Share
こちらはFindy株式会社様主催のオンラインイベント「「RAG精度の壁を突破する-精度の壁とどう向き合う?」にて発表する資料です。 https://findy.connpass.com/event/383142/
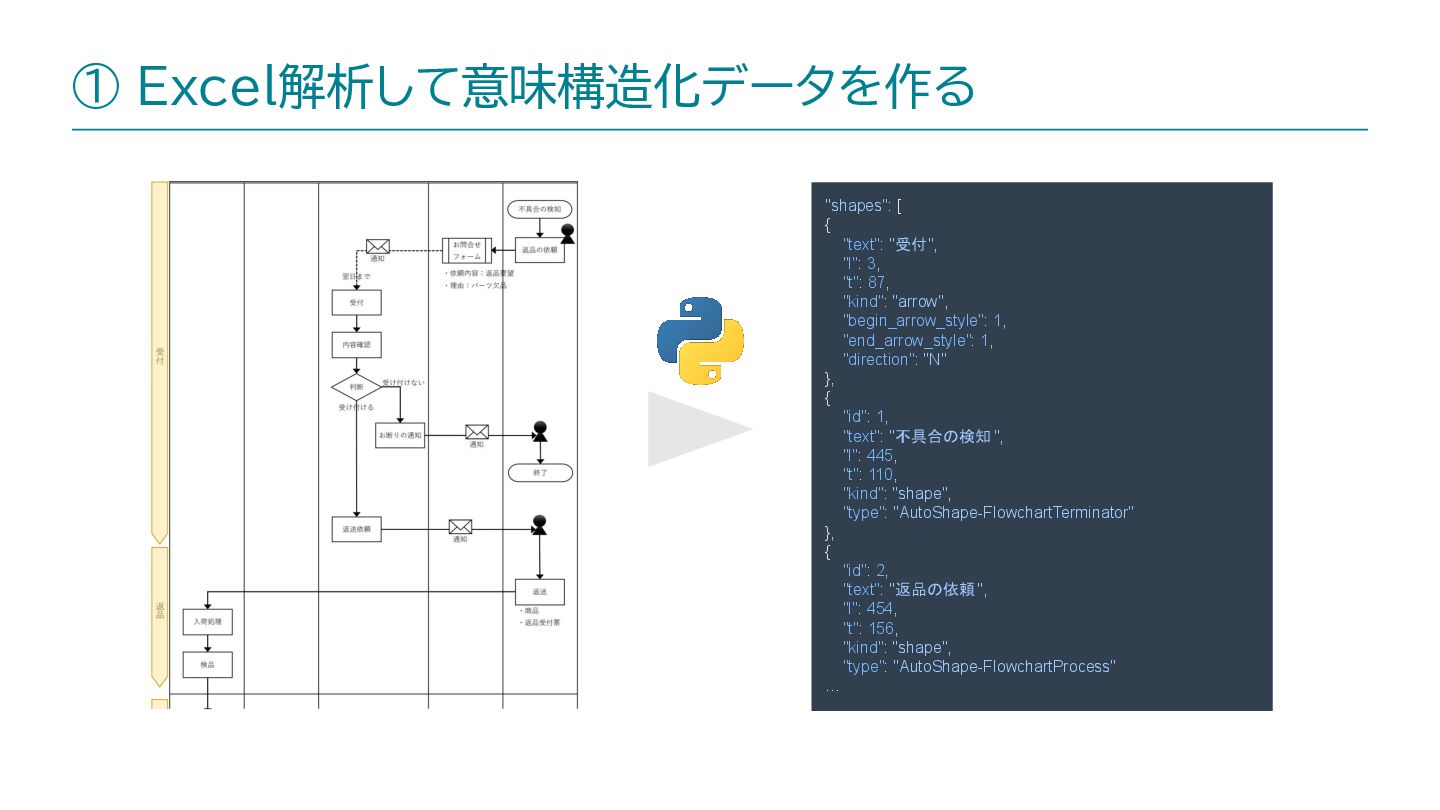
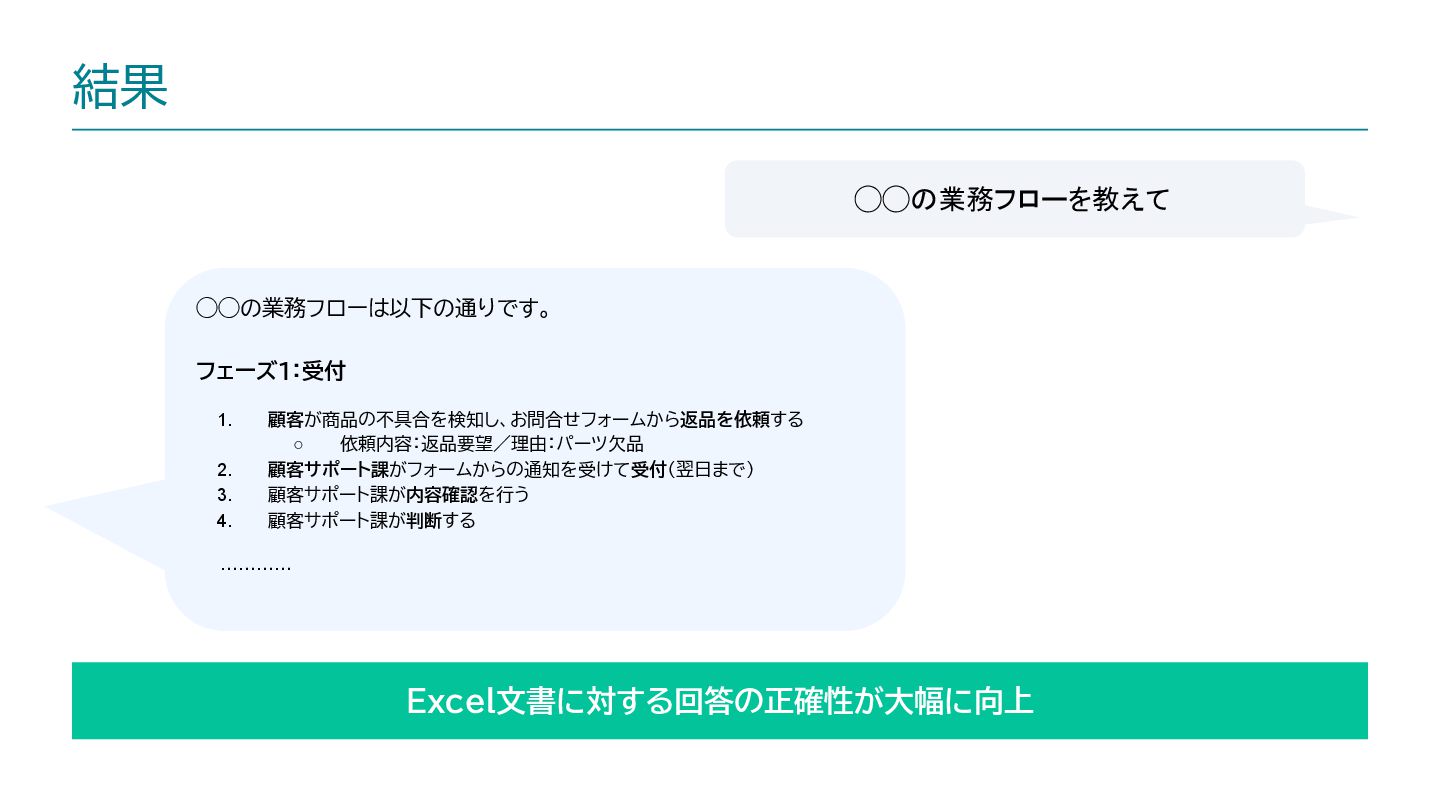
