Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Pythonスレッドとは結局何なのか? CPython実装から見るNoGIL時代の変化
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
curekoshimizu
September 25, 2025
Programming
3k
6
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Pythonスレッドとは結局何なのか? CPython実装から見るNoGIL時代の変化
curekoshimizu
September 25, 2025
More Decks by curekoshimizu
See All by curekoshimizu
Biz全員が Claude CLI を使い 可視化できるAI作業環境を共有する ~ BizTeamへ Ghostty・Herdr・共有AI基盤 の導入 ~
curekoshimizu
0
80
おしゃれ会社に入ったら CTOだけイケてなかった話
curekoshimizu
1
1.2k
AI時代を コンピュータ・アーキテクチャ視点で 取り組み 開発生産性をあげた話
curekoshimizu
1
140
[CTO of the YEAR 2025] すべてのECブランドに 最高の購入体験を届ける CTO 1年の挑戦の軌跡
curekoshimizu
0
440
会社を支える Pythonという言語戦略 ~なぜPythonを主要言語にしているのか?~
curekoshimizu
4
1.4k
未経験でSRE、はじめました! 組織を支える役割と軌跡
curekoshimizu
1
960
級数を大改造劇的ビフォーアフター
curekoshimizu
0
54
Pythonの数学機能を学ぼう! その仕組も学ぼう!
curekoshimizu
7
2.9k
Other Decks in Programming
See All in Programming
Augmenting AI with the Power of Jakarta EE
ivargrimstad
0
330
AIが無かった頃の素敵な出会いの話
codmoninc
1
300
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
180
ドリフトを絶対に許さない(?)CDK運用 / CDK Ops with Zero Tolerance for Drifts (?)
akihisaikeda
1
120
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
260
属人化した知識を、 AIが辿れる地図にする
pkshadeck
PRO
1
120
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
170
改善しないと、タスクが回らない。 “てんこ盛りポジション” を引き継いだ情シスの、入社3ヶ月の業務改善録
krm963
0
230
為什麼你並不需要ViewModel / No, you don't need a ViewModel
lovee
1
450
PostgreSQL 18で考えるUUID主キー
kazuhiro1982
0
440
数百円から始めるRuby電子工作
tarosay
0
120
20260722_microCMSで考える、AI時代のコンテンツ運用設計
yosh1
0
170
Featured
See All Featured
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
430
The Invisible Side of Design
smashingmag
301
52k
Writing Fast Ruby
sferik
630
63k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
420
Tell your own story through comics
letsgokoyo
1
1k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.2k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Designing for Timeless Needs
cassininazir
1
420
Transcript
Pythonスレッドとは結局何なのか? CPython実装から見るNoGIL時代の変化 PyCon JP 2025.9.26 (DAY1) 12:00 - 12:30 Recustomer株式会社
CTO Shugo Manabe @curekoshimizu
Profile : 眞鍋 秀悟 ( X: @curekoshimizu ) 略歴 •
京都大学 / 大学院 ◦ 入試一位合格 ◦ 数学系 (高速な計算方法を専門) [今回のお話と少し関係が深い] • Fixstars ◦ Executive Engineer • Mujin ◦ Architect • Preferred Networks ◦ Engineering Mananger • Hacobu ◦ 研究開発部部長・CTO室室長 • want.jp ◦ VPoP • [Now] Recustomer ◦ CTO かなり長い間 Pythonを 業務で使ってきた 2 昨年は 「四則演算のCPythonでの内部実装」 という話を PyCon JP 2024 で発表させていただきました。
Thread 3
人々を魅了し 高速化する技術 4
そんなThreadに 衝撃ニュースが 5
Python3.13の衝撃 6
GIL無効化できます! (ただし実験的機能) 7
Python3.14では さらに 8
実験モードから昇格して GIL無効化 公式サポート化 (ただし規定ビルドは従来どおり) 9
つまりは NoGIL (GIL無効化) というキーワードを Python界隈を騒がせました 10
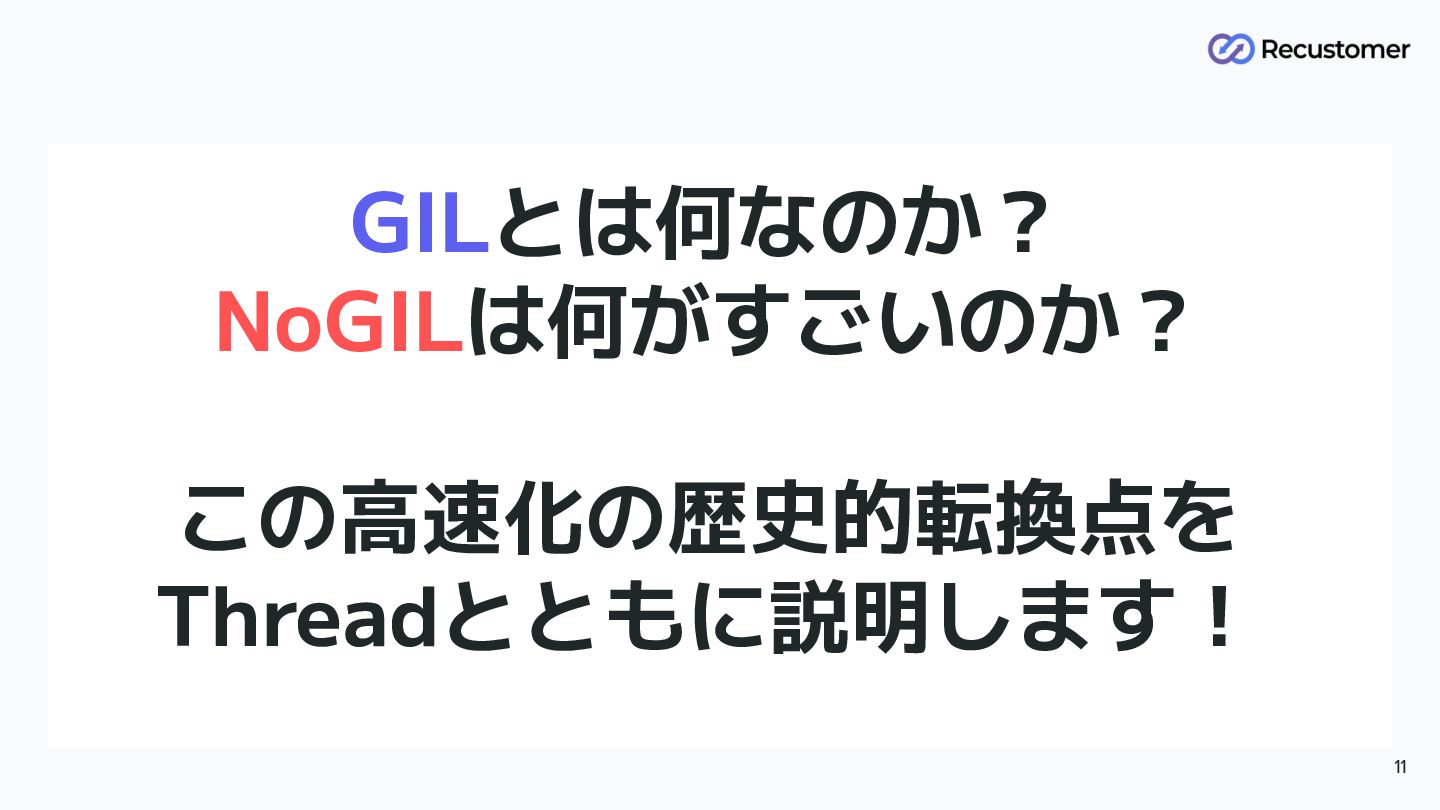
GILとは何なのか? NoGILは何がすごいのか? この高速化の歴史的転換点を Threadとともに説明します! 11
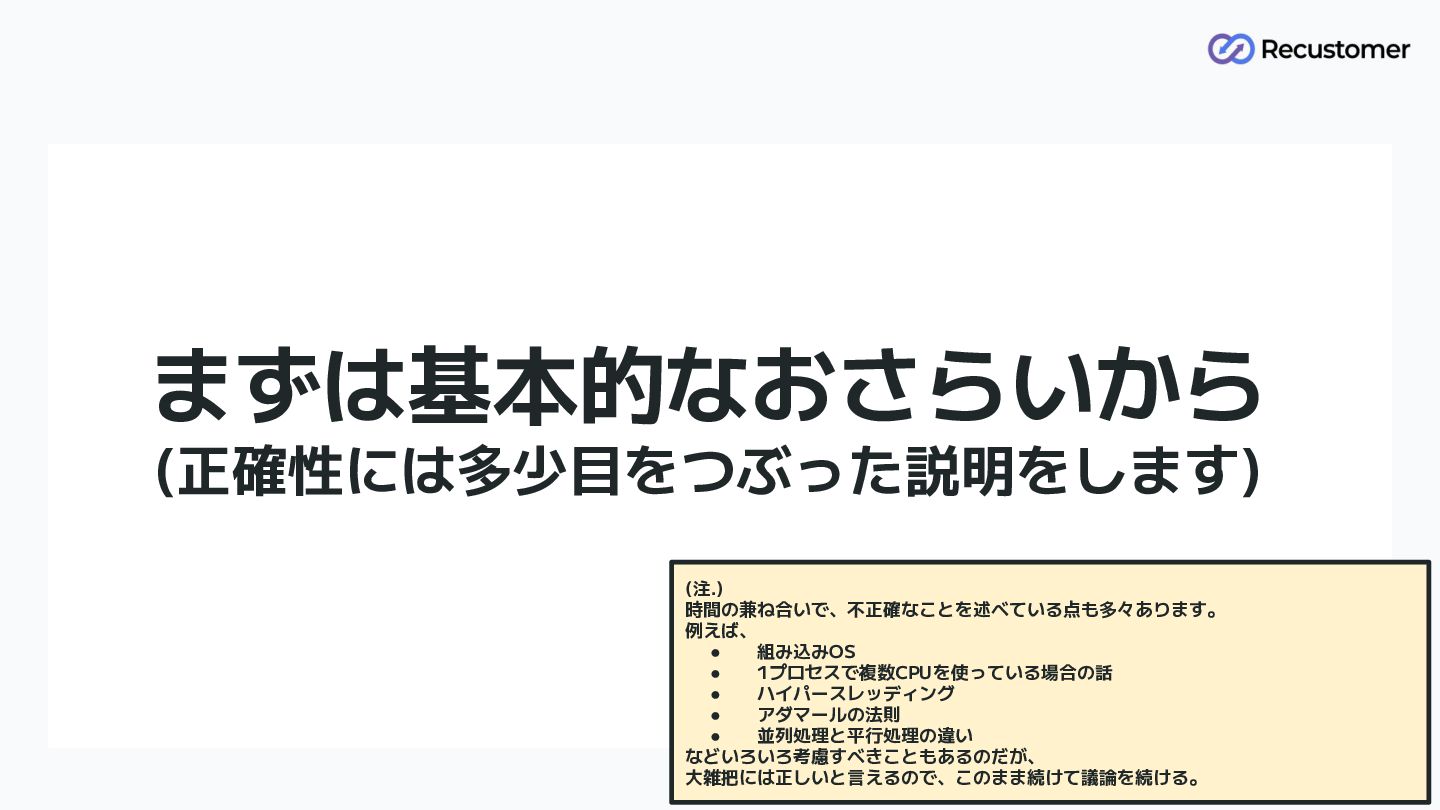
まずは基本的なおさらいから (正確性には多少目をつぶった説明をします) 12 (注.) 時間の兼ね合いで、不正確なことを述べている点も多々あります。 例えば、 • 組み込みOS • 1プロセスで複数CPUを使っている場合の話
• ハイパースレッディング • アダマールの法則 • 並列処理と平行処理の違い などいろいろ考慮すべきこともあるのだが、 大雑把には正しいと言えるので、このまま続けて議論を続ける。
逐次処理 - 並列ではなく、処理が終わったら次の処理をする 13 処理A 処理B 処理C 処理D 時間
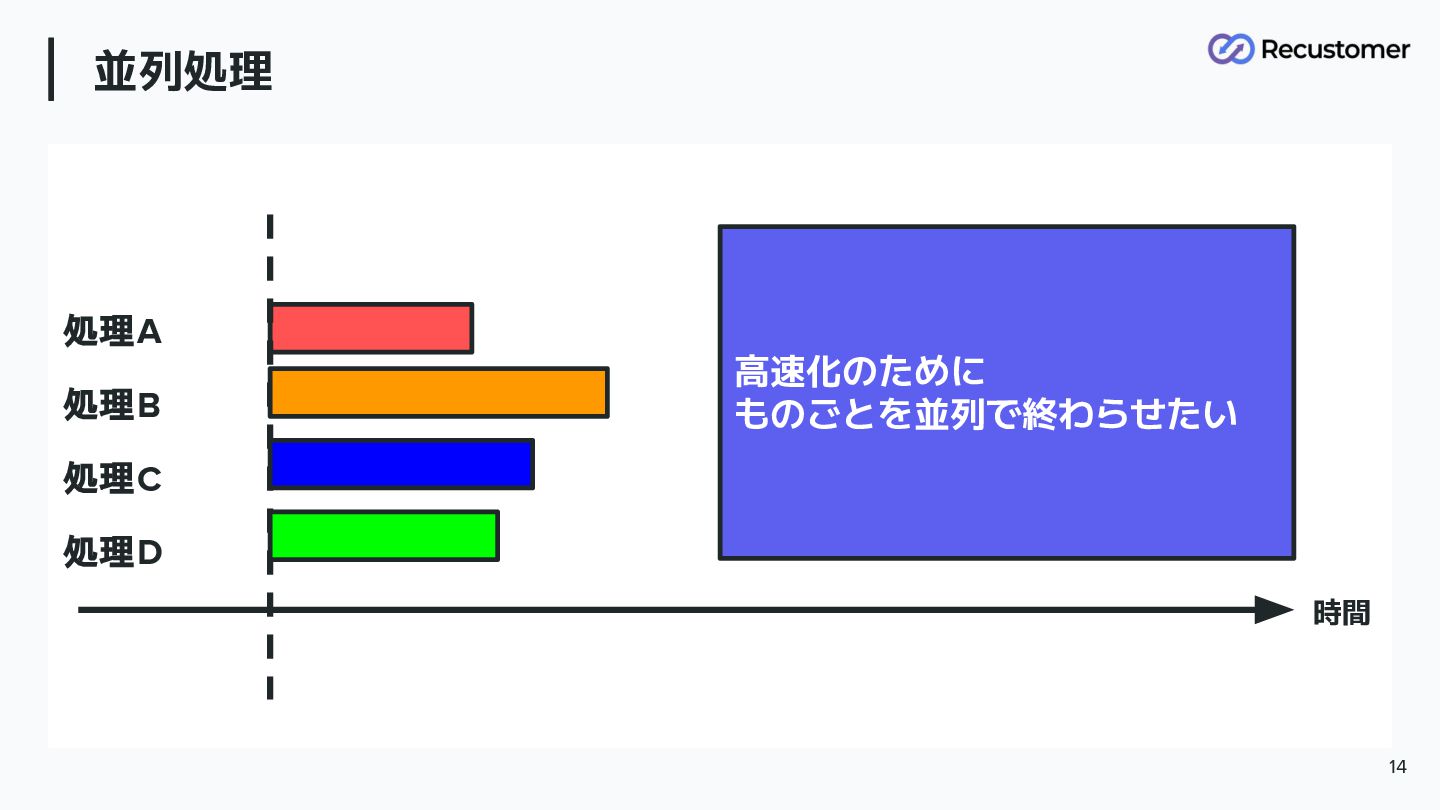
並列処理 14 時間 高速化のために ものごとを並列で終わらせたい 処理A 処理B 処理C 処理D
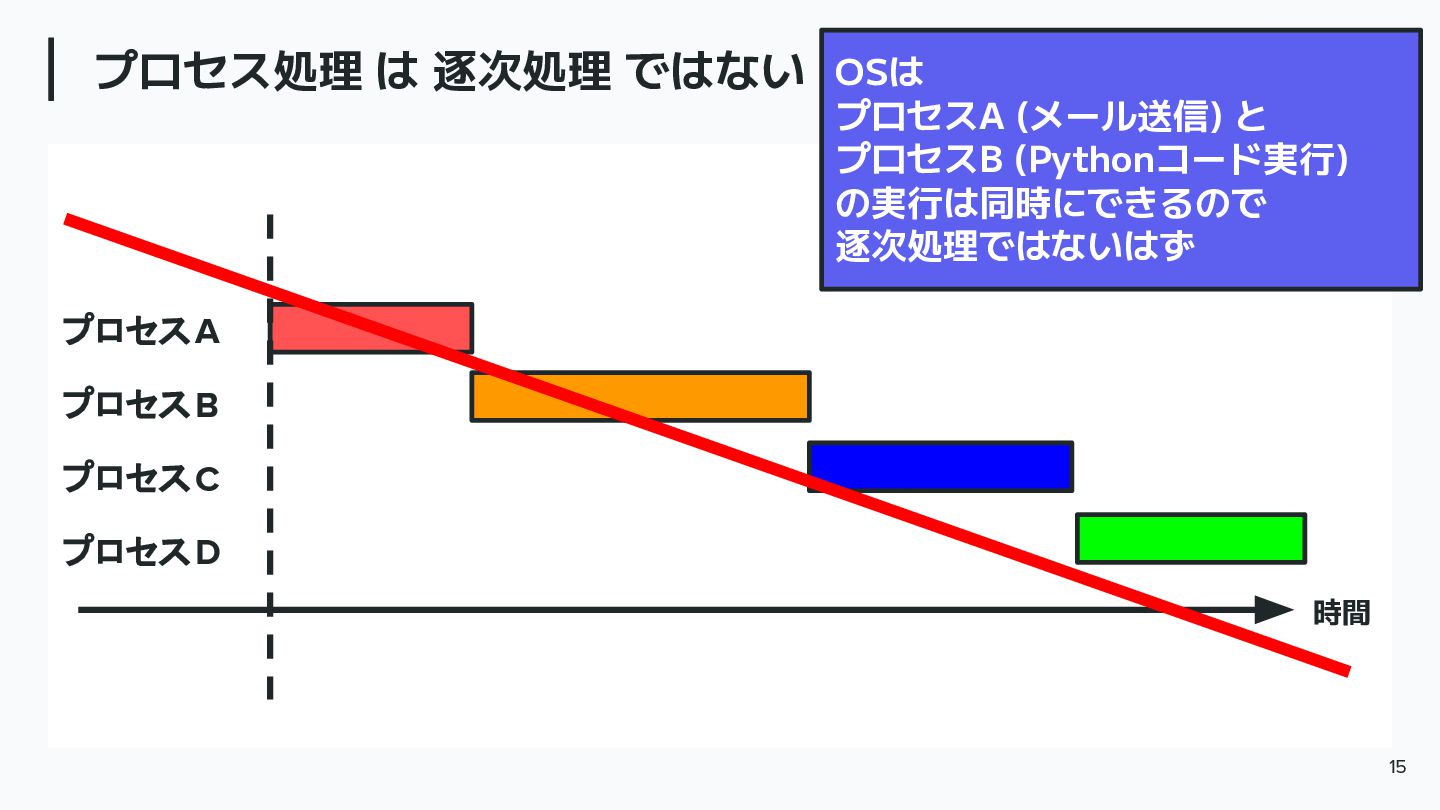
プロセス処理 は 逐次処理 ではない 15 時間 OSは プロセスA (メール送信) と
プロセスB (Pythonコード実行) の実行は同時にできるので 逐次処理ではないはず プロセスA プロセスB プロセスC プロセスD
プロセス と 並列処理 16 時間 メールを送りながらも Pythonのコード実行は同時に できているはずなので この動きが正しそう プロセスA
プロセスB プロセスC プロセスD
プロセスには「計算」という CPUを利用する では、1CPUしかなかったら? 17
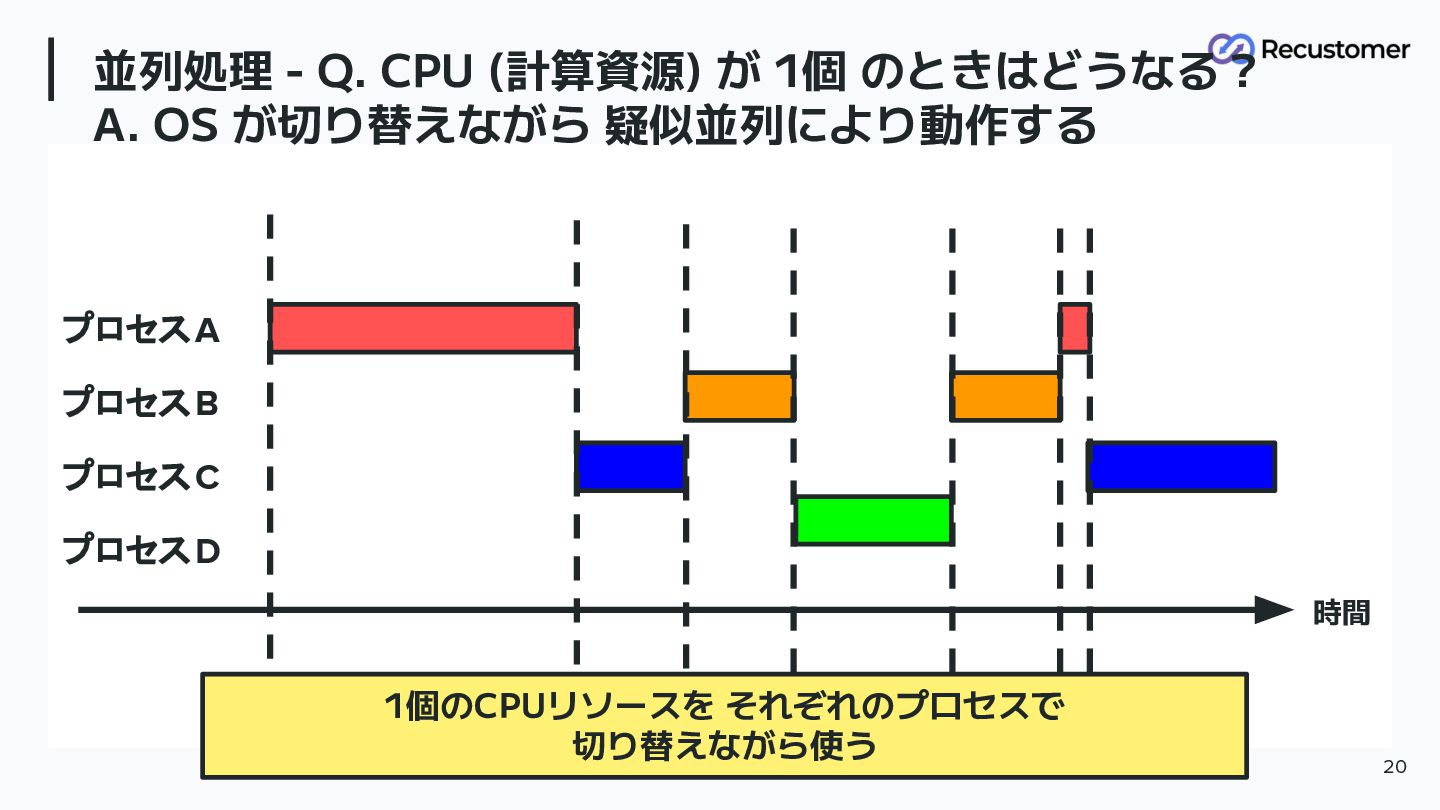
並列処理 - Q. CPU (計算資源) が 1個 のときはどうなる? 18 時間
メールを送りながらも Pythonのコード実行は同時に できているはずなので こうなっていそう プロセスA プロセスB プロセスC プロセスD
OSが 処理を切り替えながら (ディスパッチしながら) 並列処理をしているように みせている 19
並列処理 - Q. CPU (計算資源) が 1個 のときはどうなる? A. OS
が切り替えながら 疑似並列により動作する 20 プロセスA プロセスB プロセスC プロセスD 時間 1個のCPUリソースを それぞれのプロセスで 切り替えながら使う
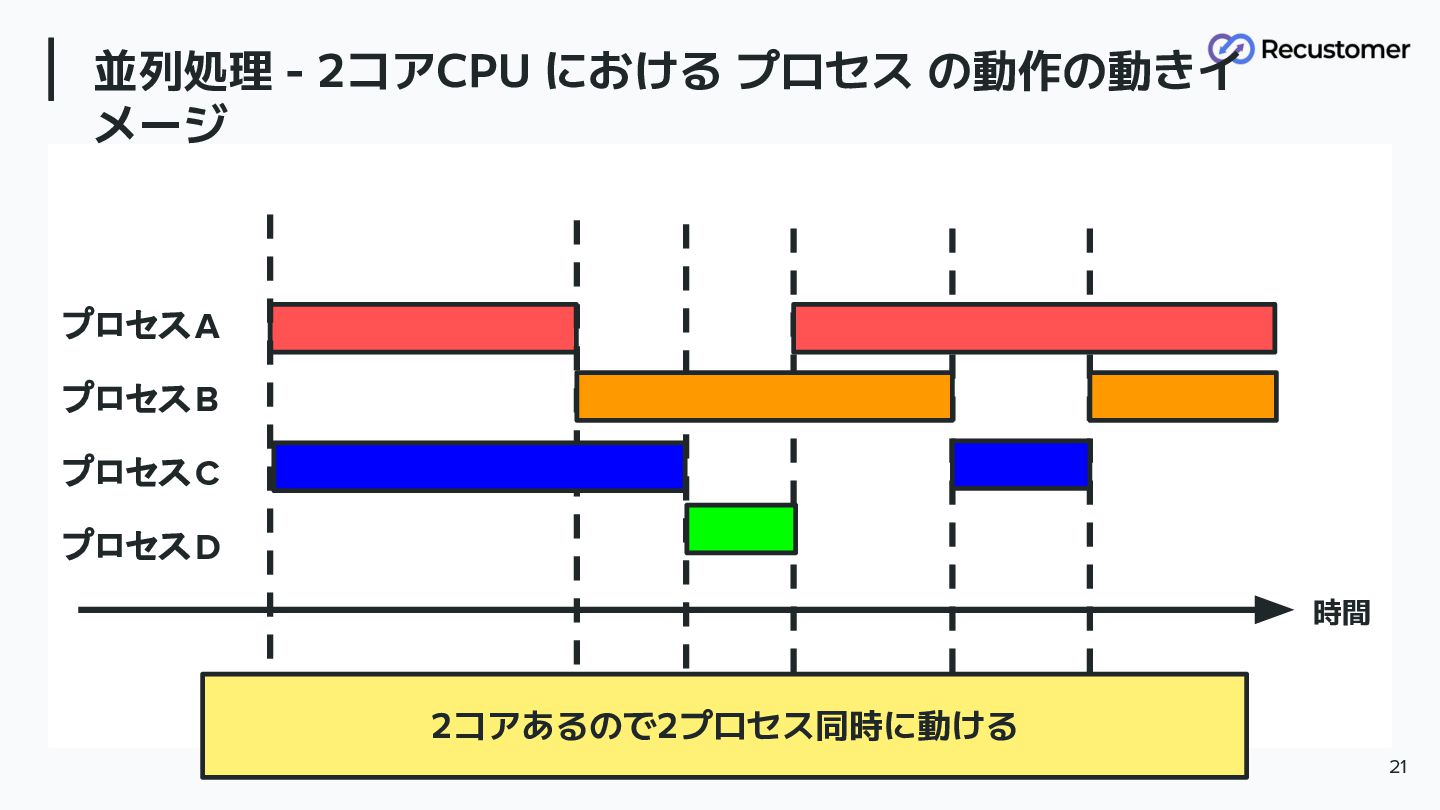
並列処理 - 2コアCPU における プロセス の動作の動きイ メージ 21 プロセスA プロセスB
プロセスC プロセスD 時間 2コアあるので2プロセス同時に動ける
並列処理 - 複数コアにおけるプロセスの動作イメージ 22 プロセスA プロセスB プロセスC プロセスD 時間 それぞれのプロセスがそれぞれの
CPUコアが割り当てられて 並列に計算できる!
