This is the presentation material for our 10th place solution in the IMC2025 Challenge Talks, held at the CVPR 2025 Workshop "Image Matching: Local Features & Beyond".
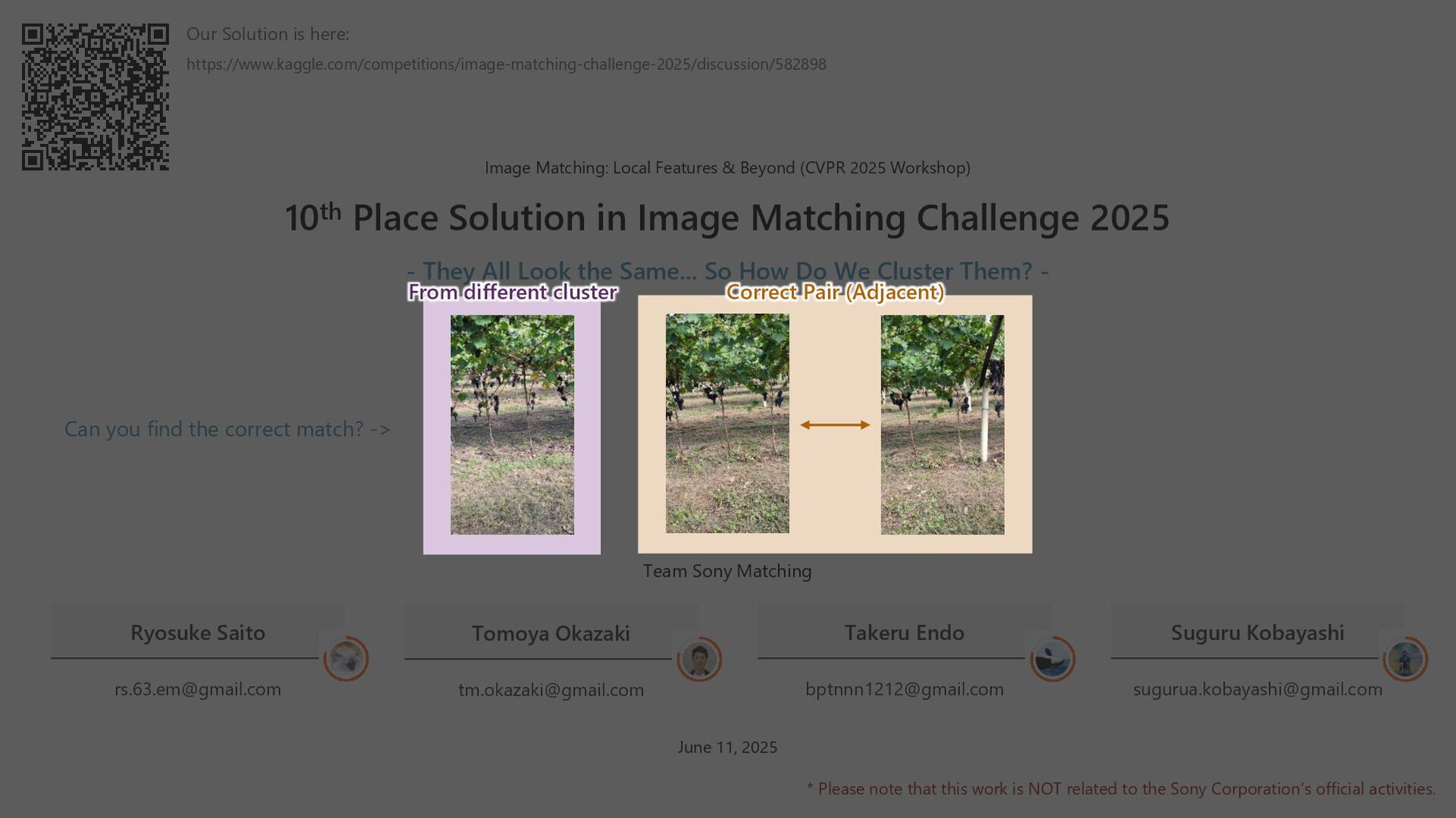
Kobayashi [email protected] * Please note that this work is NOT related to the Sony Corporation’s official activities. June 11, 2025 Team Sony Matching Our Solution is here: https://www.kaggle.com/competitions/image-matching-challenge-2025/discussion/582898 Can you find the correct match? -> Image Matching: Local Features & Beyond (CVPR 2025 Workshop) 10th Place Solution in Image Matching Challenge 2025 - They All Look the Same... So How Do We Cluster Them? -
