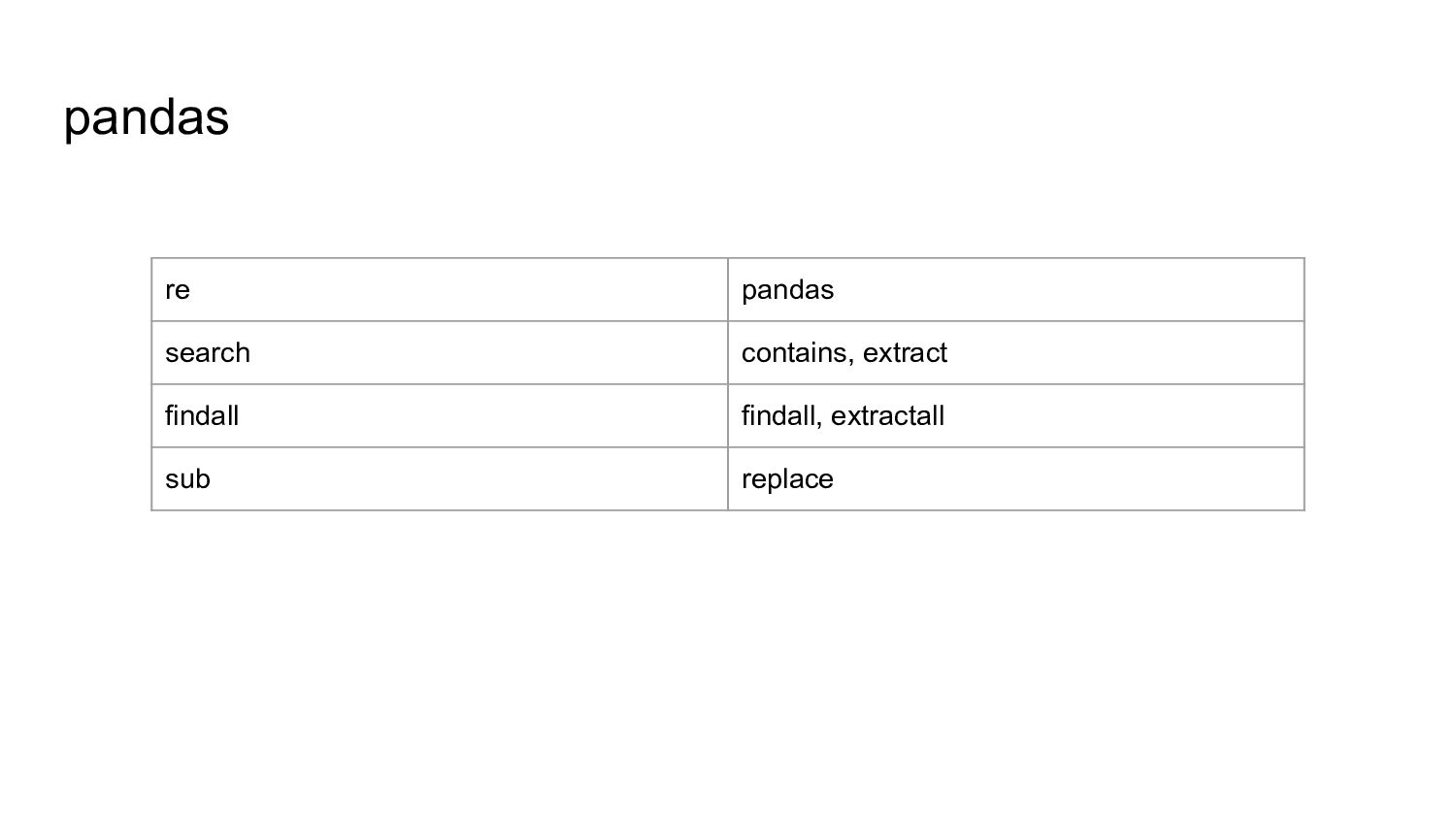
text into data ◦ Known keywords ◦ Vector encoding (one-hot encoding) • Ontologies, Vocabularies and Custom Dictionaries ◦ Keyword Search for Filtering, Cleaning, Encoding
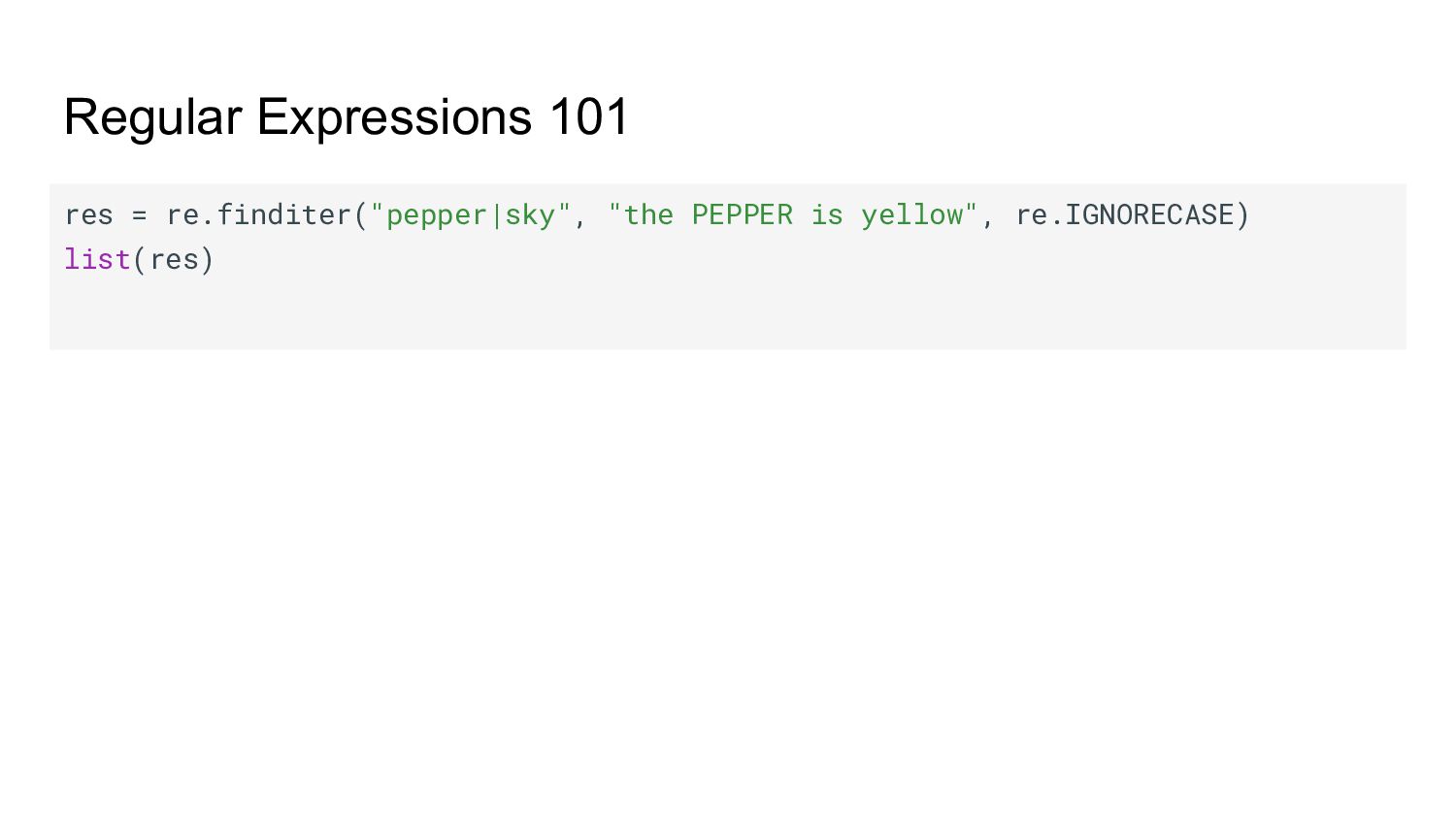
"cielo"} def repl(match, lookup=lookup, default="something"): return lookup.get(match.group(), default) re.sub("pepper|sky", repl, "the sky is blue and the pepper is yellow")