プロセスと並列についてざっくりまとめ • プロセスは OS によって管理される • OS によっていい感じに、切り替えられながら並列処理されているように動作でき る •
CPU コアという計算資源があれば、実際並列度が高まる 23 (注.) 時間の兼ね合いで、不正確なことを述べている点も多々あります。 例えば、 • 組み込みOS • 1プロセスで複数CPUを使っている場合の話 • ハイパースレッディング • アダマールの法則 • 並列処理と平行処理の違い などいろいろ考慮すべきこともあるのだが、 大雑把には正しいと言えるので、このまま続けて議論を続ける。
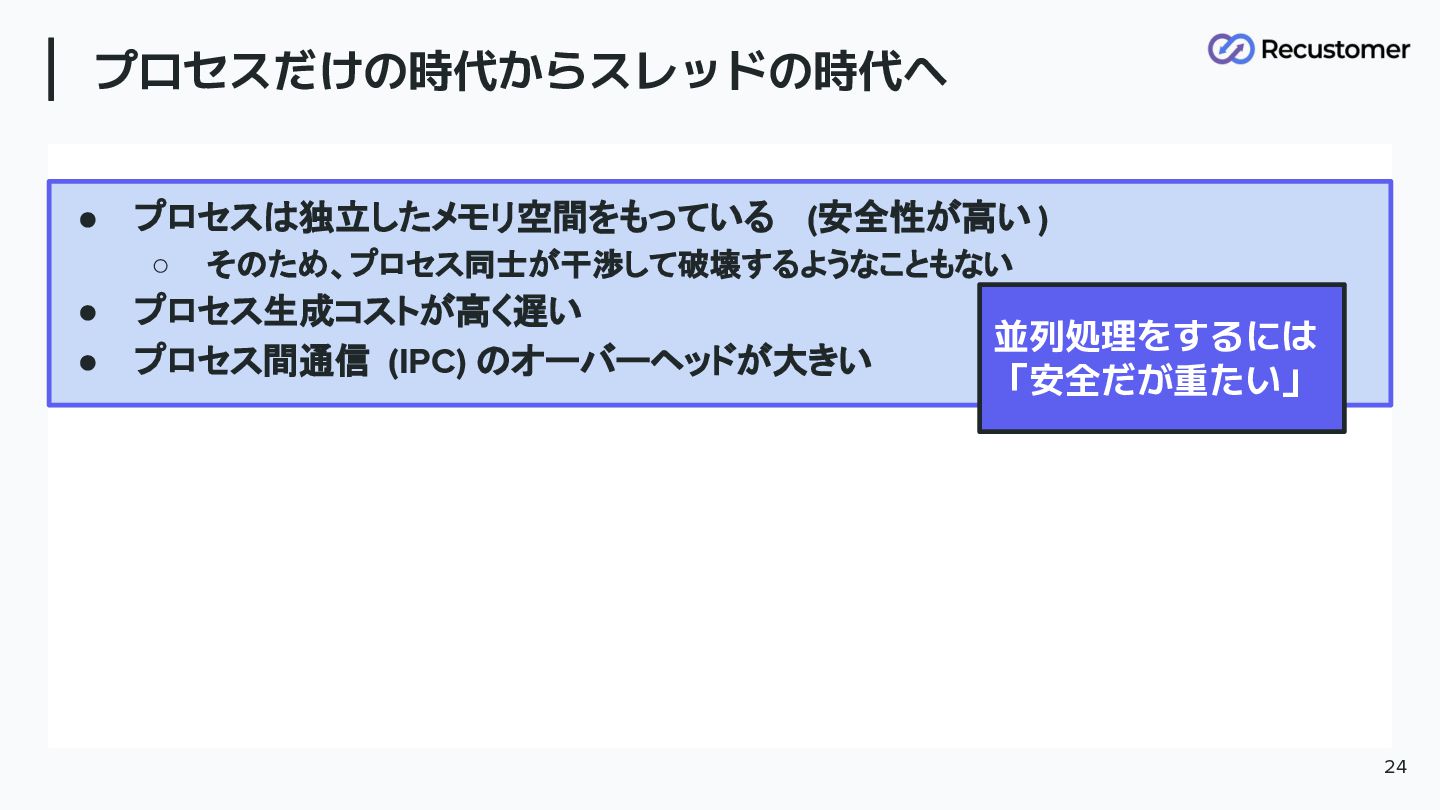
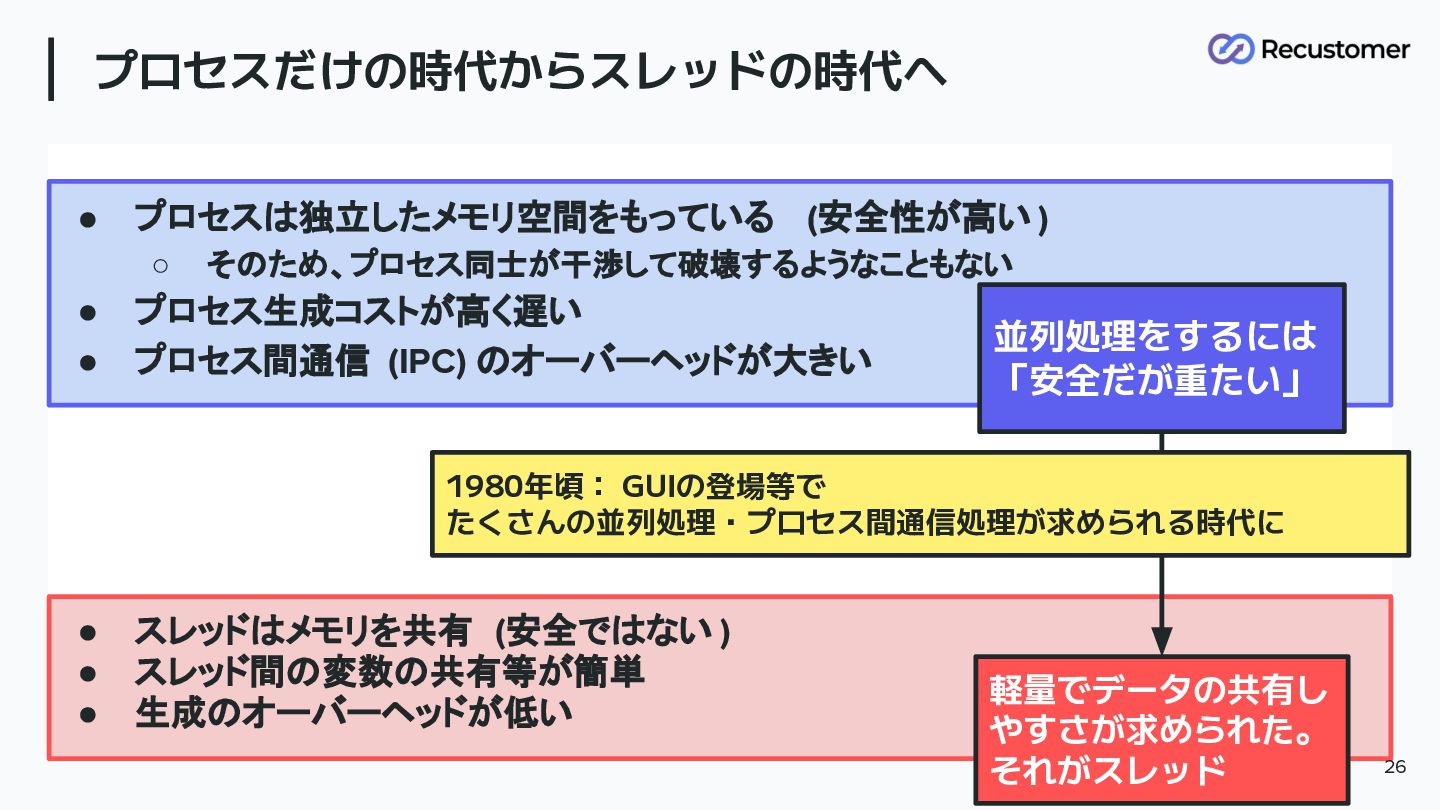
プロセスだけの時代からスレッドの時代へ • プロセスは独立したメモリ空間をもっている (安全性が高い ) ◦ そのため、プロセス同士が干渉して破壊するようなこともない • プロセス生成コストが高く遅い •
プロセス間通信 (IPC) のオーバーヘッドが大きい 24 並列処理をするには 「安全だが重たい」
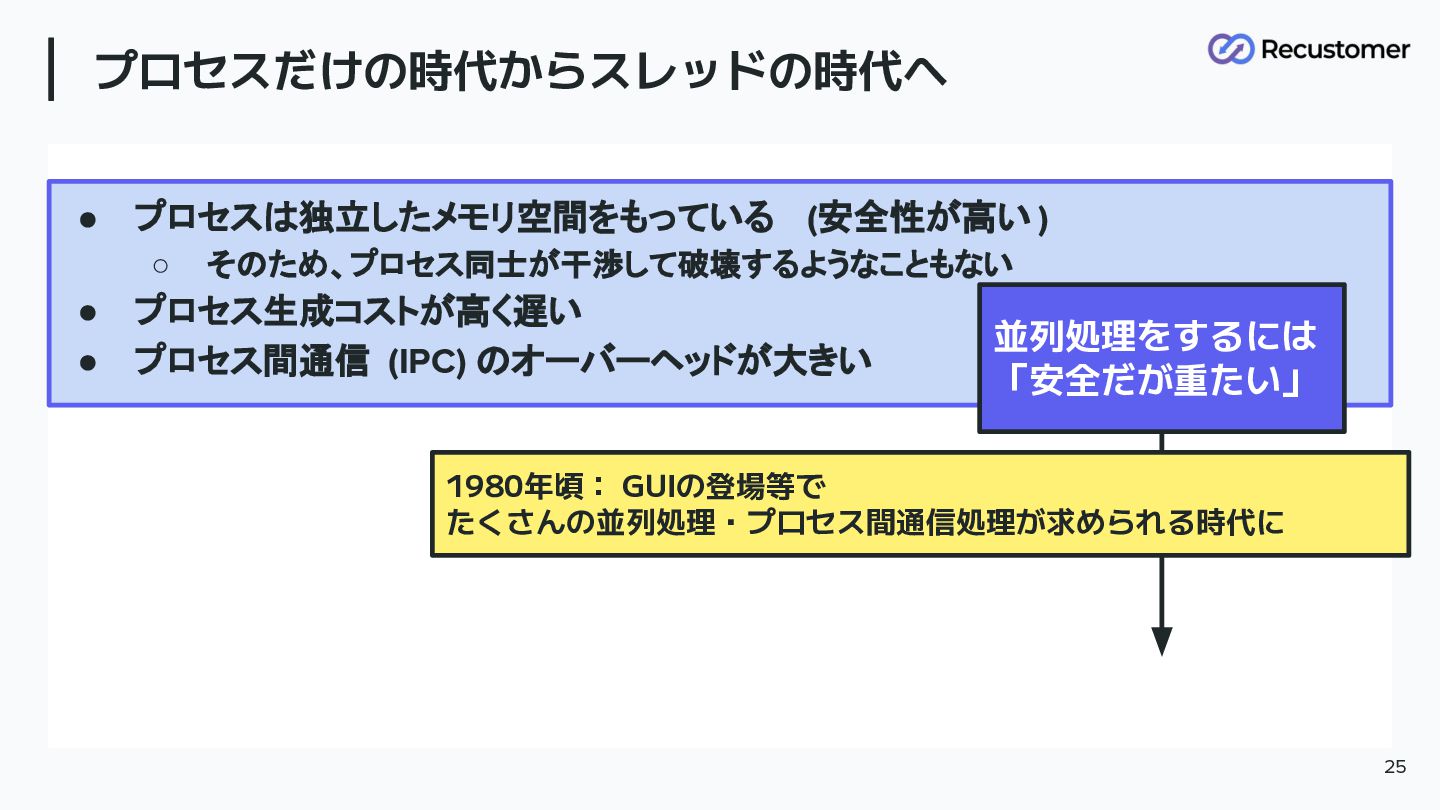
プロセスだけの時代からスレッドの時代へ • プロセスは独立したメモリ空間をもっている (安全性が高い ) ◦ そのため、プロセス同士が干渉して破壊するようなこともない • プロセス生成コストが高く遅い •
プロセス間通信 (IPC) のオーバーヘッドが大きい 25 並列処理をするには 「安全だが重たい」 1980年頃: GUIの登場等で たくさんの並列処理・プロセス間通信処理が求められる時代に
• スレッドはメモリを共有 (安全ではない ) • スレッド間の変数の共有等が簡単 • 生成のオーバーヘッドが低い プロセスだけの時代からスレッドの時代へ •
プロセスは独立したメモリ空間をもっている (安全性が高い ) ◦ そのため、プロセス同士が干渉して破壊するようなこともない • プロセス生成コストが高く遅い • プロセス間通信 (IPC) のオーバーヘッドが大きい 26 並列処理をするには 「安全だが重たい」 軽量でデータの共有し やすさが求められた。 それがスレッド 1980年頃: GUIの登場等で たくさんの並列処理・プロセス間通信処理が求められる時代に
プロセスだけの時代からスレッドの時代の流れ 27 プロセス だけの 時代
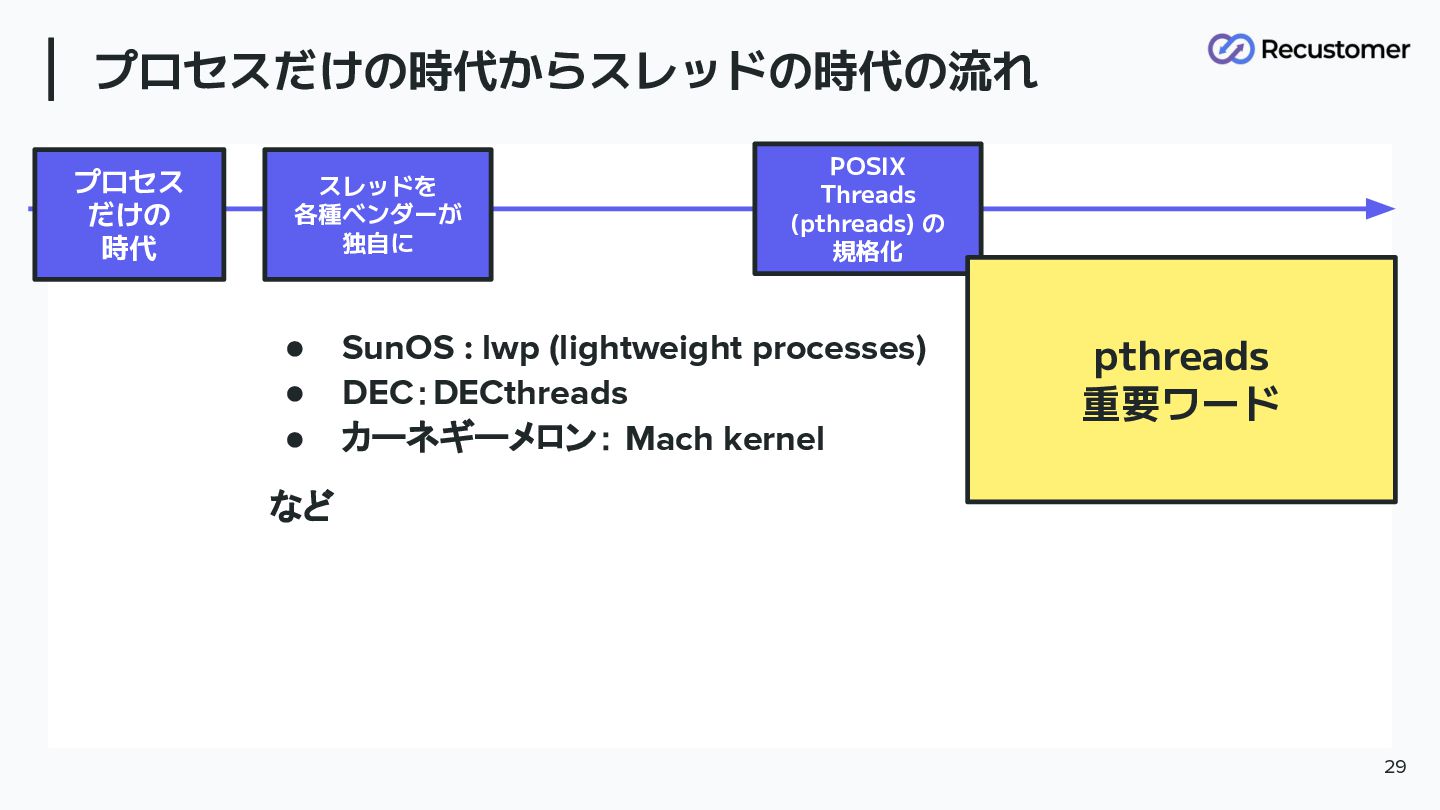
プロセスだけの時代からスレッドの時代の流れ 28 プロセス だけの 時代 スレッドを 各種ベンダーが 独自に • SunOS
: lwp (lightweight processes) • DEC:DECthreads • カーネギーメロン: Mach kernel など
プロセスだけの時代からスレッドの時代の流れ 29 プロセス だけの 時代 スレッドを 各種ベンダーが 独自に POSIX Threads
(pthreads) の 規格化 • SunOS : lwp (lightweight processes) • DEC:DECthreads • カーネギーメロン: Mach kernel など pthreads 重要ワード
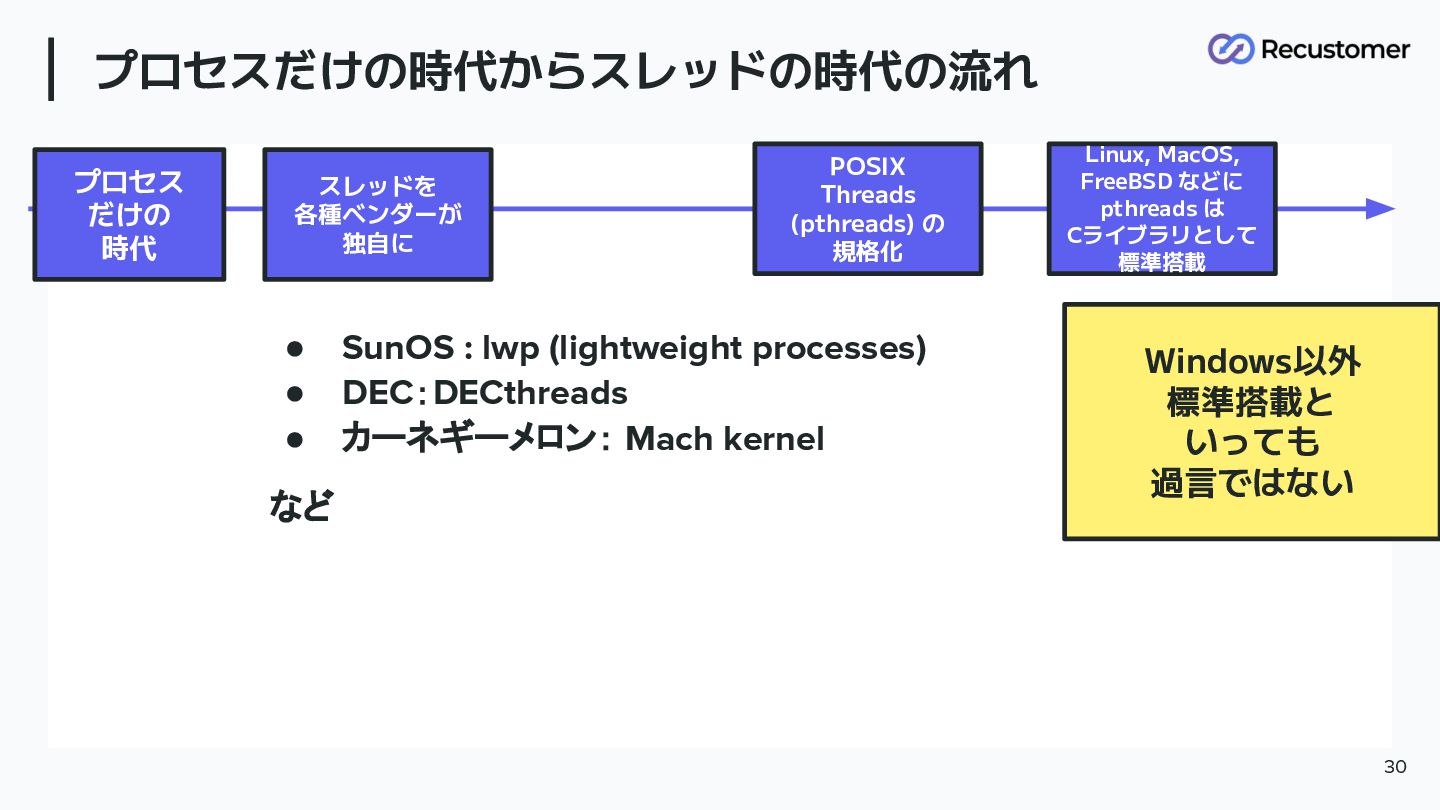
プロセスだけの時代からスレッドの時代の流れ 30 プロセス だけの 時代 スレッドを 各種ベンダーが 独自に POSIX Threads
(pthreads) の 規格化 • SunOS : lwp (lightweight processes) • DEC:DECthreads • カーネギーメロン: Mach kernel など Linux, MacOS, FreeBSD などに pthreads は Cライブラリとして 標準搭載 Windows以外 標準搭載と いっても 過言ではない
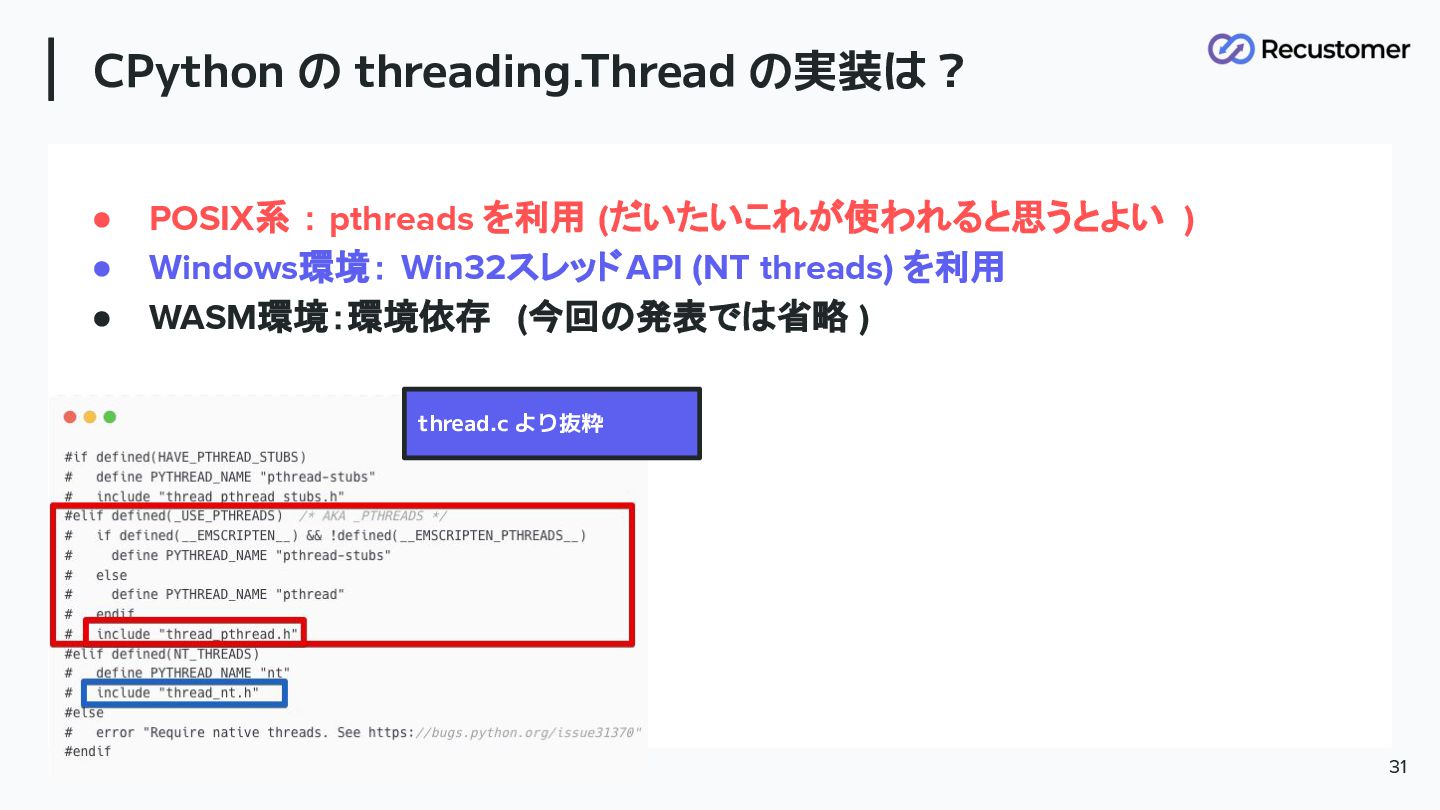
CPython の threading.Thread の実装は? 31 • POSIX系 : pthreads を利用
(だいたいこれが使われると思うとよい ) • Windows環境: Win32スレッドAPI (NT threads) を利用 • WASM環境:環境依存 (今回の発表では省略 ) thread.c より抜粋
CPython の threading.Thread の実装は? 32 from threading import Thread thread
= Thread(target=worker) thread.start() このシンプルなコードで 一体何が起こっているのか CPython本体の 実装を見ていきましょう
CPython の threading.Thread の実装は? 33 from threading import Thread thread
= Thread(target=worker) thread.start() このシンプルなコードで 一体何が起こっているのか CPython本体の 実装を見ていきましょう
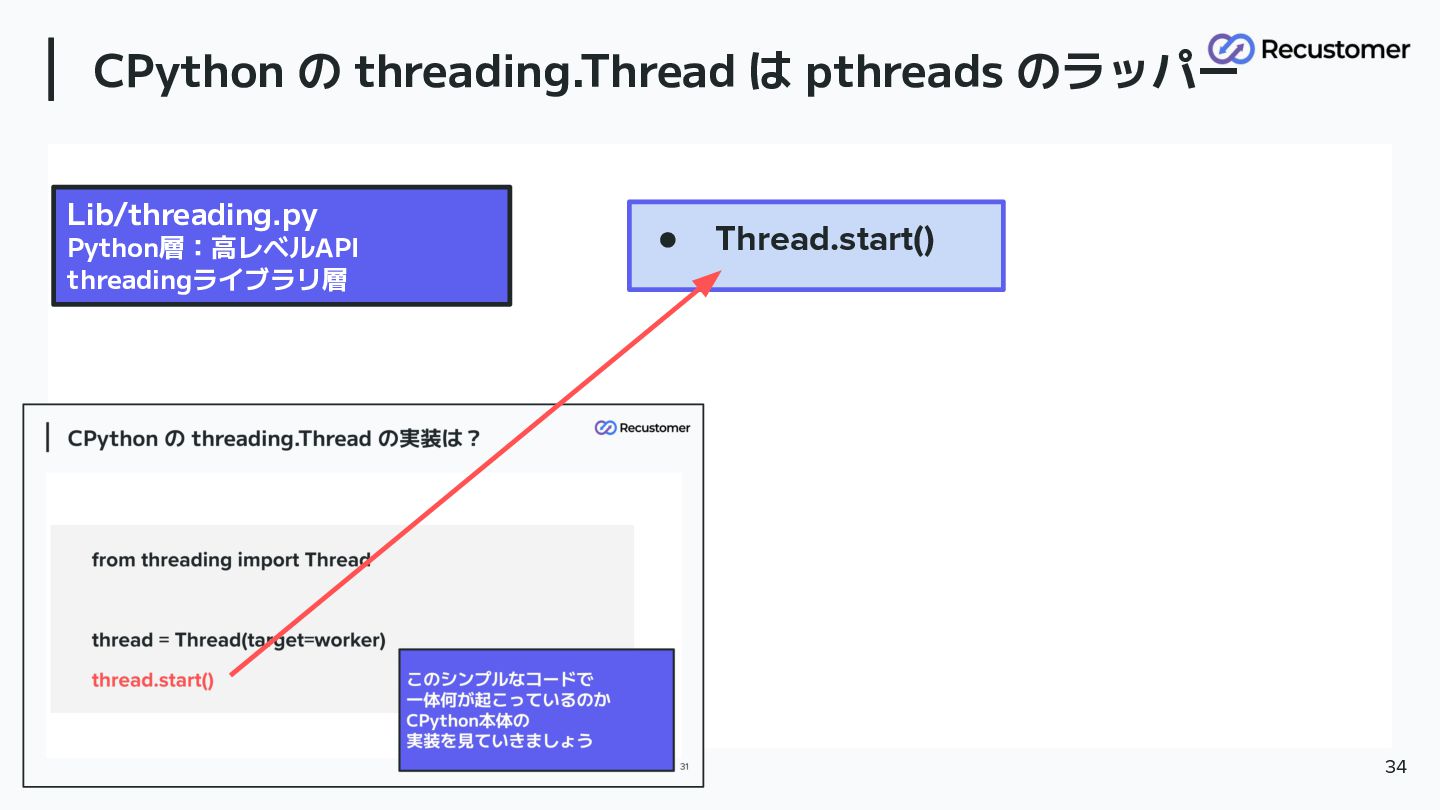