Place Solution in Image Matching Challenge 2025 - They All Look the Same... So How Do We Cluster Them? - Can you find the correct match? -> Ryosuke Saito [email protected] Tomoya Okazaki [email protected] Takeru Endo [email protected] Suguru Kobayashi [email protected] * Please note that this work is NOT related to the Sony Corporation’s official activities. June 11, 2025 Team Sony Matching Our Solution is here: https://www.kaggle.com/competitions/image-matching-challenge-2025/discussion/582898 Correct Pair (Adjacent) From different cluster
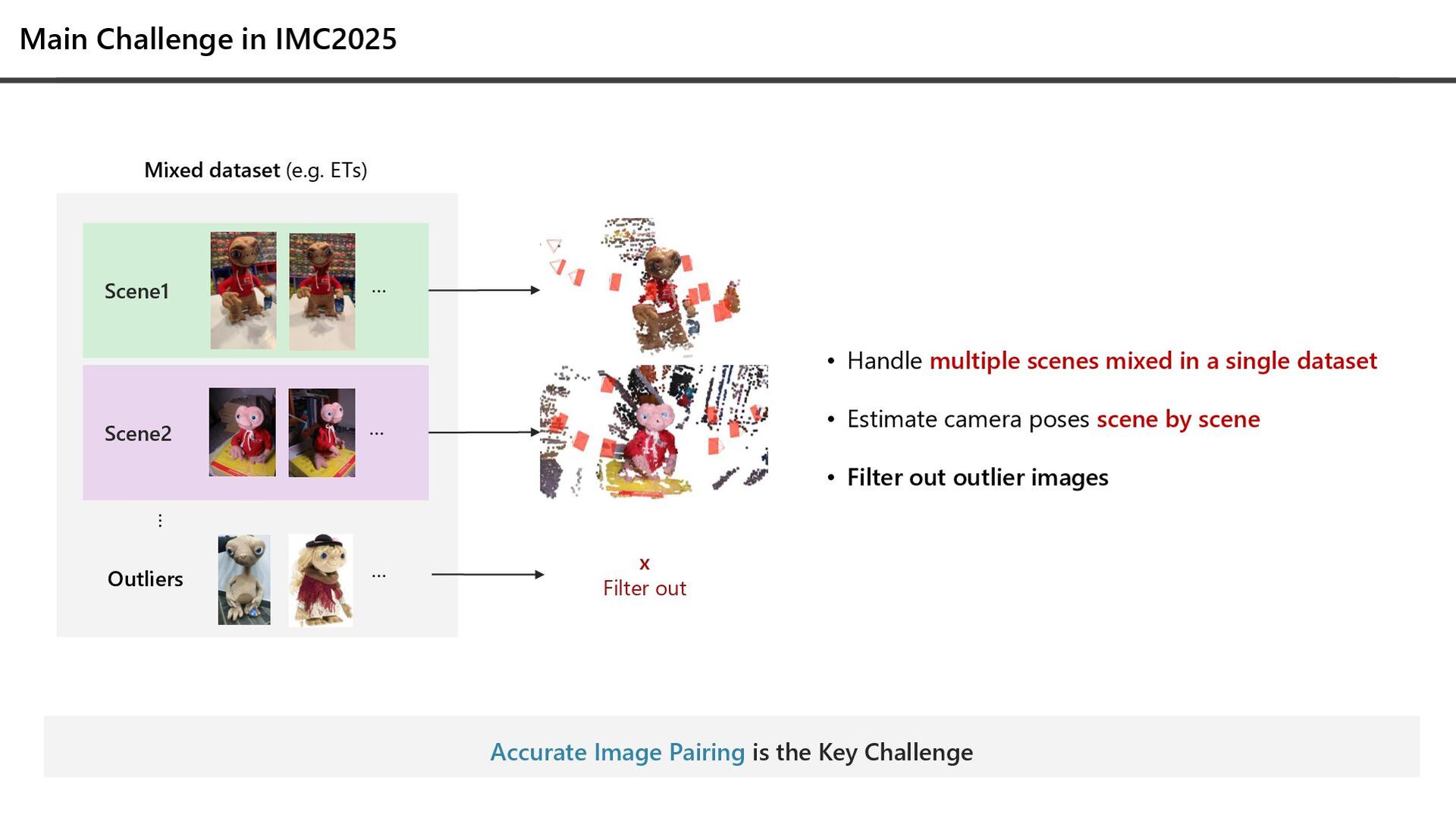
