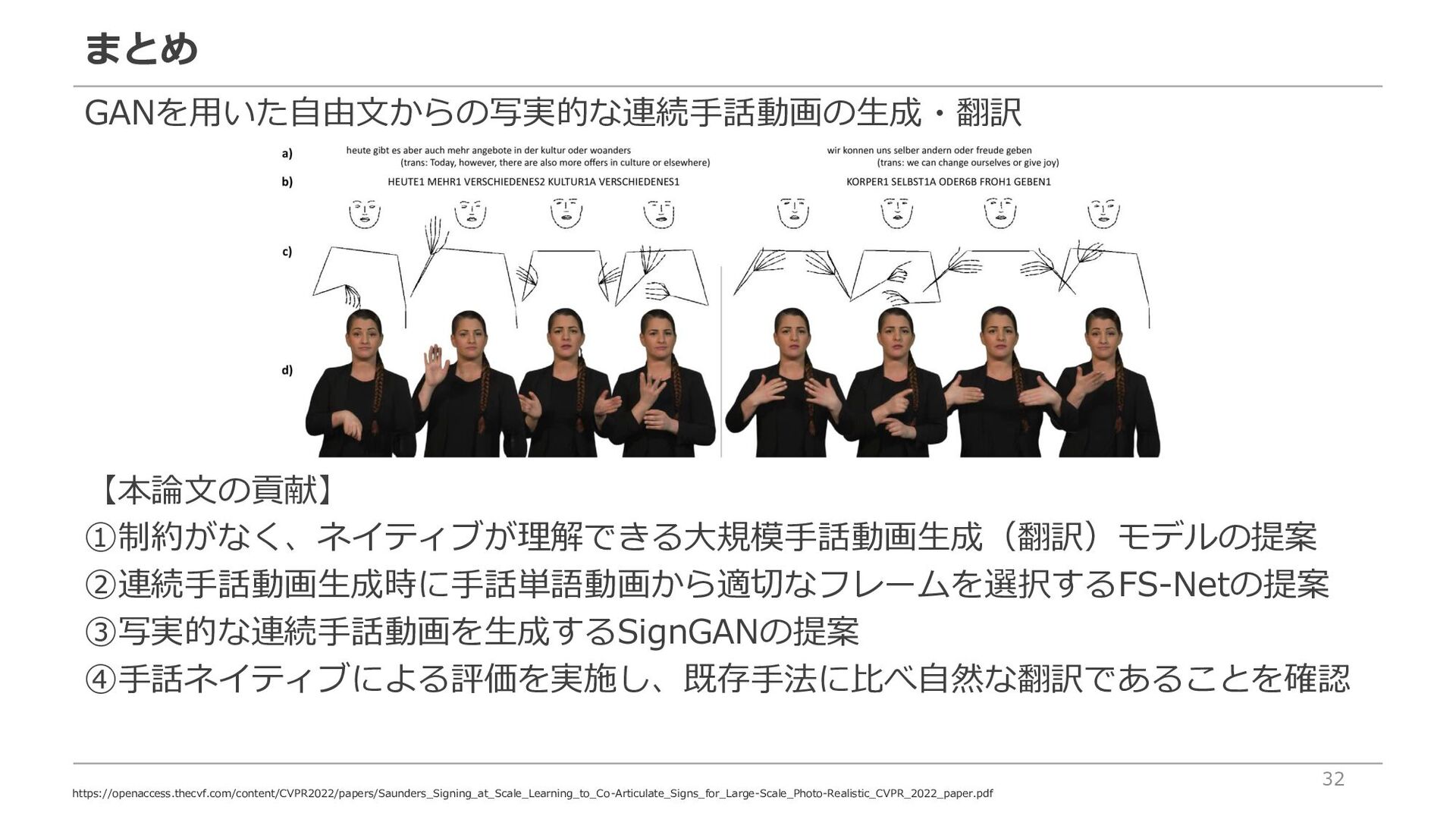
Baseline for Sign Language Translation" 手話認識向け転移学習の提案 "Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Photo-Realistic Sign Language