Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ベクトル空間における単語表現の効率的推定
Search
moguranosenshi
May 04, 2014
0
140
ベクトル空間における単語表現の効率的推定
moguranosenshi
May 04, 2014
Tweet
Share
More Decks by moguranosenshi
See All by moguranosenshi
日本語の語彙平易化
moguranosenshi
0
160
自己PR(2013.11.30)
moguranosenshi
0
530
Featured
See All Featured
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9k
Everyday Curiosity
cassininazir
0
180
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
53k
For a Future-Friendly Web
brad_frost
183
10k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
64
54k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
270
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8k
Ruling the World: When Life Gets Gamed
codingconduct
0
180
Building a Scalable Design System with Sketch
lauravandoore
463
34k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.4k
Heart Work Chapter 1 - Part 1
lfama
PRO
5
35k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Transcript
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. In
Proceedings of Workshop at ICLR, 2013. Presented by Tomoyuki Kajiwara 1
超大規模データセットを用いた単語のベクトル表現 60億語のデータから1,000次元のベクトルを2日で学習 CBOW Model(Continuous Bag-of-Words Model)
Skip-gram Model State-of-the-artなニューラルネットワークと比較 はるかに少ない計算コスト 大幅な精度向上 ベクトル空間における 単語表現の効率的推定 2
単語:様々なNLPアプリケーションの最小単位 高品質な単語ベクトル 超大規模データセットから高品質なベクトルを学習 計算を効率化・高速化 はじめに 3
