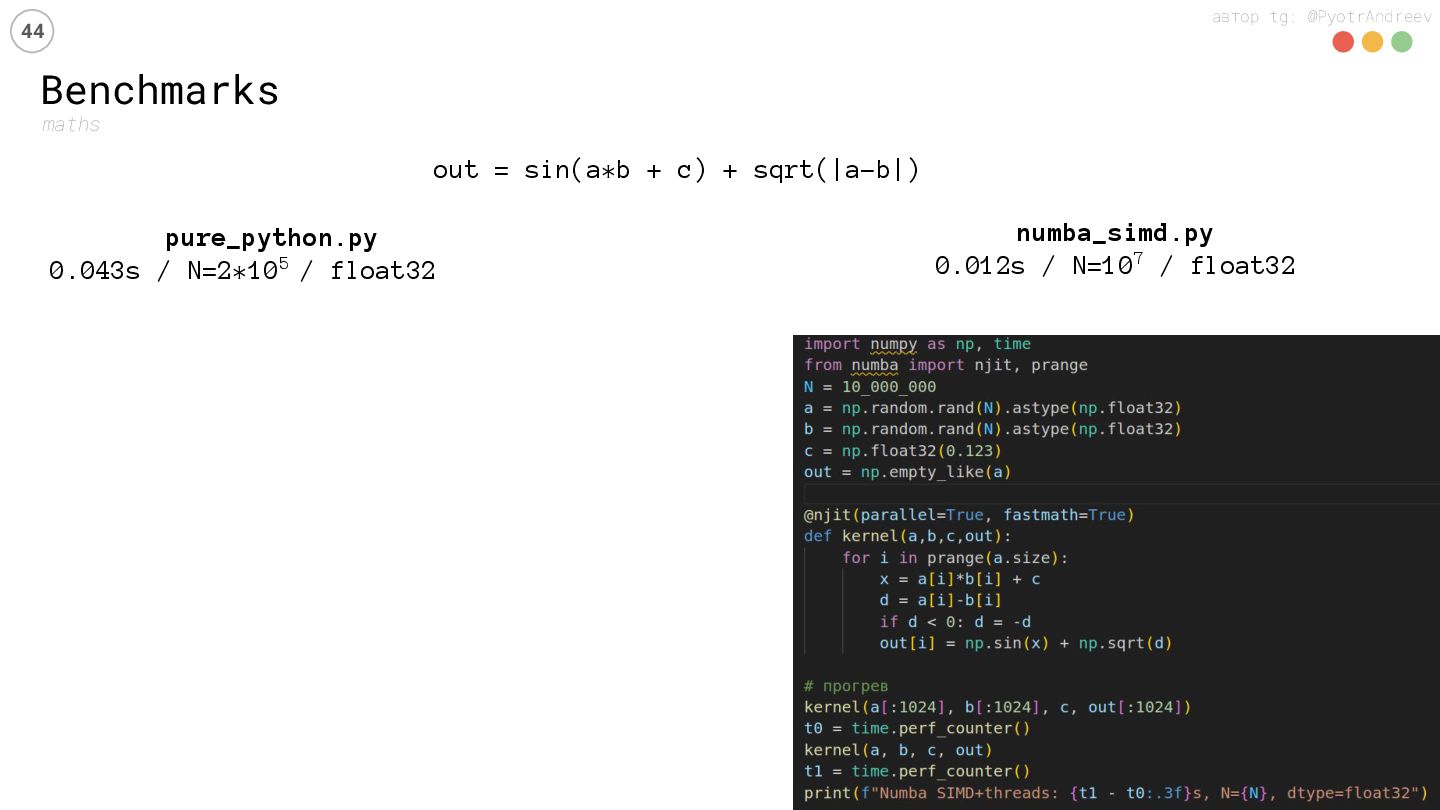
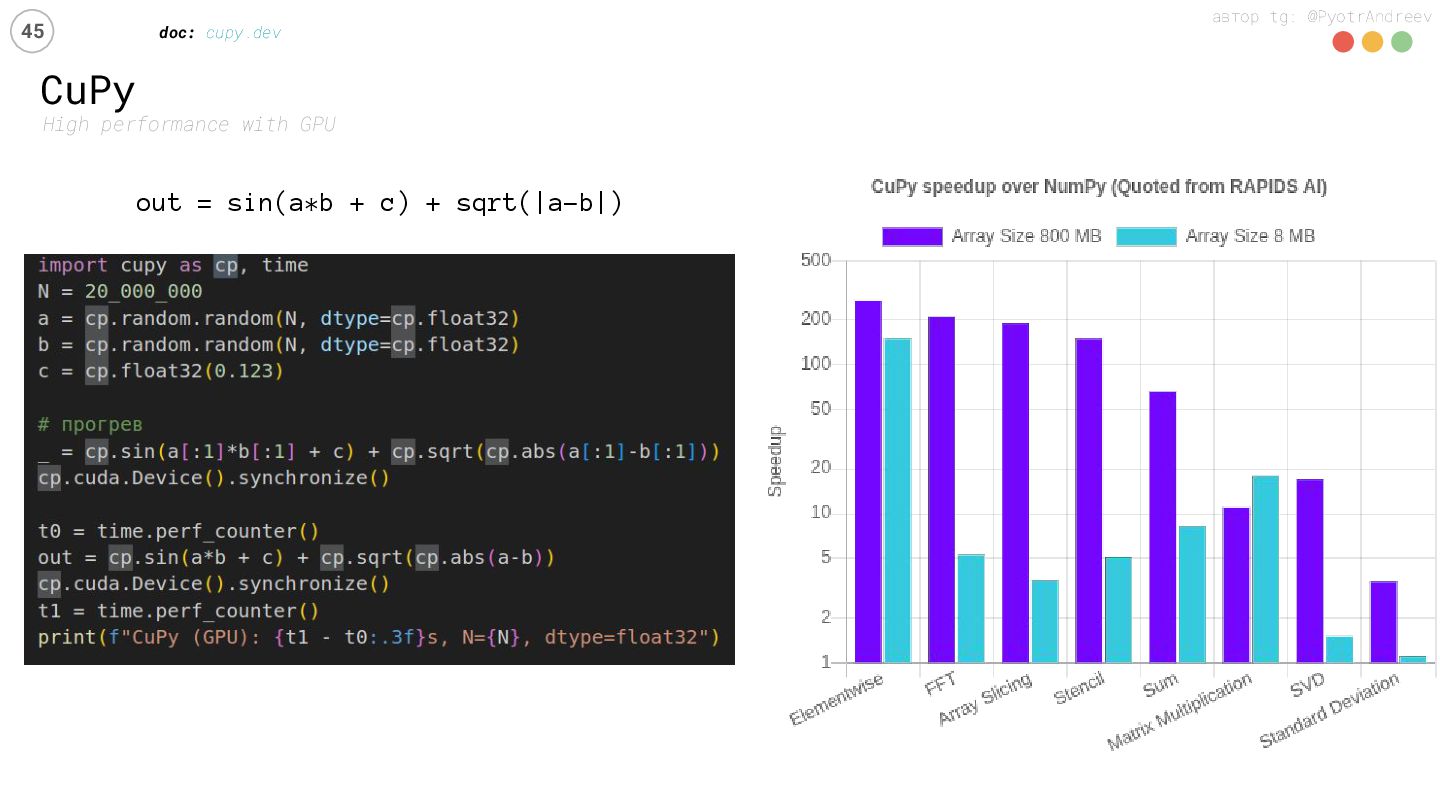
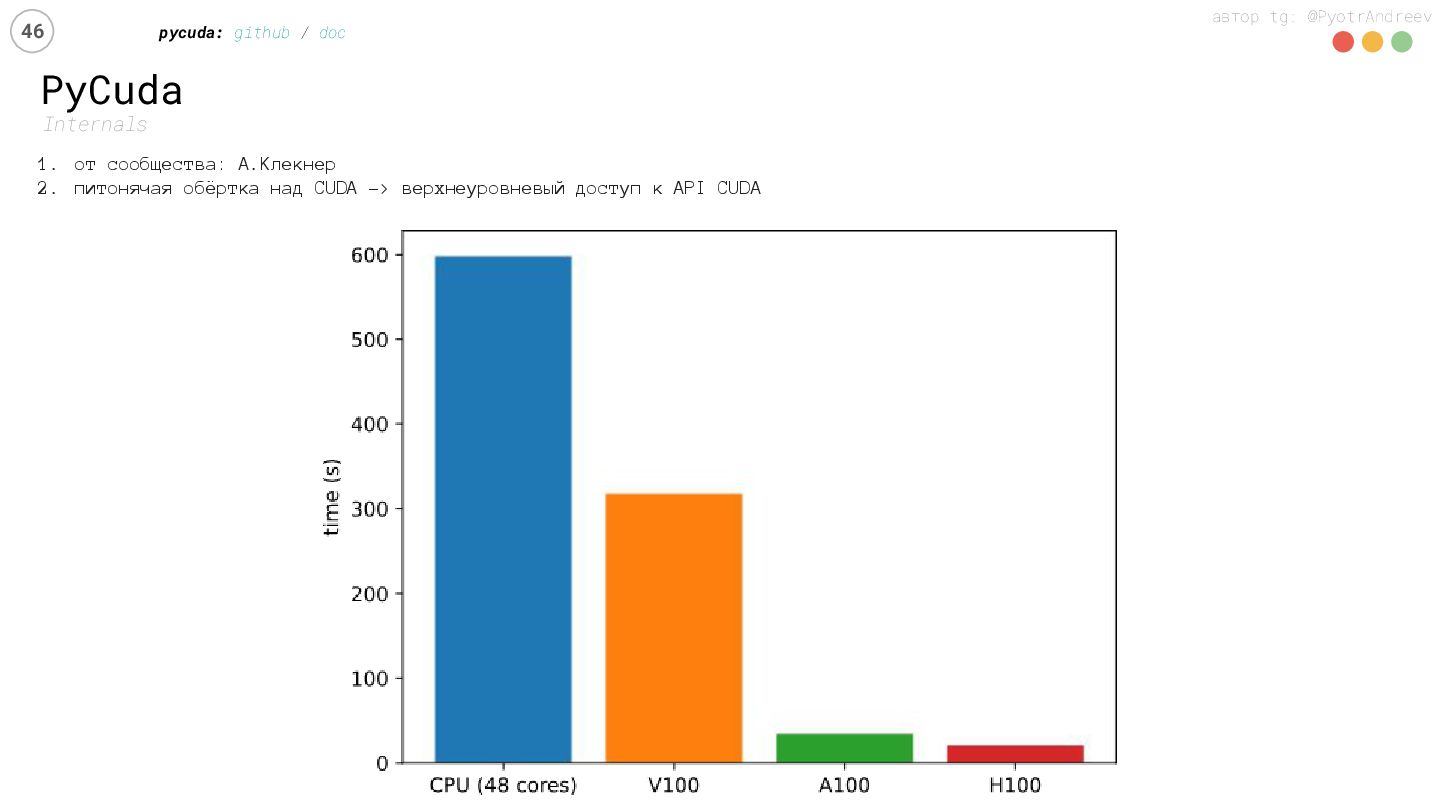
Python в 2025-м — уже не «скрипт», а инструмент, который жмёт на