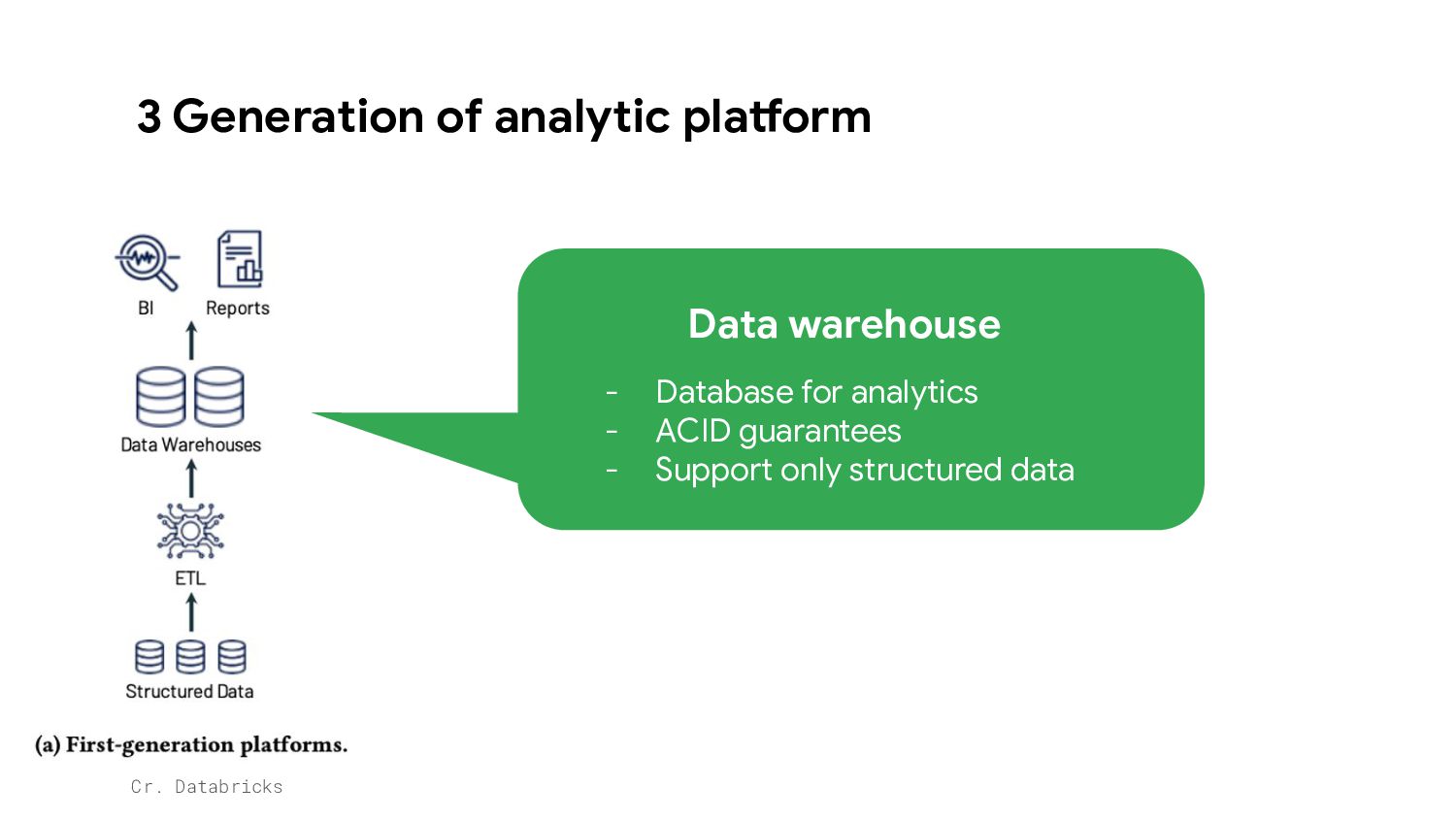
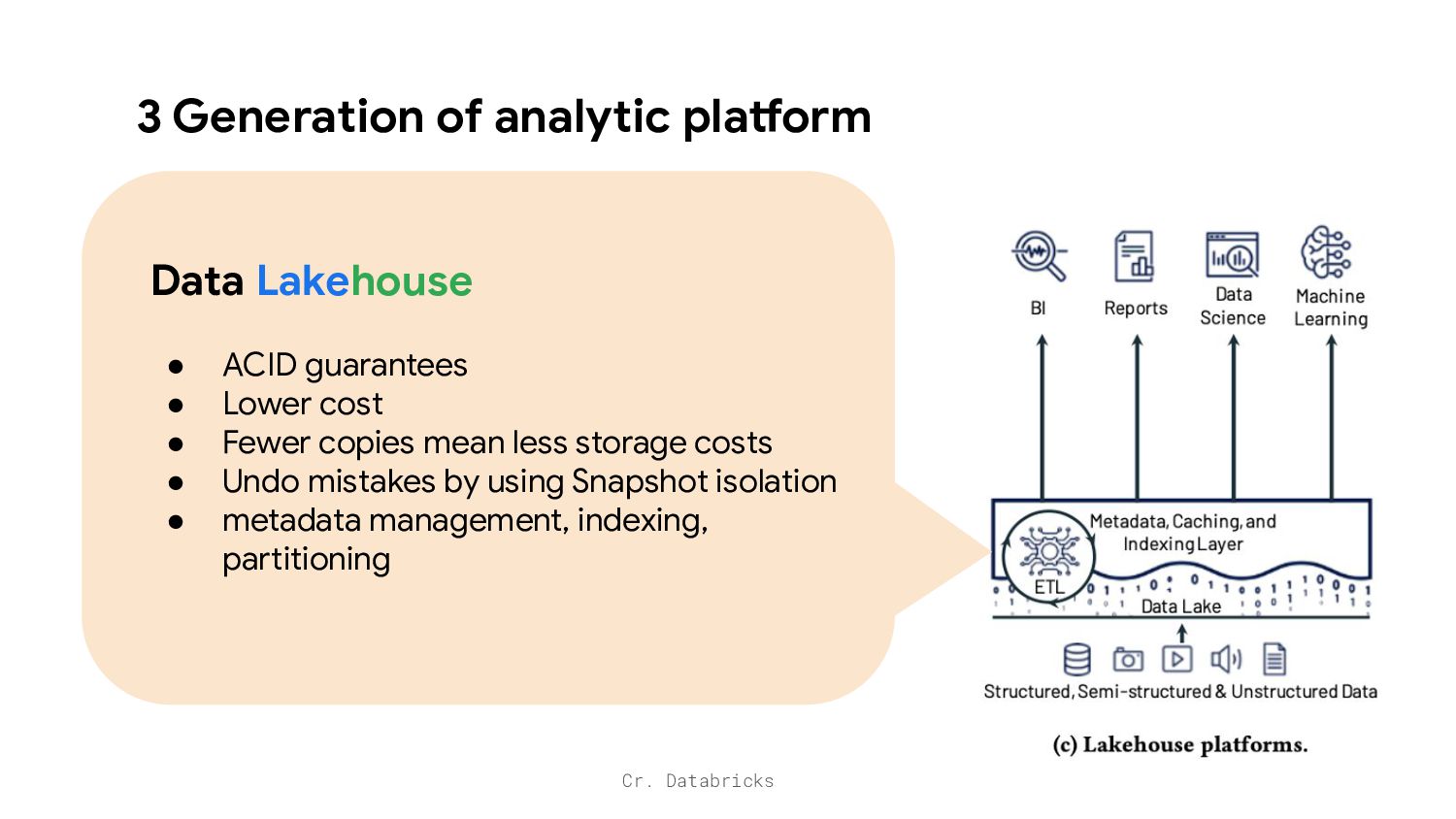
Store CSV, JSON, images, video, txt • Store