単語:様々なNLPアプリケーションの最小単位 高品質な単語ベクトル 超大規模データセットから高品質なベクトルを学習 計算を効率化・高速化 なぜかすごい結果が出た!びっくり!! はじめに
4
単語:様々なNLPアプリケーションの最小単位 高品質な単語ベクトル 超大規模データセットから高品質なベクトルを学習 計算を効率化・高速化 なぜかすごい結果が出た!びっくり!! 単語の「意味」を表現するベクトルができた!
“King” - “Man” + “Woman” = “Queen” はじめに 5
NNLM: Feedforward Neural Net Language Model 単一方向にのみ信号が伝搬される RNNLM:
Recurrent Neural Net Language Model 双方向に信号が伝搬される Hierarchical Softmax 計算量の削減:O(V) → O(log2 (V)) V:単語数 DistBelief 大規模分散フレームワーク(16,000コアで並列学習) AdaGrad 学習率自動チューニング 背景技術 6
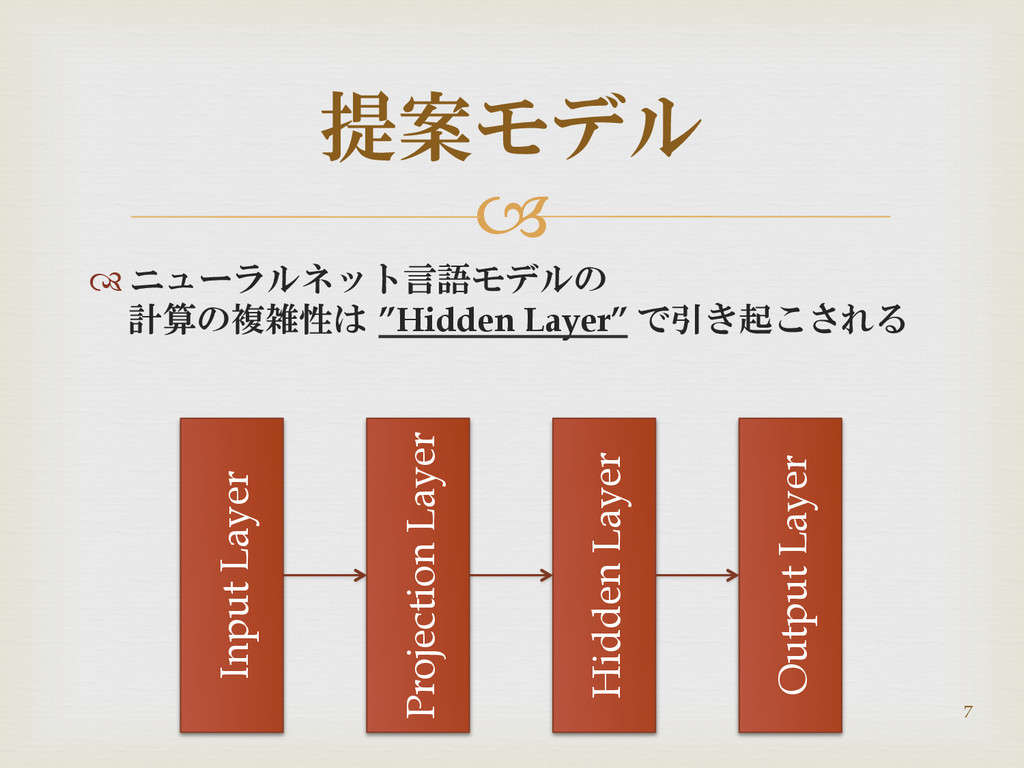
ニューラルネット言語モデルの 計算の複雑性は ”Hidden Layer” で引き起こされる 提案モデル Input Layer Projection
Layer Hidden Layer Output Layer 7
