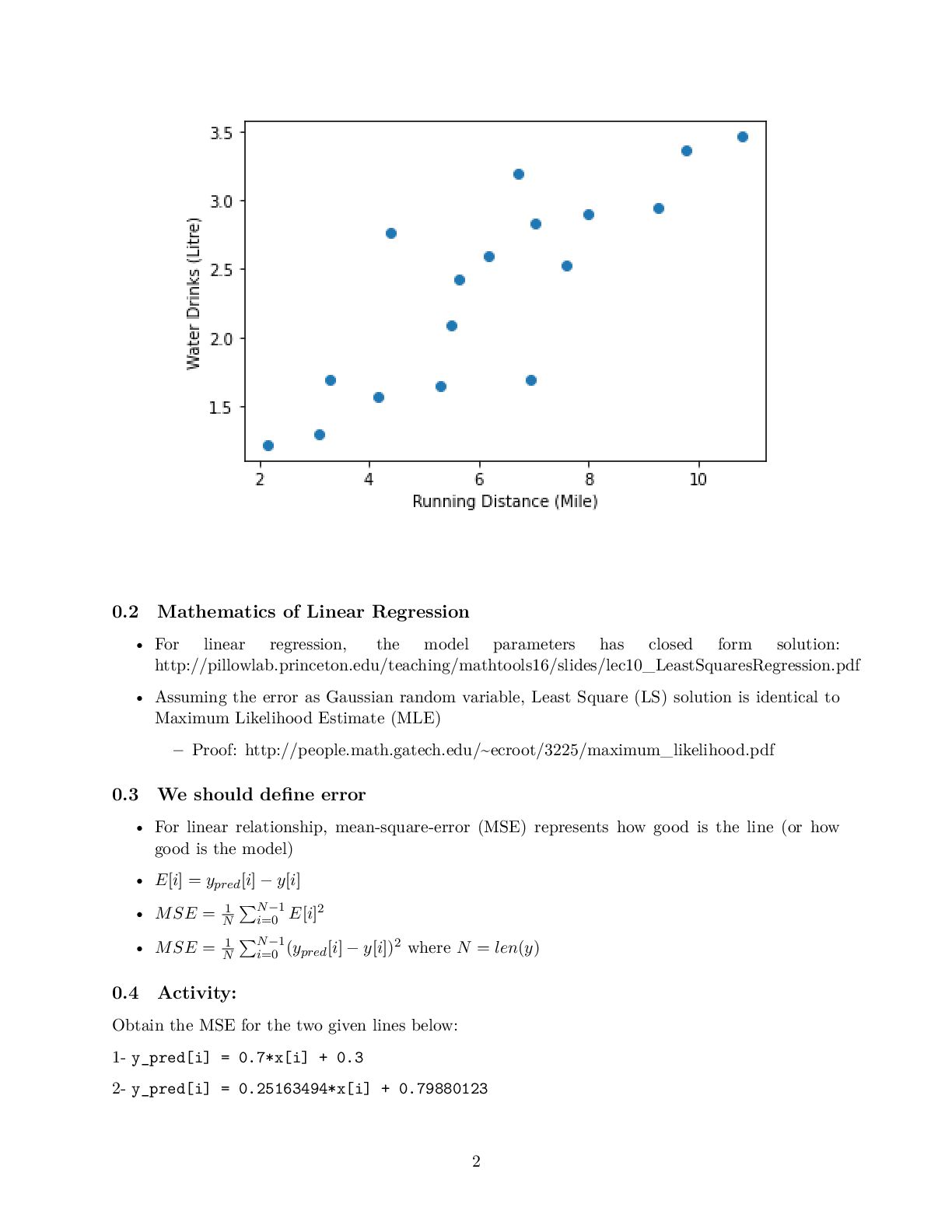
to present the relationship between variables (features and target) linearly • For simplicity, consider we have one feature denoted as the running distance and target variable know as drinking water • We are interested to obtain the best line describing by y_pred[i] = w_1 x[i] +w_0 that map running distance (x[i]) to drinking water estimation (y_pred[i]) while we know, y[i], the true values for drinking water • Then, when we only know the running distance, the model can predict the amount of water that the runner would drink [3]: import numpy as np import matplotlib.pyplot as plt # Running Distance in Mile x = np.array([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167, 7.042,10.791,5.313,7.997,5.654,9.27,3.1]) # Water Drinks in Litre y = np.array([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221, 2.827,3.465,1.65,2.904,2.42,2.94,1.3]) plt.scatter(x, y) plt.xlabel('Running Distance (Mile)') plt.ylabel('Water Drinks (Litre)') [3]: Text(0, 0.5, 'Water Drinks (Litre)') 1
{kind=link}
{kind=link}
{kind=link}
![[11]: predicted_y_values = list(map(lambda i: 0.25163494*i + 0.79880123, x)) plt.scatter(x,](https://files.speakerdeck.com/presentations/79e9ce595b9b489e9b8244fc2b984df0/slide_3.jpg){kind=link}