"cielo"} def repl(match, lookup=lookup, default="something"): return lookup.get(match.group(), default) re.sub("pepper|sky", repl, "the sky is blue and the pepper is yellow") 'the cielo is blue and the pimiento is yellow'
"cielo"} def repl(match, lookup=lookup, default="something"): return lookup.get(match.group(), default) re.sub("pepper|sky", repl, "the sky is blue and the pepper is yellow") 'the cielo is blue and the pimiento is yellow' ⚡ Cleaning, normalizing, etc
common prefix while True: prefix = None for item in items: if not item: break if prefix is None: prefix = item[0] elif item[0] != prefix: break else: # all subitems start with a common "prefix". # move it out of the branch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![What’s the problem then? 🤔 import re words = [...]](https://files.speakerdeck.com/presentations/5c963ff24fbf4cc48fa147f9fc9bee6a/slide_34.jpg){kind=link}
{kind=link}
![What’s the problem then? 🤔 import re [...] pattern =](https://files.speakerdeck.com/presentations/5c963ff24fbf4cc48fa147f9fc9bee6a/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
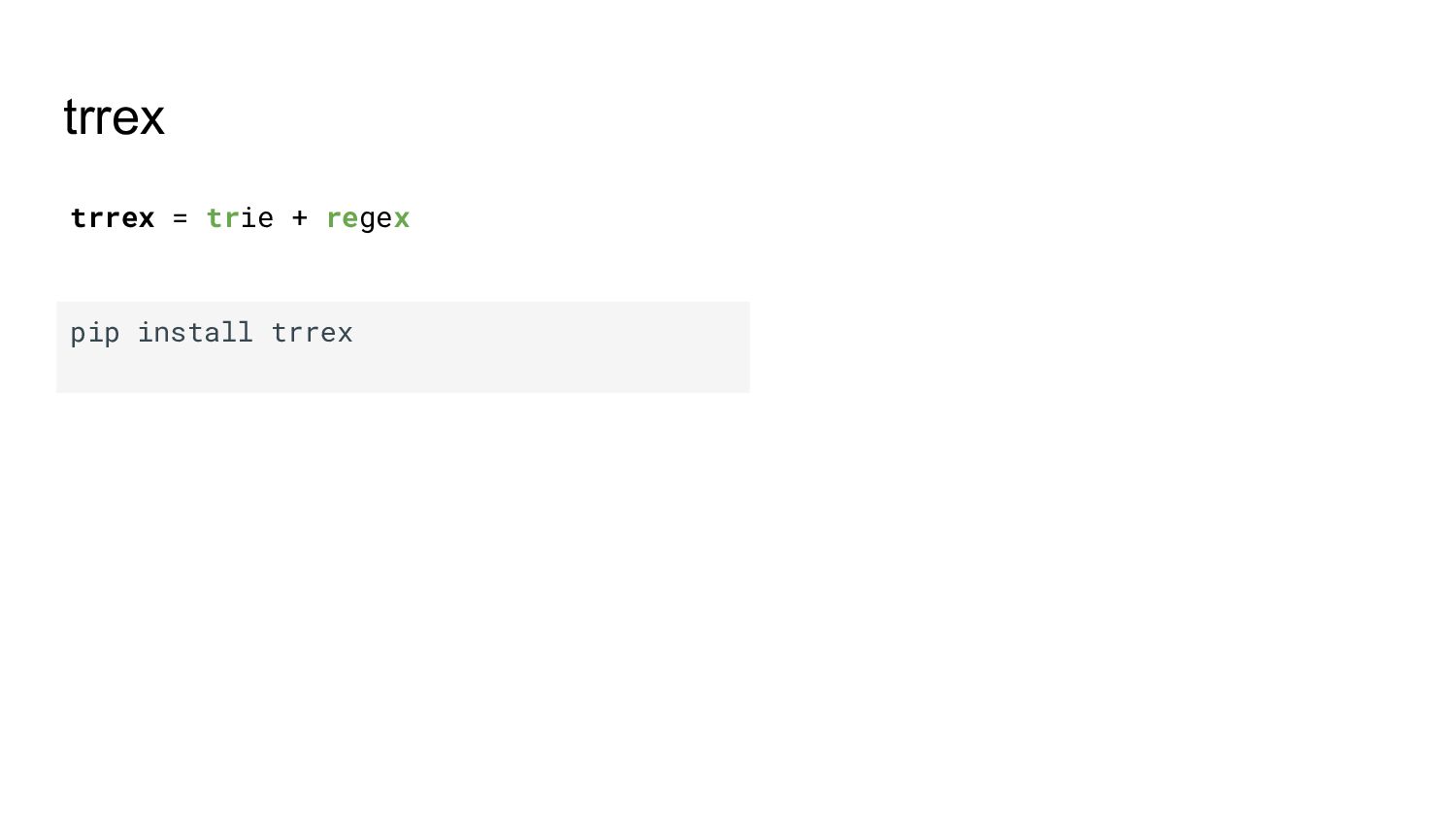{kind=link}
![trrex ['bank', 'bat', 'baby', 'air']](https://files.speakerdeck.com/presentations/5c963ff24fbf4cc48fa147f9fc9bee6a/slide_45.jpg){kind=link}
![trrex ['bank', 'bat', 'baby', 'air']](https://files.speakerdeck.com/presentations/5c963ff24fbf4cc48fa147f9fc9bee6a/slide_46.jpg){kind=link}
