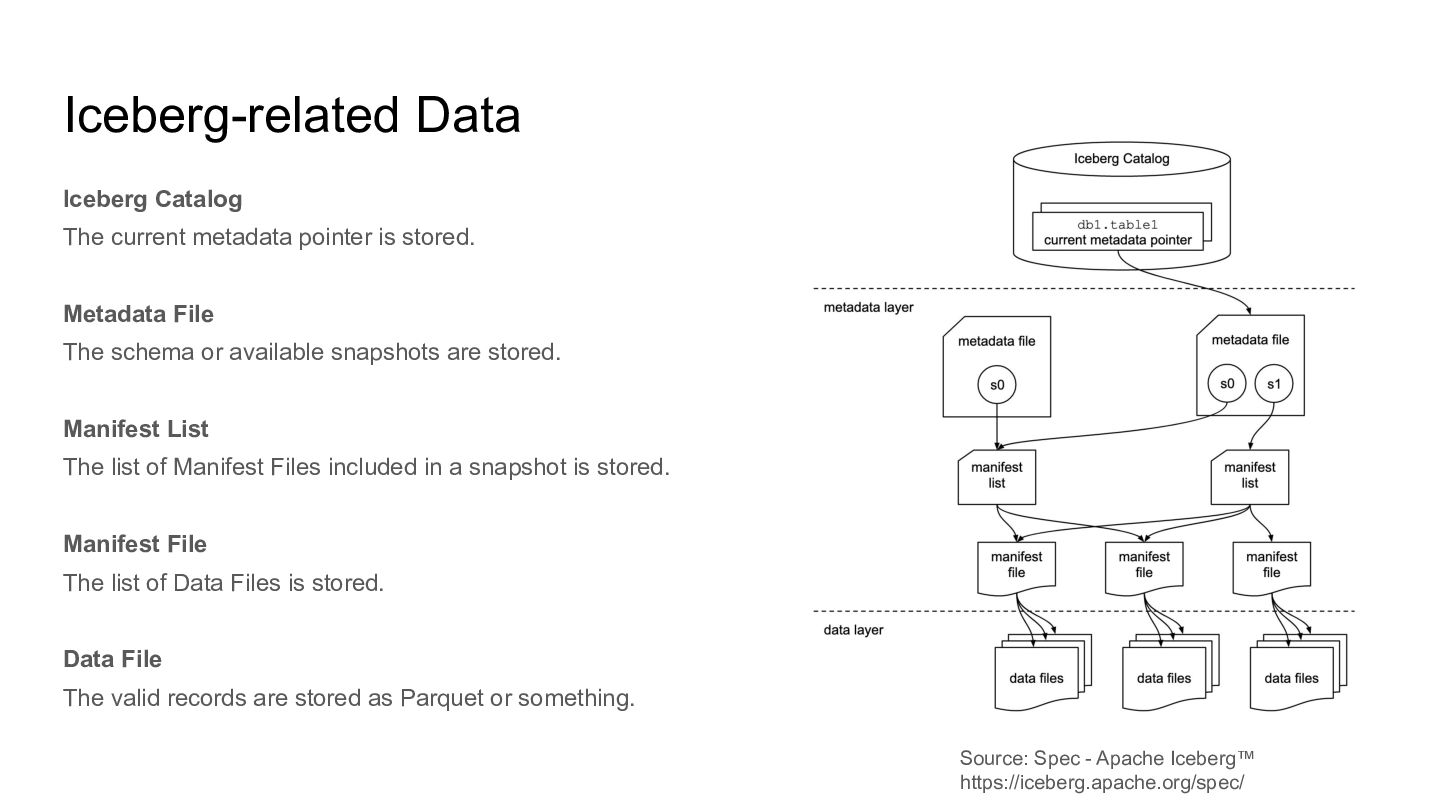
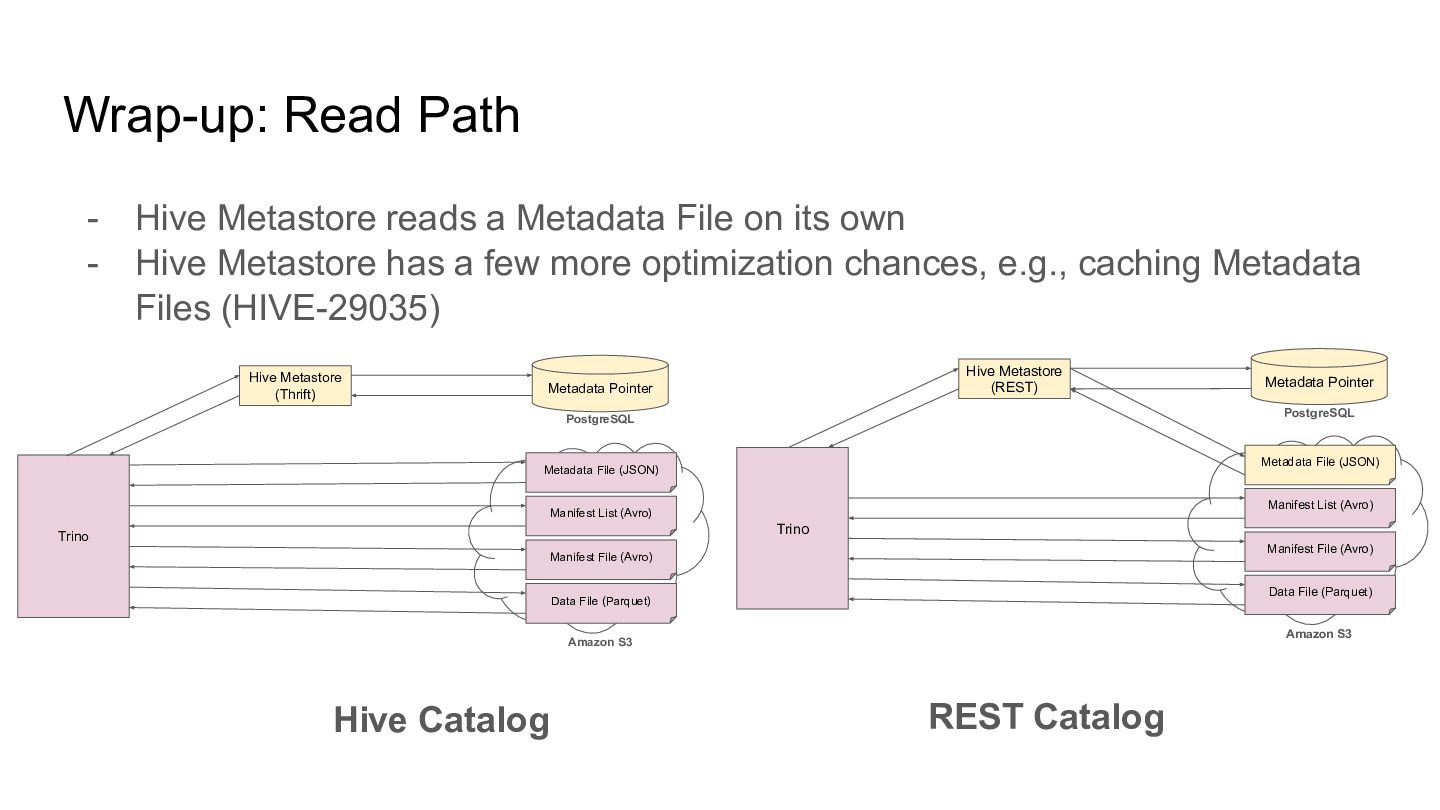
Metadata File The schema or available snapshots are stored. Manifest List The list of Manifest Files included in a snapshot is stored. Manifest File The list of Data Files is stored. Data