bool, value int8) Header Null Bitmap pa d id int4 name varlen text active bool 固定長型 int4, bool, int8 → そのまま格納 (例: int4は4バイト, boolは1バイト) 可変長型 text, varchar → 先頭に長さ情報 (varlen)。その後ろにテキスト。NULL終端しない Null Bitmap 各カラムが NULL かどうかを 1bit で管理。NULLが存在しないタプルはNull Bitmapは省略 value int8 pa d pad 次のカラムをその型が要求する境界に揃えるために挿入される空きバイト int4なら4で割り切れるメモリ番地に配置する Header 固定長のヘッダ。トランザクション可視性(xmin/xmax)や各種フラグなどがある OSSデータベースの内部構造を理解しよう 10
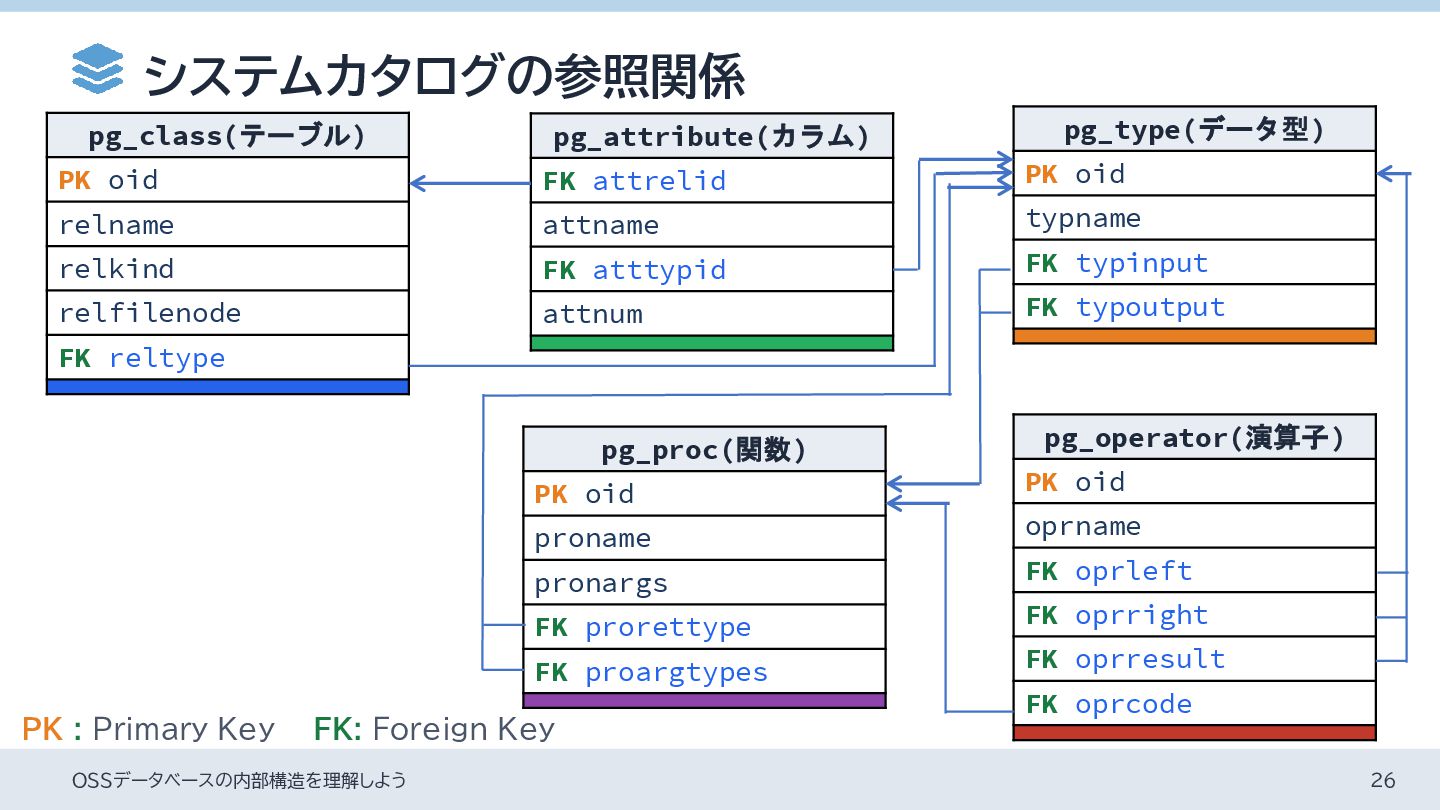
relname relkind relfilenode FK reltype pg_attribute(カラム) FK attrelid attname FK atttypid attnum pg_type(データ型) PK oid