Production" 語彙制約のない写実的な連続手話動画の生成・翻訳【本日の紹介論文】 "C2SLR: Consistency-Enhanced Continuous Sign Language Recognition" 表情と手形状に注目した視覚特徴と系列特徴の組み合わせによる手話認識の性能向上 "MLSLT: Towards Multilingual Sign Language Translation" 多言語手話データセットの収集とマルチリンガルな手話認識の提案 "Sign Language Video Retrieval With Free-Form Textual Queries" テキストを用いた手話映像検索システムの提案
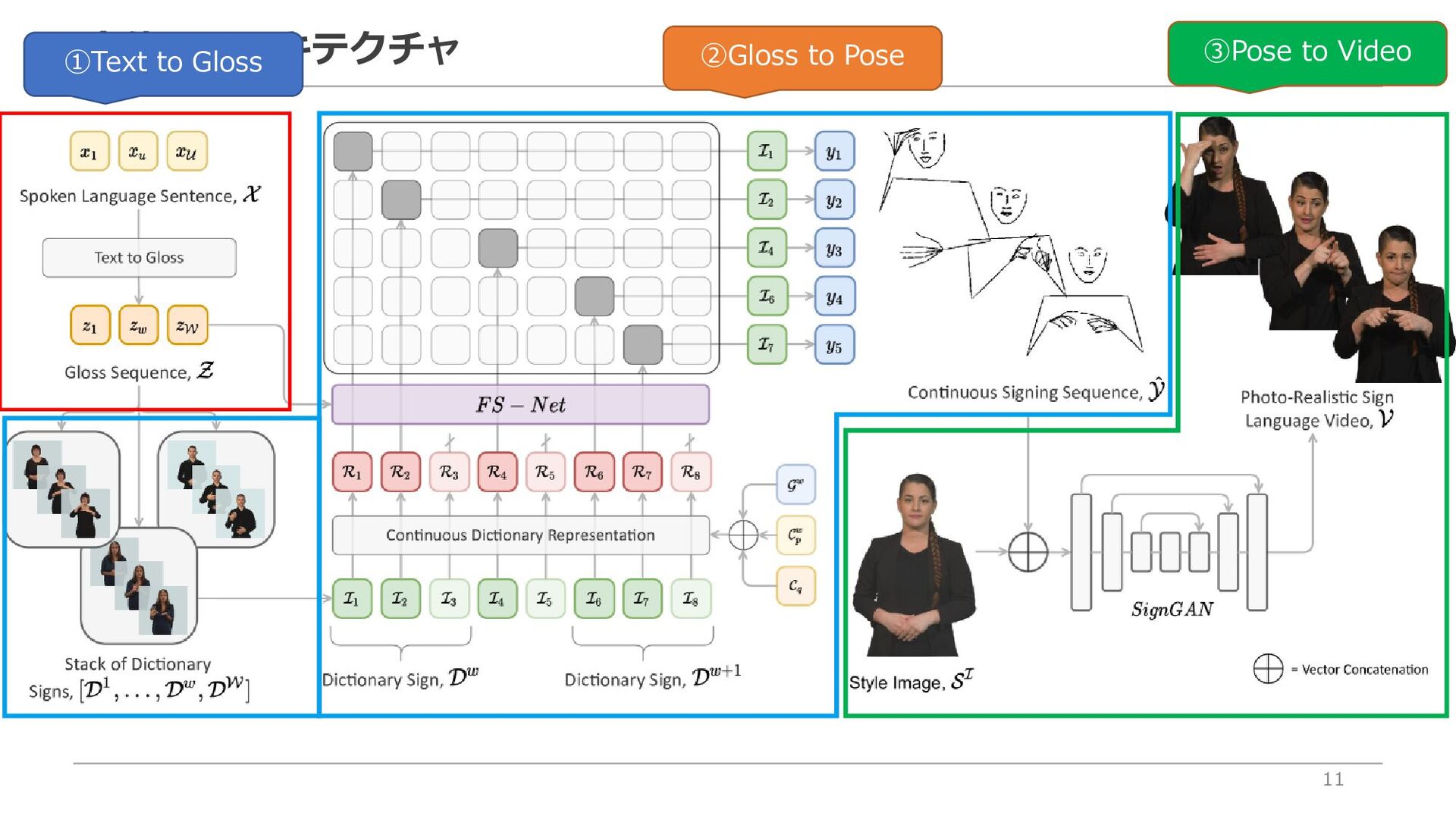