железо: AVX-512/SVE, Tensor Cores, NVLink/NVSwitch, HBM. Но где хватит CPU-SIMD и горизонтального масштабирования, а где GPU окупает TCO? На живых бенчмарках сравним NumPy2 (SIMD), Numba, и GPU-стек.
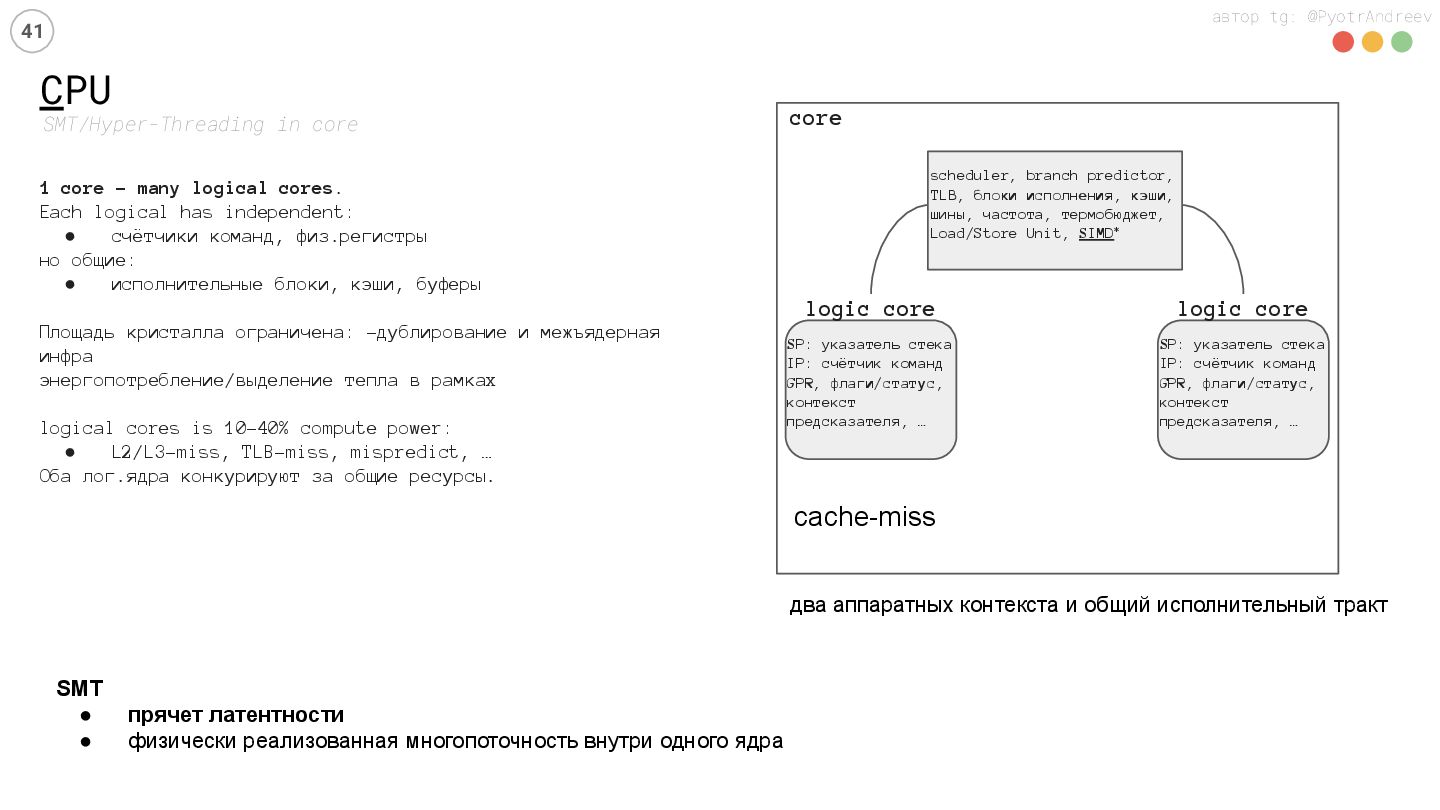
Разберём устройство C/GPU на уровне принятия решений (SM/warps, Tensor Cores, MIG). Практическая польза:
Чек-лист выбора: SIMD vs GPU vs