typname FK typinput FK typoutput pg_proc(関数) PK oid proname pronargs FK prorettype FK proargtypes pg_operator(演算子) PK oid oprname FK oprleft FK oprright FK oprresult FK oprcode システムカタログの参照関係 OSSデータベースの内部構造を理解しよう 26
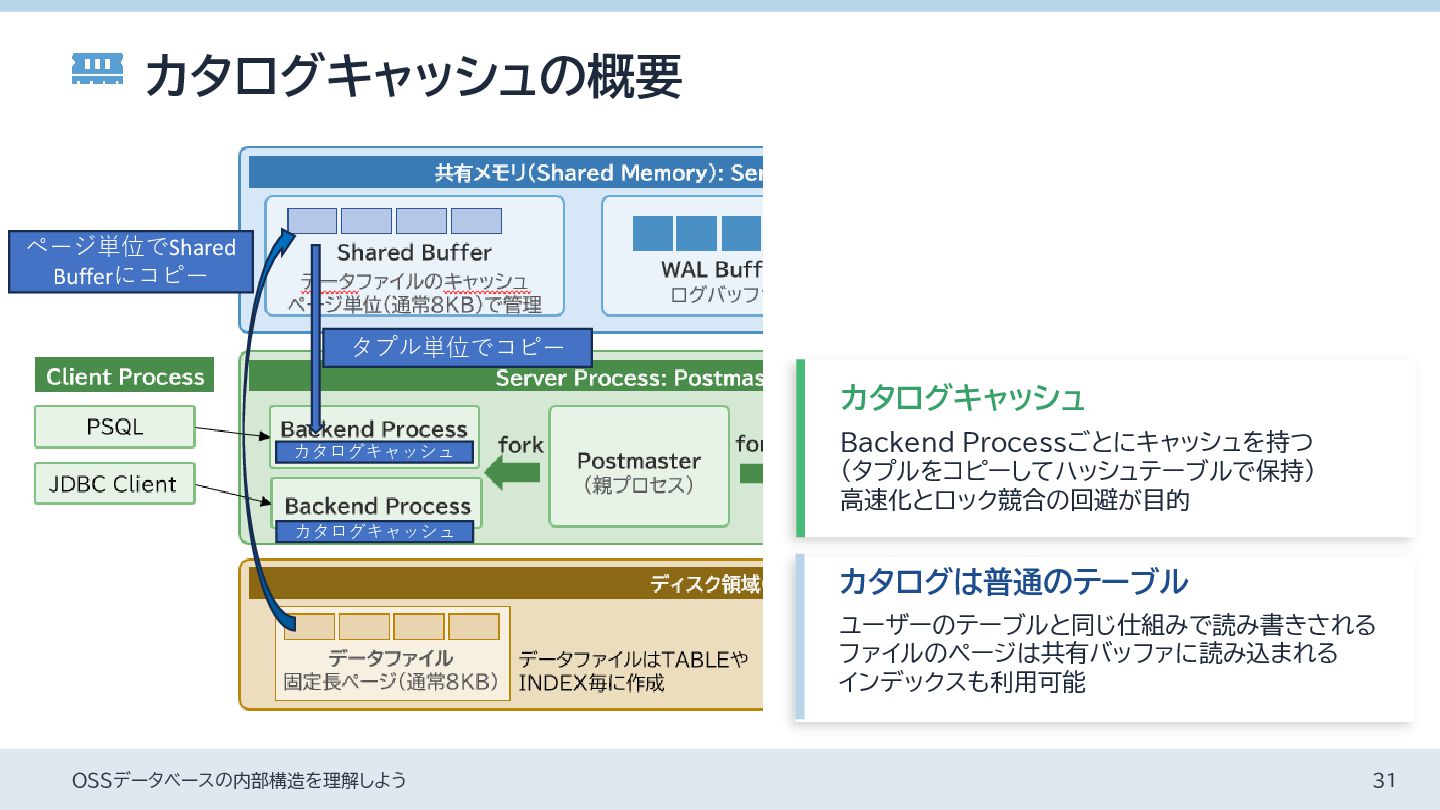