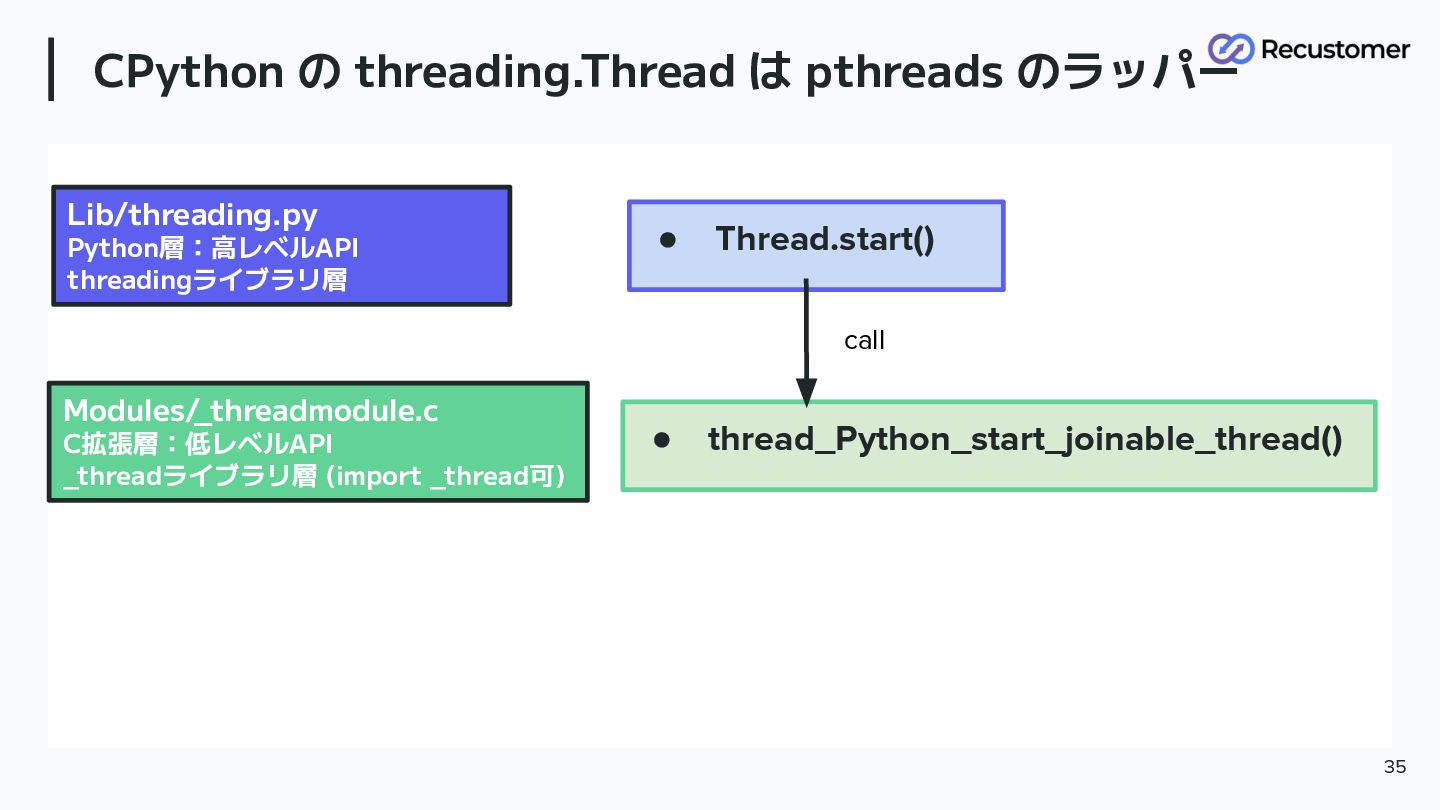
CPython の threading.Thread は pthreads のラッパー 34 • Thread.start() Lib/threading.py
Python層:高レベルAPI threadingライブラリ層
CPython の threading.Thread は pthreads のラッパー 35 • Thread.start() Lib/threading.py
Python層:高レベルAPI threadingライブラリ層 • thread_Python_start_joinable_thread() Modules/ _threadmodule.c C拡張層:低レベルAPI _threadライブラリ層 (import _thread可) call
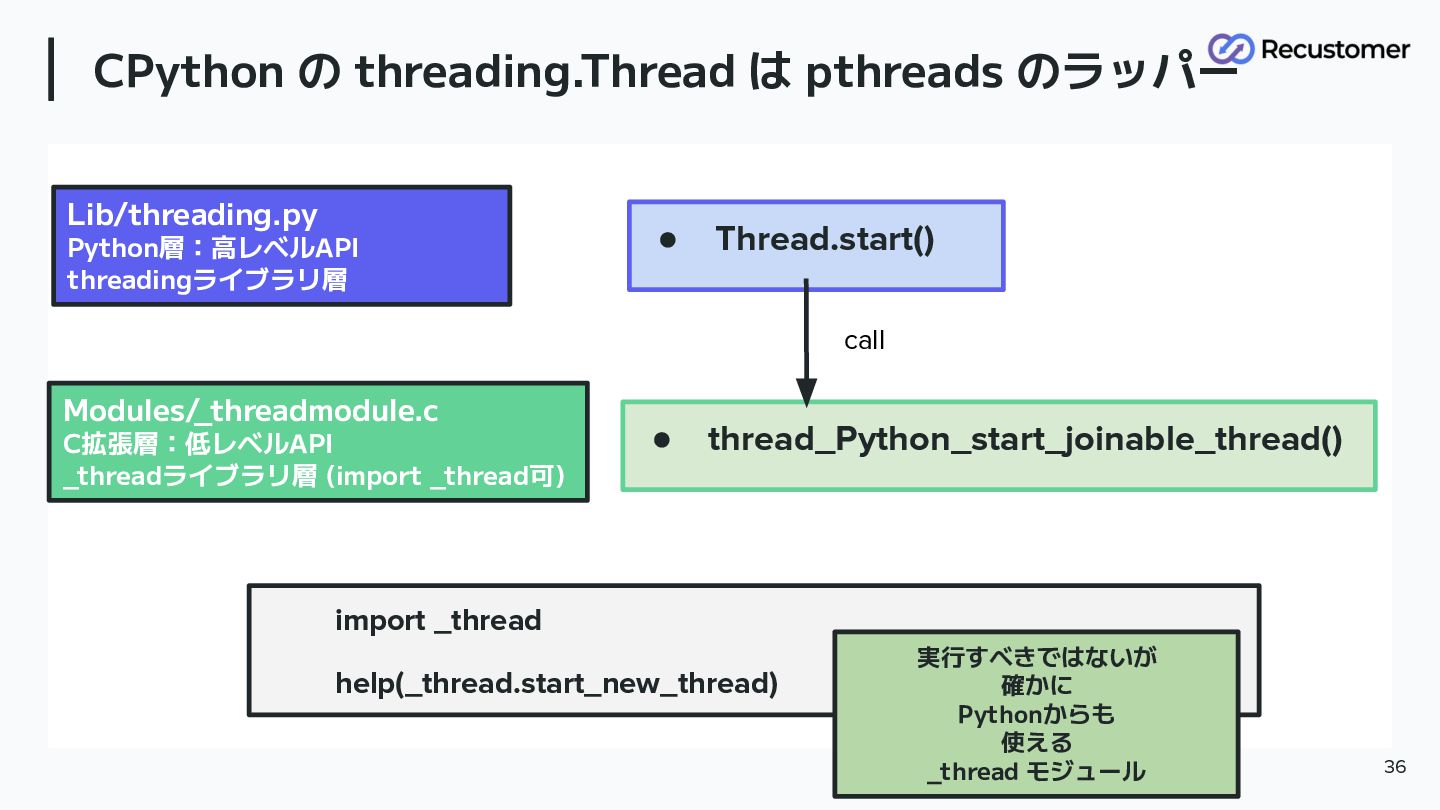
CPython の threading.Thread は pthreads のラッパー 36 • Thread.start() Lib/threading.py
Python層:高レベルAPI threadingライブラリ層 • thread_Python_start_joinable_thread() Modules/ _threadmodule.c C拡張層:低レベルAPI _threadライブラリ層 (import _thread可) call import _thread help(_thread.start_new_thread) 実行すべきではないが 確かに Pythonからも 使える _thread モジュール
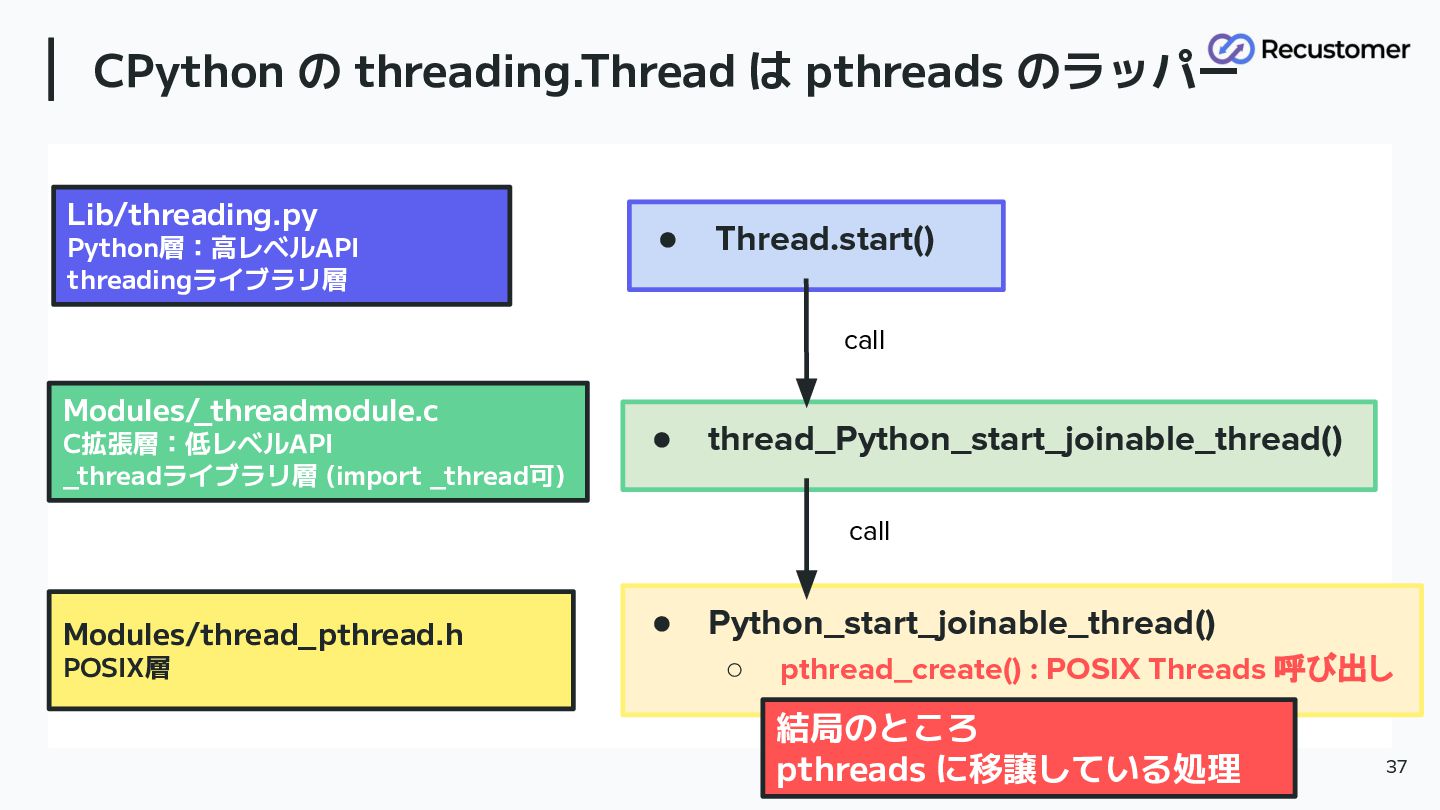
CPython の threading.Thread は pthreads のラッパー 37 • Thread.start() Lib/threading.py
Python層:高レベルAPI threadingライブラリ層 • thread_Python_start_joinable_thread() Modules/ _threadmodule.c C拡張層:低レベルAPI _threadライブラリ層 (import _thread可) • Python_start_joinable_thread() ◦ pthread_create() : POSIX Threads 呼び出し Modules/thread_pthread.h POSIX層 結局のところ pthreads に移譲している処理 call call
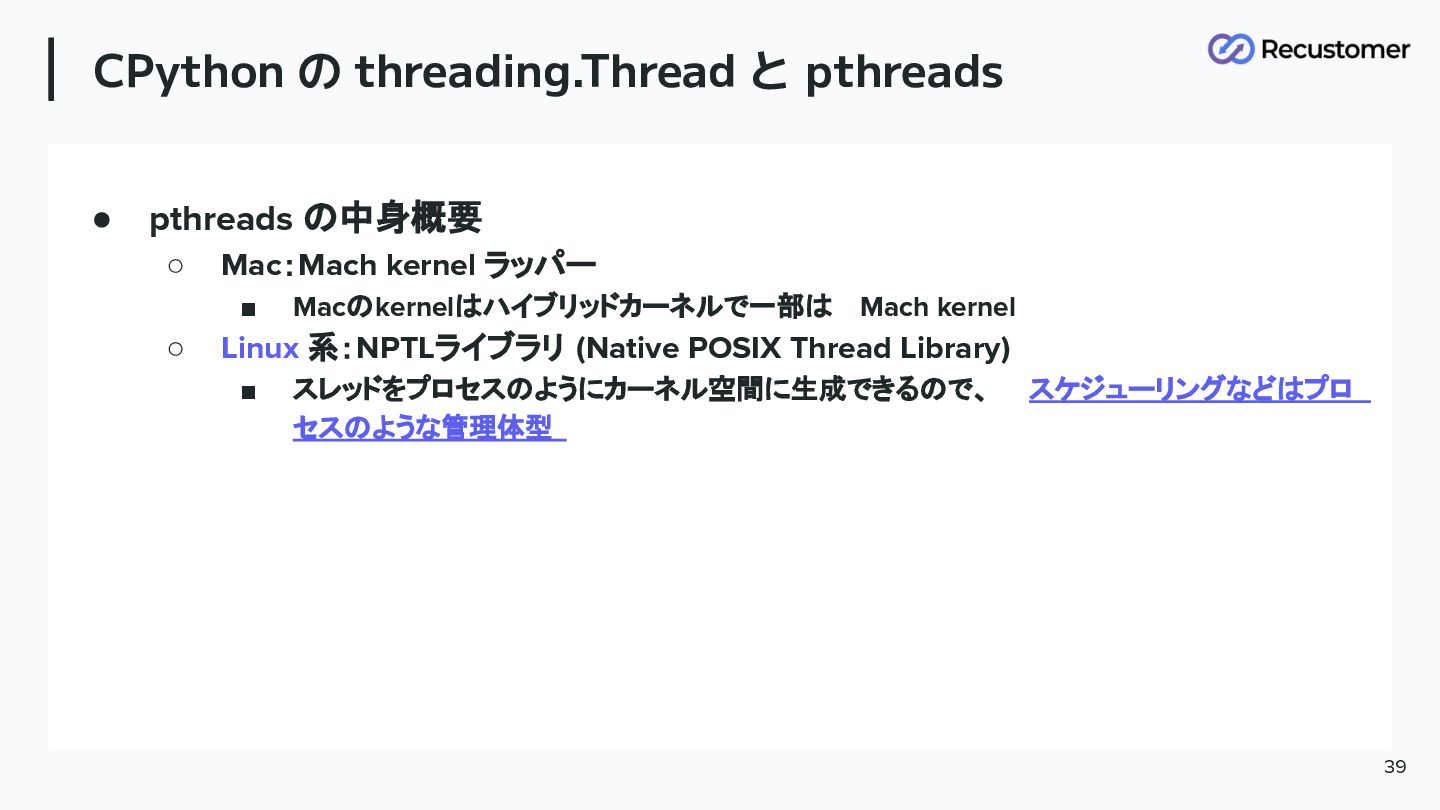
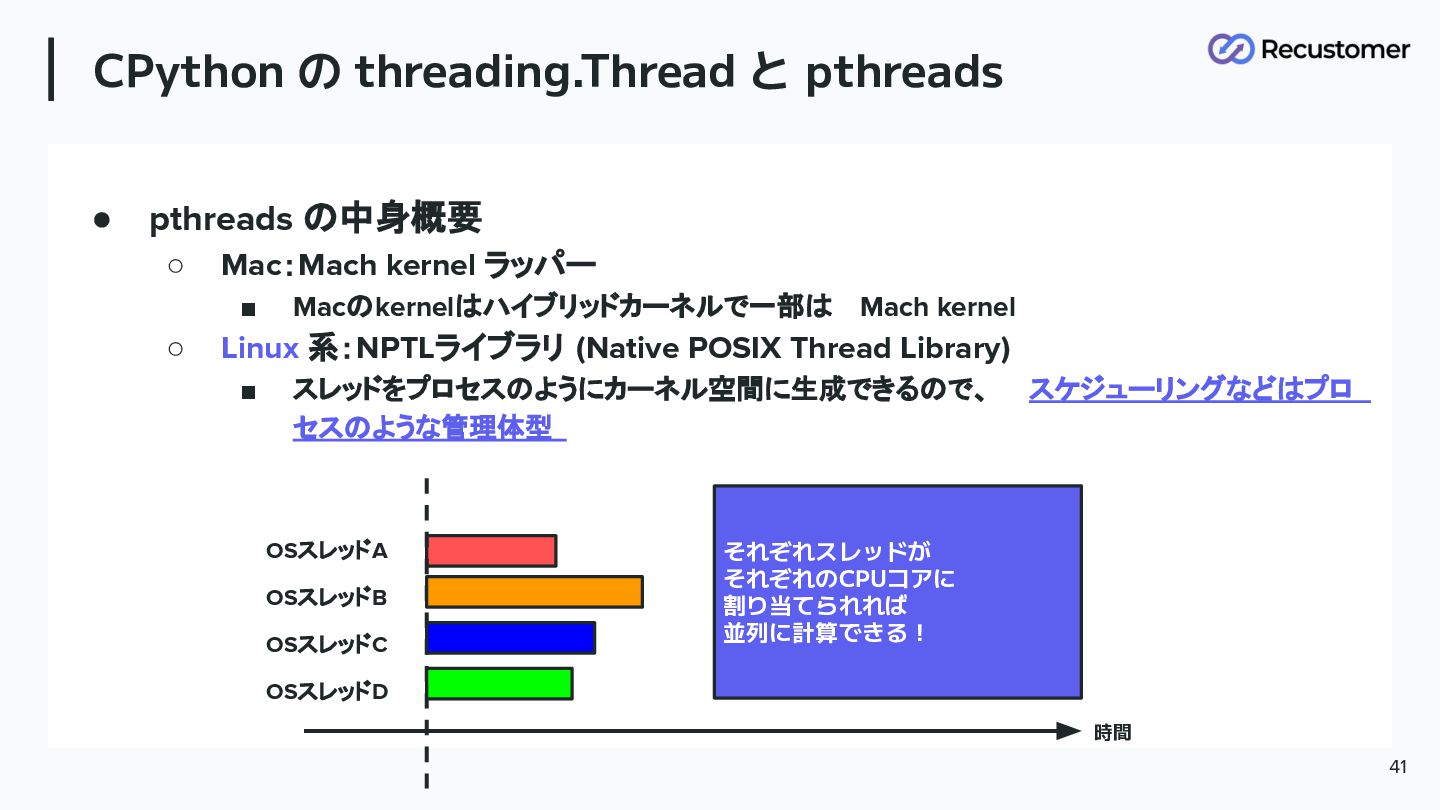
CPython の threading.Thread と pthreads 38 • pthreads の中身概要 ◦
Mac:Mach kernel ラッパー ▪ Macのkernelはハイブリッドカーネルで一部は Mach kernel ◦ Linux 系:NPTLライブラリ (Native POSIX Thread Library) ▪ スレッドをプロセスのようにカーネル空間に生成できるので、スケジューリングなどはプロ セスのような管理体型 歴史の伏線回収
CPython の threading.Thread と pthreads 39 • pthreads の中身概要 ◦
Mac:Mach kernel ラッパー ▪ Macのkernelはハイブリッドカーネルで一部は Mach kernel ◦ Linux 系:NPTLライブラリ (Native POSIX Thread Library) ▪ スレッドをプロセスのようにカーネル空間に生成できるので、 スケジューリングなどはプロ セスのような管理体型
CPython の threading.Thread と pthreads 40 • pthreads の中身概要 ◦
Mac:Mach kernel ラッパー ▪ Macのkernelはハイブリッドカーネルで一部は Mach kernel ◦ Linux 系:NPTLライブラリ (Native POSIX Thread Library) ▪ スレッドをプロセスのようにカーネル空間に生成できるので、 スケジューリングなどはプロ セスのような管理体型 つまり、 「プロセス」のように OS がいい感じに ディスパッチしながら並列処理してくれる
CPython の threading.Thread と pthreads 41 • pthreads の中身概要 ◦
Mac:Mach kernel ラッパー ▪ Macのkernelはハイブリッドカーネルで一部は Mach kernel ◦ Linux 系:NPTLライブラリ (Native POSIX Thread Library) ▪ スレッドをプロセスのようにカーネル空間に生成できるので、 スケジューリングなどはプロ セスのような管理体型 OSスレッドA OSスレッドB OSスレッドC OSスレッドD 時間 それぞれスレッドが それぞれのCPUコアに 割り当てられれば 並列に計算できる!
