This slides introduce the trrex package, for performing efficient keyword extraction with regular expressions. Additionally I'll show how to integrate it with pandas for text cleaning, how to use it with spacy to build a gazetteer and how to perform fuzzy matching with the regex library.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fast? 🤔 import re long_list_of_words = [...] pattern = "|".join(long_list_of_words)](https://files.speakerdeck.com/presentations/f7792a35268a4ed6a5ebba182d9b0c17/slide_6.jpg){kind=link}
![Fast? 🤔 import re long_list_of_words = [...] pattern = "|".join(long_list_of_words)](https://files.speakerdeck.com/presentations/f7792a35268a4ed6a5ebba182d9b0c17/slide_7.jpg){kind=link}
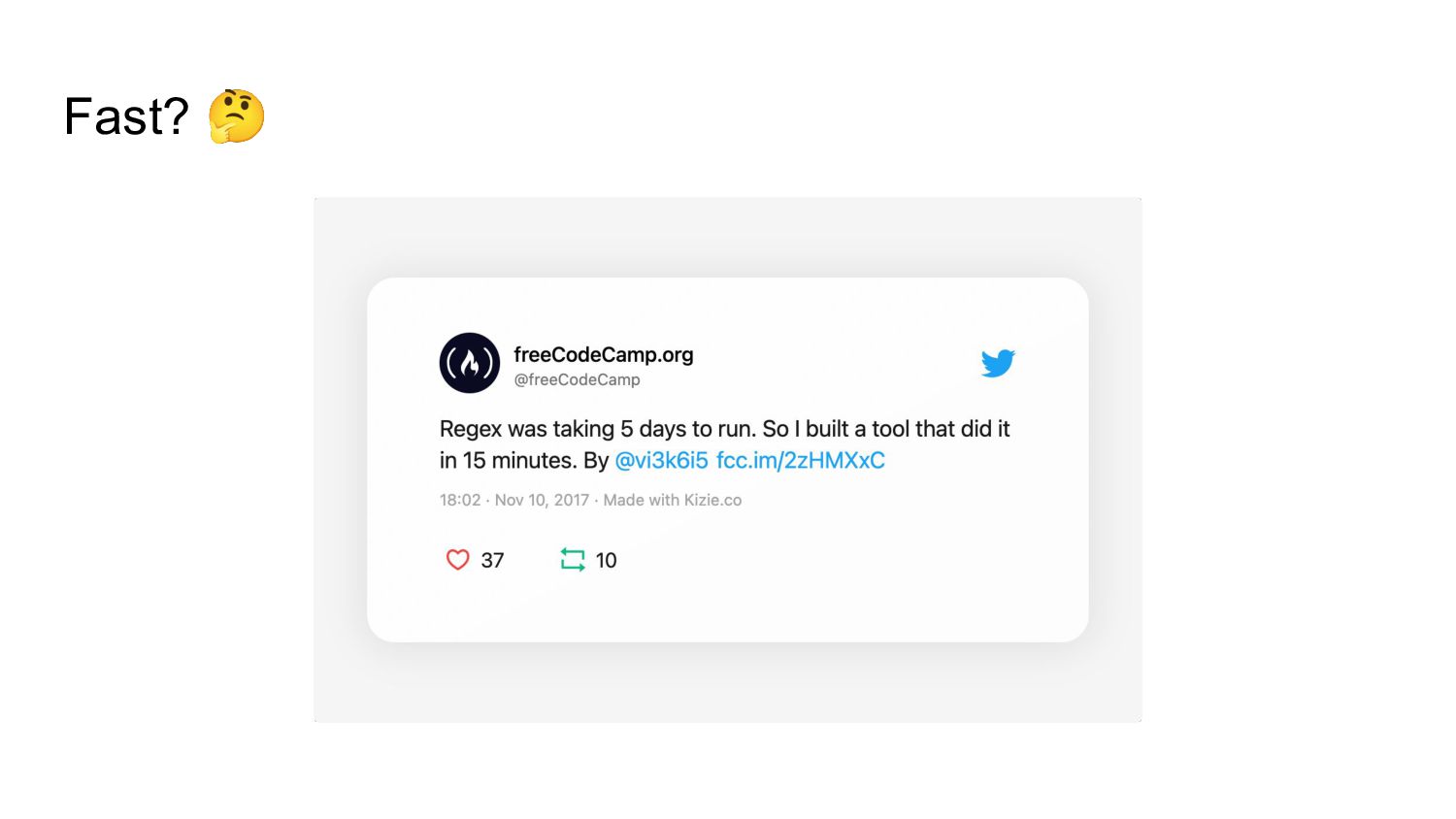{kind=link}
{kind=link}
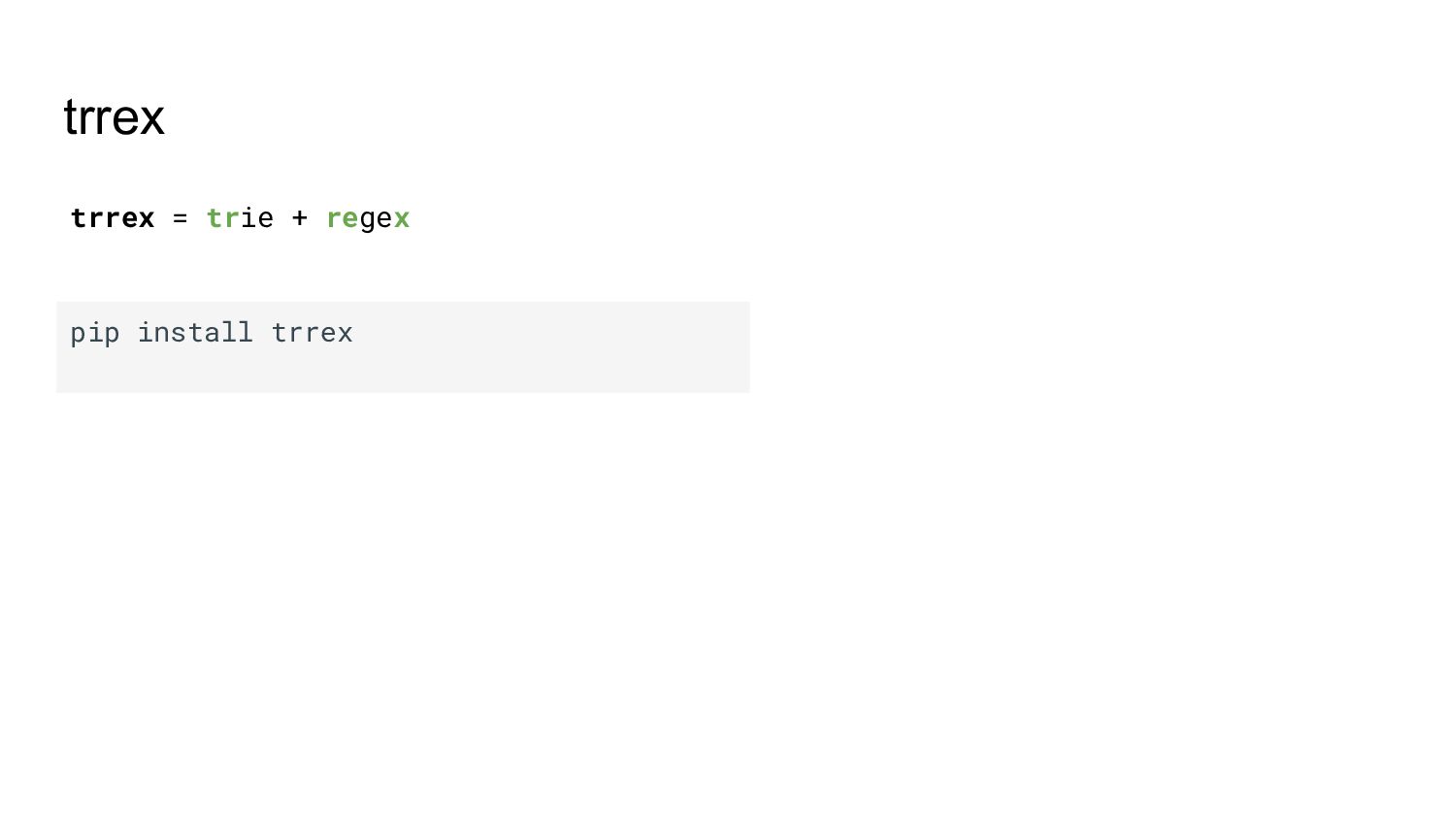{kind=link}
![trrex ['bank', 'bat', 'baby', 