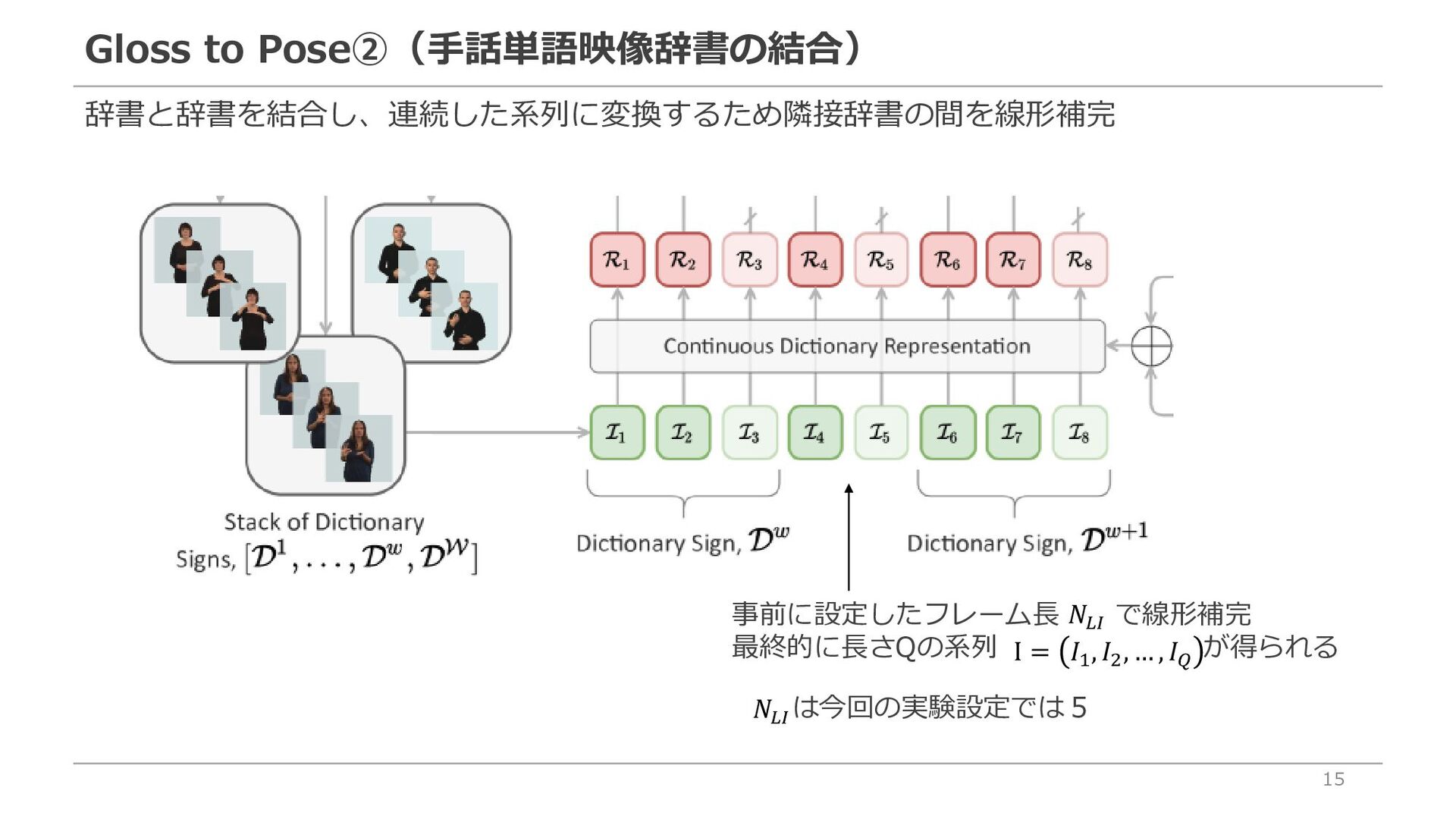
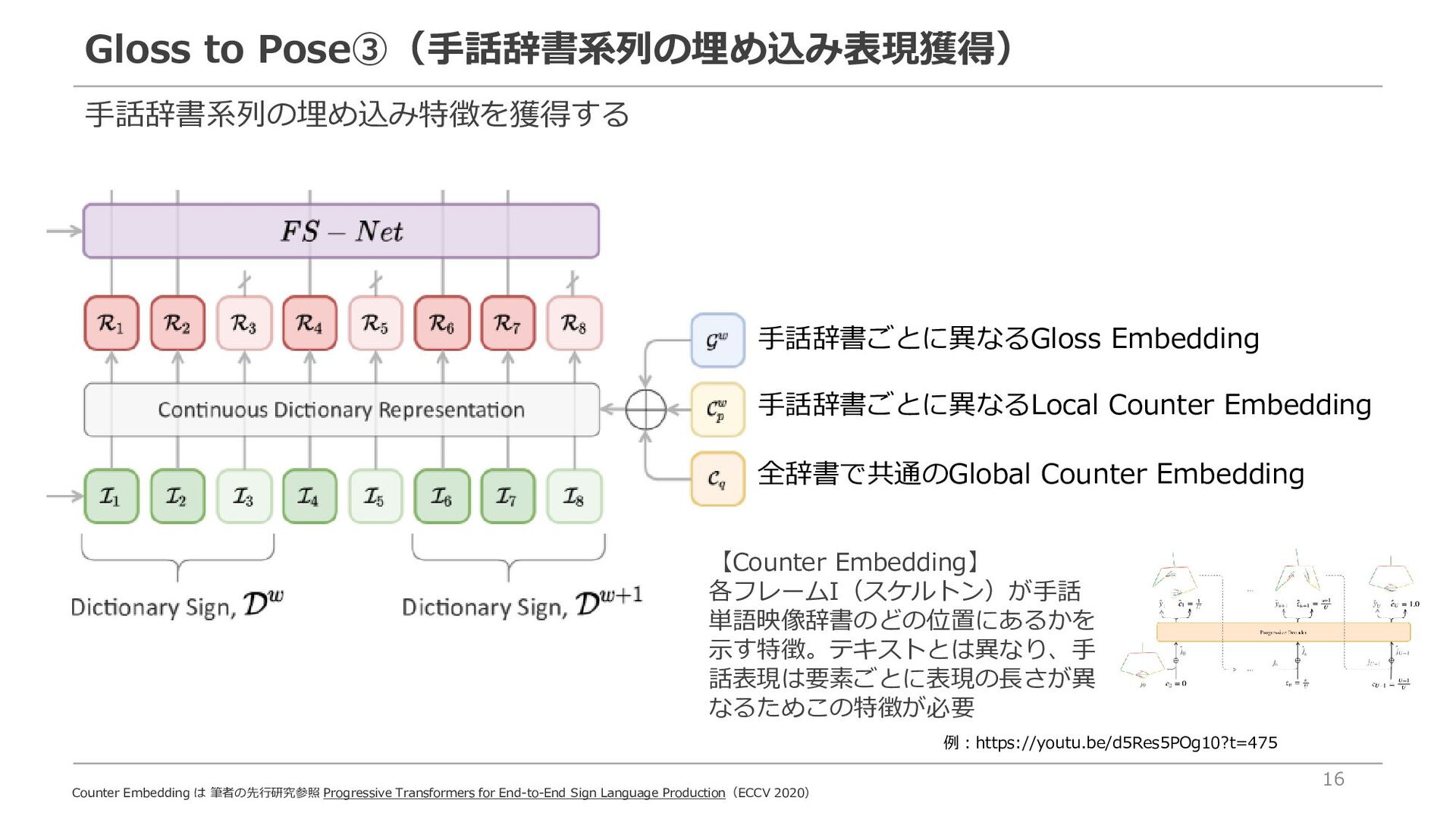
via Progressive Transformers and Mixture Density Networks. 2021.】を用いてスケルトン情報を取得 