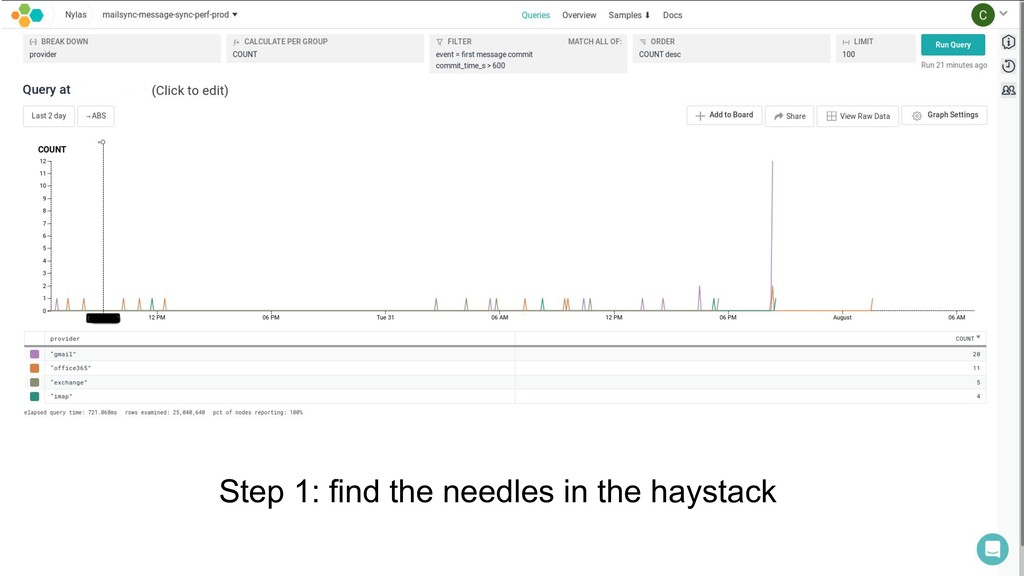
The macro landscape in software has changed in the last decade—metrics, monitoring, unstructured logs, and alerting aren't enough to tell what our software is doing