горизонтальное масштабирование по метрикам TFLOPS/Вт, латентность и TCO
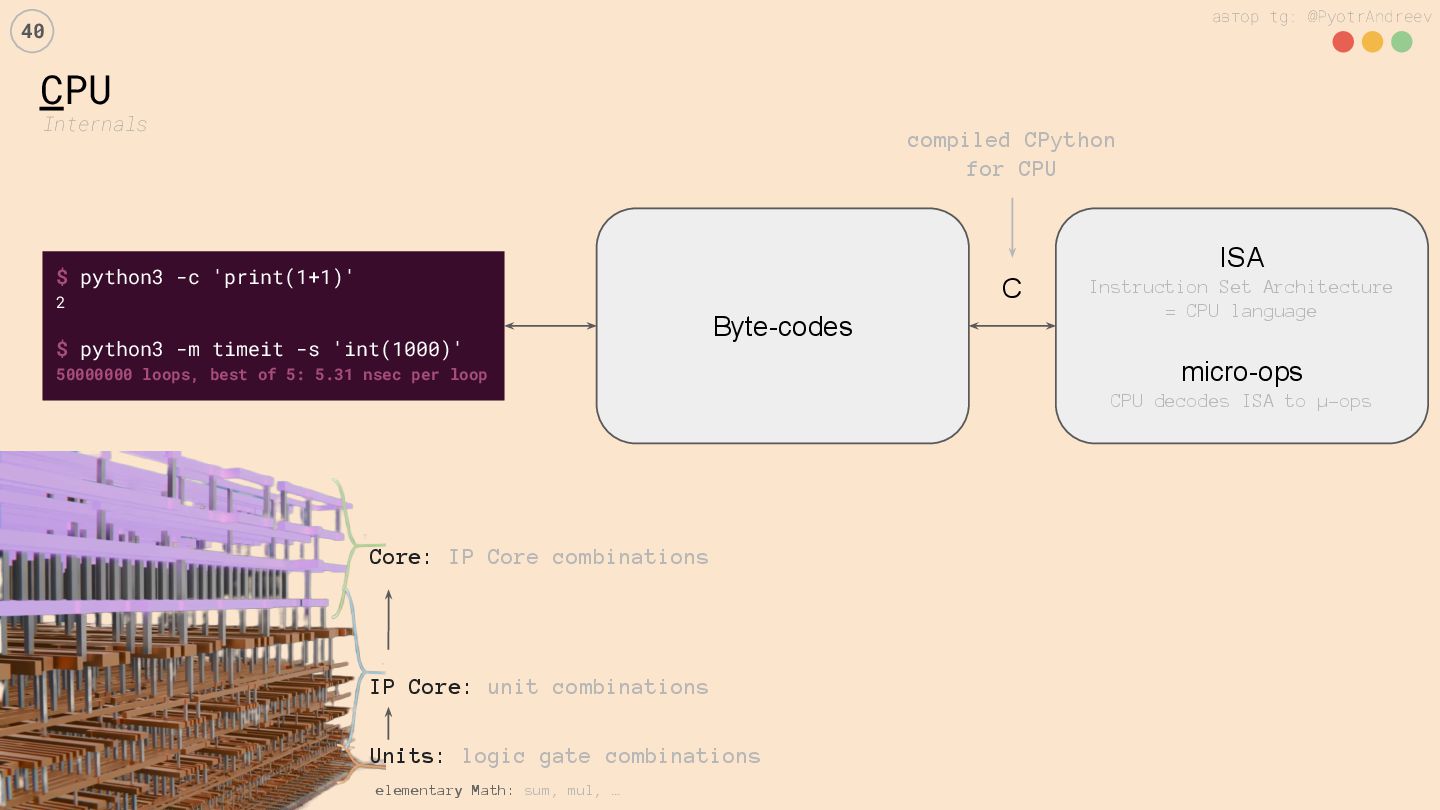
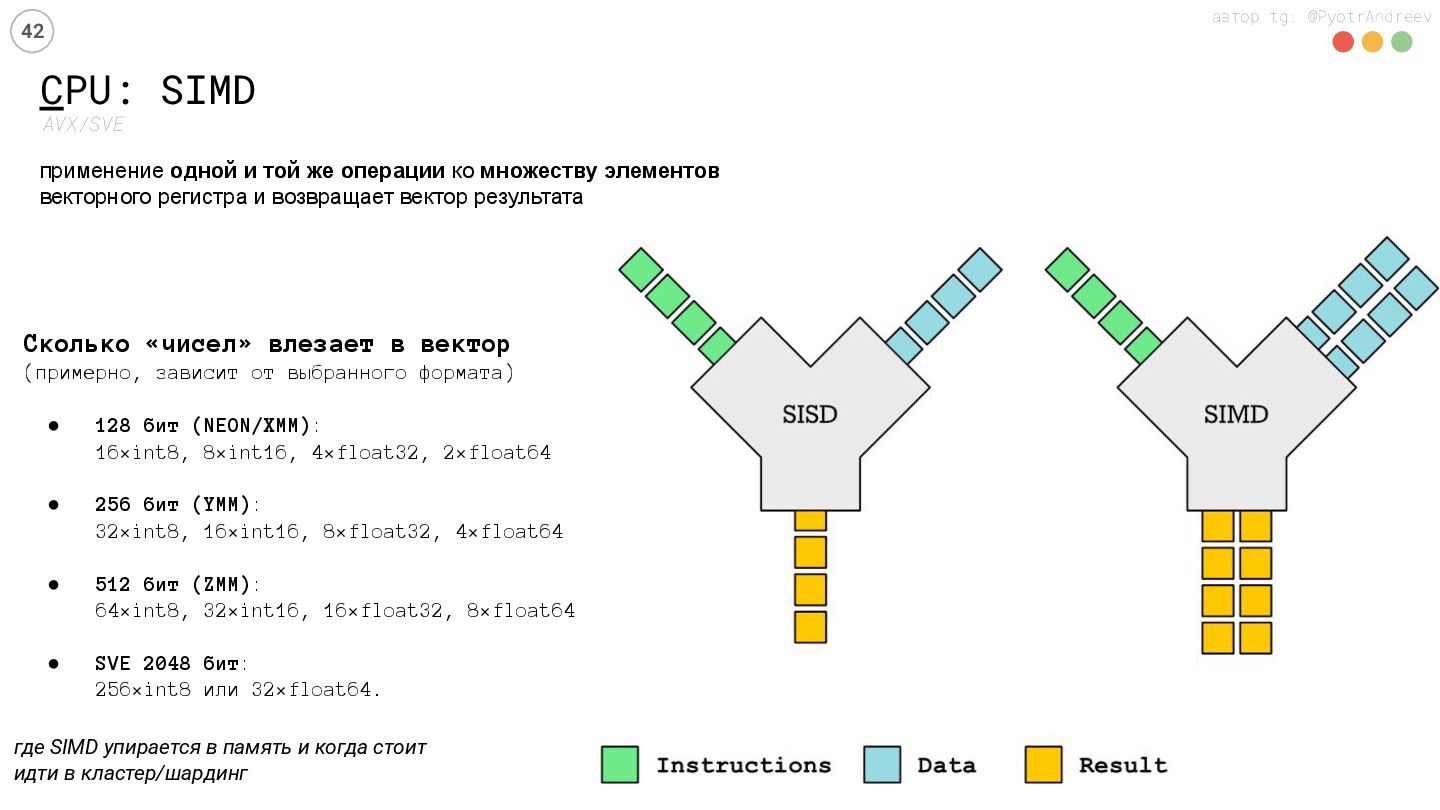
Антипаттерны: когда GPU не ускорит, где SIMD