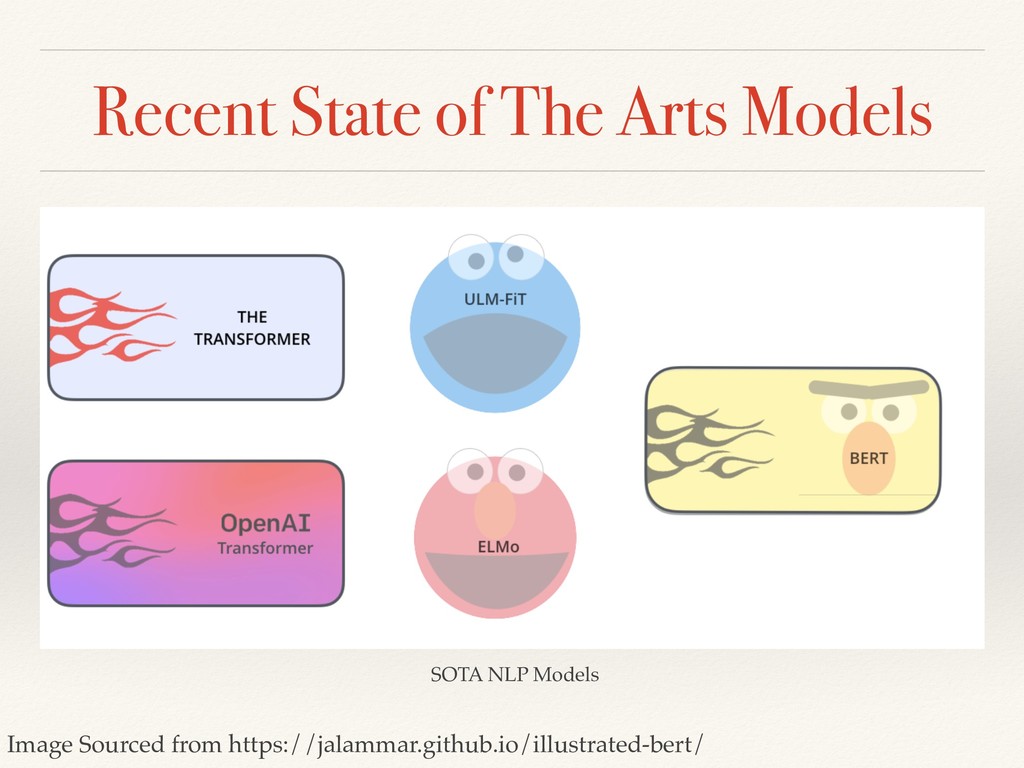
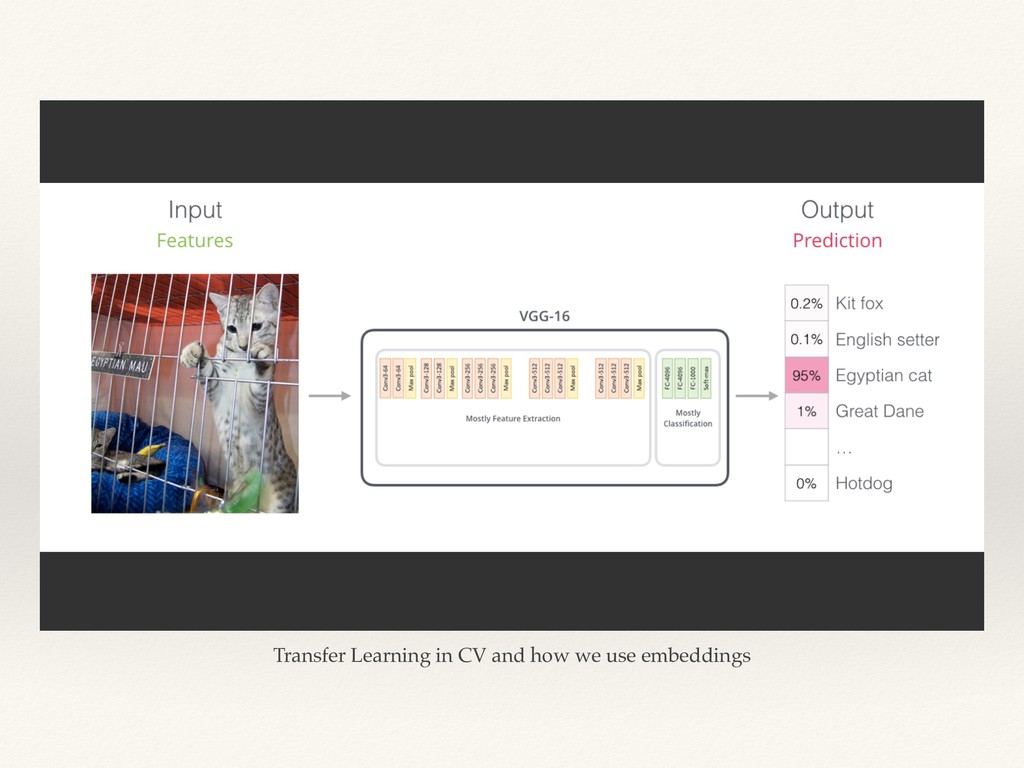
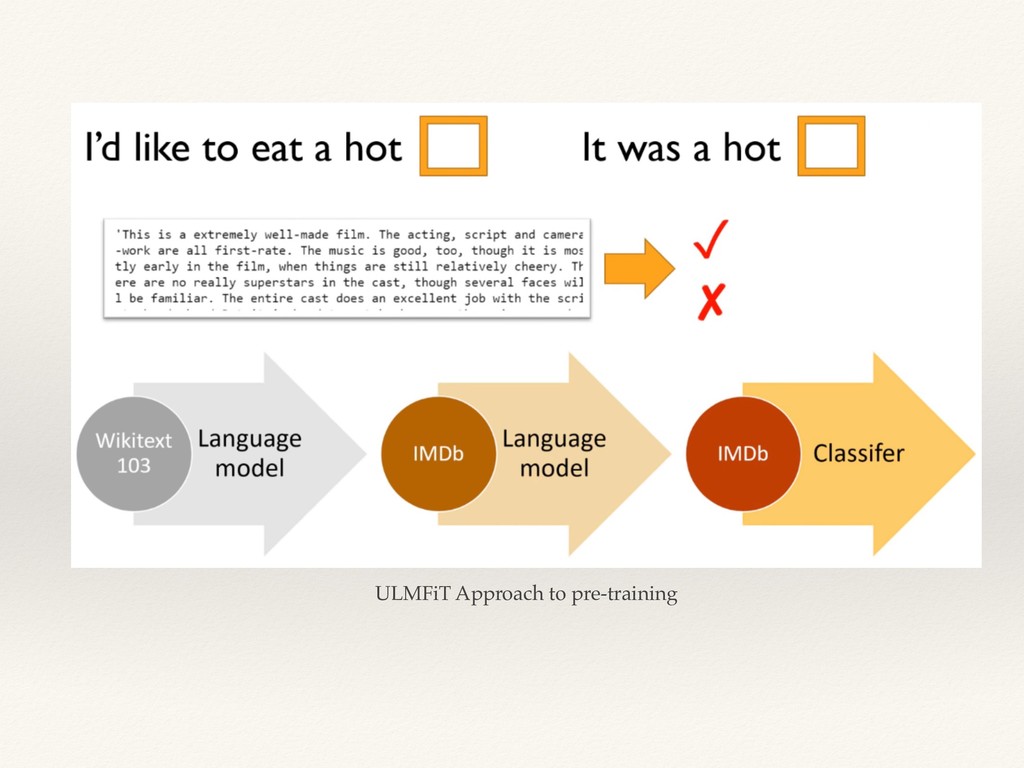
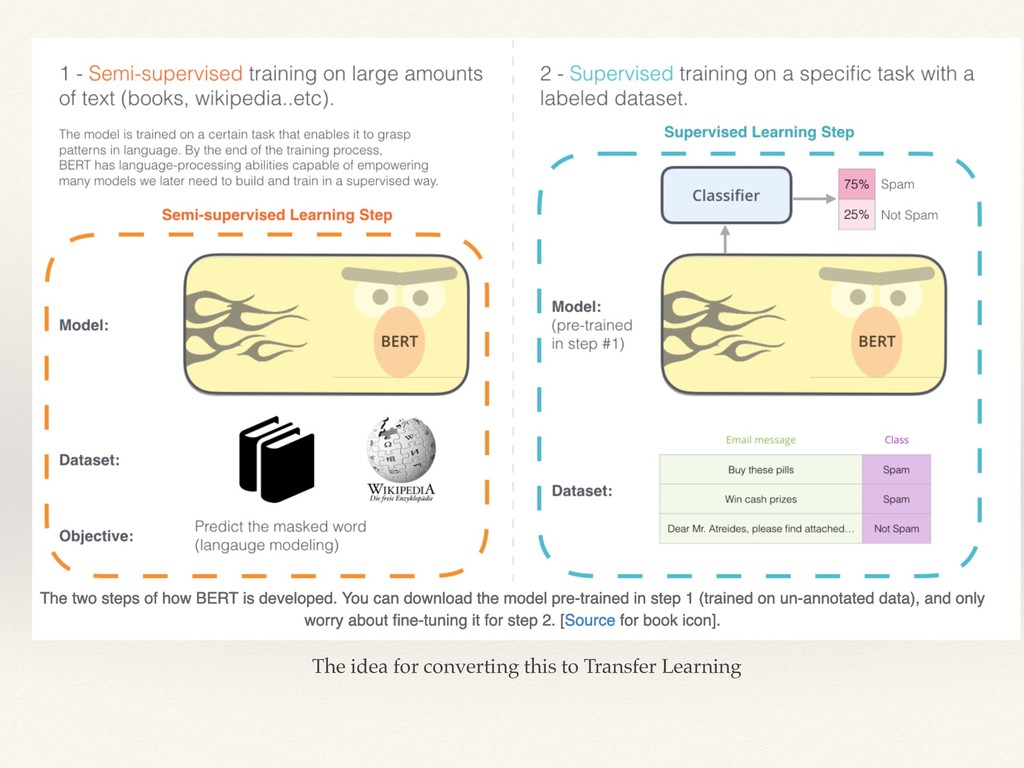