• relnameなどの文字列もNAME型(64バイト固定長)にしている • 可変長やNULLABLEなカラムはテーブルの末尾に配置 • 固定長部分は同じメモリレイアウトにすることで、高速アクセスを実現 Header Null Bitmap pa d oid OID(4byte) name NAME(64byte) active bool value int8 pa d タプルの前方は固定長かつNOT NULLの データ型を利用することで、全てのタプルが 同じメモリレイアウトになる acl aclitem[] 可変長や NULLABLEは 後方に配置
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ページ内部の構造 〜8KB ページの内部レイアウト〜 PageHeaderData (24 bytes) Line Pointer Array (ItemIdData[])](https://files.speakerdeck.com/presentations/dddb0318e0524c14a245ab804b5726d3/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
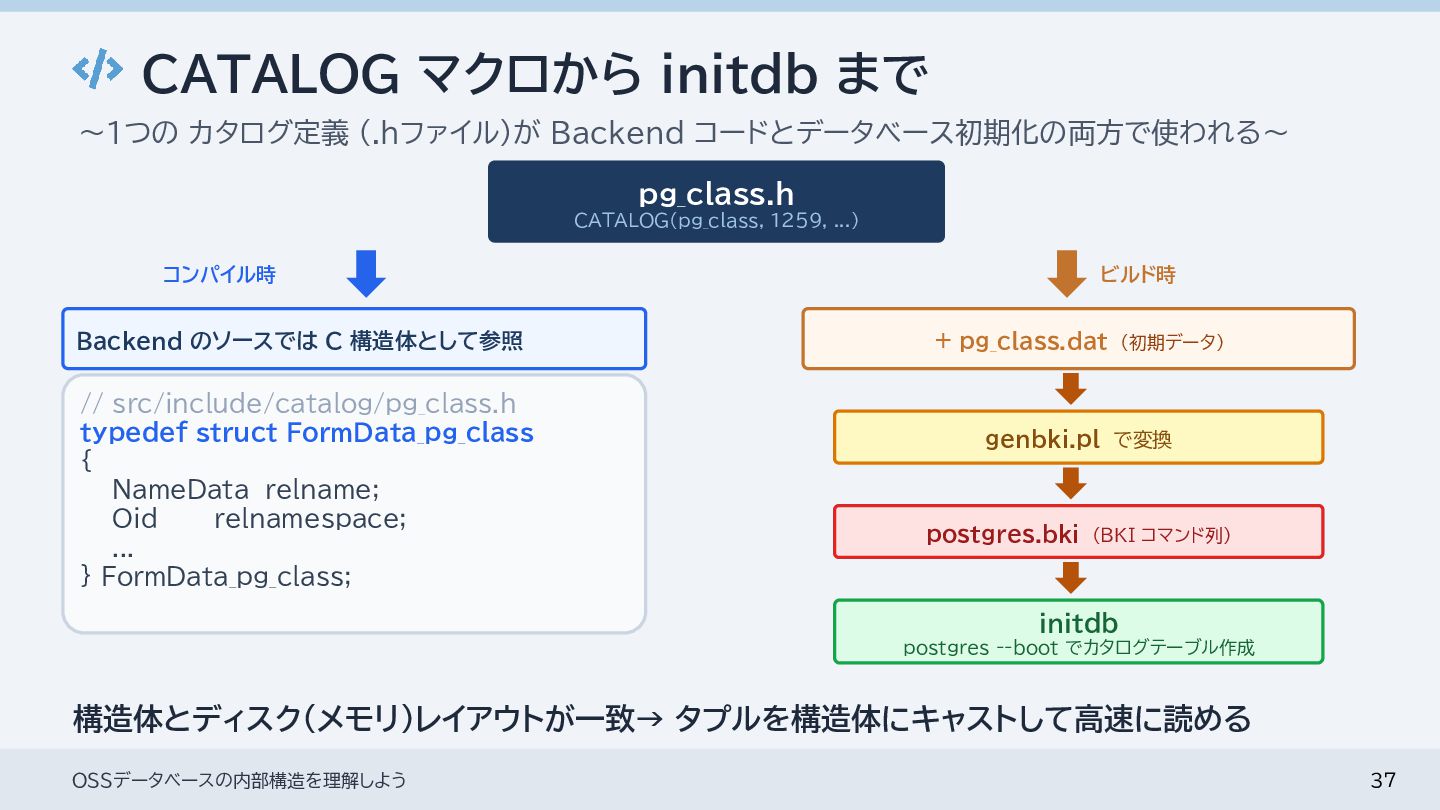{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
