Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第8回.pdf
Search
miyanishi
March 04, 2013
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第8回.pdf
コスト最小法と確率モデルの結合による形態素解析
miyanishi
March 04, 2013
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
文献紹介15年08月
miyanishi
0
240
15年7月文献紹介
miyanishi
0
270
Featured
See All Featured
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
240
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
GraphQLとの向き合い方2022年版
quramy
50
15k
Paper Plane (Part 1)
katiecoart
PRO
0
8.8k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.3k
Evolving SEO for Evolving Search Engines
ryanjones
0
210
Building Flexible Design Systems
yeseniaperezcruz
330
40k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
360
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
300
Transcript
宮西 由貴 コスト最小法と確率モデルの 統合による形態素解析 1
最適解の選択手法(1) 制約・優先規則を使用(人手) 言語現象を規則などの形に抽象化する 長所 記述量や理解の容易さにおいて効率が良い
制約・優先規則=経験の蓄積=有益な資源 短所 記述者の考慮外の現象は捕えきれない 改善策 例外的な現象を規則に追加・修正し、精度を上げる 規則が複雑=保守や管理が人間の手に負えない 追加・修正による影響が予想不能=精度向上が困難に! 2
最適解の選択手法(2) 確率パラメータを使用(機械学習) 品詞タグ付きコーパスから学習する 長所 手間や解析精度の問題をある程度解決する
欠点 大量のタグ付きコーパスが必要になる 未開拓な文やでは不向き 3
提案手法の概要 目的 未開拓な分野で高い解析精度を得る 小規模品詞タグ付きコーパスで高い精度の解析ができる 概要