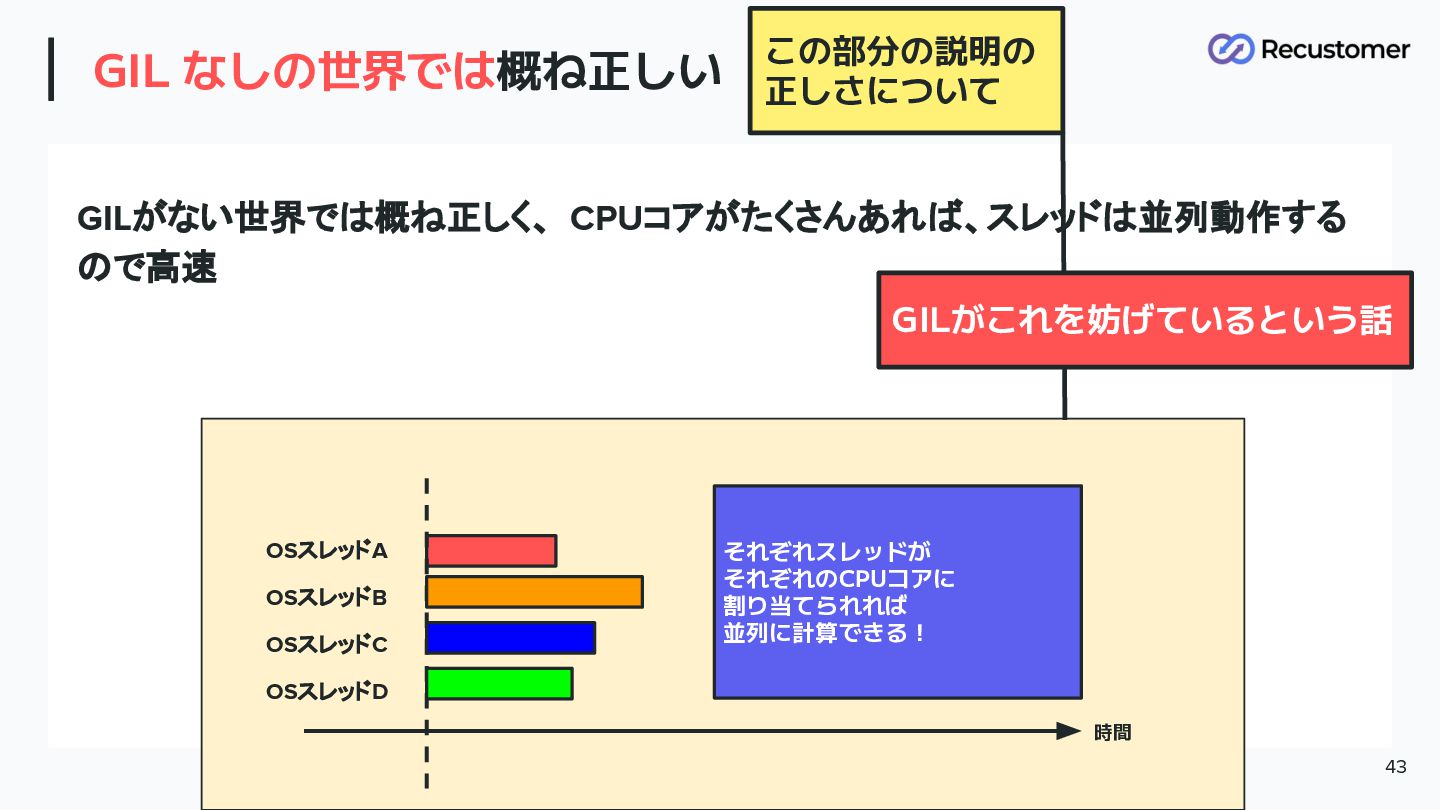
CPython の threading.Thread と pthreads 42 そう、実は、 GIL さえなければ 正しい動き
GIL なしの世界では概ね正しい 43 GILがない世界では概ね正しく、 CPUコアがたくさんあれば、スレッドは並列動作する ので高速 OSスレッドA OSスレッドB OSスレッドC OSスレッドD
時間 それぞれスレッドが それぞれのCPUコアに 割り当てられれば 並列に計算できる! この部分の説明の 正しさについて GILがこれを妨げているという話
ずっと説明を 保留してきた GIL の話に 入っていきます 44
GIL = Global Interpreter Lock 45
GIL が 並列性能を落としてでも 導入された目的とは? 46
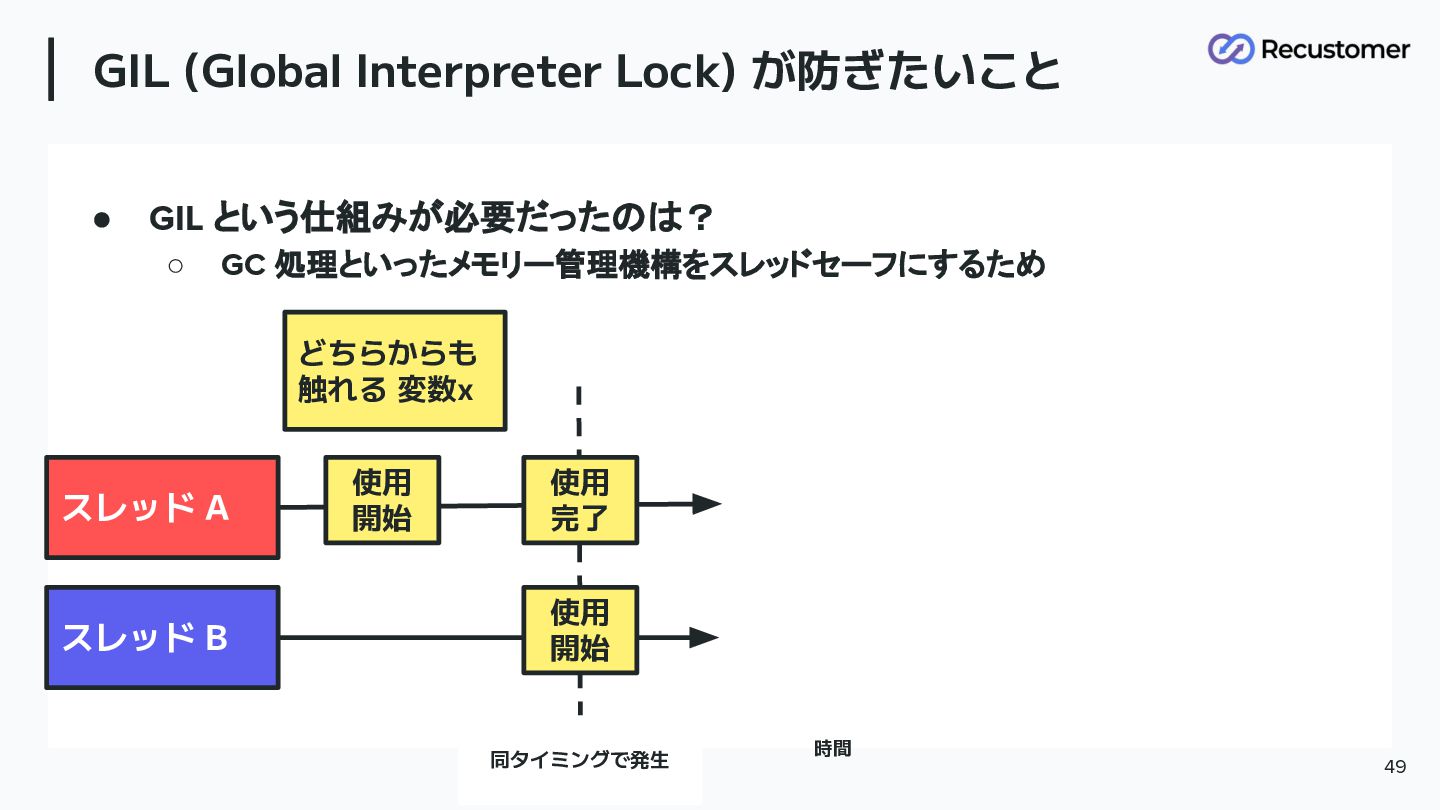
GIL (Global Interpreter Lock) が防ぎたいこと 47 • GIL という仕組みが必要だったのは? ◦
GC 処理といったメモリー管理機構をスレッドセーフにするため
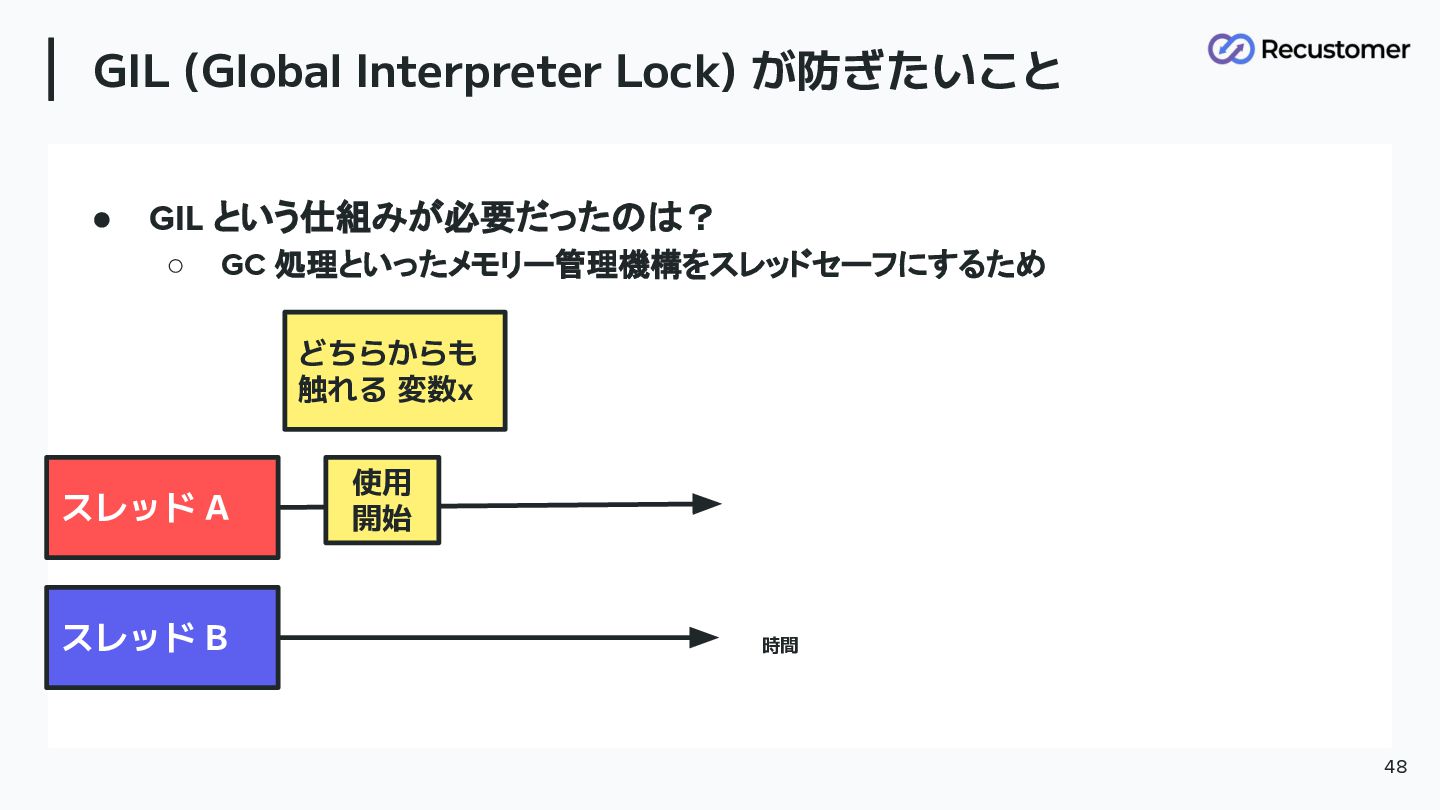
GIL (Global Interpreter Lock) が防ぎたいこと 48 • GIL という仕組みが必要だったのは? ◦
GC 処理といったメモリー管理機構をスレッドセーフにするため 時間 スレッド A スレッド B どちらからも 触れる 変数x 使用 開始
GIL (Global Interpreter Lock) が防ぎたいこと 49 • GIL という仕組みが必要だったのは? ◦
GC 処理といったメモリー管理機構をスレッドセーフにするため 時間 スレッド A スレッド B どちらからも 触れる 変数x 使用 開始 使用 完了 使用 開始 同タイミングで発生
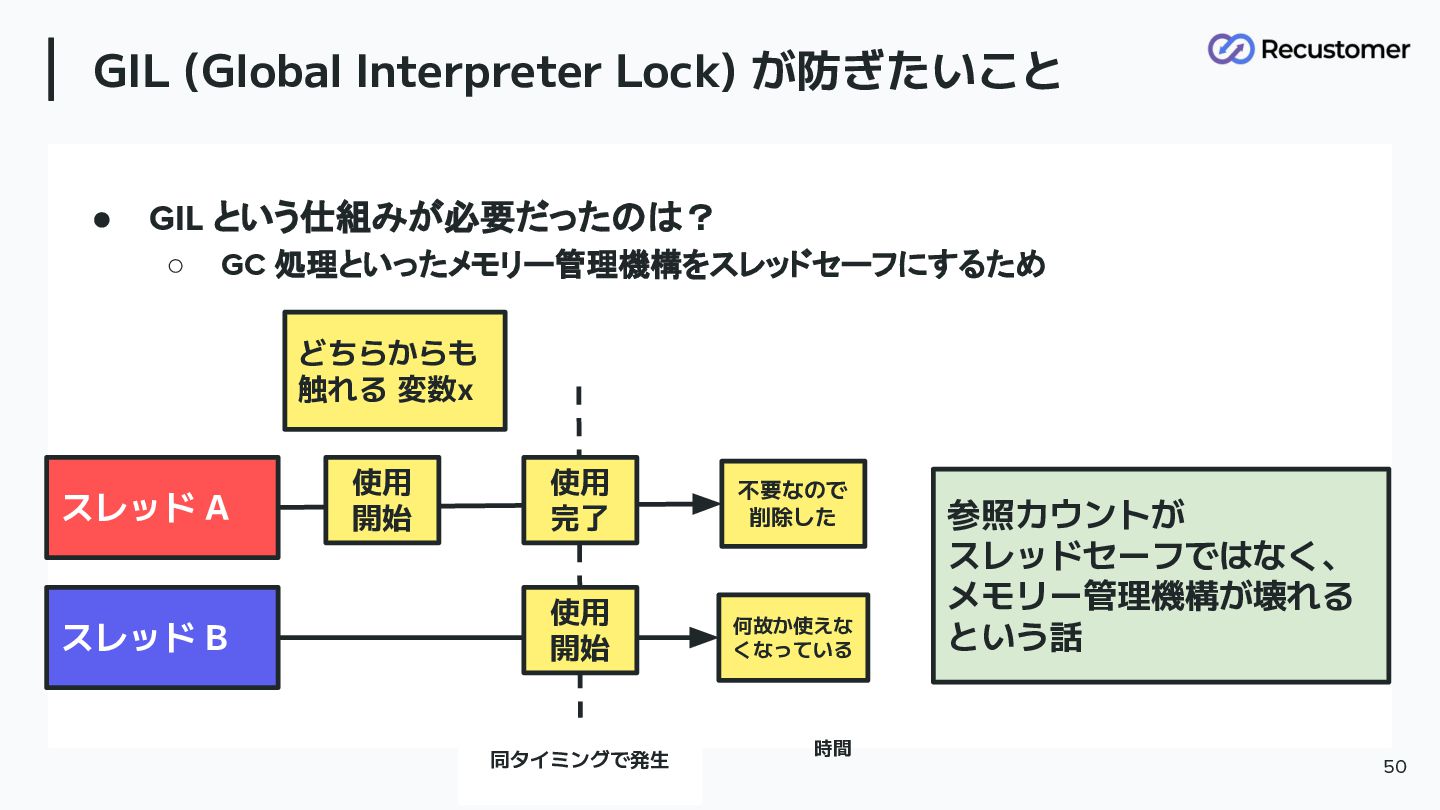
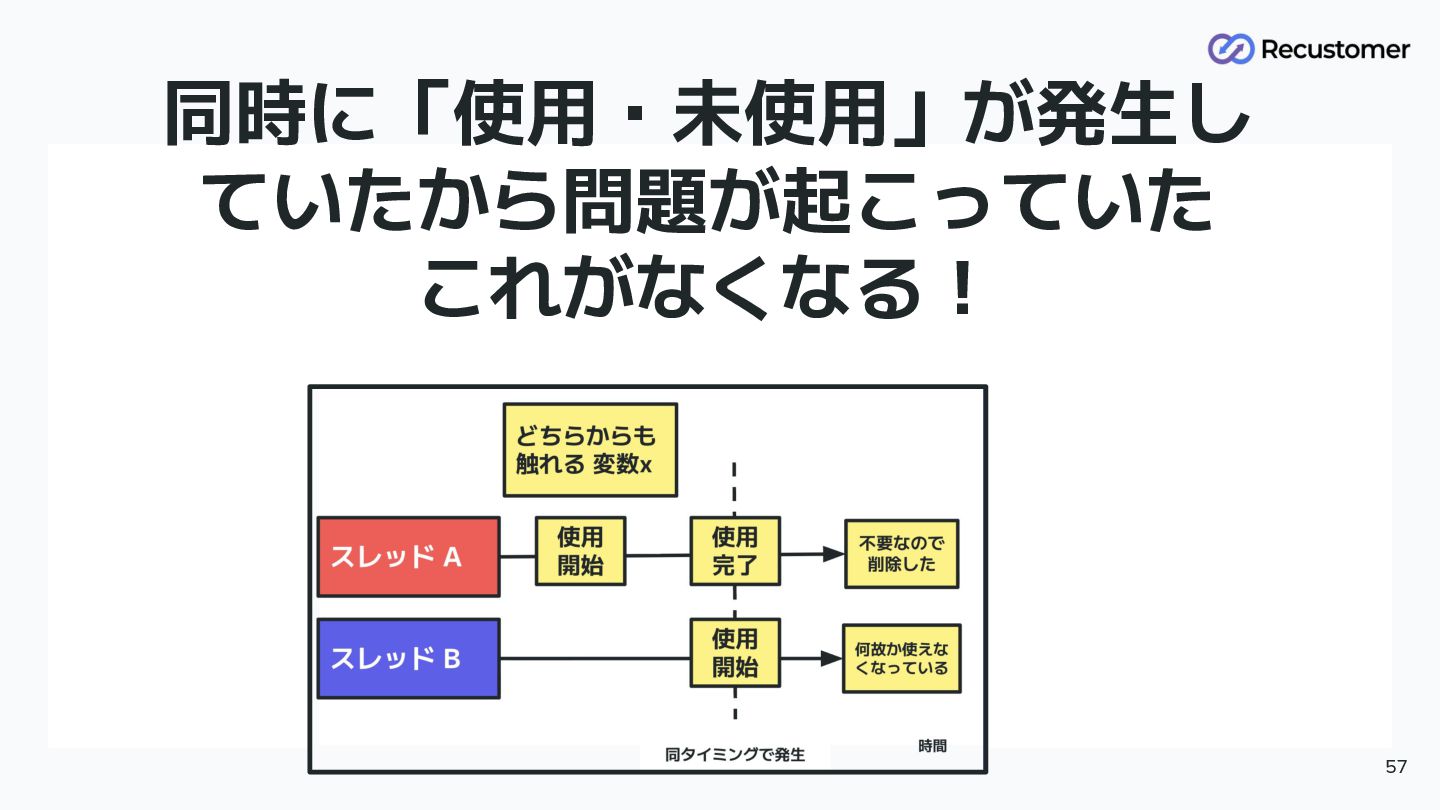
GIL (Global Interpreter Lock) が防ぎたいこと 50 • GIL という仕組みが必要だったのは? ◦
GC 処理といったメモリー管理機構をスレッドセーフにするため 時間 スレッド B どちらからも 触れる 変数x 不要なので 削除した 何故か使えな くなっている 使用 開始 同タイミングで発生 参照カウントが スレッドセーフではなく、 メモリー管理機構が壊れる という話 使用 完了 使用 開始 スレッド A
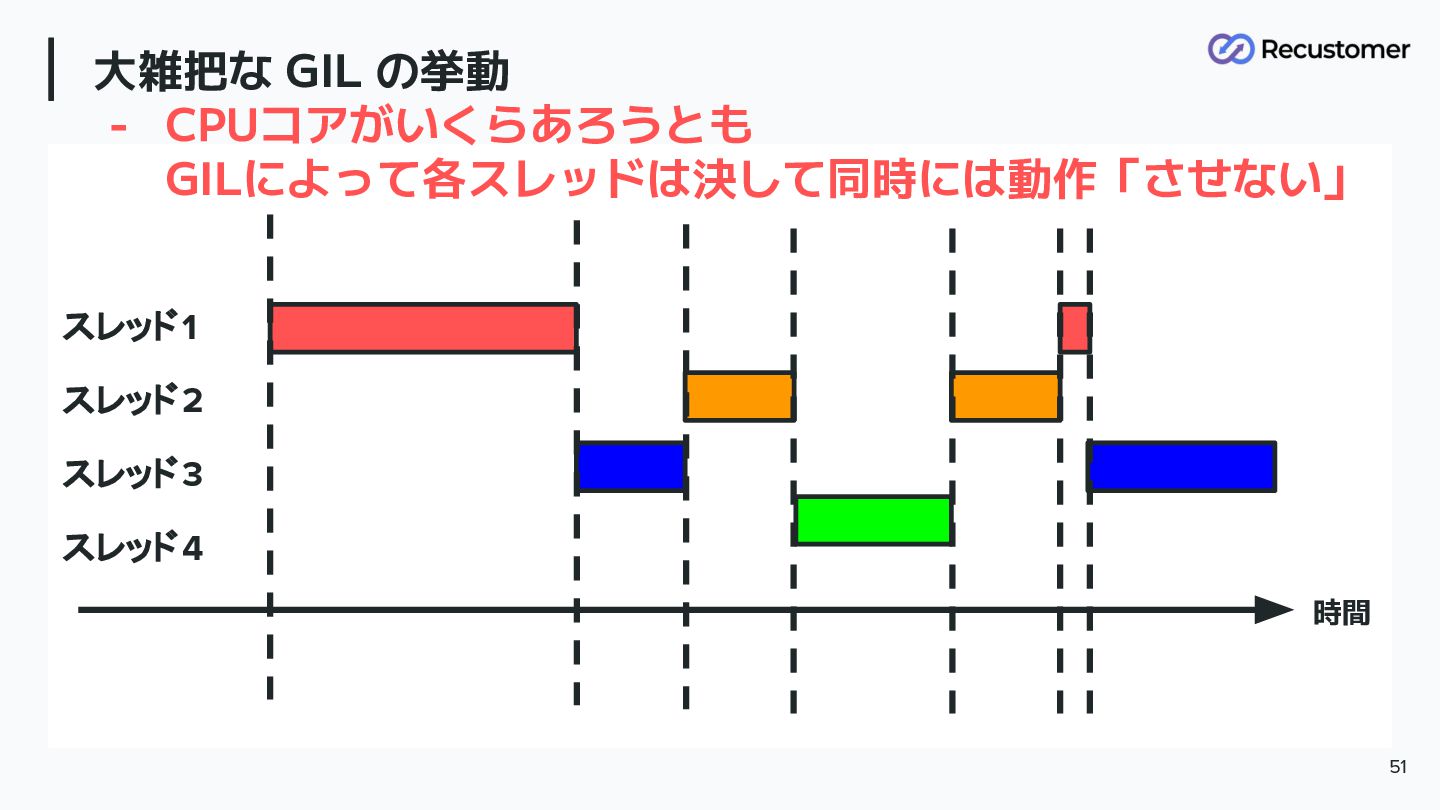
大雑把な GIL の挙動 - CPUコアがいくらあろうとも GILによって各スレッドは決して同時には動作「させない」 51 スレッド1 スレッド2 スレッド3
スレッド4 時間
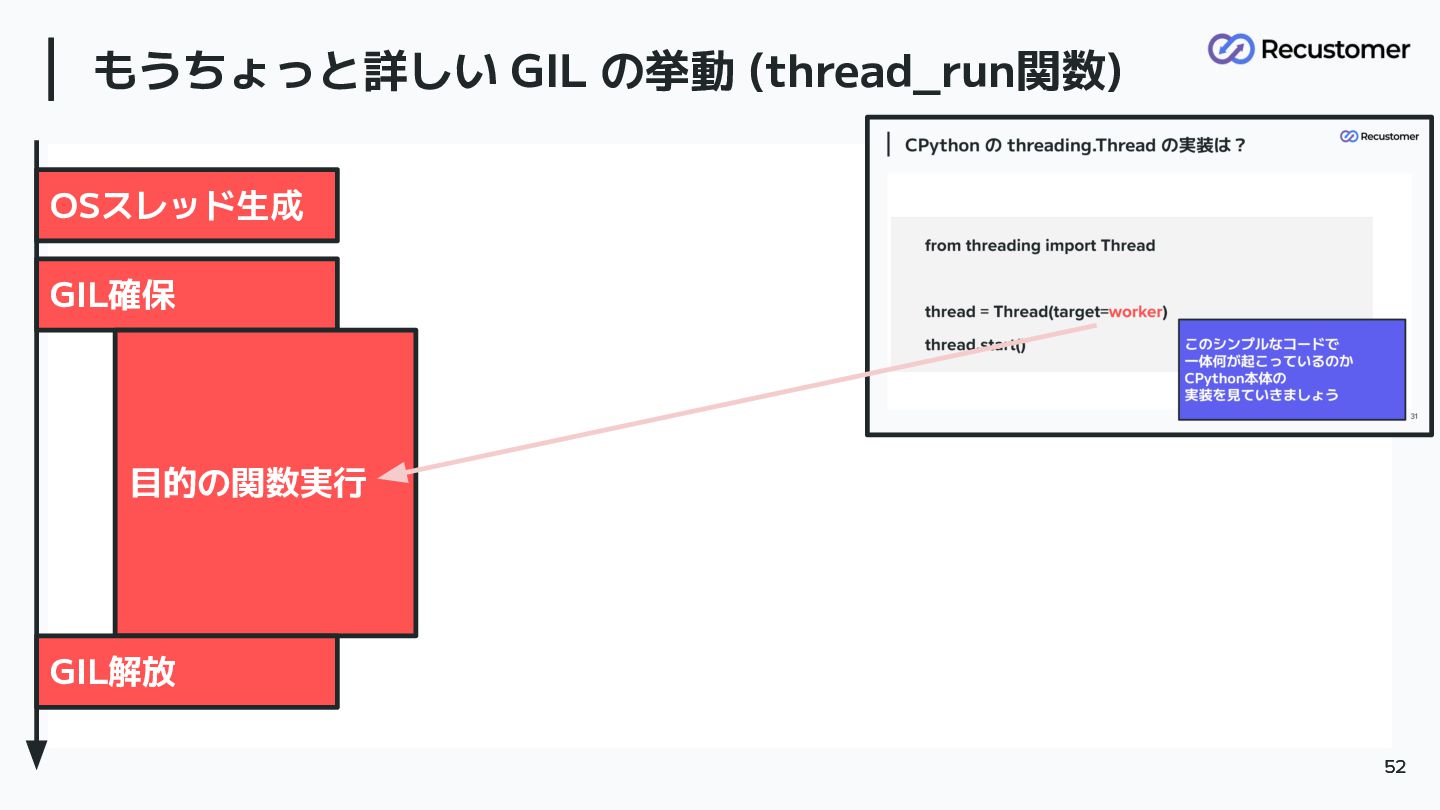
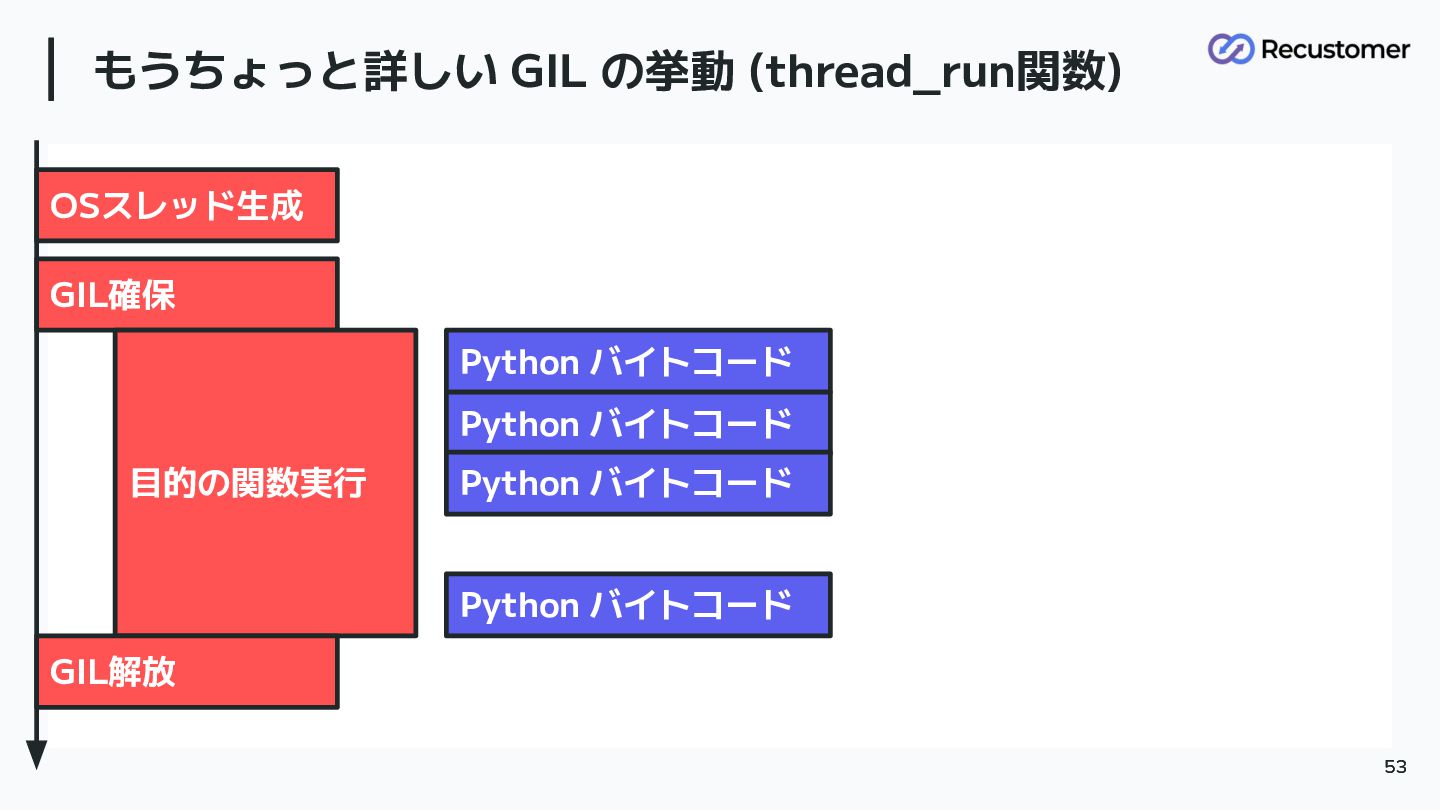
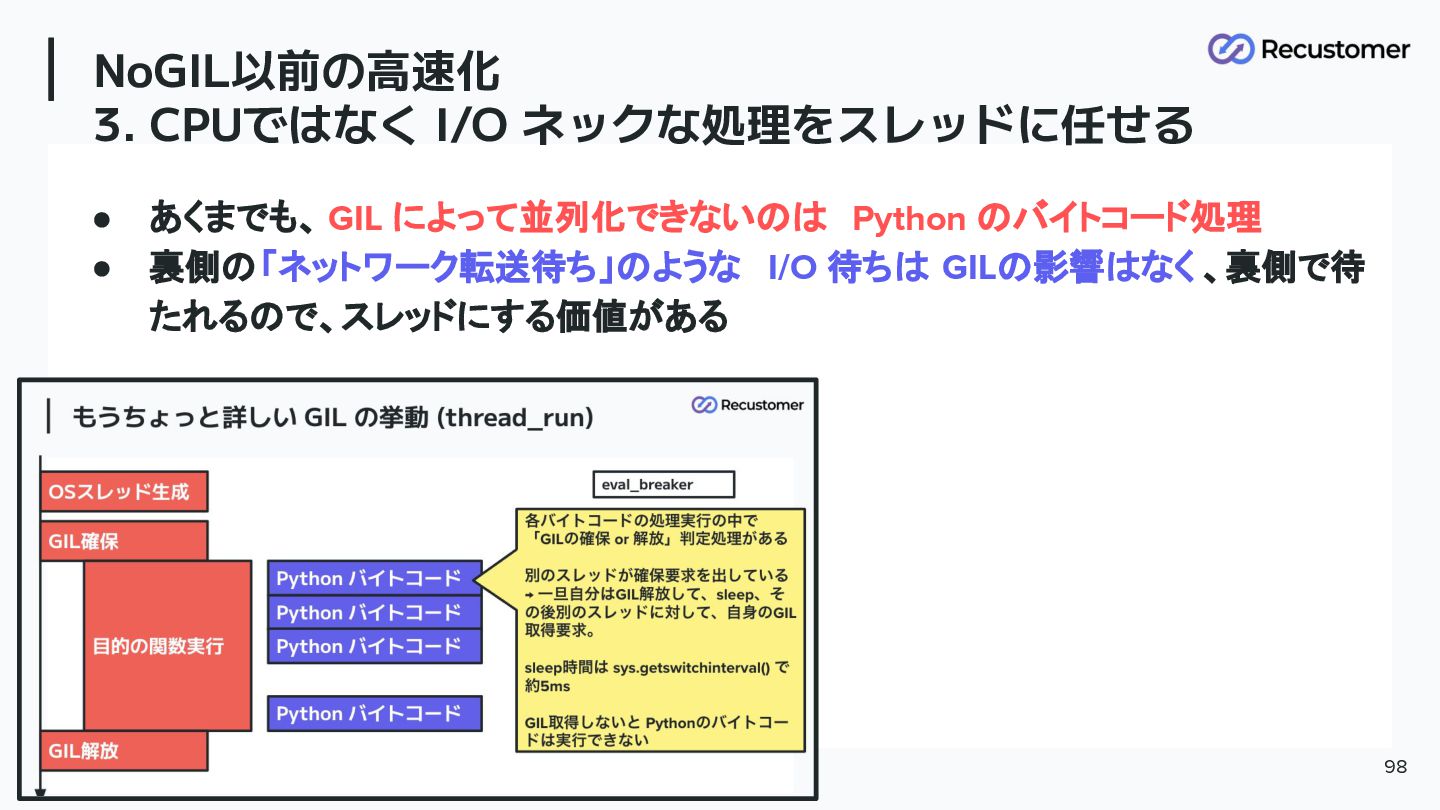
もうちょっと詳しい GIL の挙動 (thread_run関数) 52 52 OSスレッド生成 GIL確保 目的の関数実行 GIL解放
もうちょっと詳しい GIL の挙動 (thread_run関数) 53 53 OSスレッド生成 GIL確保 目的の関数実行 GIL解放
Python バイトコード Python バイトコード Python バイトコード Python バイトコード
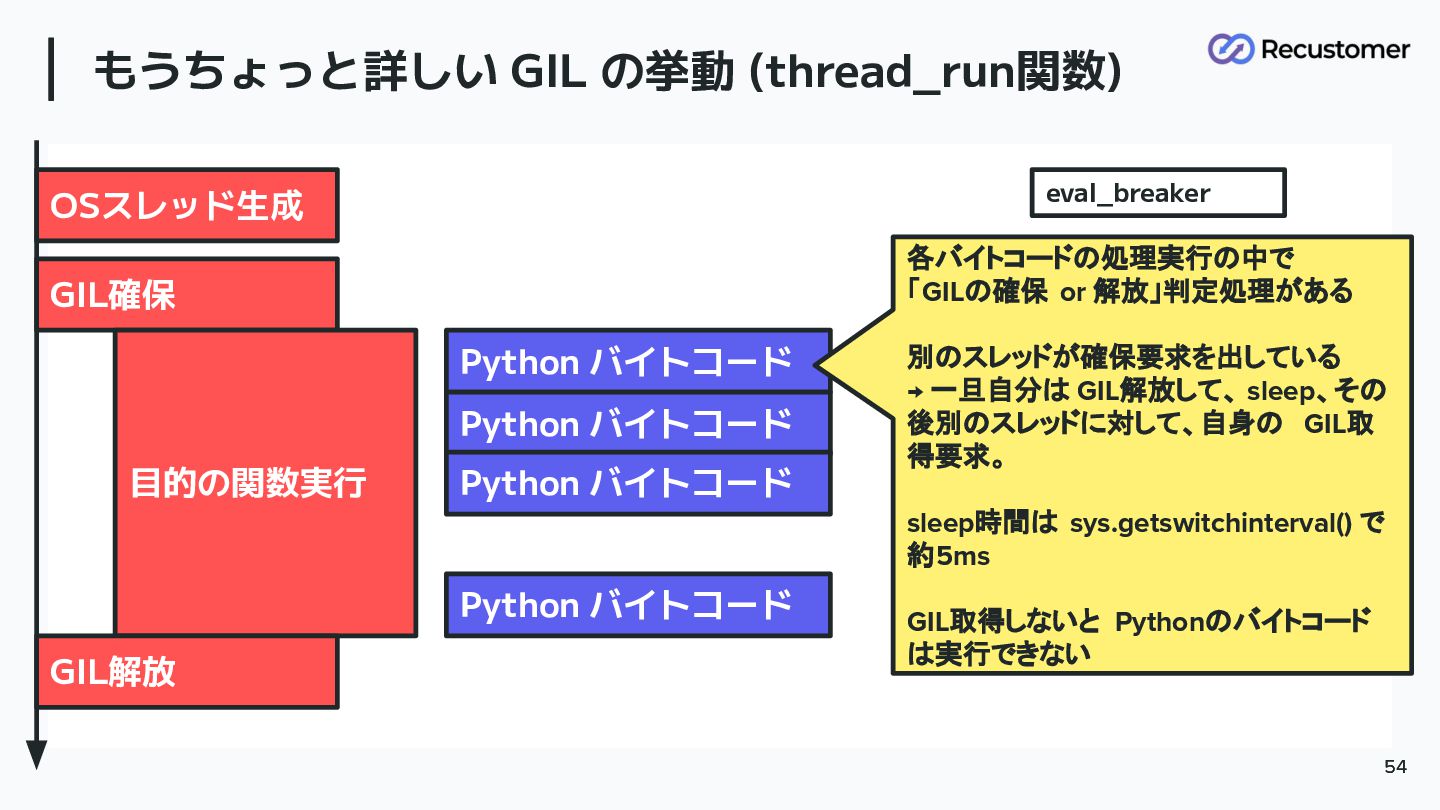