This is a MeetUp talk on the topic of Transfer Learning in NLP and how the recent State of the Arts models were able to extend the idea of transfer learning from Computer Vision datasets to NLP.
I explained the issues related to the previous approach in NLP and how the recent models solved the issue of context, and their embeddings improved the results.
YouTube link for the talk https://www.youtube.com/watch?v=2xkySbHfp_I&t=50s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
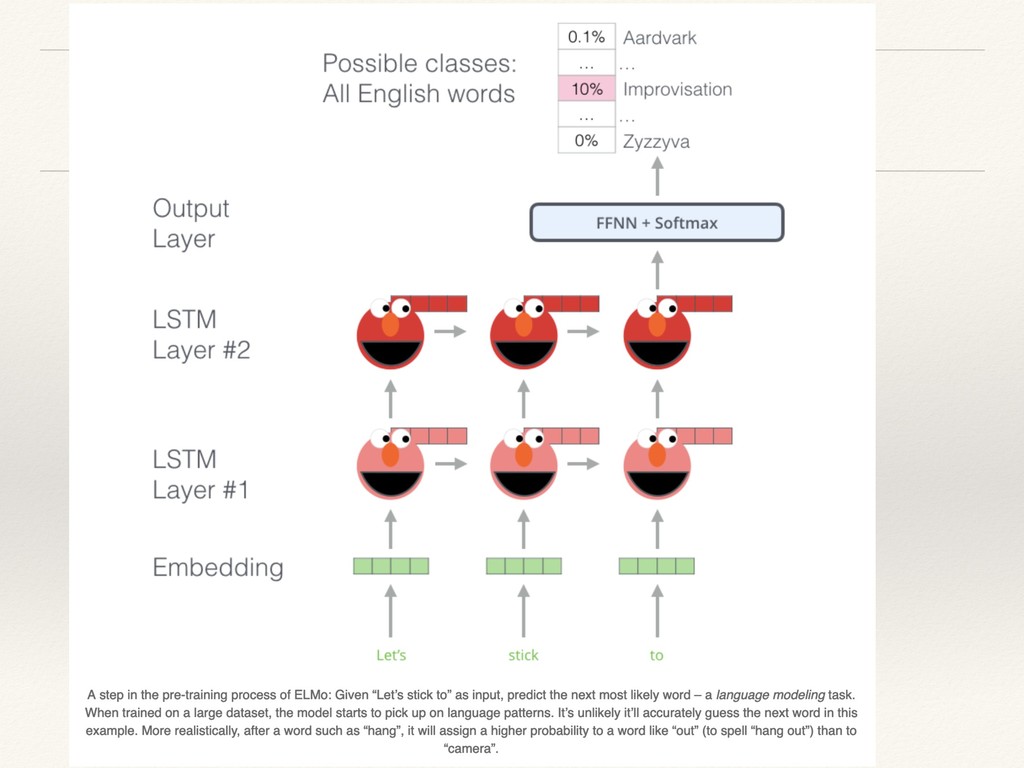{kind=link}