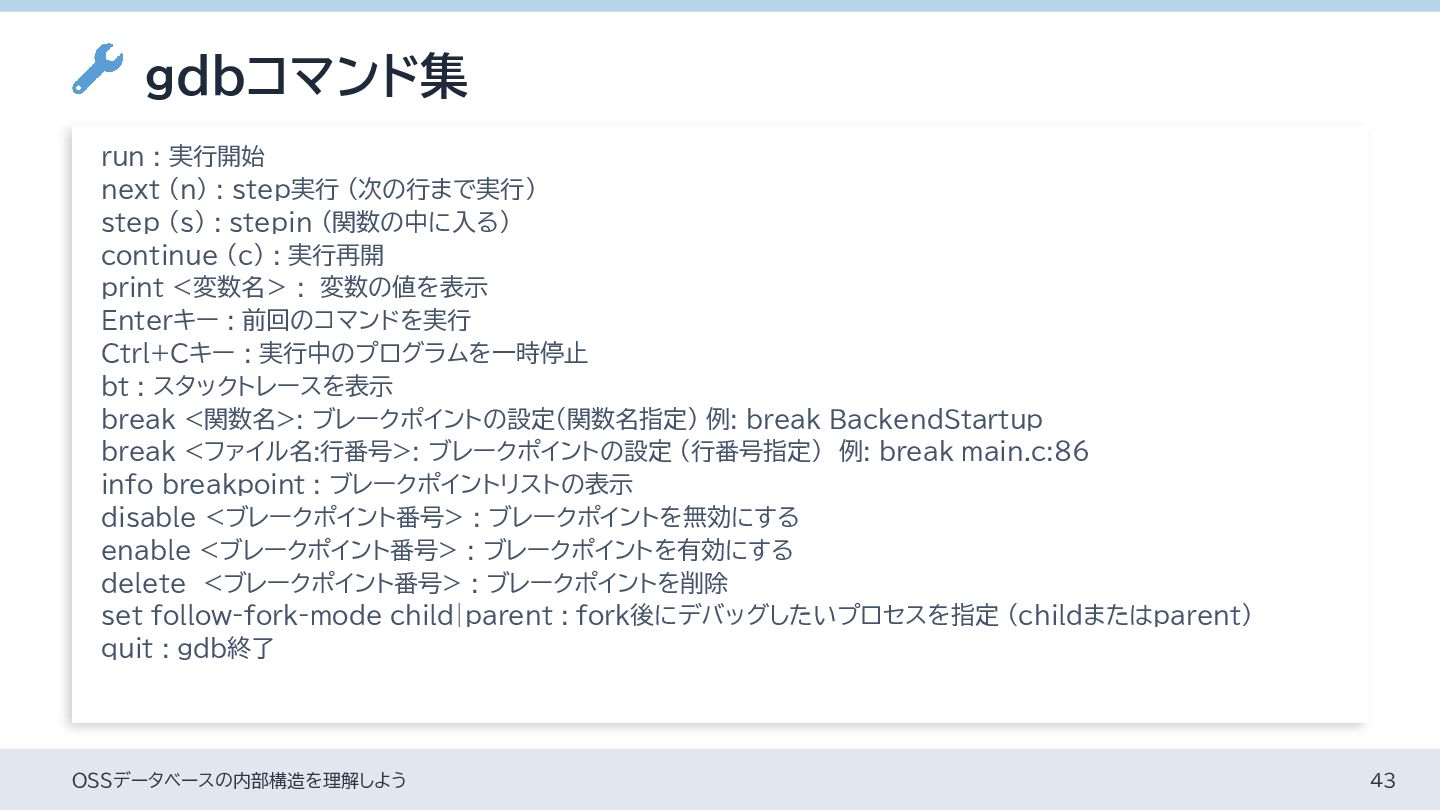{kind=link}
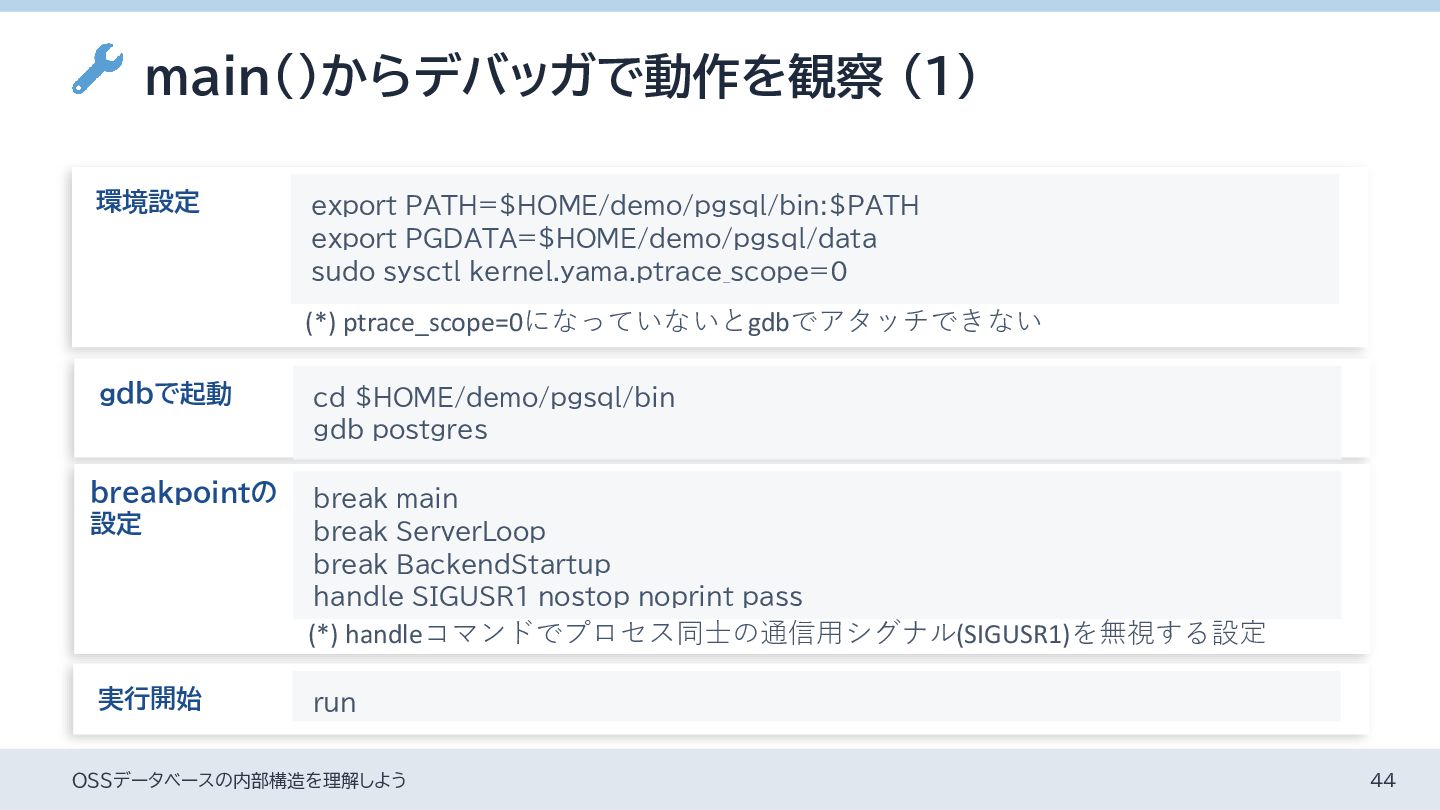{kind=link}
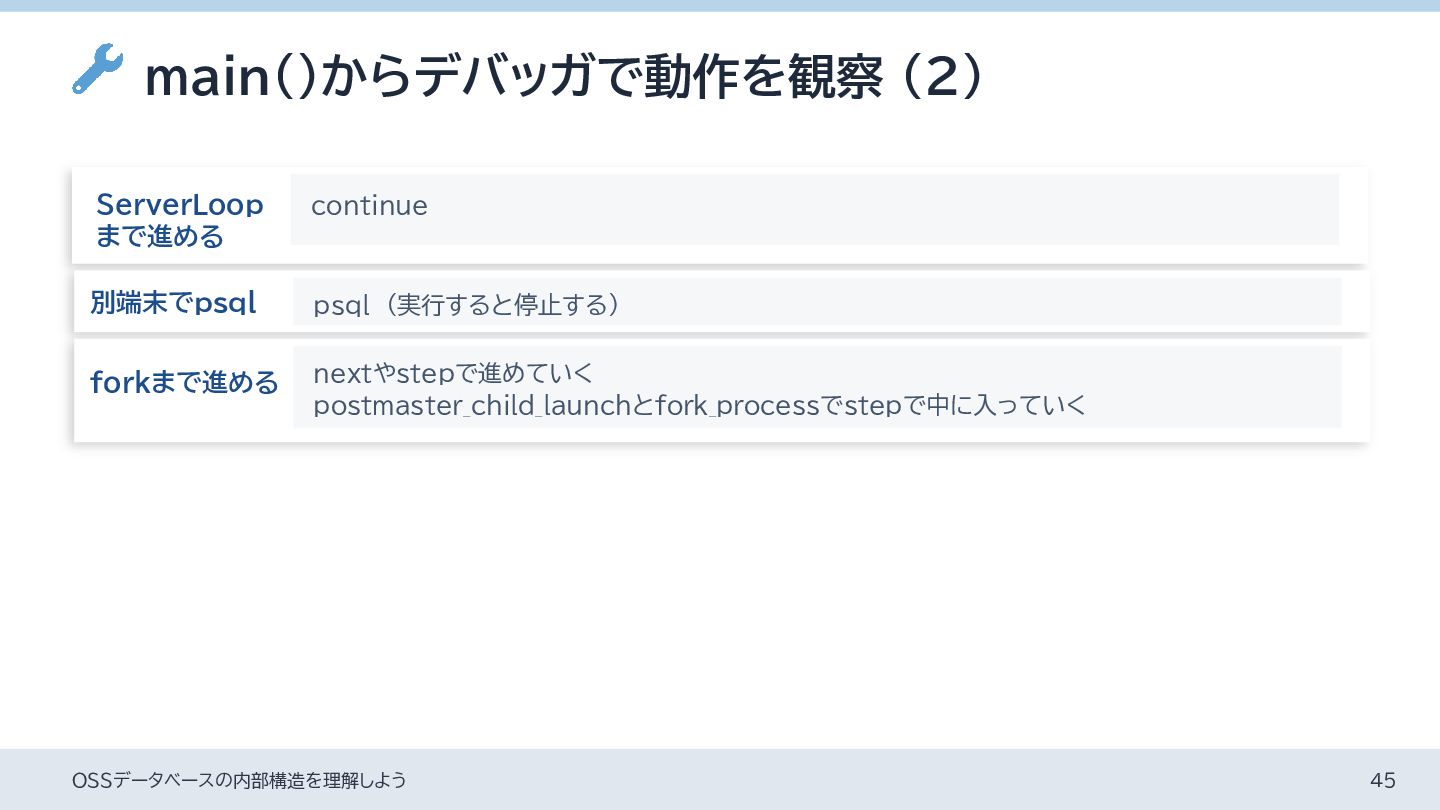{kind=link}
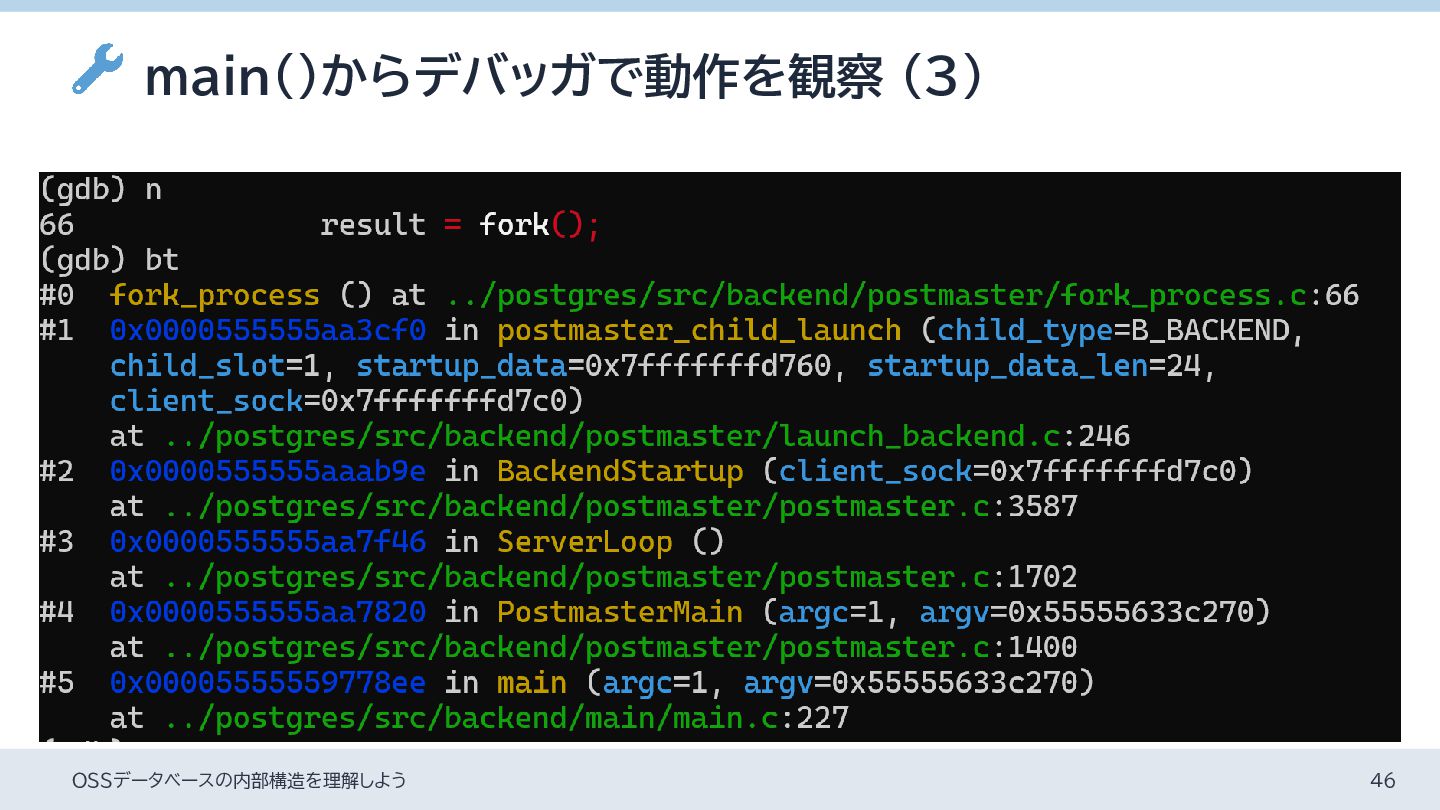{kind=link}
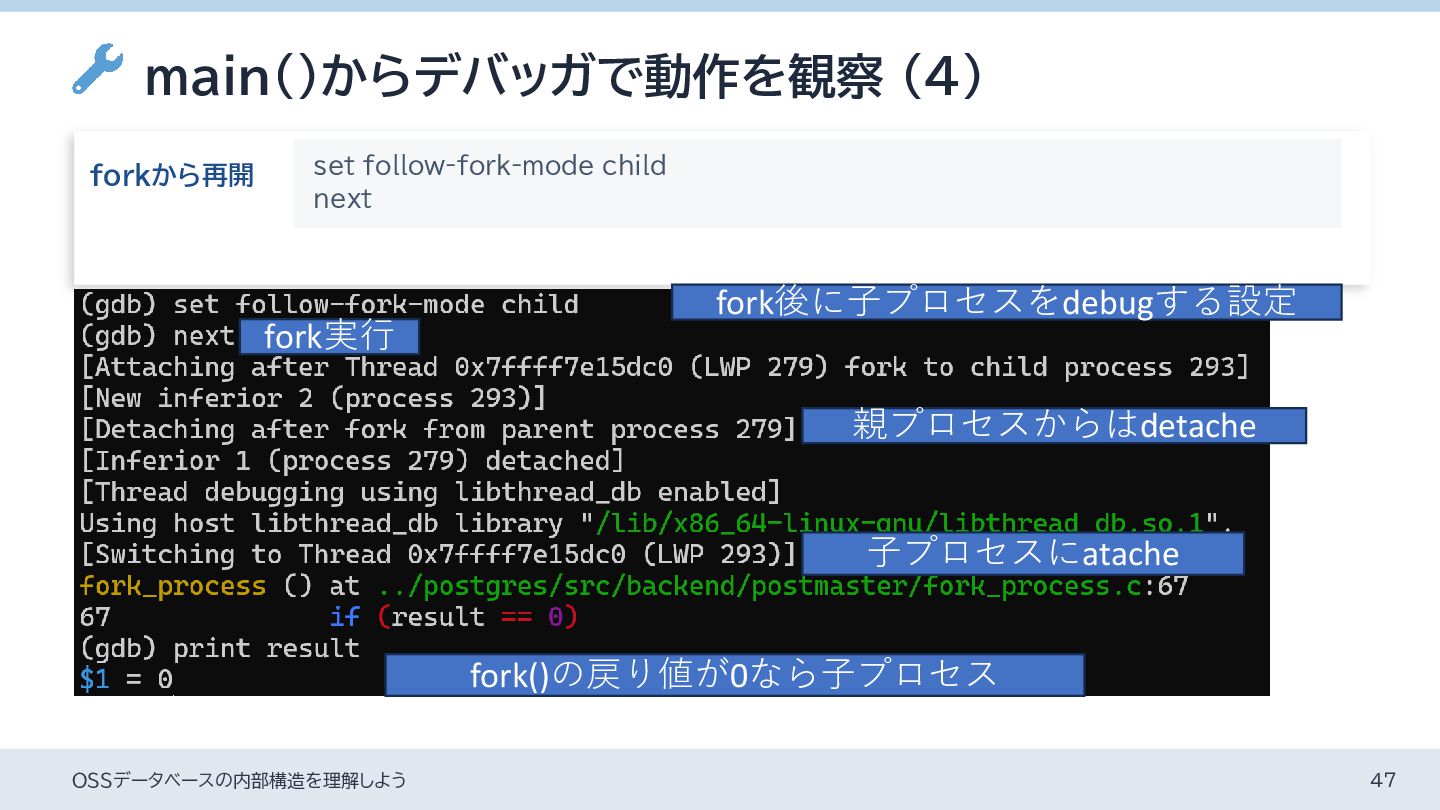{kind=link}