もうちょっと詳しい GIL の挙動 (thread_run関数) 54 54 OSスレッド生成 GIL確保 目的の関数実行 GIL解放
Python バイトコード Python バイトコード Python バイトコード Python バイトコード 各バイトコードの処理実行の中で 「GILの確保 or 解放」判定処理がある 別のスレッドが確保要求を出している → 一旦自分は GIL解放して、 sleep、その 後別のスレッドに対して、自身の GIL取 得要求。 sleep時間は sys.getswitchinterval() で 約5ms GIL取得しないと Pythonのバイトコード は実行できない eval_breaker
つまり、 Pythonのバイトコードの 実行部分を スレッド並列にしなければ 安全だ というのがGILの思想 55
もっと詳しく言うと、 1CPUのときと同様な動作にすれば 参照カウントを同時に アクセスしないから メモリー管理は壊れないよね? 疑似並列でスレッドを 実行しよう! というのがGILの思想 56
同時に「使用・未使用」が発生し ていたから問題が起こっていた これがなくなる! 57
このような ロジックになった GILが生まれた 時代背景とは? 58
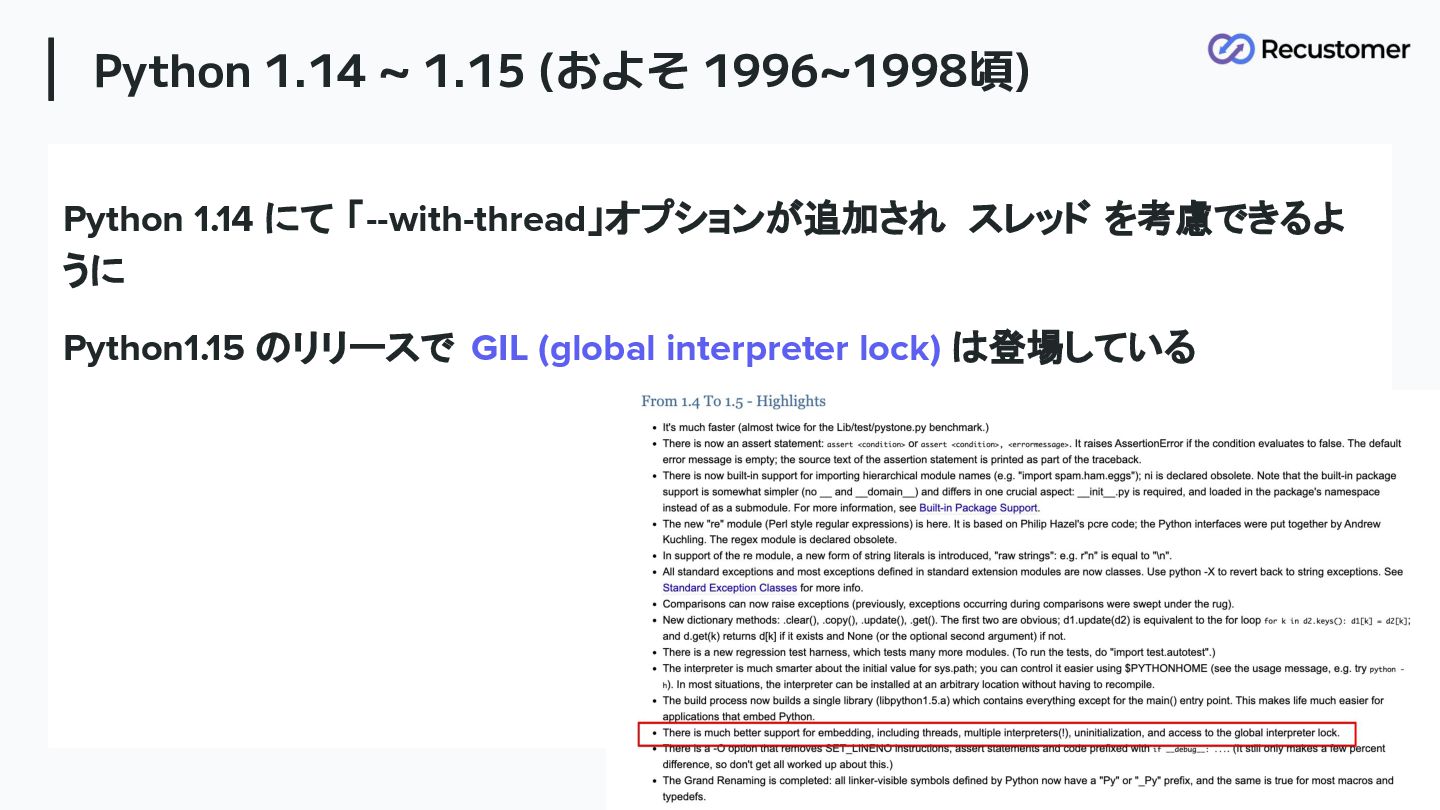
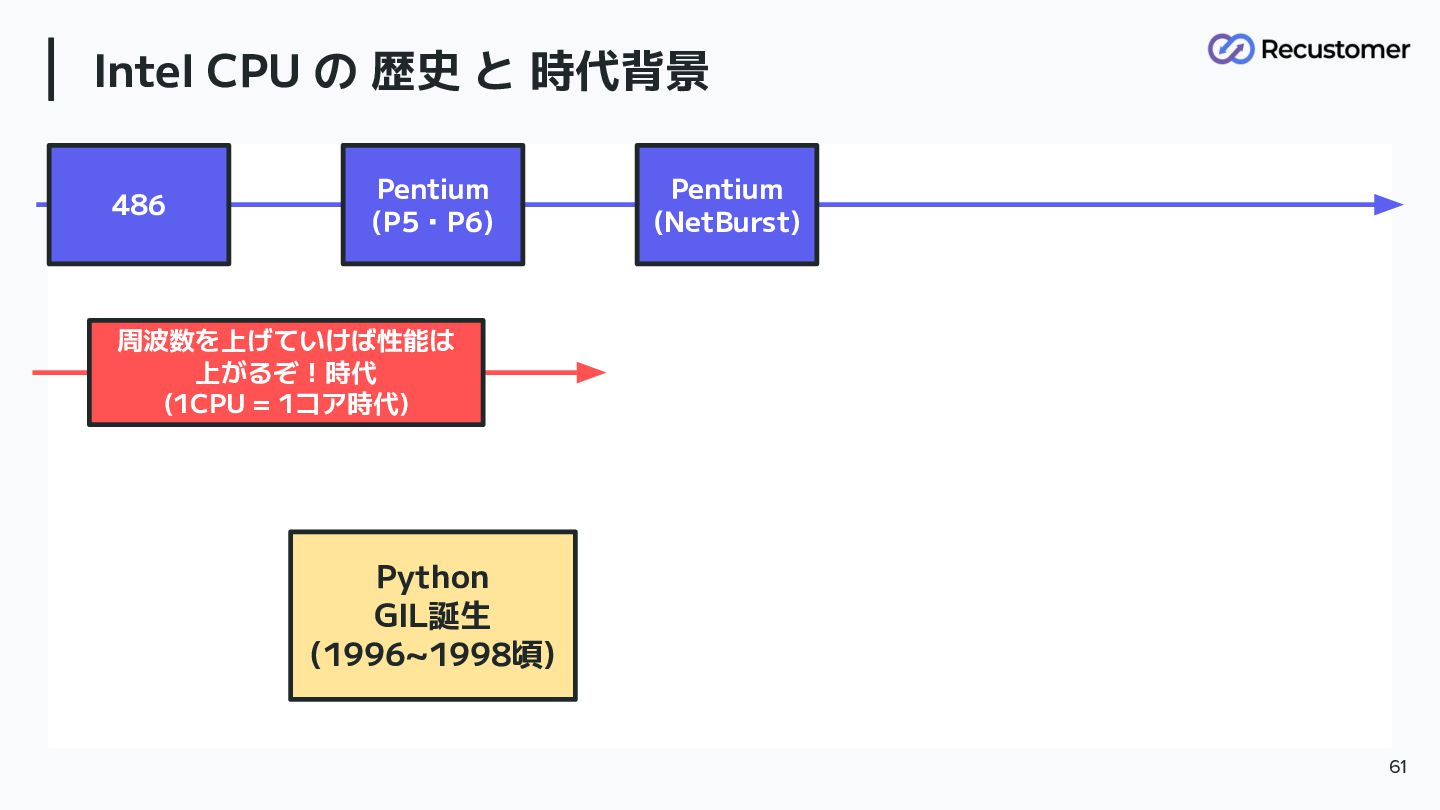
Python 1.14 ~ 1.15 (およそ 1996~1998頃) Python 1.14 にて 「--with-thread」オプションが追加され
スレッド を考慮できるよ うに Python1.15 のリリースで GIL (global interpreter lock) は登場している 59
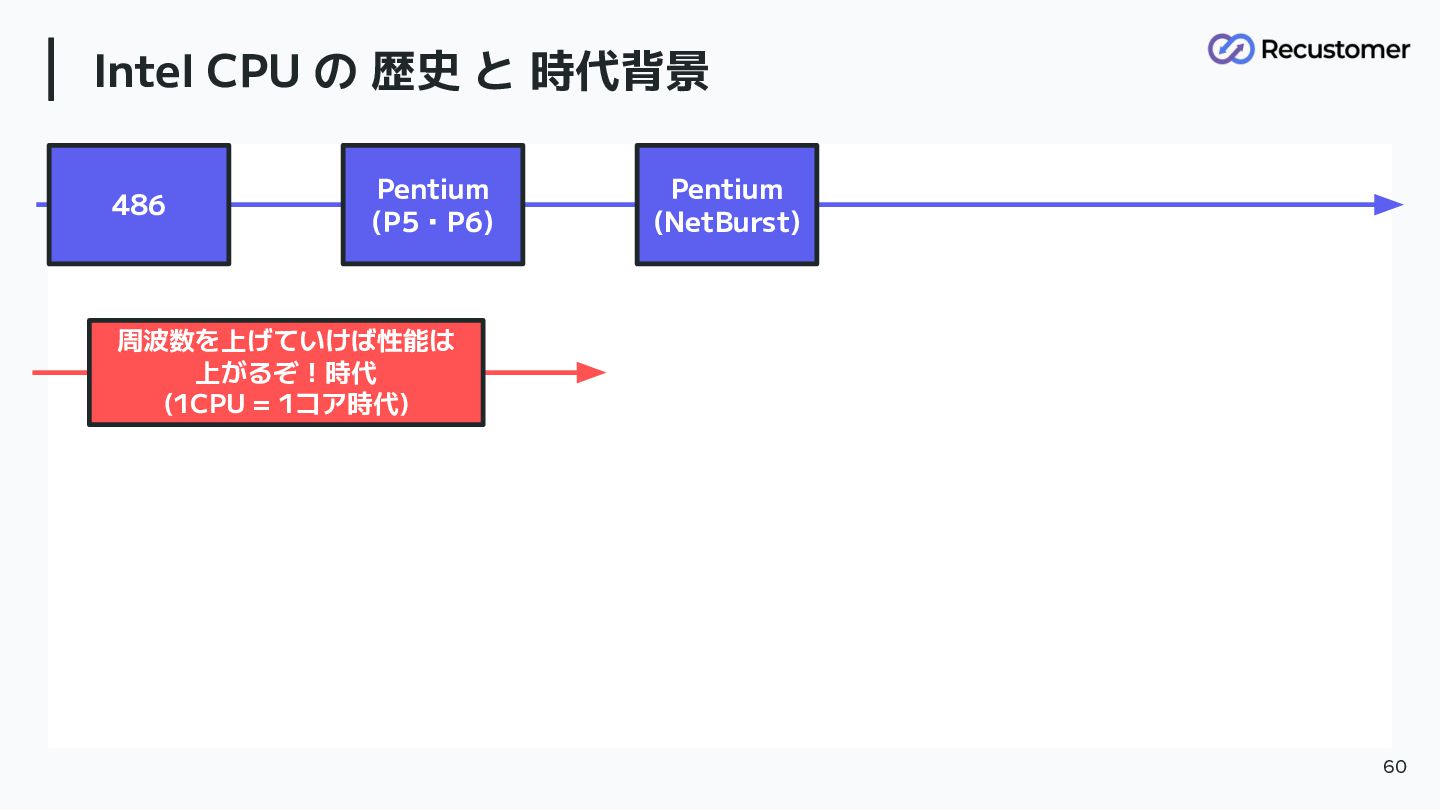
青グループ Intel CPU の 歴史 と 時代背景 60 周波数を上げていけば性能は 上がるぞ!時代
(1CPU = 1コア時代) 486 Pentium (P5・P6) Pentium (NetBurst)
青グループ Intel CPU の 歴史 と 時代背景 61 周波数を上げていけば性能は 上がるぞ!時代
(1CPU = 1コア時代) Python GIL誕生 (1996~1998頃) 486 Pentium (P5・P6) Pentium (NetBurst)
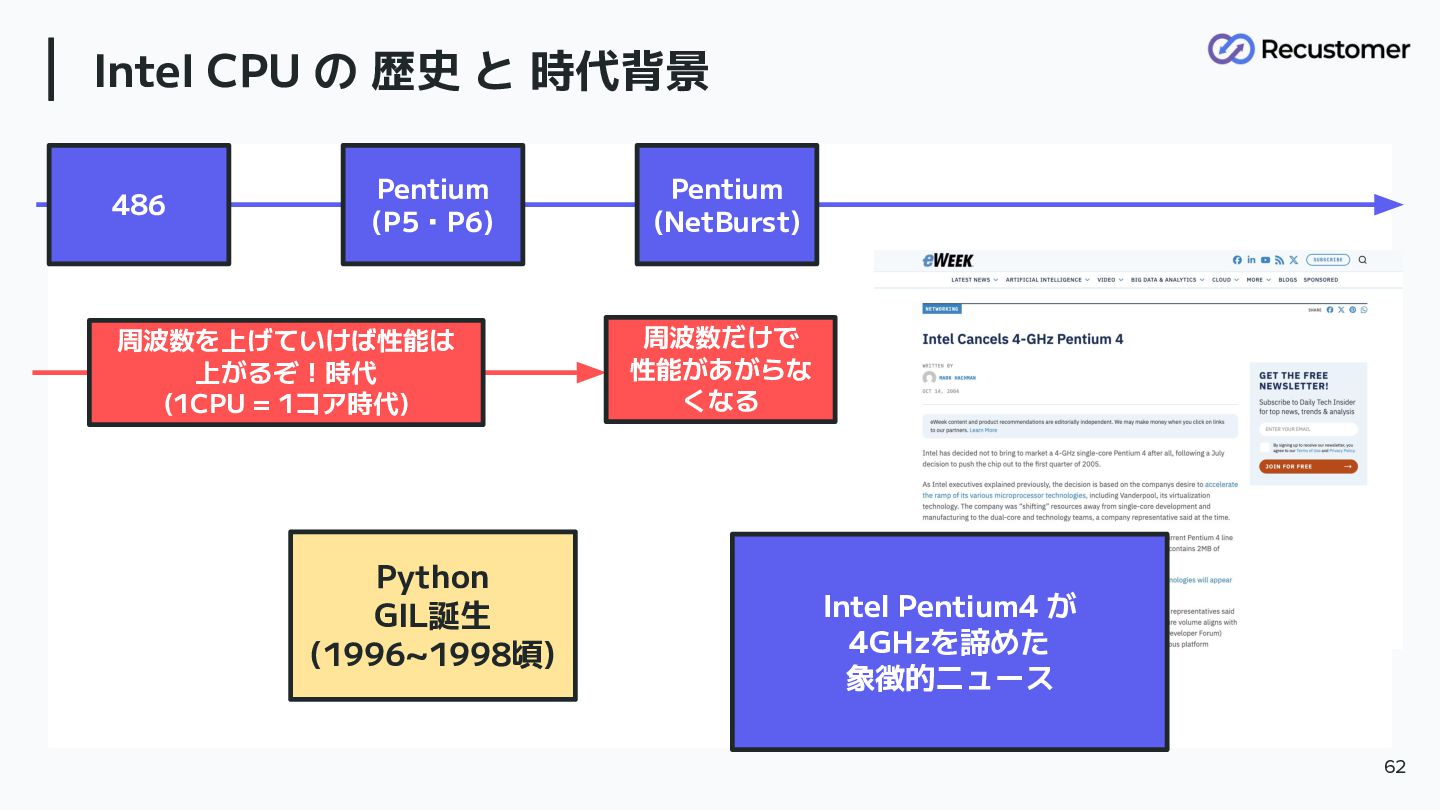
青グループ Intel CPU の 歴史 と 時代背景 62 周波数を上げていけば性能は 上がるぞ!時代
(1CPU = 1コア時代) Python GIL誕生 (1996~1998頃) 486 Pentium (P5・P6) Pentium (NetBurst) 周波数だけで 性能があがらな くなる Intel Pentium4 が 4GHzを諦めた 象徴的ニュース
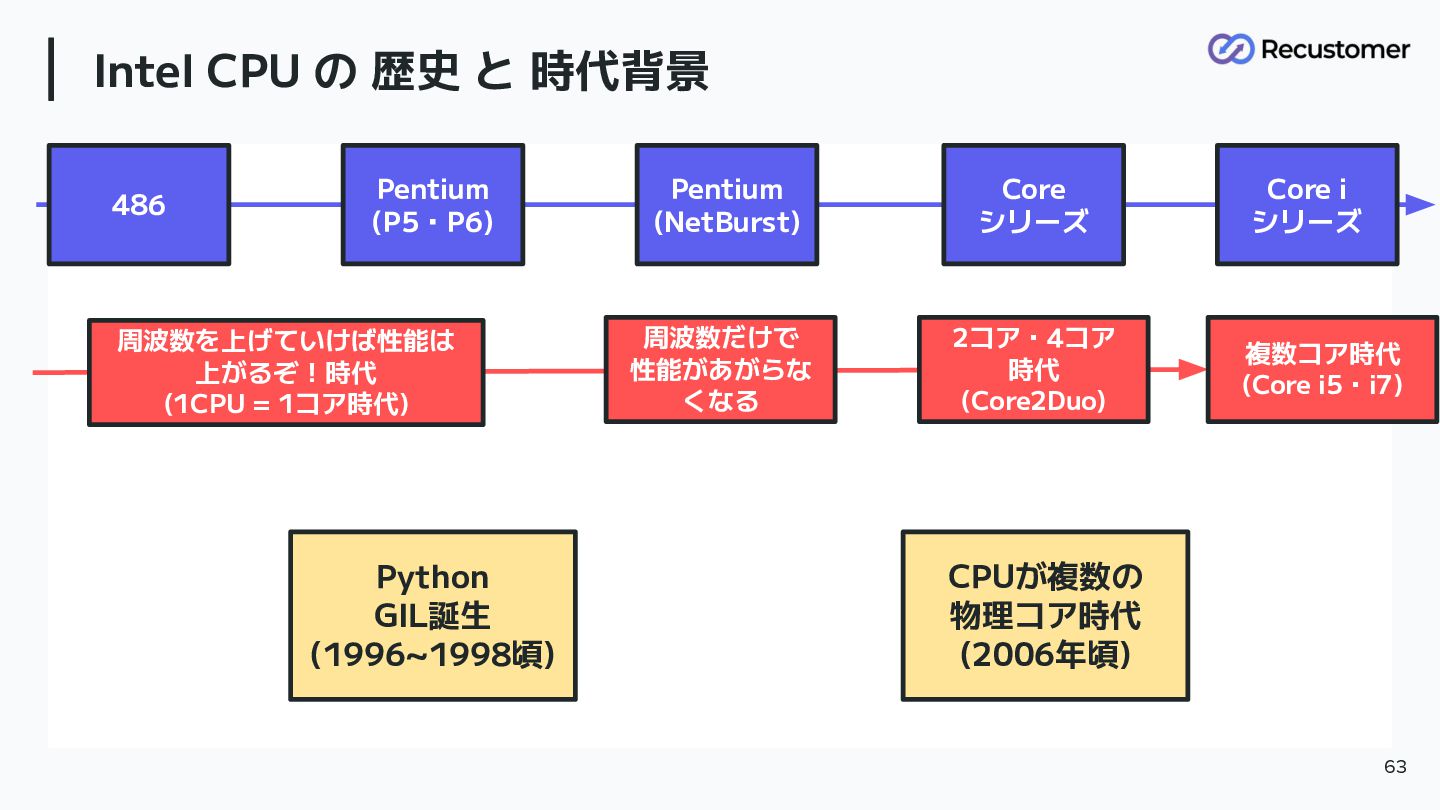
青グループ Intel CPU の 歴史 と 時代背景 63 周波数を上げていけば性能は 上がるぞ!時代
(1CPU = 1コア時代) Python GIL誕生 (1996~1998頃) 486 Pentium (P5・P6) Pentium (NetBurst) 周波数だけで 性能があがらな くなる Core シリーズ Core i シリーズ 2コア・4コア 時代 (Core2Duo) 複数コア時代 (Core i5・i7) CPUが複数の 物理コア時代 (2006年頃)
つまり Python は マルチコア時代 じゃないときに この問題の対応に 迫られていた (Rubyも同様) 64
今の時代、CPUがたくさんあるものの GILというものがあるので CPU1個しか使われていない 65 複数のCPUコアの恩恵を得るために NoGILを利用したいという話