a single dataset • Estimate camera poses scene by scene • Filter out outlier images Scene1 … Outliers Mixed dataset (e.g. ETs) … Scene2 … … x Filter out Accurate Image Pairing is the Key Challenge
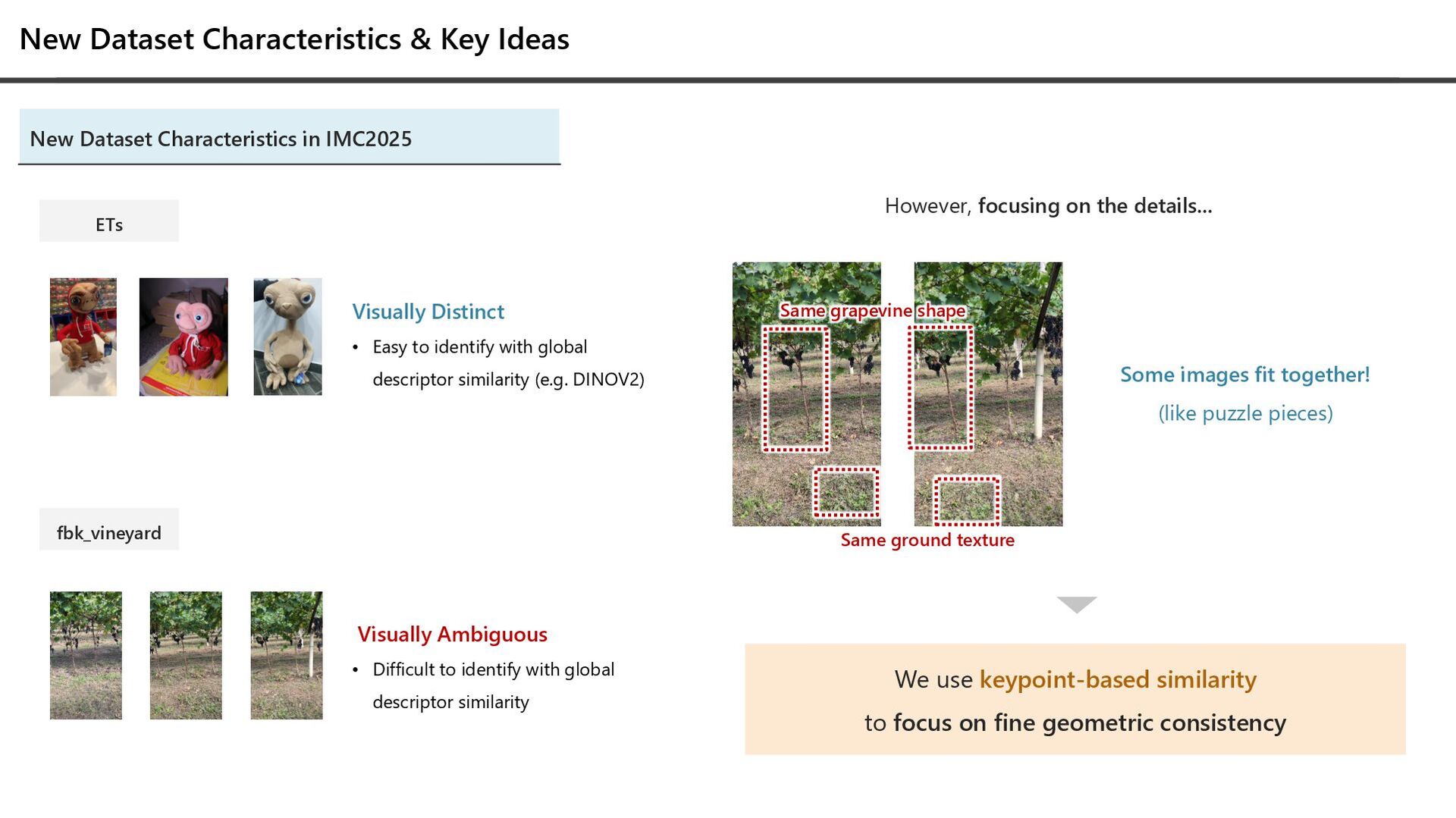
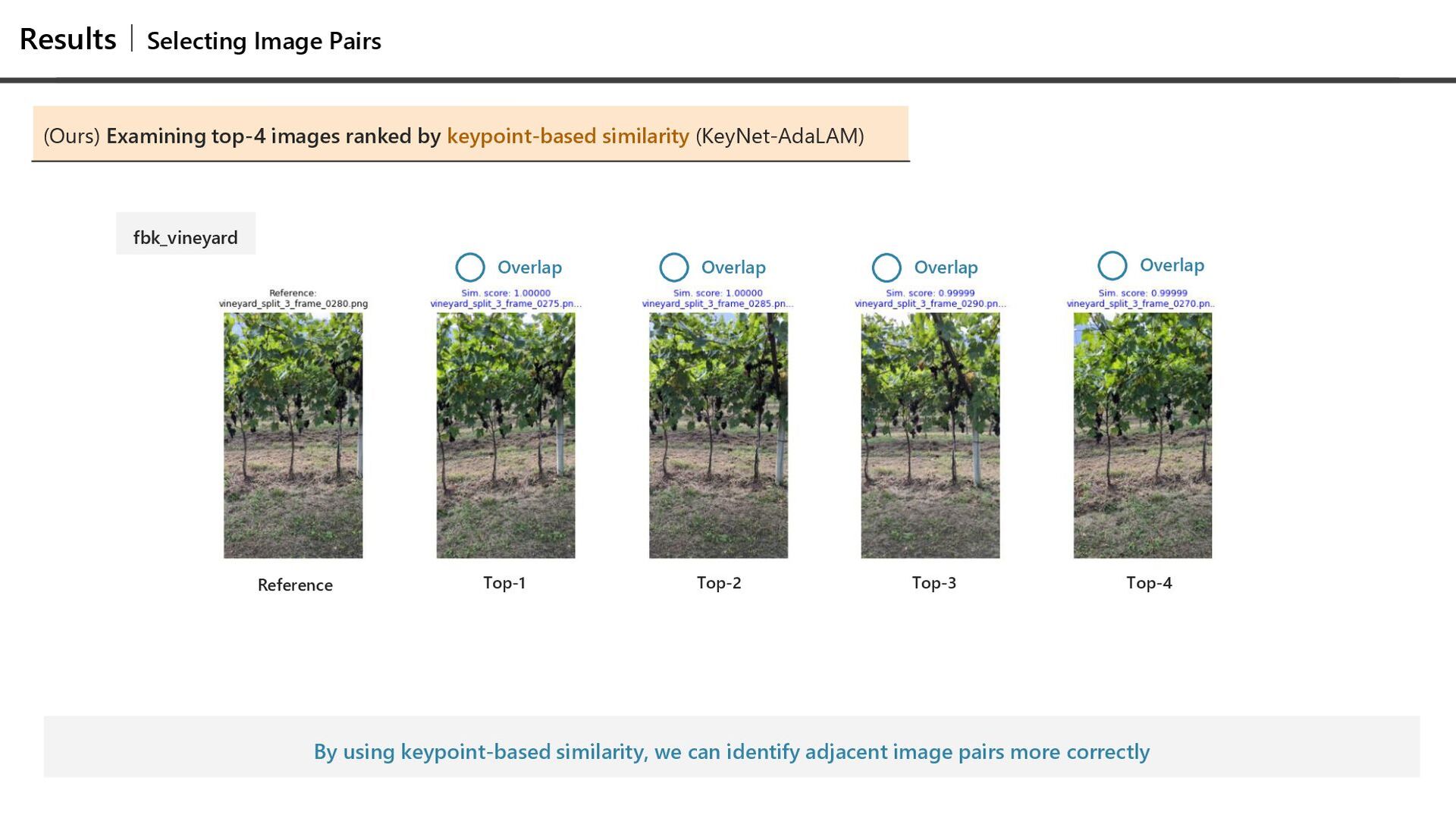
IMC2025 ETs fbk_vineyard Visually Distinct • Easy to identify with global descriptor similarity (e.g. DINOV2) Visually Ambiguous • Difficult to identify with global descriptor similarity However, focusing on the details... Same grapevine shape Same ground texture We use keypoint-based similarity to focus on fine geometric consistency Some images fit together! (like puzzle pieces)
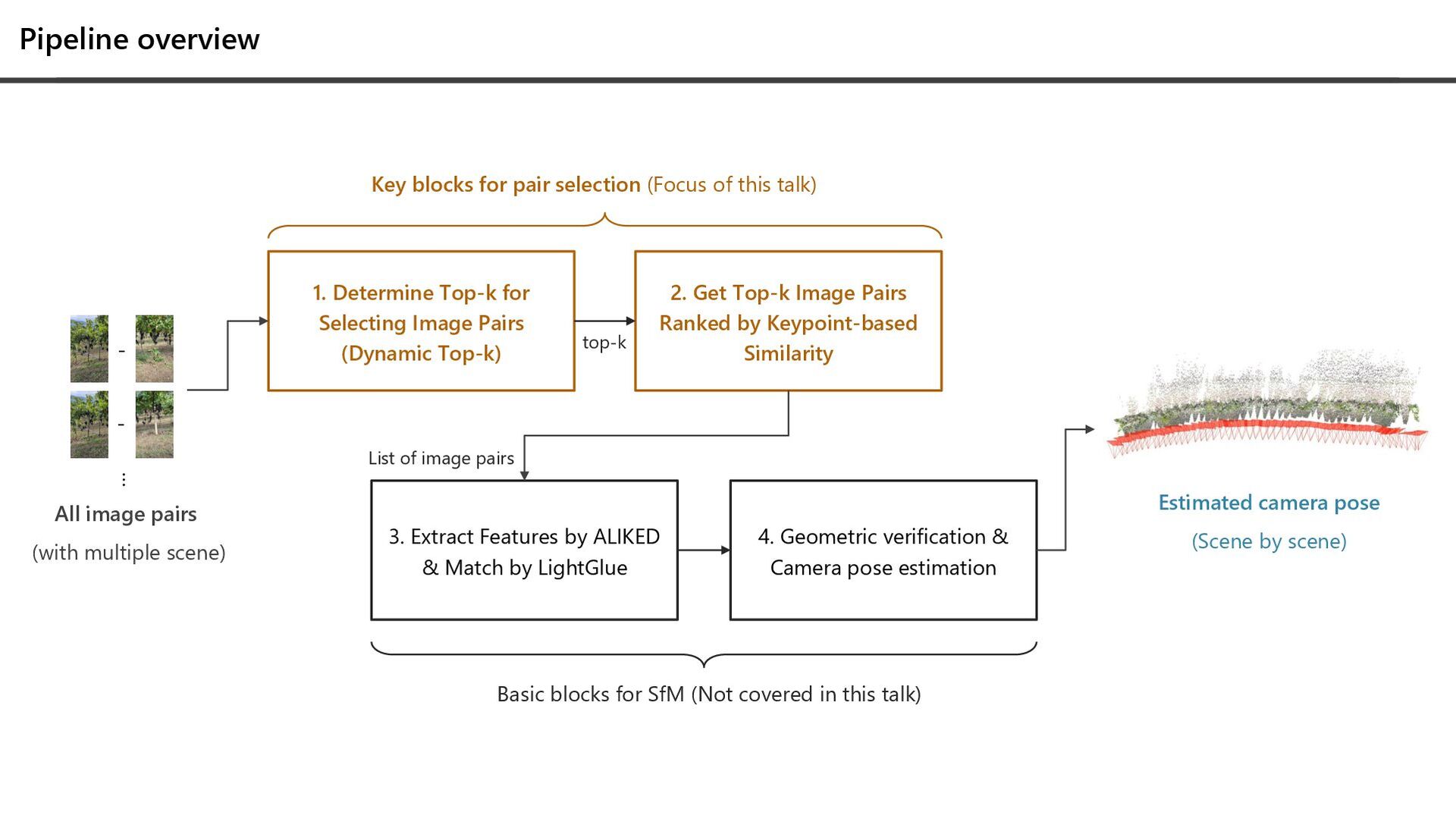
