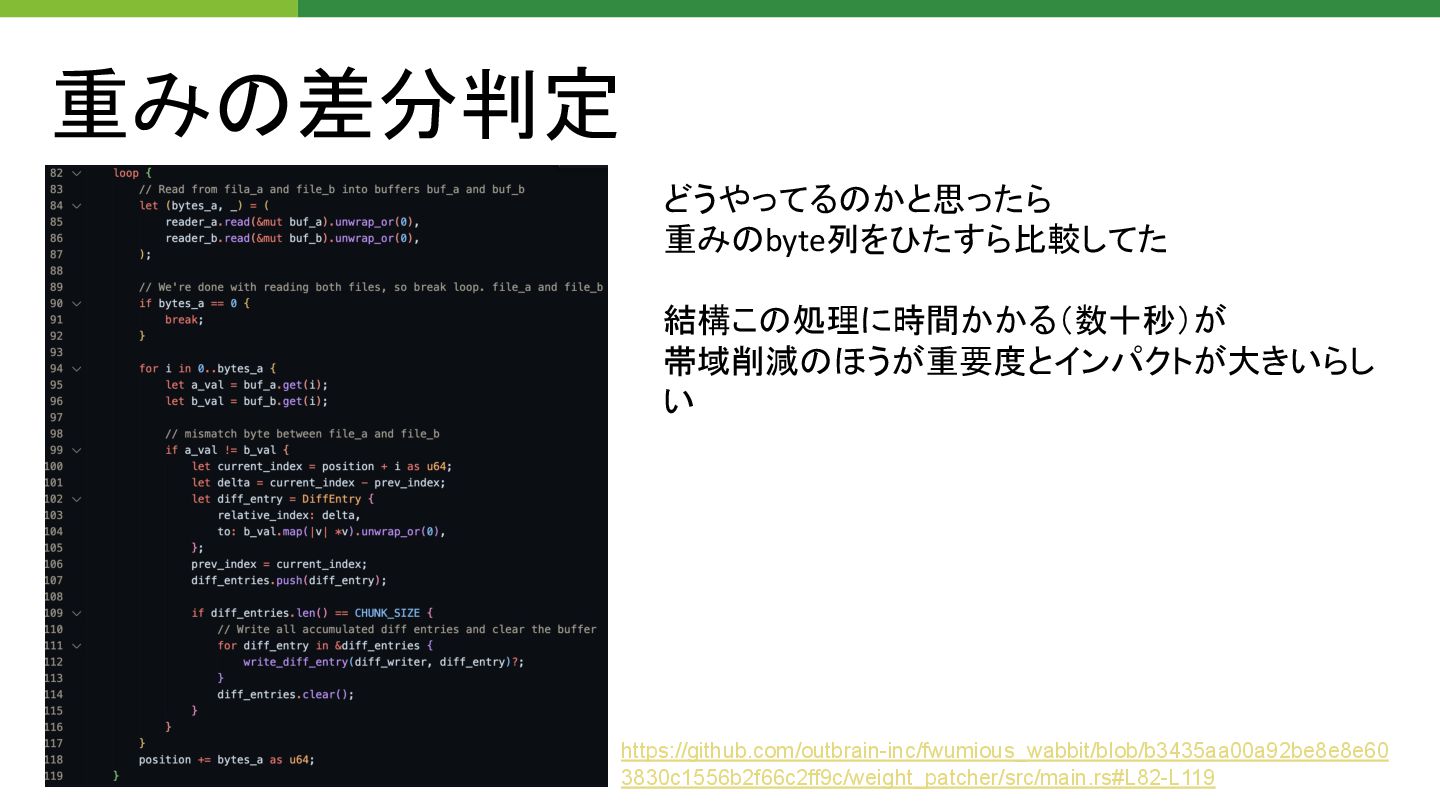
重み 差分判定 どうやってる かと思ったら 重み byte列をひたすら比較してた 結構こ 処理に時間かかる(数十秒)が 帯域削減 ほうが重要度とインパクトが大きいらし
い https://github.com/outbrain-inc/fwumious_wabbit/blob/b3435aa00a92be8e8e60 3830c1556b2f66c2ff9c/weight_patcher/src/main.rs#L82-L119
量子化
Quantization 1(整数) 符号付き32bit 0|0000001 0|0000000 00000000 00000000 00000001 符号付き8bit •
