Share
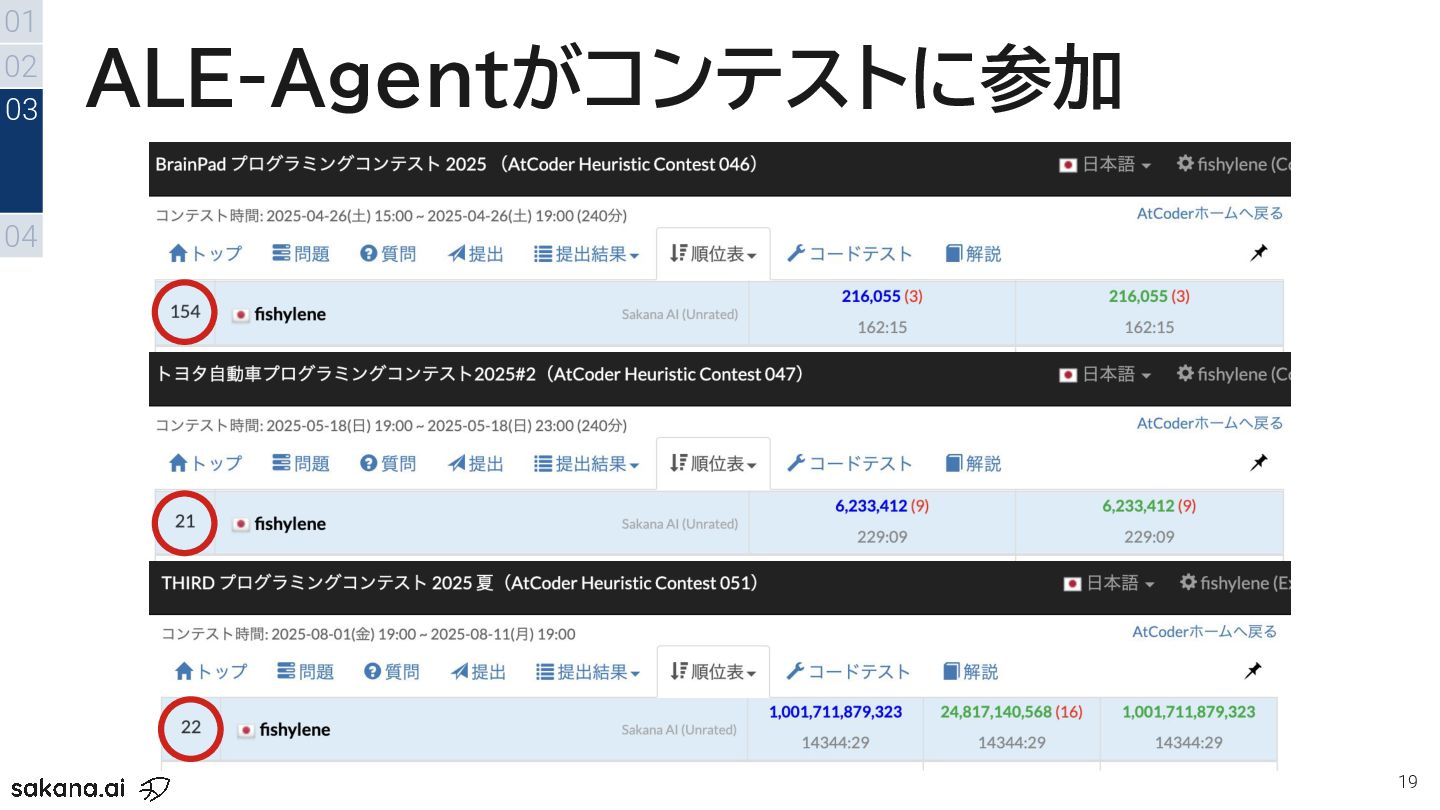
AIの長期的な推論・問題解決能力を測る新しいベンチマーク「ALE-Bench」を紹介します。