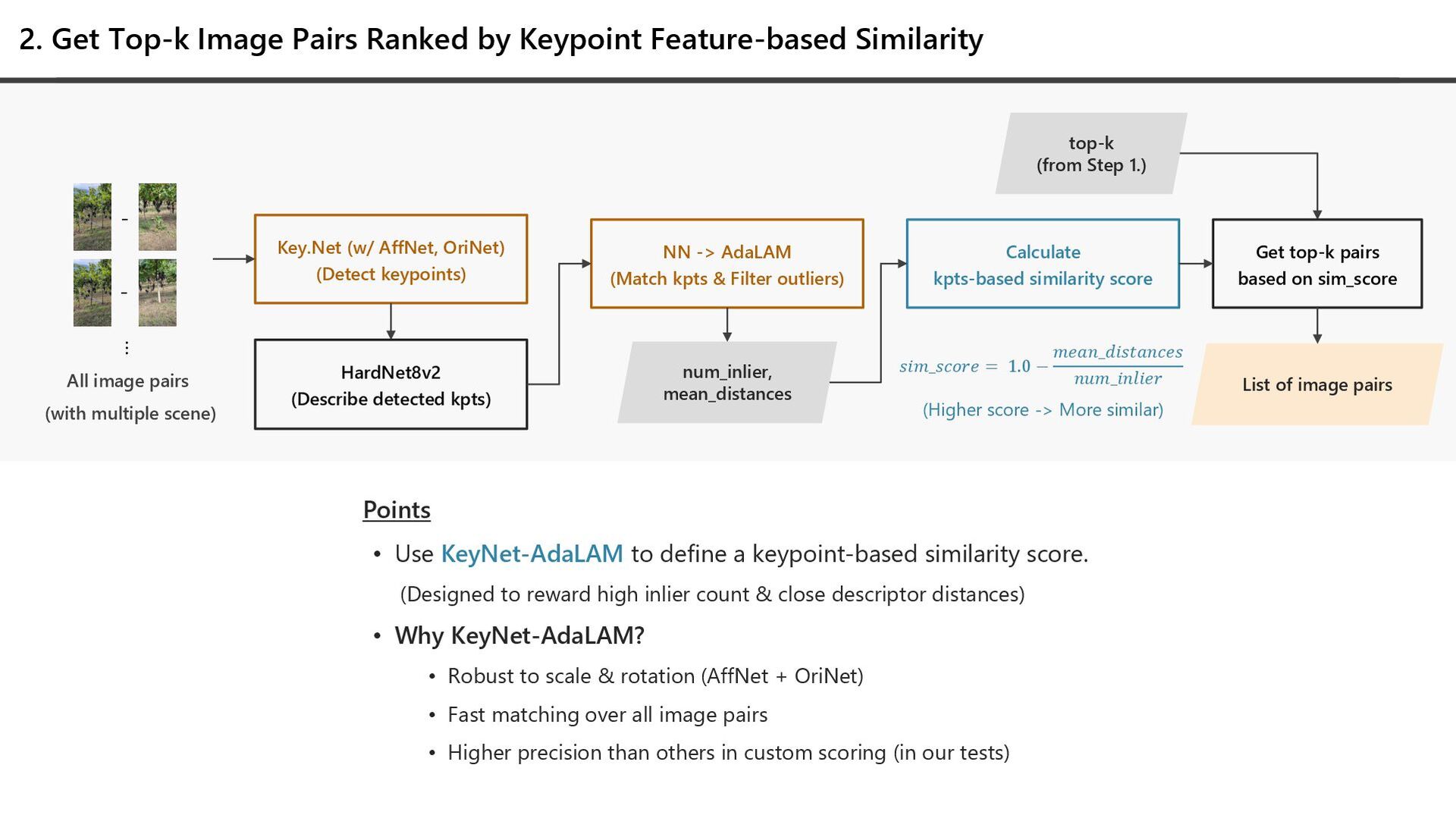
… 1. Determine Top-k for Selecting Image Pairs (Dynamic Top-k) 2. Get Top-k Image Pairs Ranked by Keypoint-based Similarity 3. Extract Features by ALIKED & Match by LightGlue 4. Geometric verification & Camera pose estimation Estimated camera pose (Scene by scene) Basic blocks for SfM (Not covered in this talk) Key blocks for pair selection (Focus of this talk) List of image pairs top-k
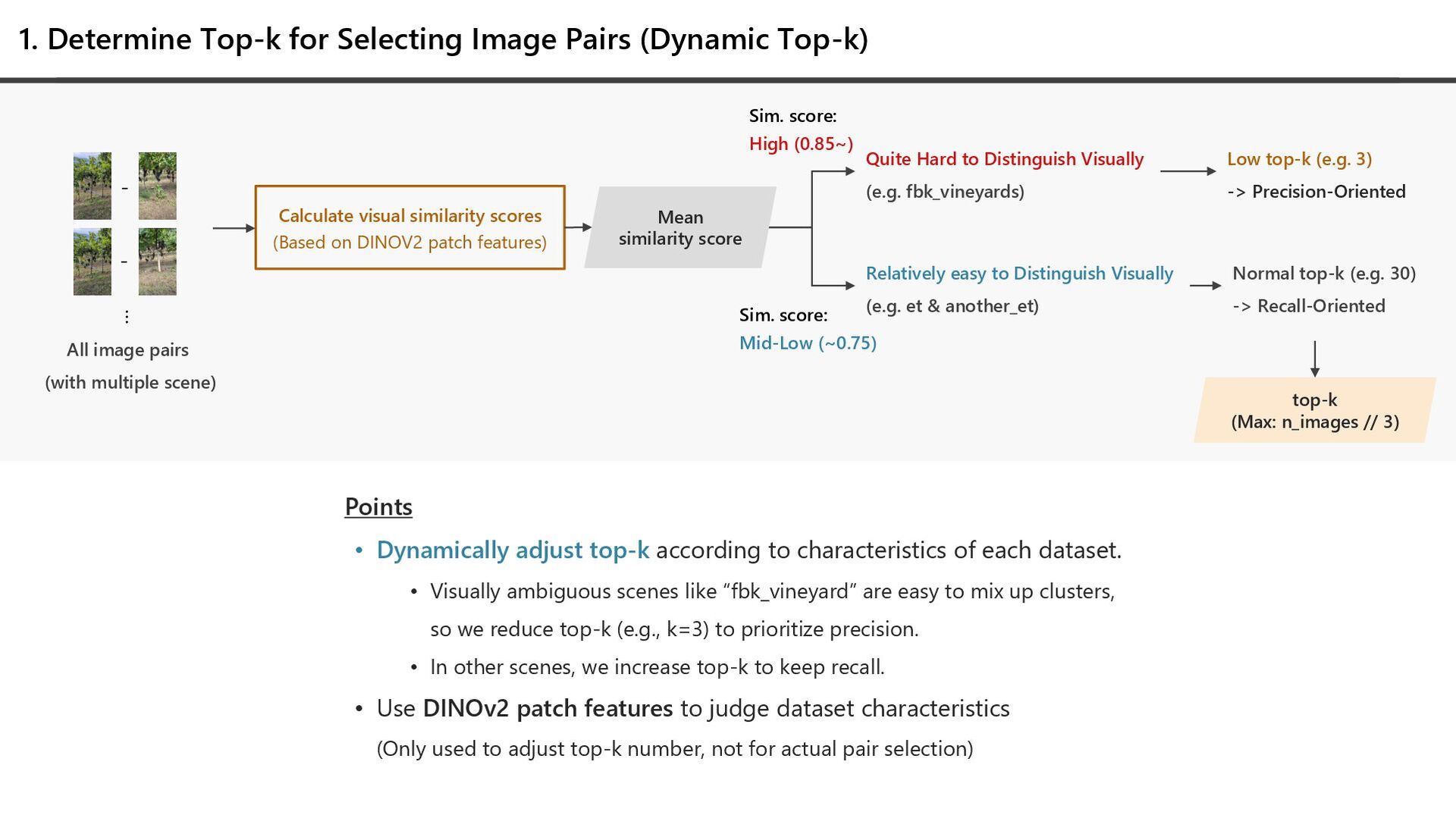
visual similarity scores (Based on DINOV2 patch features) Quite Hard to Distinguish Visually (e.g. fbk_vineyards) Relatively easy to Distinguish Visually (e.g. et & another_et) Mean