File The valid records are stored as Parquet or something. Source: Spec - Apache Iceberg™ https://iceberg.apache.org/spec/
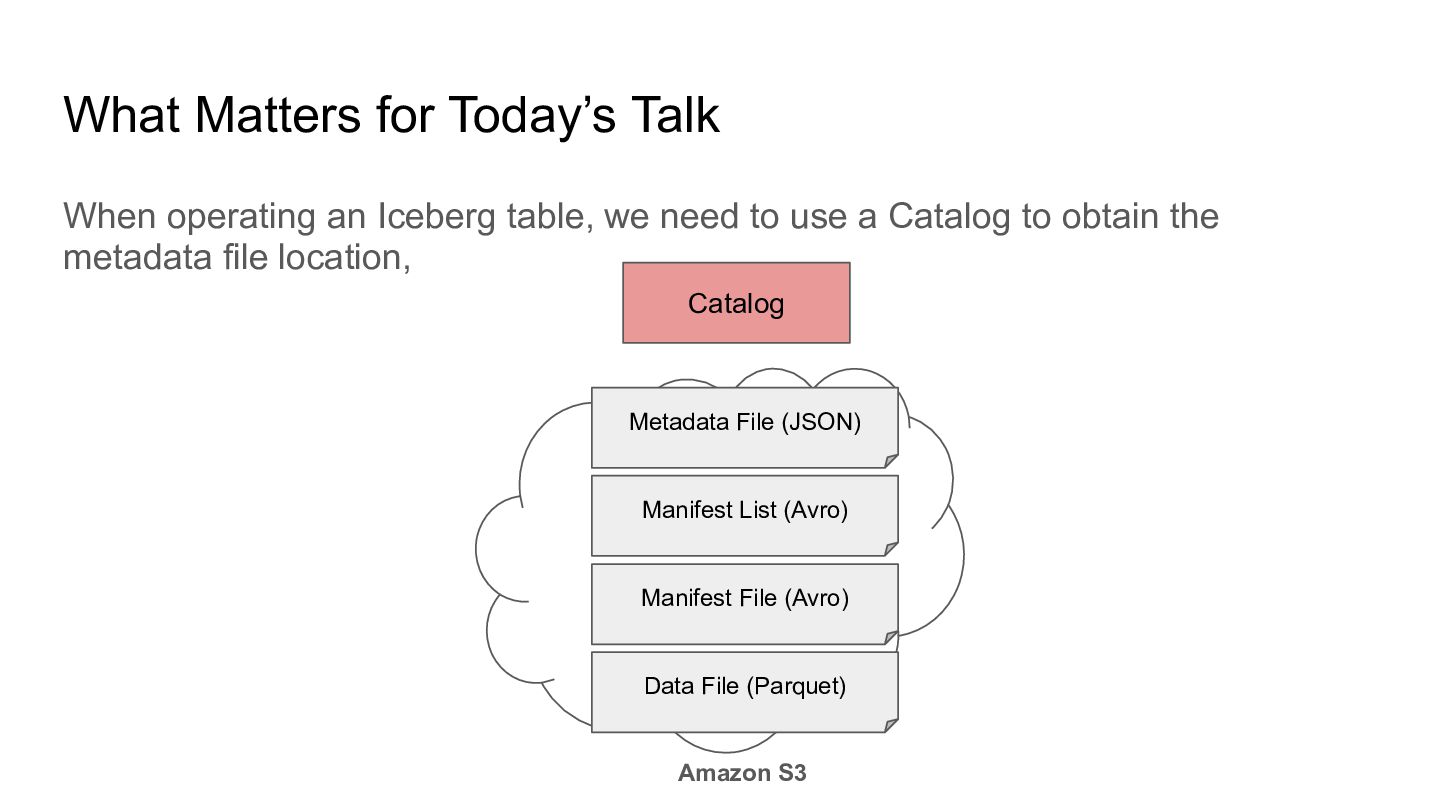
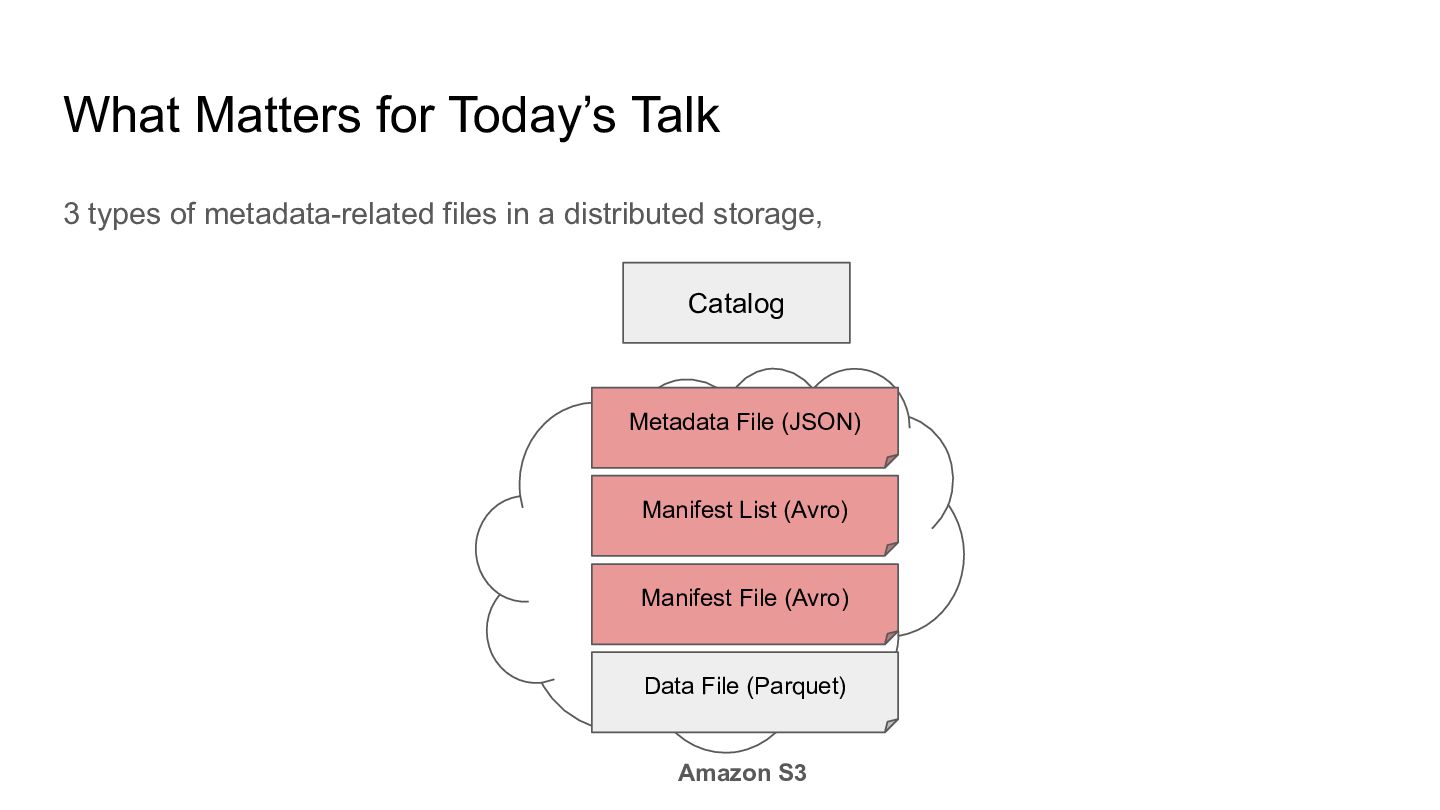
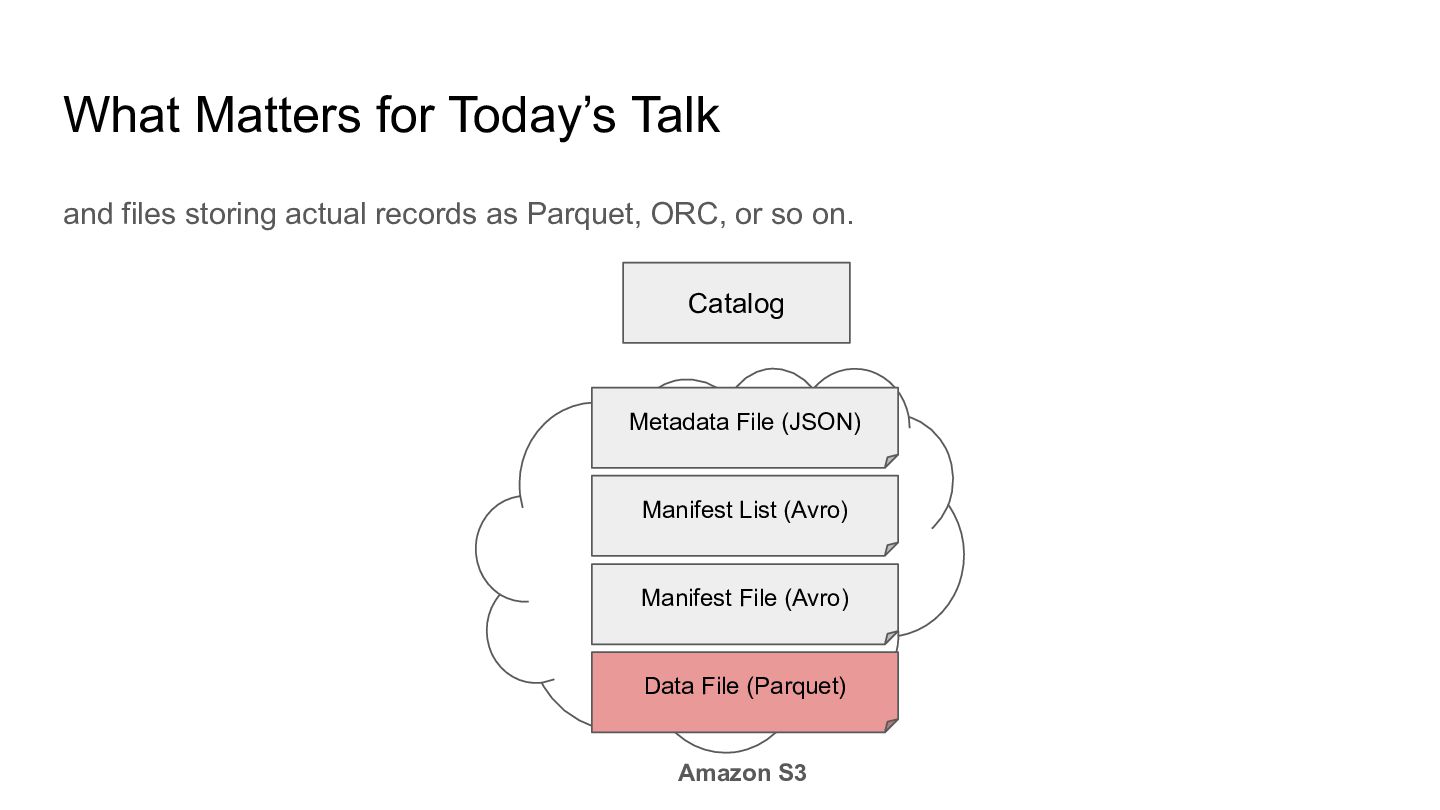
