These are the slides to the talk "Apache Pinot Case Study - Building distributed analytics systems using Apache Kafka", from Kafka Summit 2020
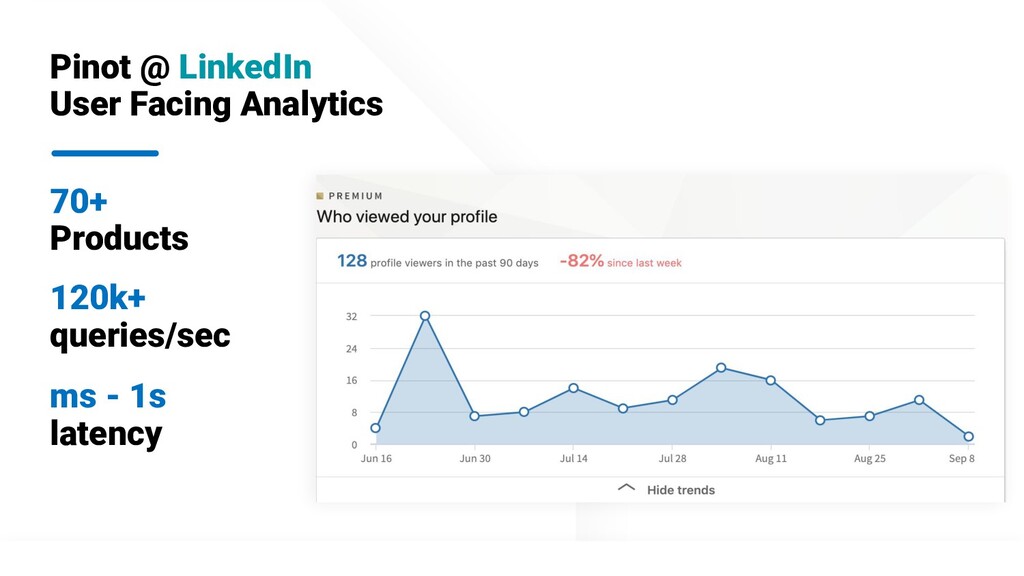
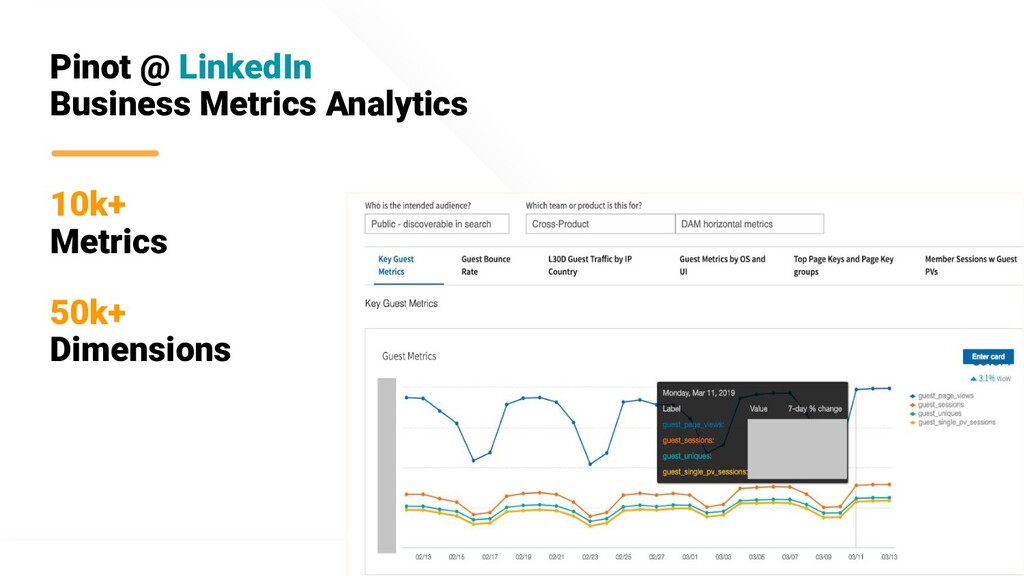
We built Apache Pinot - a real-time distributed OLAP datastore - for low-latency analytics at scale. This is heavily used at companies such as LinkedIn, Uber, Slack, where Kafka serves as the backbone for capturing vast amounts of data. Pinot ingests millions of events per sec from Kafka, builds indexes in real-time and serves 100K+ queries per second while ensuring latency SLA of millisecond to sub second.