'air']](https://files.speakerdeck.com/presentations/f7792a35268a4ed6a5ebba182d9b0c17/slide_11.jpg){kind=link}
![trrex ['bank', 'bat', 'baby', 'air']](https://files.speakerdeck.com/presentations/f7792a35268a4ed6a5ebba182d9b0c17/slide_12.jpg){kind=link}
![trrex '\\b(?:ba(?:nk|by|t)|air)\\b' ['bank', 'bat', 'baby', 'air']](https://files.speakerdeck.com/presentations/f7792a35268a4ed6a5ebba182d9b0c17/slide_13.jpg){kind=link}
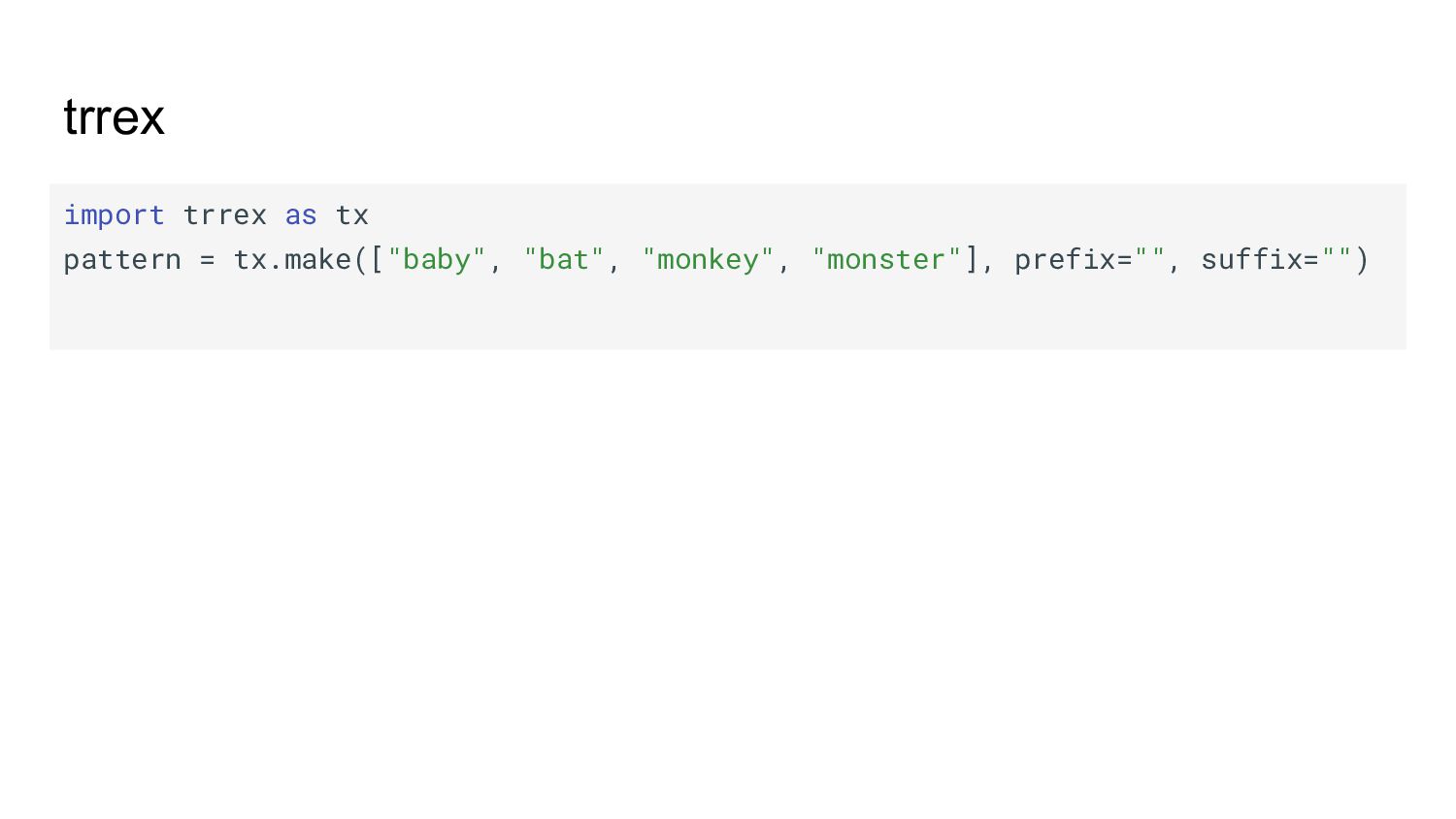{kind=link}
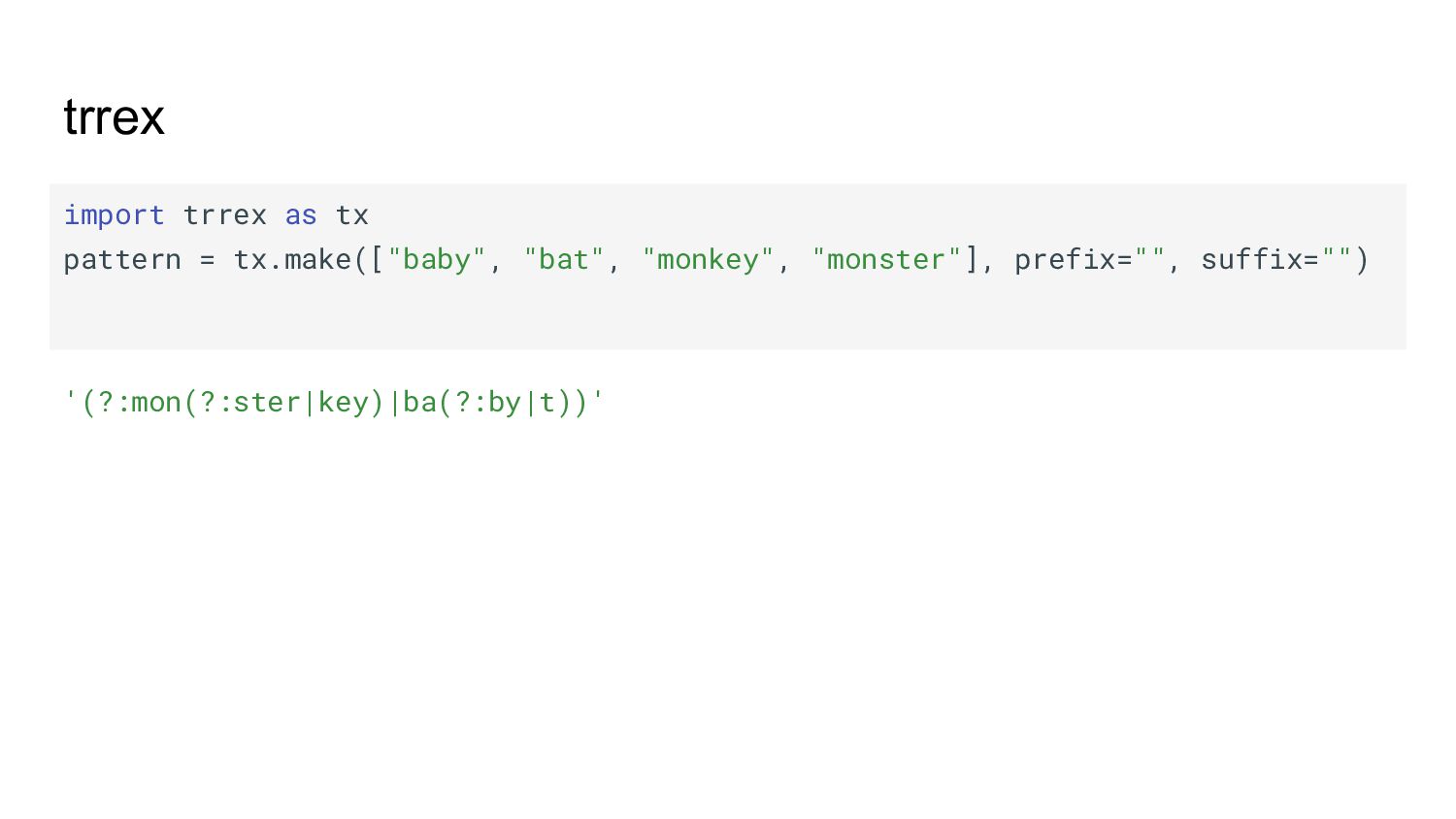{kind=link}
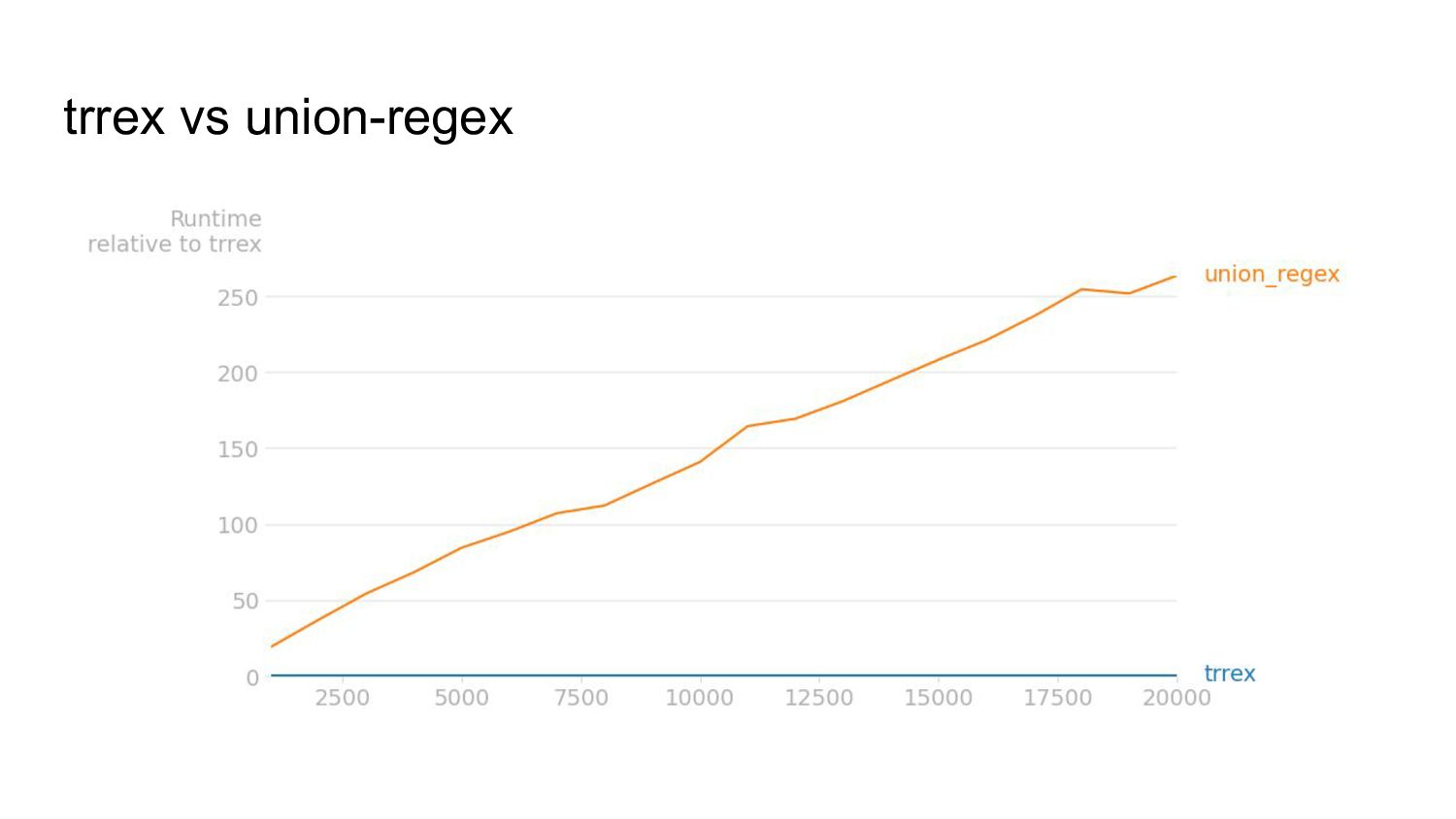{kind=link}
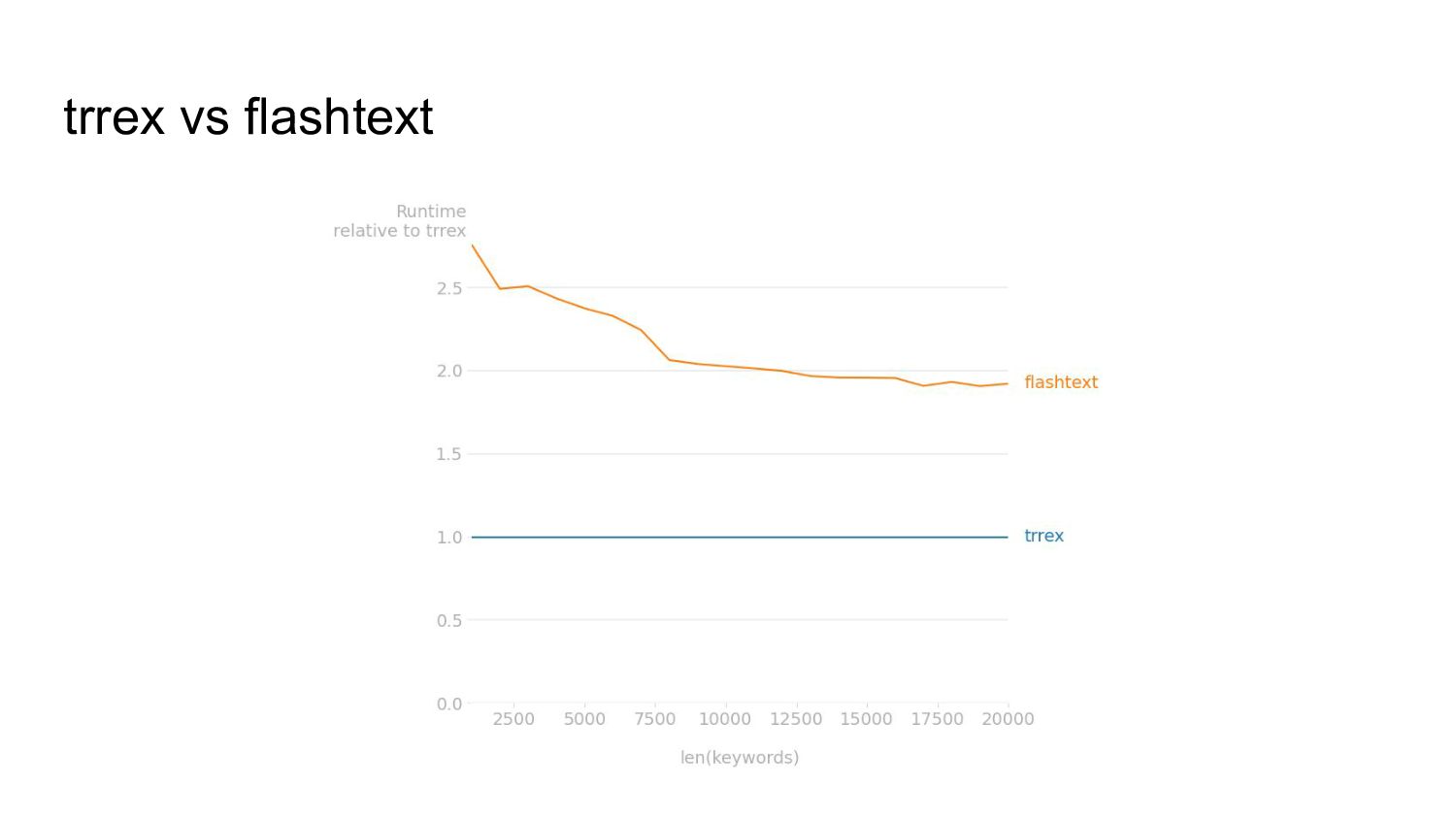{kind=link}
{kind=link}
{kind=link}
{kind=link}
