MongoNYC 2012: Rock Solid MongoDB Ops: Running MongoDB Like a Pro, Todd Dampier, MongoLab. Ok, so you’ve launched your development sandbox, love MongoDB, and are now thinking about how you want to handle your production environment. Learn all sorts of tips and tricks in this practical session on MongoDB operations by leading cloud database hosting provider MongoLab. We at MongoLab provide database hosting on EC2, Rackspace and Joyent for thousands of applications powered by MongoDB. In this session we will share with you some of the best practices we have developed, and help you avoid some of the pitfalls common with running production MongoDB deployments. This talk will cover the basics, such as VM selection, OS and disk configuration as well as more advanced topics such as clustering, VM migrations/upgrades, backup strategies and monitoring, with special emphasis on running MongoDB in the cloud. Don’t miss this informative session that will help you operate MongoDB like a pro!
{kind=link}
![Who am I? Todd O. Dampier [email protected] @t0dampier § CTO](https://files.speakerdeck.com/presentations/4fc4f07b4465dc025600a9cb/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
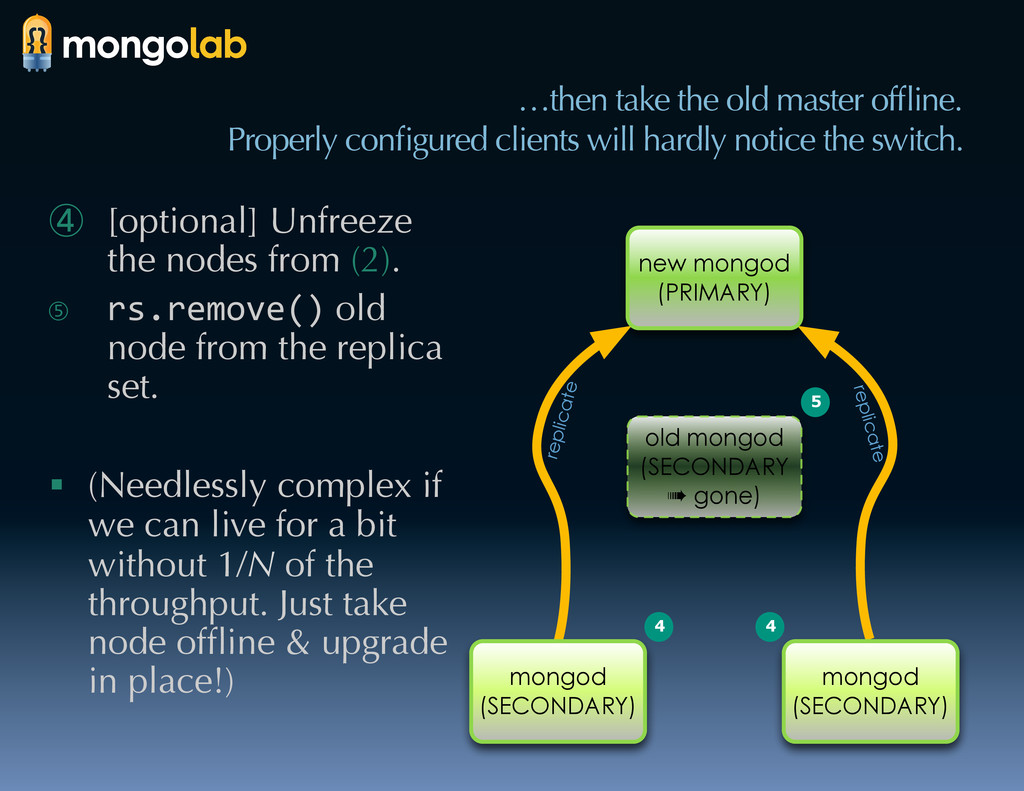{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
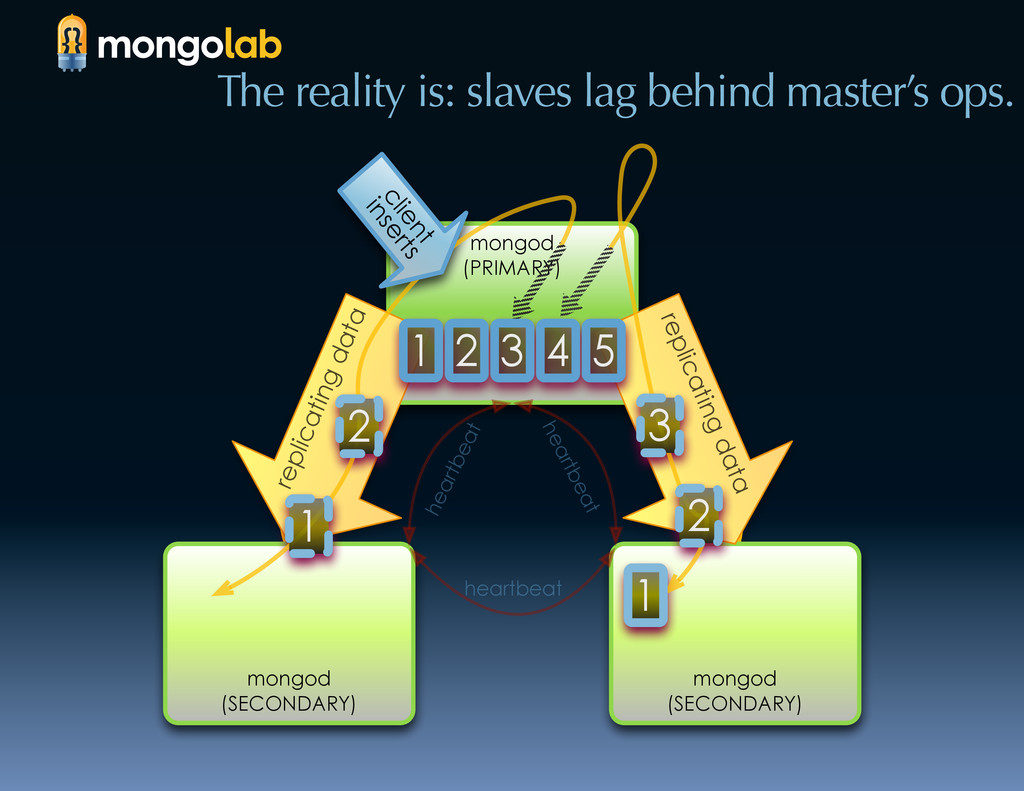{kind=link}
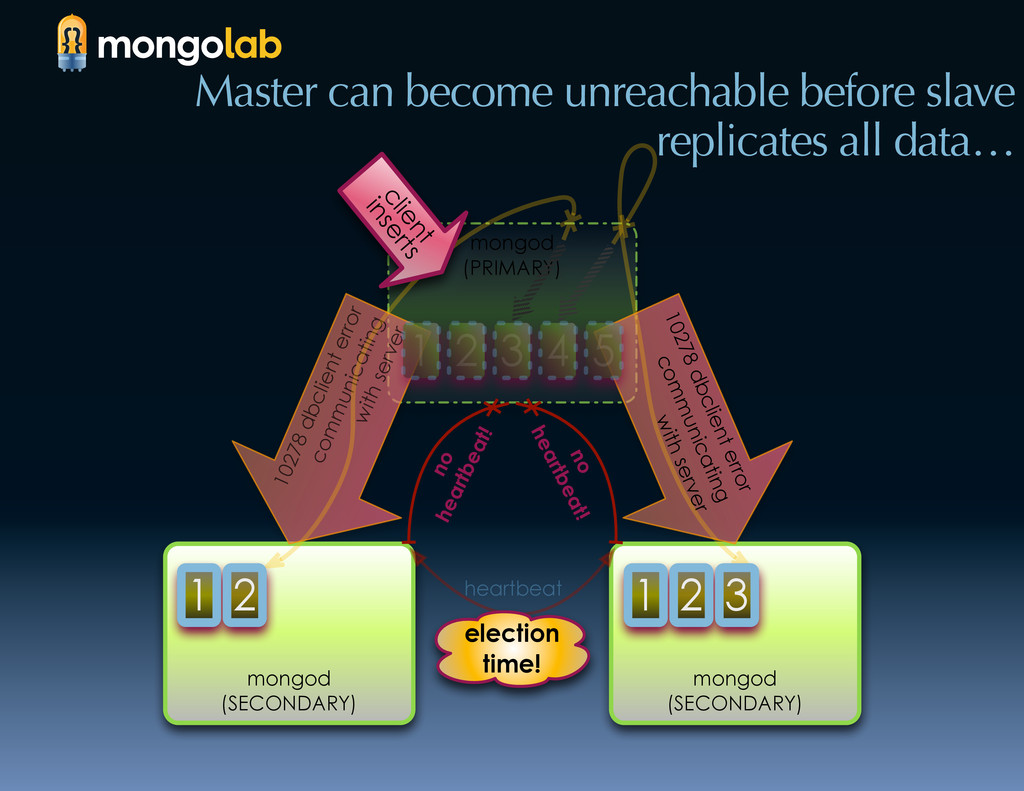{kind=link}
{kind=link}
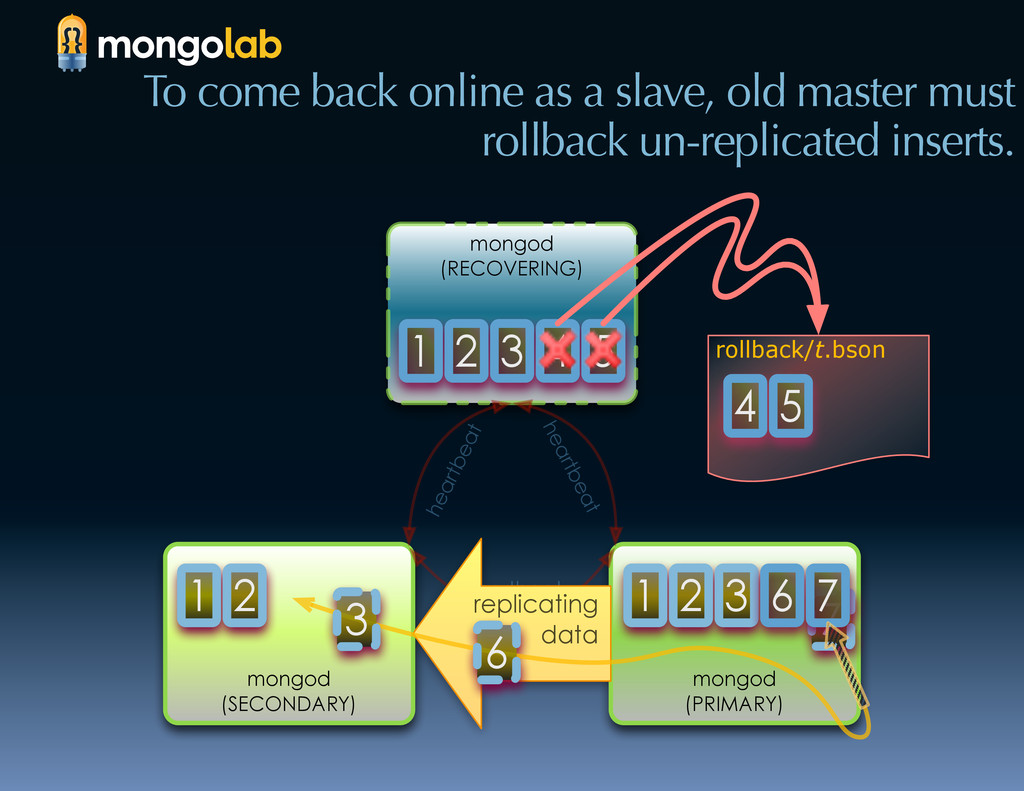{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}