O tempo em que o papel do desenvolvedor se limitava a escrever código e "jogá-lo por cima do muro" para a equipe de operações acabou. Hoje, para construir aplicações resilientes, escaláveis e seguras, o desenvolvedor moderno precisa ter uma visão 360° do ciclo de vida do software.
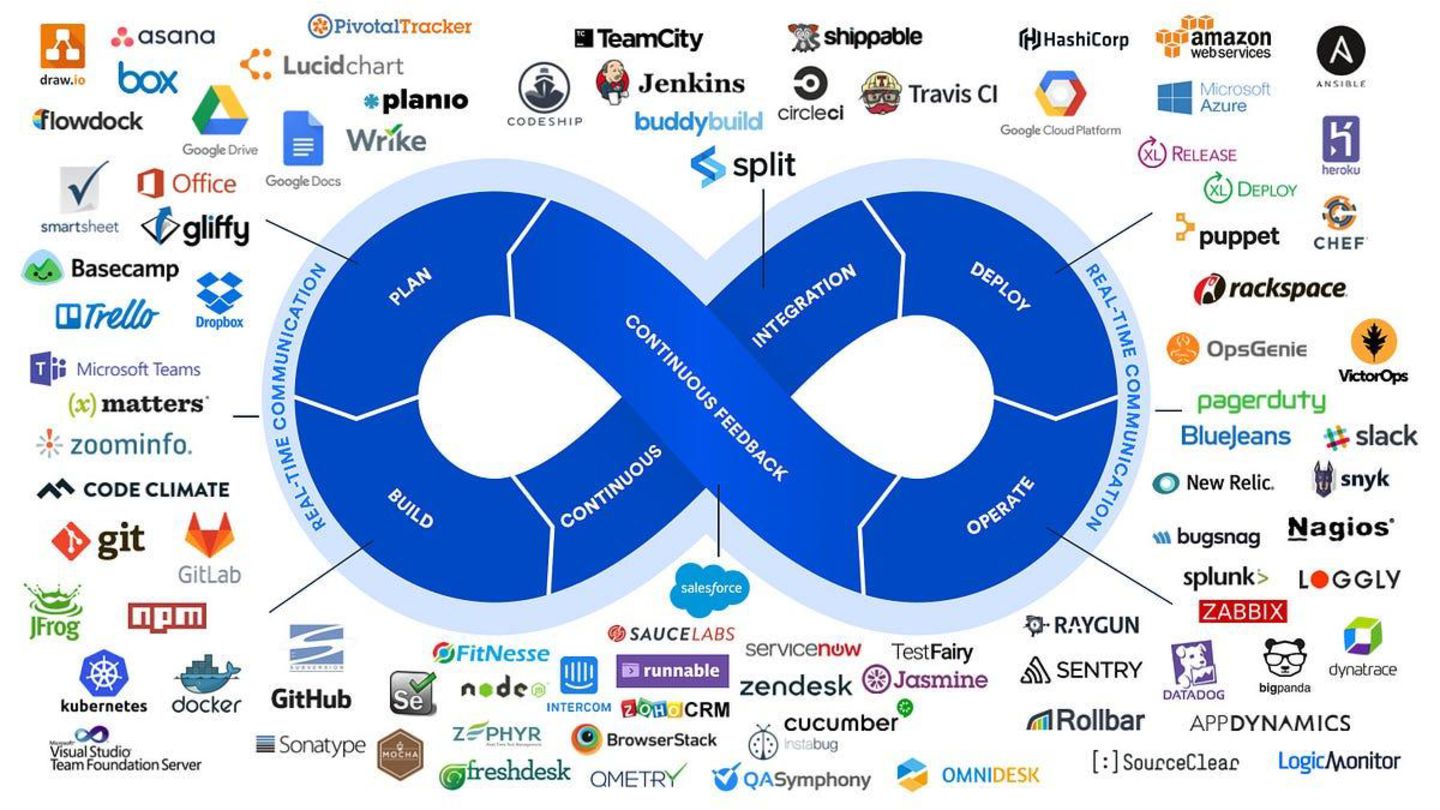
Nesta palestra, vamos viajar no tempo para entender como era o desenvolvimento antes da cultura DevOps e como o surgimento dessa filosofia (junto ao SRE) revolucionou a indústria. Vamos mergulhar nos pilares da Integração e Entrega Contínua (CI/CD), explorar as ferramentas do ecossistema e discutir por que a responsabilidade sobre o código não termina no git push.
Você descobrirá que a Observabilidade e a Segurança nascem no momento em que a primeira linha de código é escrita, e que conhecer o ambiente onde sua aplicação respira é o diferencial para se tornar um profissional de alta performance. Prepare-se para entender que DevOps não é apenas uma sopa de letrinhas, mas a chave para sua autonomia técnica.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}