制約・優先規則と確率パラメータを統合する 有益な言語資源である制約や優先規則 小規模品詞タグ付きコーパスで学習した確率パラメータ 4
本研究の最適解選択手法 人手による制約・優先規則 コスト最小法を使用 品詞タグ付きコーパスから得た確率パラメータ 品詞bi-gramモデルに基づく統計的学習に着目
コスト・パラメータの与え方が異なる どちらも同じアルゴリズムで解くことが可能 ヴィテルビ・アルゴリズムで最適解を選択 5
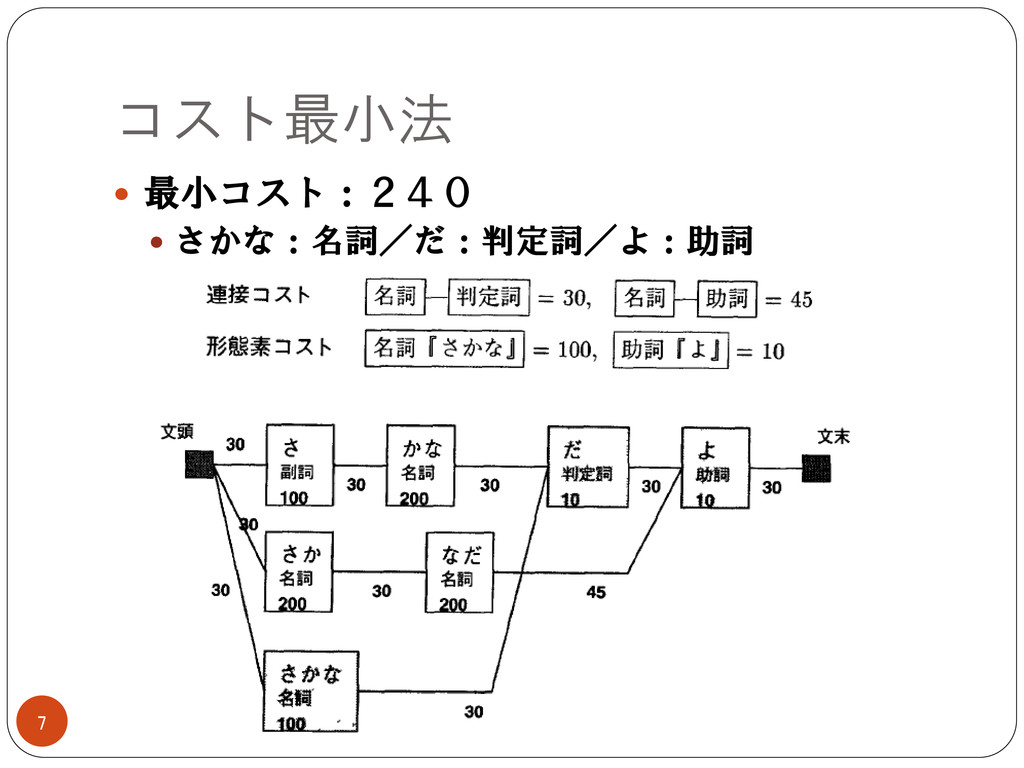
コスト最小法 形態素および形態素間の接続にコストを付与 各形態素間の接続コスト:連接コスト 各形態素に付与されるコスト:形態素コスト コストの合計が最小になる解が優先
コストは人手で付与される場合が多数 形態素コストの付与は大変 品詞ごとにコストを設定(今のJUMANも) 6
コスト最小法 最小コスト:240 さかな:名詞/だ:判定詞/よ:助詞 7
品詞bi-gramモデル 品詞 の次に品詞−1 が現れる確率: −1 [?] 品詞 のとき形態素
が現れる確率:( | ) ↑の確率の積が最大になるパスを優先 P 1 ⋯ ≅ ( | ) −1 i=1 品詞タグ付きコーパスなら最尤推定を使用 名詞が100回出現-直後に判定詞が30回出現 名詞が100回出現-その内「さかな」が5回出現 8
品詞bi-gramモデル 確率の積の最大値:4.5 × 10−7 さかな:名詞/だ:判定詞/よ:助詞 9
二つの手法の関係 コストと確率パラメータは同じ土俵で扱える コストの和を確率の積Pへ変換する Pの逆数の対数を取ったもの 1 = −
log −1 =1 = − + =1 − −1 =1 形態素コスト:− 連接コスト:− −1 10
コストと確率パラメータの統合 コスト体系と確率パラメータをある比率で混ぜる 新しい値を作って最適解の選択に使用 どの方法で統合すれば最適かは分からない 今回は確率値の線形和を使用
線形和:一番単純な手法 両者を確率として使用 11
処理のおおまかな流れ コスト 確率パラメータへ変換 変換したコスト・確率パラメータ 統合 統合した値 コストへ変換 12
確率パラメータへ変換 確率パラメータの逆数の対数→コスト ↑の処理の逆 指数関数を用いてコストを確率パラメータに変換 問題点
コスト=比較的大きな値(修正しやすいように) 直接変換すると直感と異なる 改善策 スケールを変換 最大コストが最小の確率になるように係数を決定 係数:確率係数 確率パラメータ 13
統合~コストへ変換 統合:新たなパラメータ の作成 コストを変換した確率パラメータ:ℎ コーパス学習した確率パラメータ: 混ぜ合わせの比率:統合比率λ
