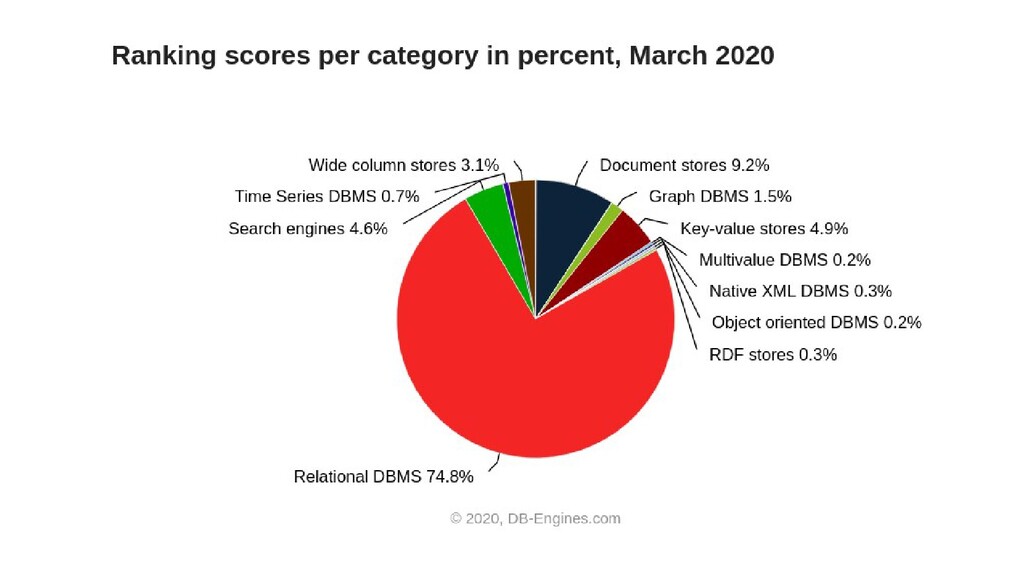
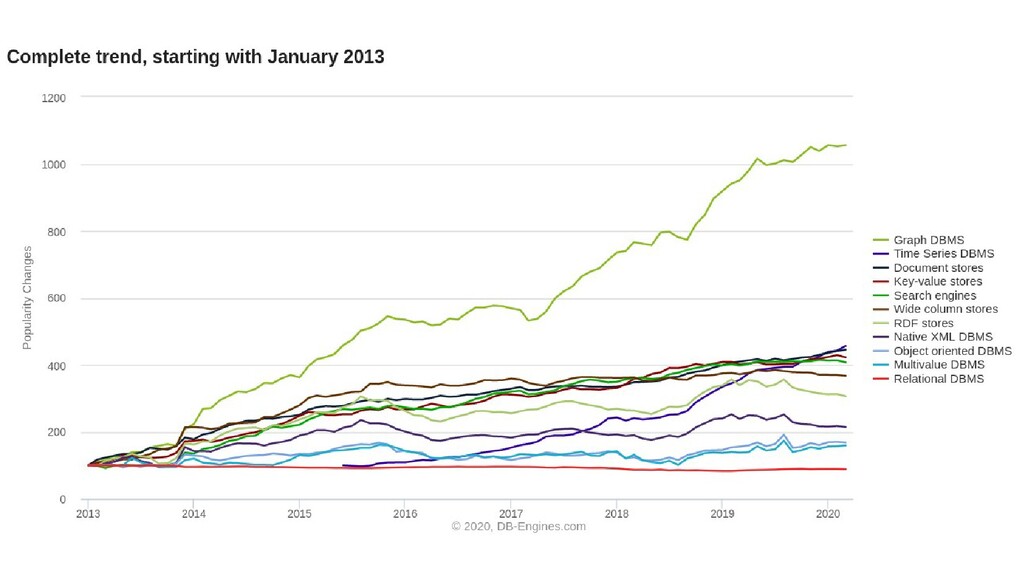
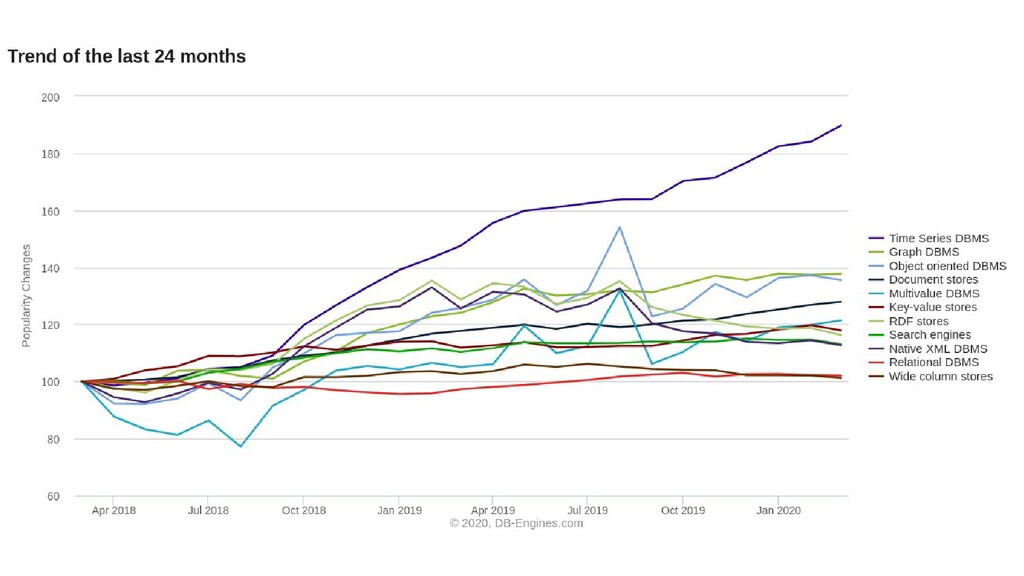
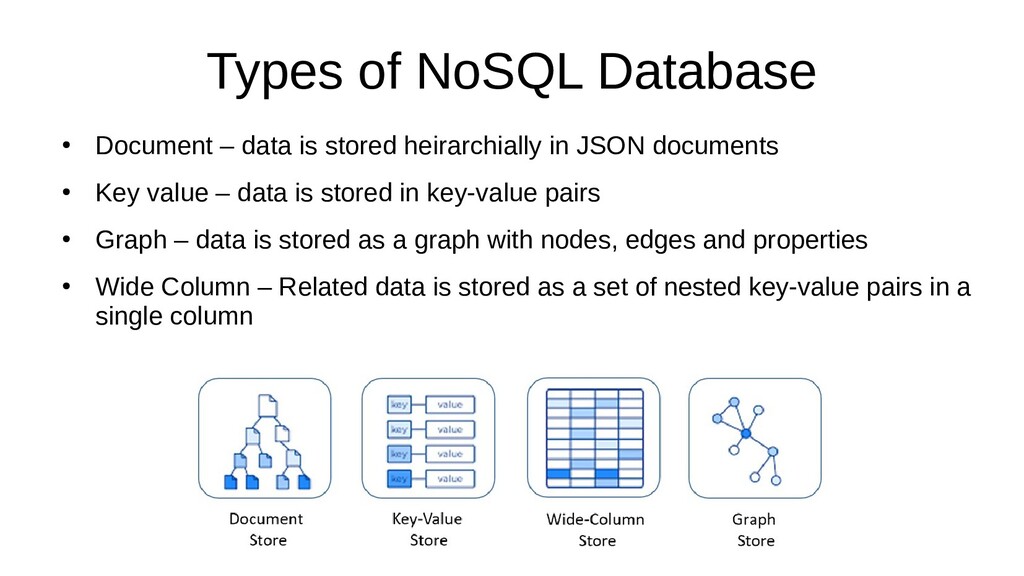
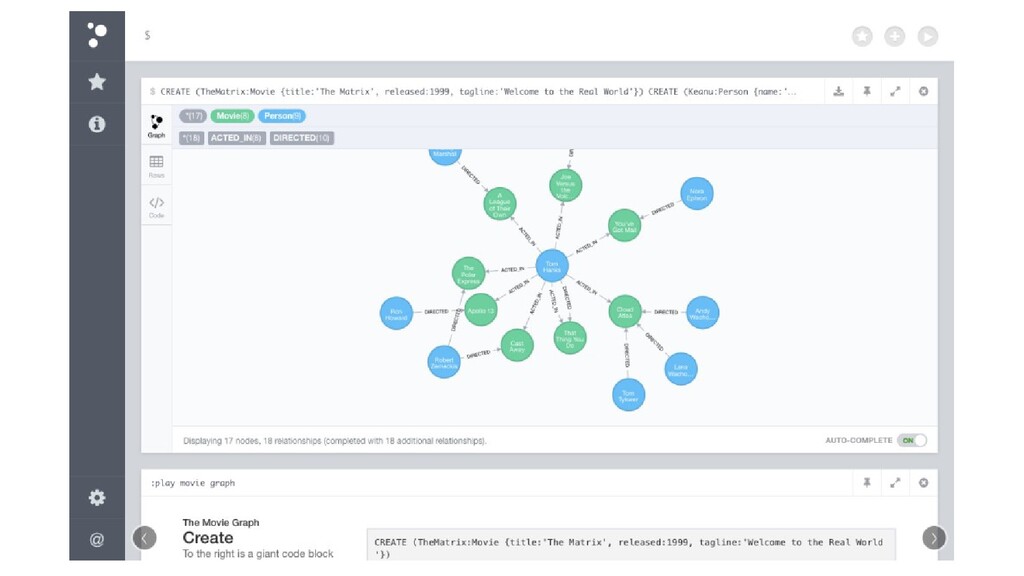
