I gave a presentation at Kafka Summit San Francisco 2019 that attempts to convince viewers that it is possible to run a stable Kafka cluster on Kubernetes without a complicated setup.
Bonus: I illustrated the slides by hand, and hid the Kafka logo in many of the pictures!
The talk description is below:
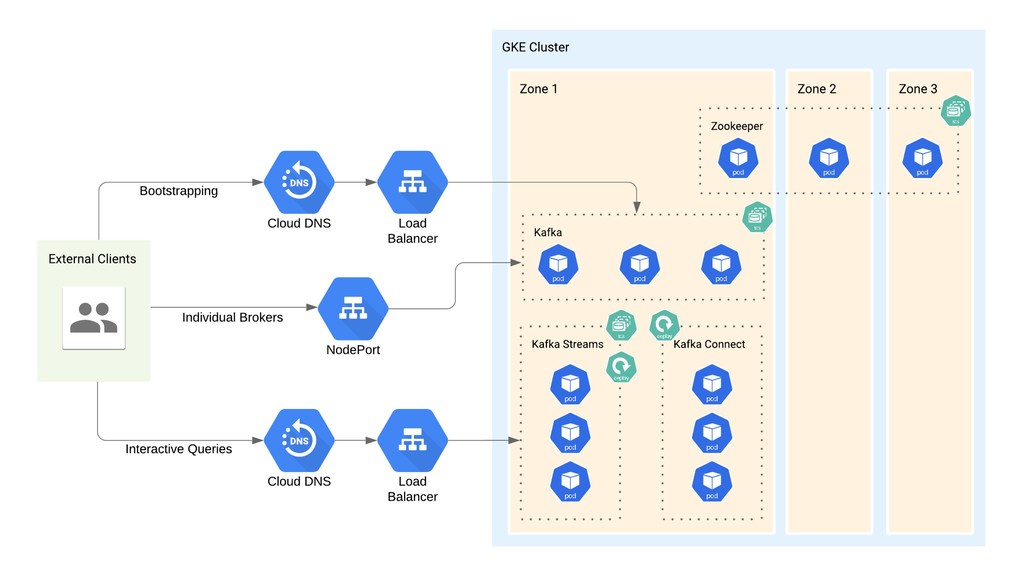
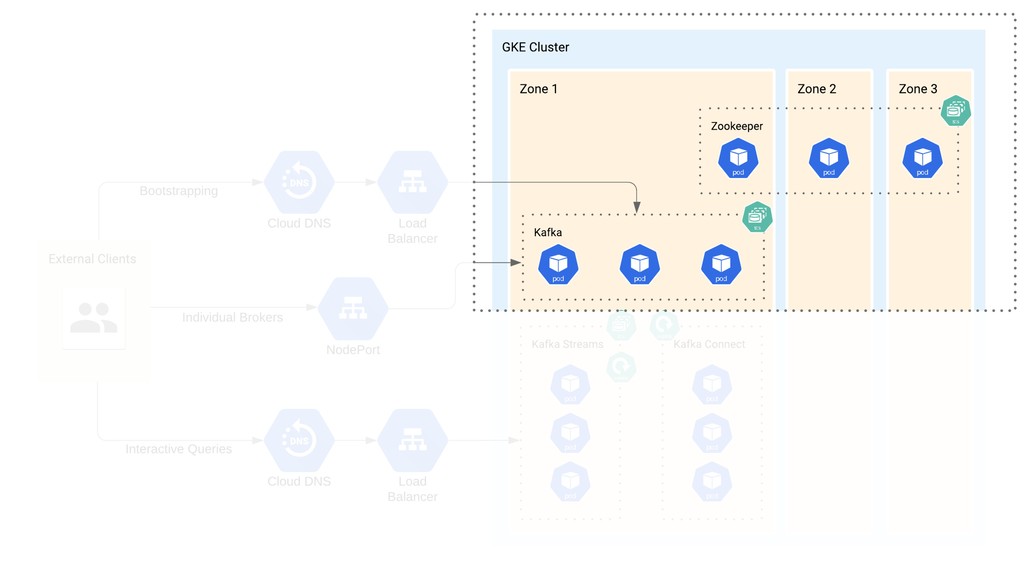
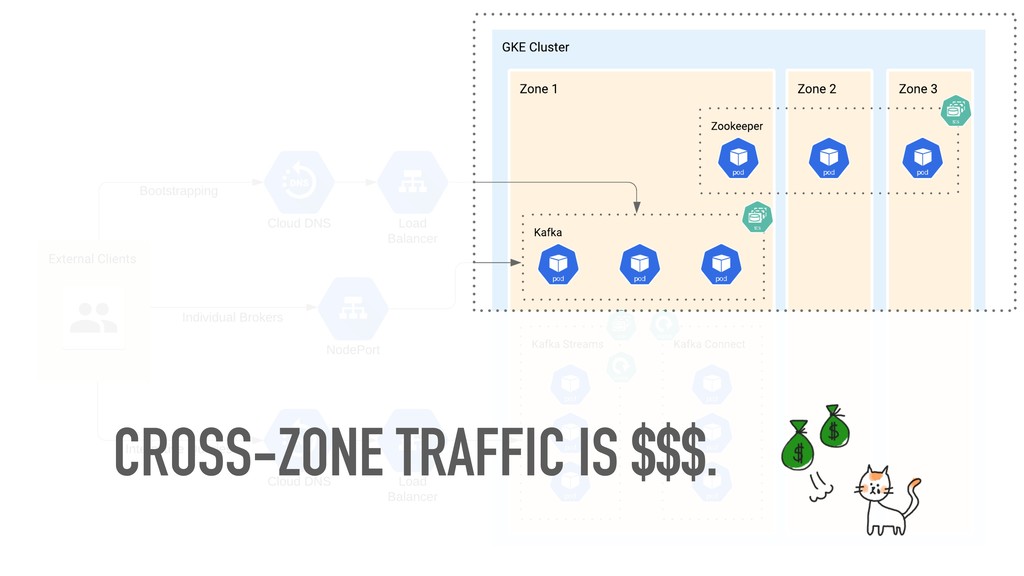
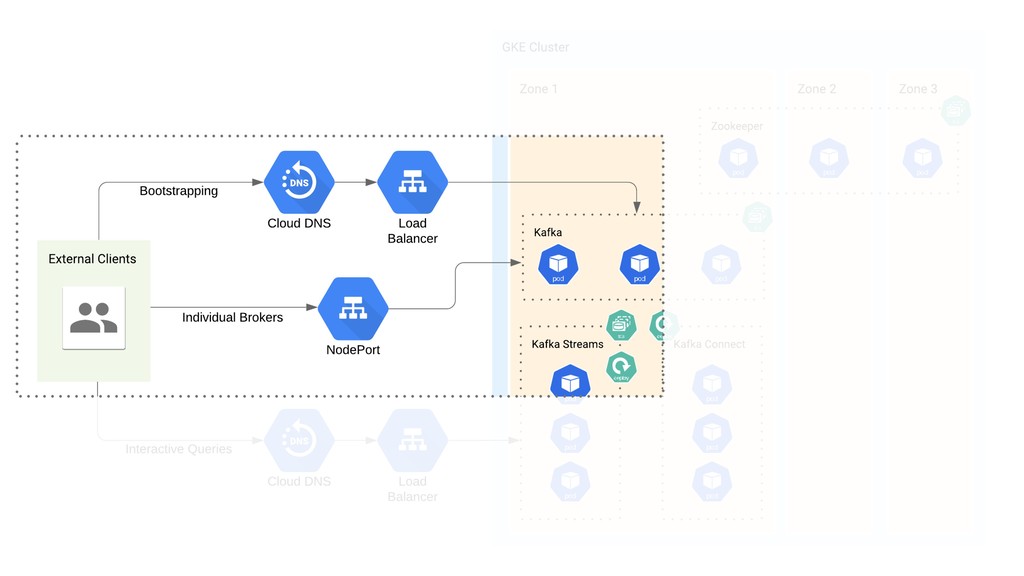
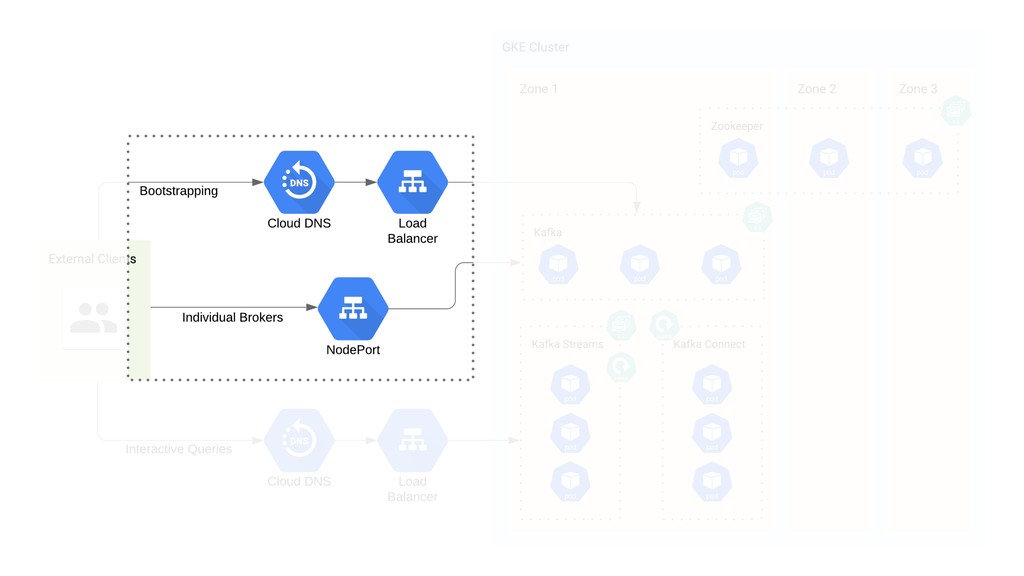