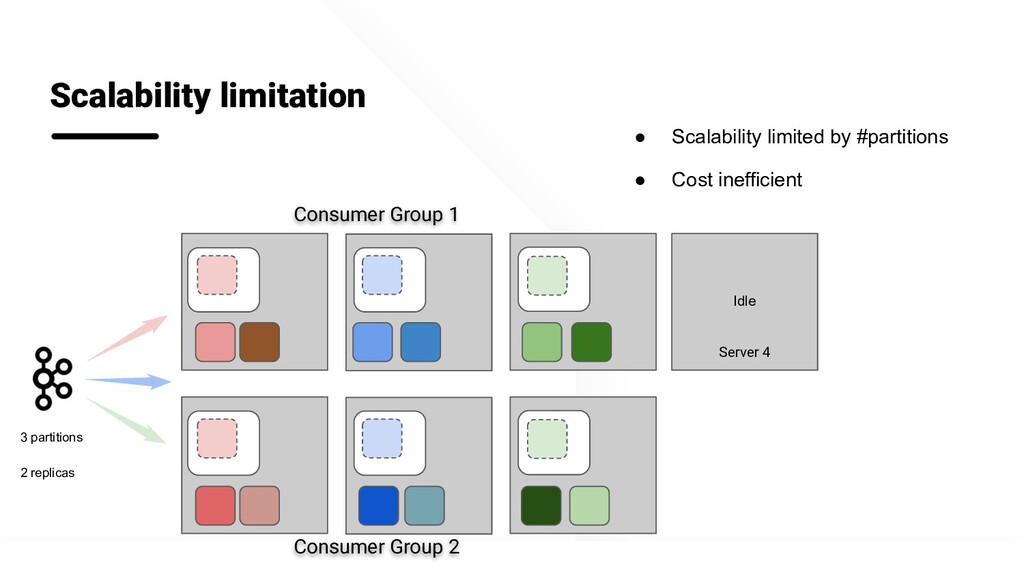
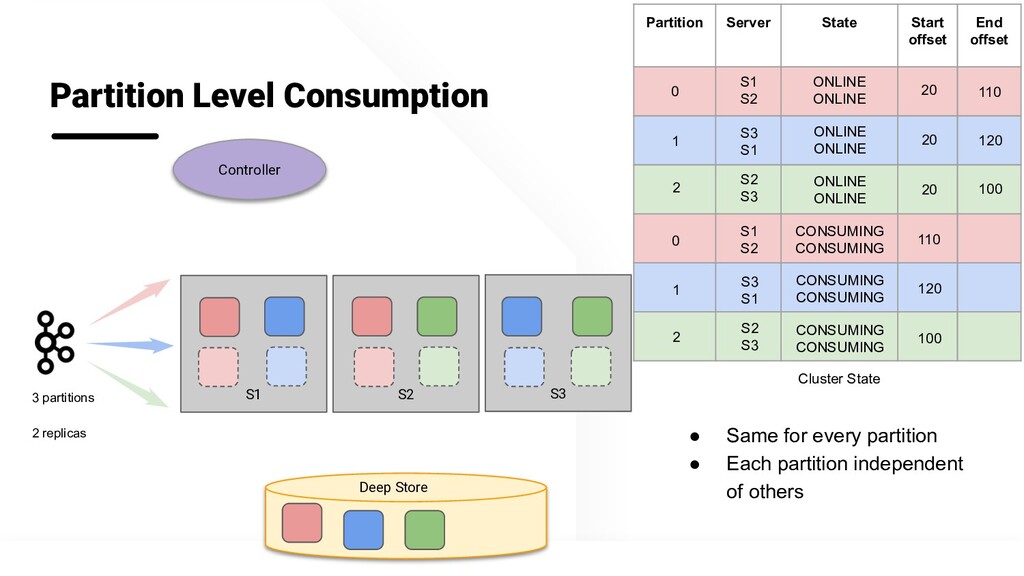
In the first implementation, we used the Kafka Consumer Groups feature to manage the offsets and checkpoints across multiple Kafka Consumers. However, to achieve fault tolerance and scalability, we had to run multiple consumer groups for the same topic. This was our initial strategy to maintain the SLA at high query workload. But this model posed other challenges - since Kafka maintains offset per consumer group, achieving data consistency across multiple consumer groups was not possible. Also, a failure of a single node in a consumer group meant the entire consumer group was unavailable for query processing. Restarting the failed node needed lot of manual operations to ensure data is consumed exactly once. This resulted in management overhead and inefficient hardware utilization.
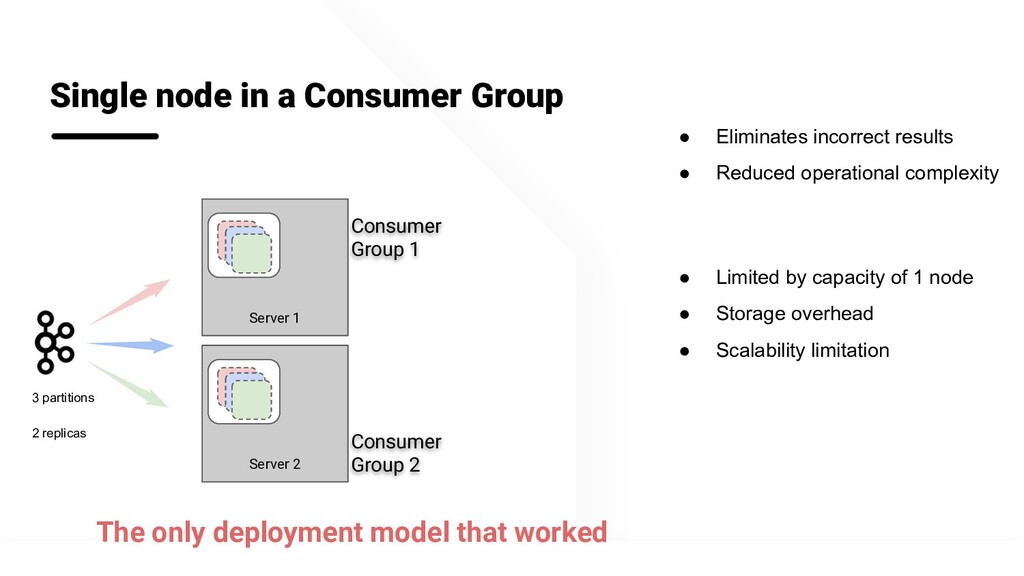
While taking inspiration from the Kafka consumer group implementation, we redesigned the real-time consumption in Pinot to maintain consistent offset across multiple consumer groups. This allowed us to guarantee consistent data across all replicas. This enabled us to copy data from another consumer group during node addition, node failure or increasing the replication group.
In this talk, we will deep dive into journey of the Pinot real-time ingestion design. We will talk about the new Partition Level Consumers design, and learn how it is resilient to failures both in Kafka Brokers and Pinot Components. We will discuss how multiple consumer groups can synchronize checkpoints periodically and maintain consistency. We'll describe how we achieve this while maintaining strict freshness SLAs, and also withstanding high throughput and ingestion.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}