Gloss(トークン)をもとに、対応付けられた手話単語映像辞書を取り出し Glossの系列長がWであれば、手話単語映像辞書の系列長もW 【手話単語辞書について】 ・辞書ごとに異なる系列長Pのスケルトン情報を格納※ ・人物はまちまち ・辞書の拡張により、生成対象手話単語の語彙を増やすことが可能
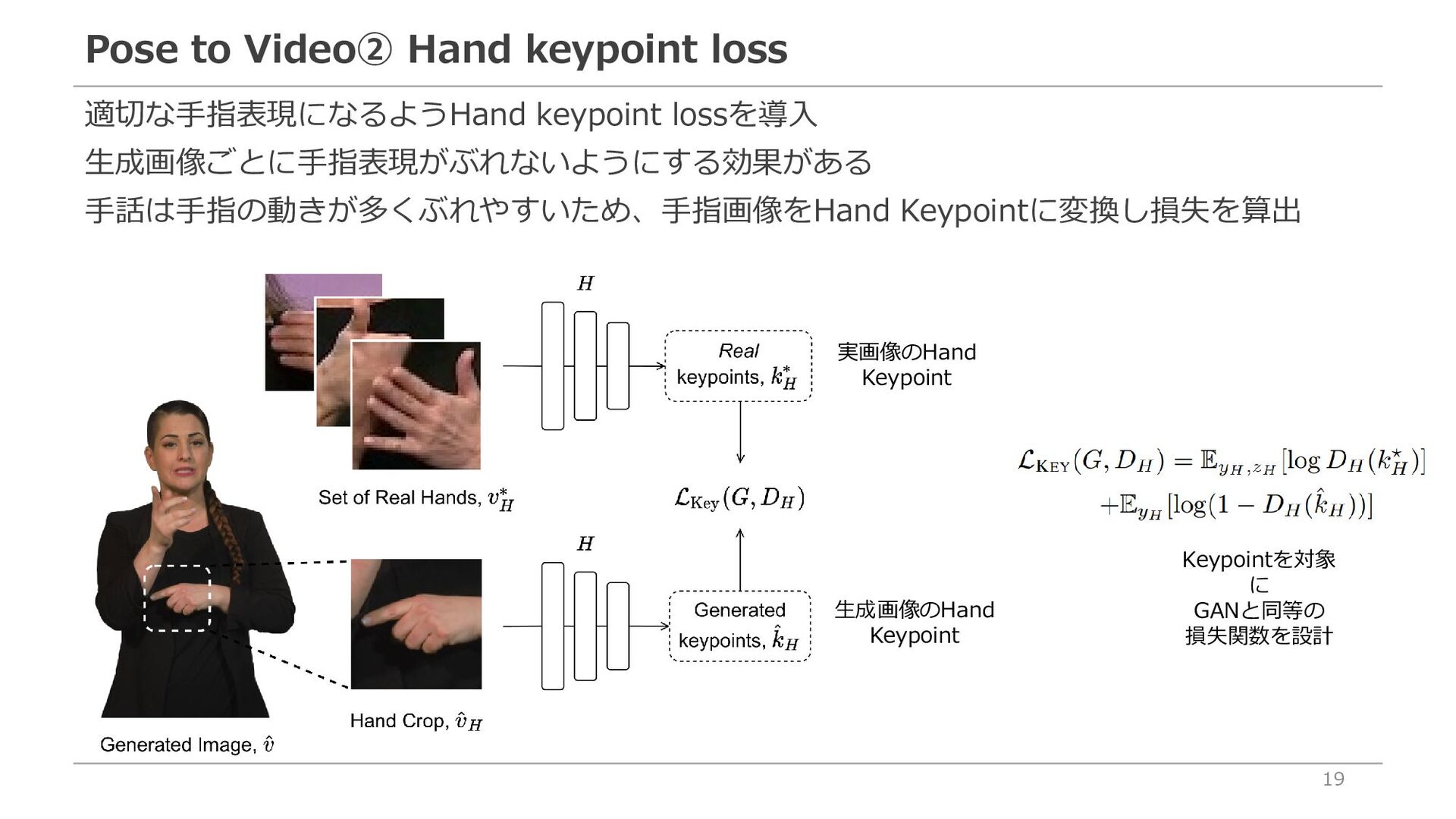