![trrex '\\b(?:ba(?:nk|by|t)|air)\\b' ['bank', 'bat', 'baby', 'air']](https://files.speakerdeck.com/presentations/5c963ff24fbf4cc48fa147f9fc9bee6a/slide_47.jpg){kind=link}
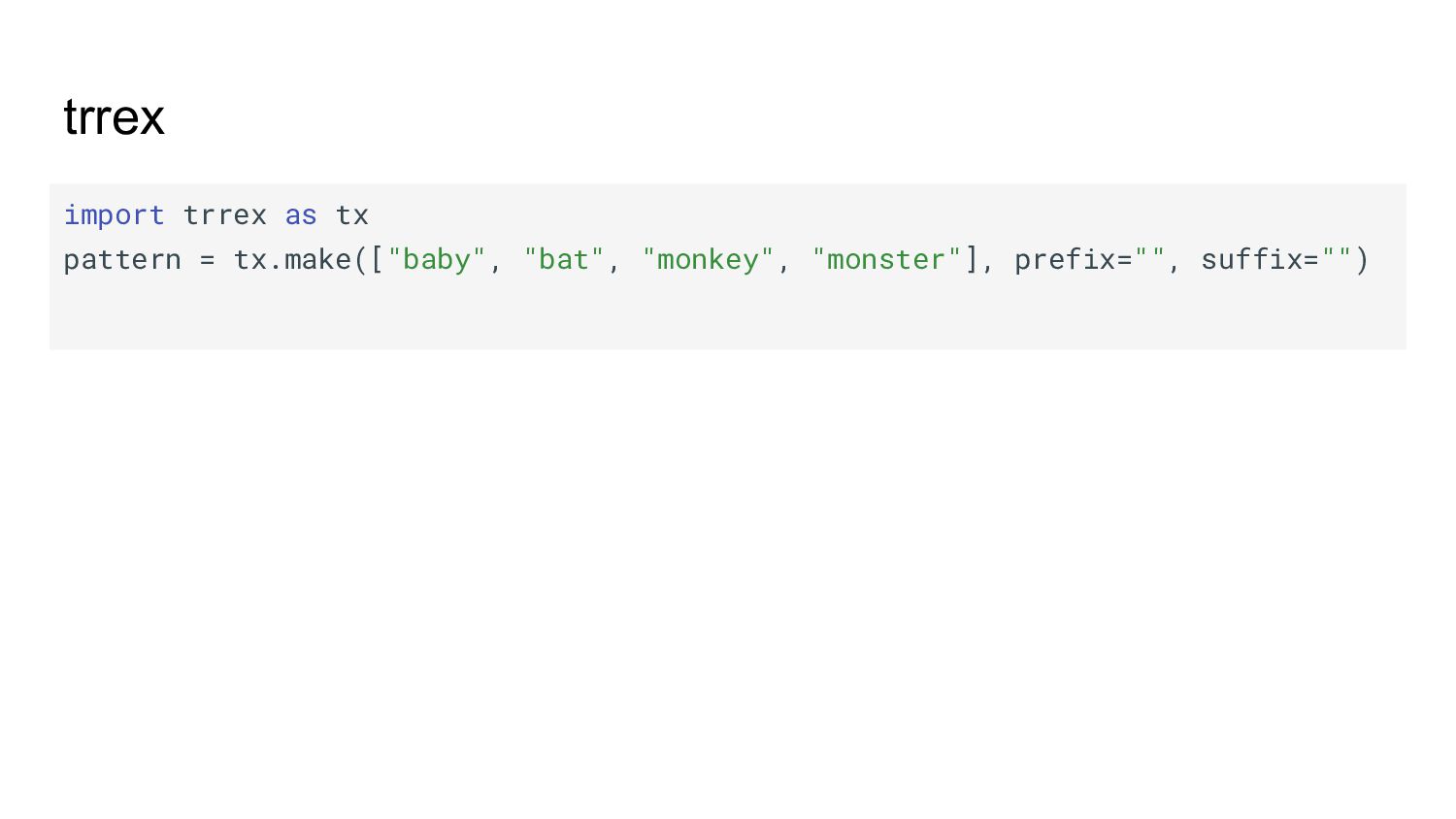{kind=link}
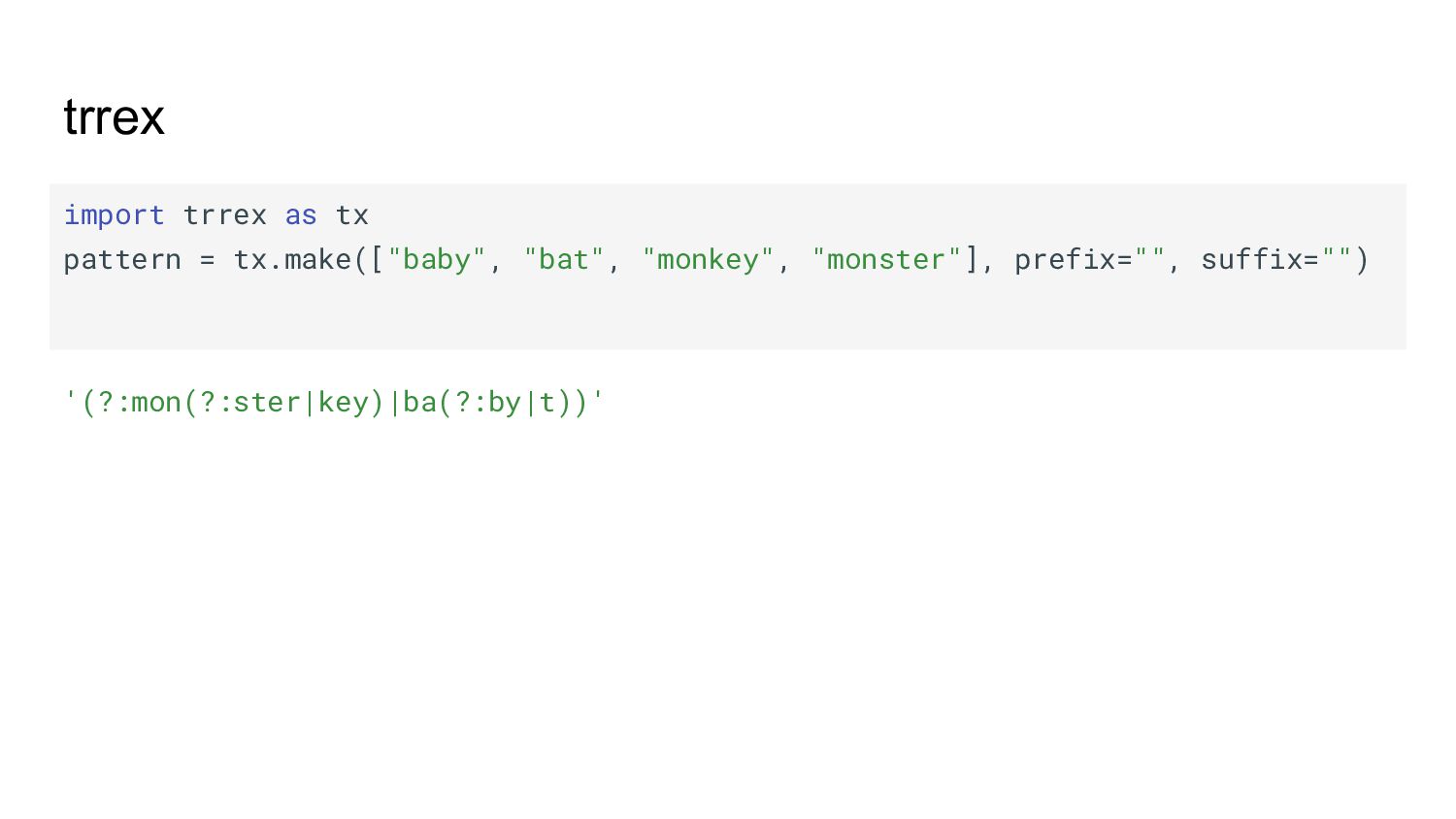{kind=link}
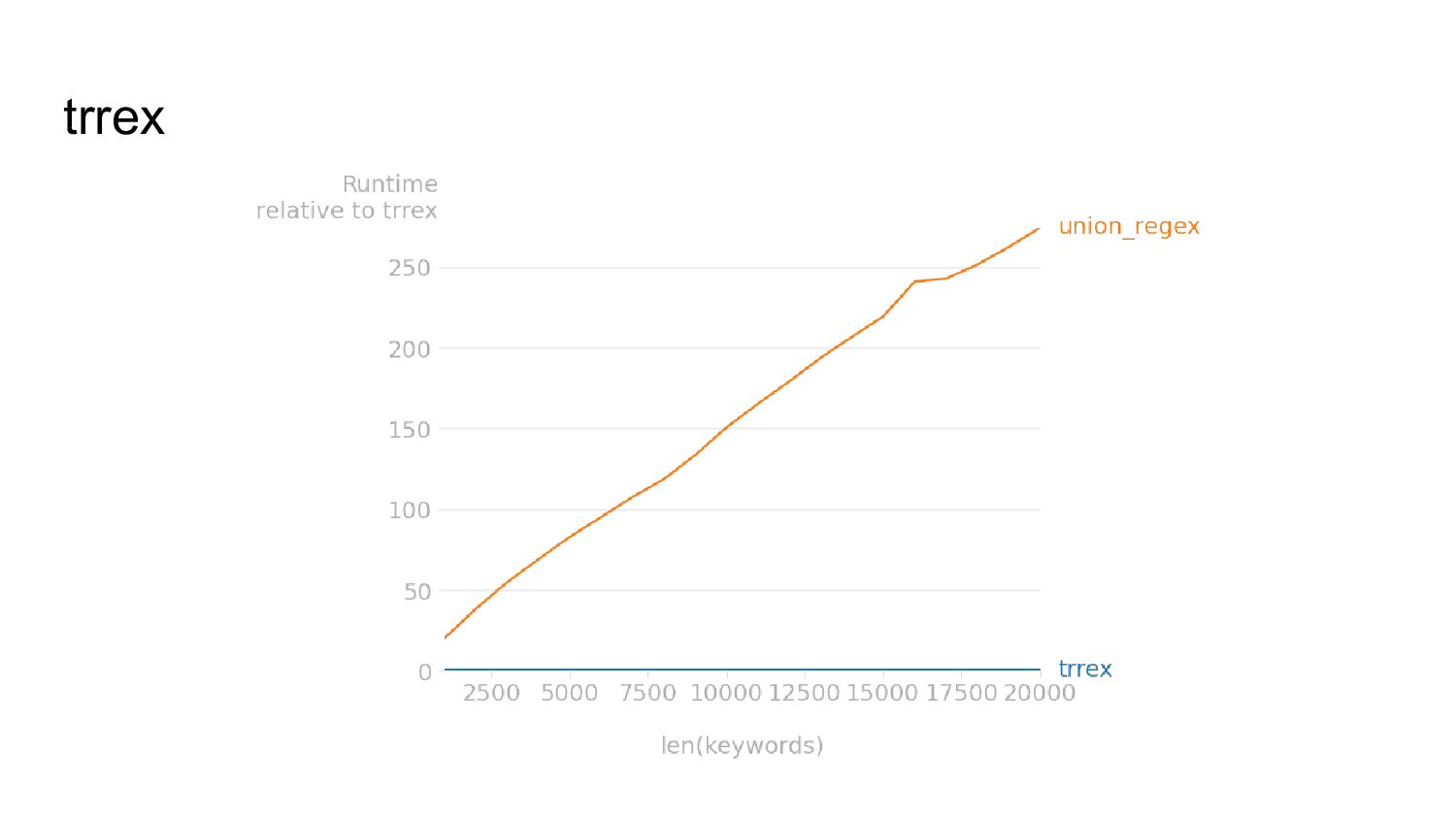{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}