AtCoder Heuristic Contestを基盤に、実務レベルの組合せ最適化タスクを用いてモデルの性能を比較・評価。最新LLMの結果や、Sakana AIが開発したAIエージェント「ALE-Agent」の取り組みについて解説します。
{kind=link}
{kind=link}
{kind=link}
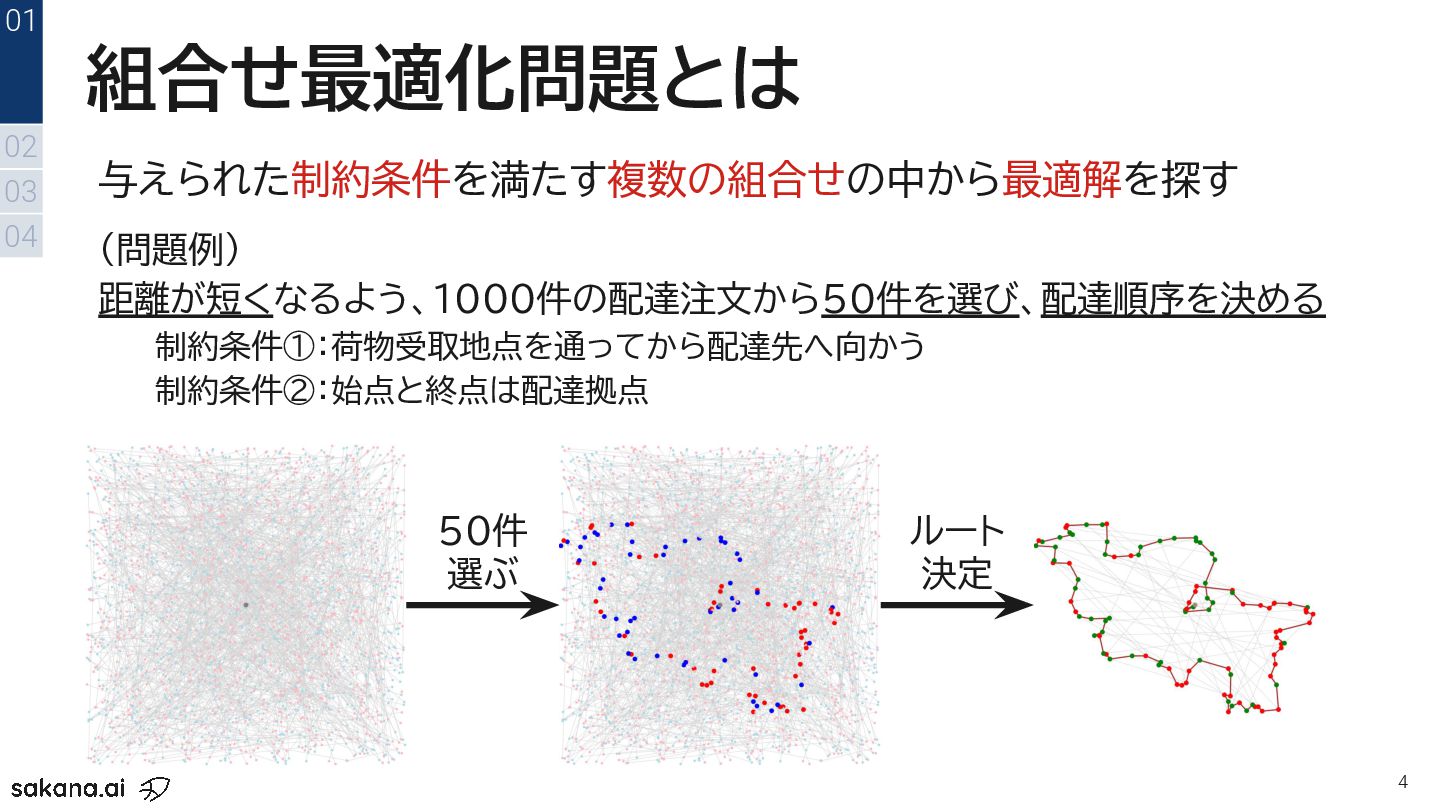