data in Open Formats e.g. parquet, avro • Lower cost Lack of ACID Guarantees, metadata management, indexing, partitioning
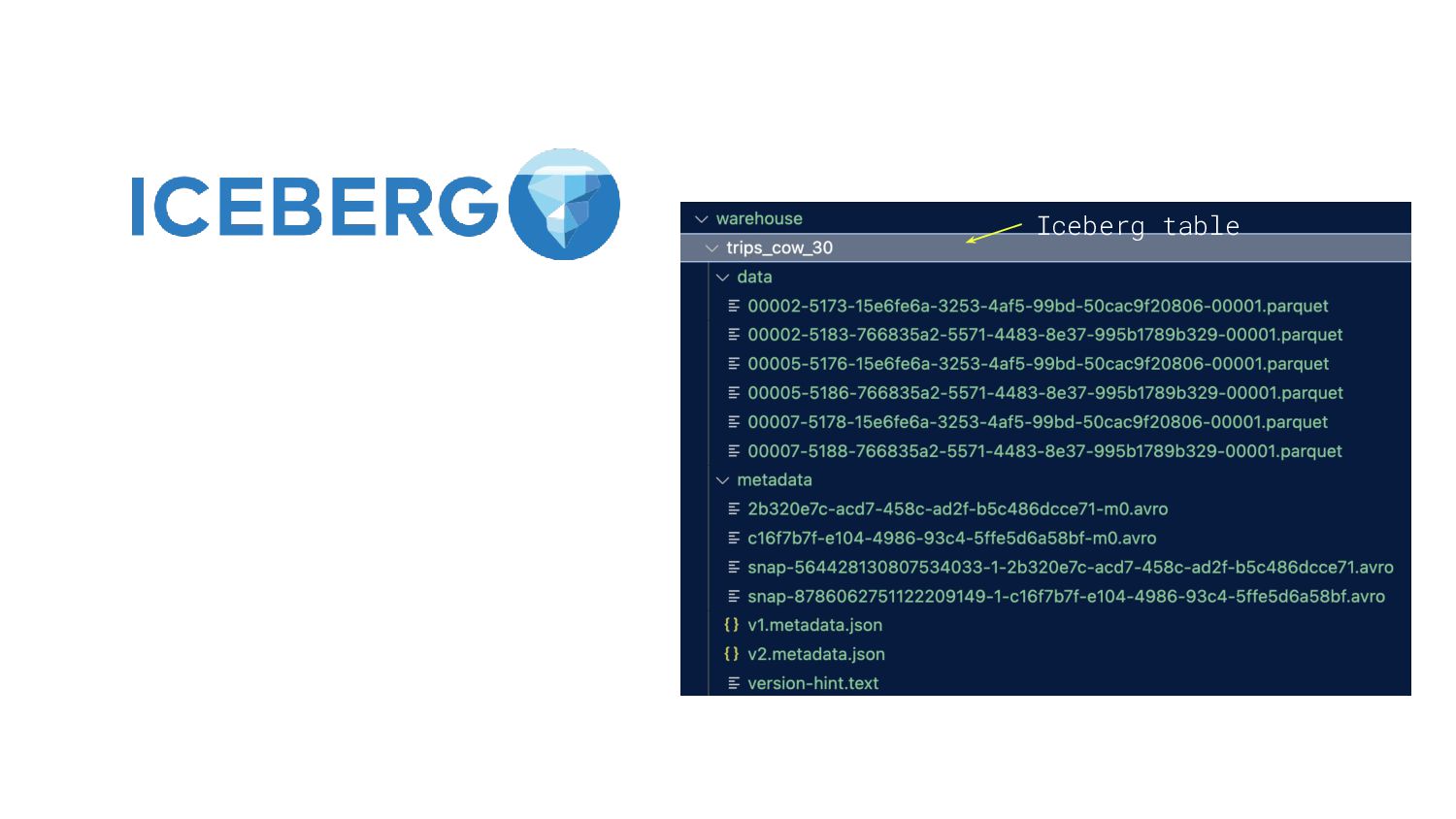
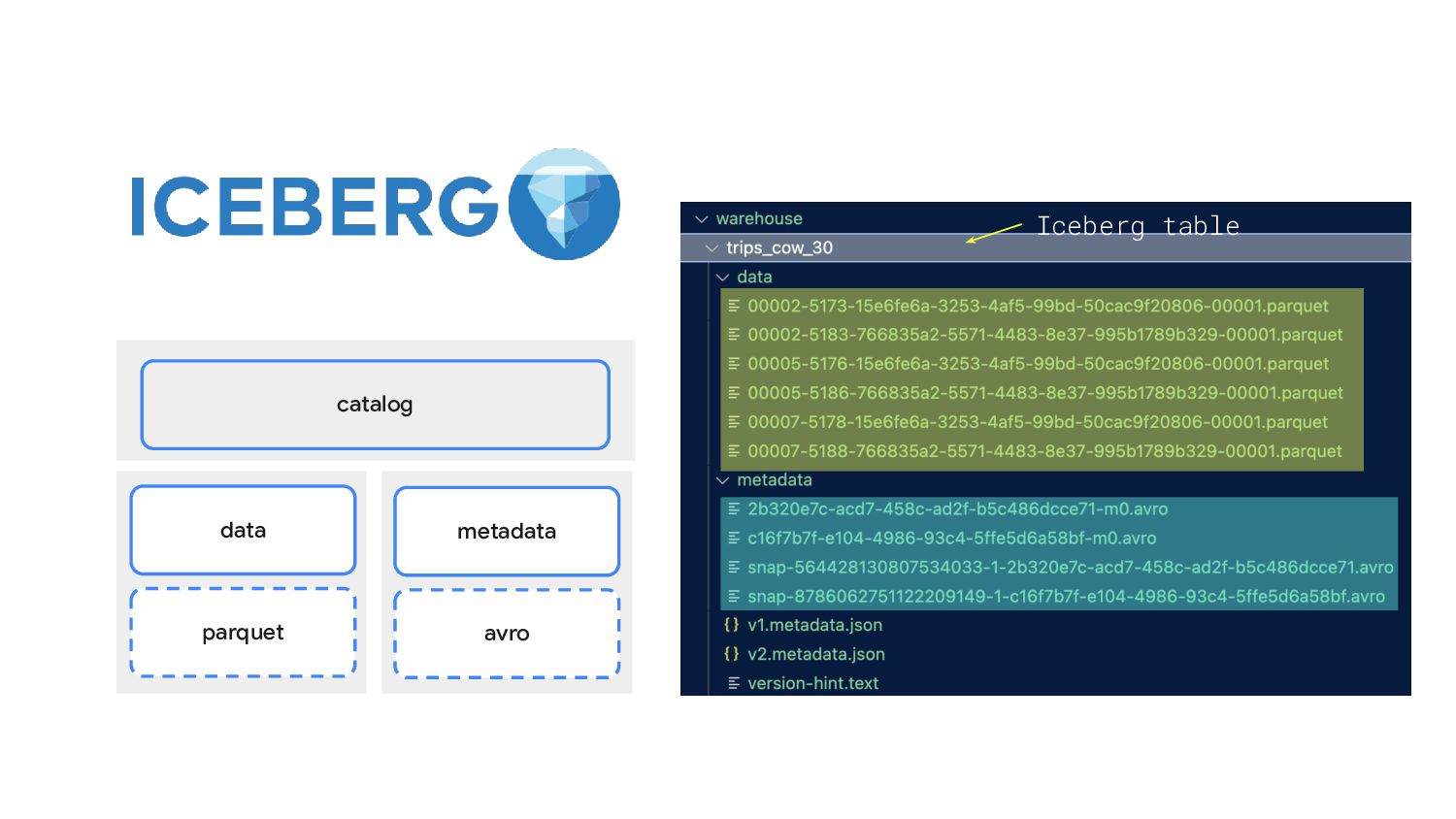
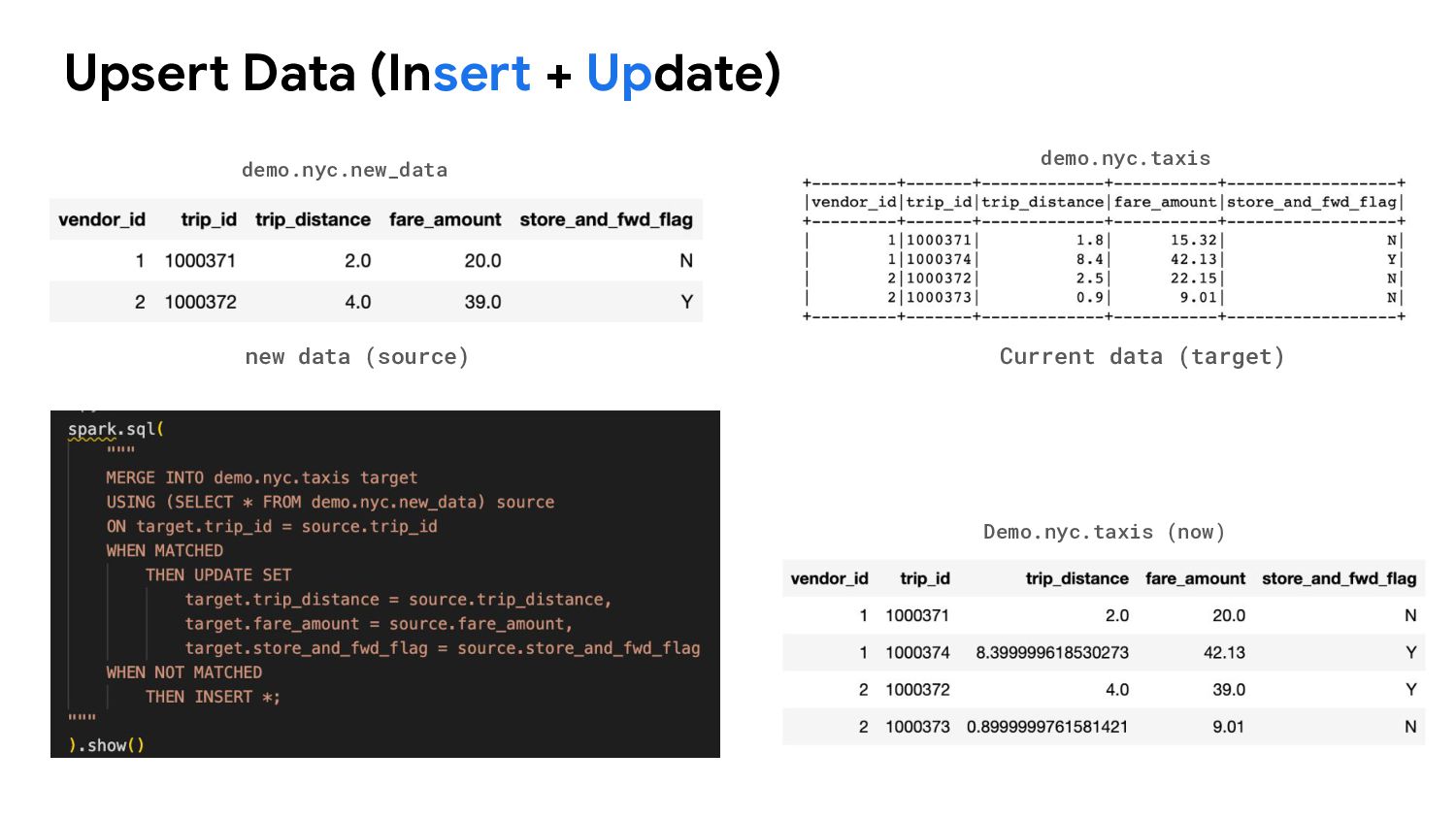