anymore. This opening keynote from o11ycon 2018 will focus on how we've achieved observability on the Nylas platform, using many concrete examples—and will show what observability means to us and where we're still lacking.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
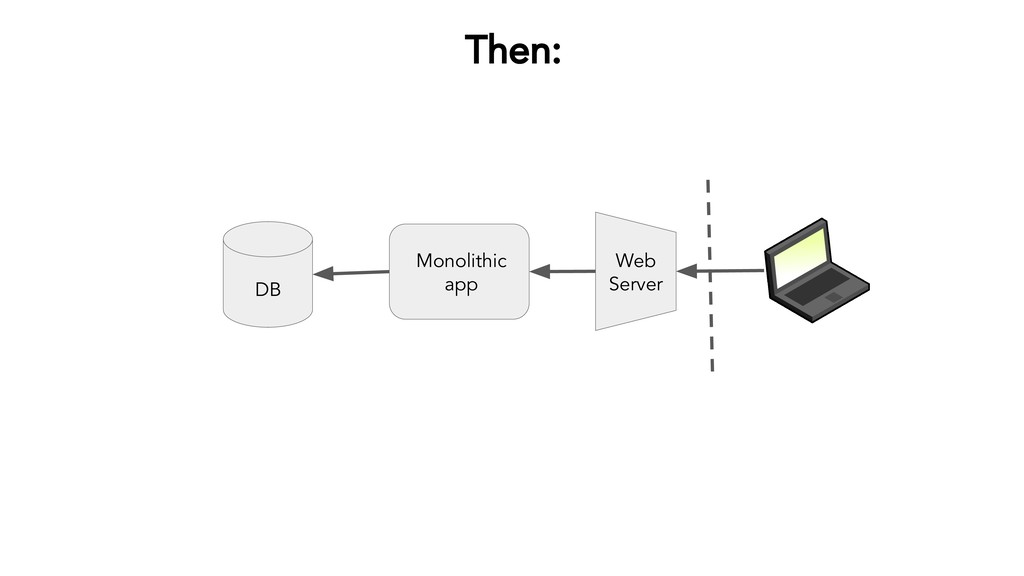{kind=link}
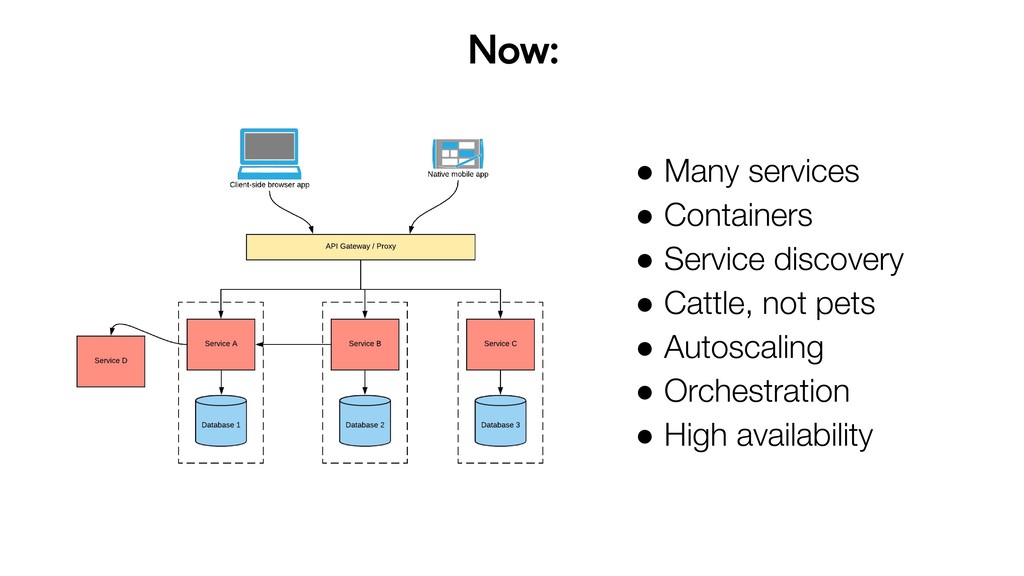{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
