expressible in terms of byte-buffer memory allocation / access patterns are to be addressed maintain a Commit Log for durability in concurrent environments, use concurrent data structures use data structures that give maximum available features: sorted index per column would allow searches on arbitrary column levelling / compaction allows simplifying sequencing data use approximate DSs (appx. histograms, bloom filters, sketches) to reduce overhead, get some big-O guarantees
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
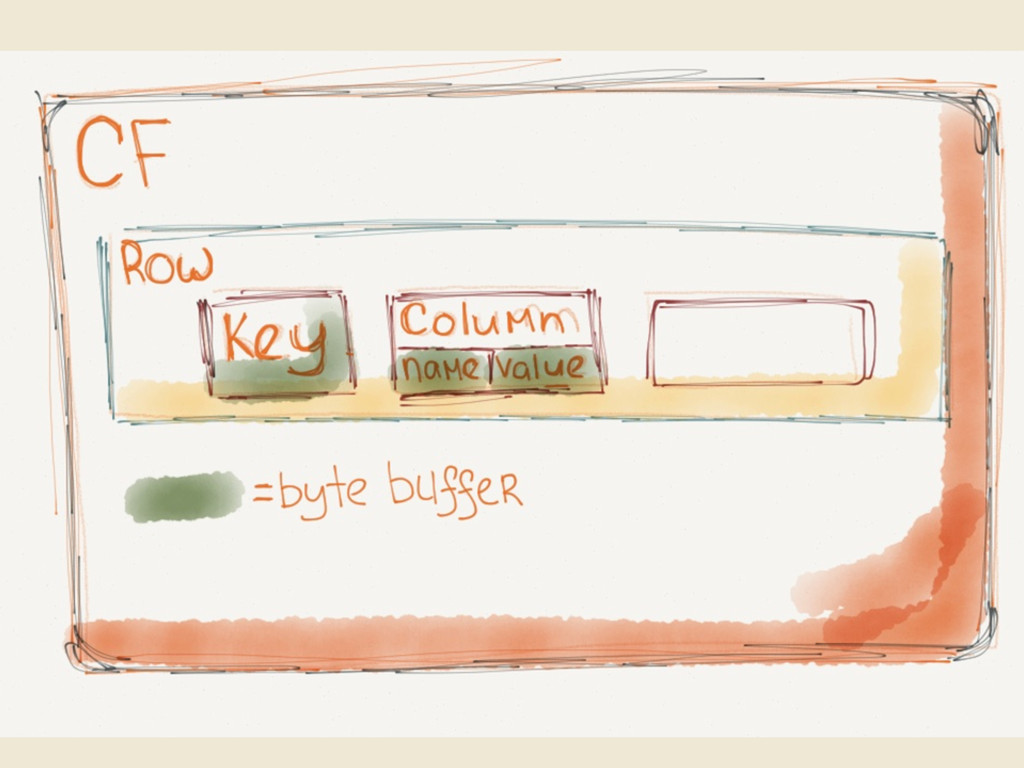{kind=link}
{kind=link}
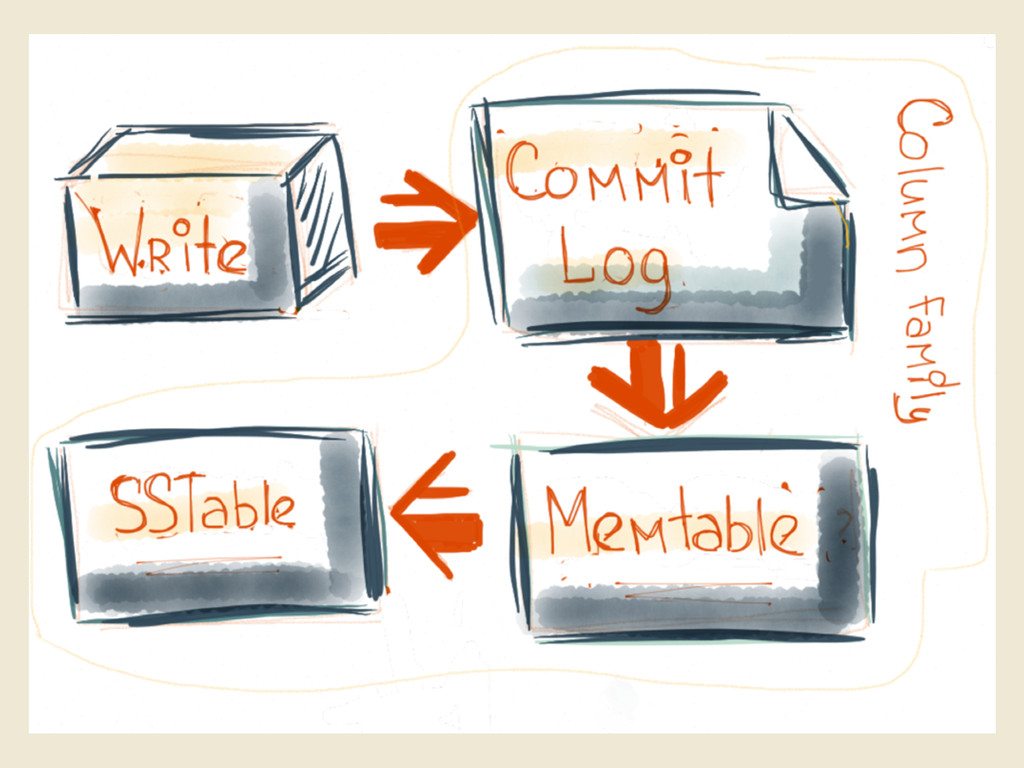{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
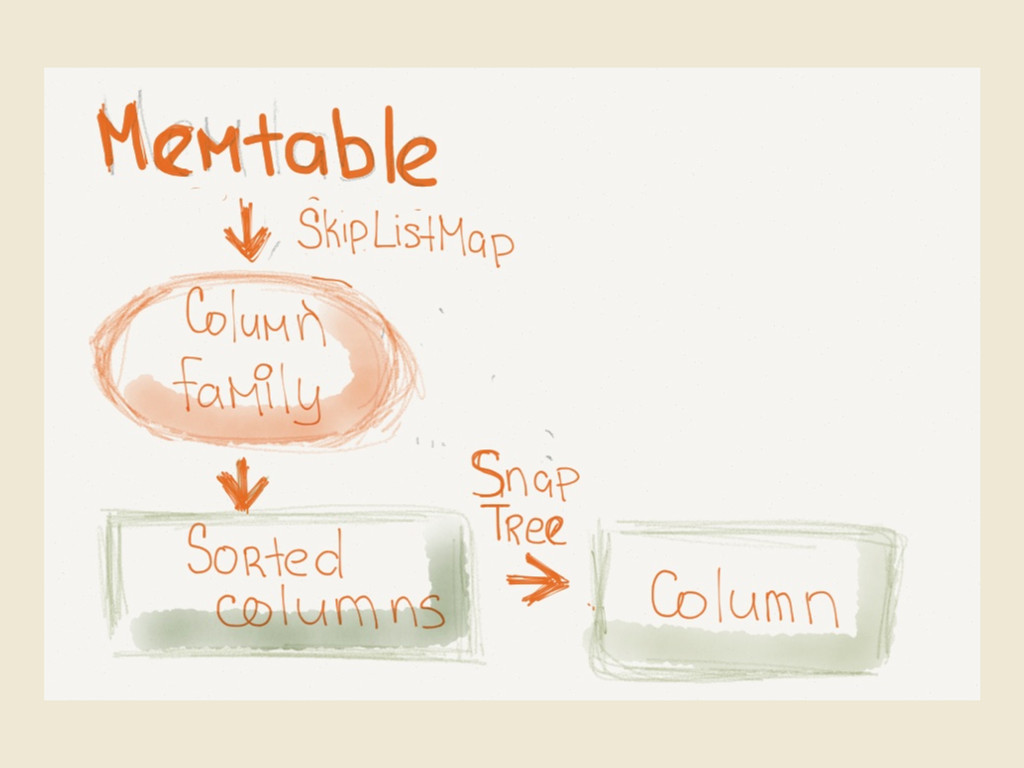{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}