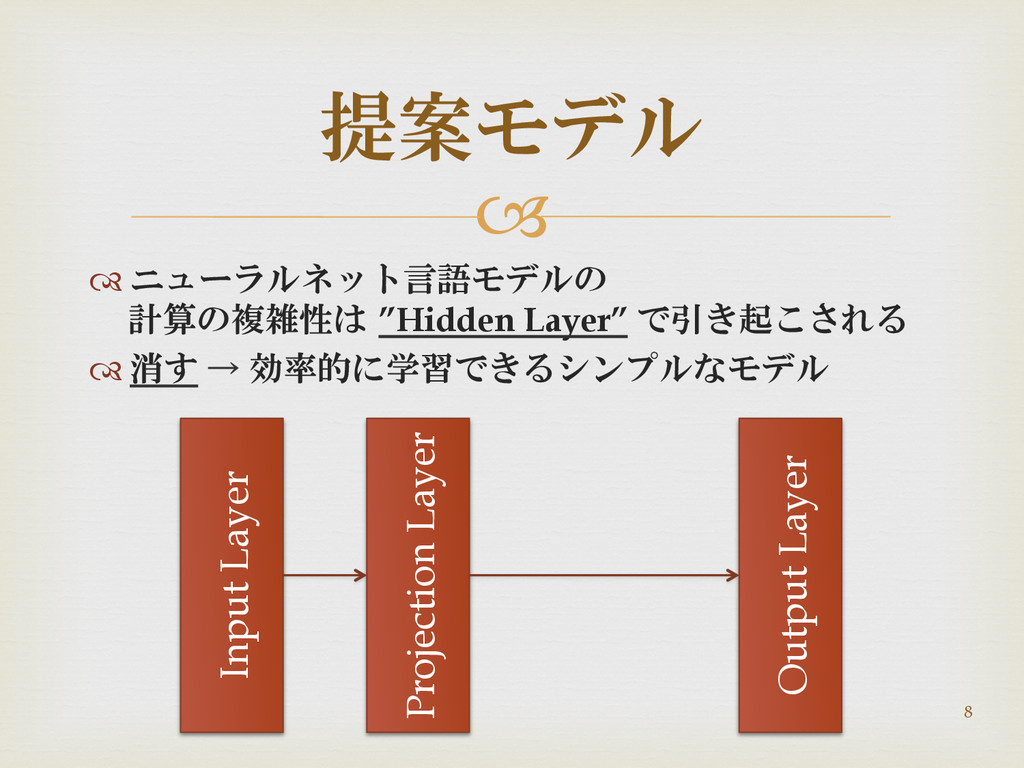
ニューラルネット言語モデルの 計算の複雑性は ”Hidden Layer” で引き起こされる 消す → 効率的に学習できるシンプルなモデル 提案モデル
Input Layer Projection Layer Output Layer 8
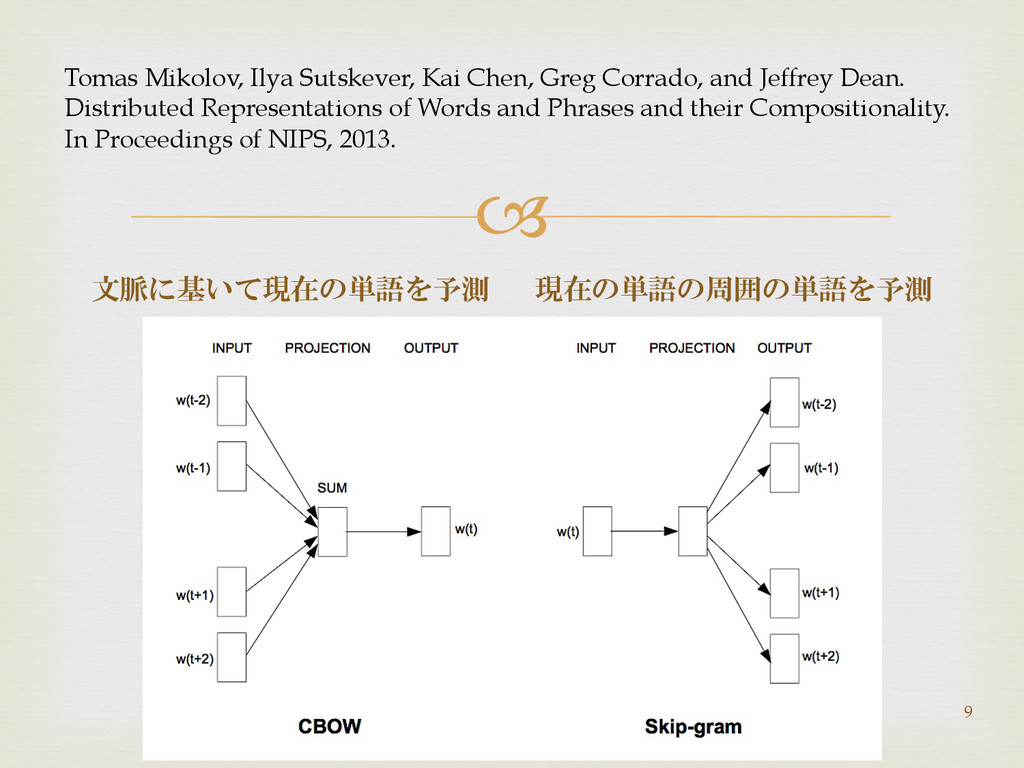
文脈に基いて現在の単語を予測 現在の単語の周囲の単語を予測 Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg
Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013. 9
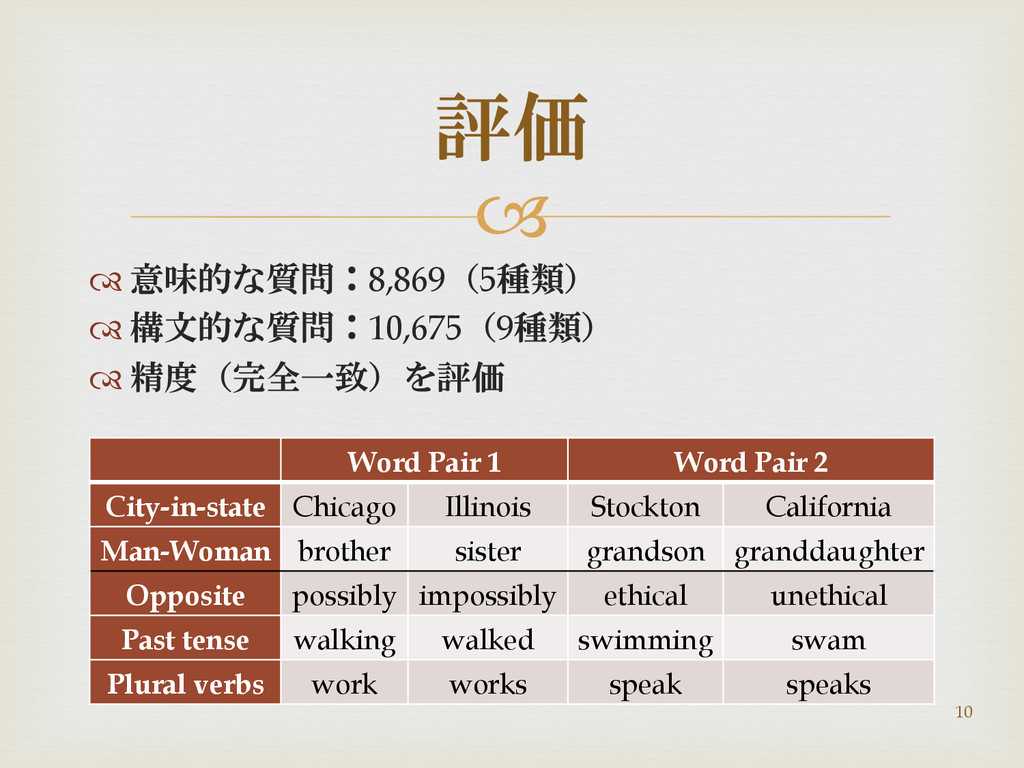
意味的な質問:8,869(5種類) 構文的な質問:10,675(9種類) 精度(完全一致)を評価 評価 Word Pair 1 Word Pair
2 City-in-state Chicago Illinois Stockton California Man-Woman brother sister grandson granddaughter Opposite possibly impossibly ethical unethical Past tense walking walked swimming swam Plural verbs work works speak speaks 10
