Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介12月
Search
miyanishi
December 19, 2014
340
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介12月
miyanishi
December 19, 2014
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
文献紹介15年08月
miyanishi
0
240
15年7月文献紹介
miyanishi
0
270
Featured
See All Featured
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
300
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Designing for humans not robots
tammielis
254
26k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Fireside Chat
paigeccino
42
3.9k
Code Reviewing Like a Champion
maltzj
528
40k
Being A Developer After 40
akosma
91
590k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
360
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
220
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
200
Java REST API Framework Comparison - PWX 2021
mraible
34
9.3k
Transcript
文献紹介ゼミ 山本研 修士1年 宮西 由貴
文献情報 Morphological Analysis and Disambiguarion for Dialectal Arabic
Nizar Habash et. al. Proceedings of NAACL-HLT2013(p426-432)
概要 Arabicの中でもDA(特にARZ)に着目 MSAのためのツールをDAに適応させる コーパスの形式を適応させる 英語との機械翻訳精度が向上
トークン化が正しく出来る=精度向上に寄与 OOVが減少
背景(Arabicの基礎) Arabicは大きく2種類に分別可能 Modern Standard Arabic(MSA):標準のArabic Dialectal Arabic(DA):各地の方言入りのArabic
Egyptian Arabic(ARZ)←一番喋られているDA Levantine Arabic Moroccan Arabic MSAとDAの違い 音韻論・形態論・語彙においても違う DAはスタンダードがない
背景(ArabicとNLP) NLPのツールやリソースはほとんどがMSA用 形態素解析もその一つ MSA用の形態素解析はDAには今一つ(約60%) 最近ARZのコーパスと形態素解析器が完成