重み メモリ使用量を削減できる • 8bitまでならそこまで性能低下しないらしい • 考慮事項 ◦ 量子化と逆量子化 高速 ◦ 丸め込み 幅を動的に決定 ▪ 時系列的なデータ量 変化に起因 3時 ~ 5時 データ量少ない→重み 更新幅も小さい 19時 ~ 21時 データ量多い→重み 更新幅も大きい
バケット割当 量子化を行う場合、重みをいくつか バケットに割り当てて丸め込む : バケットサイズ、各バケット 幅 : 可能なバケット数 最大数 各重みを上記
式にそって量子化を行う
具体例 こ 場合各バケット 0: 1.2 ~ 3.4 1: 3.4 ~
5.6 2: 5.6 ~ 7.8 3: 7.8 ~ 10.0 となる 例え 3.8 バケット1に割り当て ≒3.8 量子化されると1 複合する場合
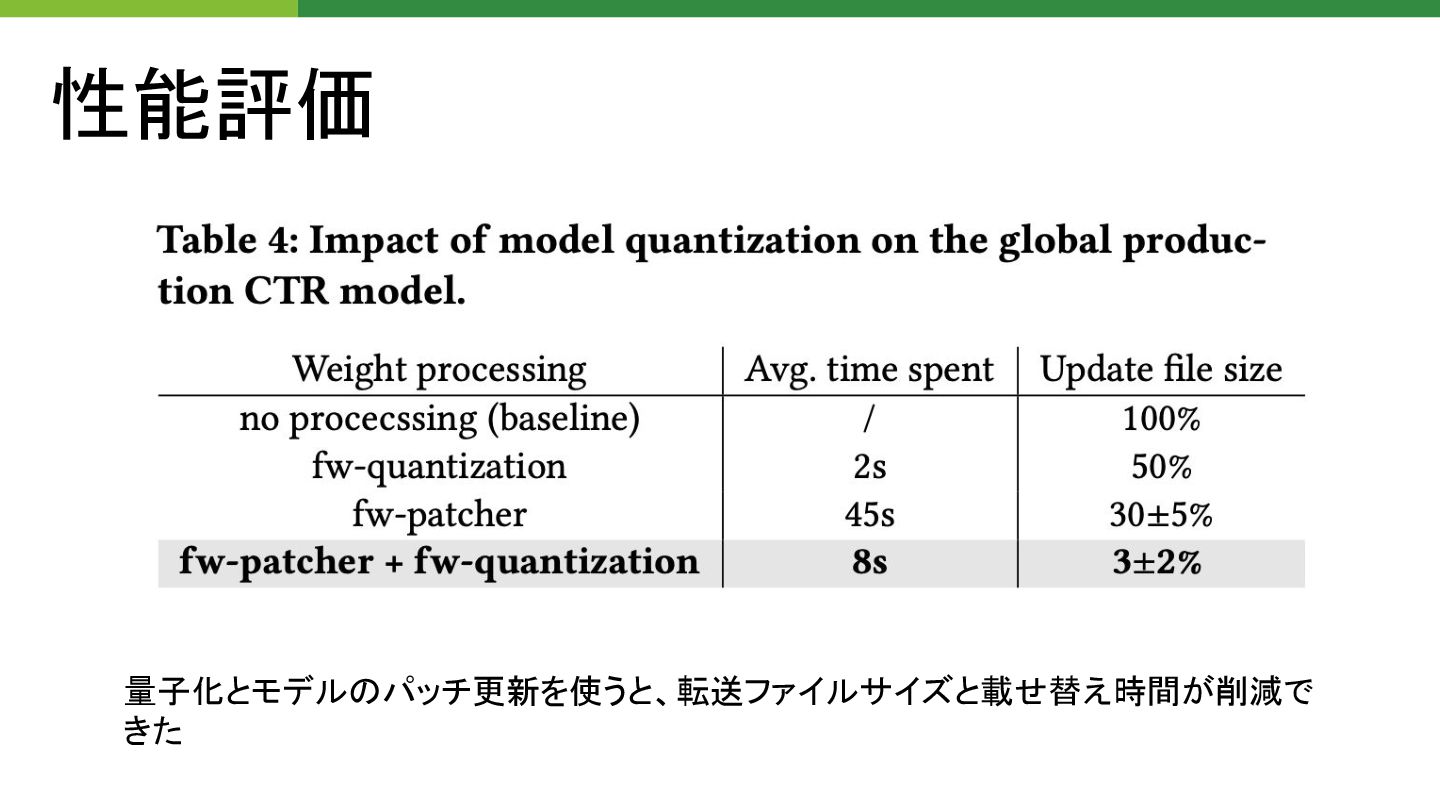
性能評価 量子化とモデル パッチ更新を使うと、転送ファイルサイズと載せ替え時間が削減で きた
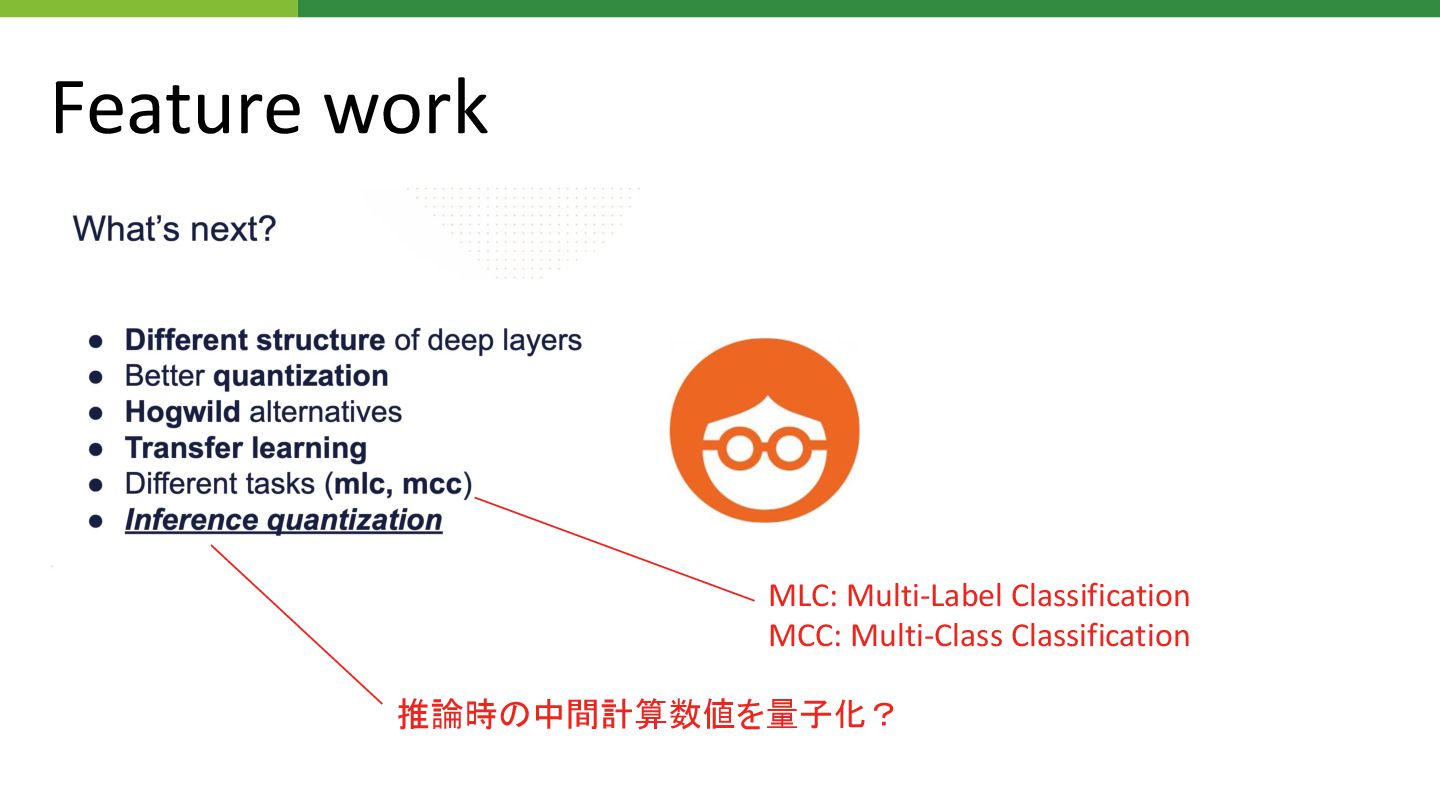
Feature work + 自分 所感
Feature work MLC: Multi-Label Classification MCC: Multi-Class Classification 推論時 中間計算数値を量子化?