![main()からデバッガで動作を観察 (5) OSSデータベースの内部構造を理解しよう 48 子プロセスで 処理を進める nextでchild_process_kinds[child_type].main_fnまで進める break launch_backend.c:290してcontinueでもよい print](https://files.speakerdeck.com/presentations/dddb0318e0524c14a245ab804b5726d3/slide_47.jpg){kind=link}
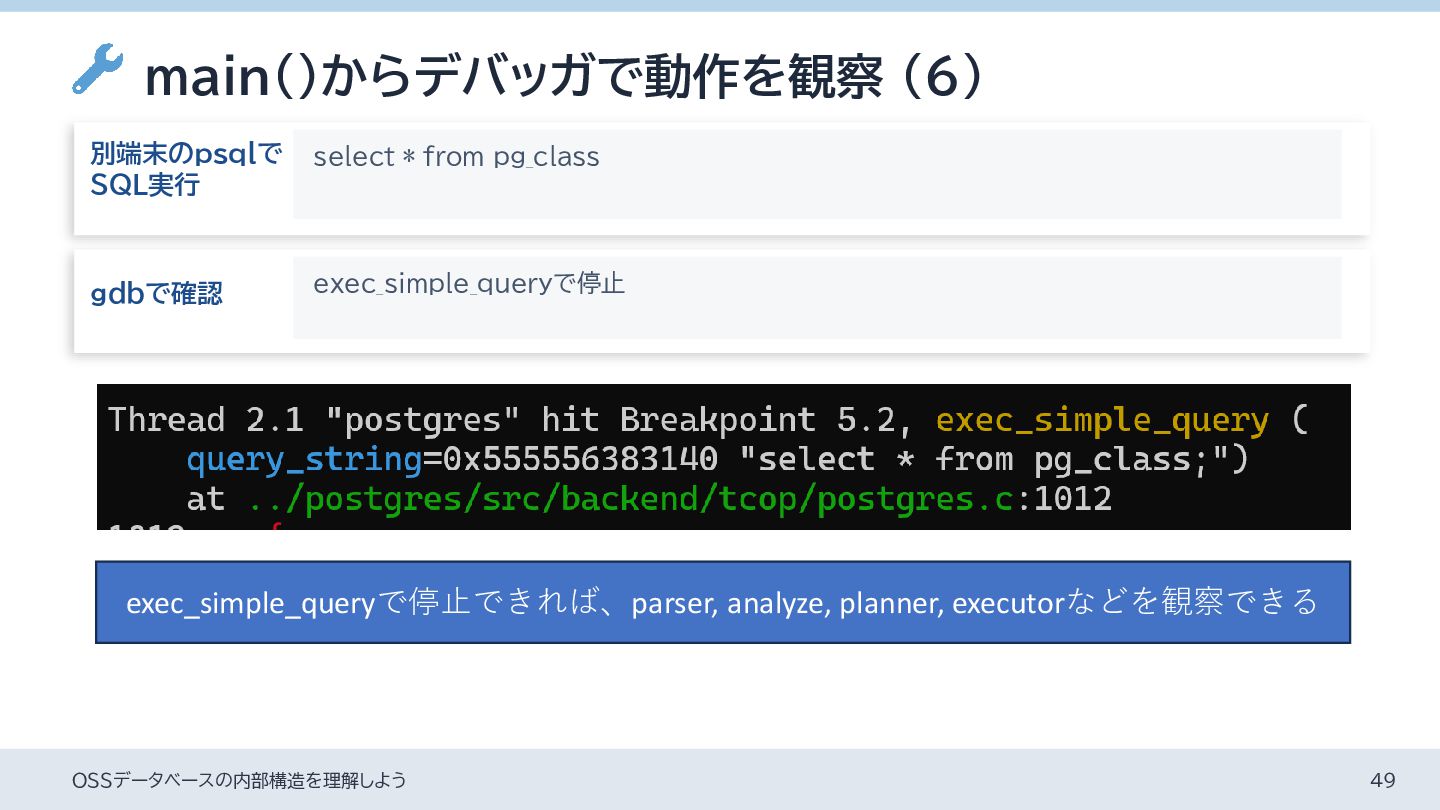{kind=link}
{kind=link}
{kind=link}
{kind=link}
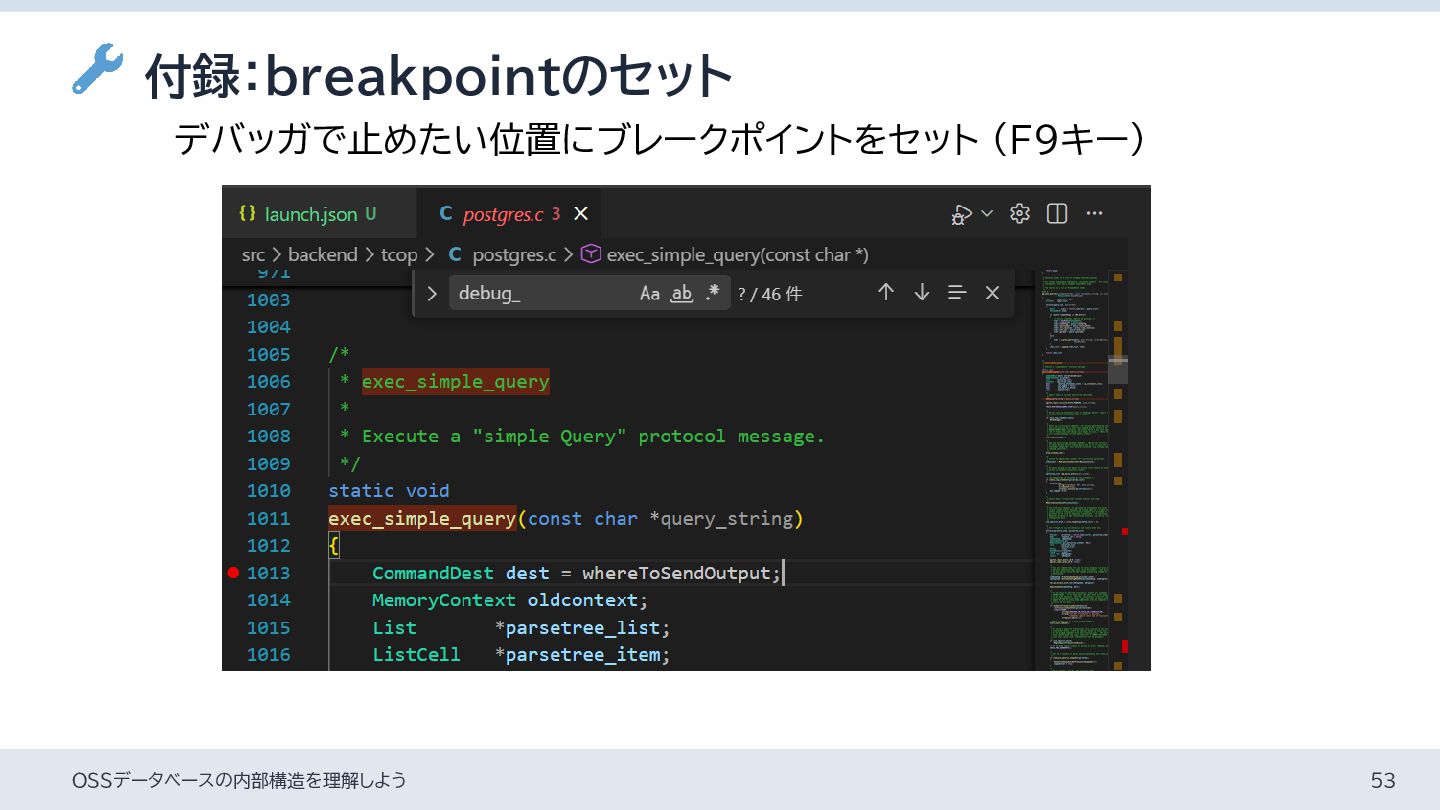{kind=link}
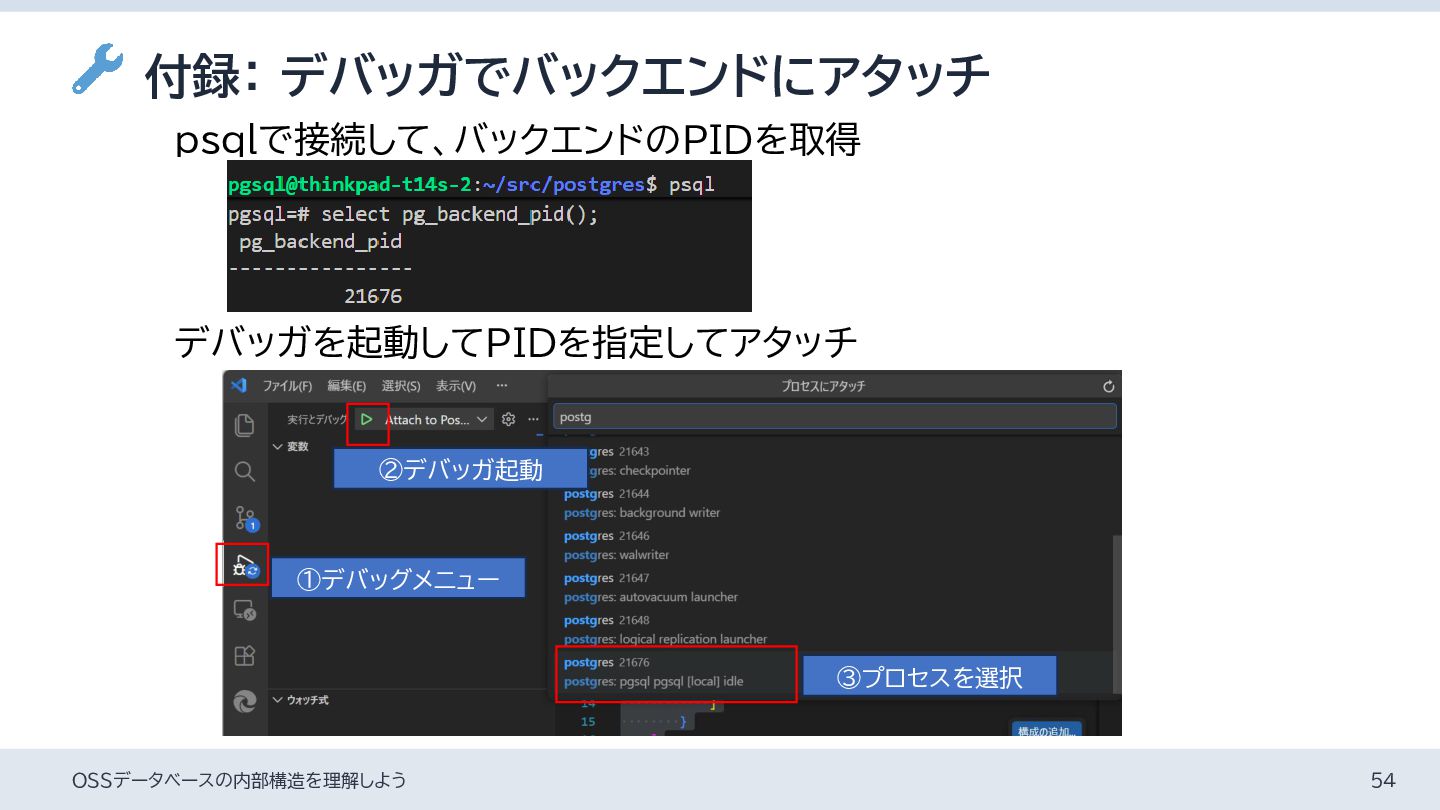{kind=link}
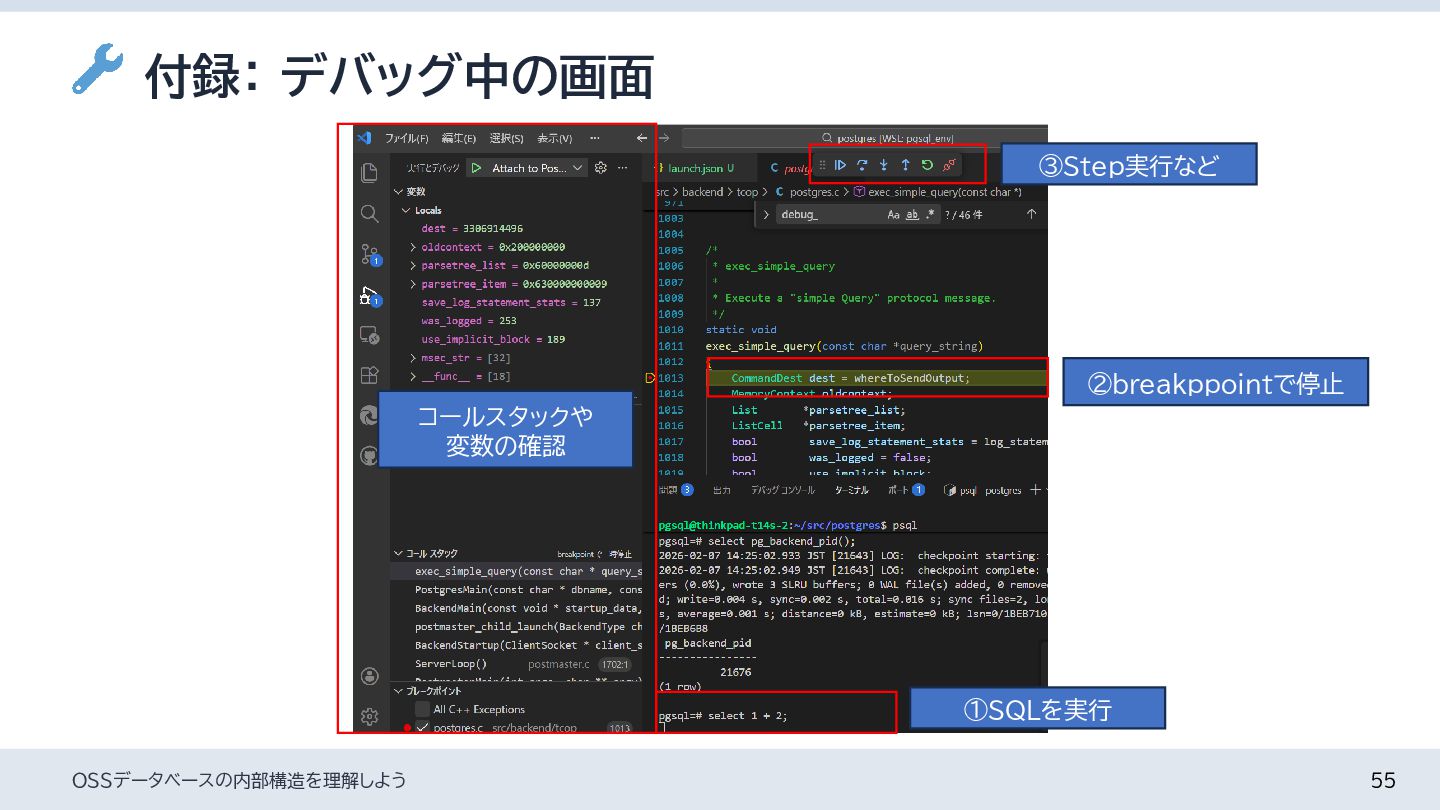{kind=link}
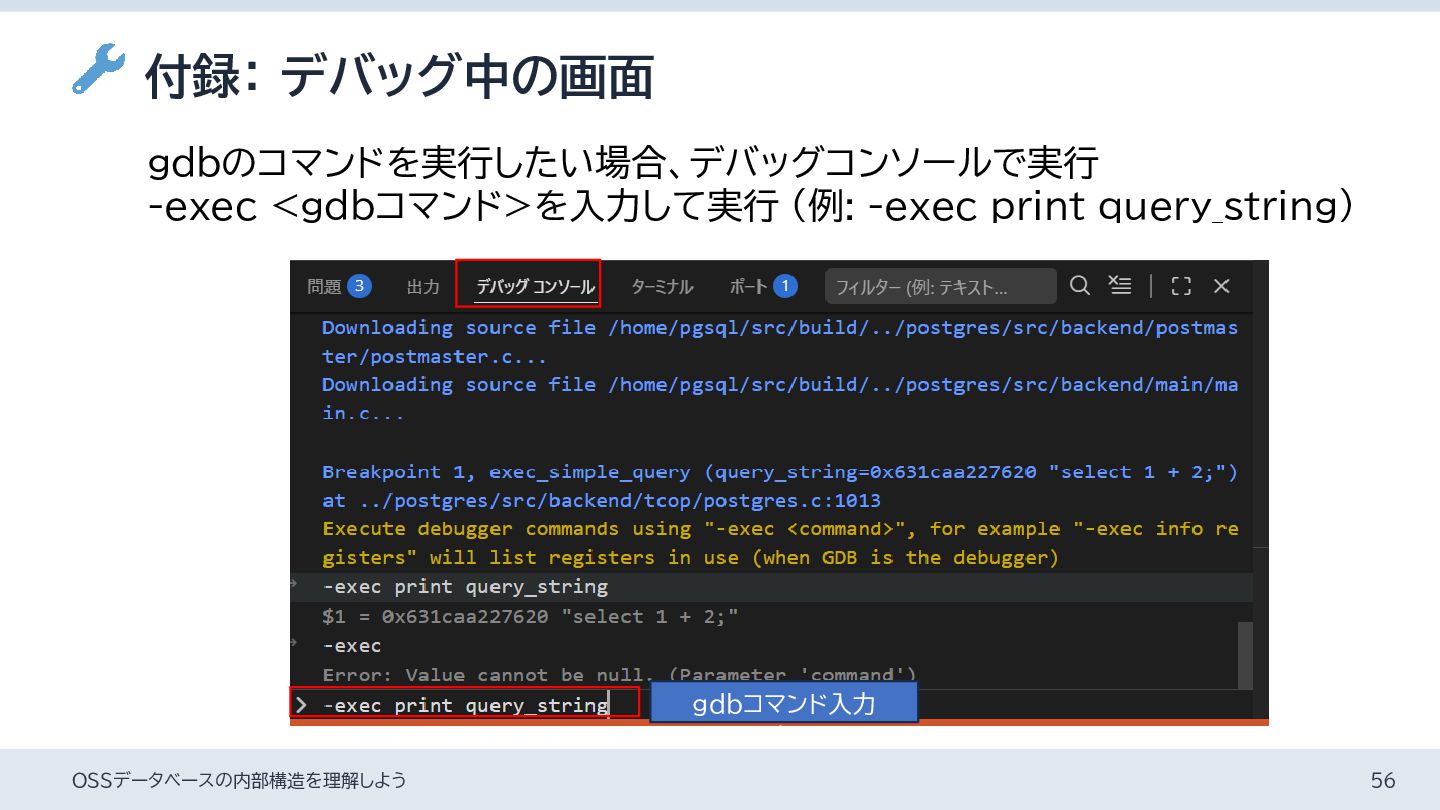{kind=link}