Будут рассмотрены ключевые архитектурные вызовы при проектировании систем на основе AI-агентов и mcp серверов, а также роль фреймворков вроде LangChain и LangGraph в этом контексте. Далее глубоко разберем, чем отличаются популярные векторные базы данных, когда какую выбрать, и как работают их внутренние механизмы — HNSW, IVF, similarity, сегментация и лайфхаки "приготовления" рага.
Видео: https://moscowpython.ru/meetup/109/vector-db/
Moscow Python: http://moscowpython.ru
Курсы Learn Python: http://learn.python.ru
Moscow Python Podcast: http://podcast.python.ru
Заявки на доклады: https://bit.ly/mp-speaker
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
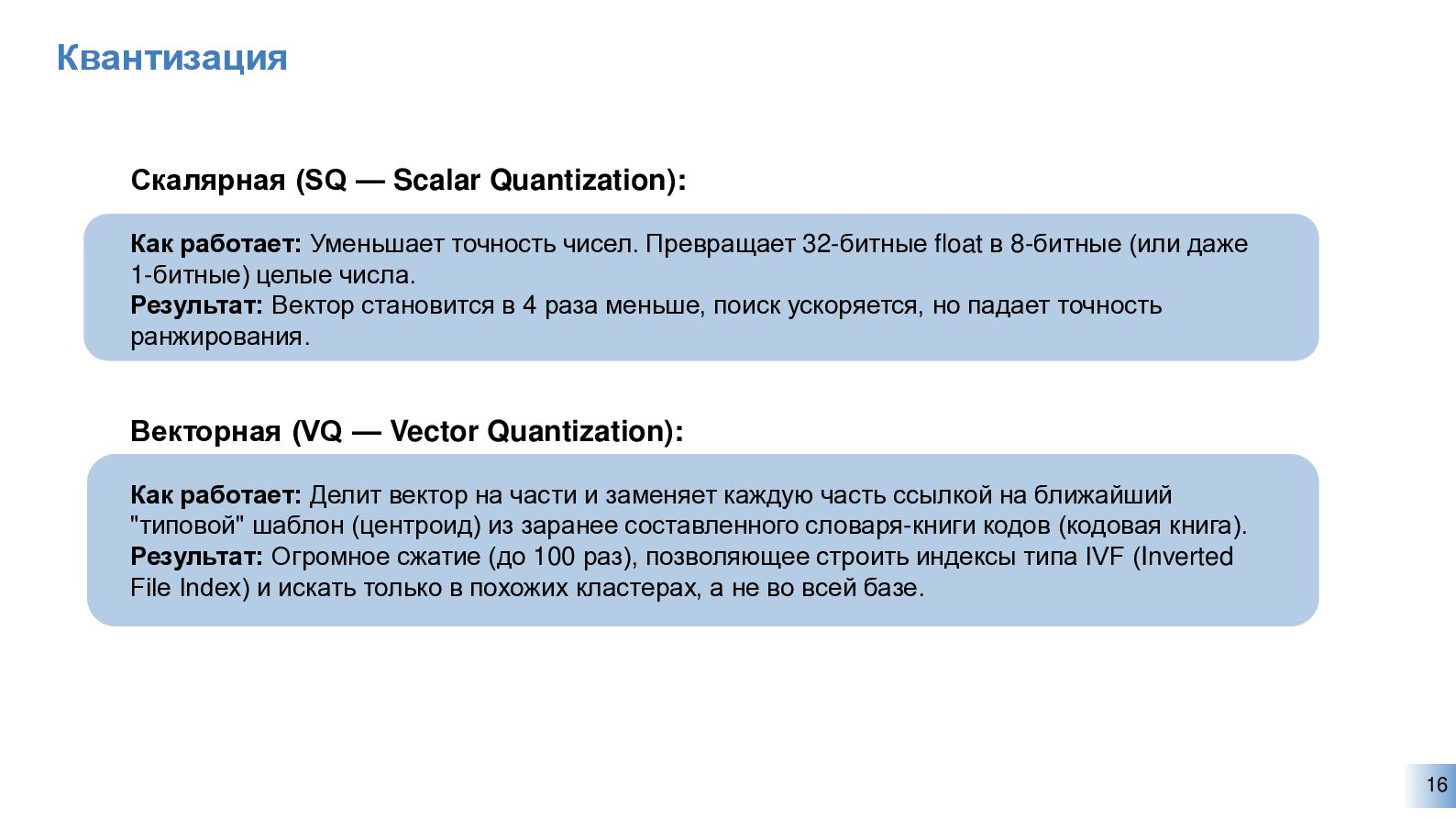{kind=link}
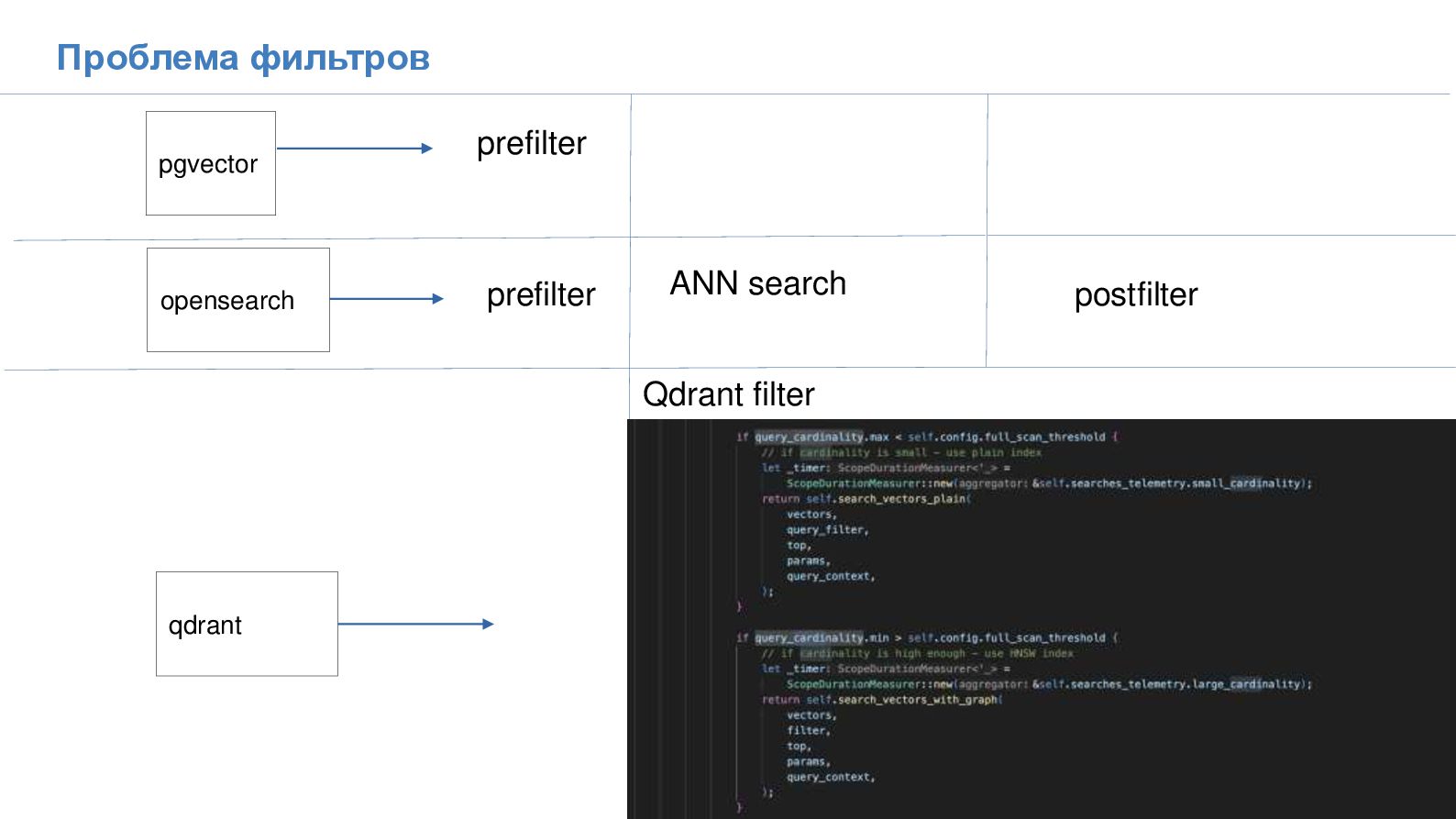{kind=link}
{kind=link}
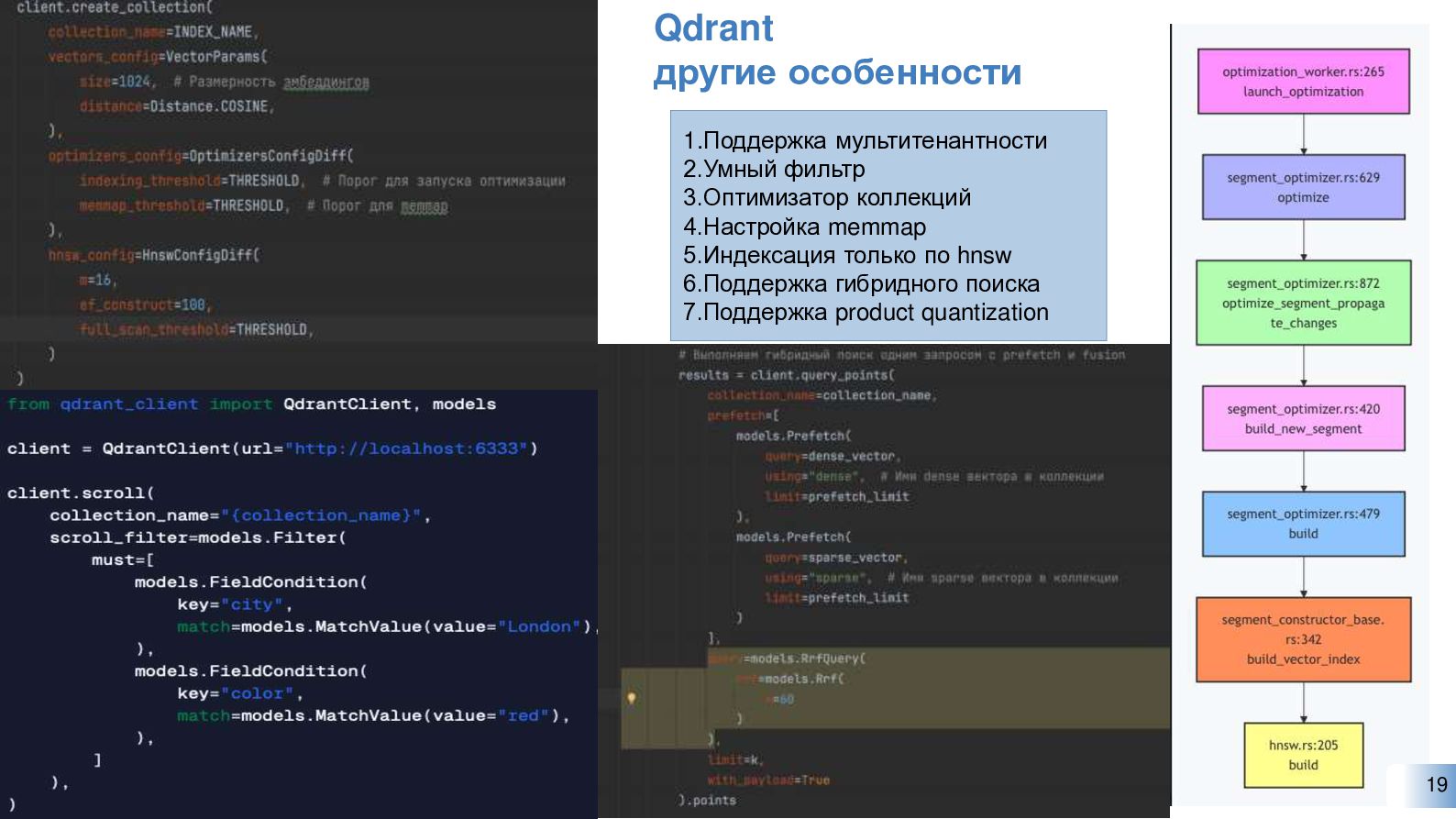{kind=link}