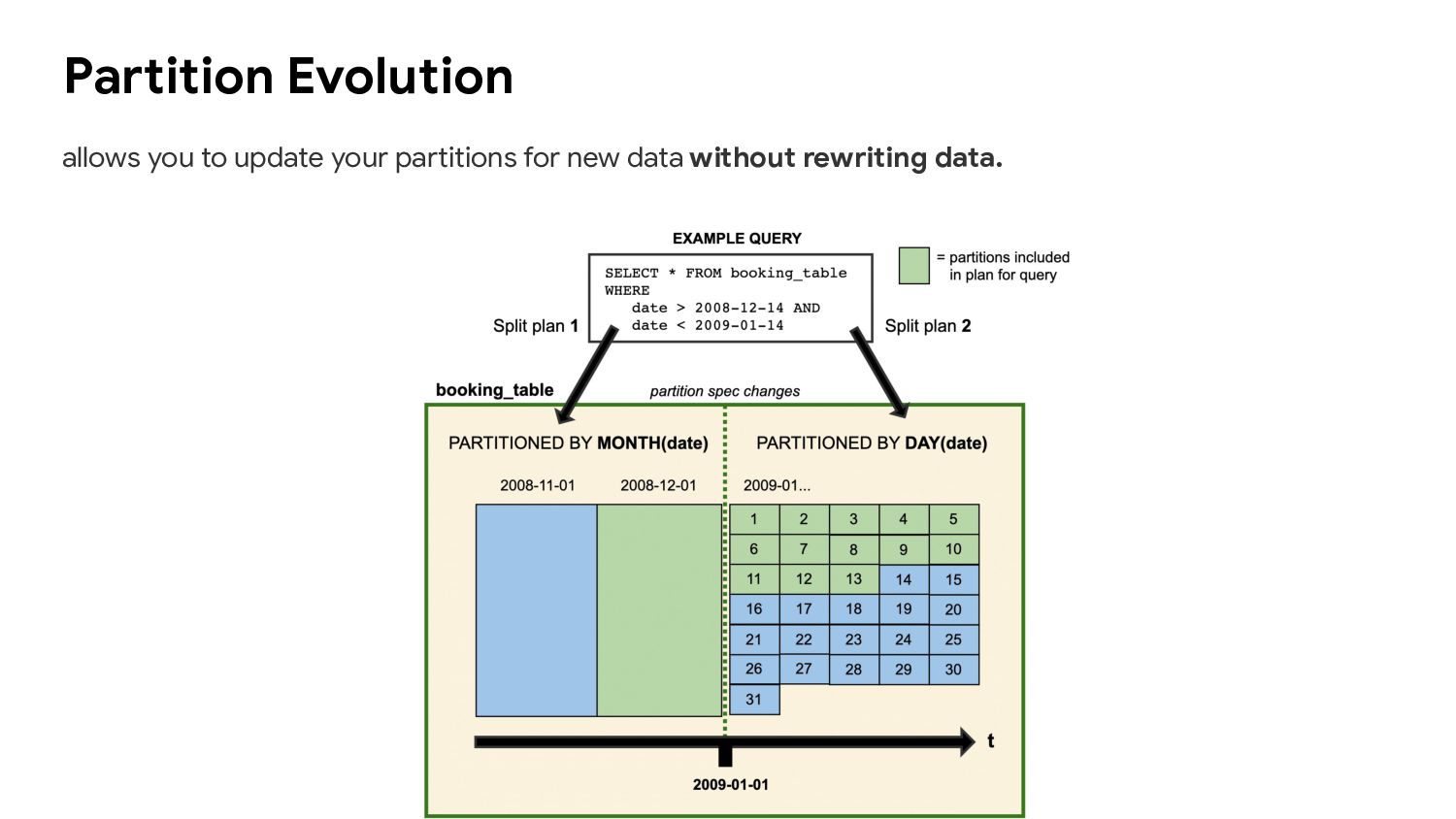
Presto, Hive and Impala to safely work with the same tables, at the same time and works just like a SQL table. 2. Upsert data 3. Schema Evolution 4. Partition evolution 5. Time Travel and Rollback What can do ?