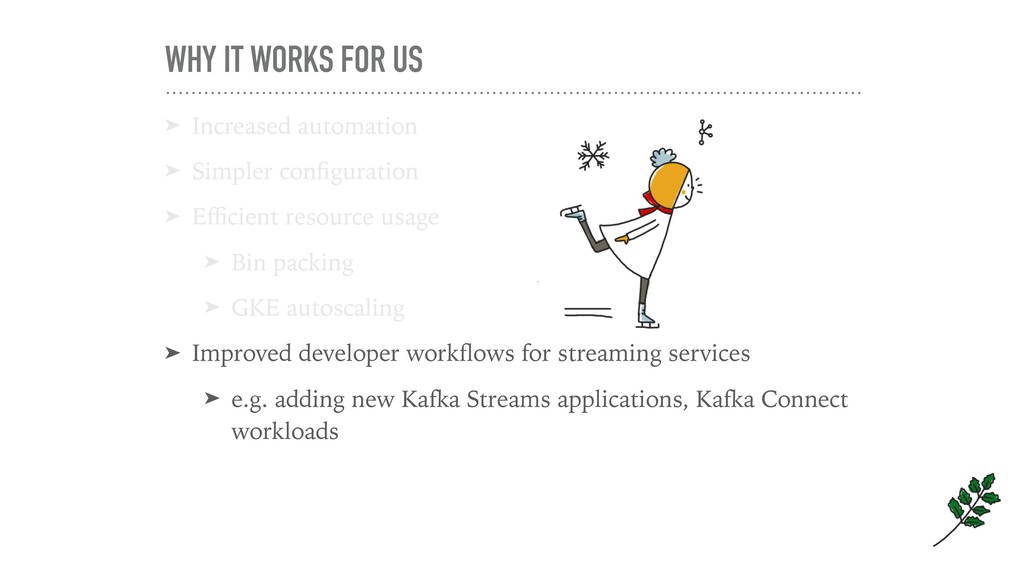
If you’ve ever thought that running Kafka on Kubernetes was a terrible idea, welcome to the club: that’s what we thought as well. When we migrated Etsy’s Kafka deployment from bare metal to GCP, we made a surprising discovery: running Kafka on Kubernetes was the best option for us — and it wasn’t half as complicated as we thought it had to be.
I’ll use the story of our cloud migration journey to frame a discussion of how a “simple” Kafka-on-k8s setup can work. You’ll walk away with an example of how to set up a stable production system that uses vanilla Kubernetes workloads, as well as some technical tips and tricks — and pitfalls to avoid — for your own cloud migration or first Kafka-on-k8s deployment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU! Twitter: @NikkiThean Confluent Slack: @nikki Email: [email protected] Thank](https://files.speakerdeck.com/presentations/b97fbdf0d1d74a908efacab49eb0c354/slide_116.jpg){kind=link}