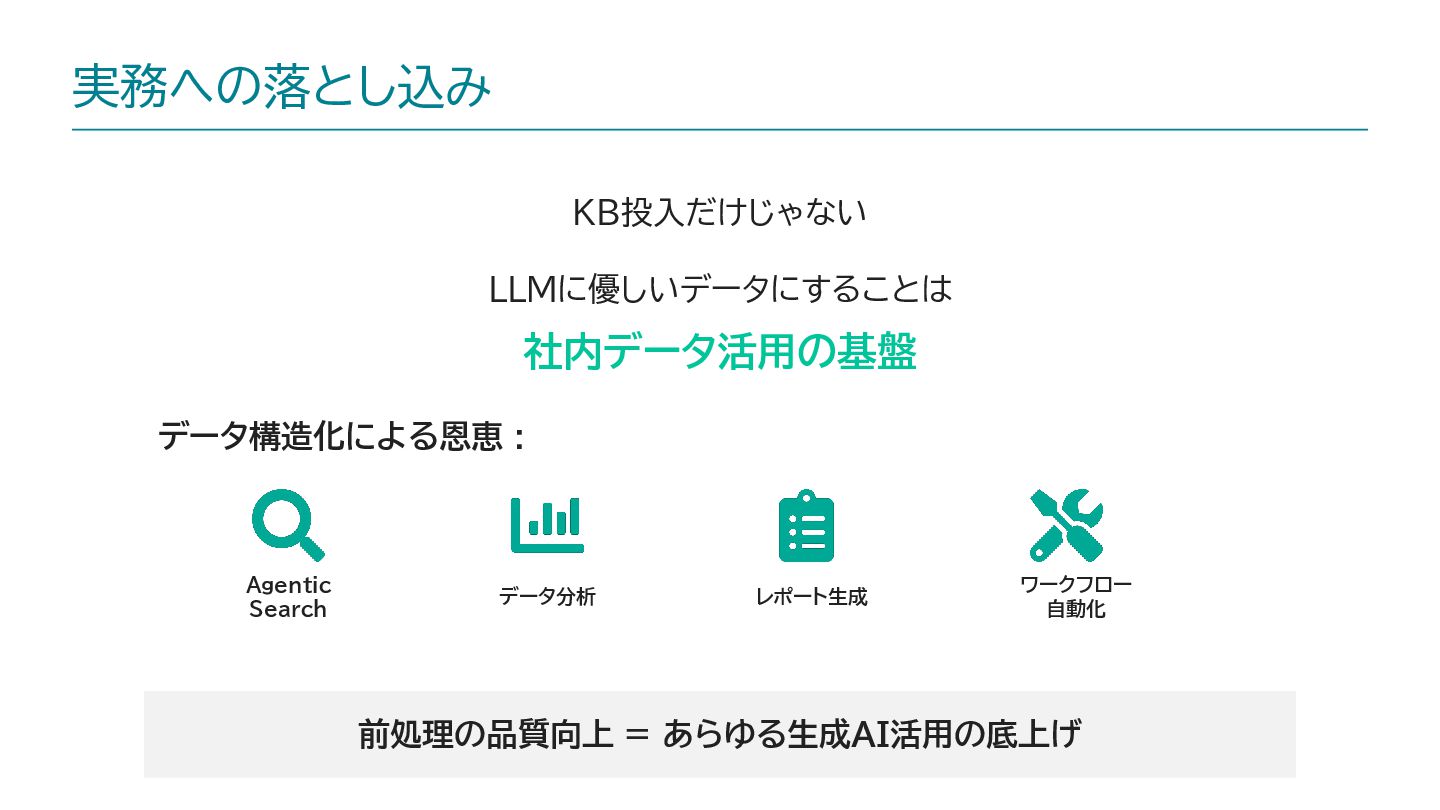
内容: RAGの精度改善において「データの扱い方」に焦点を絞り、その中でもExcel文書について現場的改善アプローチをして精度向上を計った話