VGG Loss 学習済みのVGGモデルのレイヤーを通して得られた特徴量の平均を lossとする 鮮明な画像を生成する効果がある Hand Key Point Loss 手指のボーン情報が本物かニセモノかを判定する 指の本数が変動しない一貫した手指画像を生成する効果がある Feature-Matching loss 生成画像をDiscriminatorに入力したときの中間層が実画像と同様になるよ うに設計 同一画像が大量に生成されるモード崩壊を防ぐ効果がある
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
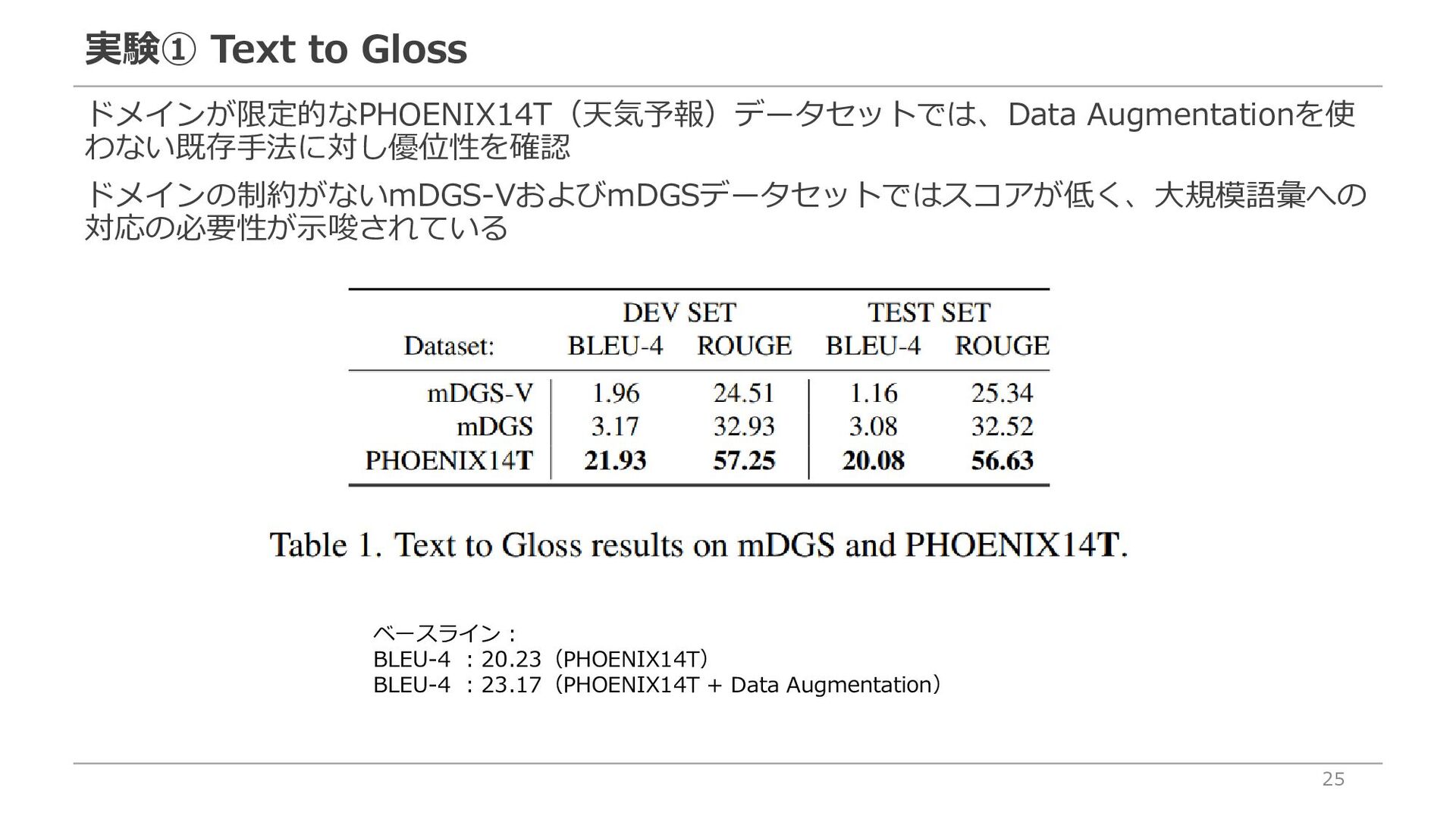{kind=link}