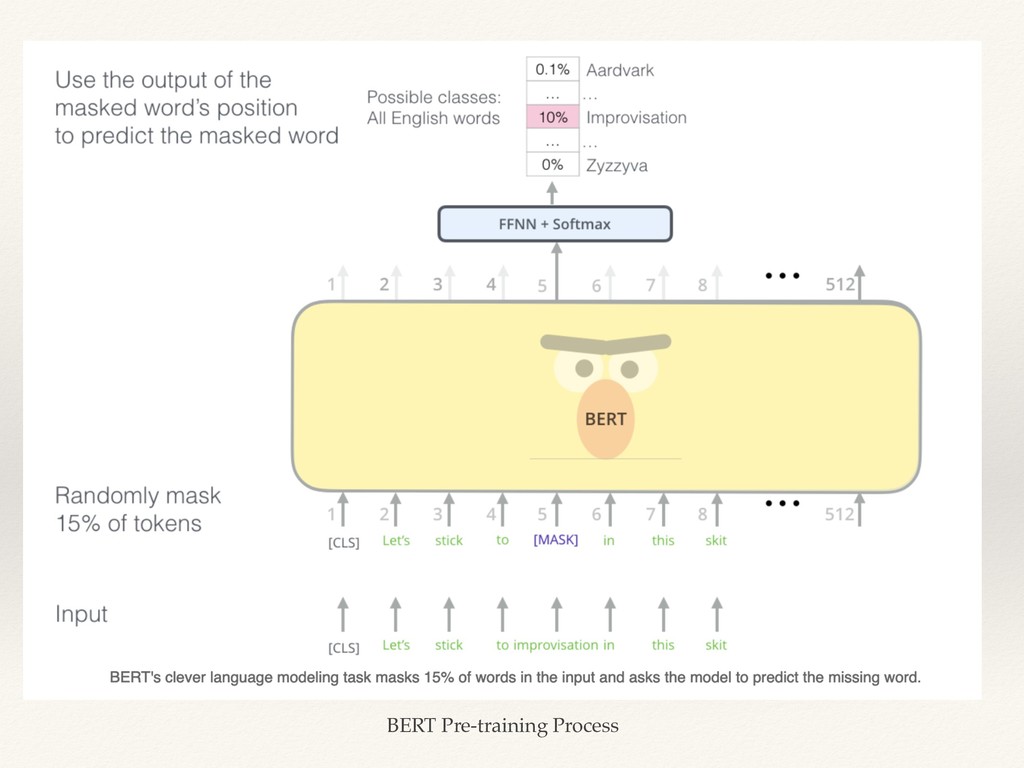{kind=link}
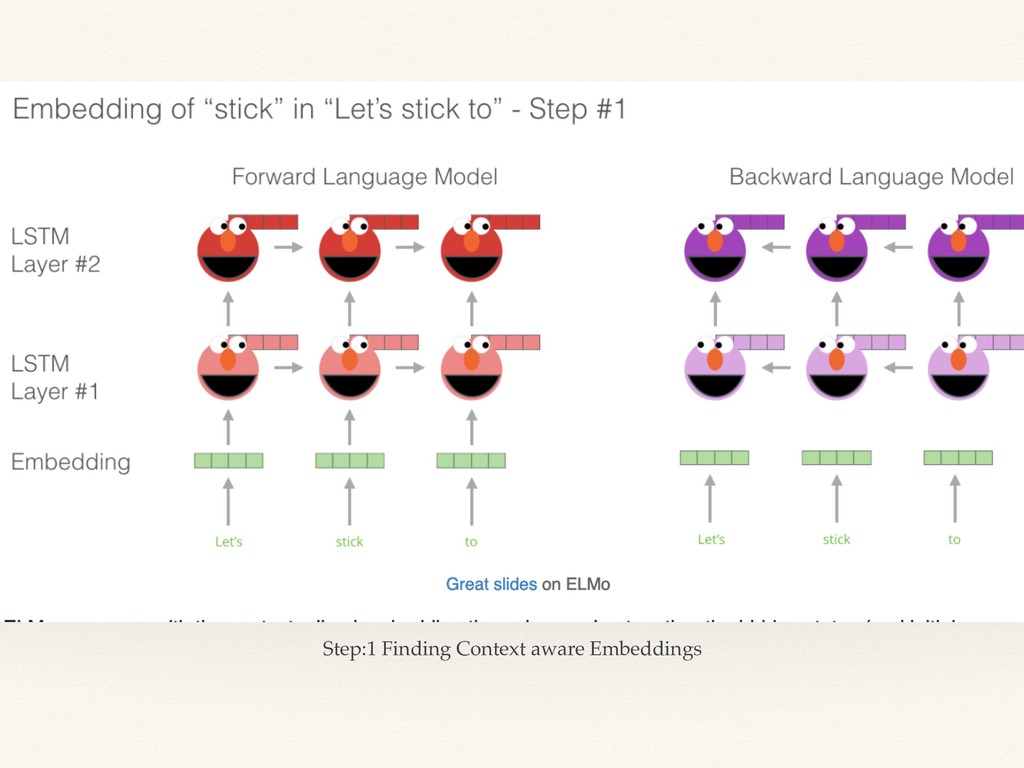{kind=link}
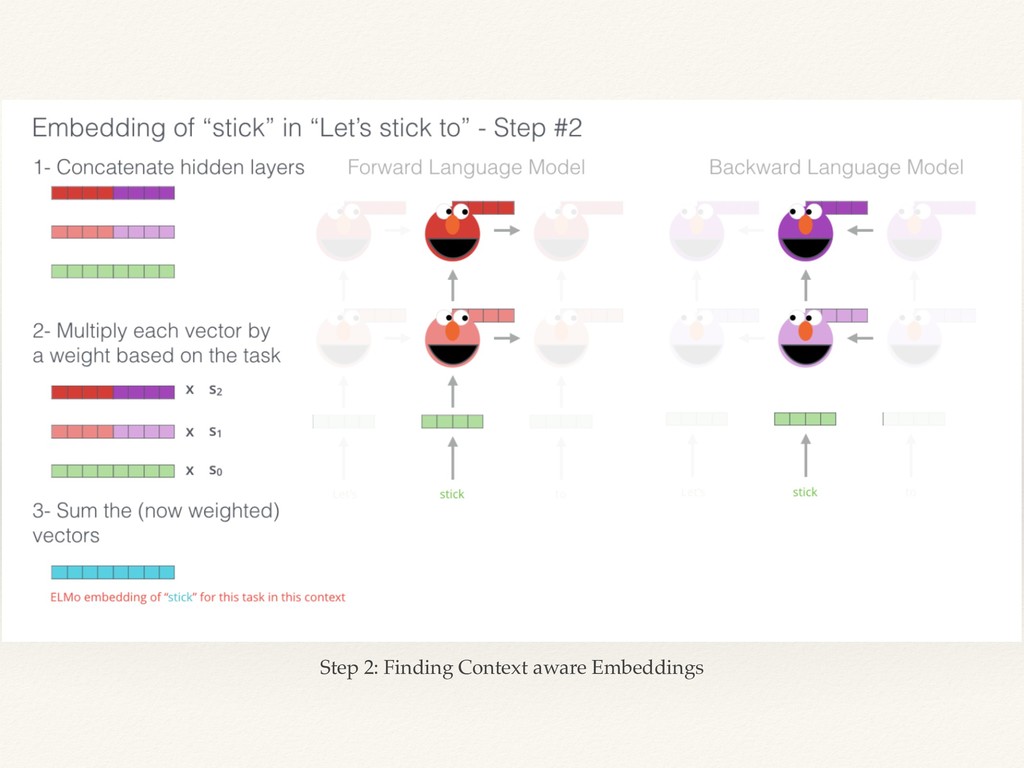{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}