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
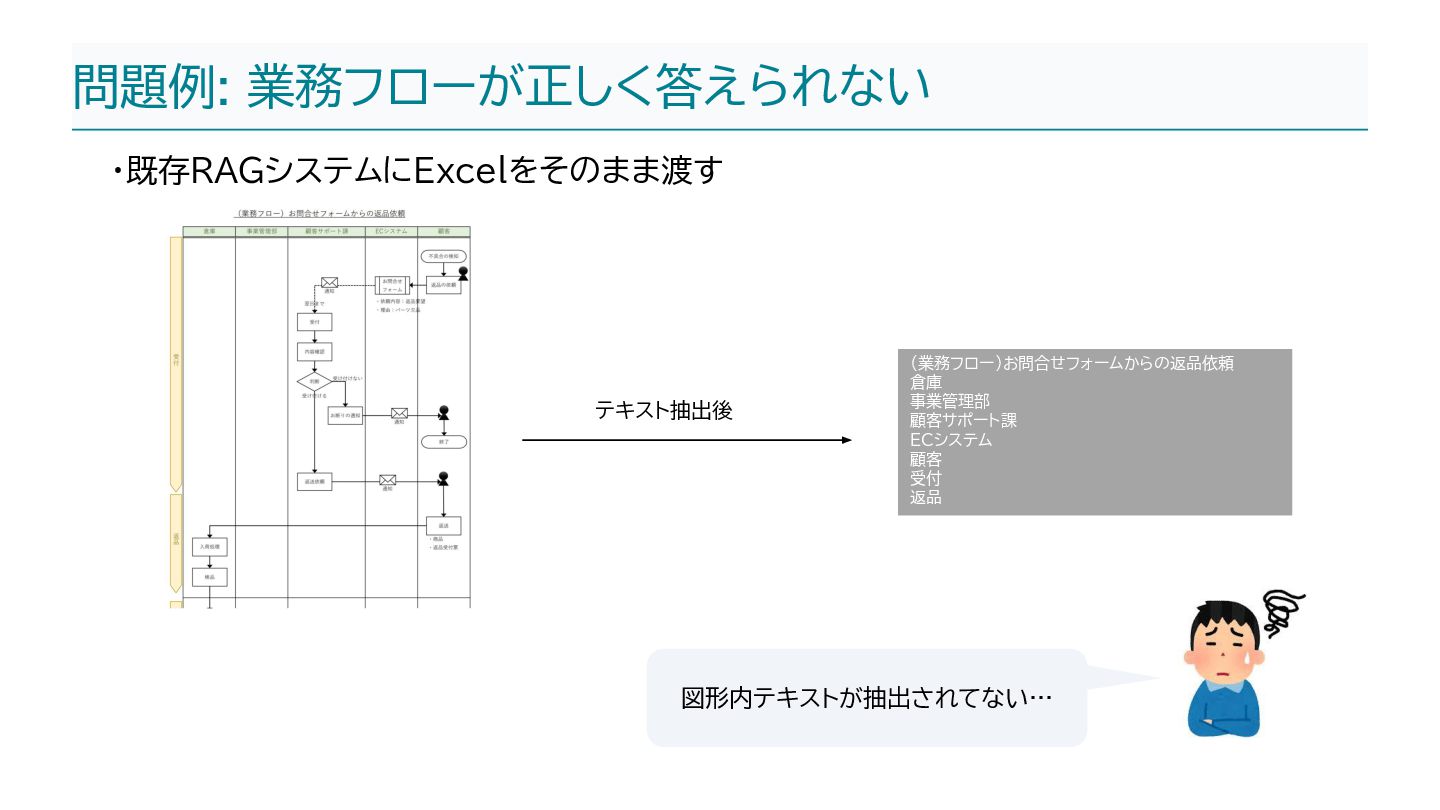{kind=link}
