Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第7回.pdf
Search
miyanishi
February 26, 2013
99
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第7回.pdf
HMMによる日本語形態素解析システムのパラメータ学習
miyanishi
February 26, 2013
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
文献紹介15年08月
miyanishi
0
240
15年7月文献紹介
miyanishi
0
270
Featured
See All Featured
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
330
GraphQLとの向き合い方2022年版
quramy
50
15k
Navigating Team Friction
lara
192
16k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
370
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
220
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
300
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
280
Building AI with AI
inesmontani
PRO
1
1.1k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Crafting Experiences
bethany
1
170
My Coaching Mixtape
mlcsv
0
140
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
180
Transcript
宮西 由貴 HMMによる 日本語形態素解析システムの パラメータ学習 1
JUMANのコスト 品詞の連接と単語にコストを付与 曖昧性の絞り込みが目的 コスト値は解析精度に大きく影響 欠点
ユーザが値を決定 目的のコーパスに人手でコストを作成 2
関連研究 3 コスト値を機械学習 英語 HMMで求める⇒精度96% 日本語
解析済みコーパスが無い分野では学習できない 文法が統一されていないので利用できないこともある
提案するシステム 4 JUMAN-HMMシステム コーパスによって学習⇒コスト値の最適化を実現 初期値の獲得:少量のタグ付コーパスを使用 学習:タグなしのコーパスを使用
大規模タグ付コーパスがない分野でも学習可能 今回は新聞記事を使用
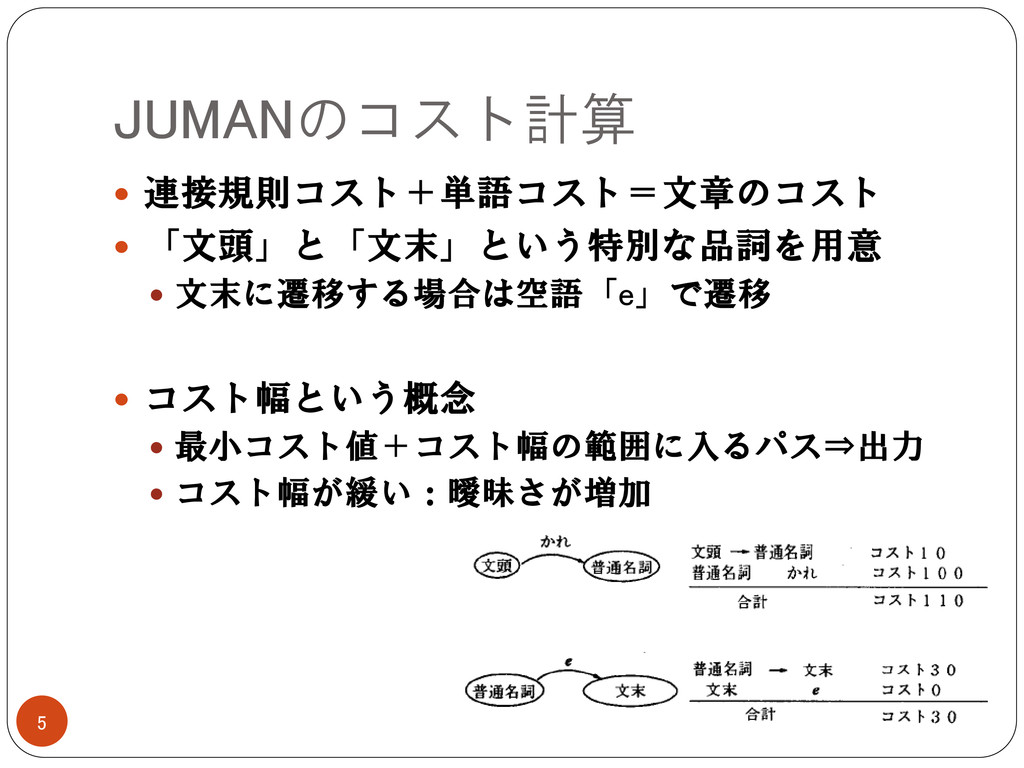
JUMANのコスト計算 5 連接規則コスト+単語コスト=文章のコスト 「文頭」と「文末」という特別な品詞を用意 文末に遷移する場合は空語「e」で遷移 コスト幅という概念
最小コスト値+コスト幅の範囲に入るパス⇒出力 コスト幅が緩い:曖昧さが増加
HMMの定式化 6 ある入力文字列Lから得られる単語列 1, = 1 , 2 ,
⋯ , 品詞系列 t = 1 , 2 , ⋯ , 入力列Lに対する確率 P L = (1,+1 ) 1,+1∈ = ( |−1 ) +1 =1 0,+1 1,+1∈ 0 :文頭 n+1 :文末
学習 7 通常のHMM あらゆる可能な状態遷移パスの確率を計算 今回のHMM コスト幅を緩めて出現する範囲のパスの確率を計算
計算量が少なくて済む 明らかにおかしな解釈を学習の対象から外す