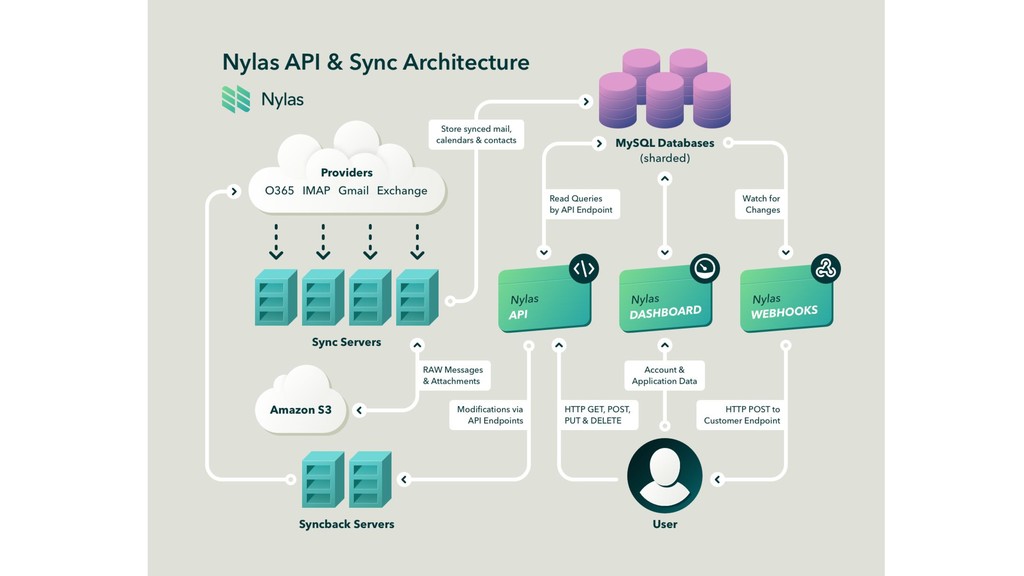{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
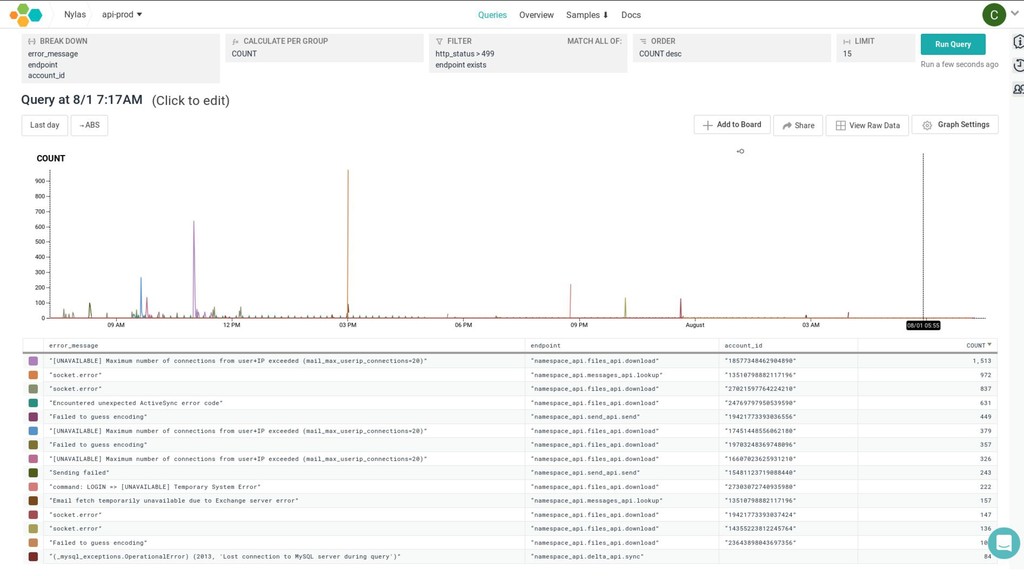{kind=link}
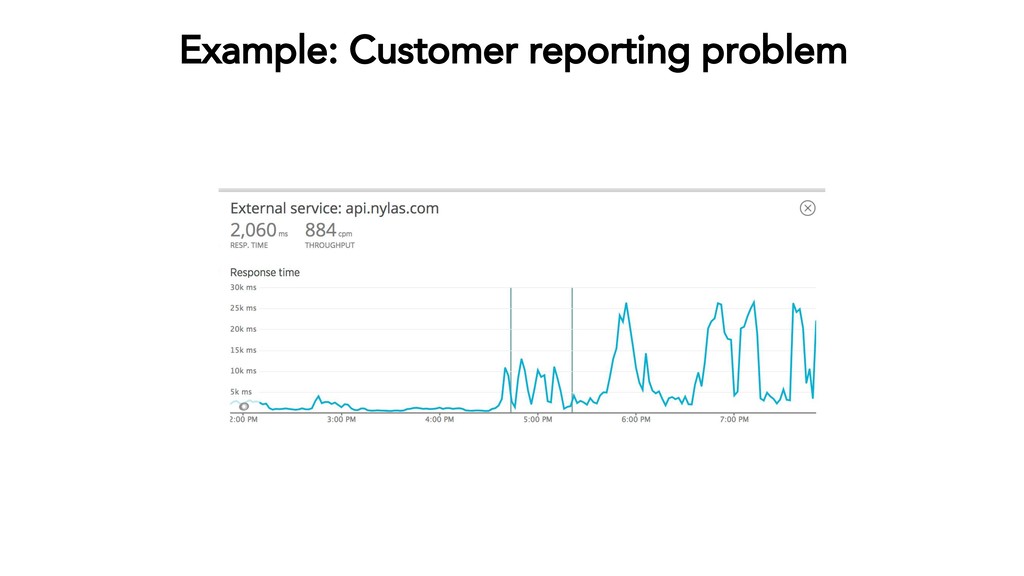{kind=link}
