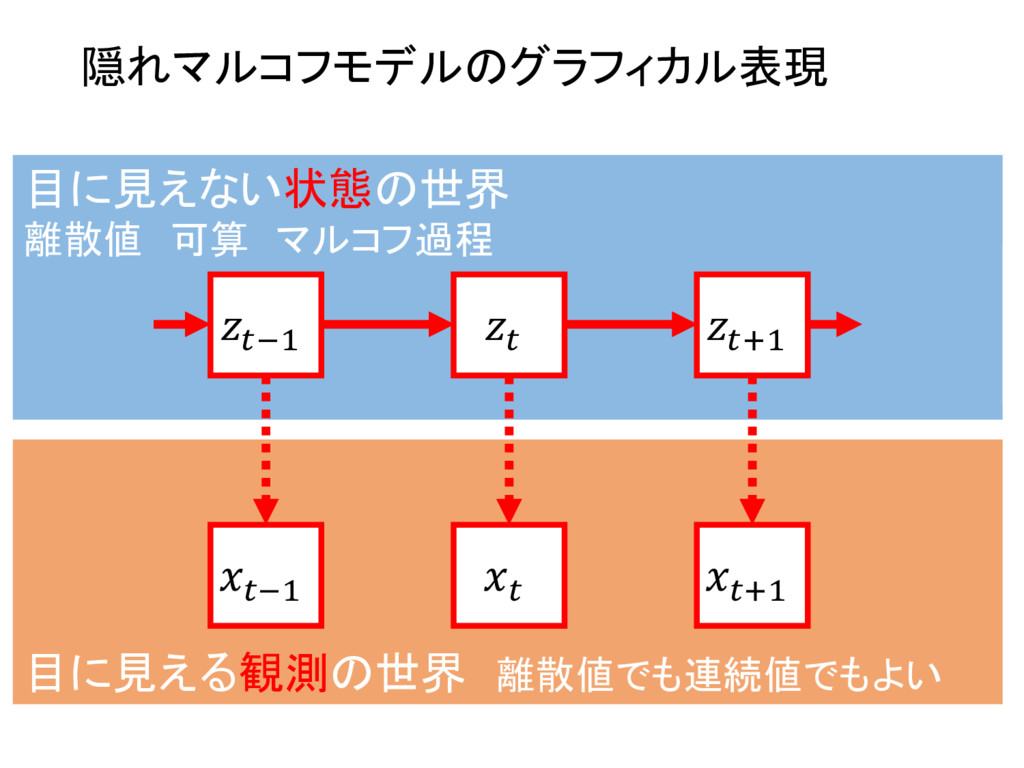
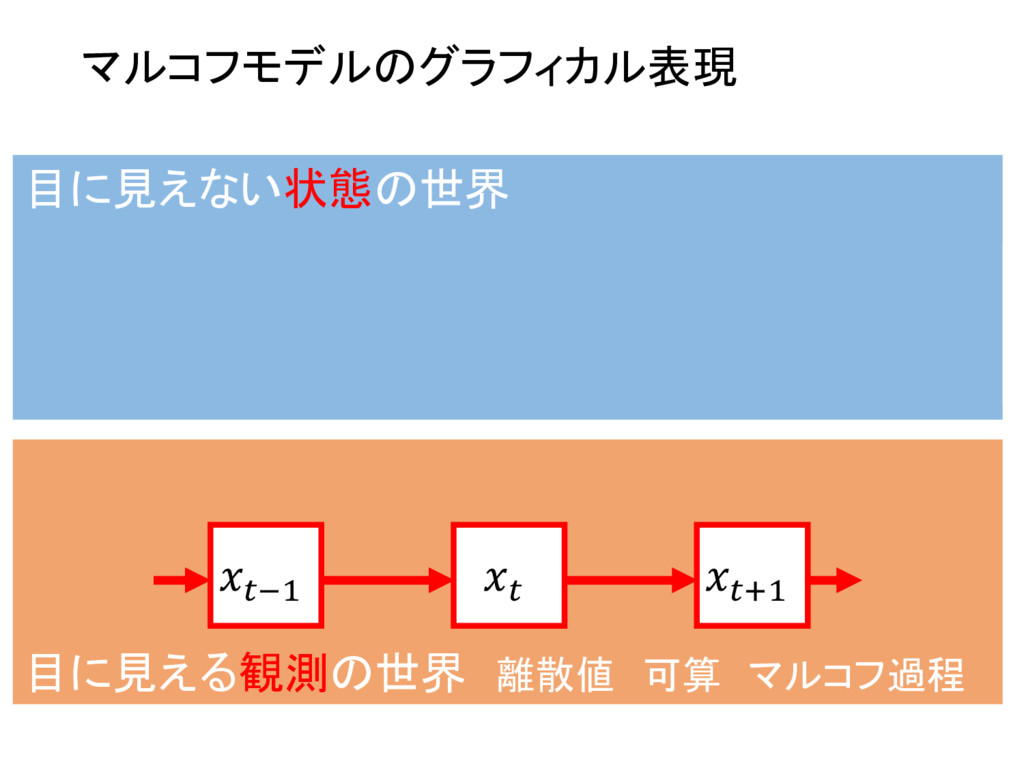
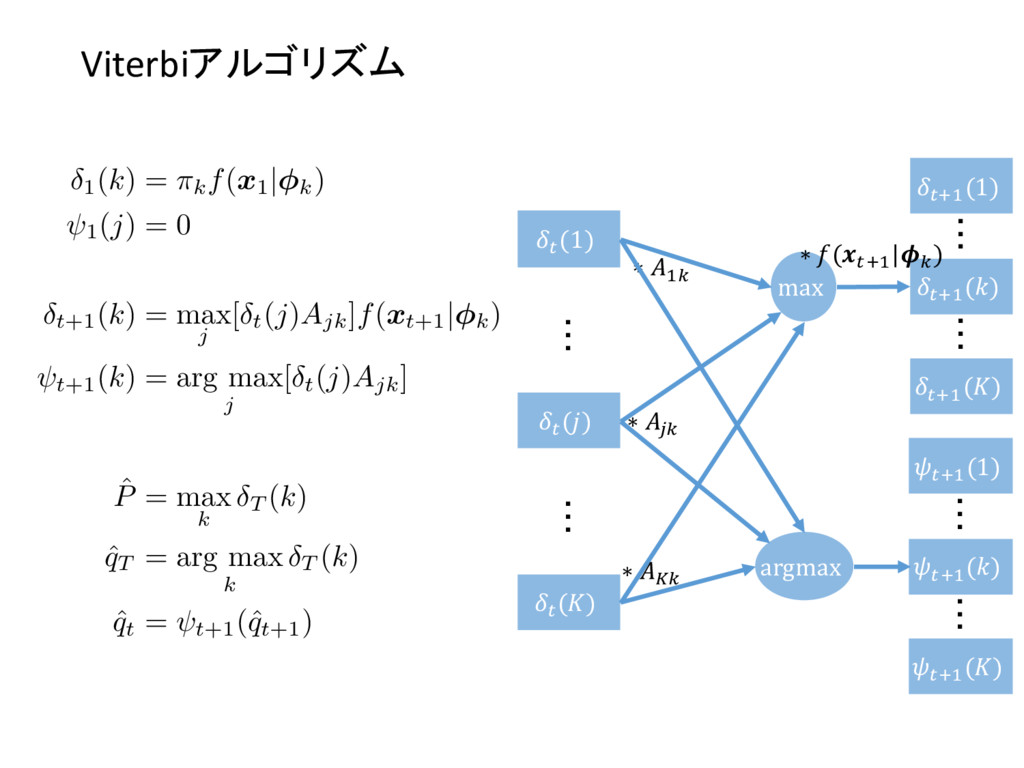
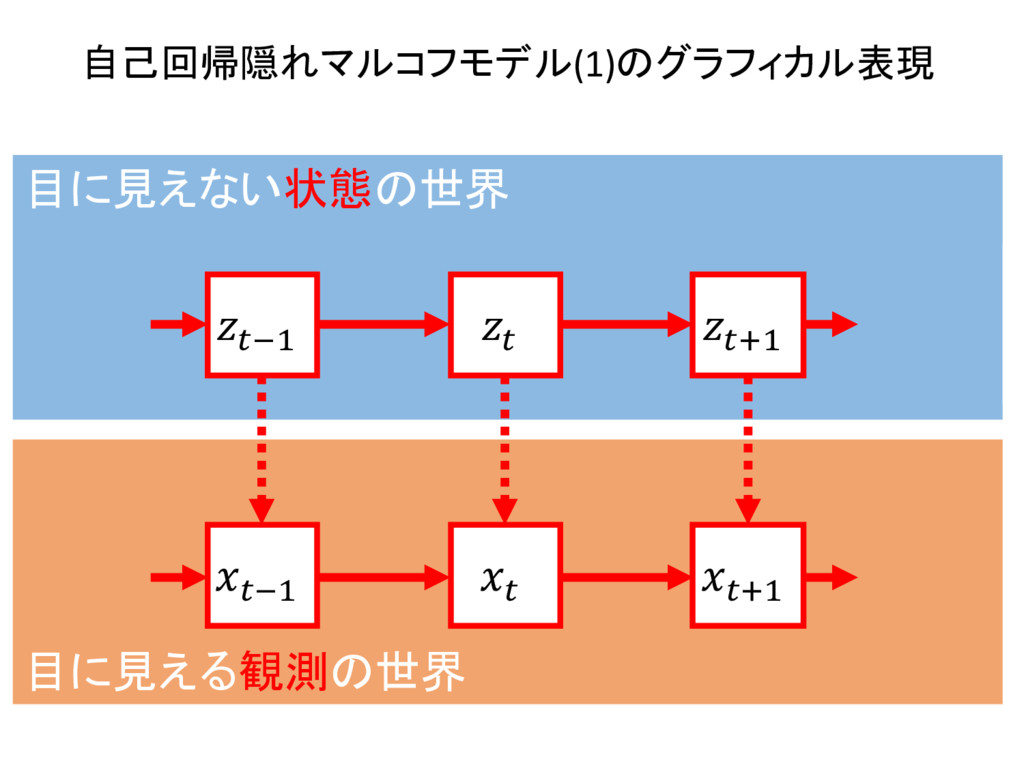
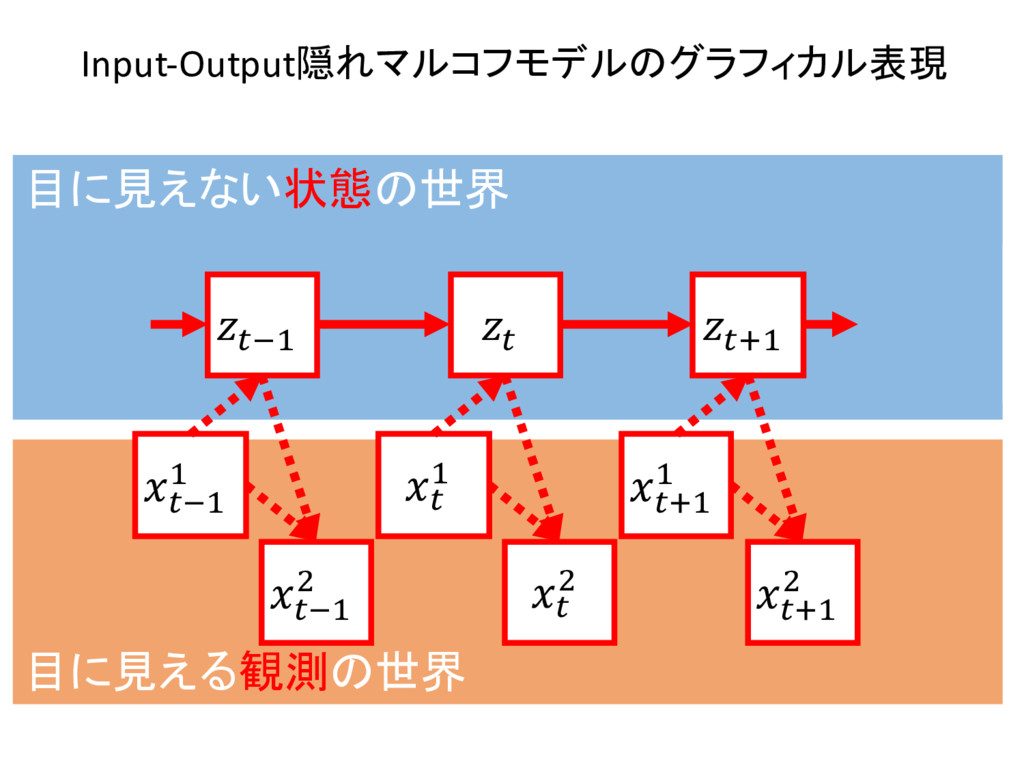
2 {1, ..., K} ⇢ N , n 2 {1, ..., N} ⇢ N 8k , 8n , znk 2 {0, 1} where K X k=1 znk = 1 and zn = {zn1, zn2, ..., znK } 8k , ⇡k = p(z1k = 1) where 0 ⇡k 1 ^ K X k=1 ⇡k = 1 and ⇡ = {⇡1, ⇡2, ..., ⇡K } 8k , 8j , 8n , Ajk = p(znk = 1|zn 1,j = 1) where 0 Ajk 1 ^ K X k=1 Ajk = 1 and A = [Ajk] 1jK,1kK 8k , 8n , p( xn |znk, k) = znkf( xn | k) and = { 1, 2, ..., K } then p( xn | zn, ) = K Y k=1 f( xn | k)znk X = { x1, x2, ..., xN } , Z = { z1, z2, ..., zN } , ✓ = { ⇡ , A , } as the result p( X , Z | ✓ ) = p( z1 | ⇡ ) ( N Y n=2 p( zn | zn 1, A ) ) ( N Y n=1 p( xn | zn, ) )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}