{kind=link}
{kind=link}
{kind=link}
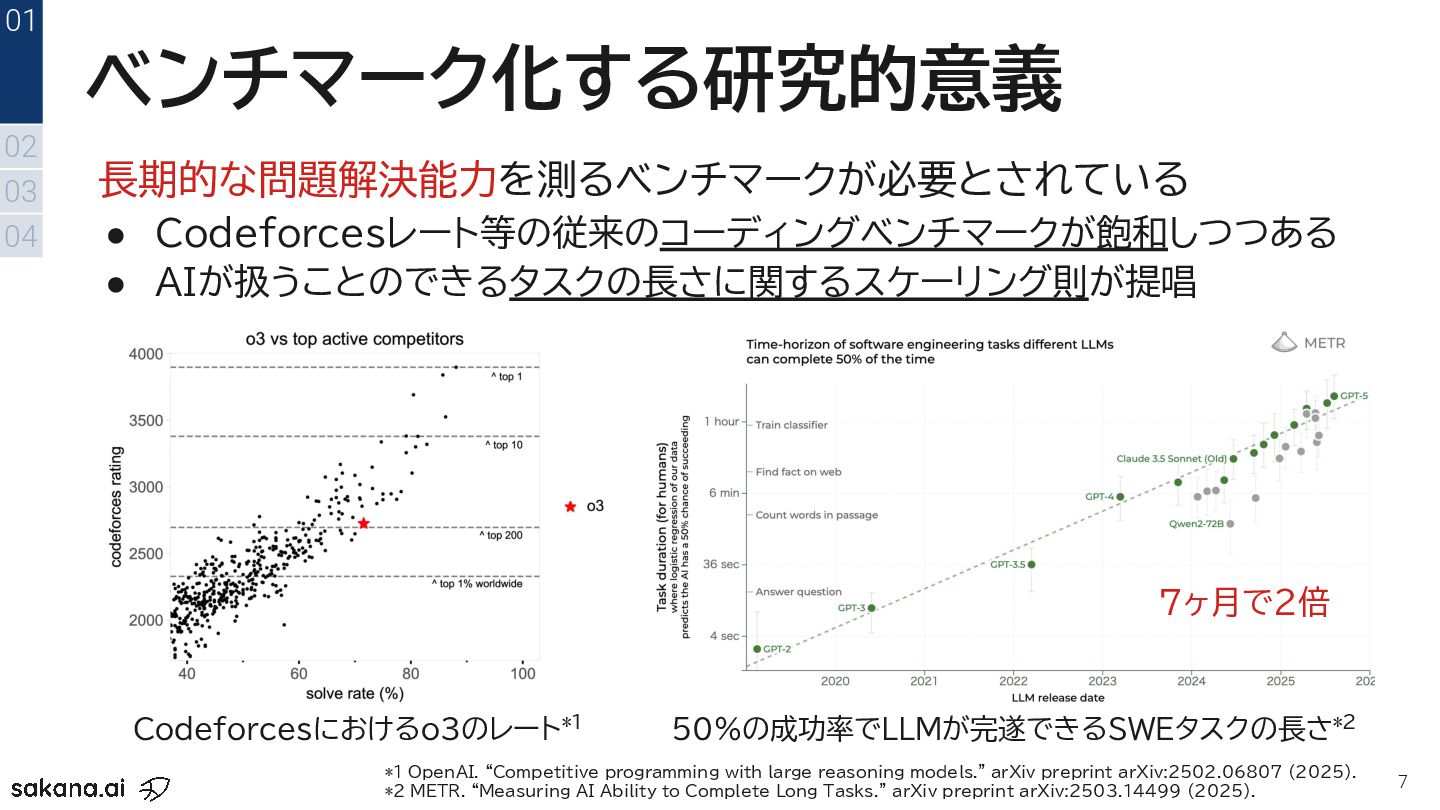