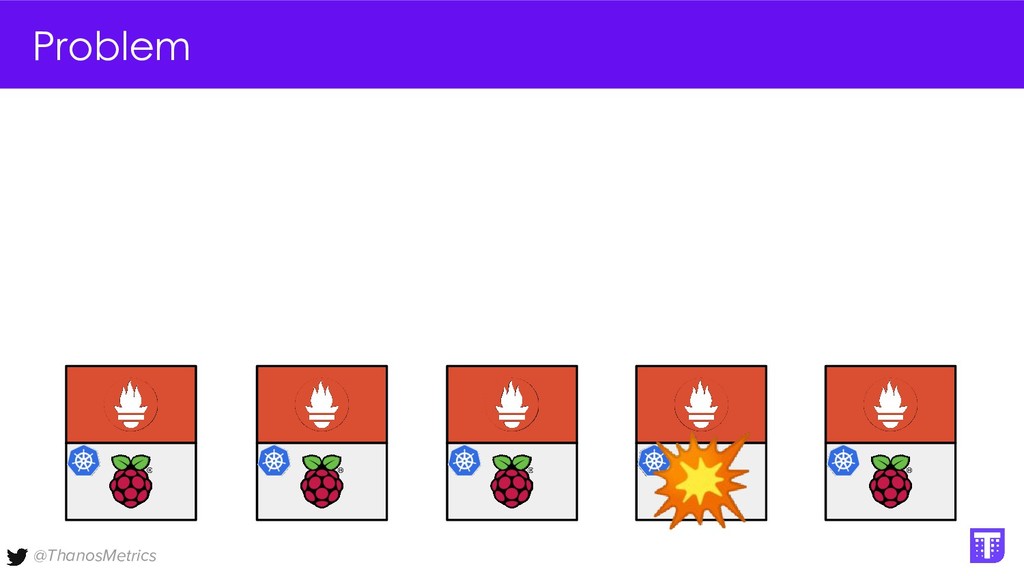
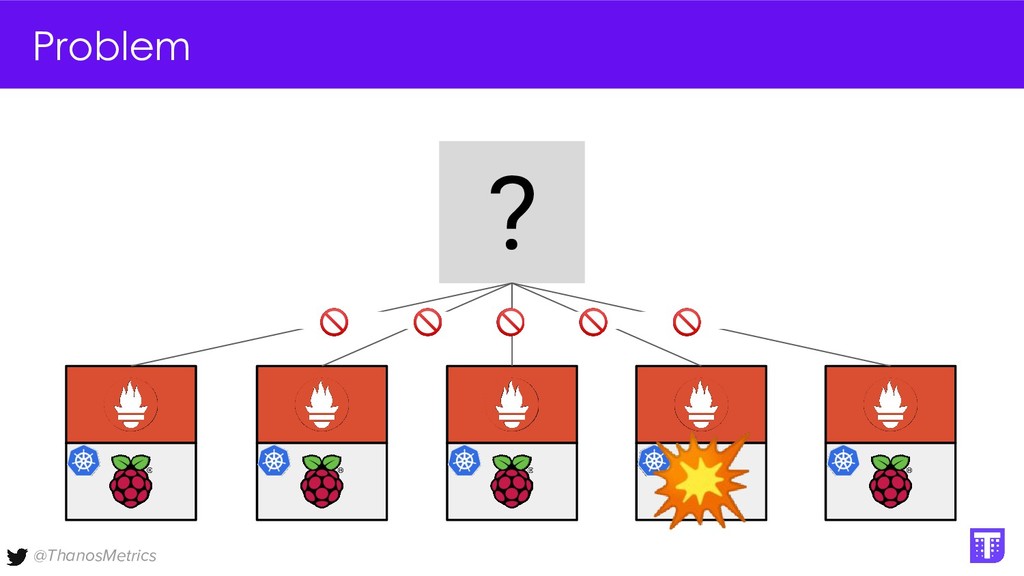
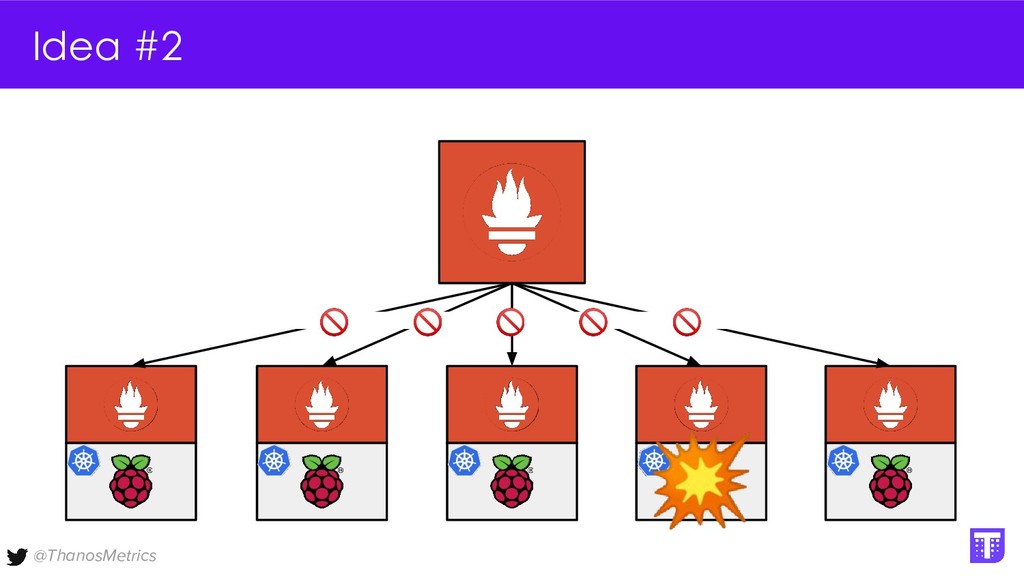
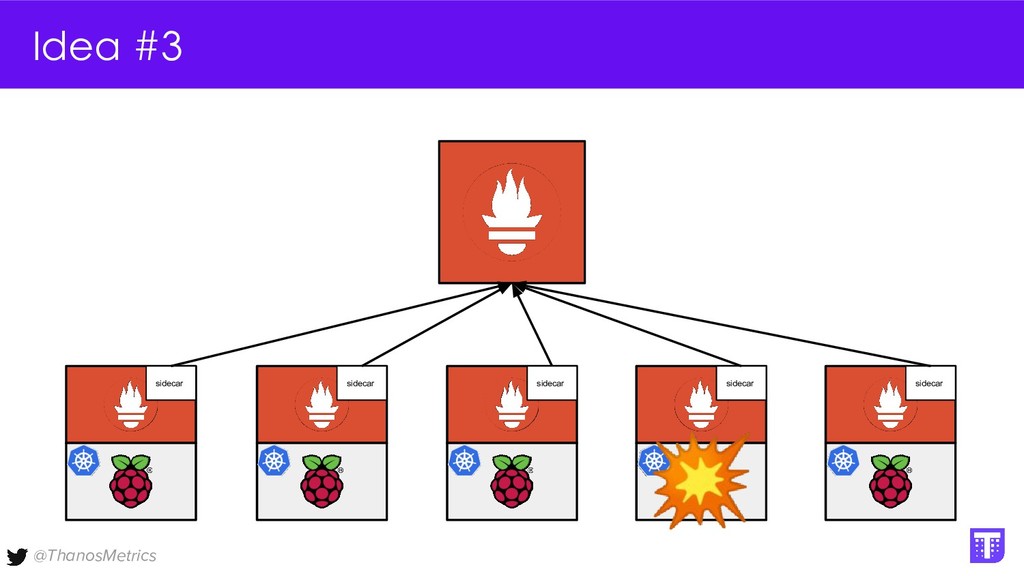
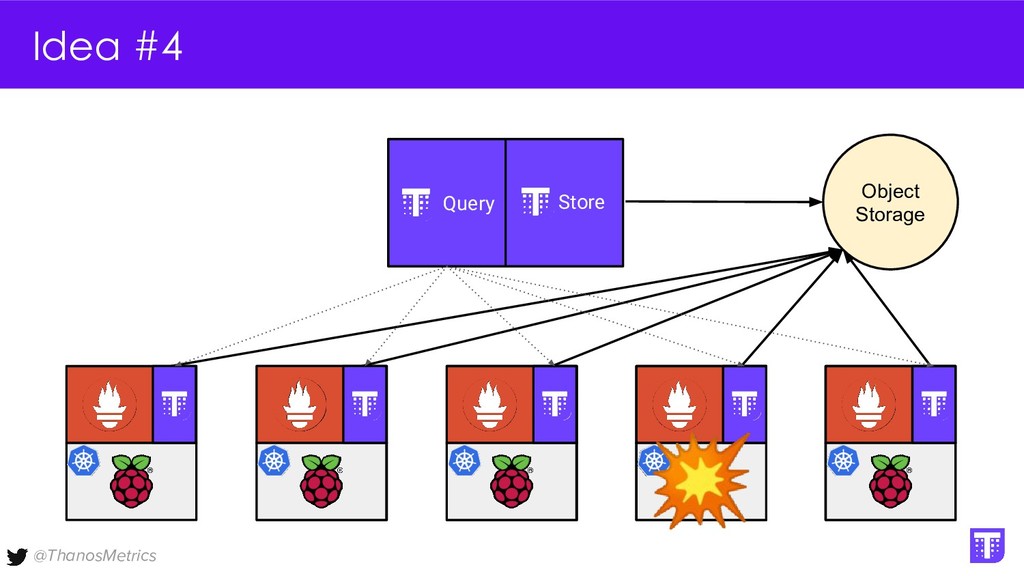