{kind=link}
{kind=link}
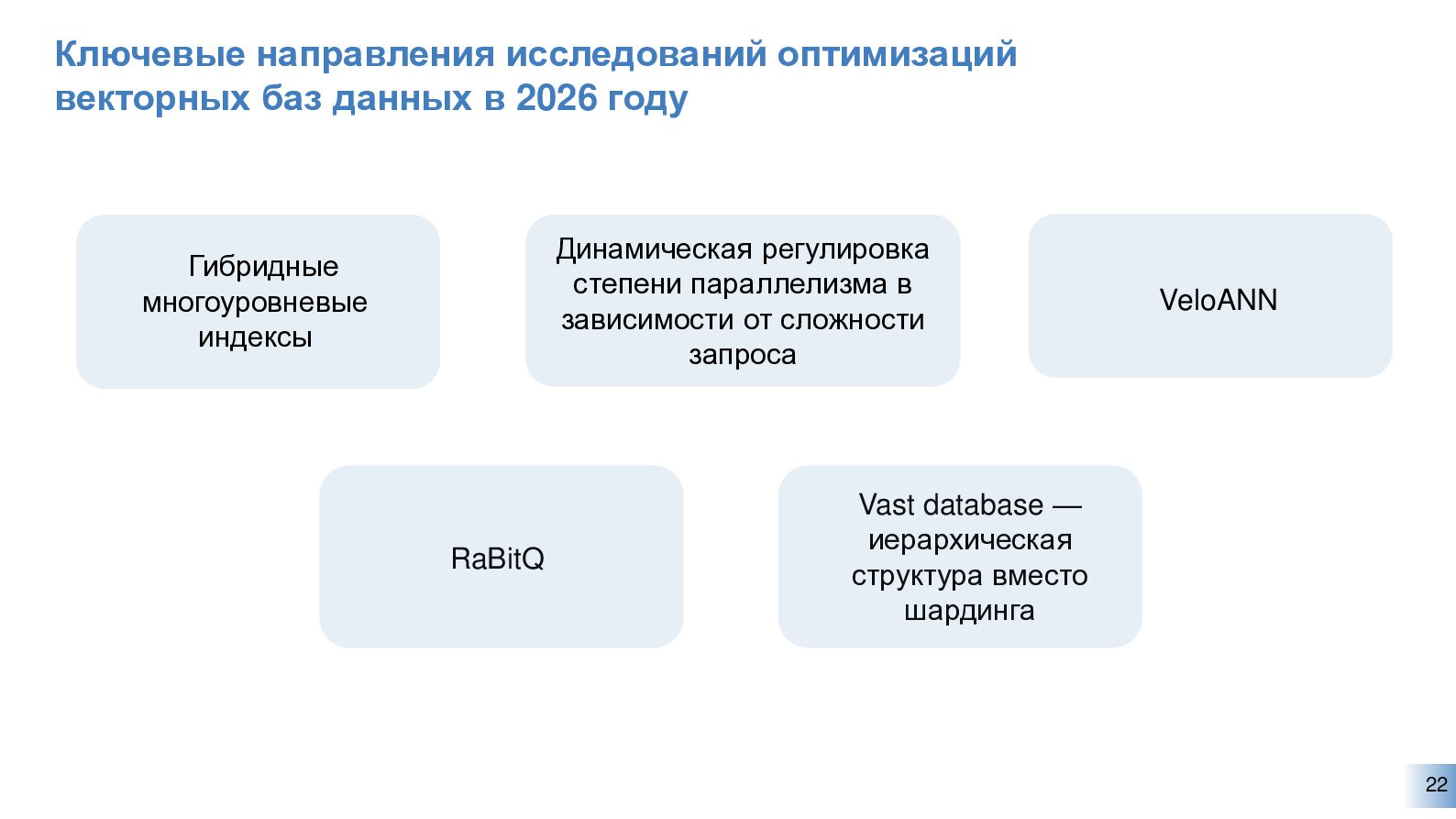{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание! Контакты: @George14adv [email protected] 29](https://files.speakerdeck.com/presentations/34e8f22178c347d2ae4f189260f7ae4b/slide_28.jpg){kind=link}