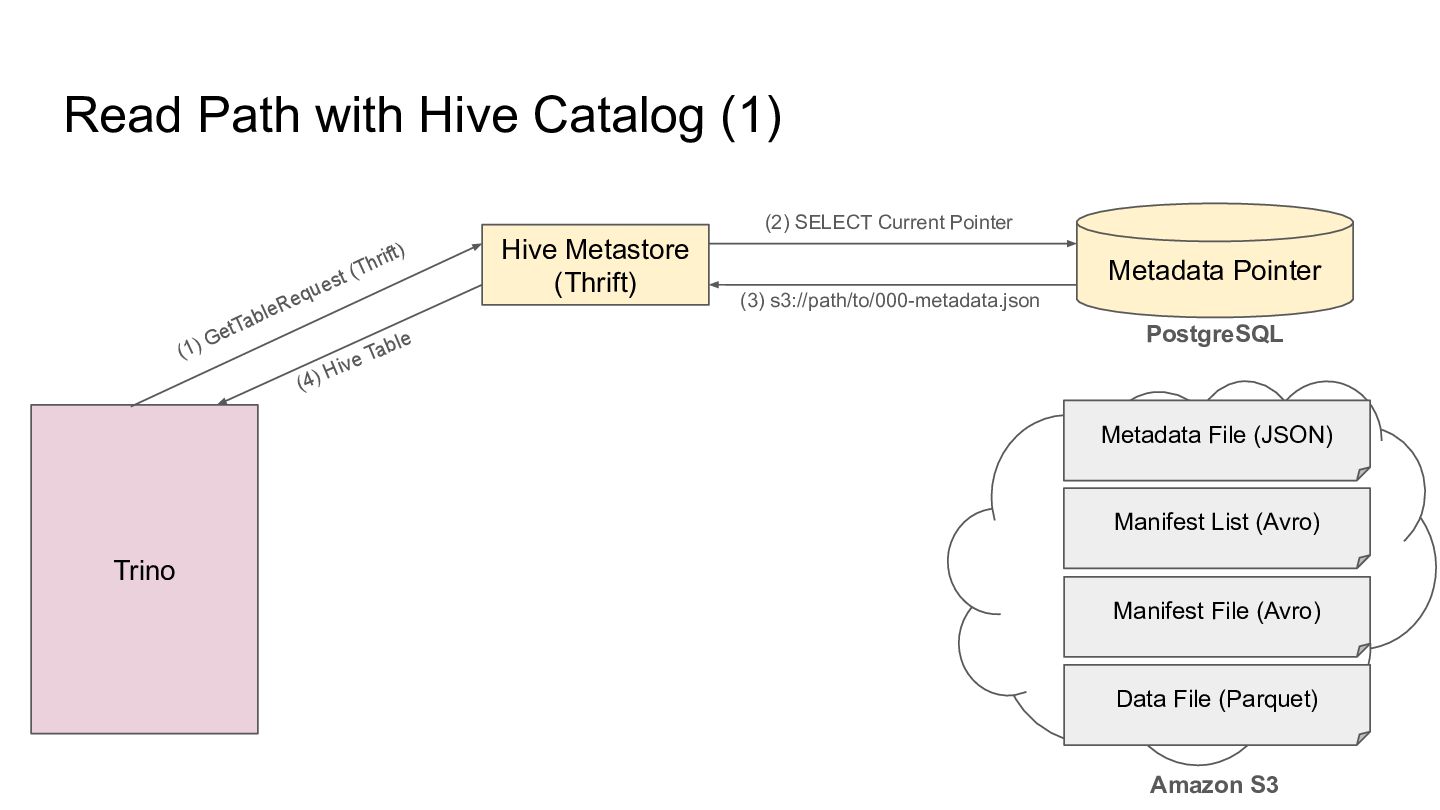
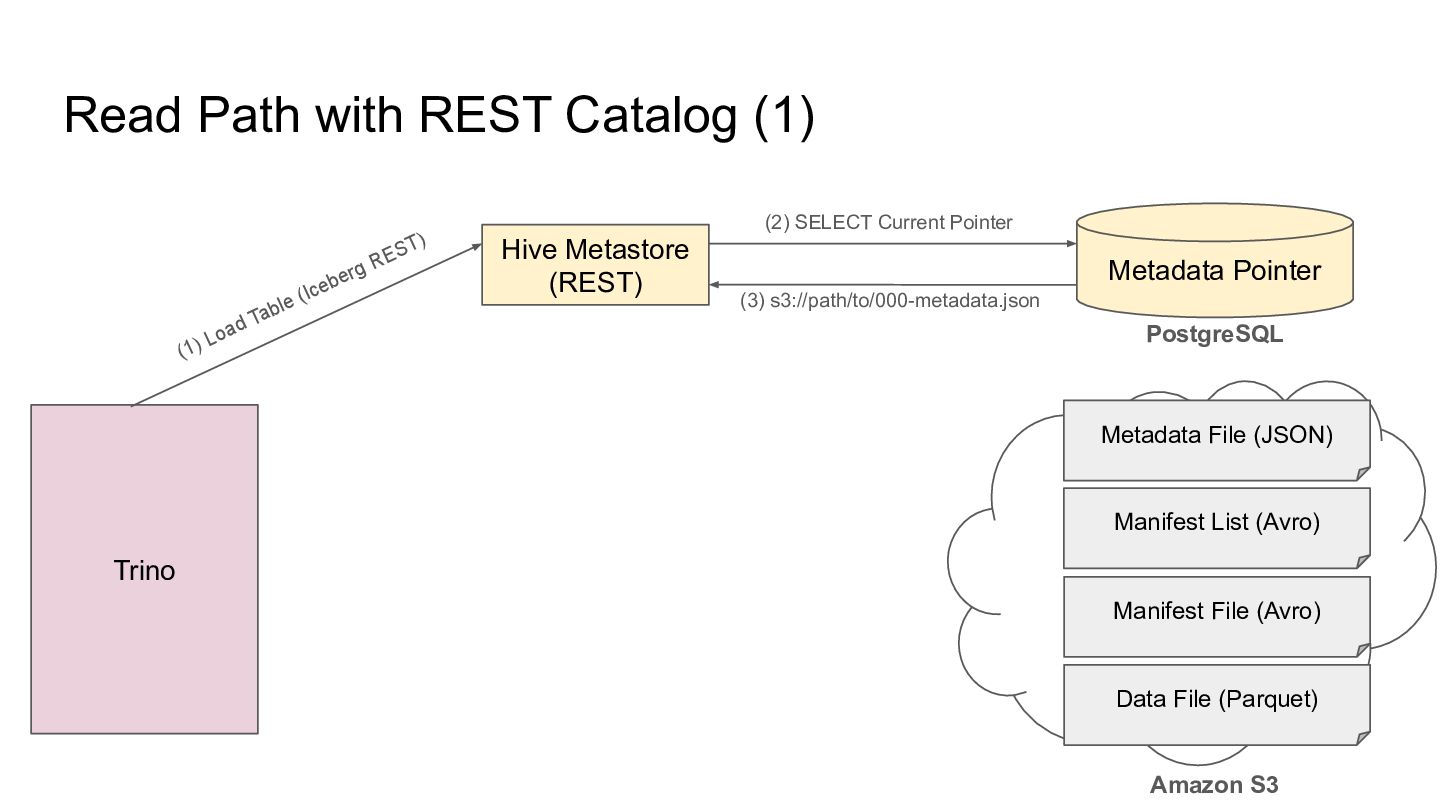
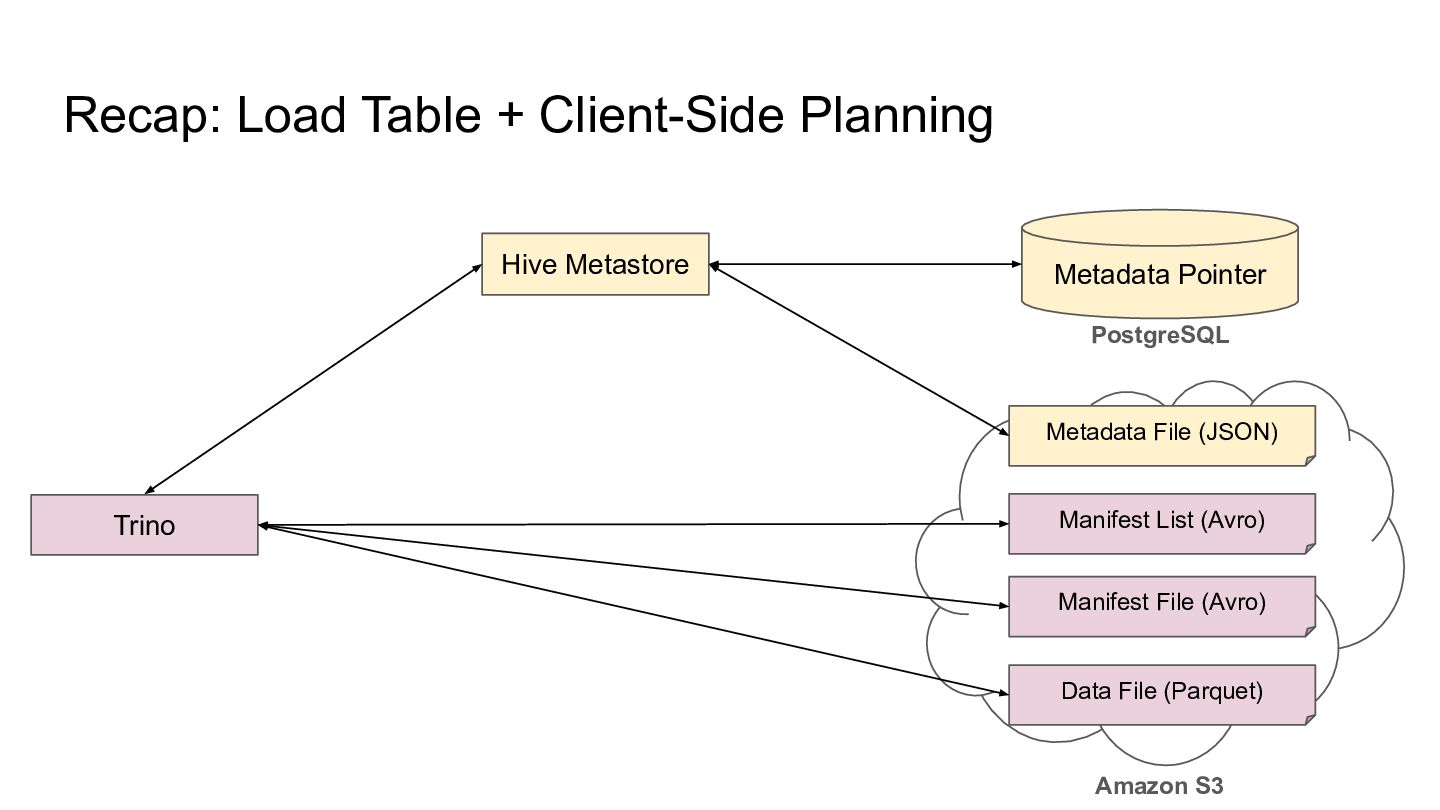
we need to use a Catalog to obtain the metadata file location, Catalog Metadata File (JSON) Amazon S3 Manifest List (Avro) Manifest File (Avro) Data File (Parquet)