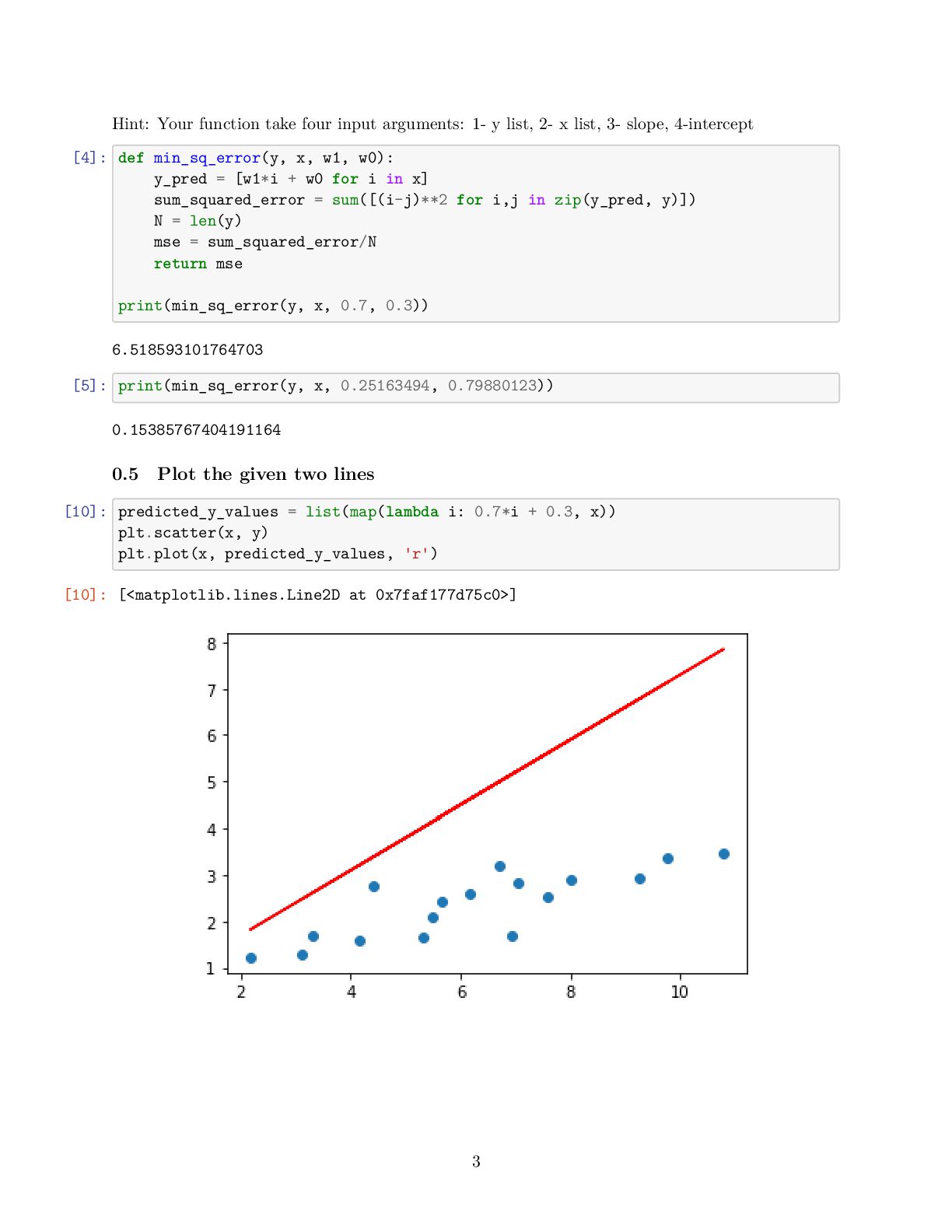
![0.7 Activities: [3]: from scipy import stats slope, intercept, r_value,](https://files.speakerdeck.com/presentations/79e9ce595b9b489e9b8244fc2b984df0/slide_4.jpg){kind=link}
![[17]: print(intercept) 0.7988012261753894 [18]: print("r-squared:", r_value**2) r-squared: 0.6928760302783604 [4]: print(std_err)](https://files.speakerdeck.com/presentations/79e9ce595b9b489e9b8244fc2b984df0/slide_5.jpg){kind=link}
![or `histplot` (an axes-level function for histograms). warnings.warn(msg, FutureWarning) [20]:](https://files.speakerdeck.com/presentations/79e9ce595b9b489e9b8244fc2b984df0/slide_6.jpg){kind=link}
![[50]: def slope_intercept_LR(x, y): w1 = (np.mean([i*j for i, j](https://files.speakerdeck.com/presentations/79e9ce595b9b489e9b8244fc2b984df0/slide_7.jpg){kind=link}
![x = np.array([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167, 7.042,10.791,5.313,7.997,5.654,9.27,3.1]) # Water Drinks in Litre y](https://files.speakerdeck.com/presentations/79e9ce595b9b489e9b8244fc2b984df0/slide_8.jpg){kind=link}
![print(lr_reg.coef_) print(lr_reg.intercept_) [0.25163494] 0.7988012261753894 10](https://files.speakerdeck.com/presentations/79e9ce595b9b489e9b8244fc2b984df0/slide_9.jpg){kind=link}