最初のスライドを 思い出しましょう 66
Python3.13と3.14 の衝撃 67
GIL無効化できます! 68
そう これは高速化界隈に とって 衝撃なのです 69
GIL無効化の実現には どんな努力が あったのでしょうか? 70
残念ながら 時間の都合もあり 細かくお話することは できません 71
ここからは 雰囲気で理解し CPythonに感謝する気持ち を持って返りましょう 72
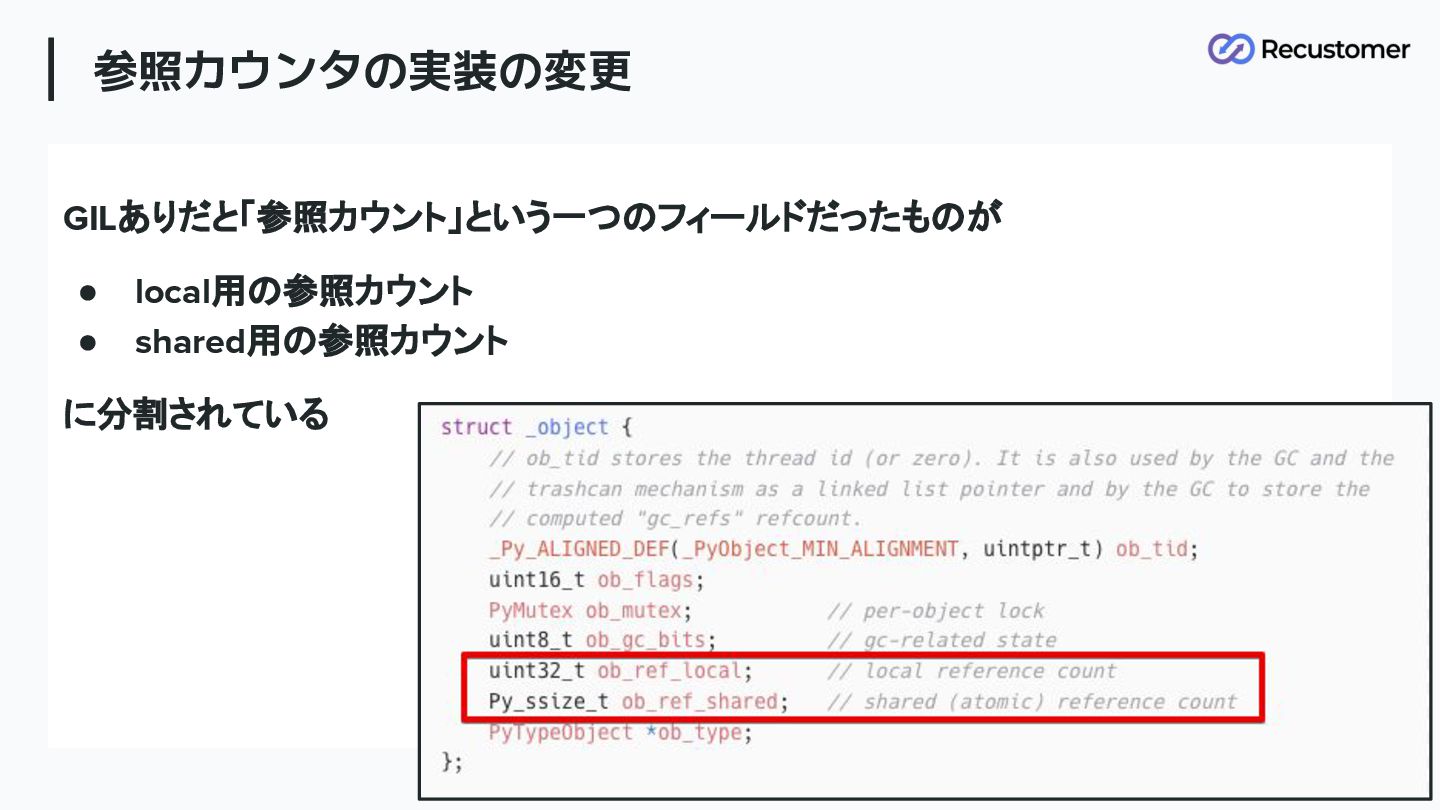
GILありだと「参照カウント」という一つのフィールドだったものが • local用の参照カウント • shared用の参照カウント に分割されている 参照カウンタの実装の変更 73
objectを生成したスレッドが所有スレッド • local用の参照カウント : 所有スレッドが更新する用 ◦ 絶対に自分しか更新しないので、気にせず更新できる • shared用の参照カウント :
その他のスレッドが更新する用 ◦ 複数のスレッドから更新されても大丈夫な AtomicなRead-Modify-Write命令が必要な ため、処理コストがかかる どちらかが 0になったりすると、統合要求などを経て、 objectを削除することになる 参照カウンタの実装の変更 74 sys.getrefcount(x) というリファレンスカウントを返す関数は、 local + shared の値を返すなど、 GILとNoGILで結果が異なる点も面白い
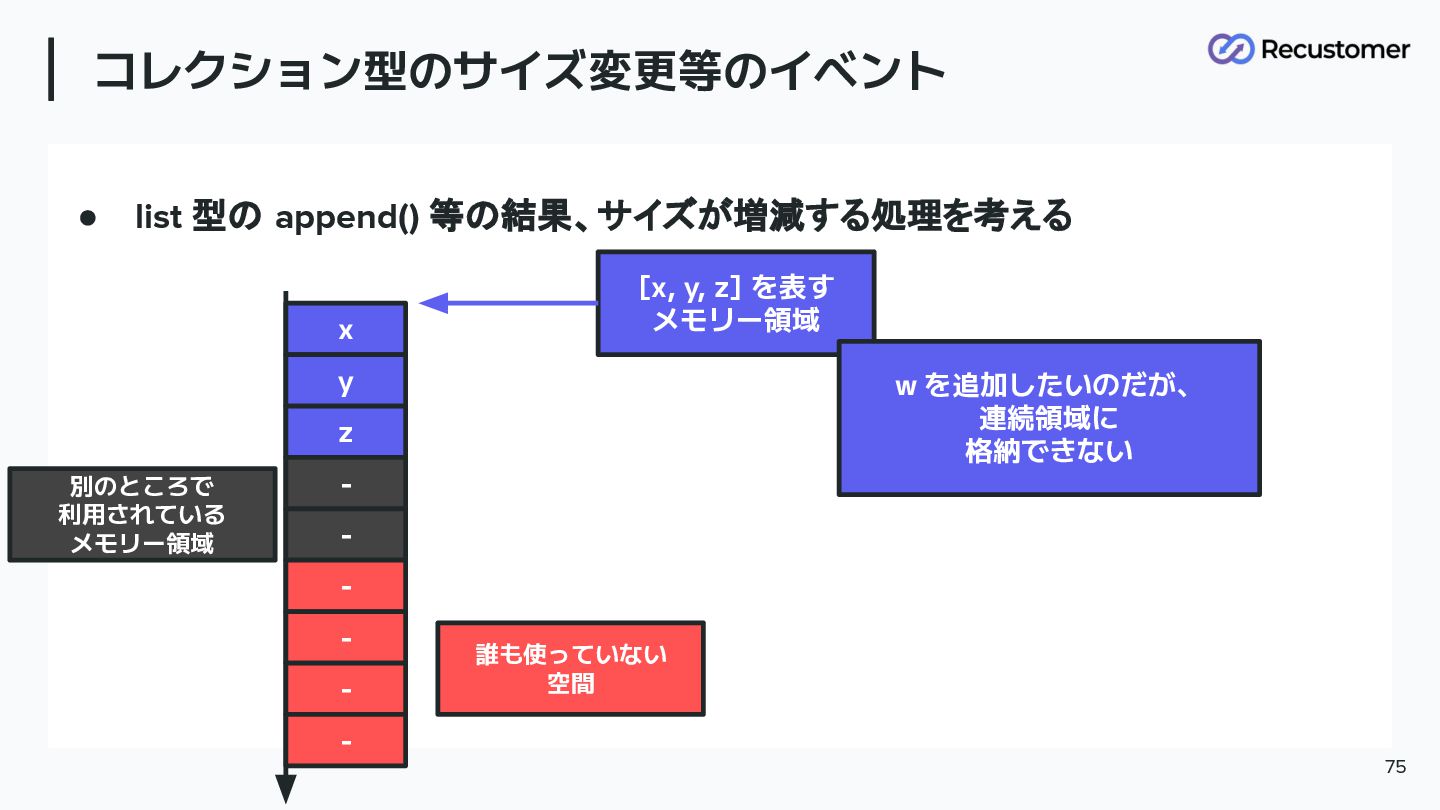
• list 型の append() 等の結果、サイズが増減する処理を考える コレクション型のサイズ変更等のイベント 75 x y z
- - - - - - [x, y, z] を表す メモリー領域 別のところで 利用されている メモリー領域 誰も使っていない 空間 w を追加したいのだが、 連続領域に 格納できない
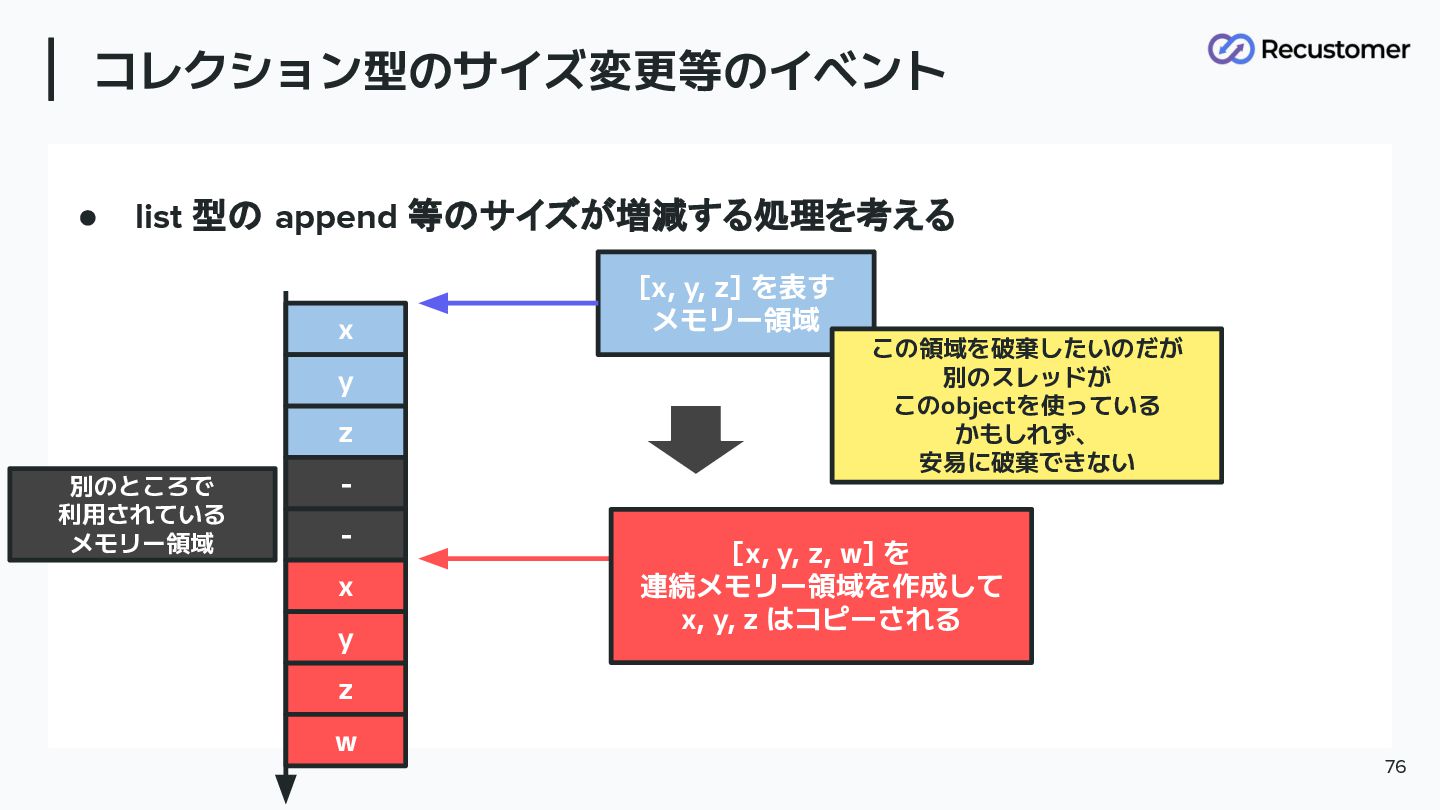
• list 型の append 等のサイズが増減する処理を考える コレクション型のサイズ変更等のイベント 76 x y z
- - [x, y, z] を表す メモリー領域 x y z w 別のところで 利用されている メモリー領域 [x, y, z, w] を 連続メモリー領域を作成して x, y, z はコピーされる この領域を破棄したいのだが 別のスレッドが このobjectを使っている かもしれず、 安易に破棄できない
list型のオブジェクトは多数ありそれらをすべて Lockで同期で取るのは大変 QSBR(Quiescent State-Based Reclamation)という技法が利用されている。 • 各スレッドが、クリティカルセクションを抜けて、古いデータ構造を参照していない ことを、定期的に報告させる ◦ eval_breaker
がこのポイントになっている • これにより、古いデータは誰からも参照されないことを保証し、遅延削除 QSBR (Quiescent State-Based Reclamation) 77
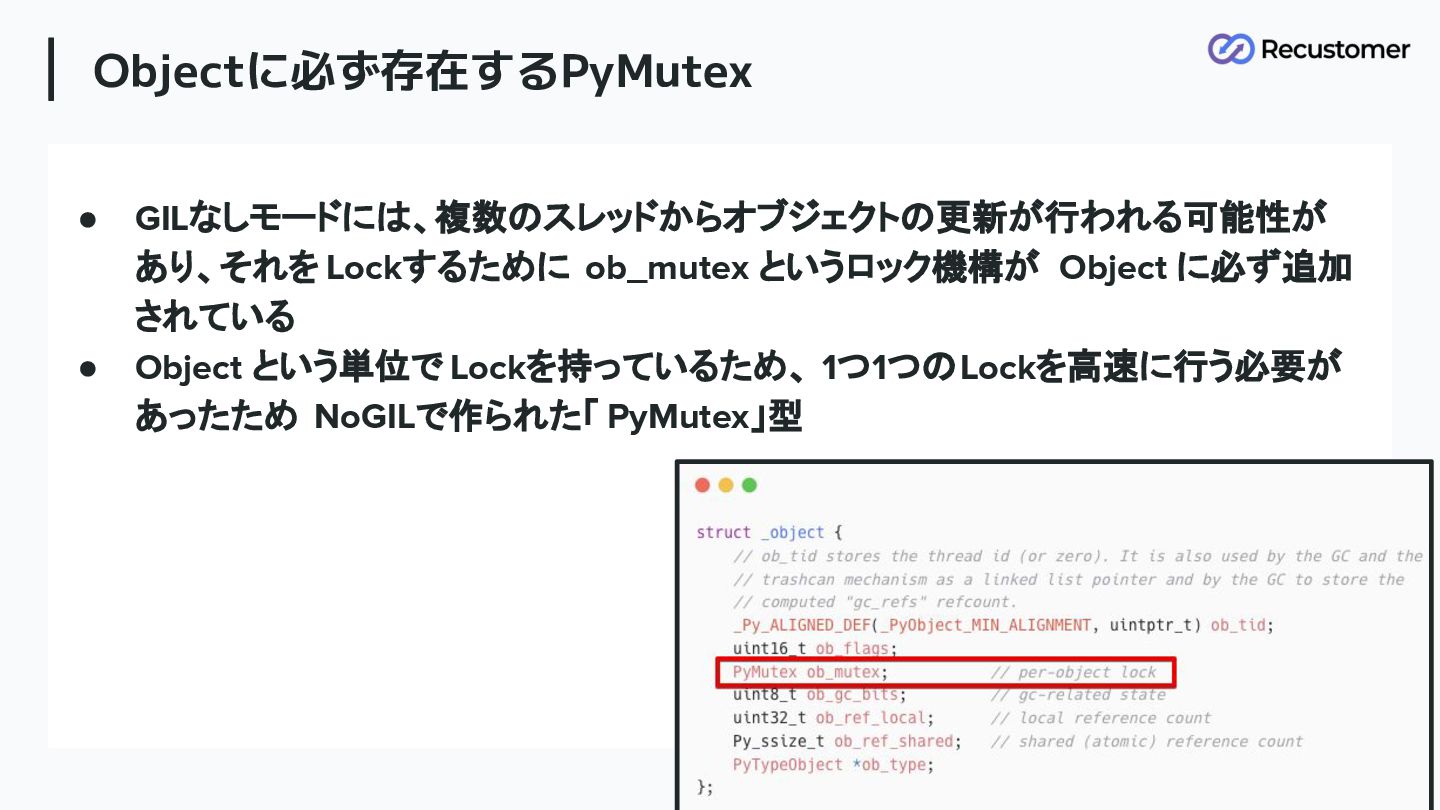
• GILなしモードには、複数のスレッドからオブジェクトの更新が行われる可能性が あり、それを Lockするために ob_mutex というロック機構が Object に必ず追加 されている •
Object という単位で Lockを持っているため、 1つ1つのLockを高速に行う必要が あったため NoGILで作られた「 PyMutex」型 Objectに必ず存在するPyMutex 78
