MongoNYC 2012: NYT + MongoDB in Production, Deep Kapadia, NYTimes.
This is a follow up talk to Jake Porway's talk at MongoNYC 2011 where he presented Project Cascade as one of R&D Labs Projects backed by MongoDB. Since then Project Cascade has moved to a scalable production level system. The talk will cover challenges and lessons learnt in moving MongoDB from a research project to a production environment.
{kind=link}
{kind=link}
{kind=link}
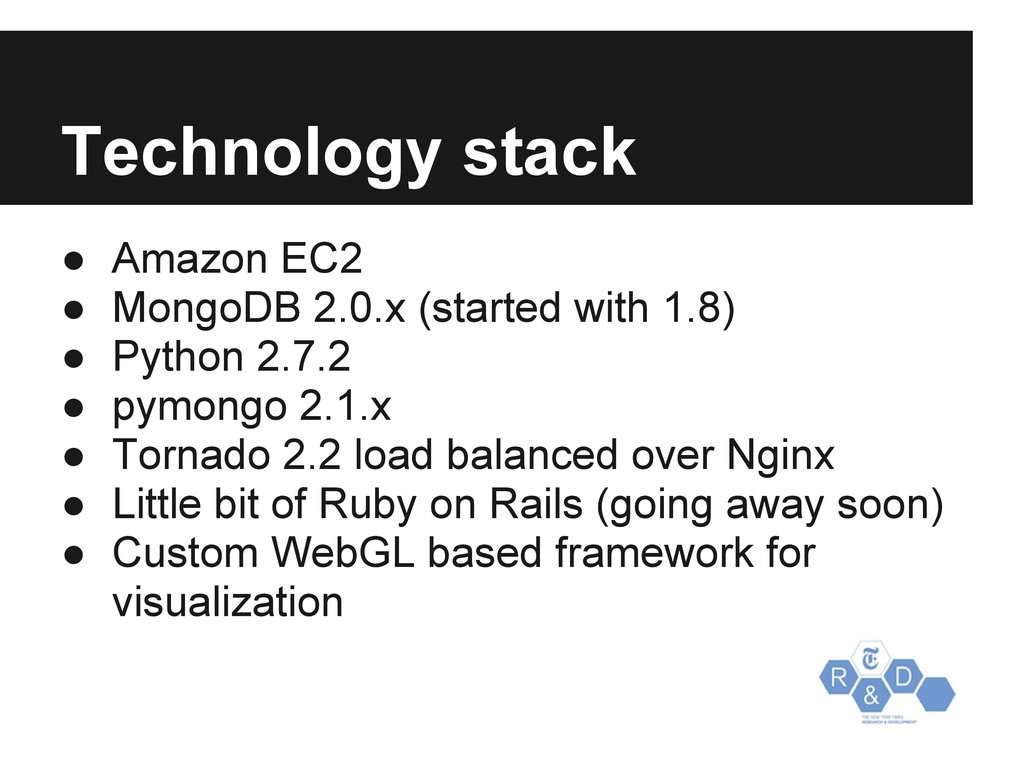{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Deep Kapadia @durple [email protected] NYT R&D Labs @nytlabs http://nytlabs.com](https://files.speakerdeck.com/presentations/4fc64df75fb56f001f01671f/slide_20.jpg){kind=link}