similarity score Sim. score: High (0.85~) Sim. score: Mid-Low (~0.75) Low top-k (e.g. 3) -> Precision-Oriented Normal top-k (e.g. 30) -> Recall-Oriented top-k (Max: n_images // 3) All image pairs (with multiple scene) - - … Points • Dynamically adjust top-k according to characteristics of each dataset. • Visually ambiguous scenes like “fbk_vineyard” are easy to mix up clusters, so we reduce top-k (e.g., k=3) to prioritize precision. • In other scenes, we increase top-k to keep recall. • Use DINOv2 patch features to judge dataset characteristics (Only used to adjust top-k number, not for actual pair selection)
global descriptor similarity can lead to incorrect matches (Comparison) Examining top-4 images ranked by global descriptor similarity (DINOV2) Overlap Top-1 Top-2 Top-3 Top-4 Reference fbk_vineyard No overlap Overlap
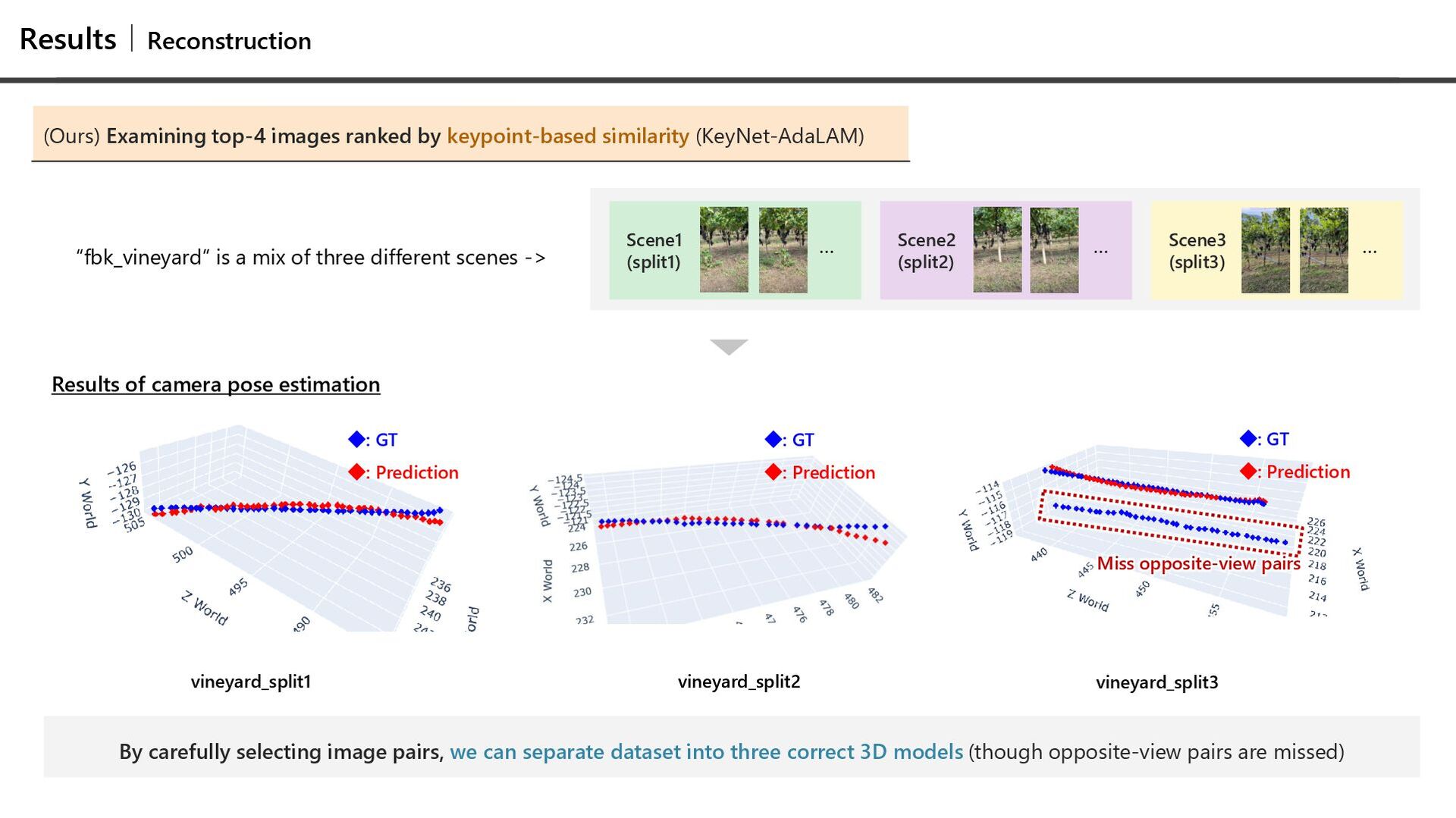
into three correct 3D models (though opposite-view pairs are missed) Scene1 (split1) Scene2 (split2) Scene3 (split3) … “fbk_vineyard” is a mix of three different scenes -> vineyard_split1 vineyard_split2 vineyard_split3 ◆: GT ◆: Prediction ◆: GT ◆: Prediction ◆: GT ◆: Prediction … … Miss opposite-view pairs (Ours) Examining top-4 images ranked by keypoint-based similarity (KeyNet-AdaLAM) Results of camera pose estimation
