Like many companies, Uber launched with a monolithic backend; driver dispatching, receipt processing, and every other business function ran as a component within one application. A few short years later, Uber runs a complex system of more than a thousand microservices. While applications are now simpler to modify and safer to deploy, they’re further removed from the business that they support—even if every service is healthy, Uber can’t be sure that riders in each city are able to take trips.
If you’re planning (or in the midst of) a transition to microservices, you’ll need a strategy to deal with the same challenge: your system architecture no longer matches your business. How can you reassemble the metrics from your microservices to confidently monitor the messy world of business outcomes? How can you strike the right balance between catching outages and avoiding midnight pages?
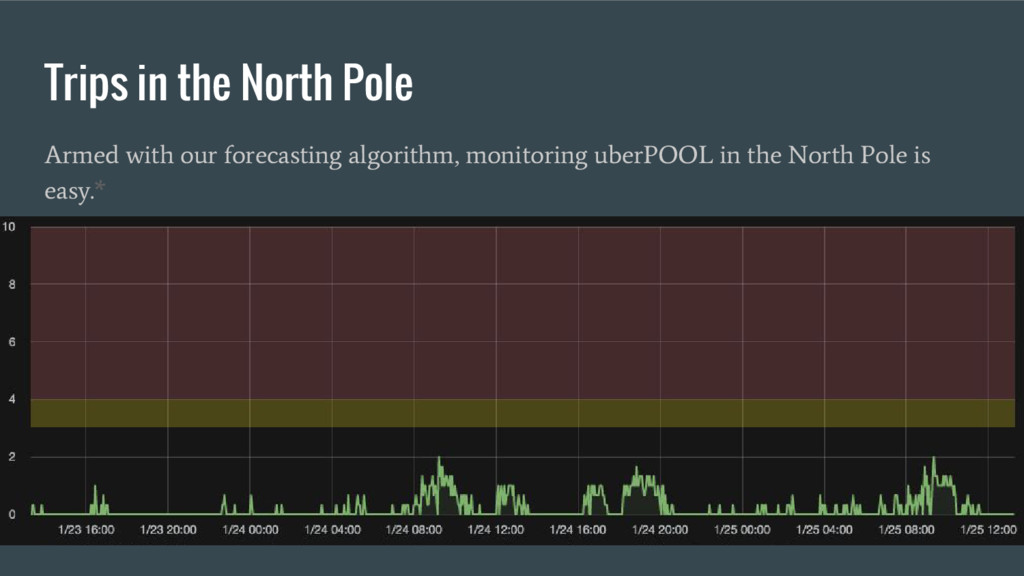
Akshay Shah and Michael Hamrah share the challenges Uber faced when monitoring business outcomes instead of engineering metrics and why building an anomaly detection system to solve those problems is easier than you might expect. Akshay and Michael describe how Uber selected which metrics to monitor and why traditional software monitoring tools don’t work for business metrics. They also offer an overview of Uber’s scalable, low-noise, highly accurate anomaly detection system, highlighting the design trade-offs made to prioritize simplicity and performance.
{kind=link}
![Akshay Shah [email protected] @akshayjshah Michael Hamrah [email protected] @mhamrah](https://files.speakerdeck.com/presentations/aa8186d1852b414e9c6d058bbb52160e/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Akshay Shah [email protected] @akshayjshah Michael Hamrah [email protected] @mhamrah Thanks! http://eng.uber.com/](https://files.speakerdeck.com/presentations/aa8186d1852b414e9c6d058bbb52160e/slide_25.jpg){kind=link}