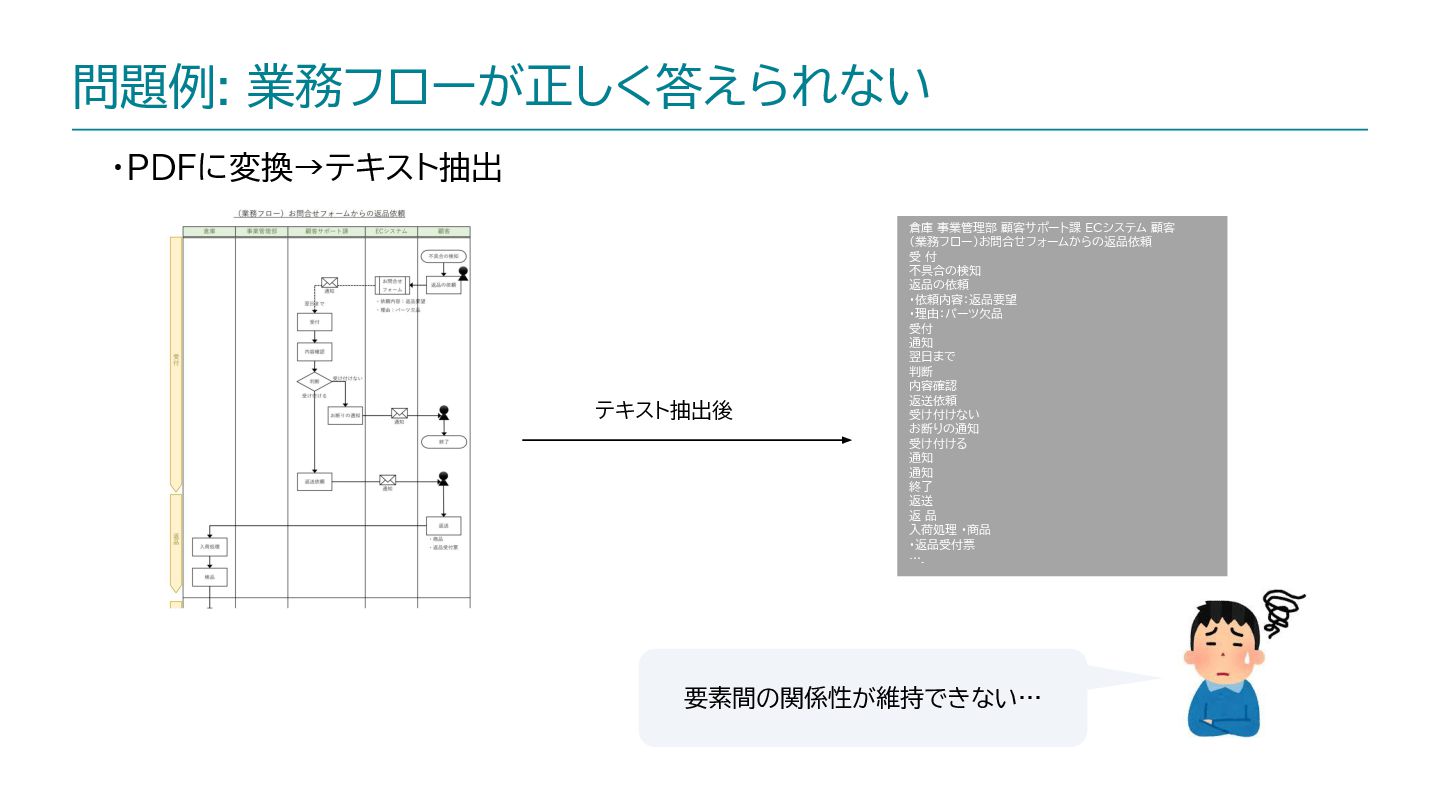{kind=link}
{kind=link}
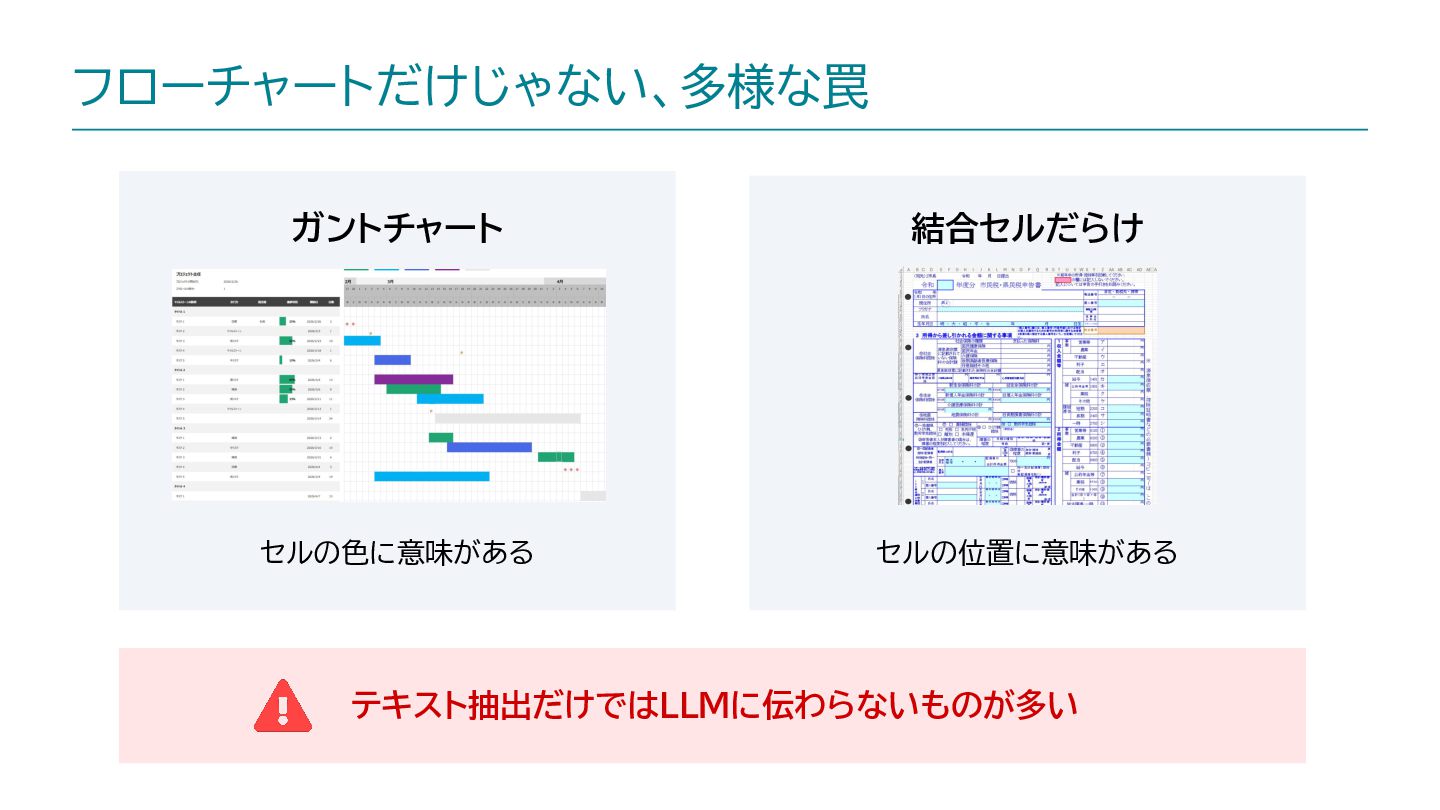{kind=link}
