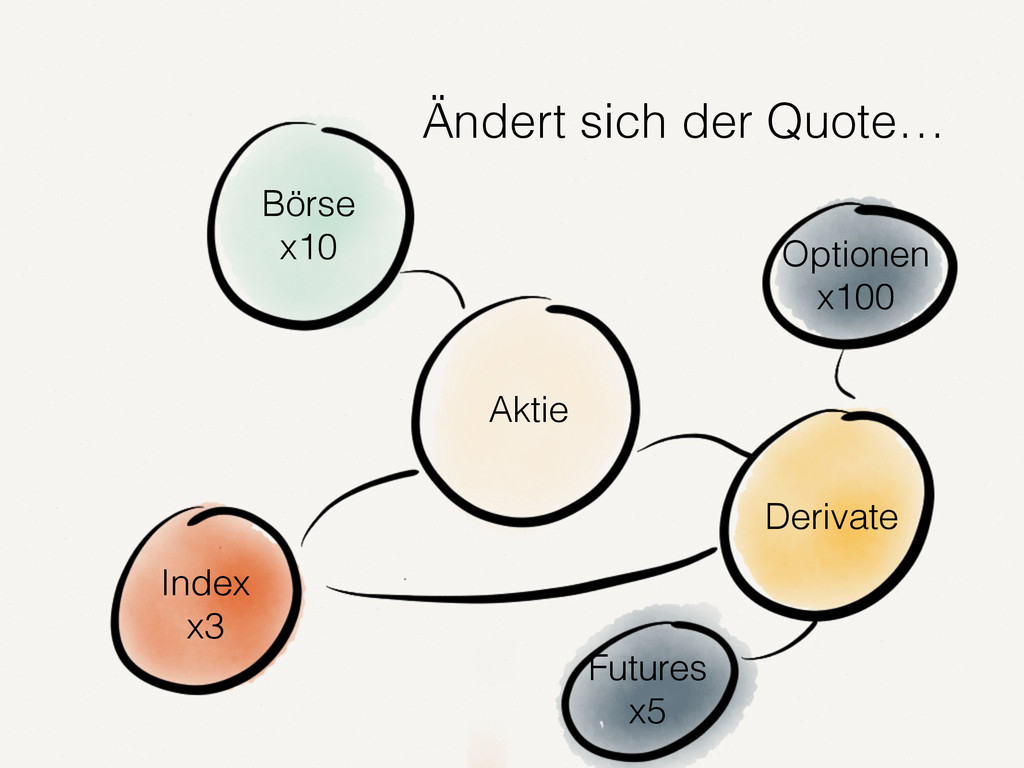
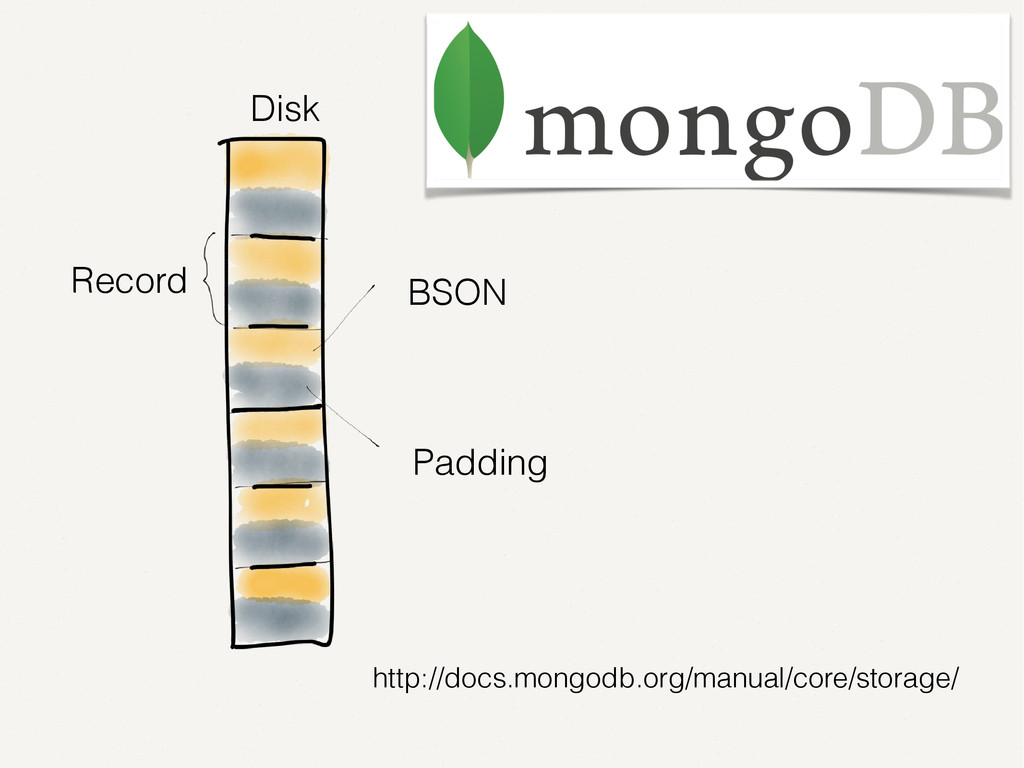
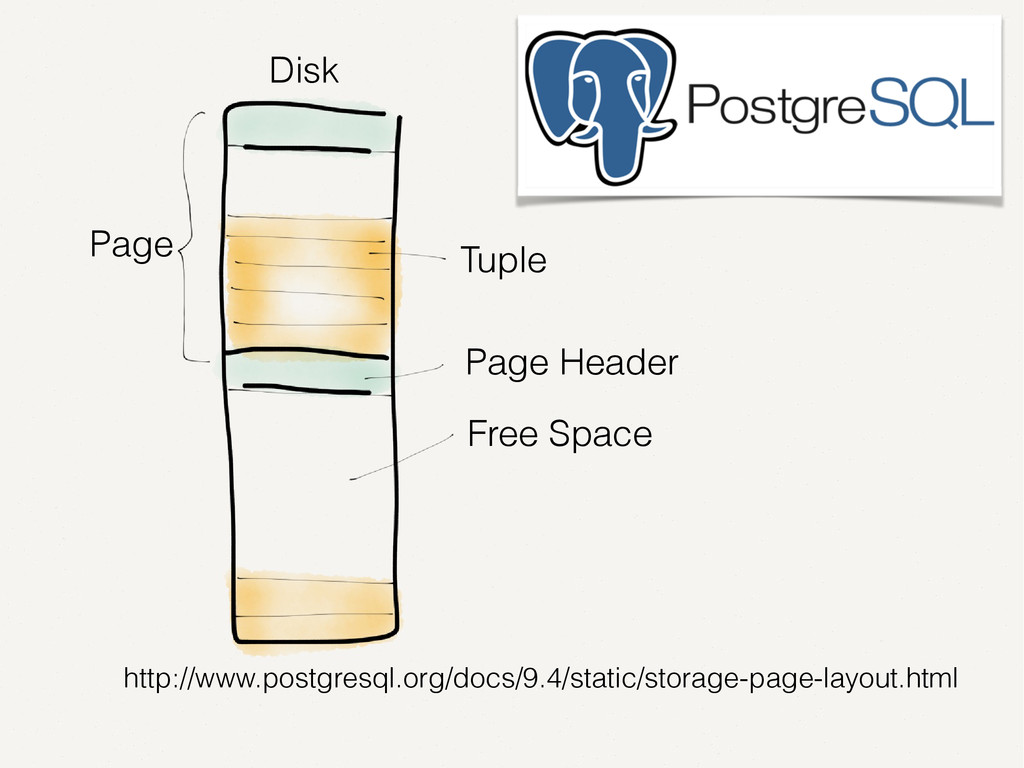
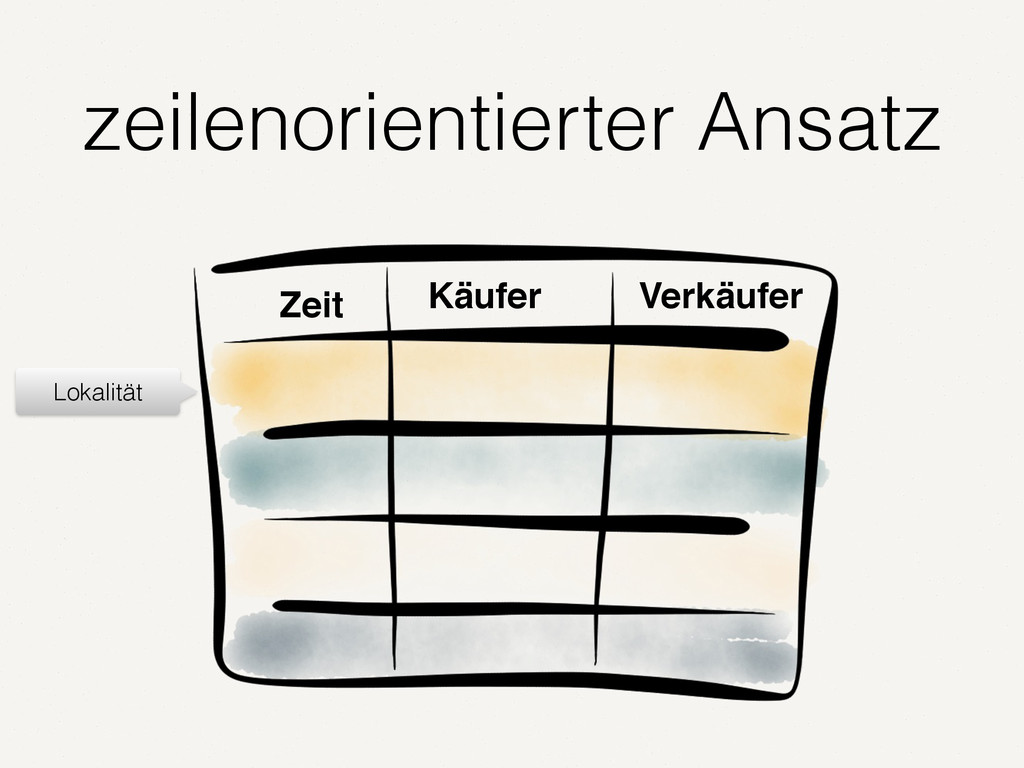