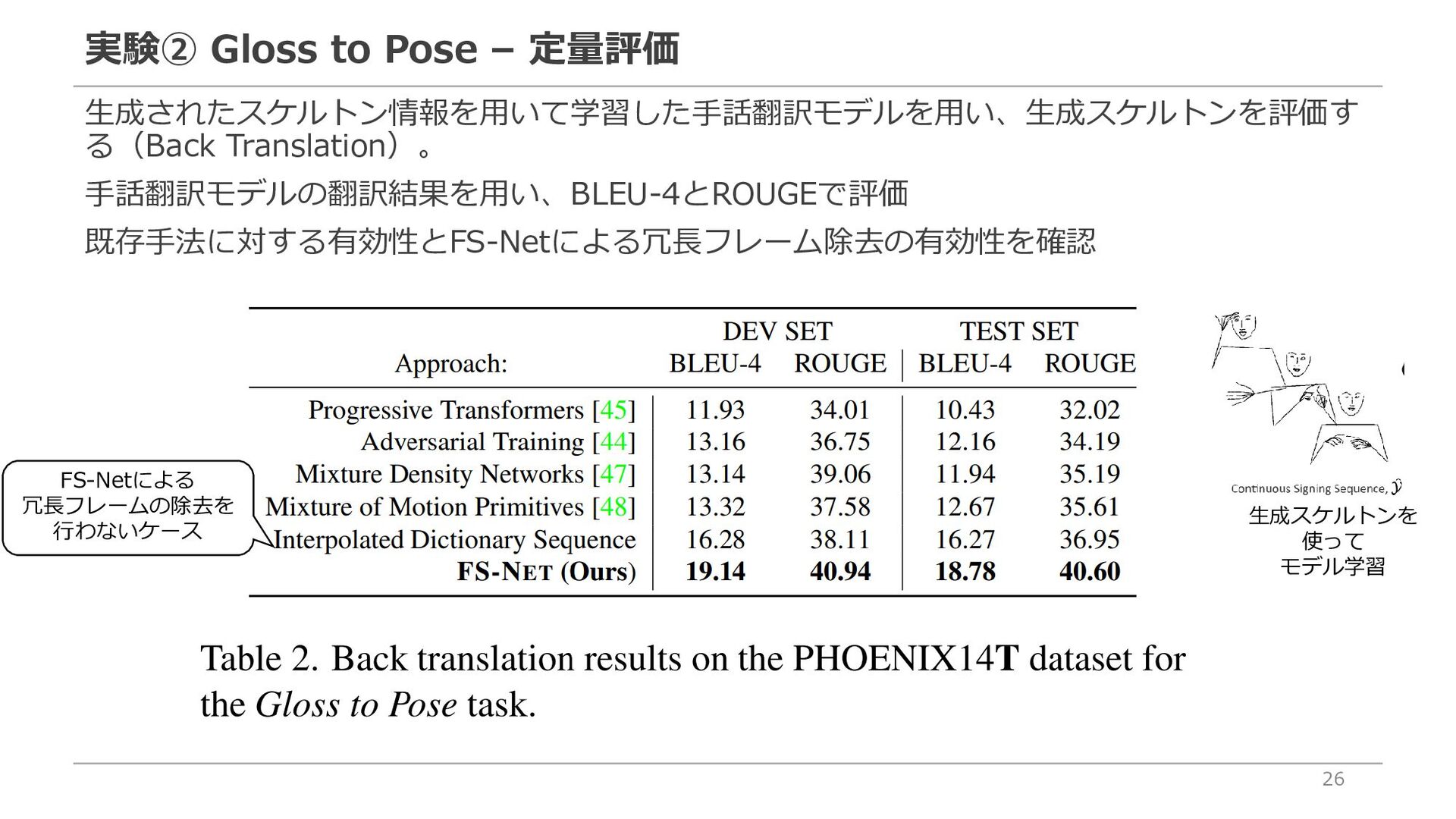{kind=link}
{kind=link}
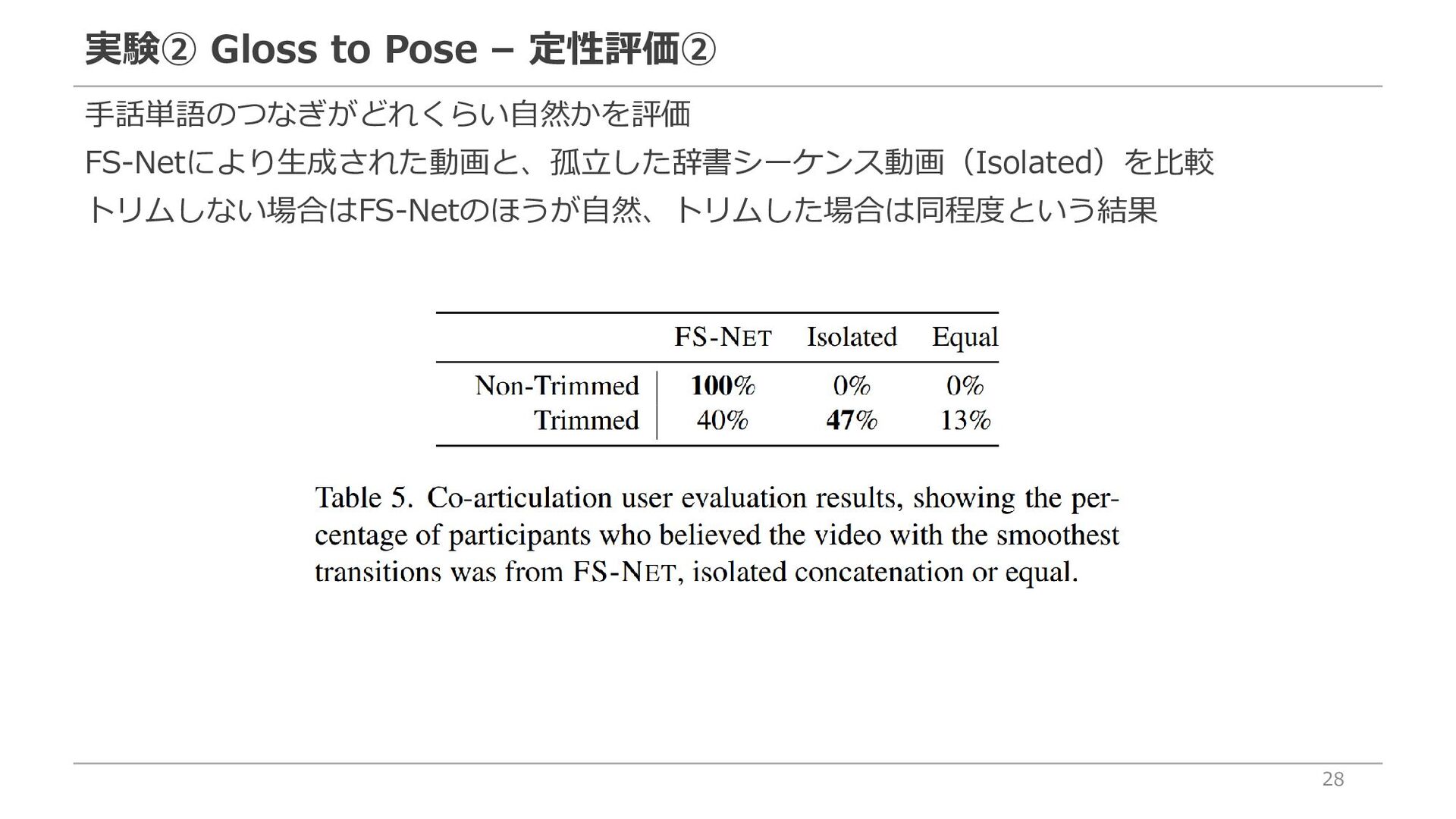{kind=link}
{kind=link}
{kind=link}
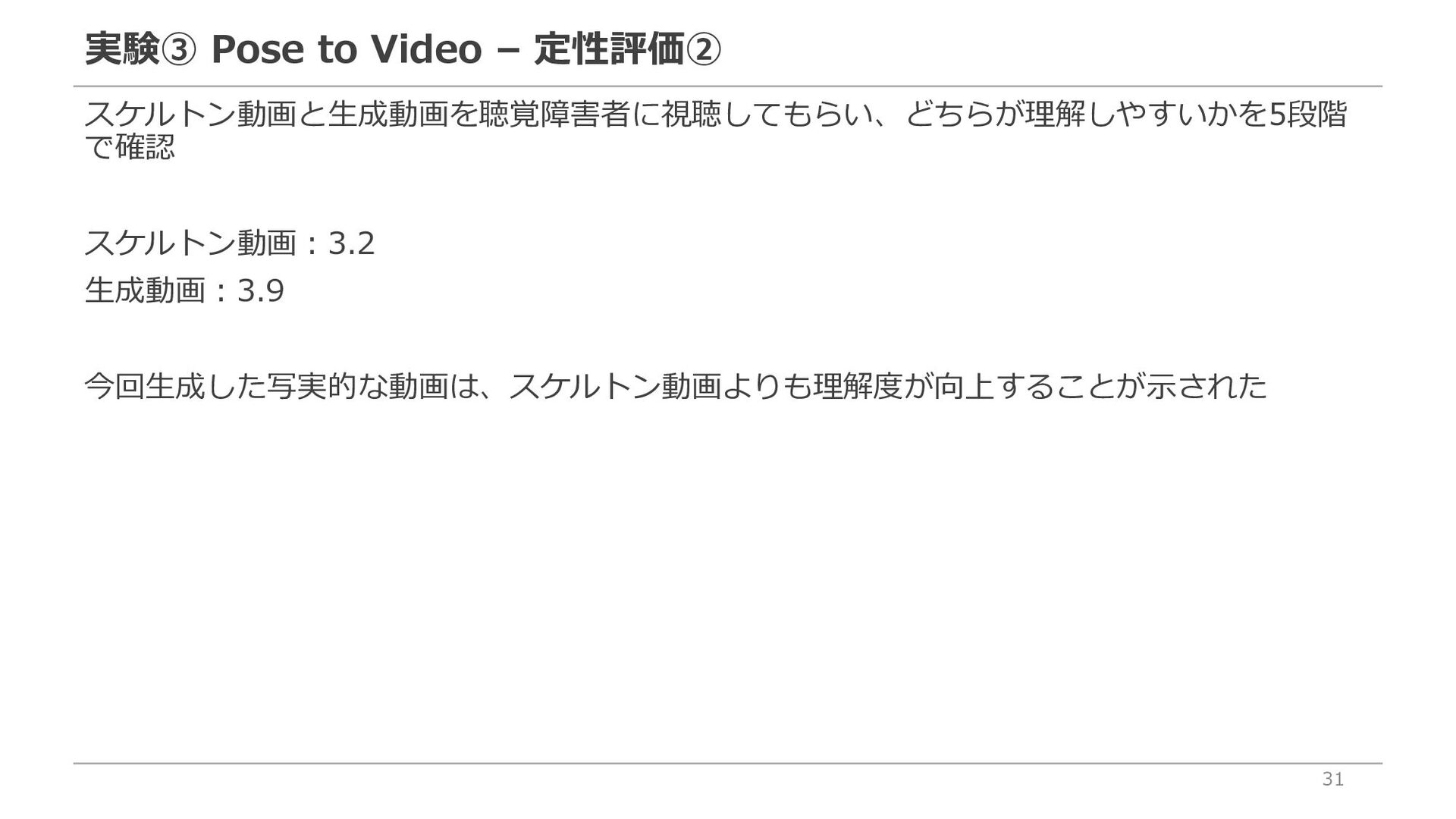{kind=link}
{kind=link}