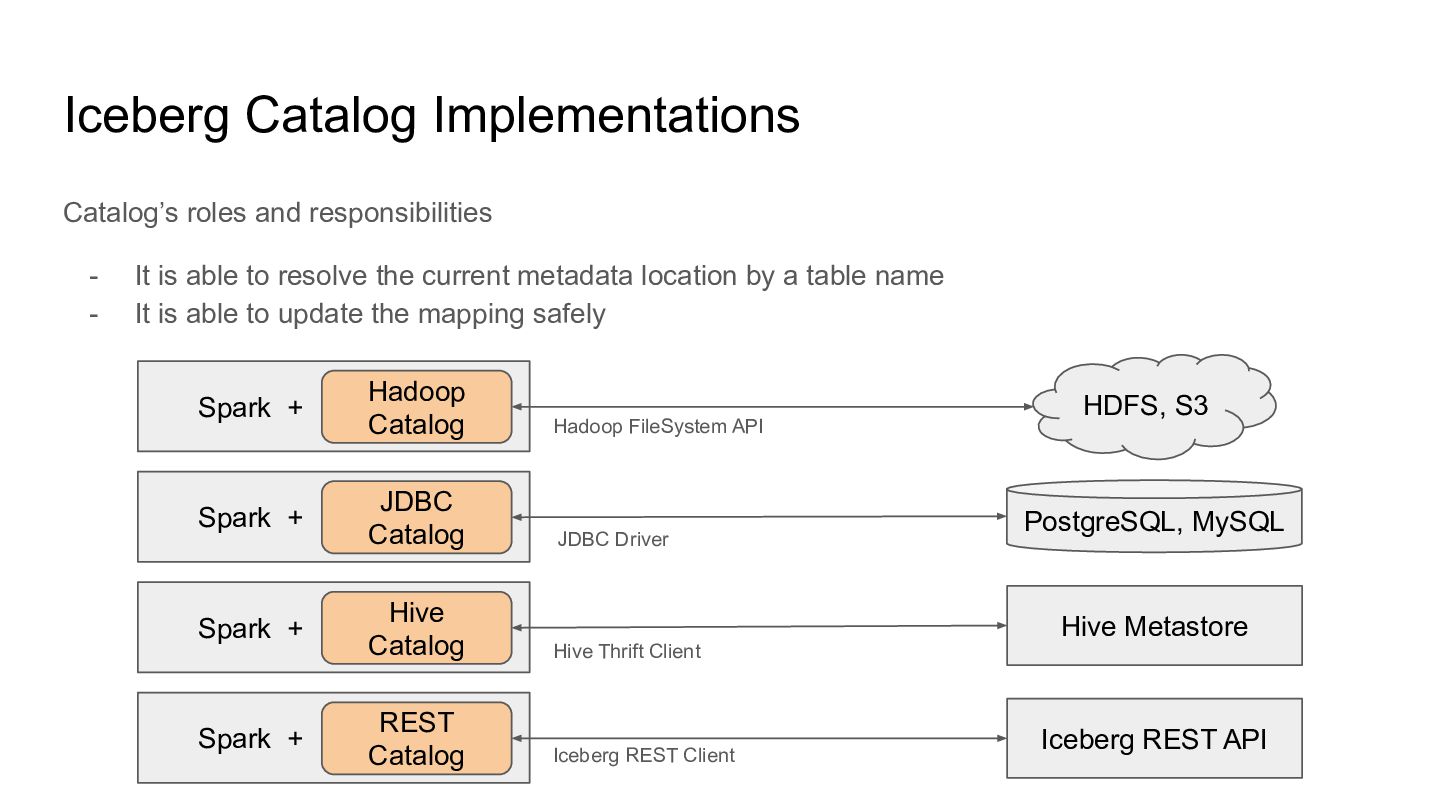
able to resolve the current metadata location by a table name - It is able to update the mapping safely Spark + Hadoop Catalog Spark + JDBC Catalog Spark + Hive Catalog Spark + REST Catalog HDFS, S3 PostgreSQL, MySQL Iceberg