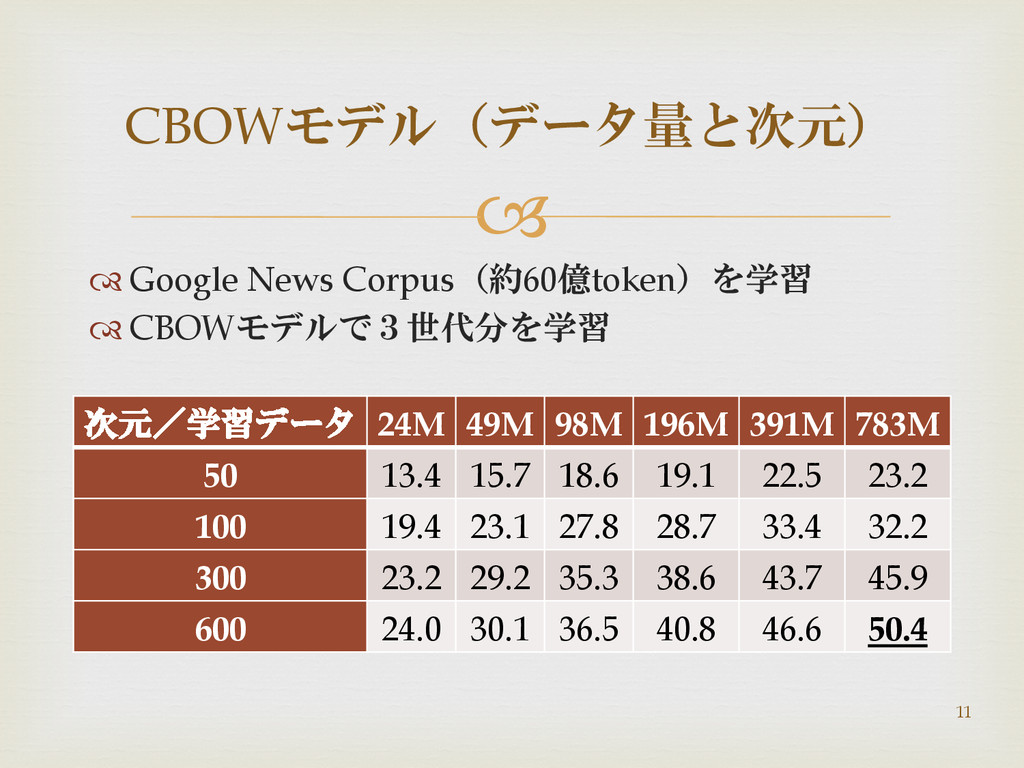
Google News Corpus(約60億token)を学習 CBOWモデルで3世代分を学習 CBOWモデル(データ量と次元) 次元/学習データ 24M 49M 98M
196M 391M 783M 50 13.4 15.7 18.6 19.1 22.5 23.2 100 19.4 23.1 27.8 28.7 33.4 32.2 300 23.2 29.2 35.3 38.6 43.7 45.9 600 24.0 30.1 36.5 40.8 46.6 50.4 11
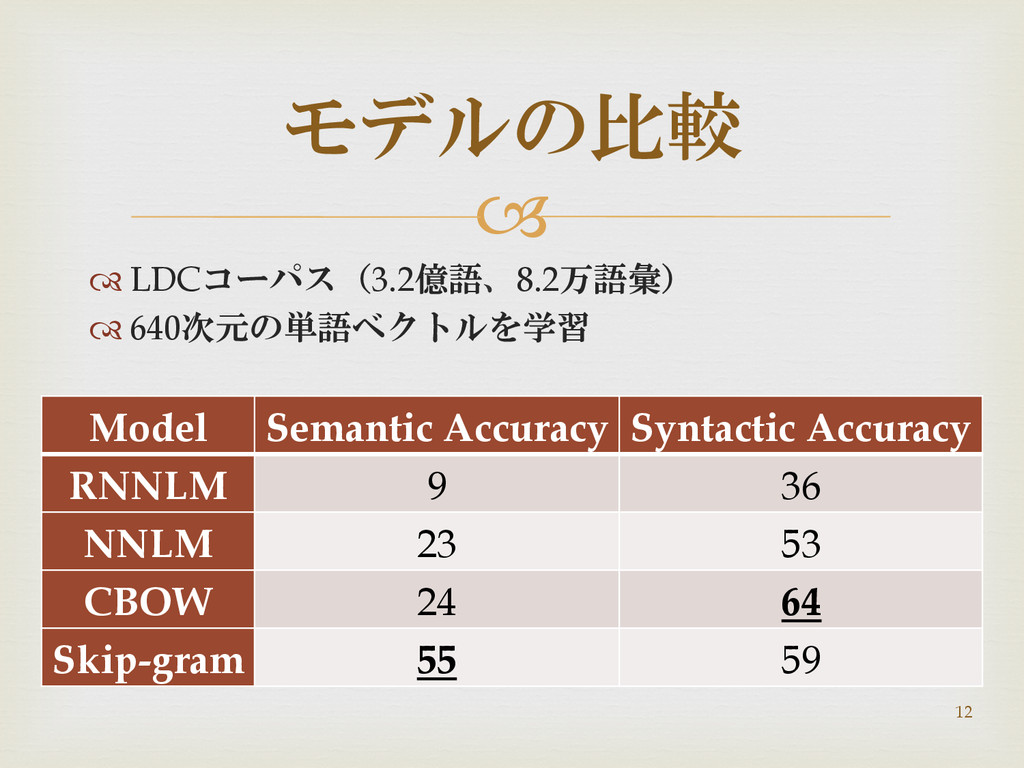
LDCコーパス(3.2億語、8.2万語彙) 640次元の単語ベクトルを学習 モデルの比較 Model Semantic Accuracy Syntactic Accuracy RNNLM
9 36 NNLM 23 53 CBOW 24 64 Skip-gram 55 59 12
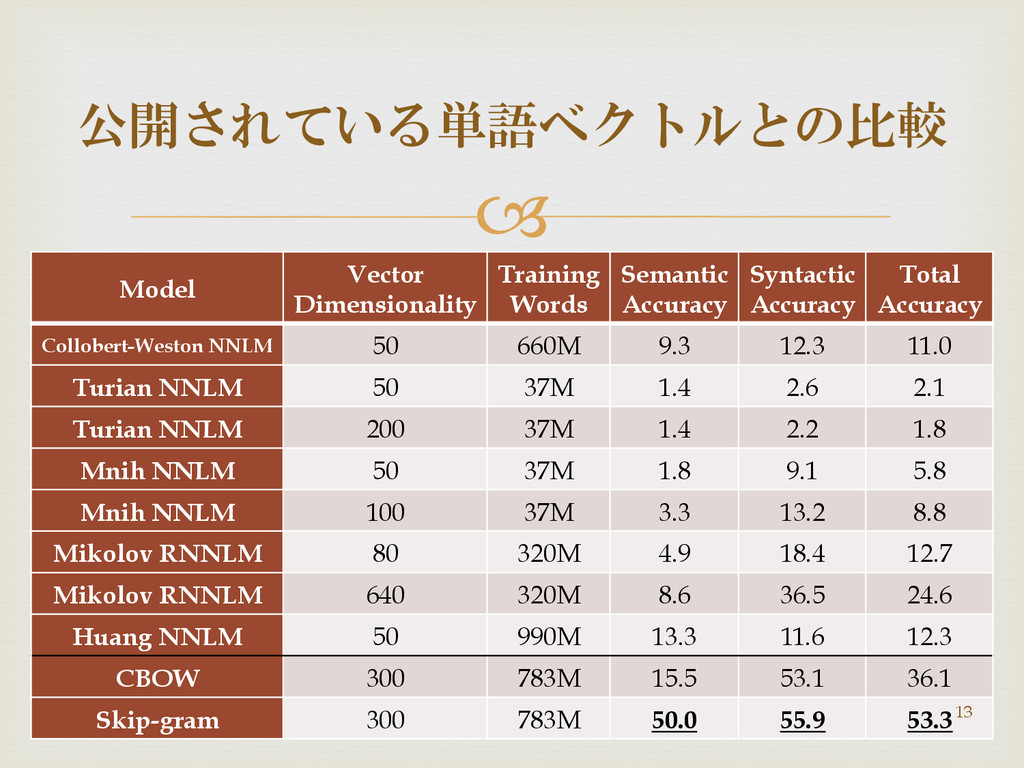
Model Vector Dimensionality Training Words Semantic Accuracy Syntactic Accuracy