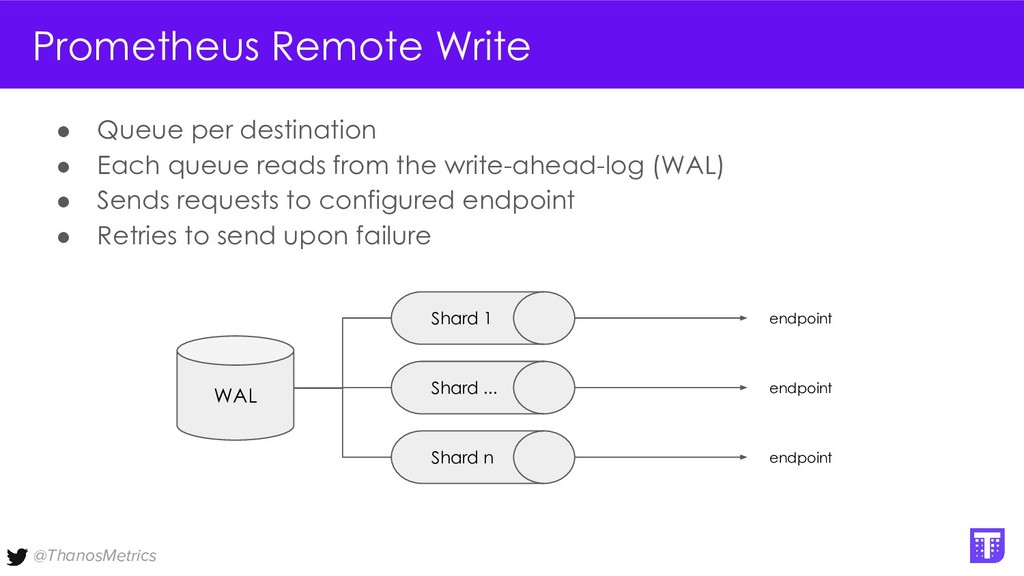
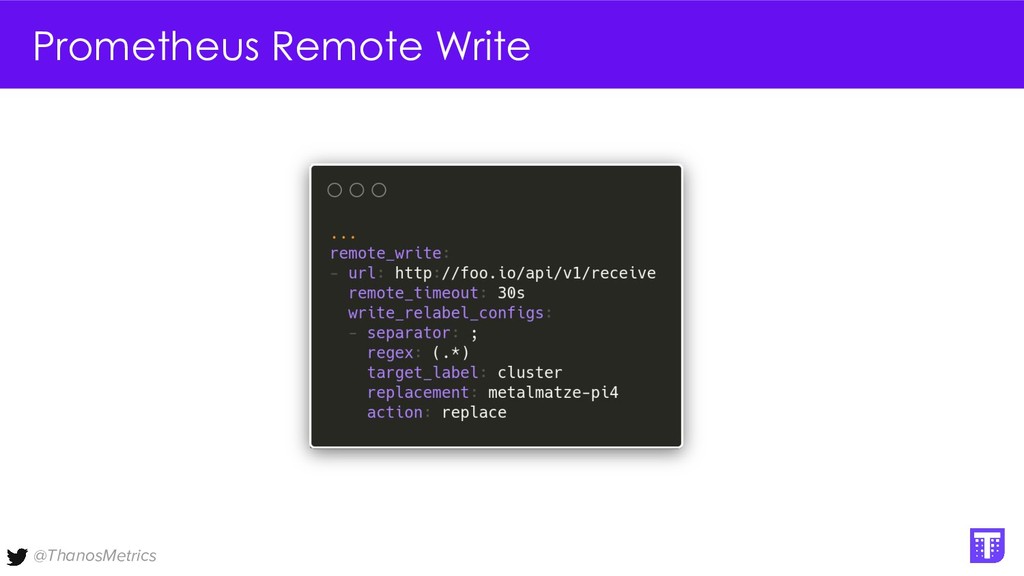
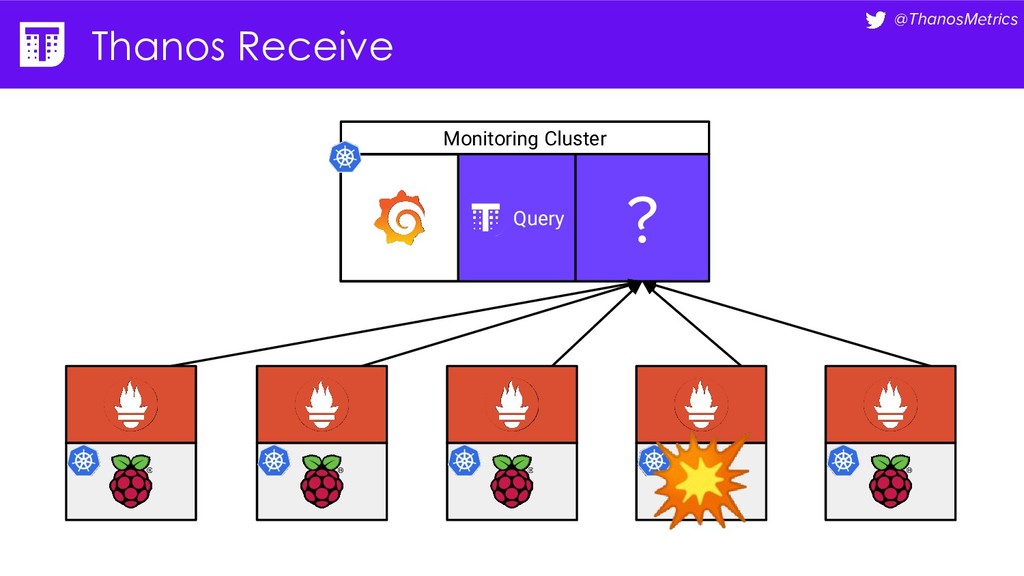
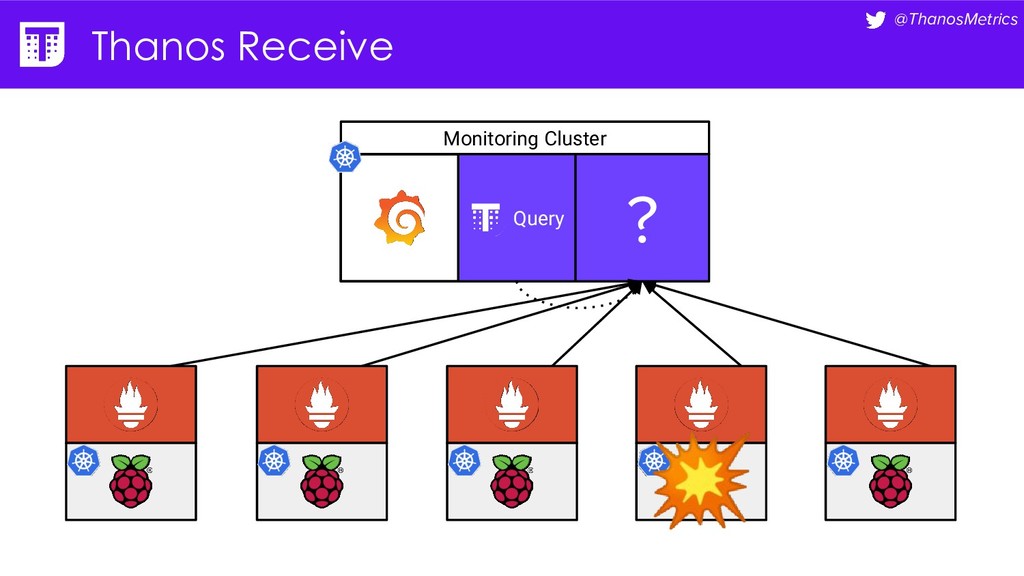