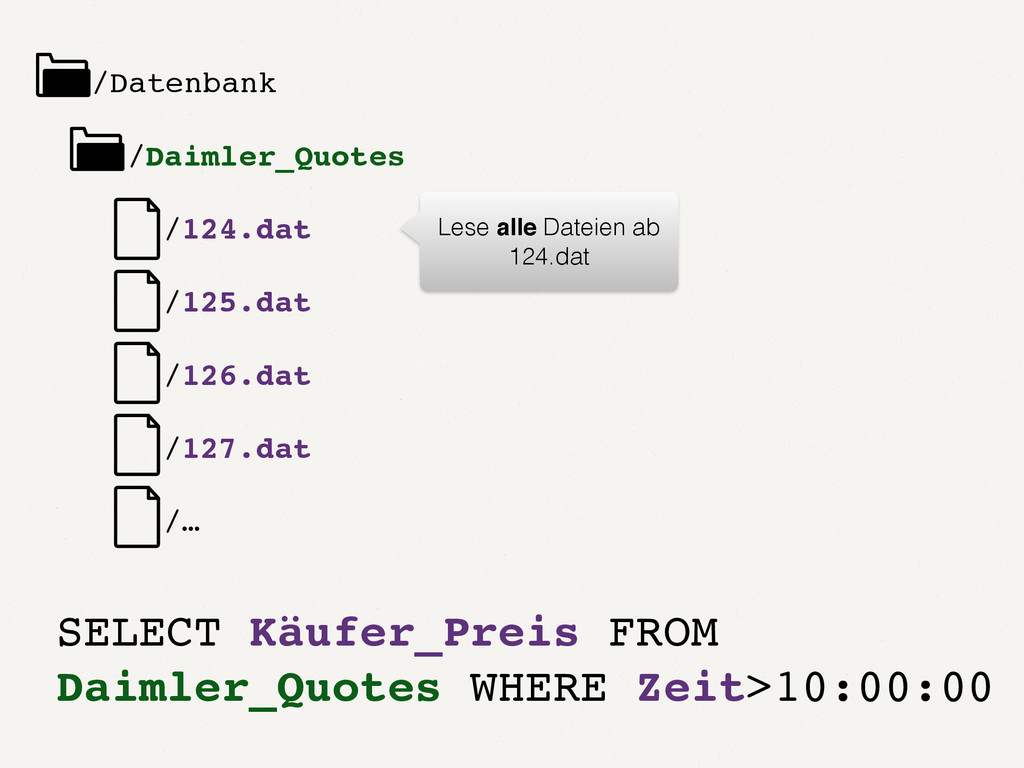
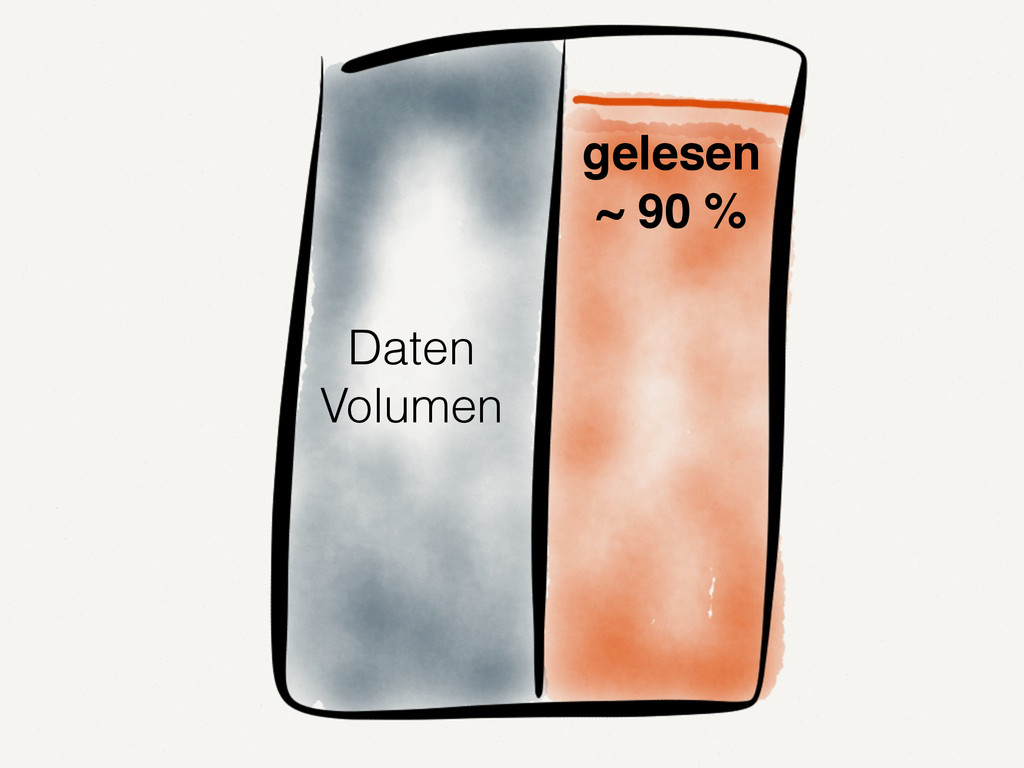
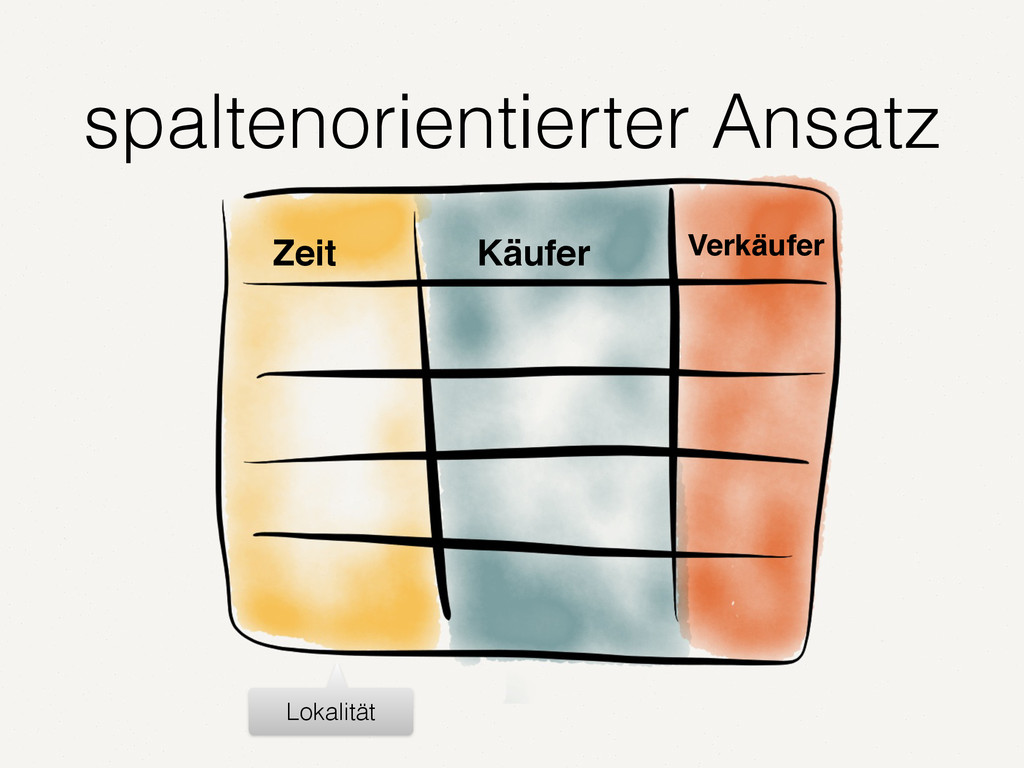
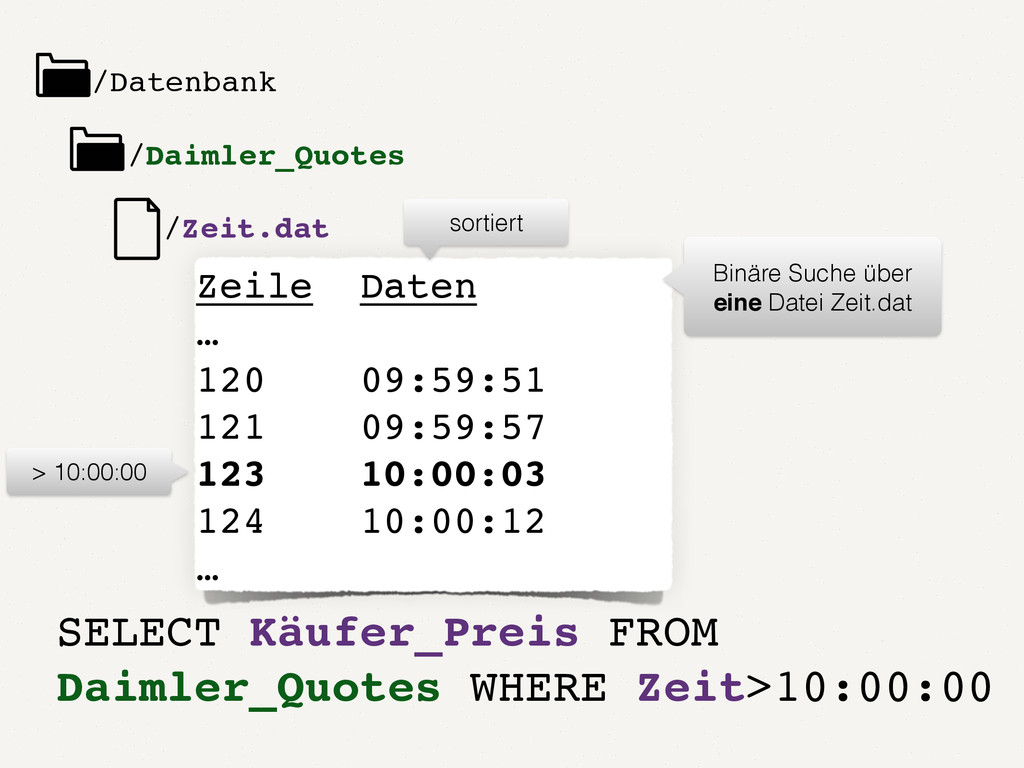
