-> pd.DataFrame: df = df_.copy() df['current_month'] = (df['publication_date'] + pd.to_timedelta(df['current_day'], unit='d')).dt.month df['current_dayofyear'] = (df['publication_date'] + pd.to_timedelta(df['current_day'], unit='d')).dt.dayofyear df['current_weekday'] = (df['publication_date'] + pd.to_timedelta(df['current_day'], unit='d')).dt.weekday df.loc[df['campaign'], 'campaign_count'] = df.loc[df['campaign'], 'campaign_count'] - 1 df = df.drop( ['document_id', 'from', 'to', 'campaign', 'from_day', 'to_day', 'ratio', 'publication_date', 'dist_kindle', 'base_price'], axis=1 ) # encode circular data (months, weekdays) as sin() + cos() for column, max_value in ( ('publication_month', 12), ('publication_dayofyear', 365), ('publication_weekday', 7), ('current_month', 12), ('current_dayofyear', 365), ('current_weekday', 7) ): df['{}_sin'.format(column)] = np.sin(2 * np.pi / max_value * df[column]) df['{}_cos'.format(column)] = np.cos(2 * np.pi / max_value * df[column]) df.drop([column], axis=1, inplace=True) return df 39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
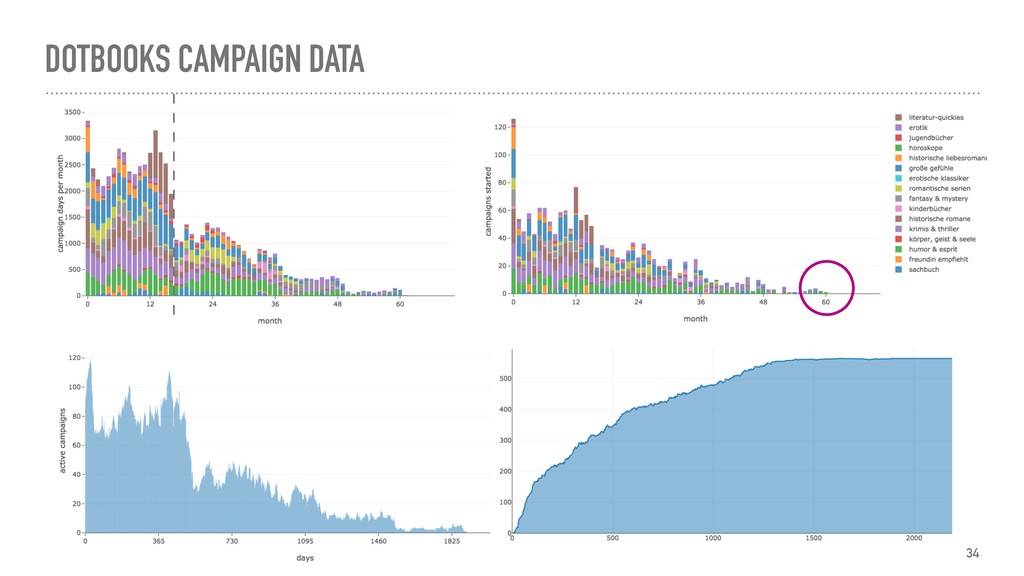{kind=link}
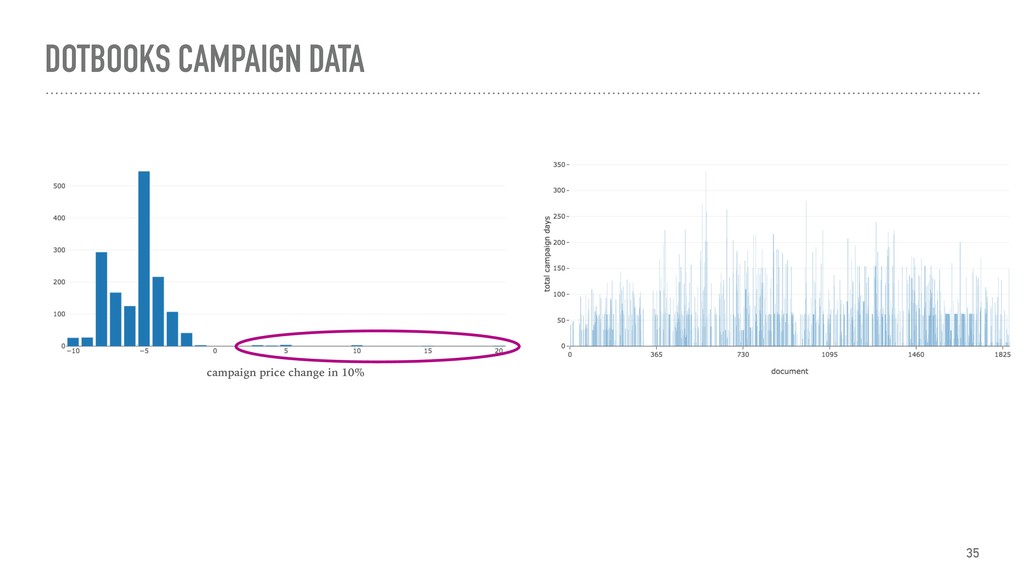{kind=link}
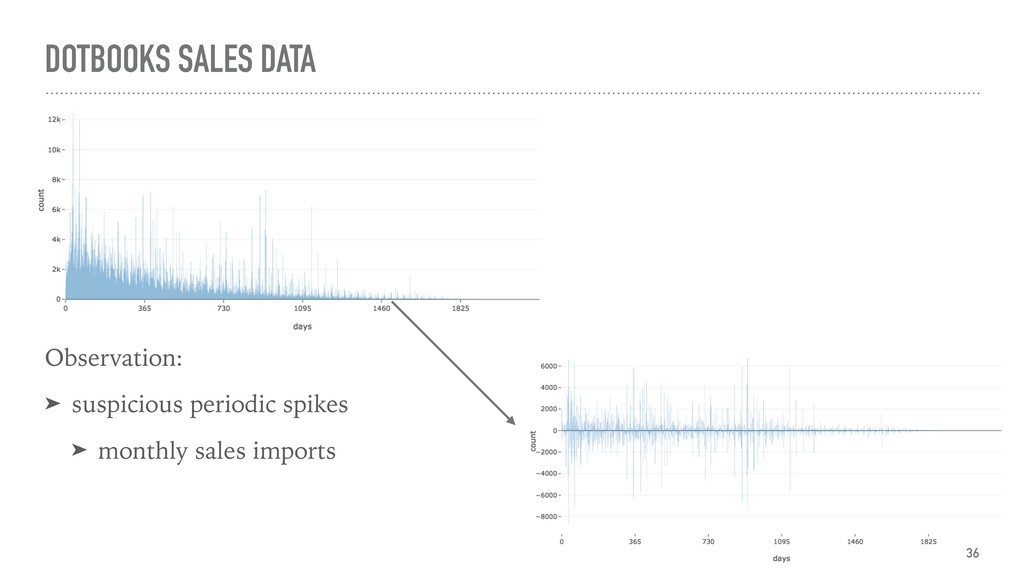{kind=link}
{kind=link}
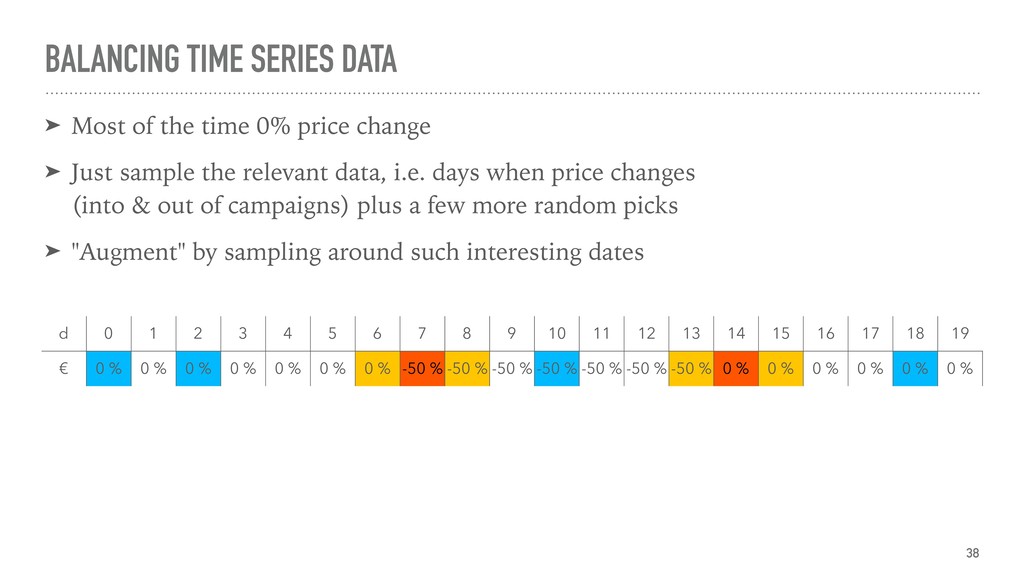{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
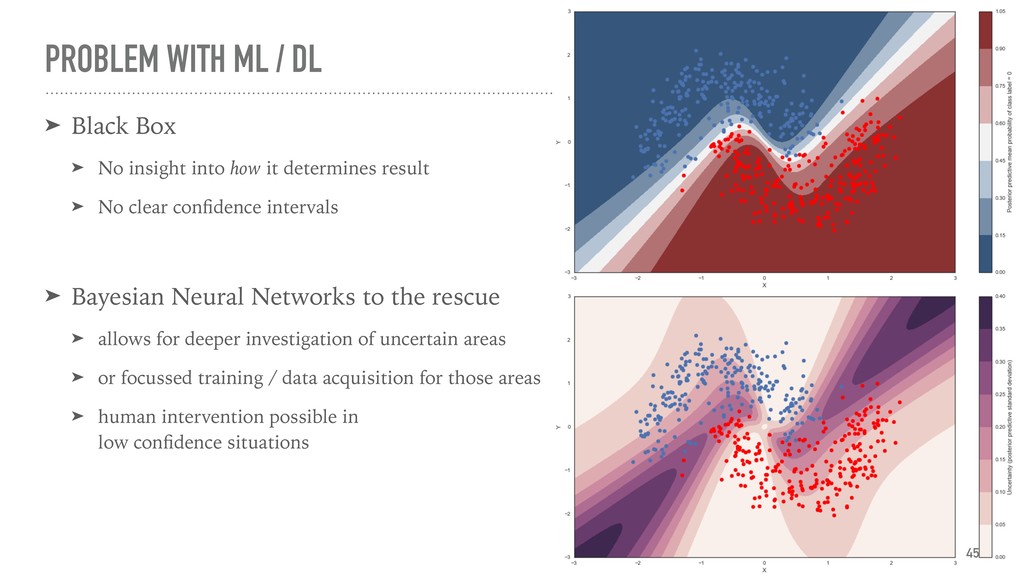{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}