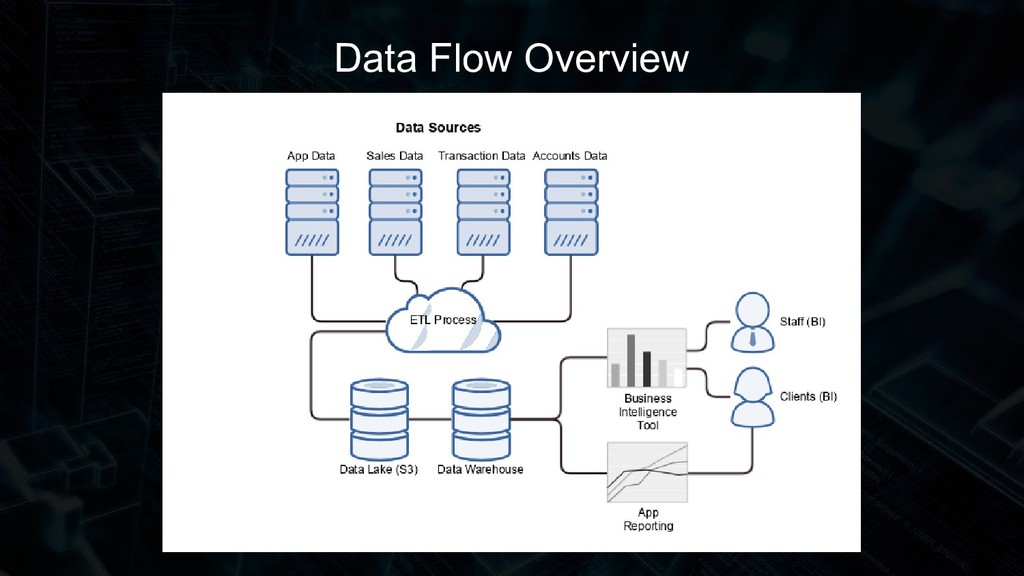
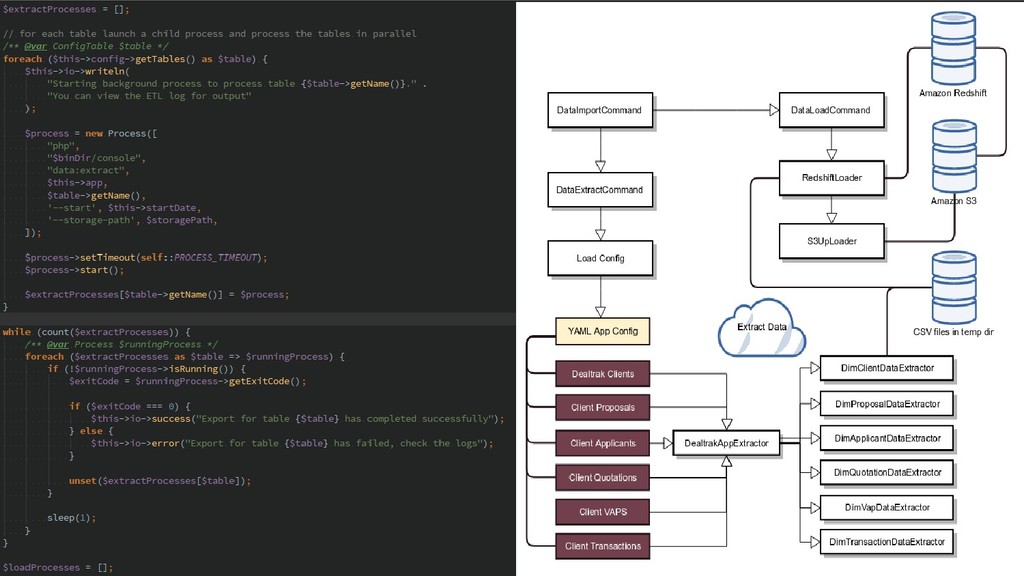
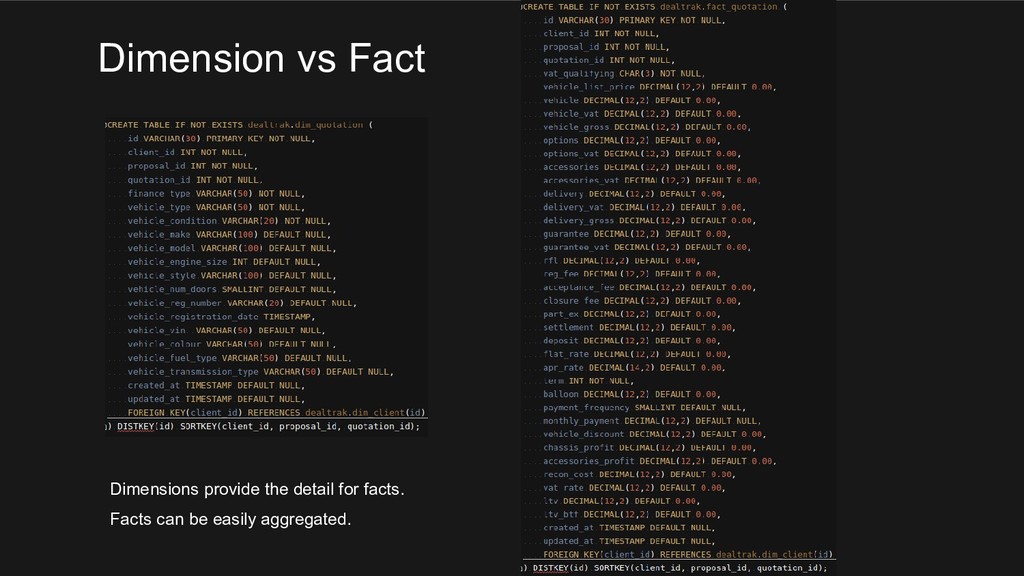
Learn the advantages of having a Data Warehouse, what the hell a star schema is, and how we designed and built our solution with a custom PHP7 & Symfony 4 powered ETL (Extract Transform Load) process leveraging parallel processing. Our solution at DealTrak runs on the highly scaleable Amazon Redshift in our production environment and uses Postgres for development and testing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}