自分 所感 • アイデア 論文内で理解できなく ないが、「どうやる ?」に関して 実装見ないとわか らない •
運用に乗せる 難しそう ◦ 事故った時 切り戻しとか ◦ 原因となったモデルとか
Appendix
AdKDD と • KDD(Knowledge Discovery and Data Mining) Workshop 一つ
• あんまりLLMに侵食されてなさそう? • TODO: 情報書き足し(社内ブログとか)
著者情報 • Outbrain ML researcher • NLP専門っぽい? • Auto ML
に興味があるっぽい ネイティブアド パイオニア (これど サービス?)
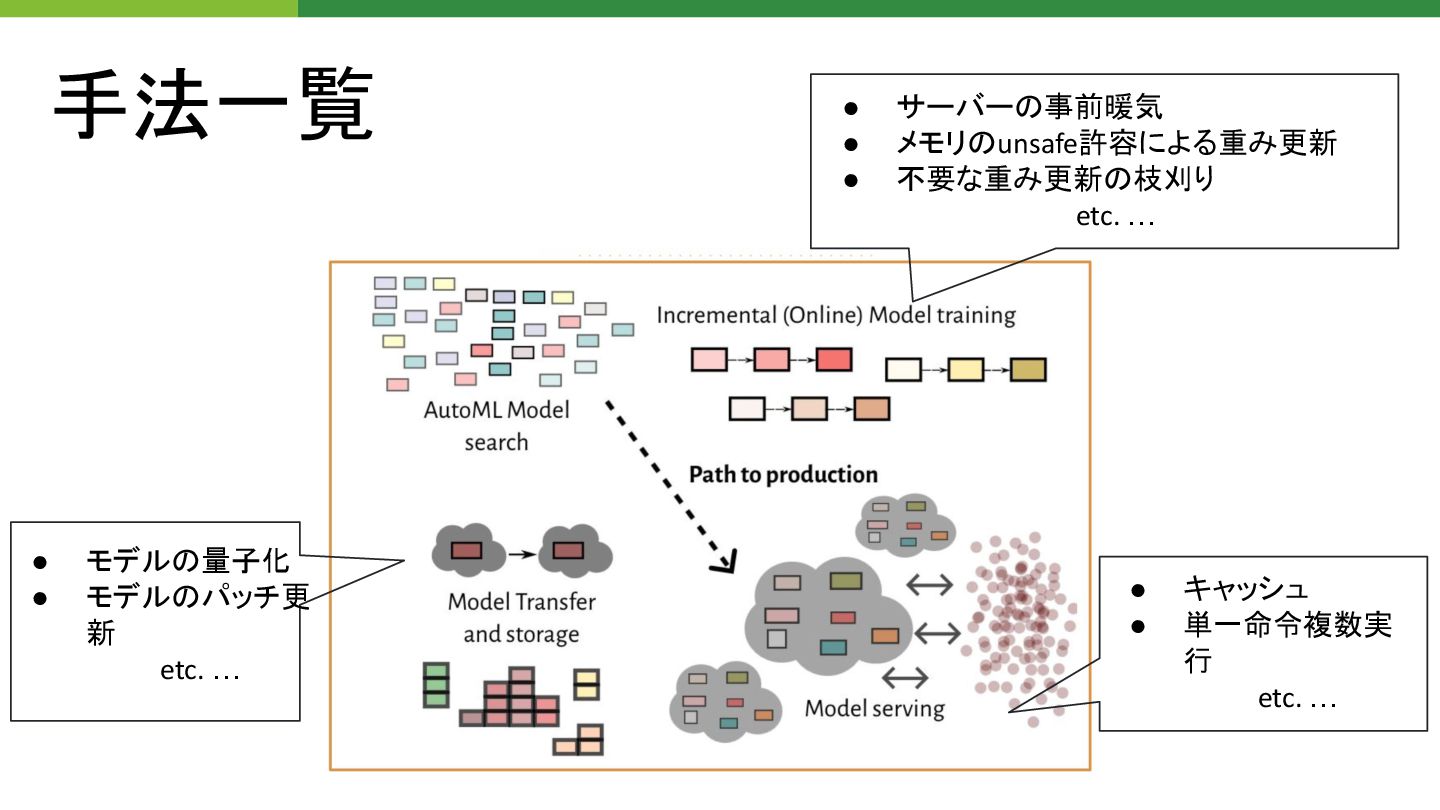
手法一覧 • モデル 量子化 • モデル パッチ更 新 etc. …
• サーバー 事前暖気 • メモリ unsafe許容による重み更新 • 不要な重み更新 枝刈り etc. … • キャッシュ • 単一命令複数実 行 etc. …
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}