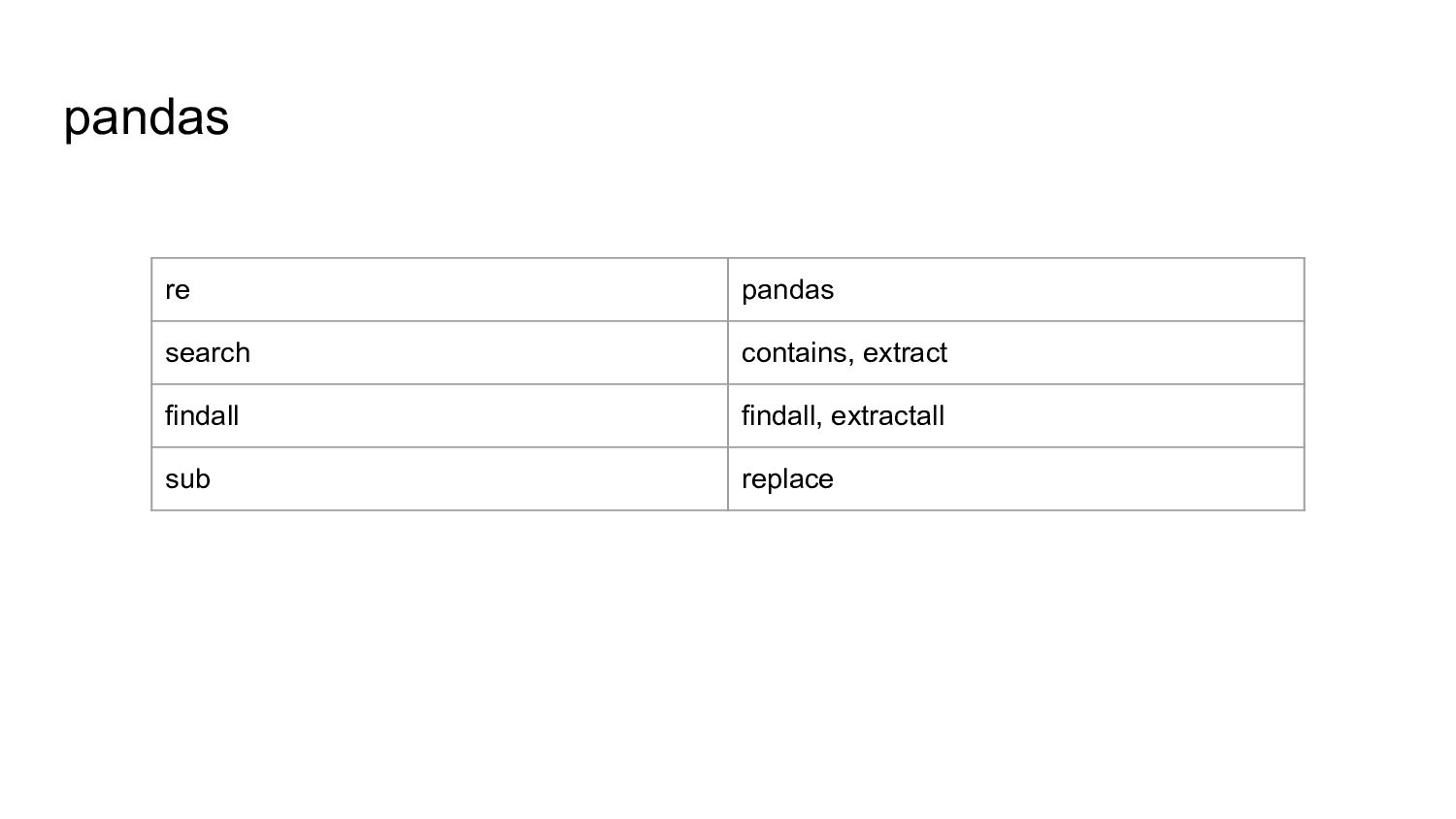{kind=link}
{kind=link}
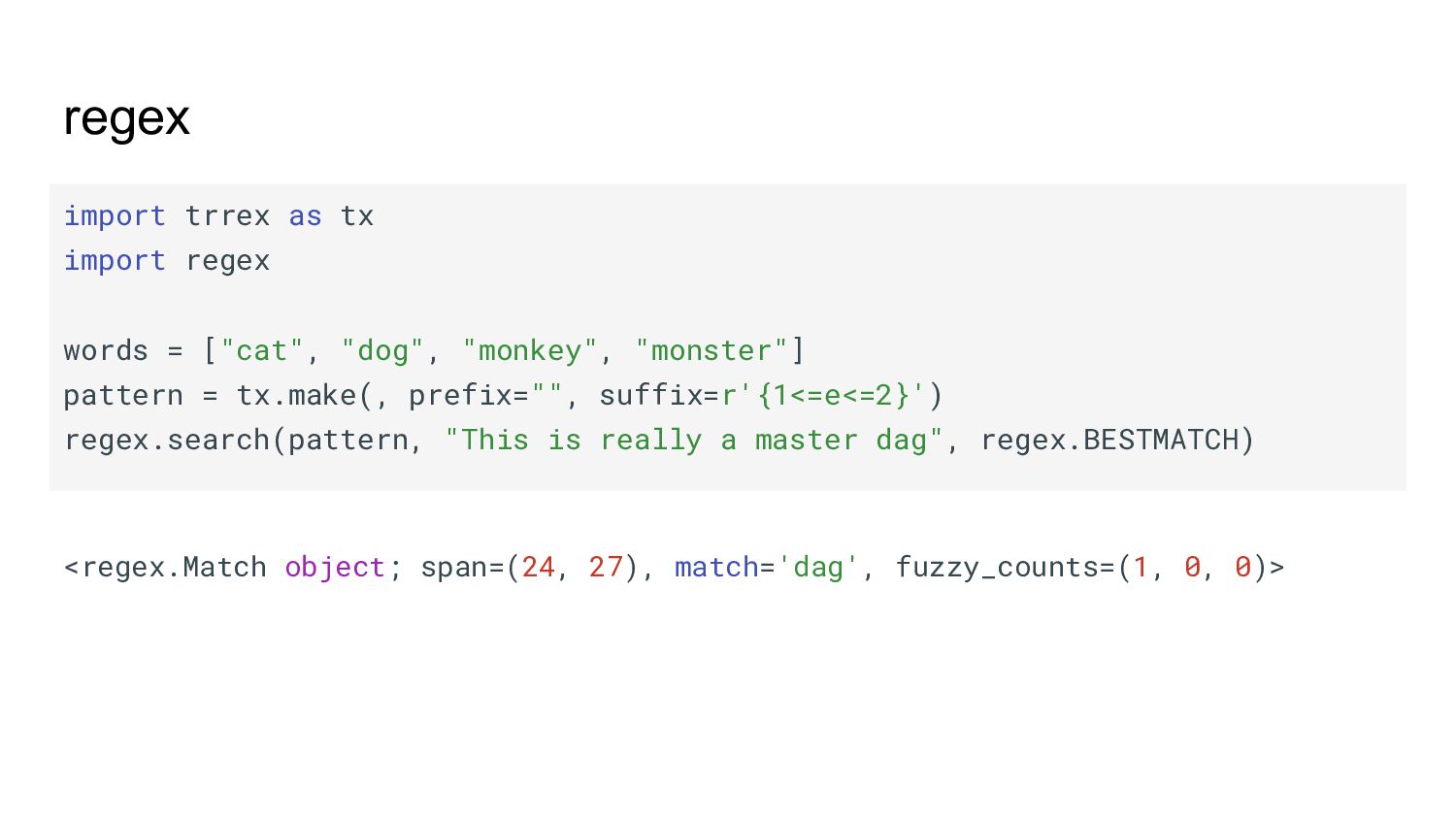{kind=link}
{kind=link}
{kind=link}
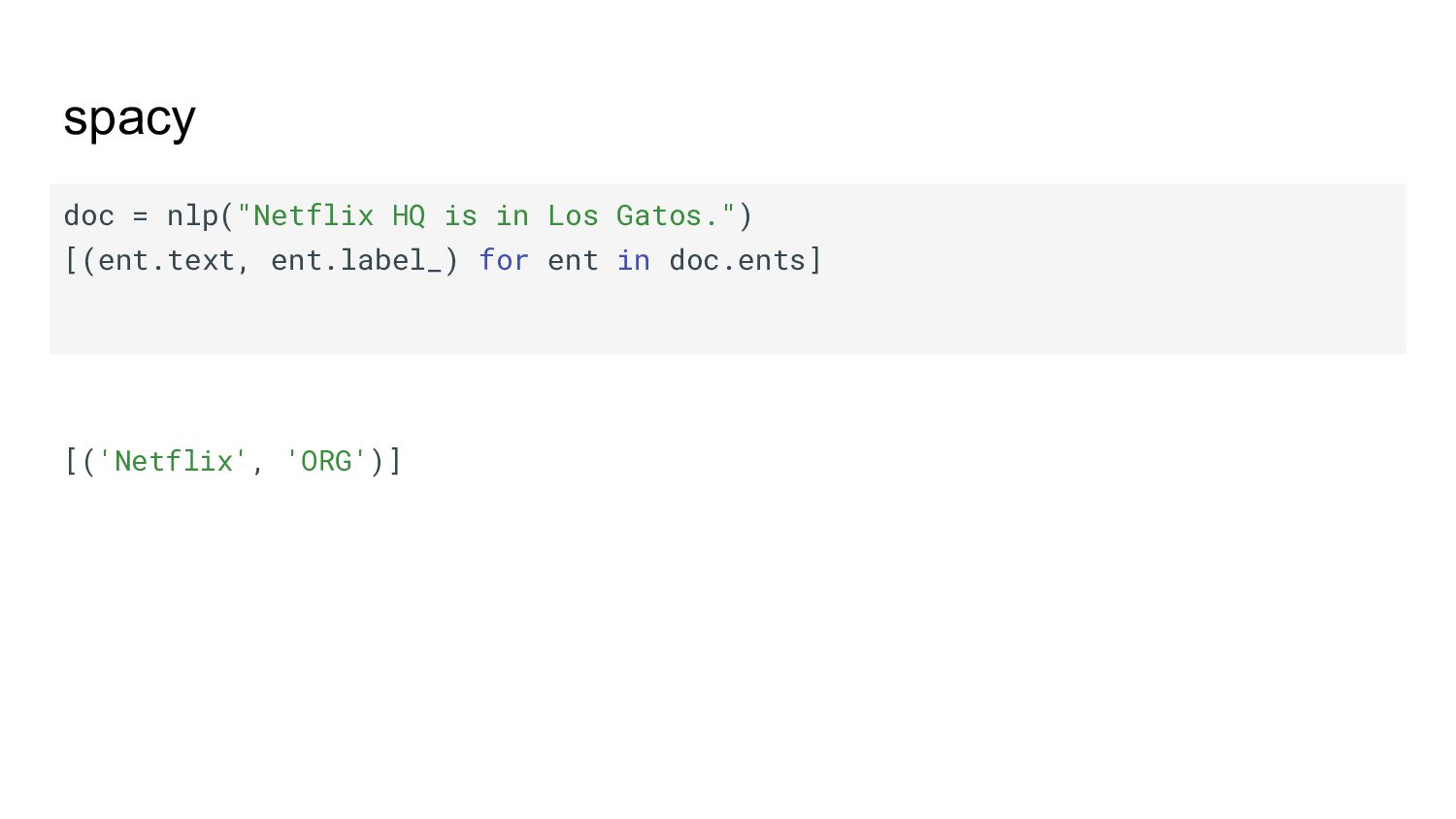{kind=link}
{kind=link}
{kind=link}