コストへ変換:ChaSenに対応 ChaSen:コスト最小法を使用 パラメータ の逆数の対数⇒スケール変換 14
統合~コストへ変換 確率パラメータへ変換 の最適値は実験で 統合 λ =0.25
人手:コーパス学習 =1:3 コストへ変換 ChaSenのコスト範囲 =1~255 15
実験 人手によるコスト ChaSen付随の定義ファイル 品詞タグ付きコーパス 日経新聞94年版:1000文/3万形態素
ATR経路探索課題:30対話/8万7千形態素 Cross Validation(新聞:10fold 対話:30fold) 学習モデルの評価法(解析の妥当性を検証) 別名:交差検定 標本データを分割し、一部を解析&残りで解析のテスト 16
実験 手法:3種類 統合手法で解析 人手によるコストのみで解析 コーパスからの学習結果のみで解析
コーパス:2種類 日経新聞(書き言葉) ATR経路探索課題(話し言葉) 各種パラメータ 確率化係数 :3~11 統合比率λ :0.1~0.001 17
実験結果 日経新聞を使用 横軸: 文数(学習時) 30形態素/一文 縦軸: 解析精度
(再現率と適合率) 評価基準: 単語分割、読み、 品詞情報の3つ 全てが正しい 18
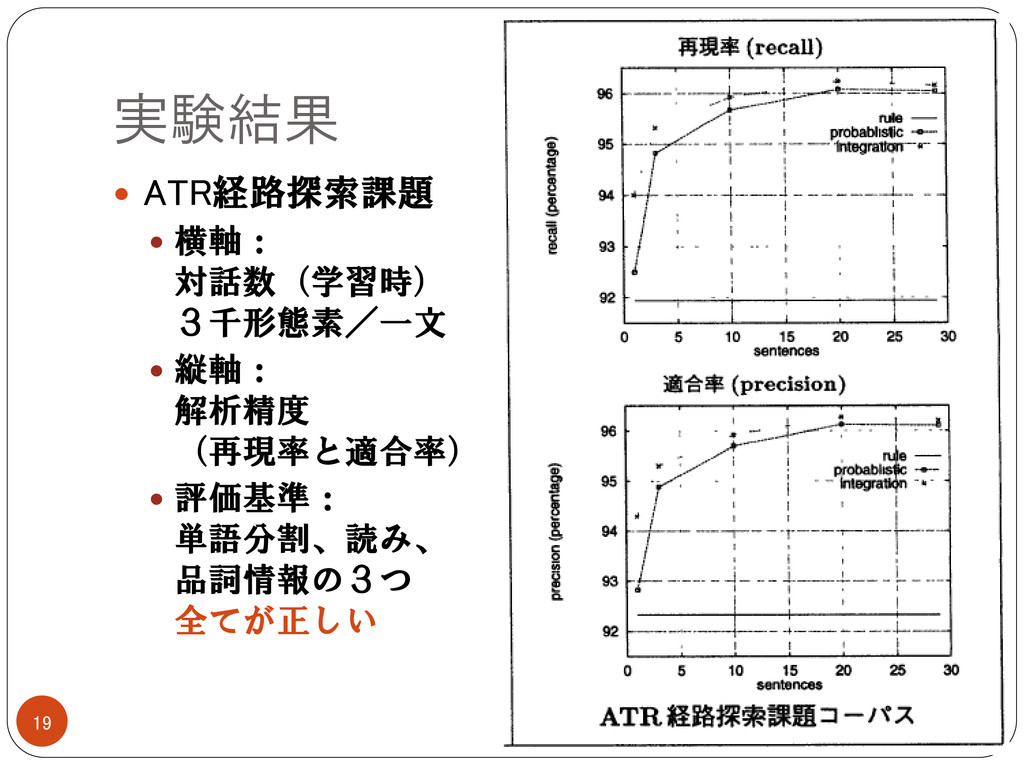
実験結果 ATR経路探索課題 横軸: 対話数(学習時) 3千形態素/一文 縦軸: 解析精度
(再現率と適合率) 評価基準: 単語分割、読み、 品詞情報の3つ 全てが正しい 19
結論 統合手法は他の手法より精度が良い 学習時のコーパスが小規模の時に優位性が高い 小規模コーパスでも精度向上に有効利用できる 別の実験で分かったこと・・・ 分野が異なると解析精度が下がる
分野依存である 20
応用 適用分野を限定して形態素解析を行う場合 大規模品詞タグ付きコーパスがあれば精度UP! 未開拓な分野では大量のコーパスはない 形態素解析の精度が悪い=品詞タグ付け作業は難しい
本研究の手法を用いる 小規模品詞タグ付きコーパスで高精度の解析ができる =品詞タグ付きコーパスの作成が容易になる 形態素解析精度を徐々に向上させることができる 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![品詞bi-gramモデル 品詞 の次に品詞−1 が現れる確率: −1 [?] 品詞 のとき形態素](https://files.speakerdeck.com/presentations/e7ccf380671e013059761231381d4f85/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}