• 従来の Lock型は 100Byte 程の大きさであり、オブジェクト一つ一つに持たせる には大きかった • PyMutex は 1Byte
というとても小さなデータでロックを表す PyMutex : 軽量なロック機構 79 旧来のLock機構 (Python/thread_pthread.h) 新しい PyMutex (Python/thread_pthread.h)
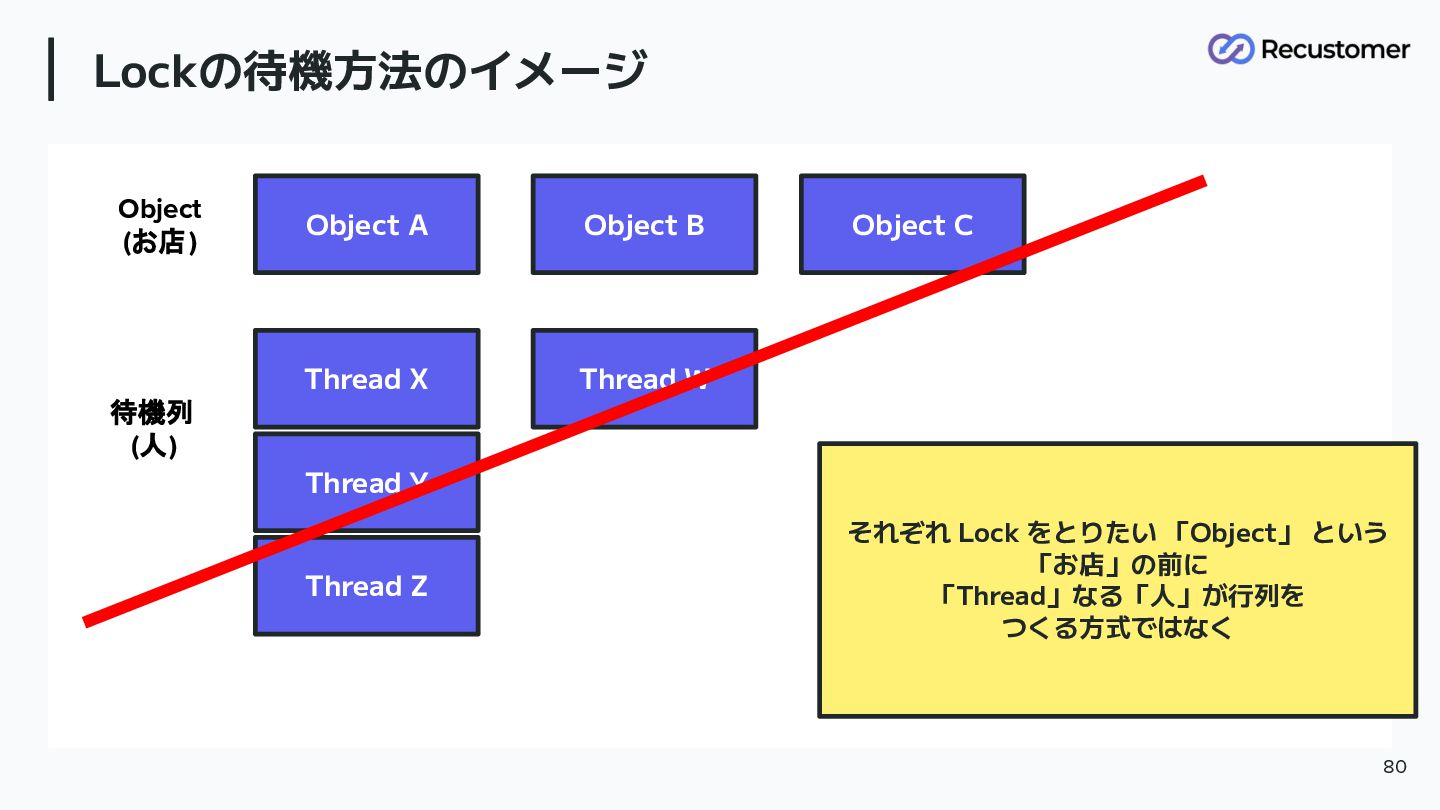
Lockの待機方法のイメージ 80 Object A Object B Object C Thread X
Thread Y Thread W Thread Z それぞれ Lock をとりたい 「Object」 という 「お店」の前に 「Thread」なる「人」が行列を つくる方式ではなく 待機列 (人) Object (お店)
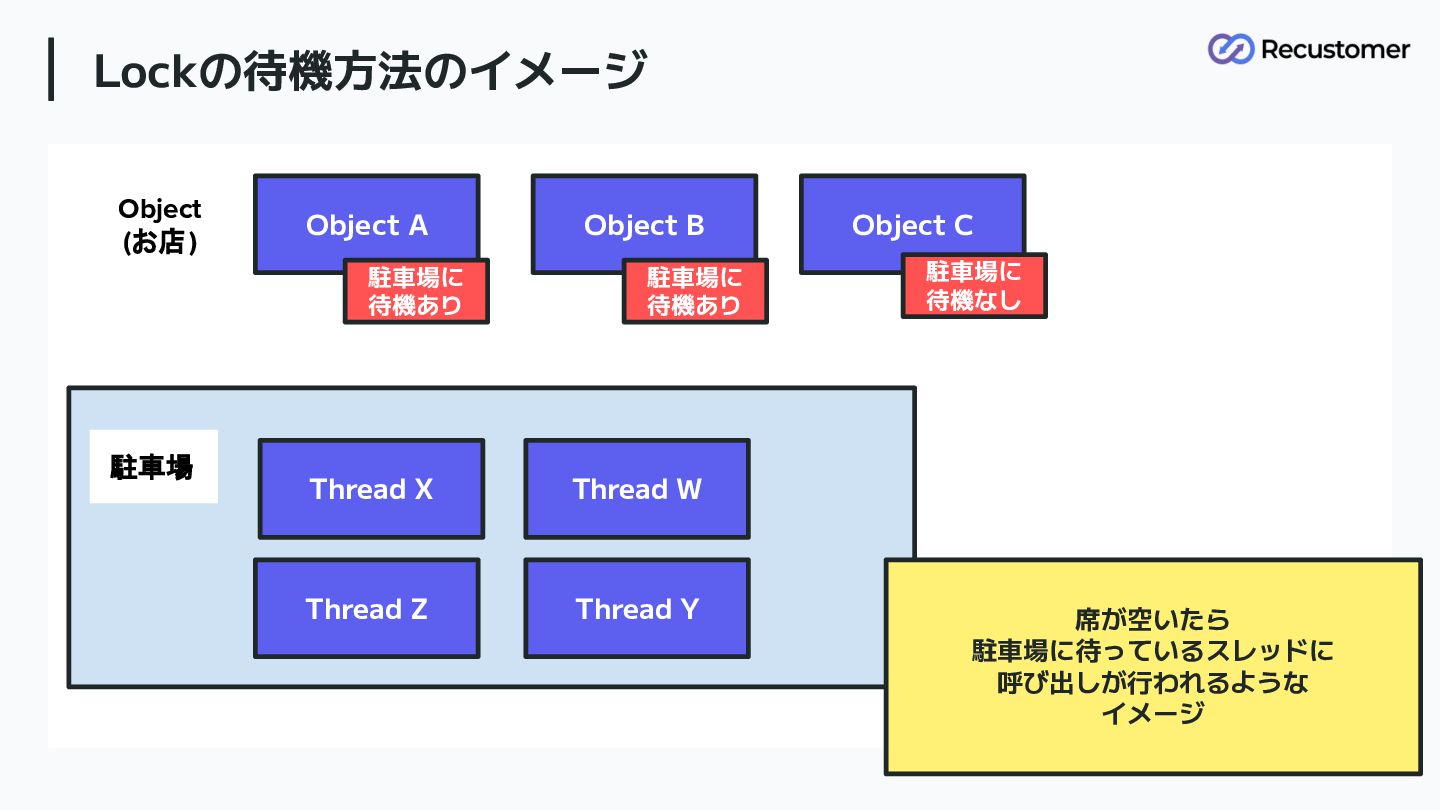
Lockの待機方法のイメージ 81 Object A Object B Object C Thread X
Thread Y Thread W Thread Z 駐車場 Object (お店) 駐車場に 待機あり 駐車場に 待機あり 駐車場に 待機なし 席が空いたら 駐車場に待っているスレッドに 呼び出しが行われるような イメージ
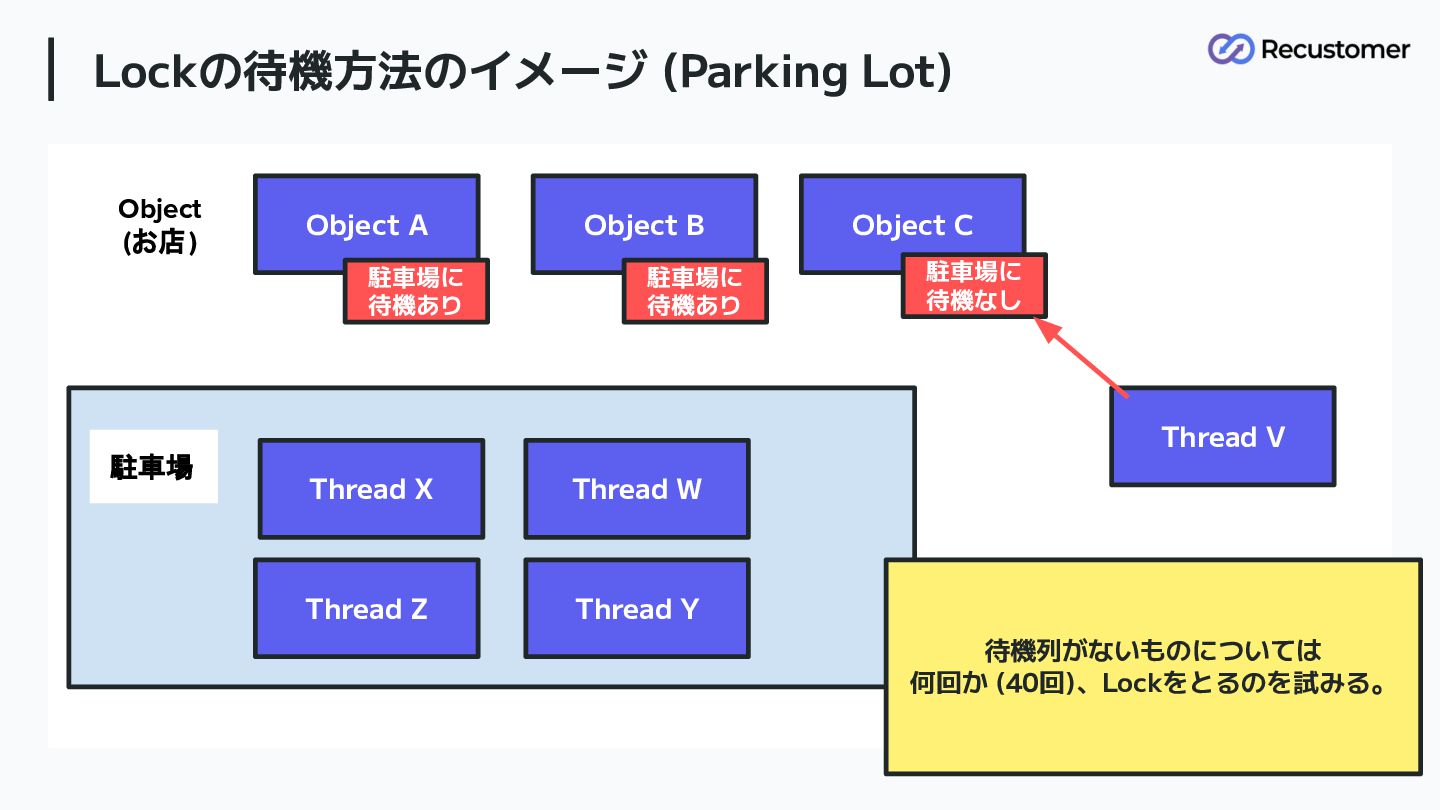
Lockの待機方法のイメージ (Parking Lot) 82 Object A Object B Object C
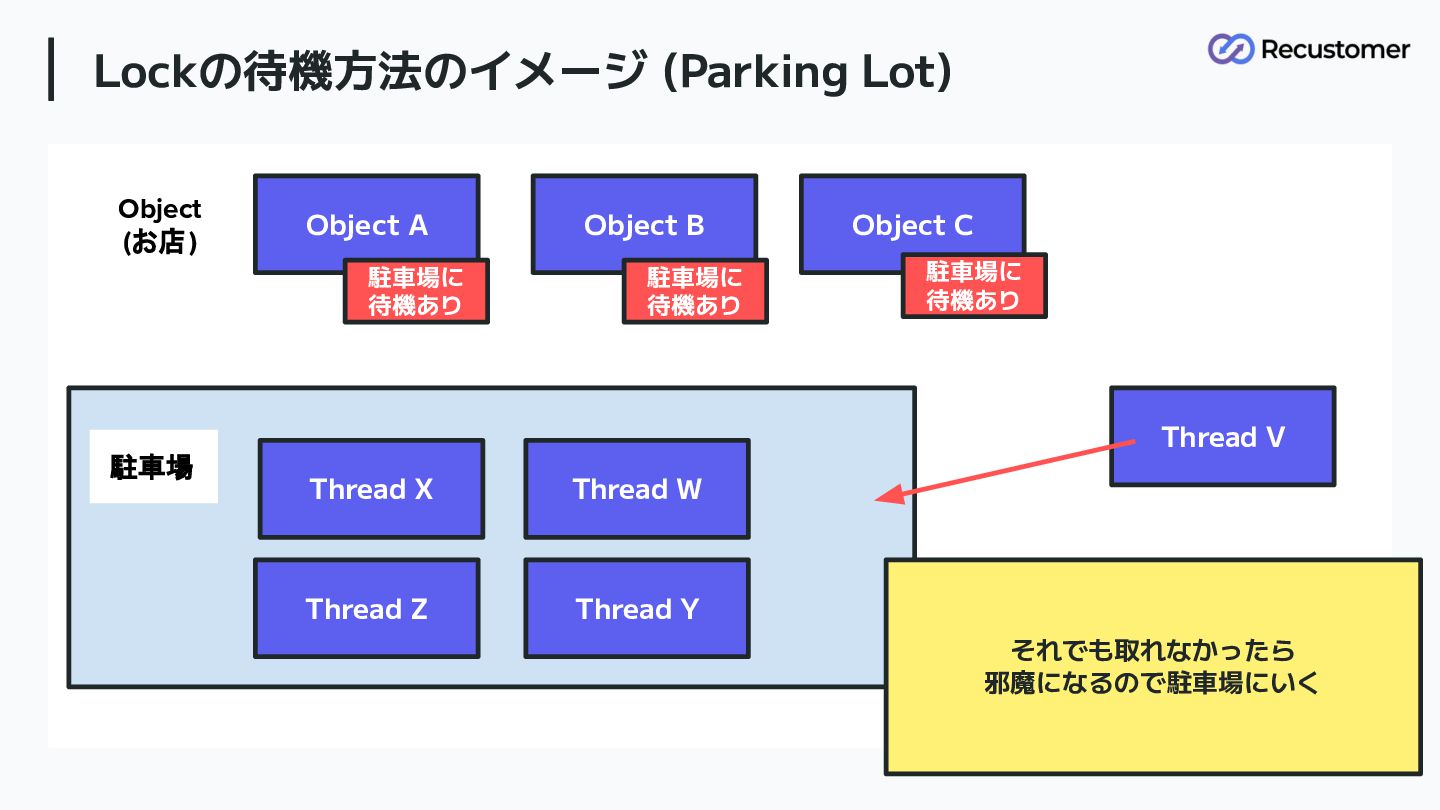
Thread X Thread Y Thread W Thread Z 駐車場 Object (お店) 駐車場に 待機あり 駐車場に 待機あり 駐車場に 待機なし 待機列がないものについては 何回か (40回)、Lockをとるのを試みる。 Thread V
Lockの待機方法のイメージ (Parking Lot) 83 Object A Object B Object C
Thread X Thread Y Thread W Thread Z 駐車場 Object (お店) 駐車場に 待機あり 駐車場に 待機あり 駐車場に 待機あり それでも取れなかったら 邪魔になるので駐車場にいく Thread V
Parking Lot アルゴリズム APIと名称は WebKit の WTF::ParkingLot (Web Template Framework)と
Linux の futex API に参考にされてつくられたもの 汎用Lockに比べて高速になっており、 Lockを表すサイズも小さい 84 Include/internal/pycore_parking_lot.h
本当は もっともっと語りたい CPython GIL無効化の歴史!!! 85
時間がないので ここまで出てきた キーワードだけ 覚えておきましょう 86
• 参照カウントの領域分割 • QSBR • Objectに1つ1つにLock情報 • 軽量Lockの実装 • ParkingLotアルゴリズム
などの力で NoGIL 実現に至りました 87
細かい話から戻りましょう 88
そもそも我々は 89
GIL無効化を 手に入れるまでの この長い歴史の中 90
CPythonで 複数CPUの恩恵は うけてこなかったのか? 91
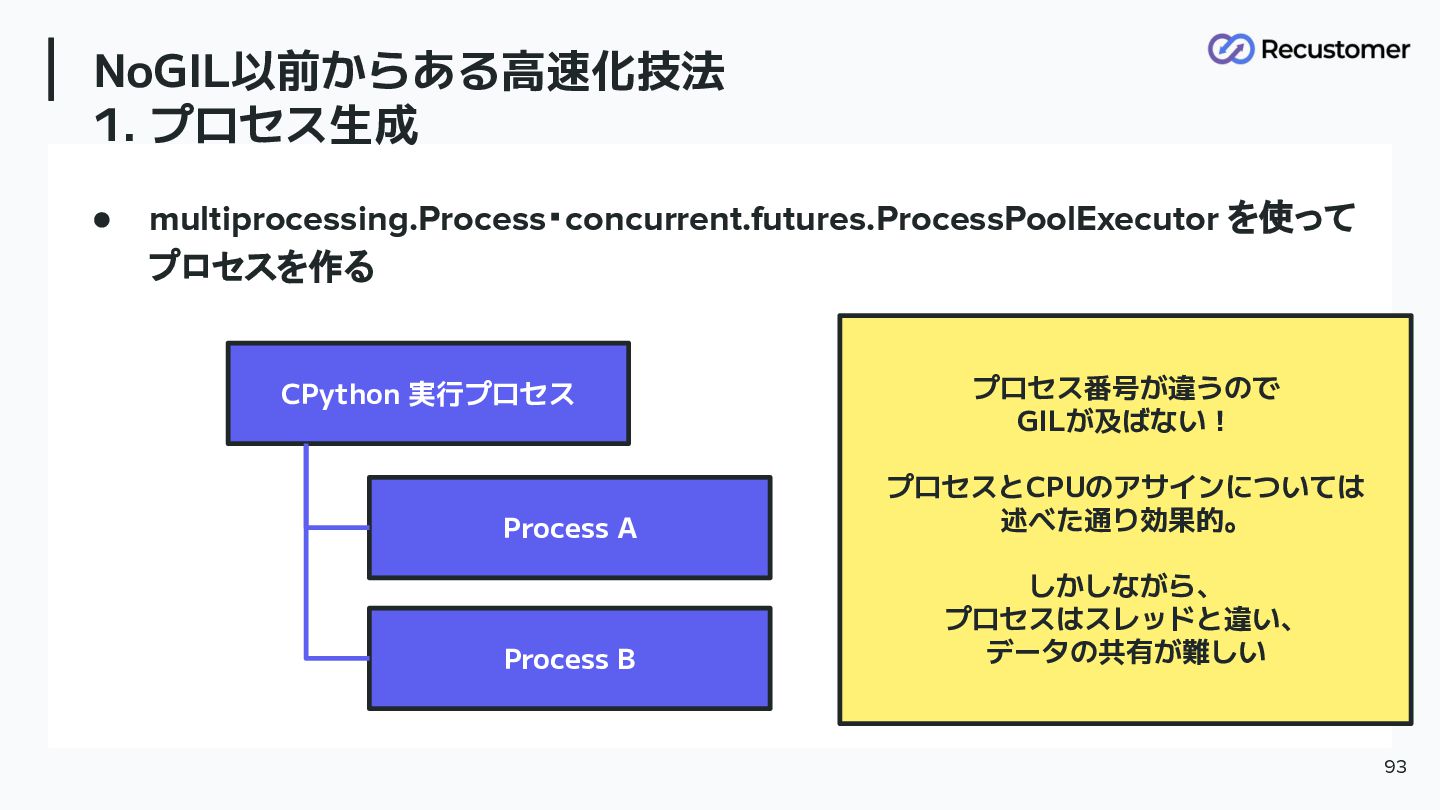
これまでの高速化技術 1. プロセス生成 92
NoGIL以前からある高速化技法 1. プロセス生成 93 • multiprocessing.Process・concurrent.futures.ProcessPoolExecutor を使って プロセスを作る CPython 実行プロセス
