Machine learning has seen an impressing boom in the past years. In practice, every learning algorithm has to prove its worth by better classification/prediction performance than previous algorithms. However, obvious performance measures such as the misclassification rate and so on suffer a high variability across data-sets or even re-sampling iterations. Thus, it is a challenging problem to assess the performance reliably, and its importance has been given surprisingly little attention in literature and practice. I will talk about the usual performance measures such as misclassification rate, AUC or mean squared error etc. I will explain cross-validation and its pitfalls. Finally, I will show you a new method to estimate the variability of the performance estimators in a general and statistically correct way.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
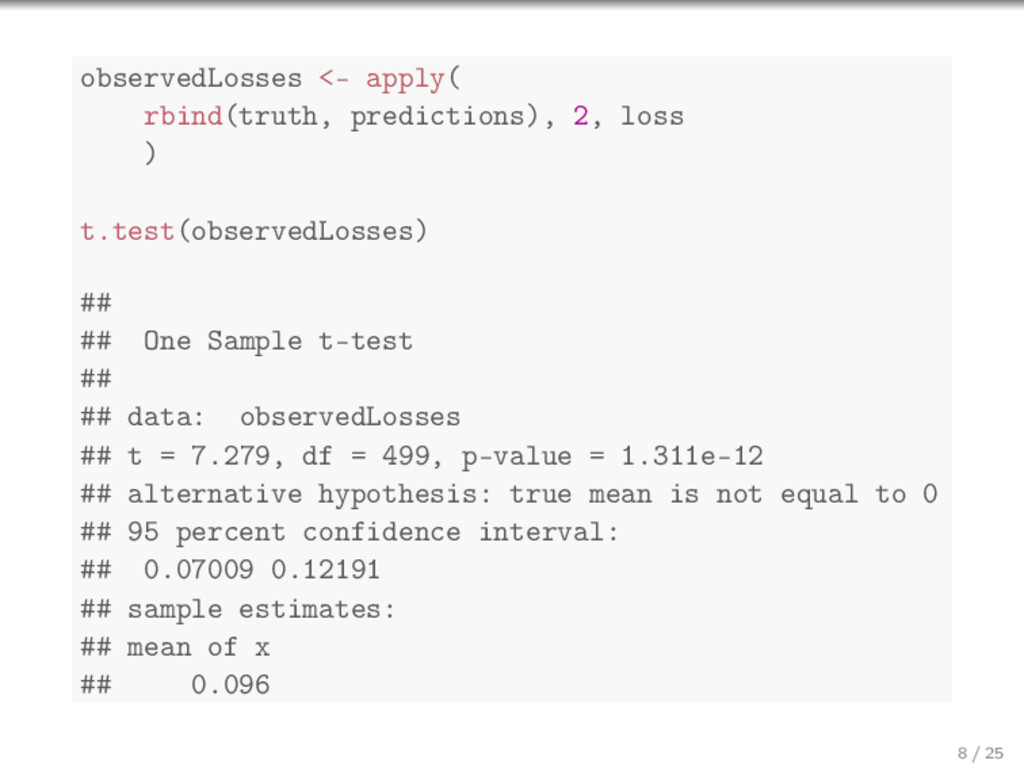{kind=link}
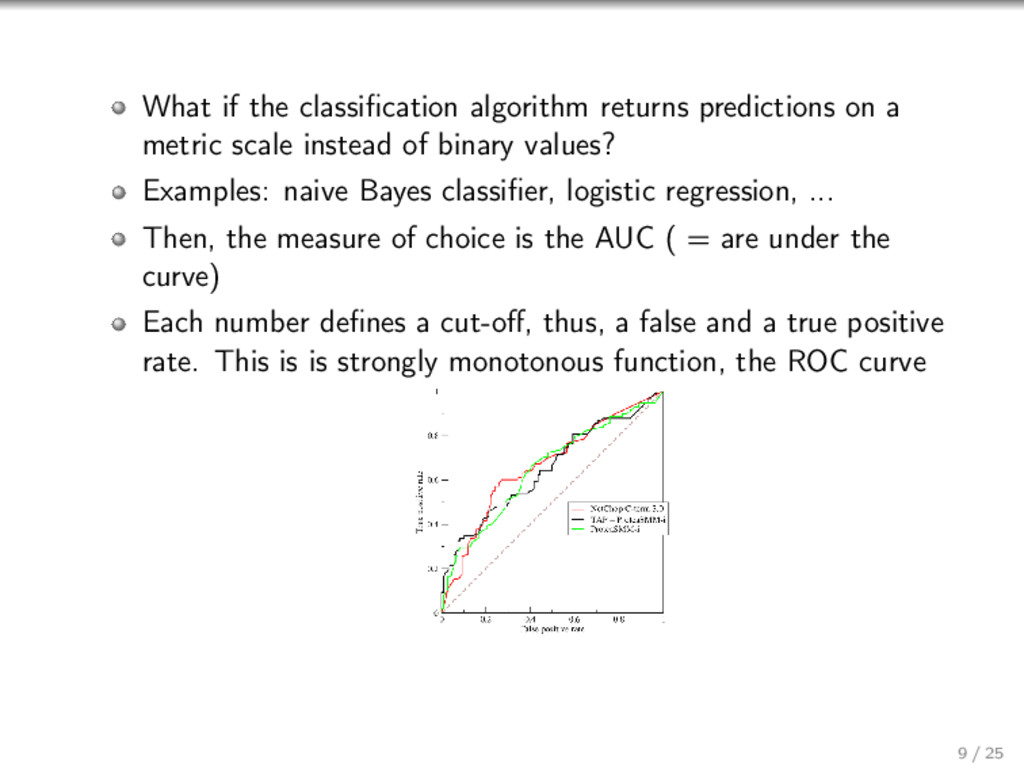{kind=link}
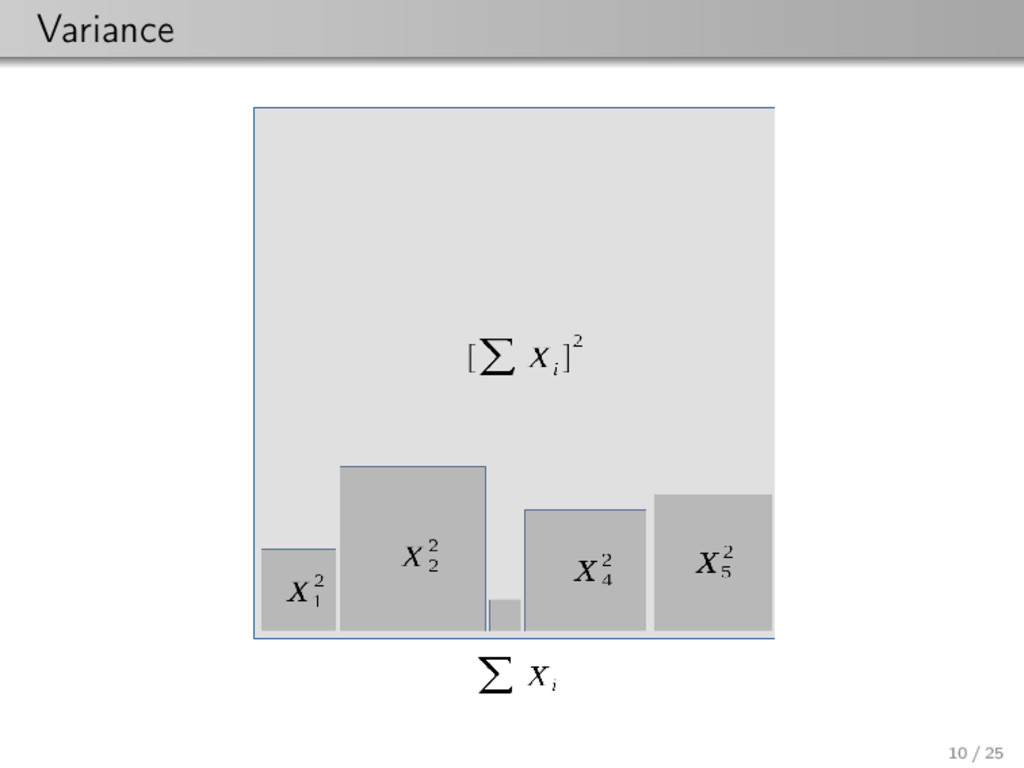{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
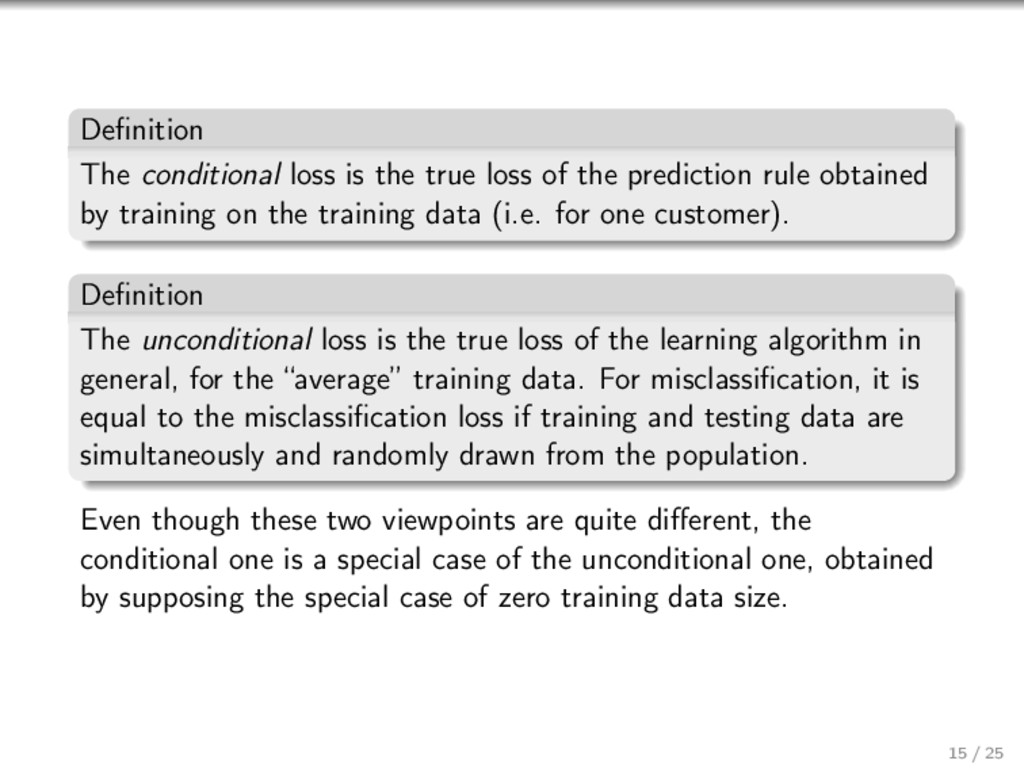{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks for your attention! www.biostats.de [email protected] 25 / 25](https://files.speakerdeck.com/presentations/fabeb180ceda01312cdc6aa590f2ec17/slide_24.jpg){kind=link}