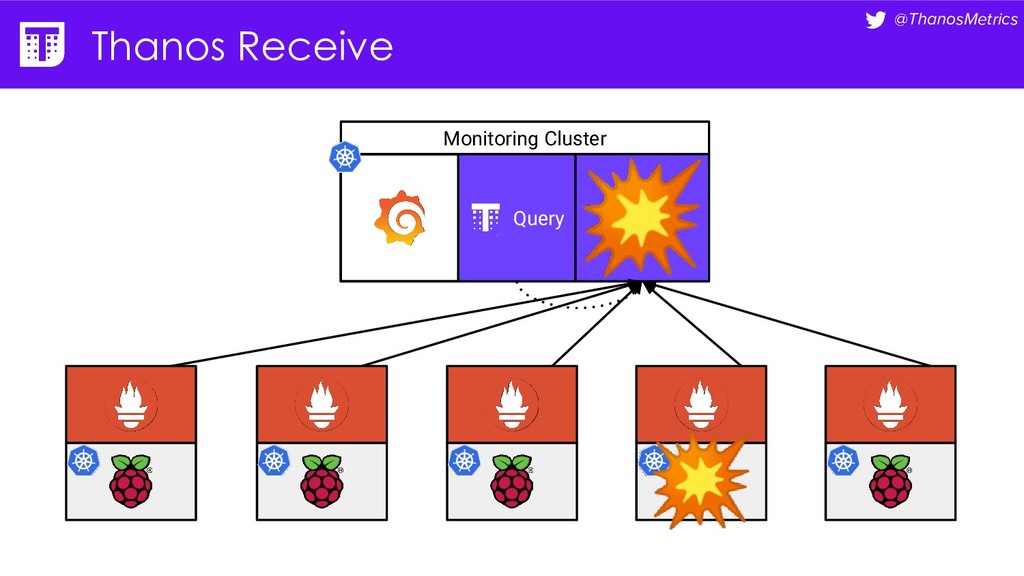
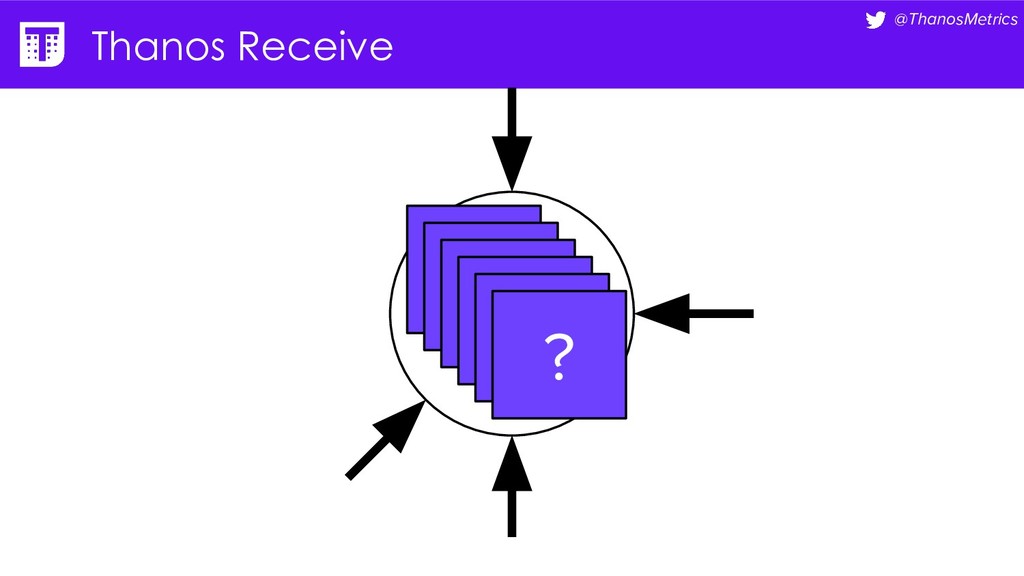
Computing is getting pushed to the edge, it may be your car, TV, washing machine, or your toaster. All these devices have a lot