Process A Process B プロセス番号が違うので GILが及ばない! プロセスとCPUのアサインについては 述べた通り効果的。 しかしながら、 プロセスはスレッドと違い、 データの共有が難しい
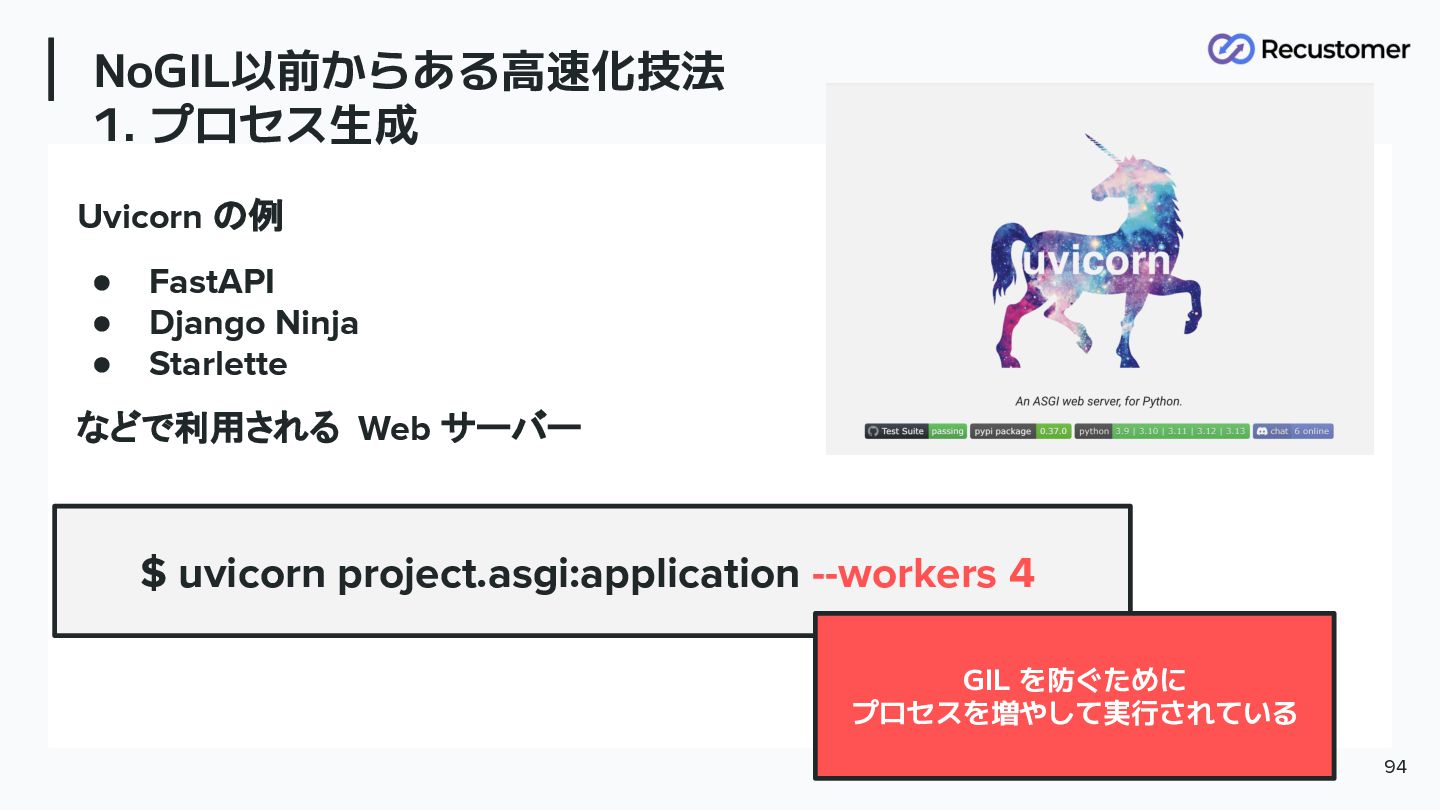
NoGIL以前からある高速化技法 1. プロセス生成 94 Uvicorn の例 • FastAPI • Django
Ninja • Starlette などで利用される Web サーバー $ uvicorn project.asgi:application --workers 4 GIL を防ぐために プロセスを増やして実行されている
これまでの高速化技術 2. マルチCPUに対応した ライブラリに任せる 95
NoGIL以前の高速化 2. マルチコアCPUに対応しているライブラリに任せる 96 • numpy などのライブラリは 複数のCPUコアを用いた計算に対応済み • 特に
numpy に至っては、 BLAS・LAPACK といった 各 CPU に向けてとても チューニングされたライブラリ が呼び出されており、 人力でnumpyの演算より高 速に実行することは極めて難しい。 • 劇的にチューニングされているライブラリには頼ったほうがいい
これまでの高速化技術 3. スレッドがI/Oネック を解消してくれていた 97
NoGIL以前の高速化 3. CPUではなく I/O ネックな処理をスレッドに任せる 98 • あくまでも、 GIL によって並列化できないのは
Python のバイトコード処理 • 裏側の「ネットワーク転送待ち」のような I/O 待ちは GILの影響はなく 、裏側で待 たれるので、スレッドにする価値がある
最後のテーマ 99
同様の問題を抱える Ruby は GIL に どう対応するのか? 100
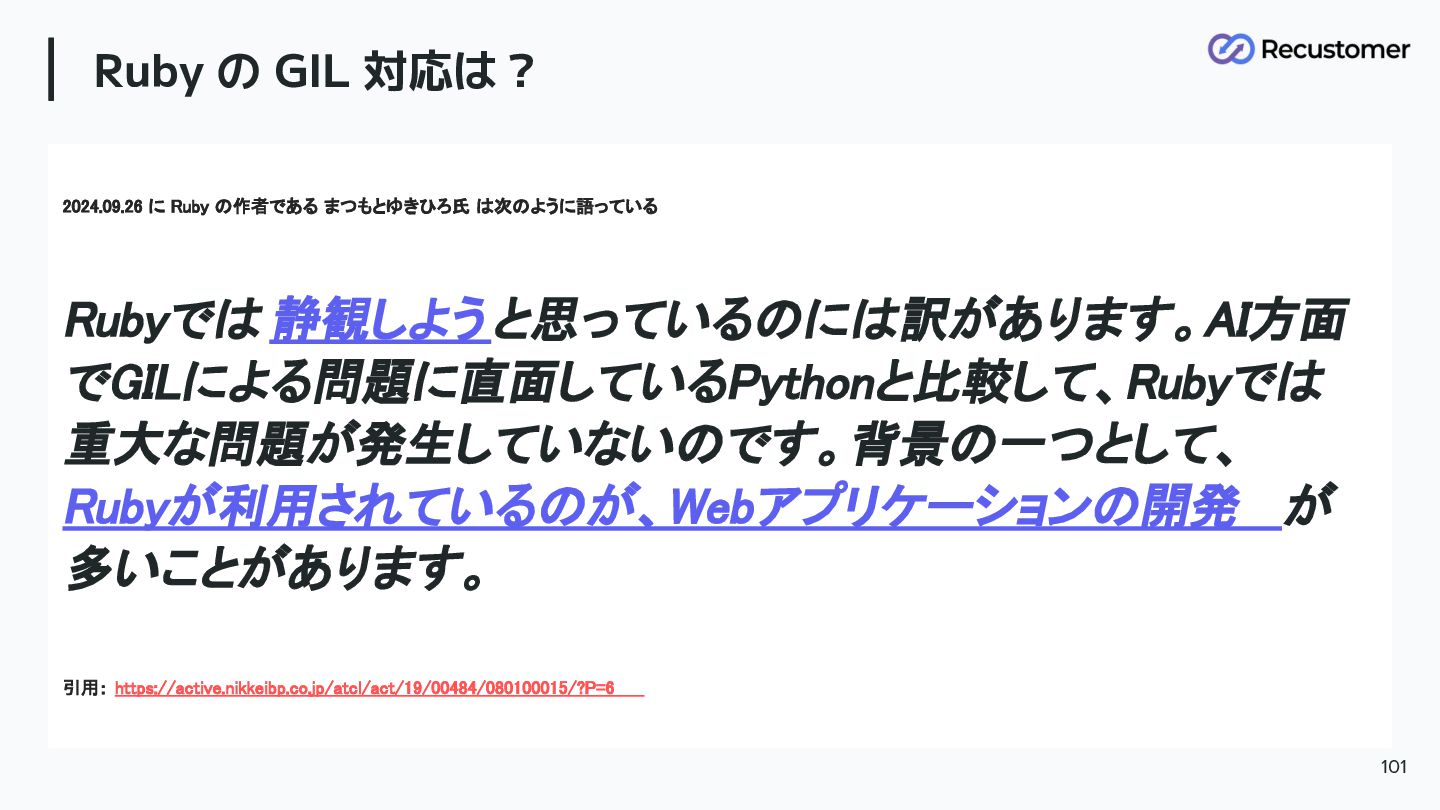
Ruby の GIL 対応は? 2024.09.26 に Ruby の作者である まつもとゆきひろ氏 は次のように語っている
Rubyでは 静観しよう と思っているのには訳があります。AI方面 でGILによる問題に直面しているPythonと比較して、Rubyでは 重大な問題が発生していないのです。背景の一つとして、 Rubyが利用されているのが、Webアプリケーションの開発 が 多いことがあります。 引用: https://active.nikkeibp.co.jp/atcl/act/19/00484/080100015/?P=6 101
つまりは Ruby の立場はこういうこと 102 • Ruby = Web 開発向け •
Web 開発向け = I/O 処理ネックになりがち • GILがあっても I/O 処理は スレッドで高速になる • Webサーバーであればプロセスを独立させることもできるので CPUは活かせる ということなんだと思います
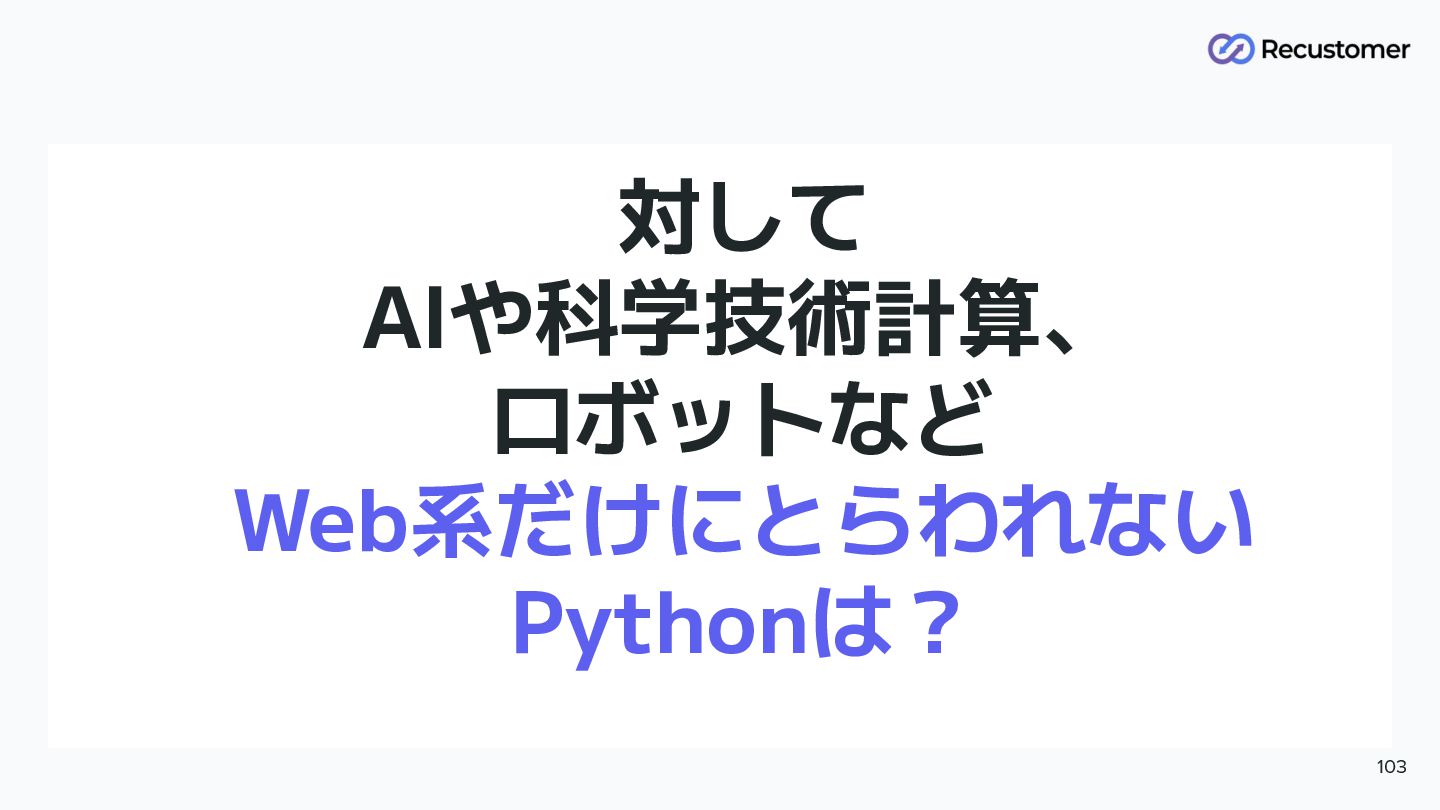
対して AIや科学技術計算、 ロボットなど Web系だけにとらわれない Pythonは? 103
これらの分野はI/Oというより、 本当にCPUがネックになる処理が 求められることも多い 104
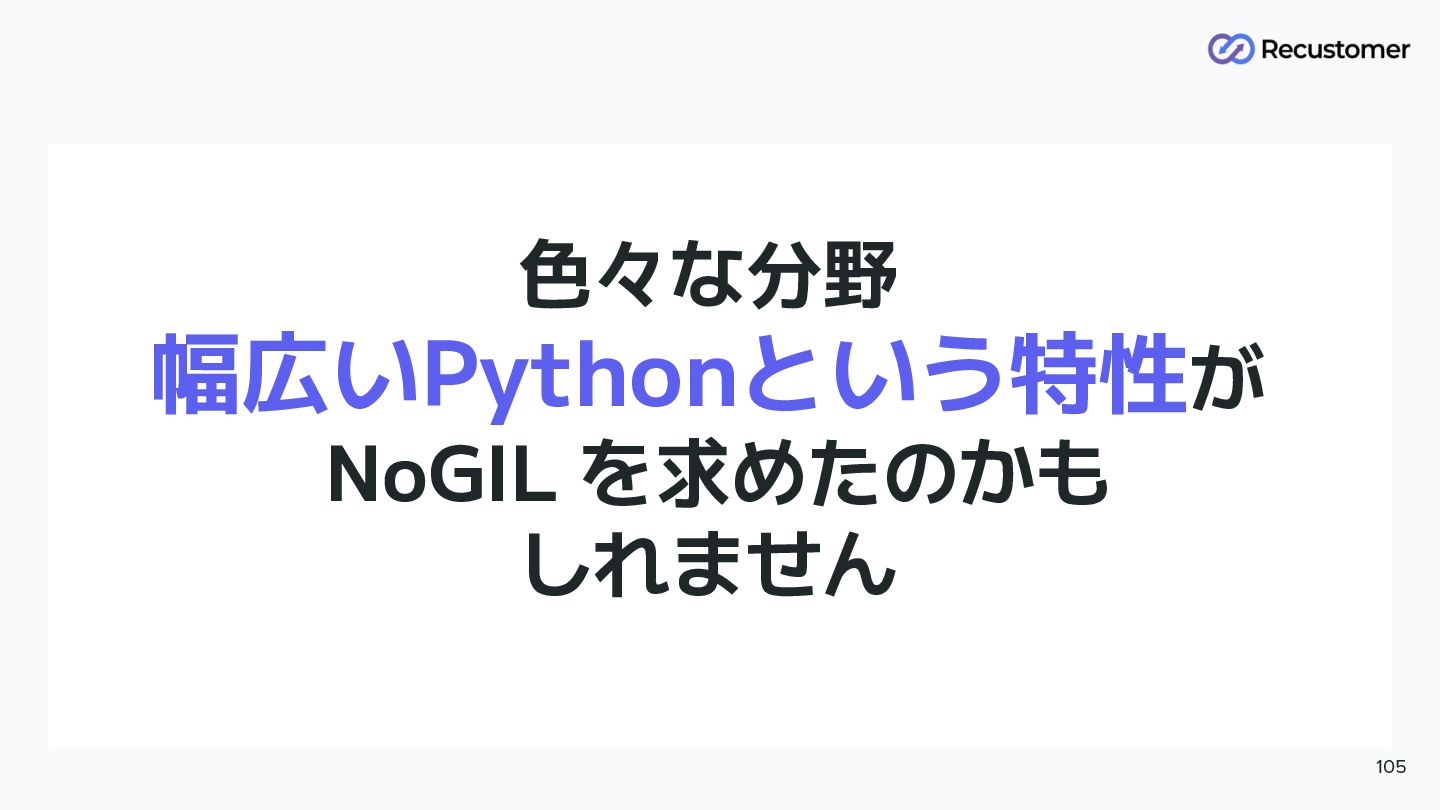
色々な分野 幅広いPythonという特性が NoGIL を求めたのかも しれません 105
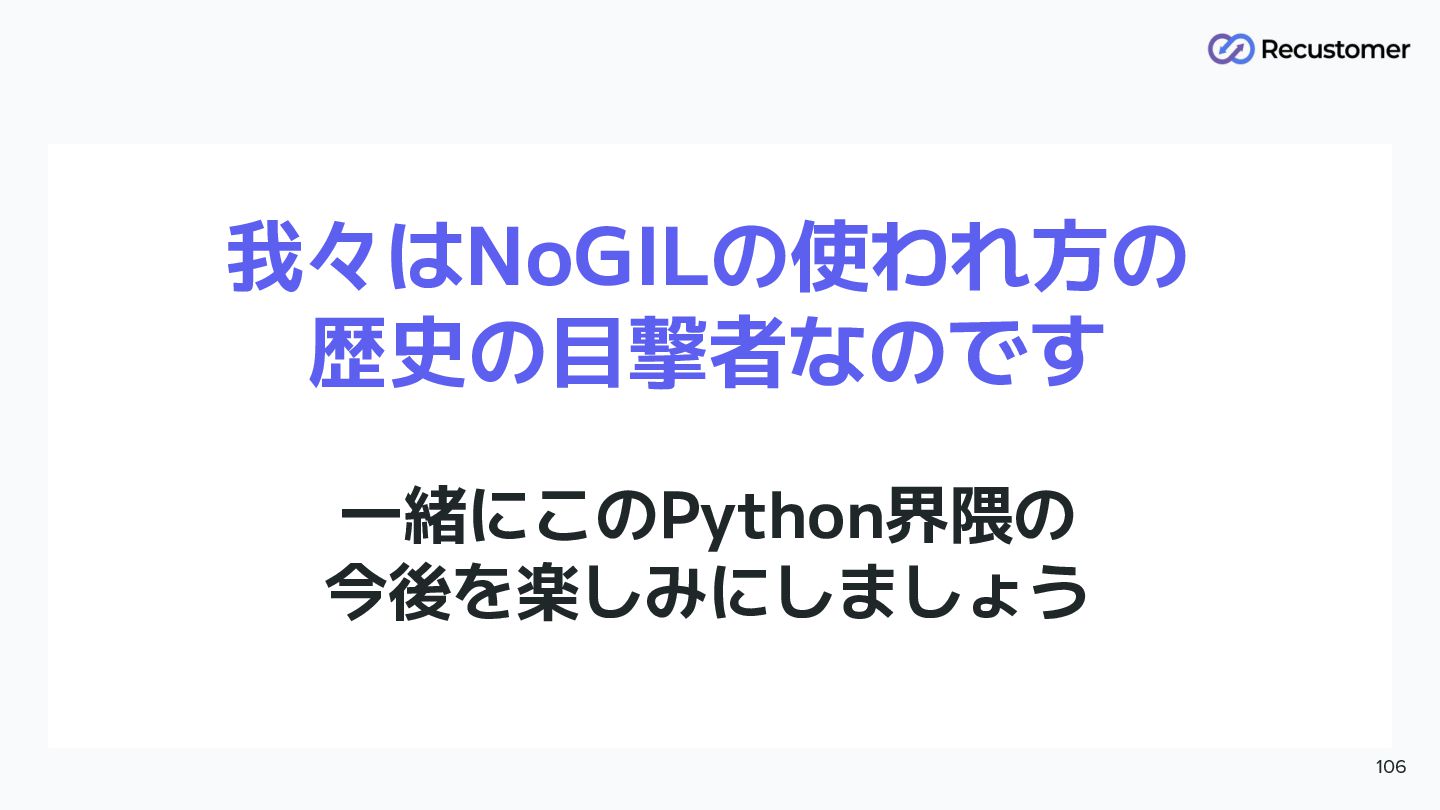
我々はNoGILの使われ方の 歴史の目撃者なのです 一緒にこのPython界隈の 今後を楽しみにしましょう 106
107 エンジニア9名しかいません
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}