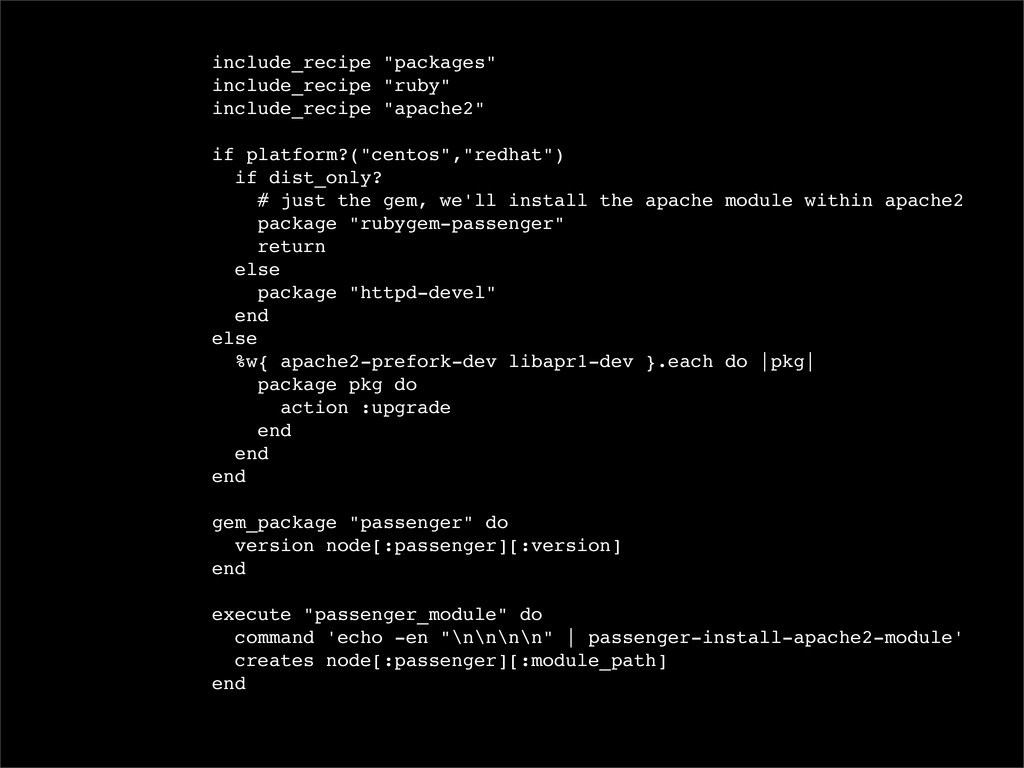
# just the gem, we'll install the apache module within apache2 package "rubygem-passenger" return else package "httpd-devel" end else %w{ apache2-prefork-dev libapr1-dev }.each do |pkg| package pkg do action :upgrade end end end gem_package "passenger" do version node[:passenger][:version] end execute "passenger_module" do command 'echo -en "\n\n\n\n" | passenger-install-apache2-module' creates node[:passenger][:module_path] end
performance H size 56,000 (25GB) Runtime (16x8 processors) Local (Infiniband) 3h:48 Cloud (10Gbps) 1h:30 ($40) WIEN2k Parallel Performance Credit: K. Jorissen, F. D. Villa, and J. J. Rehr (U. Washington) •1200 atom unit cell; SCALAPACK+MPI diagonalization, matrix size 50k-100k
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
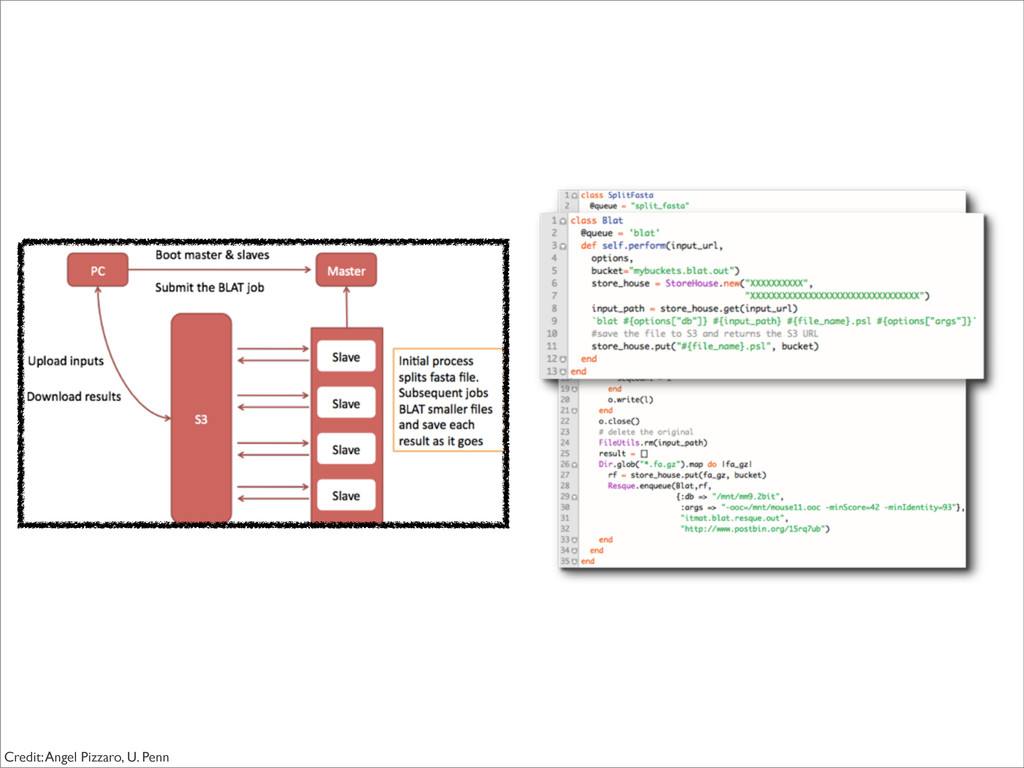{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] Twitter:@mndoci http://slideshare.net/mndoci http://mndoci.com Inspiration and ideas from Matt Wood&](https://files.speakerdeck.com/presentations/4e877bbe6ea0ae005000d1f2/slide_123.jpg){kind=link}