REST API Hive Metastore Hadoop FileSystem API JDBC Driver Hive Thrift Client Iceberg REST Client
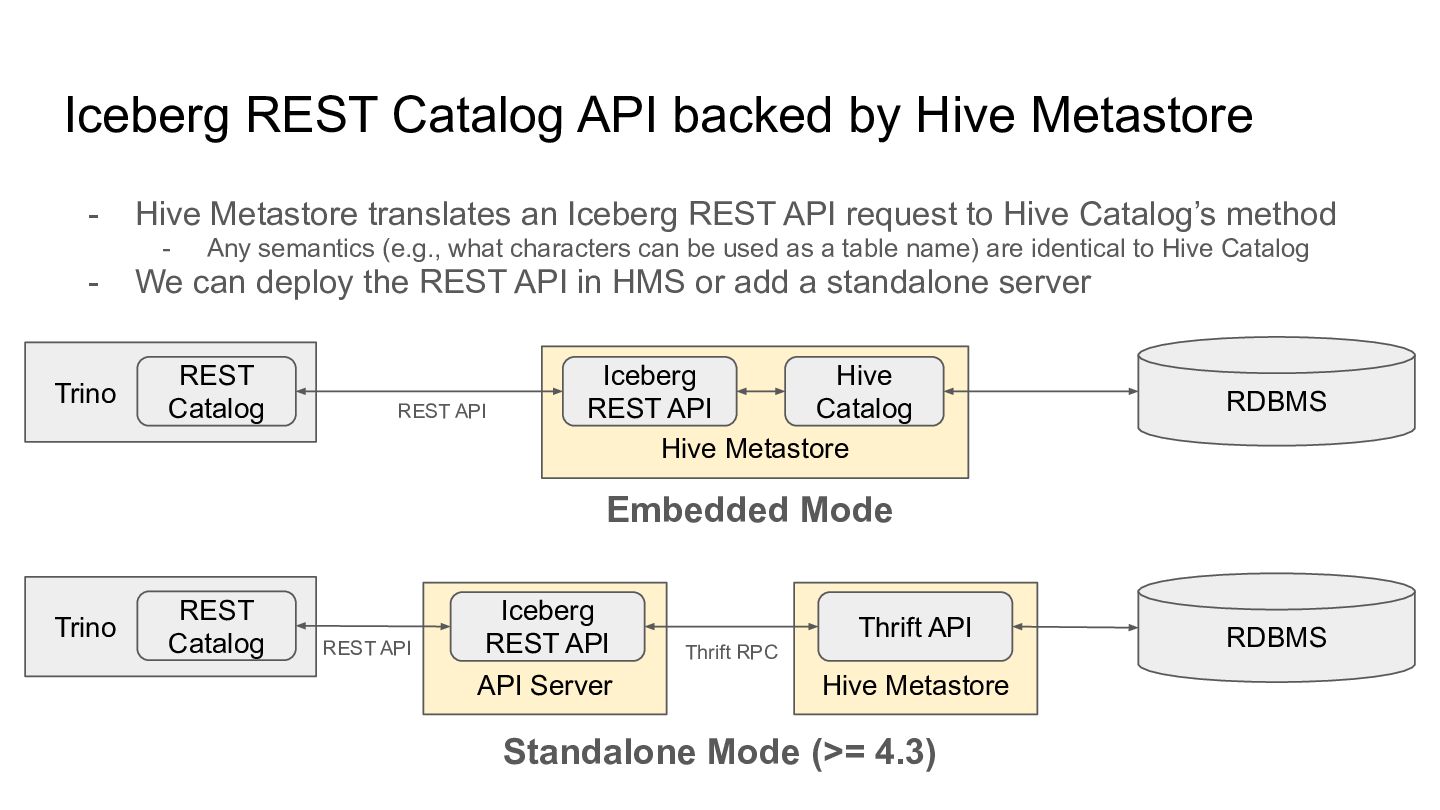
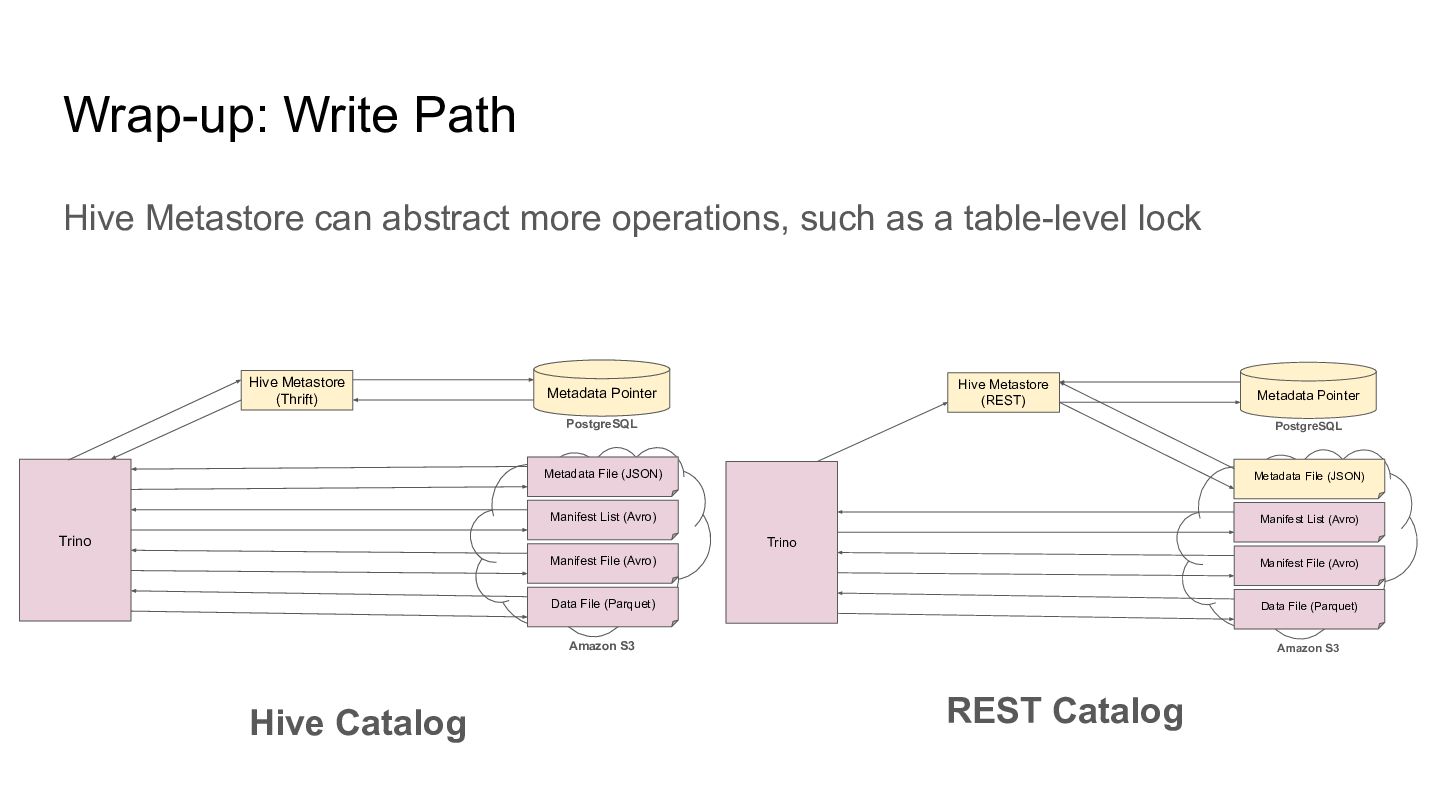
Metastore translates an Iceberg REST API request to Hive Catalog’s method - Any