упирается в память и когда стоит идти в кластер/шардинг
Benchmark-suite и исходники для повторения тестов на вашей инфраструктуре
Видео: https://moscowpython.ru/admin/meetup/talk/321/change/
Moscow Python: http://moscowpython.ru
Курсы Learn Python: http://learn.python.ru
Moscow Python Podcast: http://podcast.python.ru
Заявки на доклады: https://bit.ly/mp-speaker
{kind=link}
{kind=link}
{kind=link}
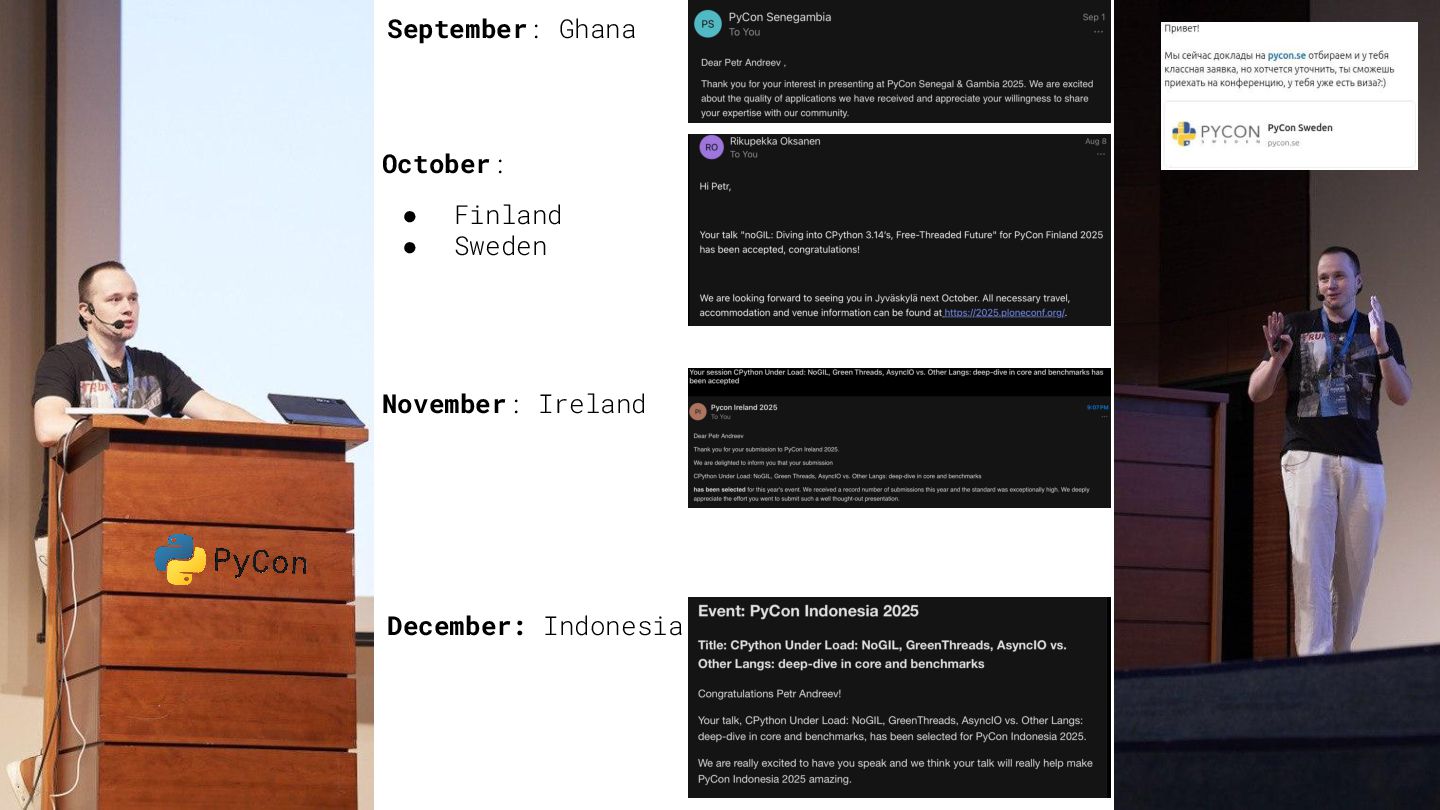{kind=link}
{kind=link}
{kind=link}
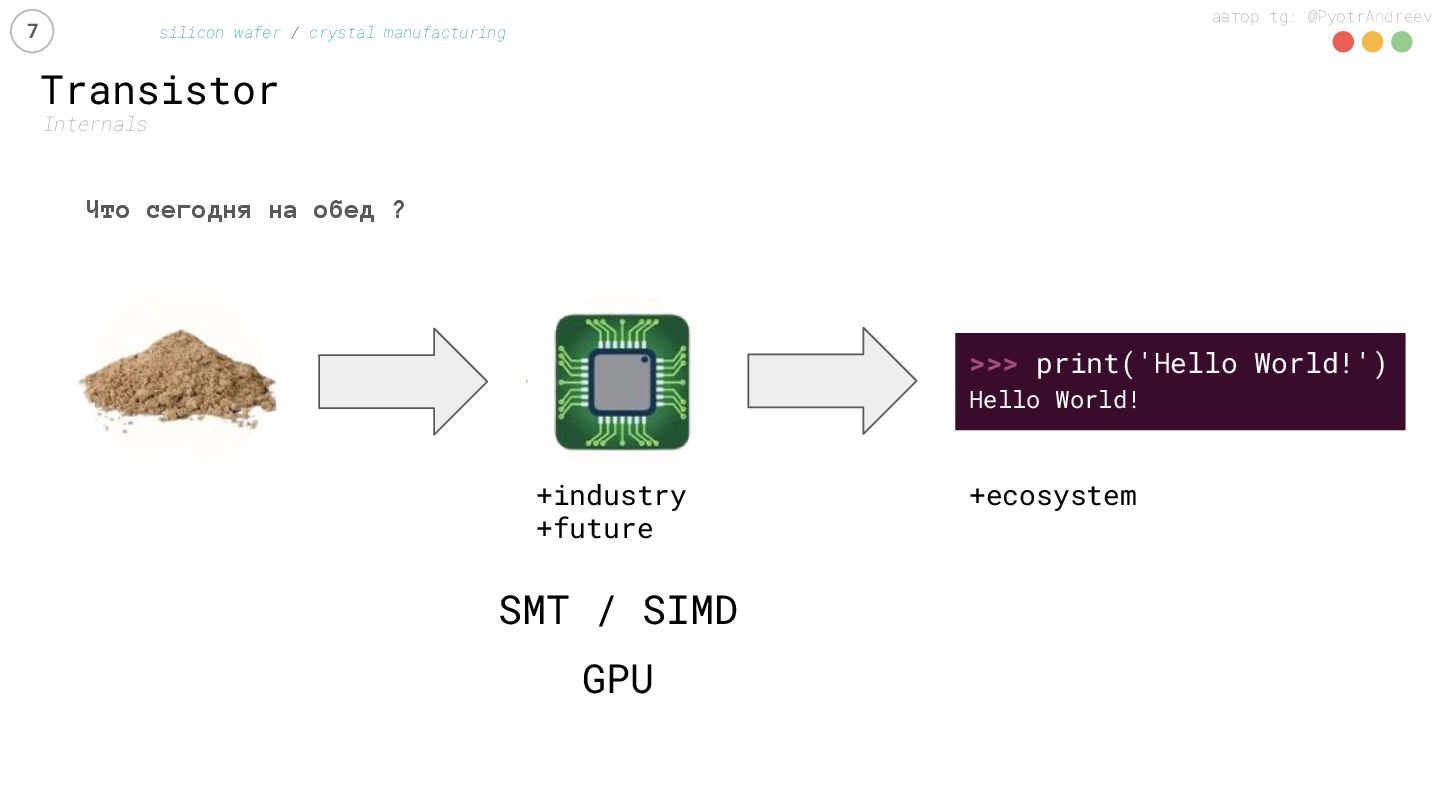{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