{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
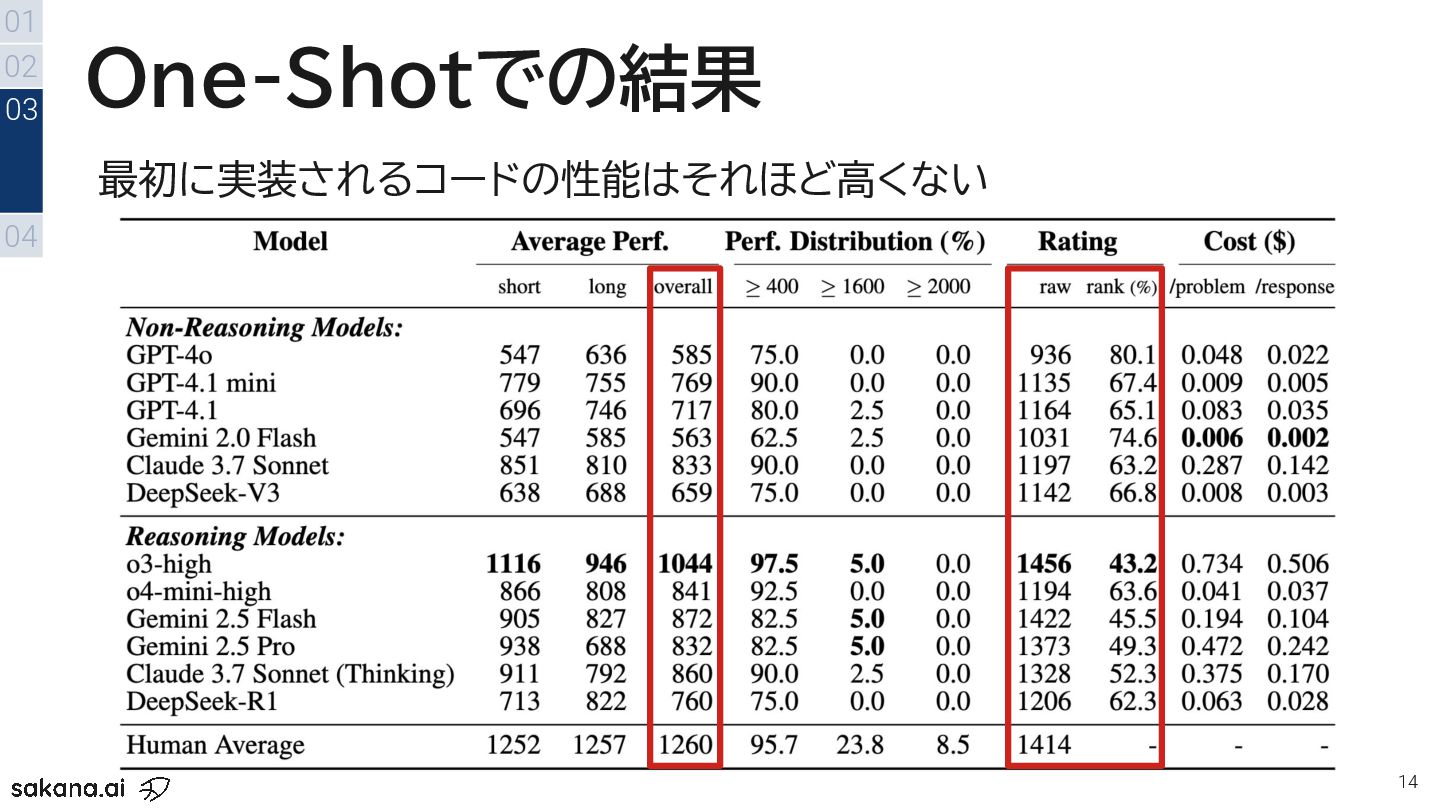