of computing power these days. While extending the cloud to the edge is getting solved with projects like KubeEdge or k3s, in this talk we want to take a closer look at how to run Prometheus on them. We want to configure Prometheus in a way that we can replicate its data to a central collecting point, that is running Thanos on Kubernetes in a replicated setup, and then make use of all the shipped metrics to efficiently query across the entire fleet.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
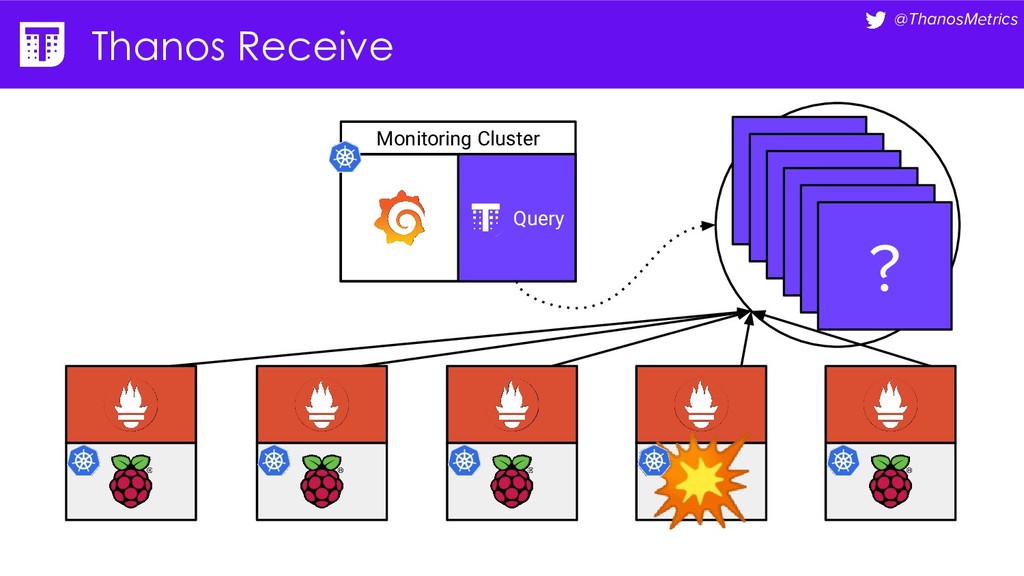{kind=link}
{kind=link}