Final Pipeline [1] J. Wang et al., VGGT: Visual Geometry Grounded Transformer, CVPR, 2025 Our Pipeline w/ VGGT tracker VGGT tracker provides strong matching capabilities even for opposite-view image pairs Result of fbk_vineyard split3 (w/ opposite-view pairs) VGGT tracker[1] ◆: GT ◆: Prediction Grapevines Grapevines Integrate w/o VGGT tracker Opposite-view pairs are misclassified as different scenes Grapevines ◆: GT ◆: Prediction w/ VGGT tracker Opposite-view pairs are recognized as same scenes VGGT tracker Incorrectly devided into two models
• Global descriptors alone is difficult to handle visually ambiguous datasets correctly. • To focus on fine geometry consistency, we use keypoint-based similarity score. • Careful pair selection improves reconstruction results on ambiguous datasets. • VGGT offers promising results for future pipelines — even with complex cases like opposite views. Takeaways
![Ryosuke Saito [email protected] Tomoya Okazaki [email protected] Takeru Endo [email protected] Suguru](https://files.speakerdeck.com/presentations/2d85939dd4dd4037a71c4428ee13098e/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Exploration for VGGT: Visual Geometry Grounded Transformer[1] * Not in](https://files.speakerdeck.com/presentations/2d85939dd4dd4037a71c4428ee13098e/slide_10.jpg){kind=link}
{kind=link}