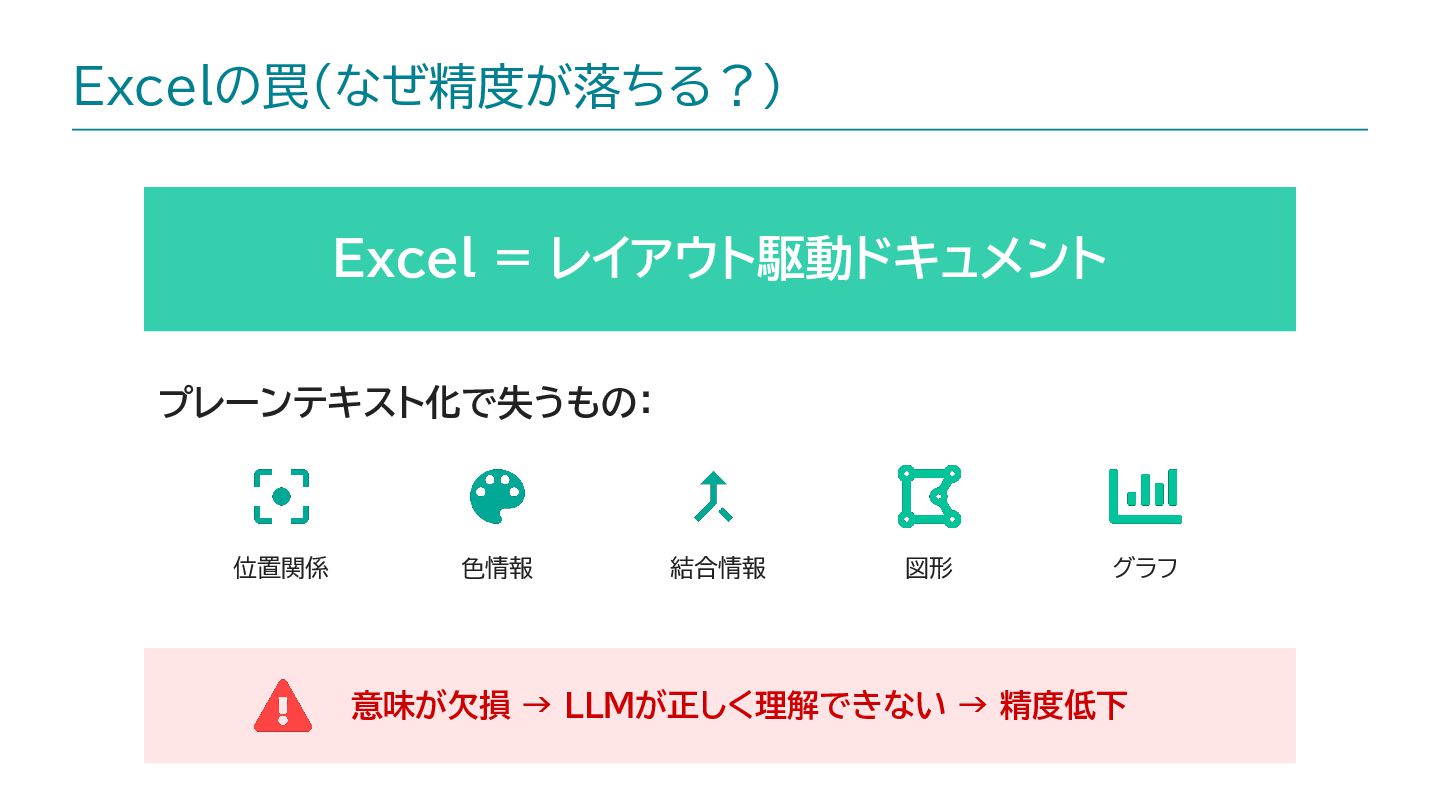{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}