学習で用いるパラメータ 8 :品詞接続確率 :とある品詞での単語 の出現確率 :1文中の番目の単語における 文頭から品詞までの確率の総和
+ 1 :文末から品詞jまでの確率の総和
JUMAN-HMMシステム 9 タグ付コーパスからマルコフ学習 ⇒単純に頻度を数えて初期値を取得 得られた確率値をHMMに、 コスト値に変換した値をJUMANに送信 大量のコーパスを用意
JUMANにコスト幅を許して解析 HMMで出現頻度を初期値から計算 コーパスの解析終了後、確率値を再推定
JUMAN-HMMシステム 10 再推定された確率値をコスト値に変換 ⇒JUMANに与えコーパスに対して学習 値が安定したところで学習を中止 JUMANは辞書引きの役目のみ
HMMには独自に確率値を保存 辞書にコスト値を書き込む際の丸め誤差を 再推定の計算に繰り越さないため
HMMノードの作成 11 JUMANの文法 品詞、品詞細分類、活用型、活用形、表層の基本形 原則:HMMのノードは品詞細分類を採用 例外
前方の単語が活用する: 前方から連接確率を計算⇒品詞細分類まで観測 後方から連接確率を計算⇒活用形まで観測 助詞・助動詞: 表層語まで区別して個別のノード
注意 12 未定義後の扱い サ変名詞として扱う(JUMANと同じ) 各連接確率を再評価する際には使用しない 確率の最小値
コーパス中に1回もその規則や単語が出ない =確率は0である コスト値に変換するため低い確率値を与える
実験(初期値獲得実験) 13 初期値:連接確率&単語確率 学習に大きな影響を与える 初期値の獲得実験の手法 A
EDR解析済みコーパスを用いる 直接変換が容易でないため、分かち書き情報のみ使用 B 社説をJUMANに解析させた結果を用いる 学習に用いるコーパスと同じものを使用 C 社説を人手によって解析した結果を用いる A,Bよりデータが少量(300文-6700形態素) D 現在のJUMANのコストを直接変換 JUMANの精度と等価
実験(初期値獲得実験) 14 評価 朝日新聞解析済み社説2種類を使用 300文(6700形態素)と200文(5000形態素) 300文は手法Cで初期値として使用
正誤の判断 一意に正解を記述している解析済みコーパスと比較 品詞細分類又は活用形まで観測 一つでも異なれば不正解 1形態素で正解を2つに分割 ⇒誤り数2 EDR以外の 初期値獲得方法を使用する
実験(学習実験) 15 初期値はB~Dの方法を採用 Bについては社説3年分(6.5万語)を使用 学習コーパス:朝日新聞社説9年分(20万語) コスト幅:無駄な解析が出ない程度
実験(学習実験) 16 Dの結果が悪い 学習前はJUMANと同程度の解析精度有 第1候補以外の候補に誤った例が多数 第1候補以外には統計的に合致した順序を保証しない
学習することで正解だった第一候補まで確率値が下がる Bの社説3年分の学習結果も悪い 現在のJUMANの誤りが学習によって強化 第2候補以降に内在していたものが強化された JUMANのコスト値の与え方の悪さが響く 学習による自動修正は不可
実験(学習実験) 17 Cの誤りは少し異質 少数の正解のみの初期値しか保持していない Inside:このモデルの最適値まで誤りが減少 Outside:初期値にない未知の連接規則・単語による誤り
少量の正解が未知の連接規則・単語に対して 正しい方向に引き込む機構
まとめ 18 現在のJUMANより正解率が少し向上 以下の2点がHMM学習に必要 最適なパラメータ値は分野によって異なる ⇒対象分野の解析済みコーパスが少量必要である
解析済みコーパスは量を増やすより 誤りの種類の絶対数が少ないことが大切である 今後の課題 モデルのチューニングを行う 様々な分野に対する実験を行う
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}