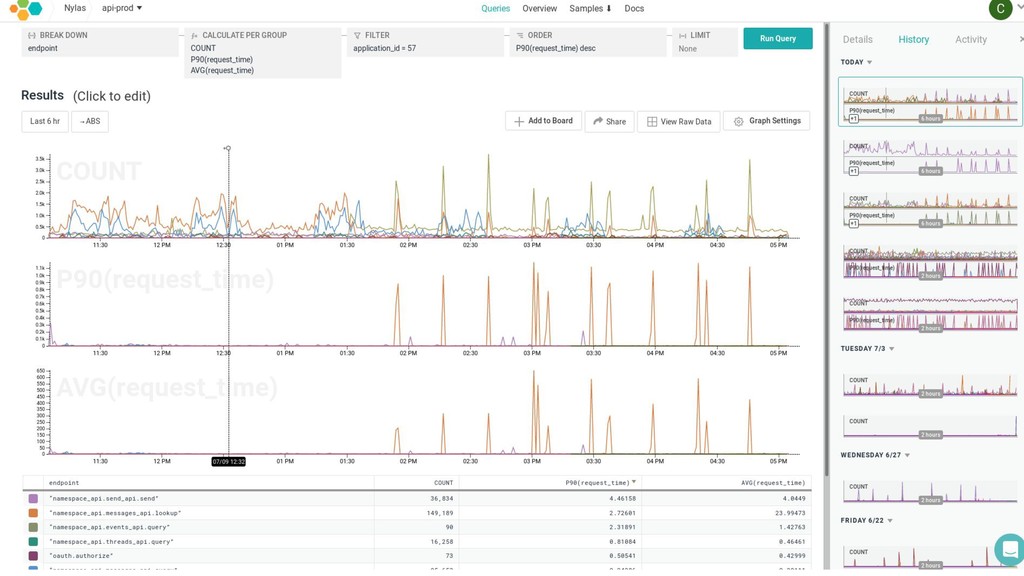{kind=link}
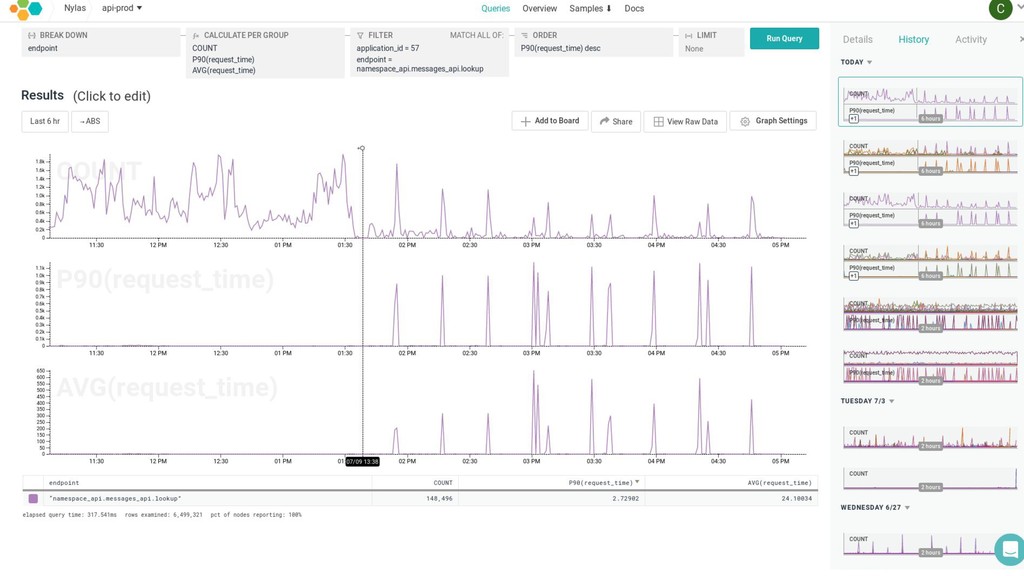{kind=link}
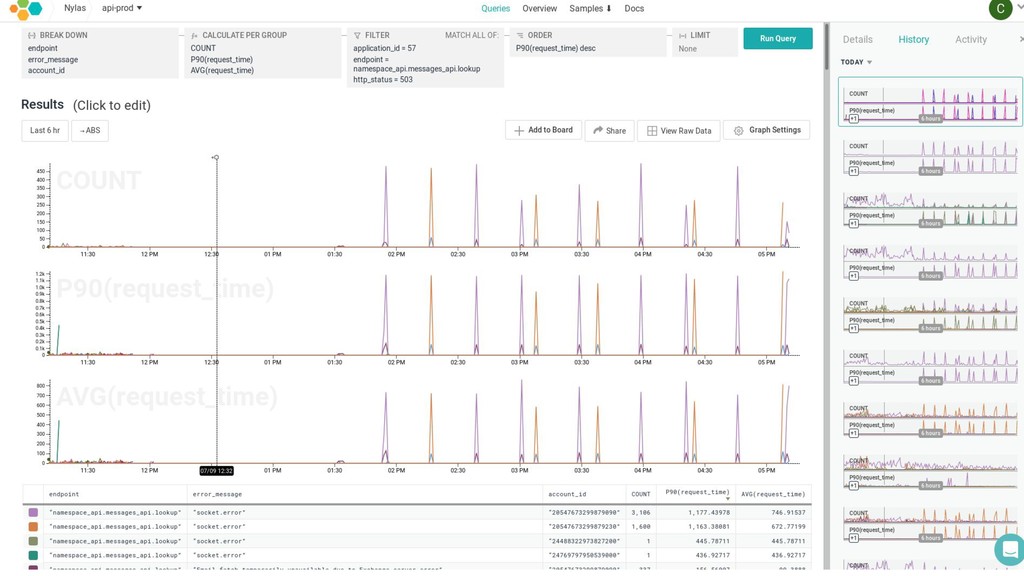{kind=link}
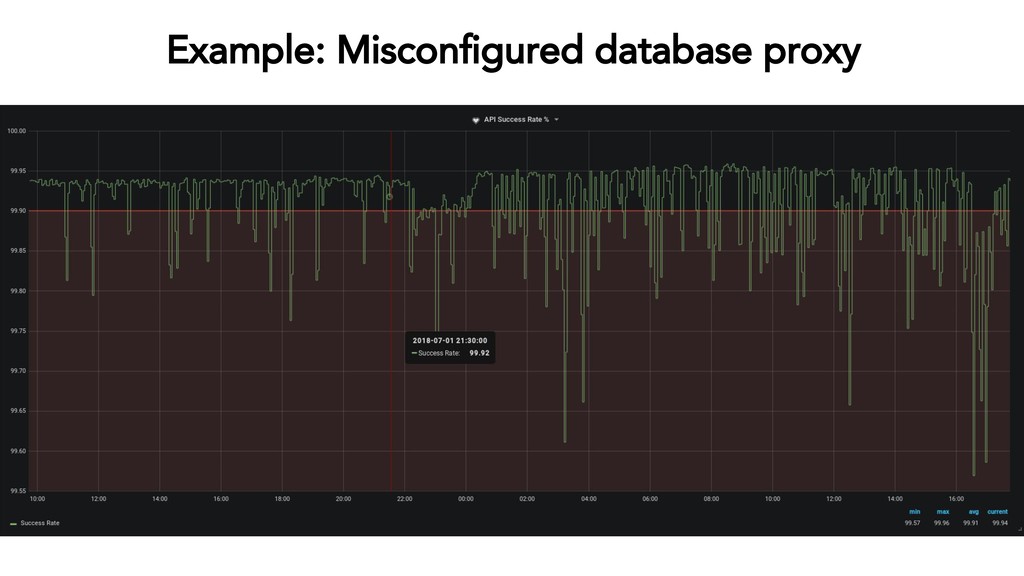{kind=link}