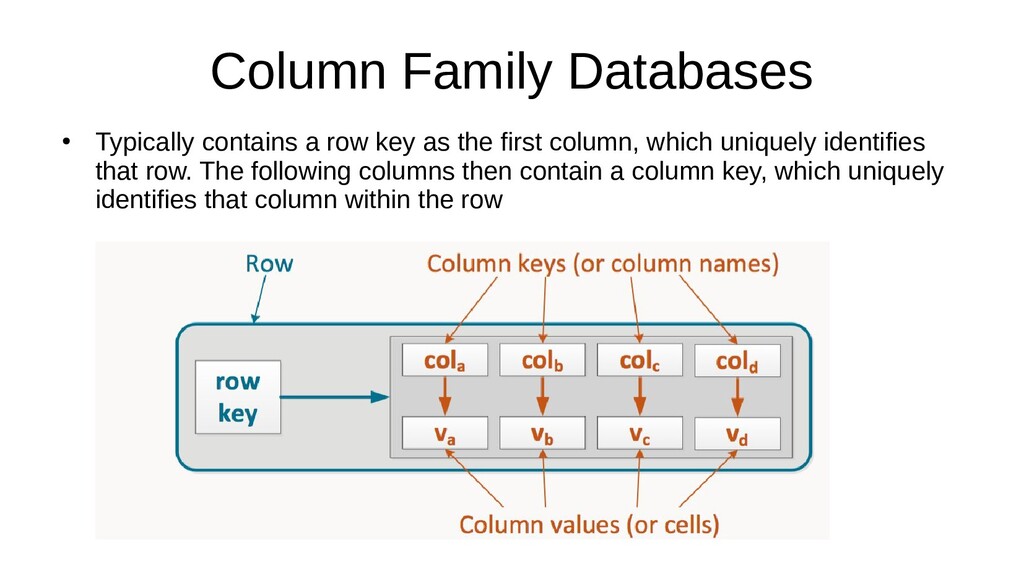
Often Developers will go with a commonly used relational database as it's what they're already comfortable with, however a relational database can often not be the best tool for the job. Learn instead how to choose the best database type for your project's requirements. Candidates for discussion will be Relational, NoSQL, Graph and Time Series databases.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}