• Drop existing column • Reorder column • Rename existing column • Add column comment = No need to create and write to new table But you can do it in-place !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
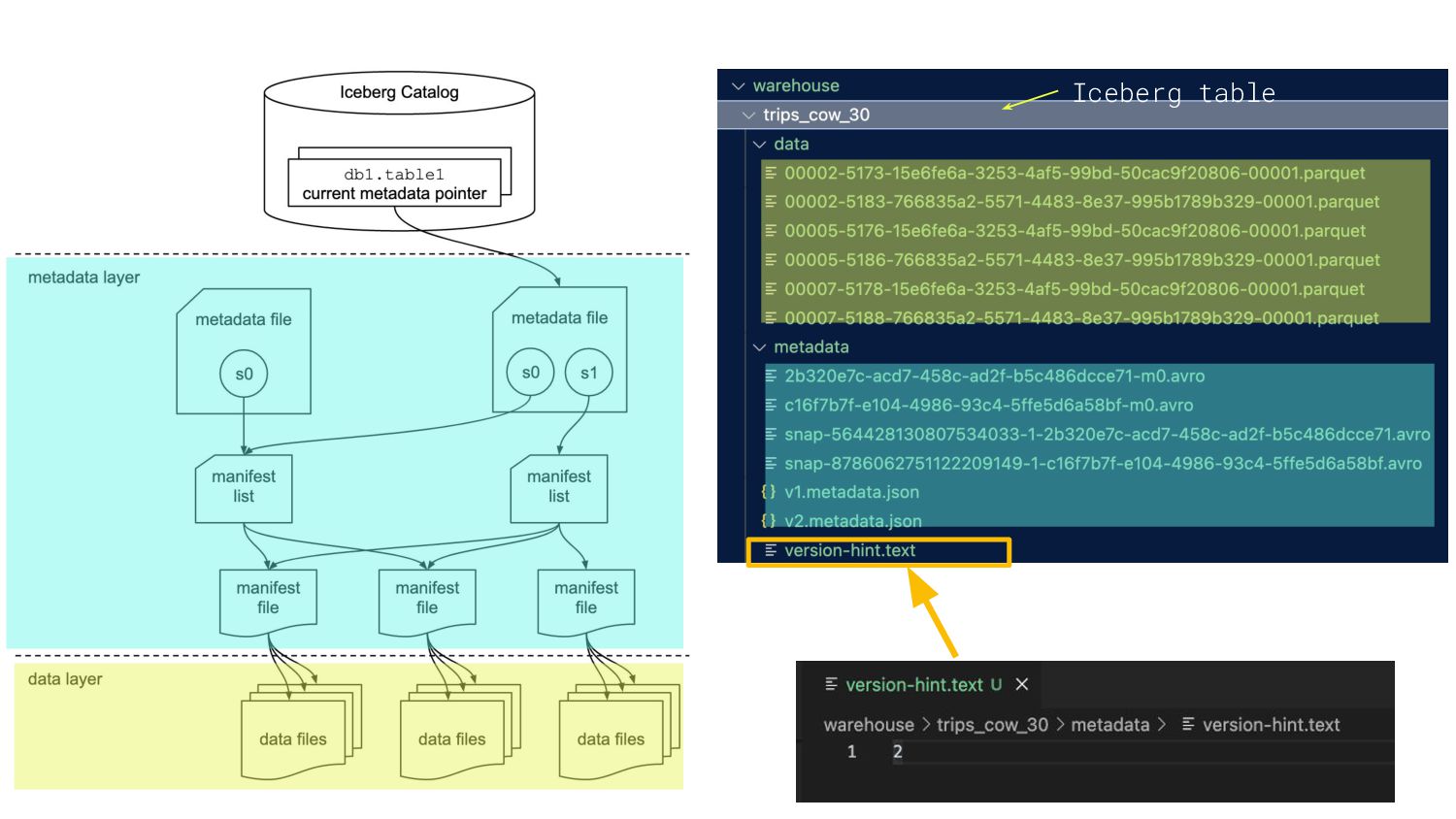{kind=link}
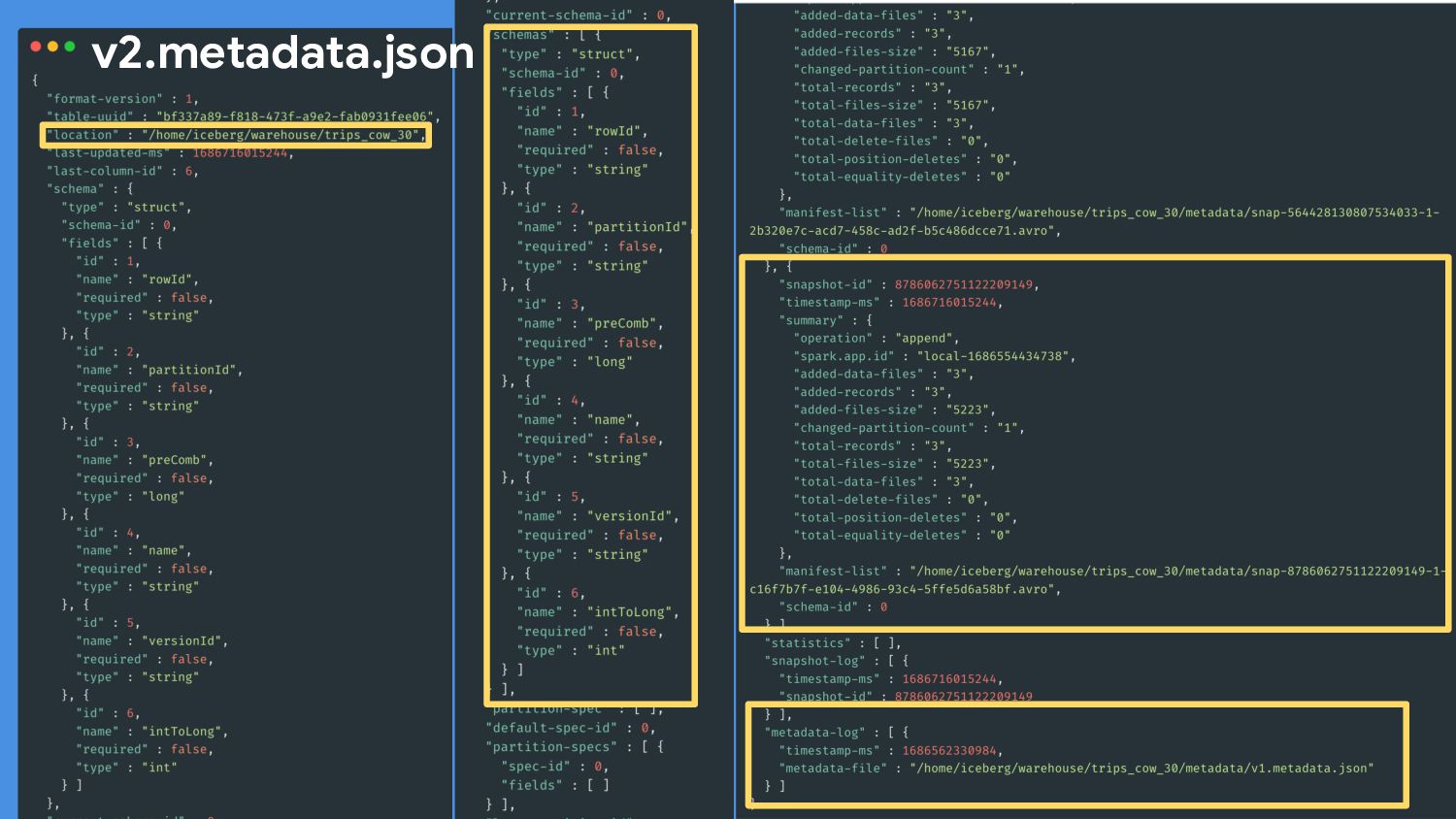{kind=link}