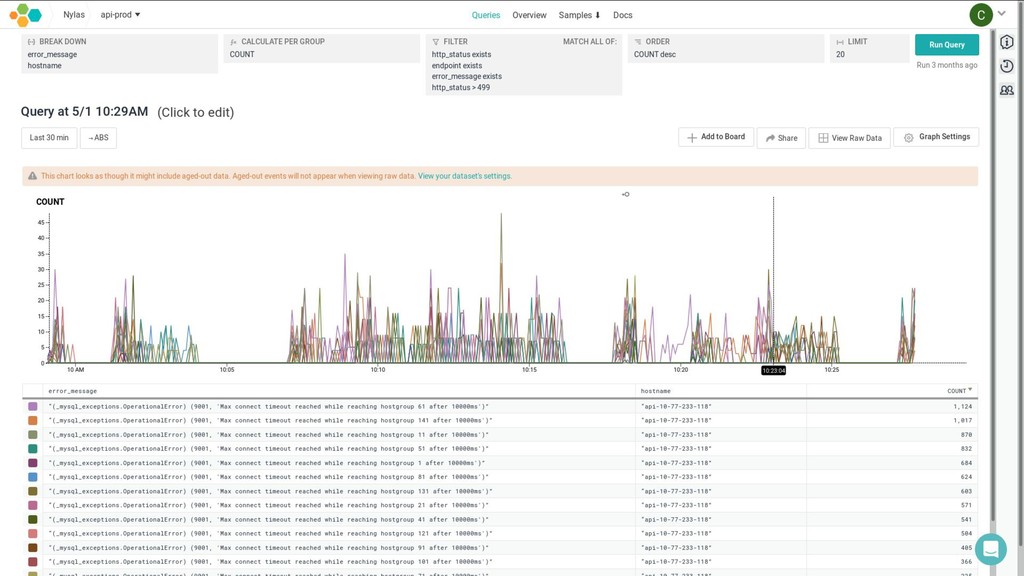{kind=link}
{kind=link}
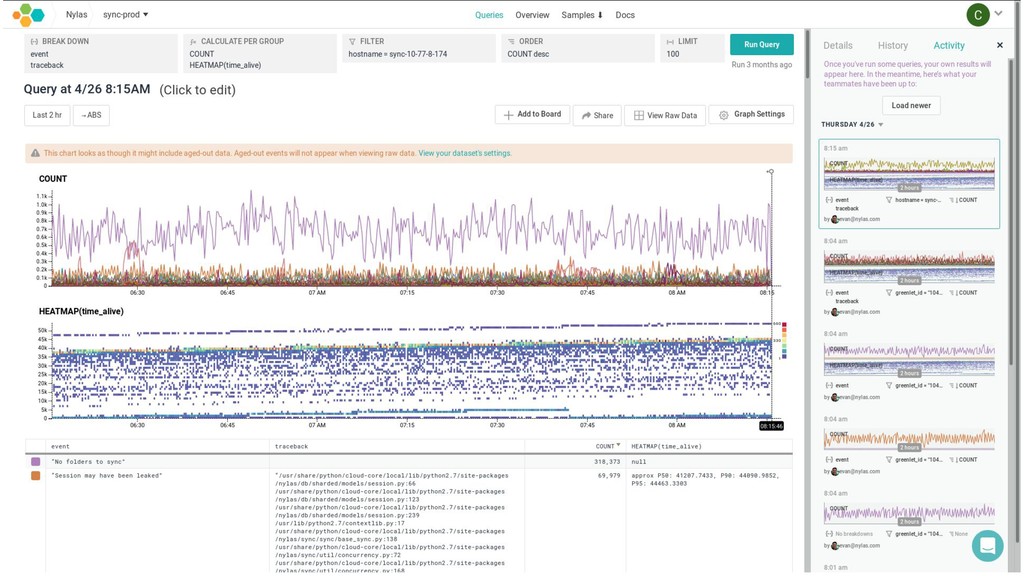{kind=link}
{kind=link}
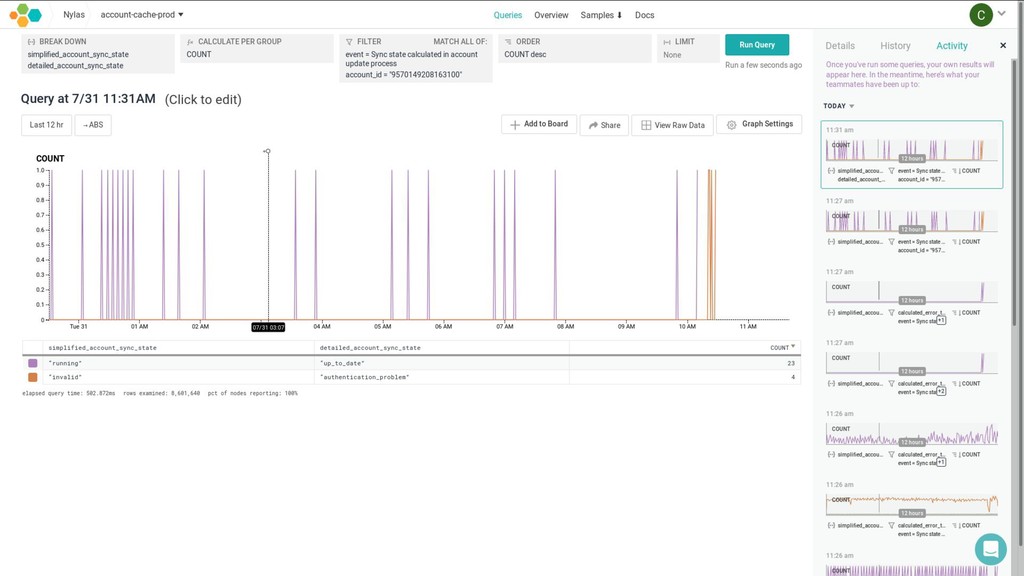{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}