{kind=link}
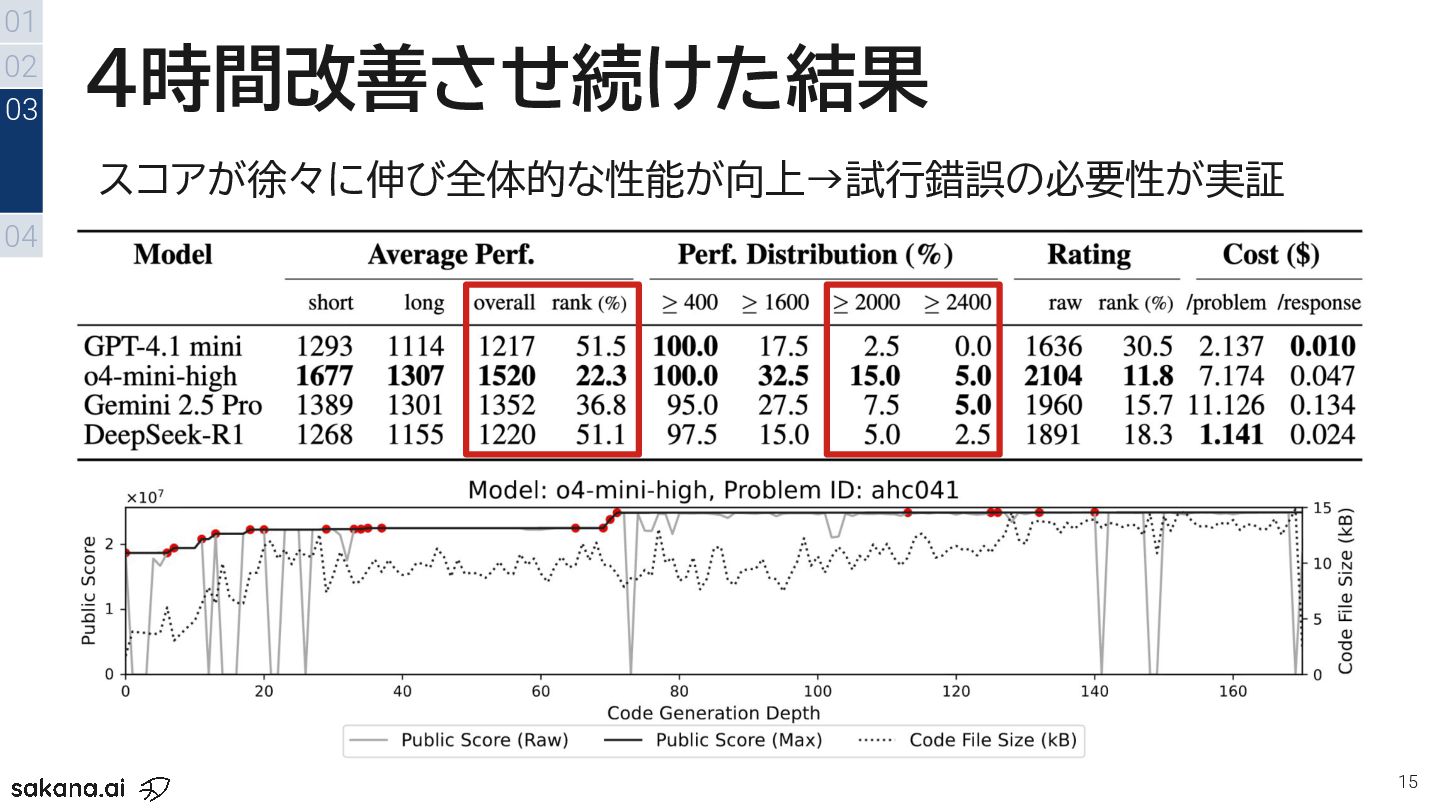{kind=link}