形態素解析器:CALIMA-ARZ LDCコーパス:Linguistic Data Consortium
目的と実験概要 最先端のMSA形態素解析器をDAに拡張 最先端のMSA形態素解析器:MADA 特にARZに拡張 LDCコーパスの適応
二種類の実験を用意 形態素解析の精度を見る実験 機械翻訳へ応用した際の効果を見る実験
Arabic NLPの難しいところ MSA・DA共通の難点 語形変化する形態素が多い 接語の数が多い スペリングの曖昧性が大きい
DAのみの難点 異形がたくさん存在する スタンダードのつづりがない
MADAのアプローチ 人手でアノテートしたリソースを使用 素性:音韻,品詞,見出し語,13の語形変化,接語) 出力:品詞,表層形,性別,人称 モデルに適応
SVM N-gram language model スコア付けてスコアが高い物を選択
拡張MADAのアプローチ LDコーパスの問題点と解決策 数々のアノテートの不一致 CALIMAの形式との不一致 ↓ 最新のCALIMAの形式に適合
素性について 格やモード,クエスチョンマークなどは使用しない
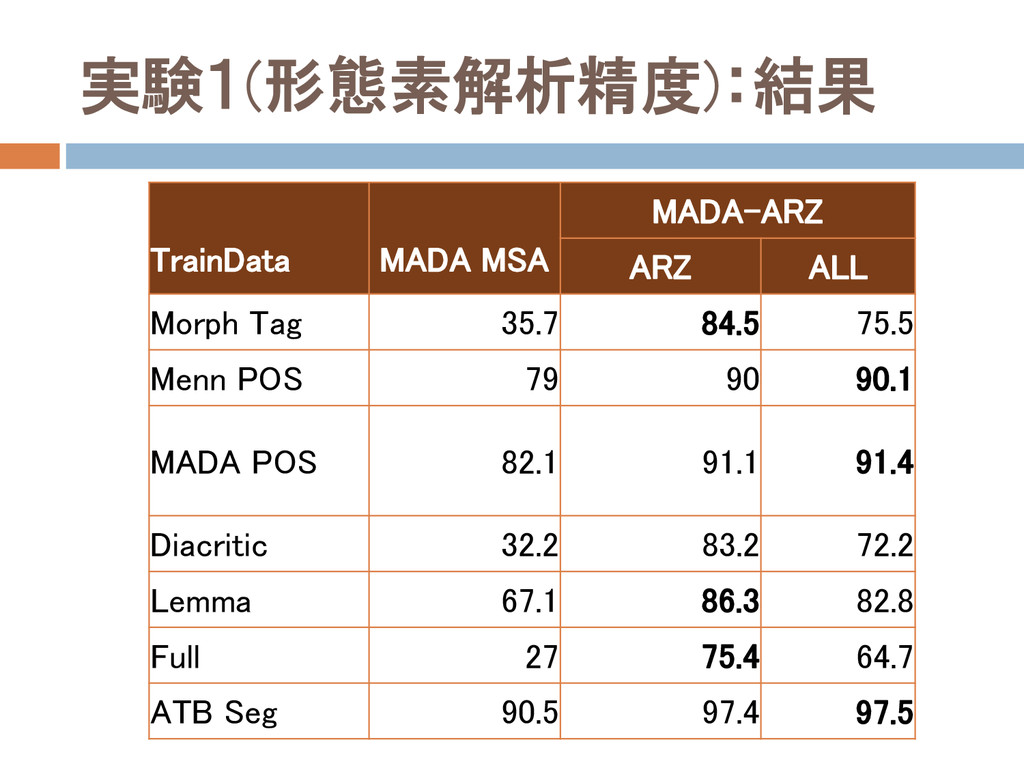
実験1(形態素解析精度):設定 二つのデータセット(LDコーパス内)を用いる ATB-123:MSA Penn Treebank ATB-ARZ:Egyptian Arabic
Treebank この二つをトレーニング&評価データに使用 トレーニングデータ Morph Tag : CALIMAタグ ATB Seg : 単語の割合(ATBのセグメンテーション)
実験1(形態素解析精度):結果 TrainData MADA MSA MADA-ARZ ARZ ALL Morph Tag 35.7
84.5 75.5 Menn POS 79 90 90.1 MADA POS 82.1 91.1 91.4 Diacritic 32.2 83.2 72.2 Lemma 67.1 86.3 82.8 Full 27 75.4 64.7 ATB Seg 90.5 97.4 97.5
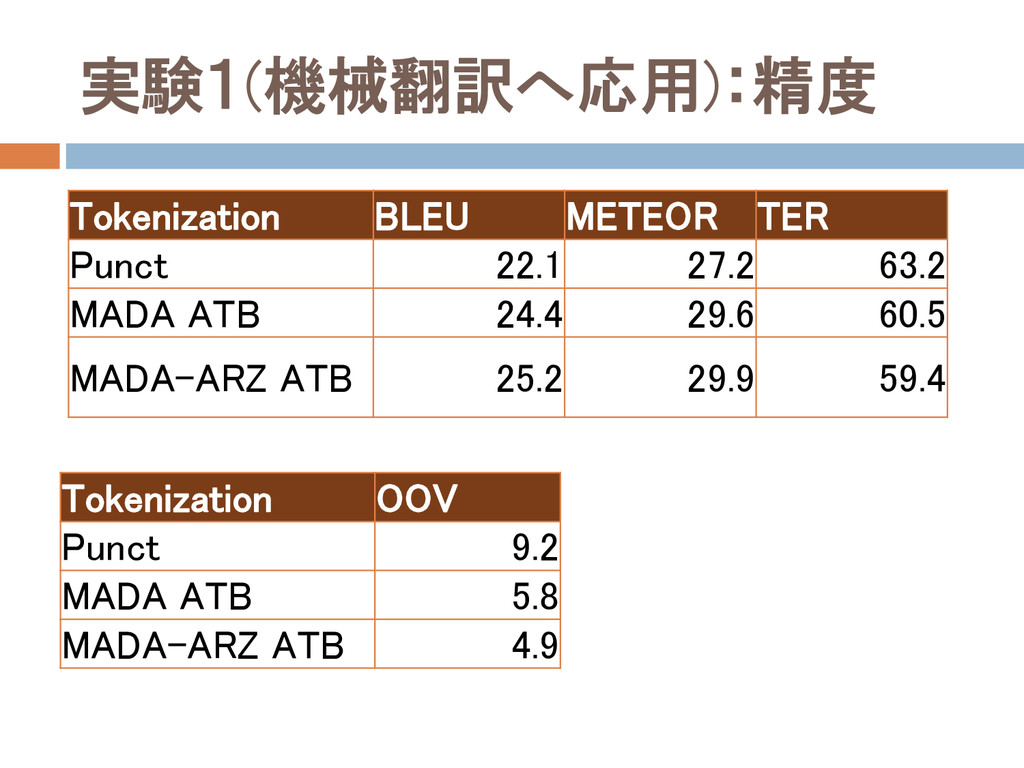
実験1(機械翻訳へ応用):設定 Egyptian Arabic to English 機械翻訳ツール:Moses アライメントツール:MGIZA++
評価:BLEU,METEOR,TER,OOV DA(Egyptian,Levantine)-Engパラレルコーパス使用 比較するトークン化システム Punct:句読点のみを見て行った場合 MADA ATB MADA-ARZ ATB
実験1(機械翻訳へ応用):精度 Tokenization BLEU METEOR TER Punct 22.1 27.2 63.2 MADA
ATB 24.4 29.6 60.5 MADA-ARZ ATB 25.2 29.9 59.4 Tokenization OOV Punct 9.2 MADA ATB 5.8 MADA-ARZ ATB 4.9
まとめ Arabicの中でもDA(特にARZ)に着目 MSAのためのツールをDAに適応させる コーパスの形式を適応させる 英語との機械翻訳精度が向上
トークン化が正しく出来る=精度向上に寄与 OOVが減少
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}