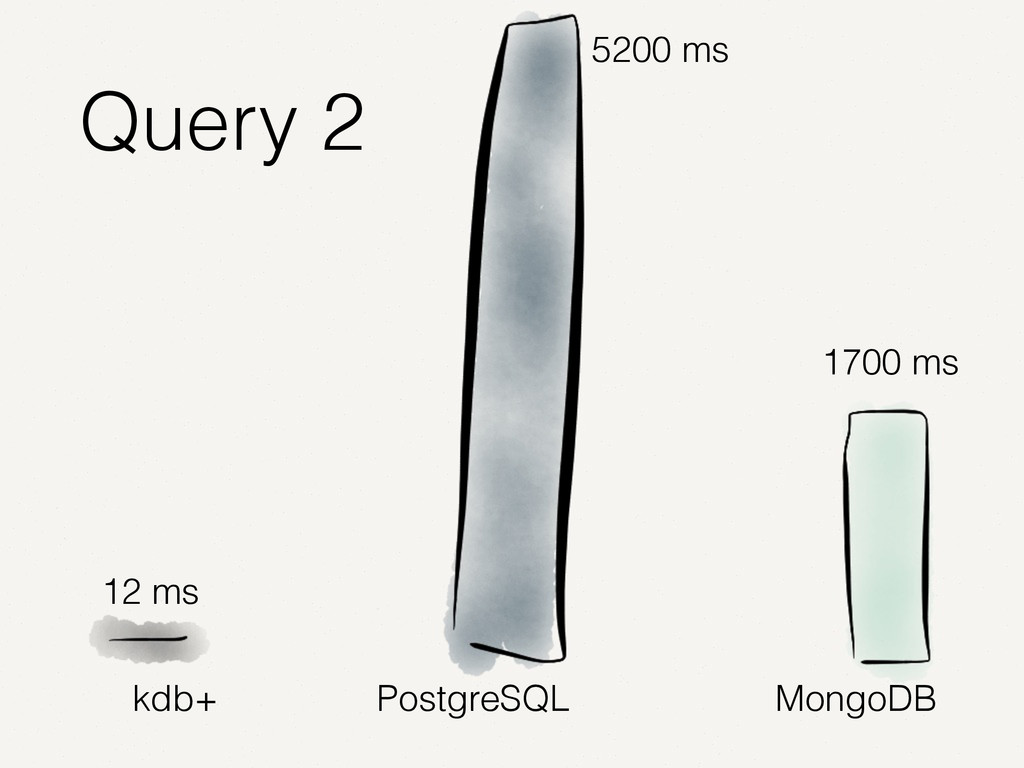
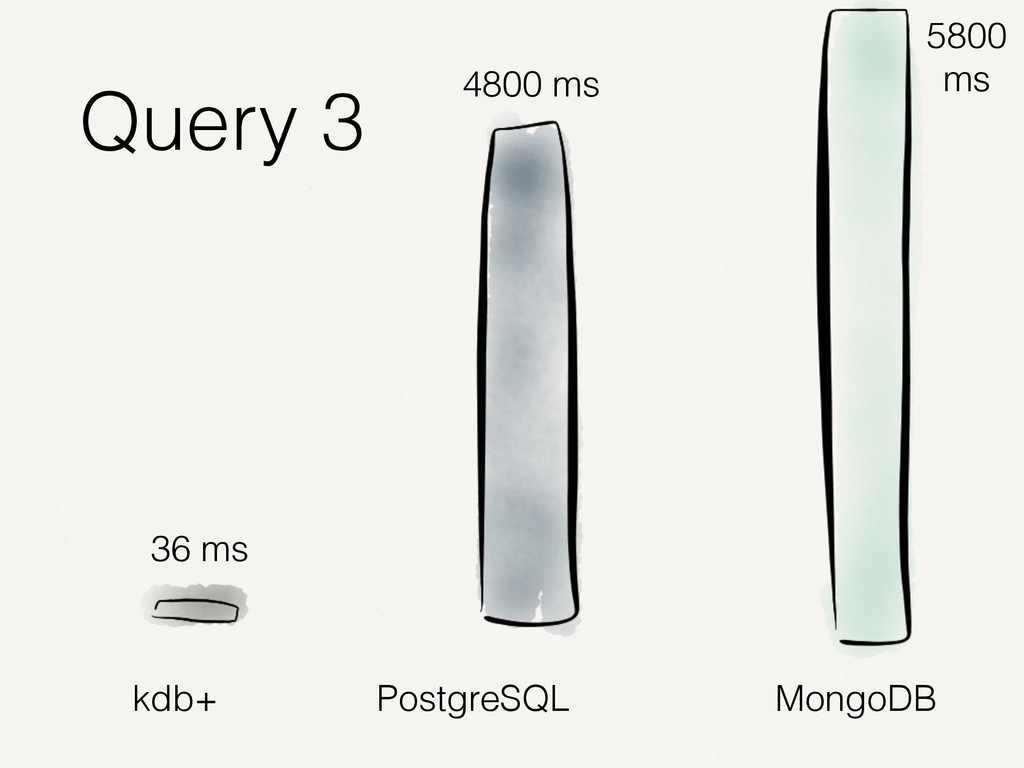
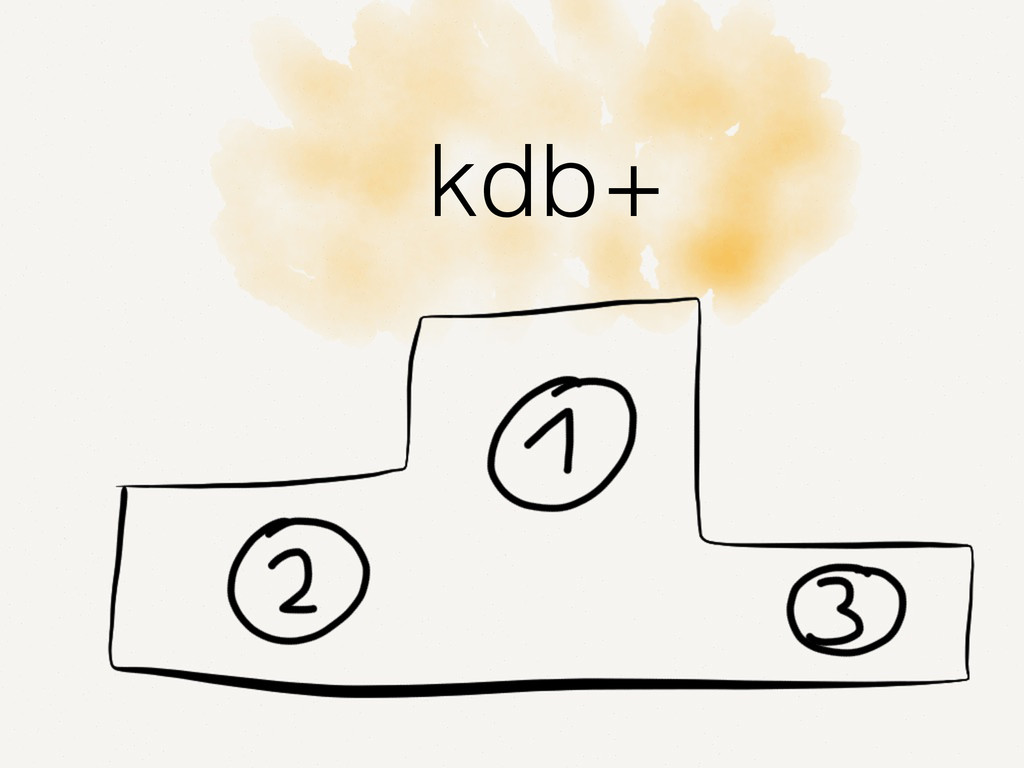
Wir alle kennen und schätzen SQL- und NoSQL-Datenbanken. Doch es gibt Anwendungsfälle, in denen diese Datenbanken an ihre Grenzen stoßen. Zum Beispiel bei der Analyse von Finanzmarktdaten. Dort müssen Zeitreihen von enormer Größe verarbeitet werden. Der Vortrag zeigt auf, wie spaltenorientierte Datenbanken dieses Problem lösen. Die Architektur solcher Tick-Data-Systeme wird beleuchtet. Der Vortrag endet mit dem Beispiel einer technischen Implementierung für Finanzmarktdaten.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![http://manning.com/wittig Michael Wittig [email protected] SaaS Zeitreihendatenbank TimeSeries.Guru 40% Rabatt Code](https://files.speakerdeck.com/presentations/5bdf848a6fda474ba25cb45656a9f4f7/slide_68.jpg){kind=link}