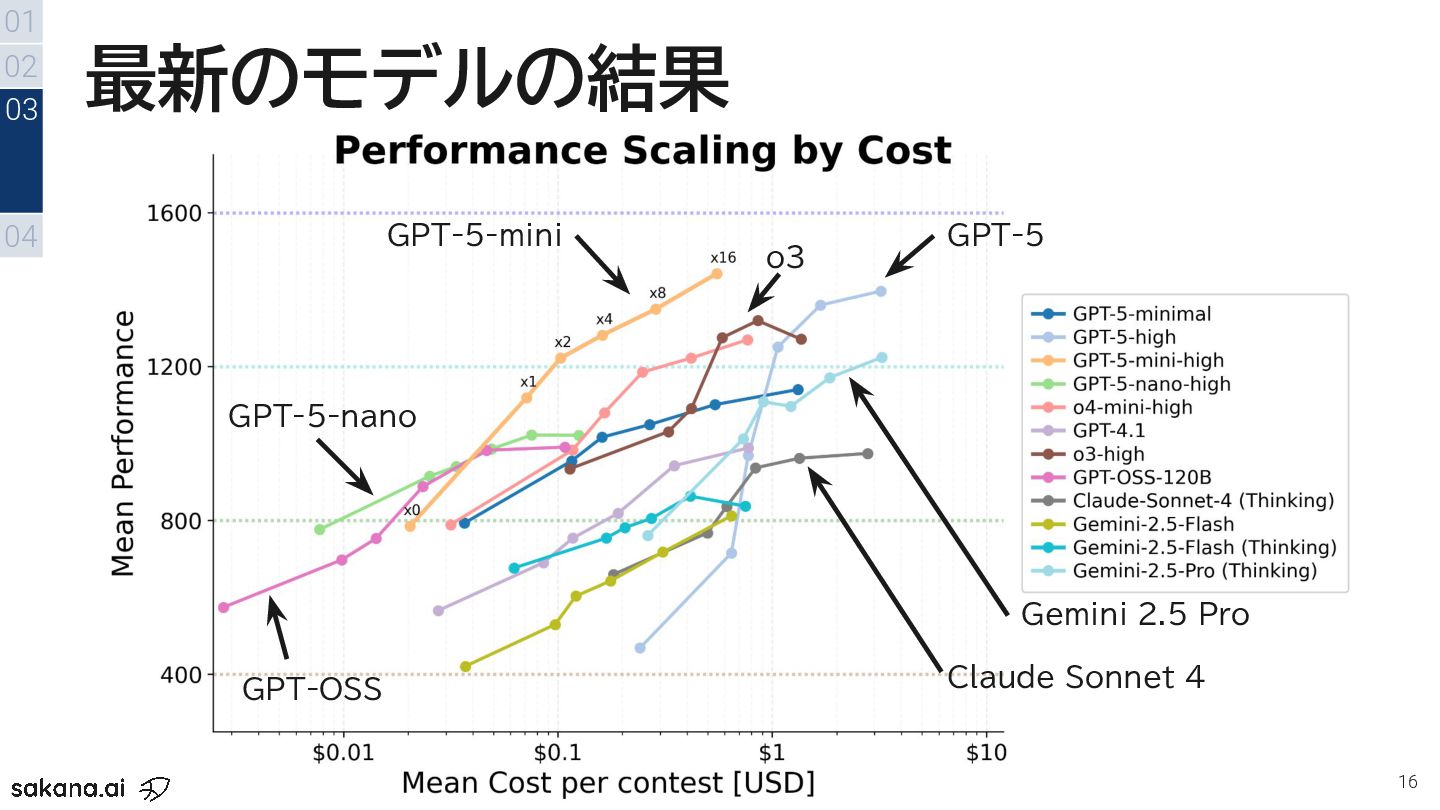{kind=link}
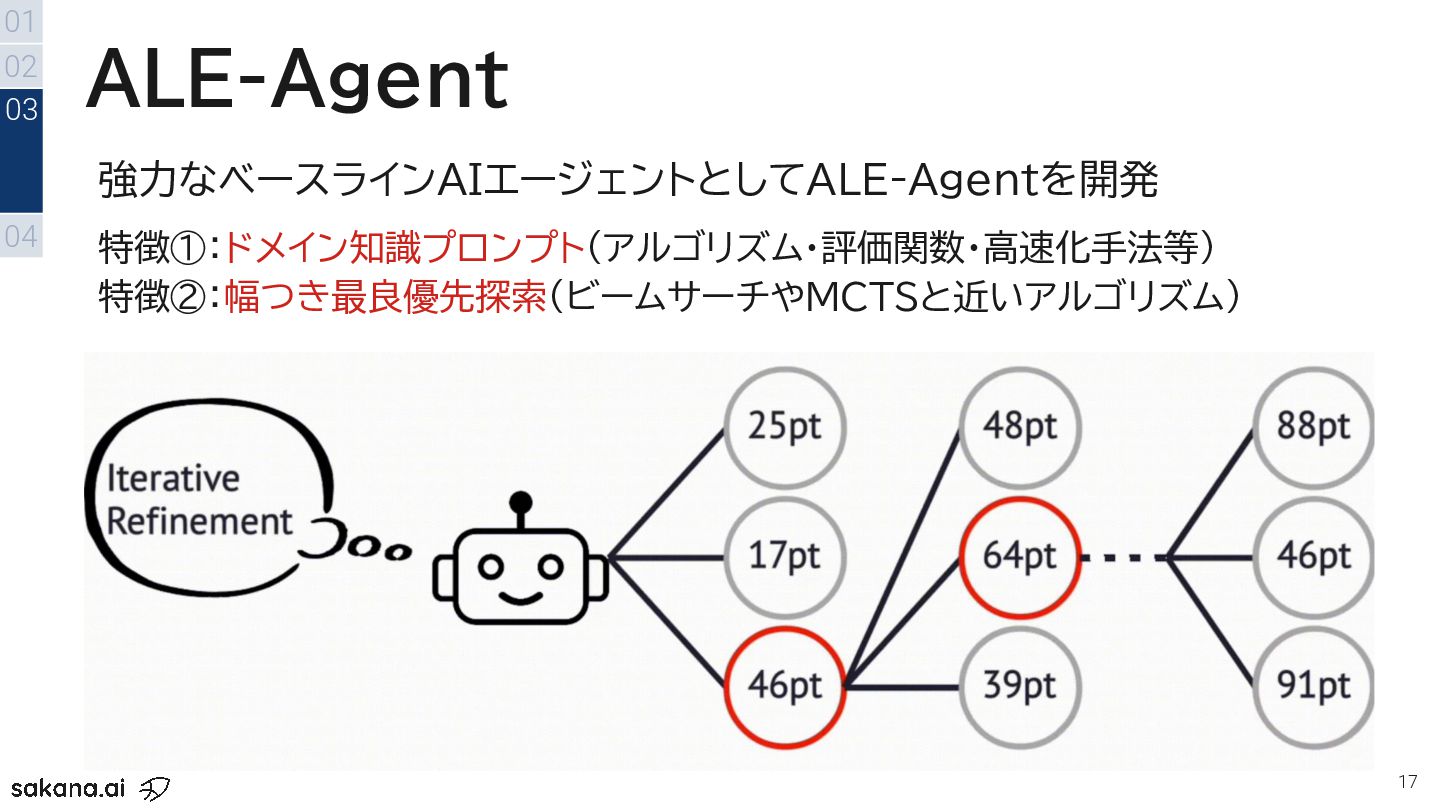{kind=link}
