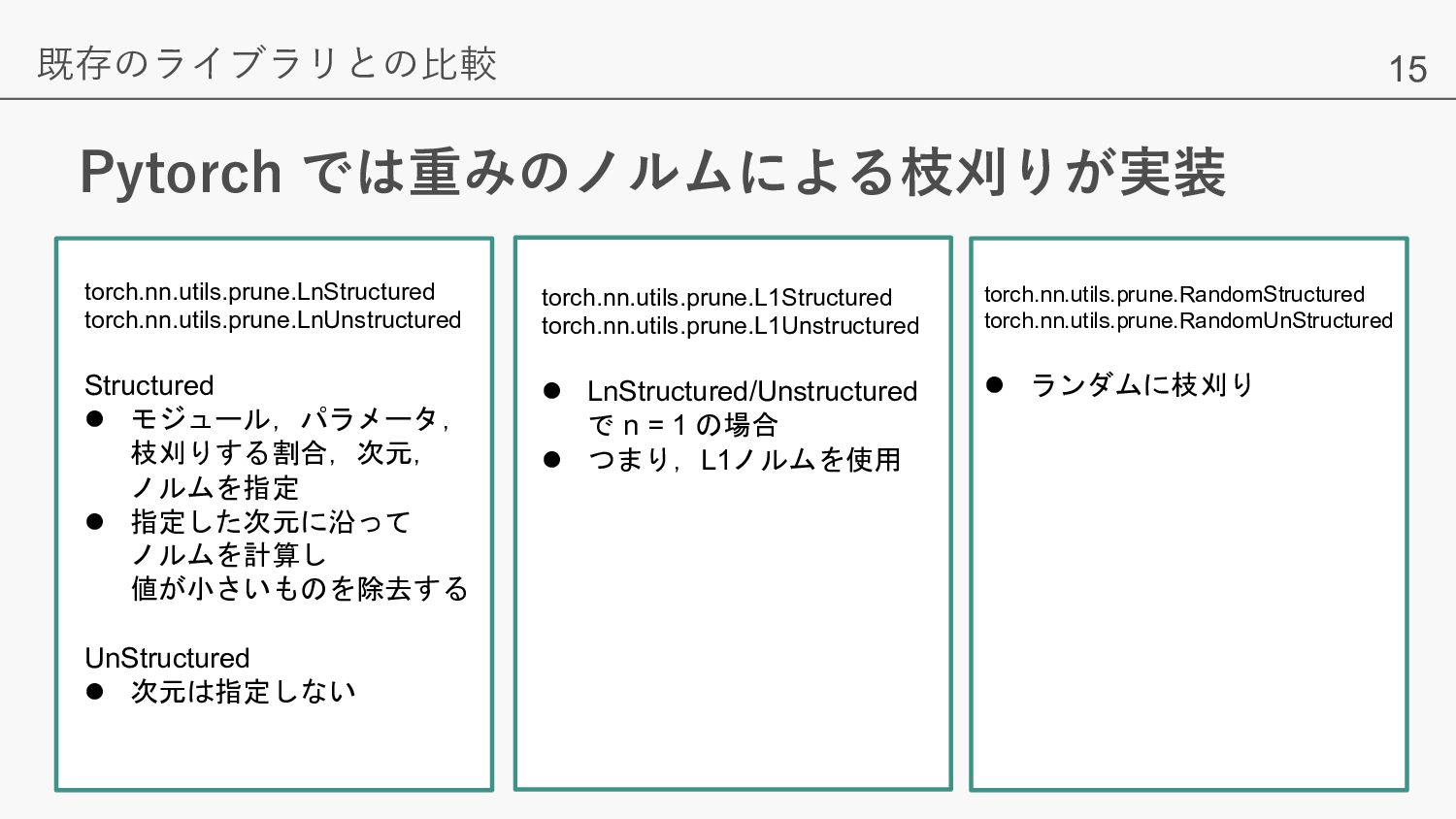
ノルムを指定 l 指定した次元に沿って ノルムを計算し 値が小さいものを除去する UnStructured l 次元は指定しない torch.nn.utils.prune.L1Structured torch.nn.utils.prune.L1Unstructured l LnStructured/Unstructured で n = 1 の場合 l つまり,L1ノルムを使用 torch.nn.utils.prune.RandomStructured torch.nn.utils.prune.RandomUnStructured l ランダムに枝刈り
SQuAD l NLP Hacks でも紹介した QA データセット l 参考: NLP News #2 l preprint: https://arxiv.org/abs/2202.01764 • ベースラインの BERT と実験コードを公開している l HF: hf.co/SkelterLabsInc/bert-base-japanese-jaquad l GitHub: https://github.com/SkelterLabsInc/JaQuAD l ベースラインモデルに対して枝刈りを実施 l 実験に使用した Notebook 実験設定
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}