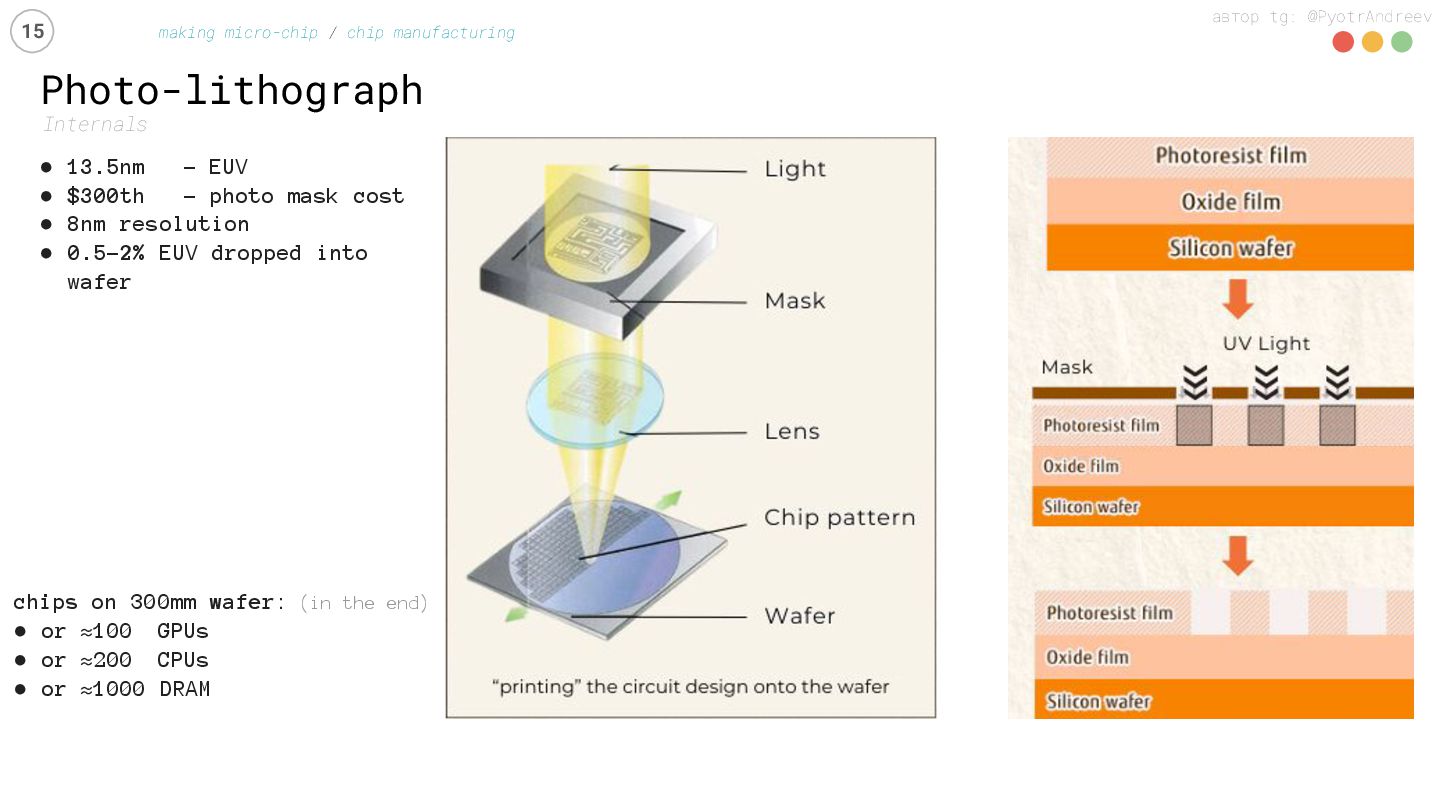{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
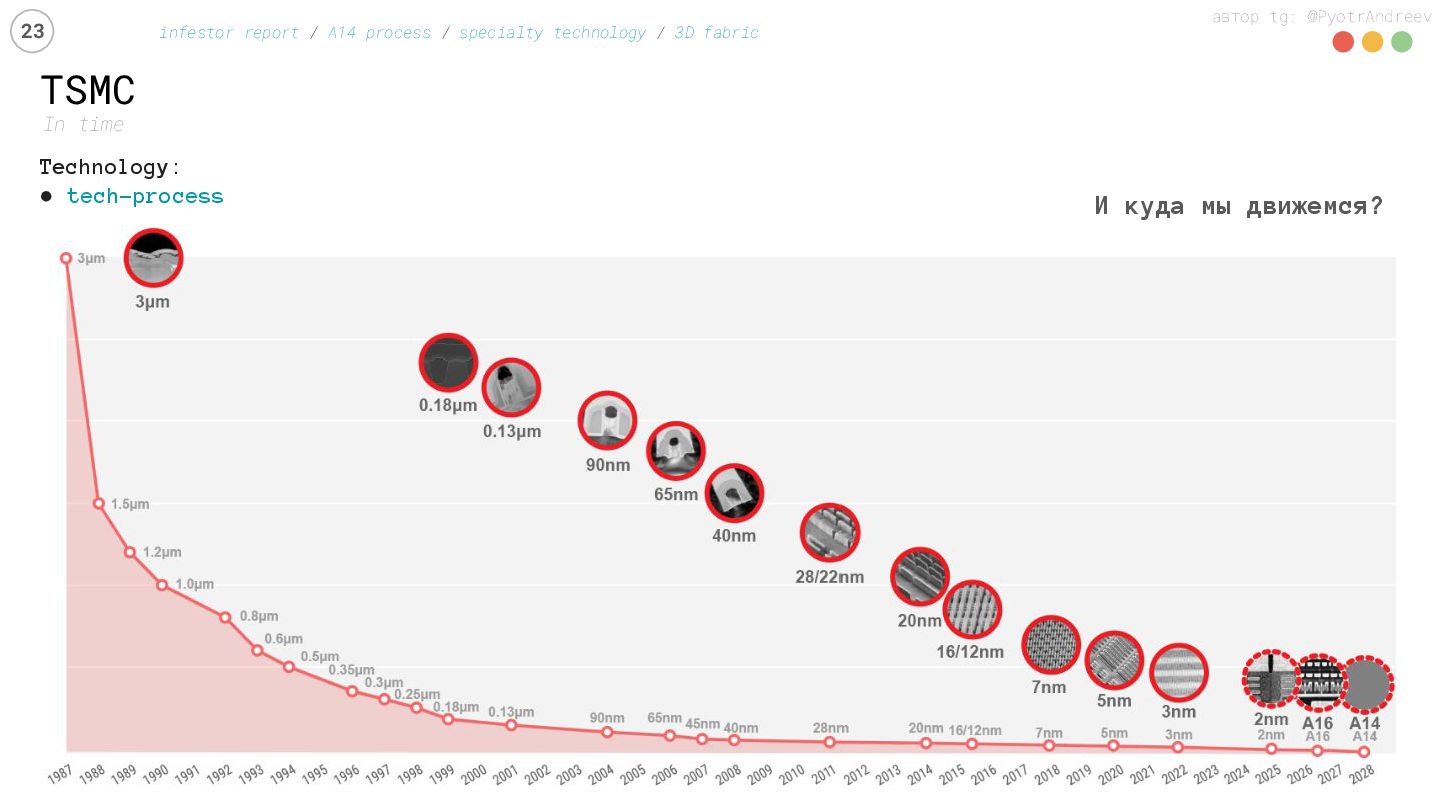{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}