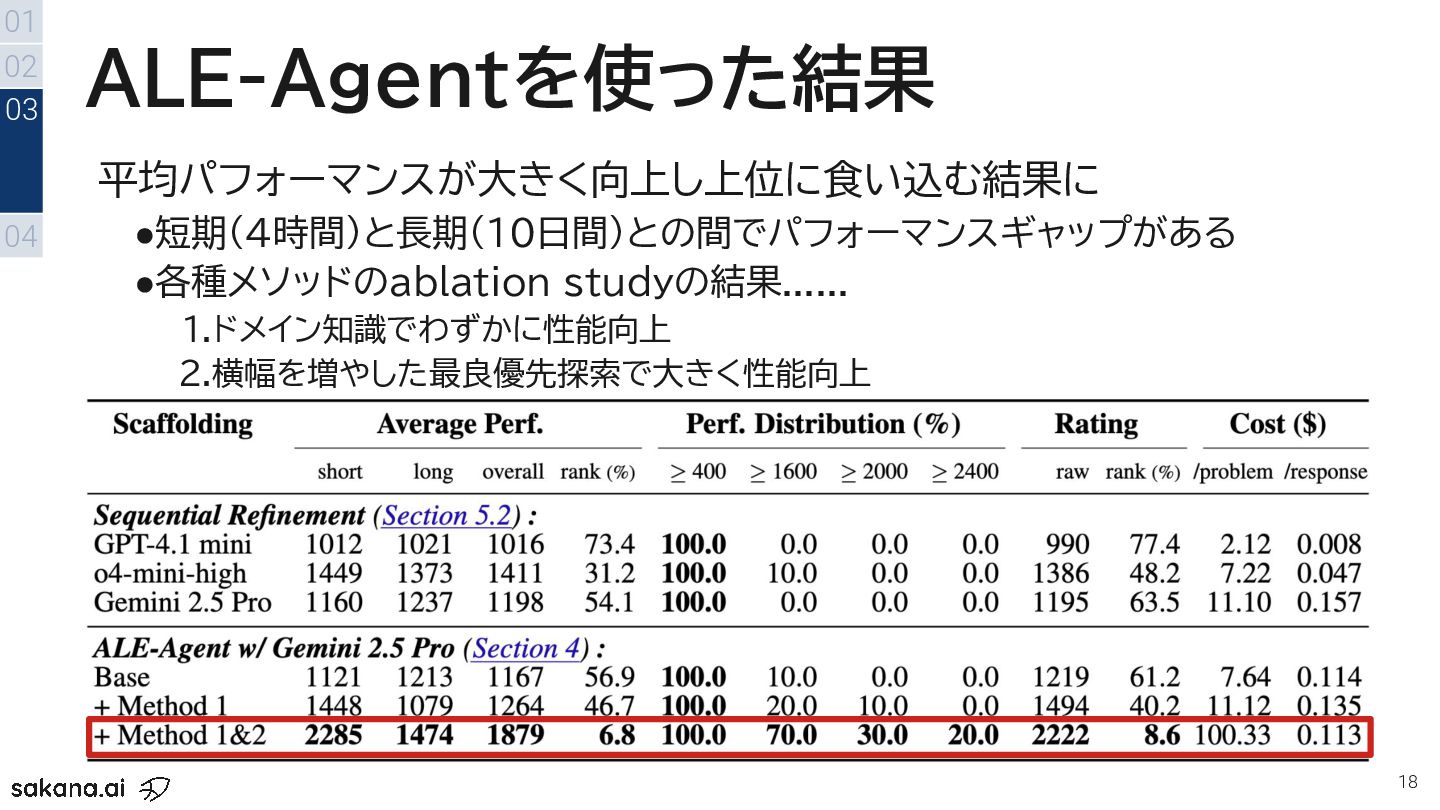{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}