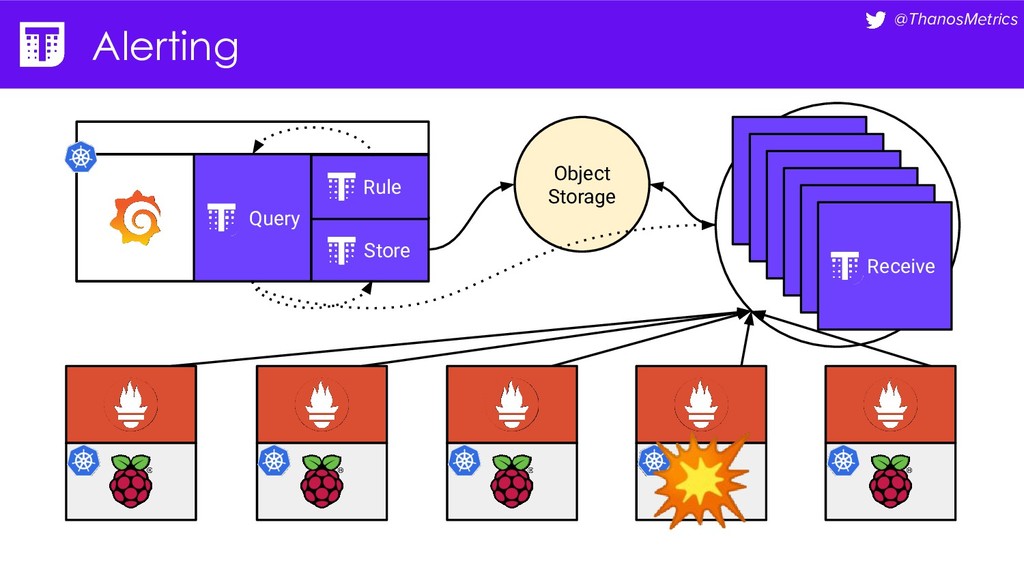{kind=link}
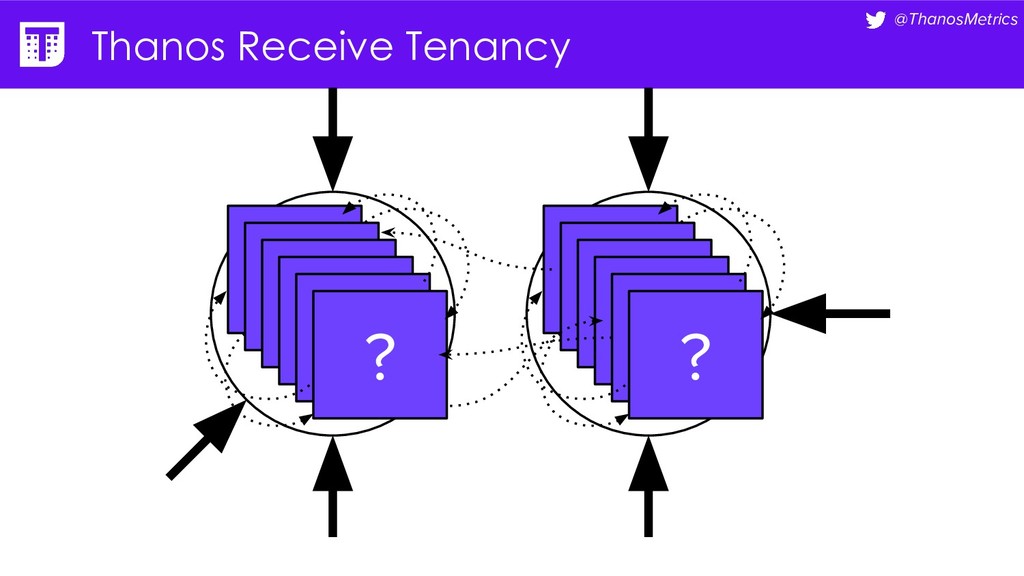{kind=link}
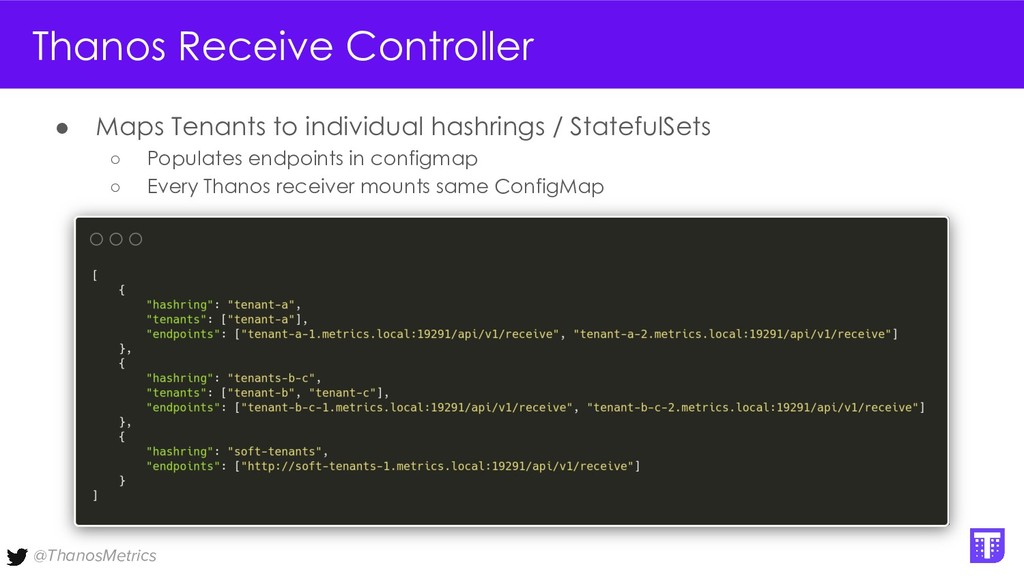{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}