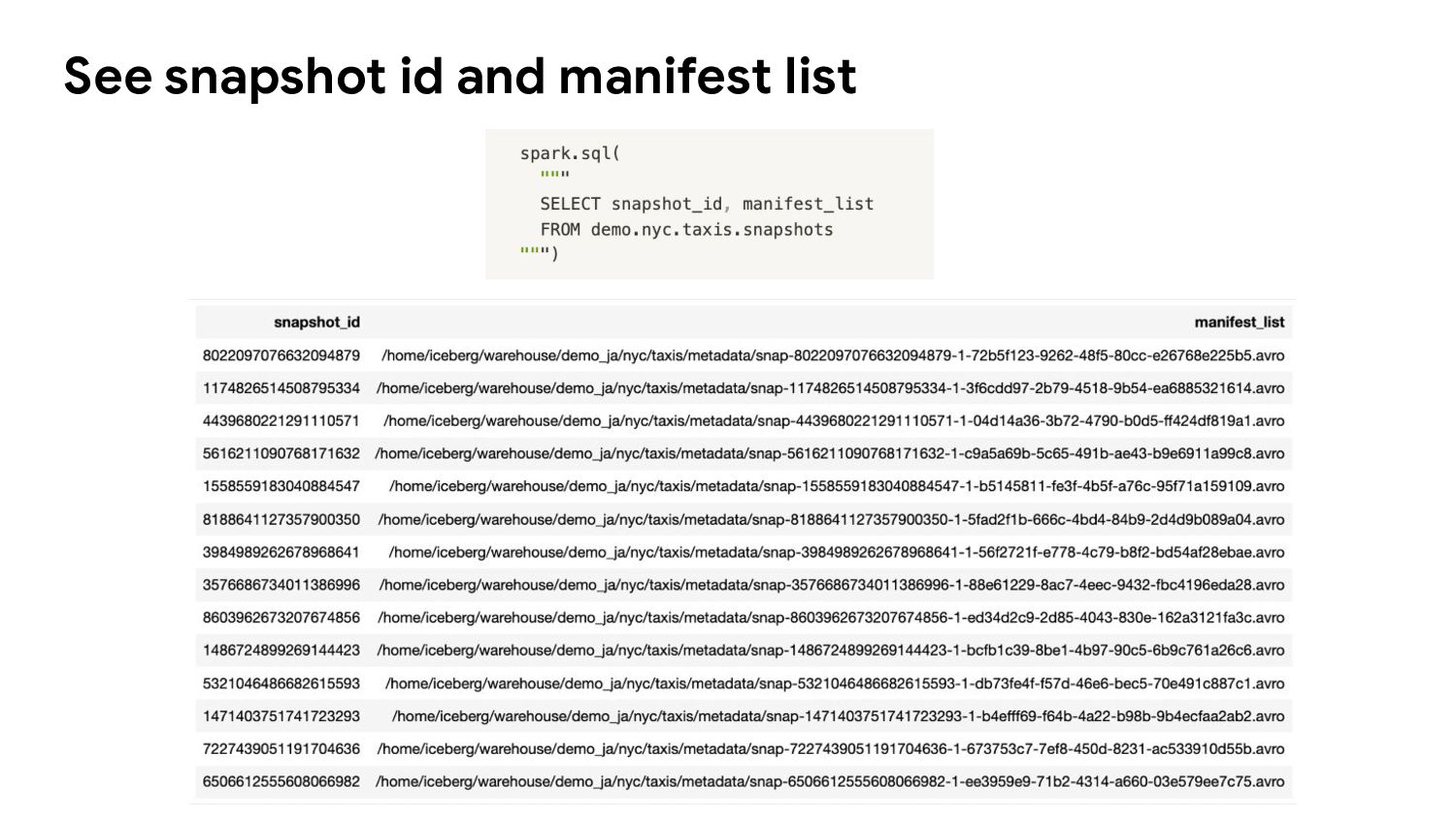{kind=link}
{kind=link}
{kind=link}
{kind=link}
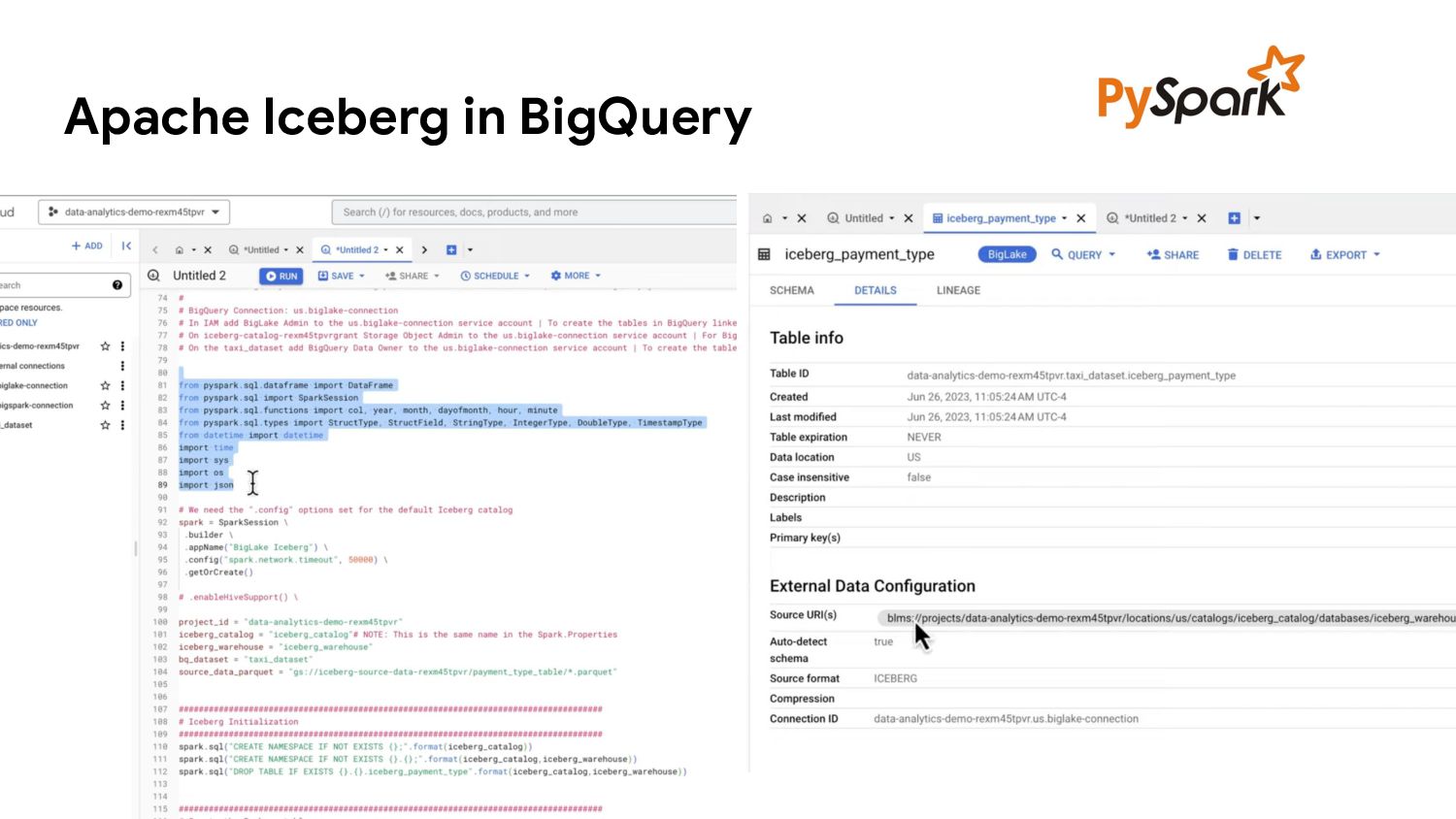{kind=link}
{kind=link}
{kind=link}