Total Accuracy Collobert-Weston NNLM 50 660M 9.3 12.3 11.0 Turian NNLM 50 37M 1.4 2.6 2.1 Turian NNLM 200 37M 1.4 2.2 1.8 Mnih NNLM 50 37M 1.8 9.1 5.8 Mnih NNLM 100 37M 3.3 13.2 8.8 Mikolov RNNLM 80 320M 4.9 18.4 12.7 Mikolov RNNLM 640 320M 8.6 36.5 24.6 Huang NNLM 50 990M 13.3 11.6 12.3 CBOW 300 783M 15.5 53.1 36.1 Skip-gram 300 783M 50.0 55.9 53.3 公開されている単語ベクトルとの比較 13
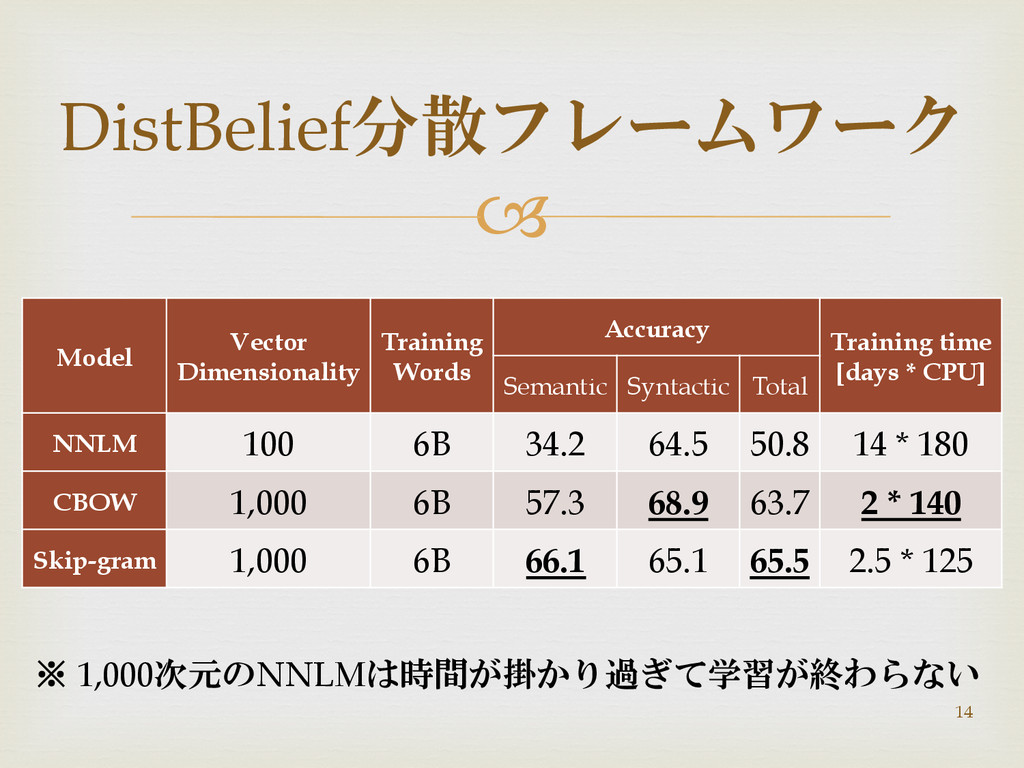
Model Vector Dimensionality Training Words Accuracy Training time [days
* CPU] Semantic Syntactic Total NNLM 100 6B 34.2 64.5 50.8 14 * 180 CBOW 1,000 6B 57.3 68.9 63.7 2 * 140 Skip-gram 1,000 6B 66.1 65.1 65.5 2.5 * 125 DistBelief分散フレームワーク ※ 1,000次元のNNLMは時間が掛かり過ぎて学習が終わらない 14
Relationship Example 1 Example 2 Example 3 France -
Paris Italy: Rome Japan: Tokyo Florida: Tallahassee big - bigger small: larger cold: colder quick: quicker Einstein - scientist Messi: midfielder Mozart: violinist Picasso: painter Microsoft - Windows Google: Android IBM: Linux Apple: iPhone Microsoft - Ballmer Google: Yahoo IBM: McNealy Apple: Jobs Japan - sushi Germany: bratwurst France: tapas USA: pizza 学習した関係 ※ 7.83億語、300次元で学習された Skip-gram モデル 15
大規模分散フレームワーク DistBelief 上で 学習率自動チューニング AdaGrad を使用して Hierarchical Softmax を用いて
NNLM を実装 計算コストが高い Hidden Layer を削除した CBOWモデル・Skip-gramモデルを提案 計算コストが下がったため 超大規模データセットから高次元ベクトルを計算でき 非常に高品質な単語ベクトルを得ることができた “King” - “Man” + “Woman” = “Queen” まとめ 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}