semantics (e.g., what characters can be used as a table name) are identical to Hive Catalog - We can deploy the REST API in HMS or add a standalone server Trino REST Catalog Hive Metastore Iceberg REST API Hive Catalog API Server Iceberg REST API Hive Metastore Thrift API Trino REST Catalog REST API RDBMS RDBMS Thrift RPC REST API Embedded Mode Standalone Mode (>= 4.3)
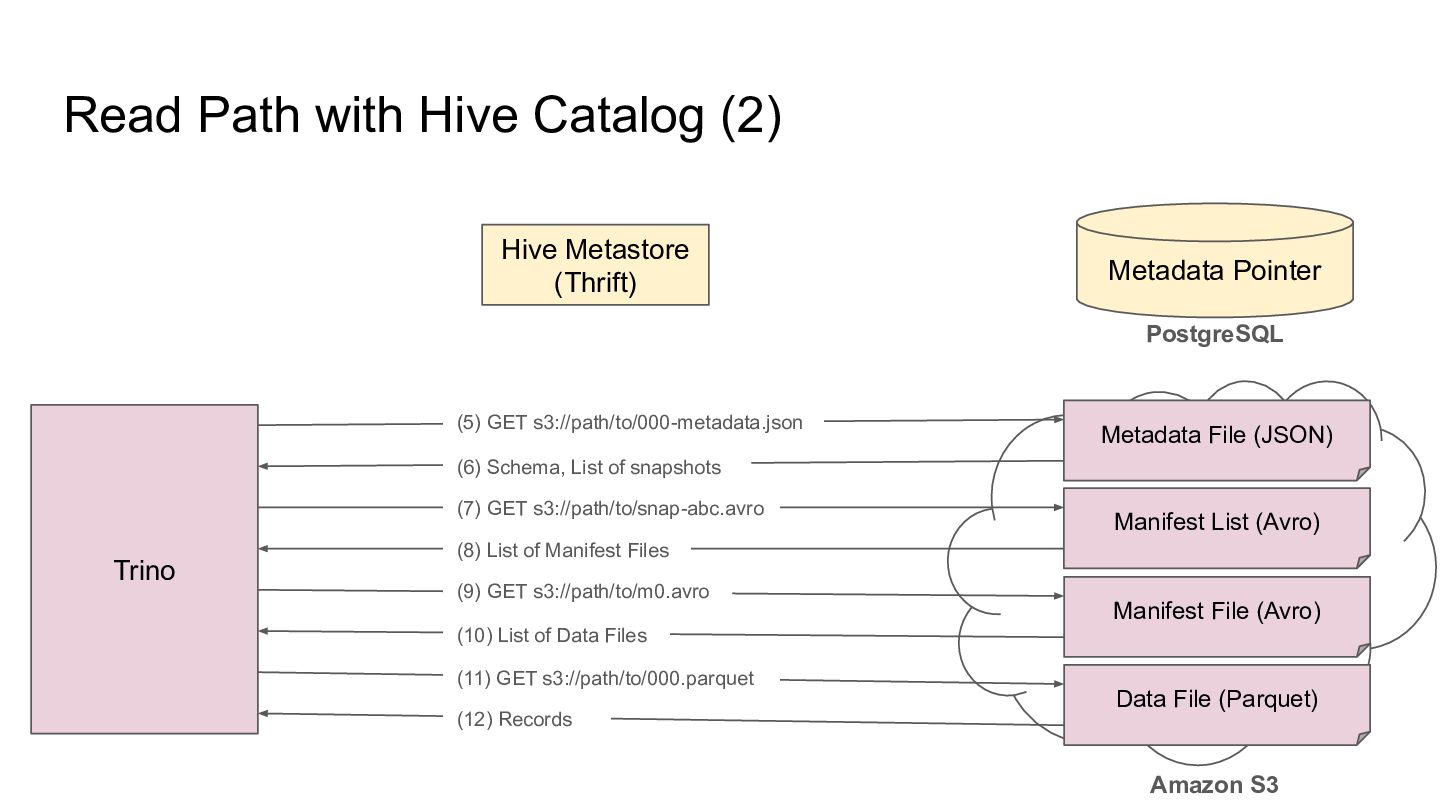
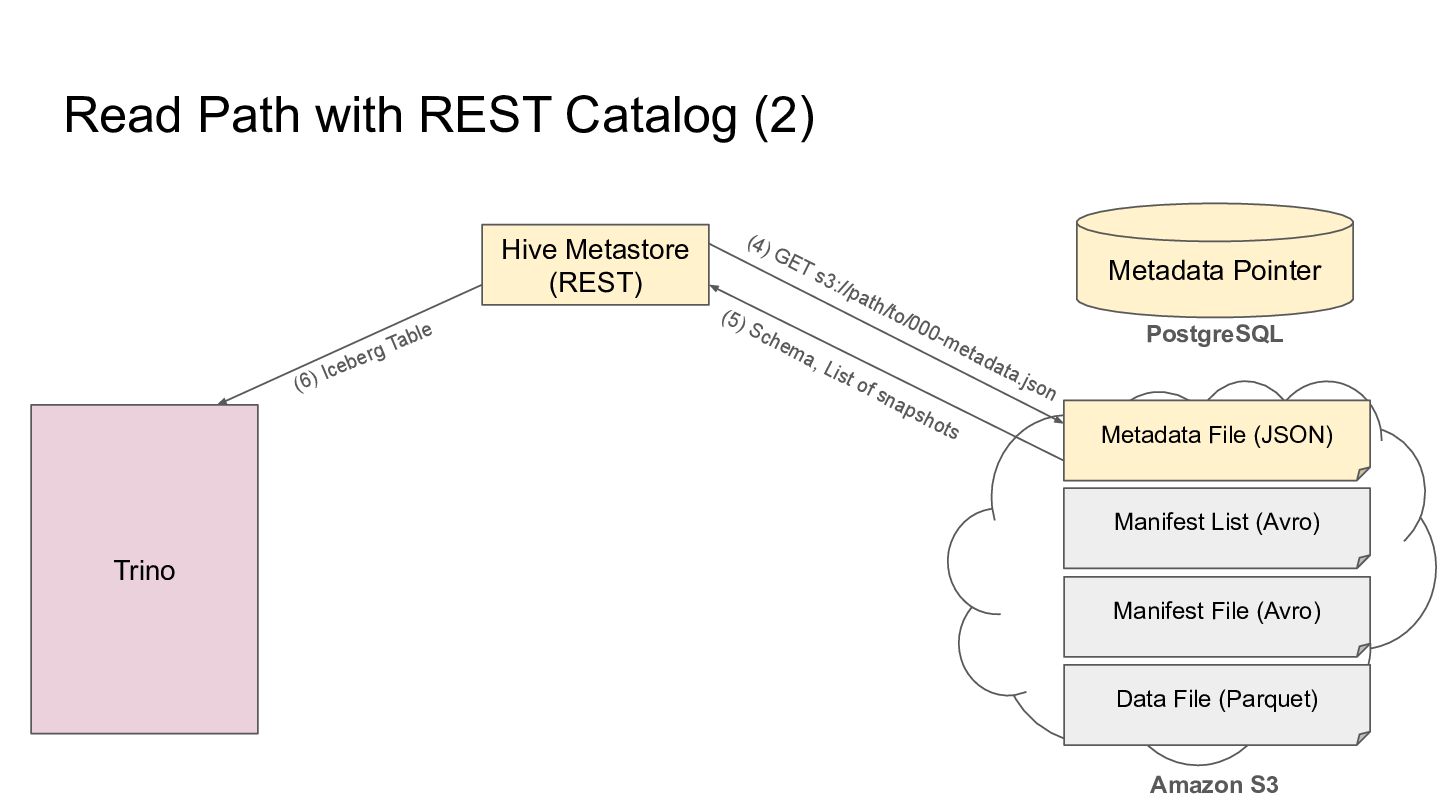
Pointer Metadata File (JSON) PostgreSQL Amazon S3 Trino Manifest List (Avro) Manifest File (Avro) Data File (Parquet) (5) GET s3://path/to/000-metadata.json (6) Schema, List of snapshots (7) GET s3://path/to/snap-abc.avro (8) List of Manifest Files (9) GET s3://path/to/m0.avro (10) List of Data Files (11) GET s3://path/to/000.parquet (12) Records
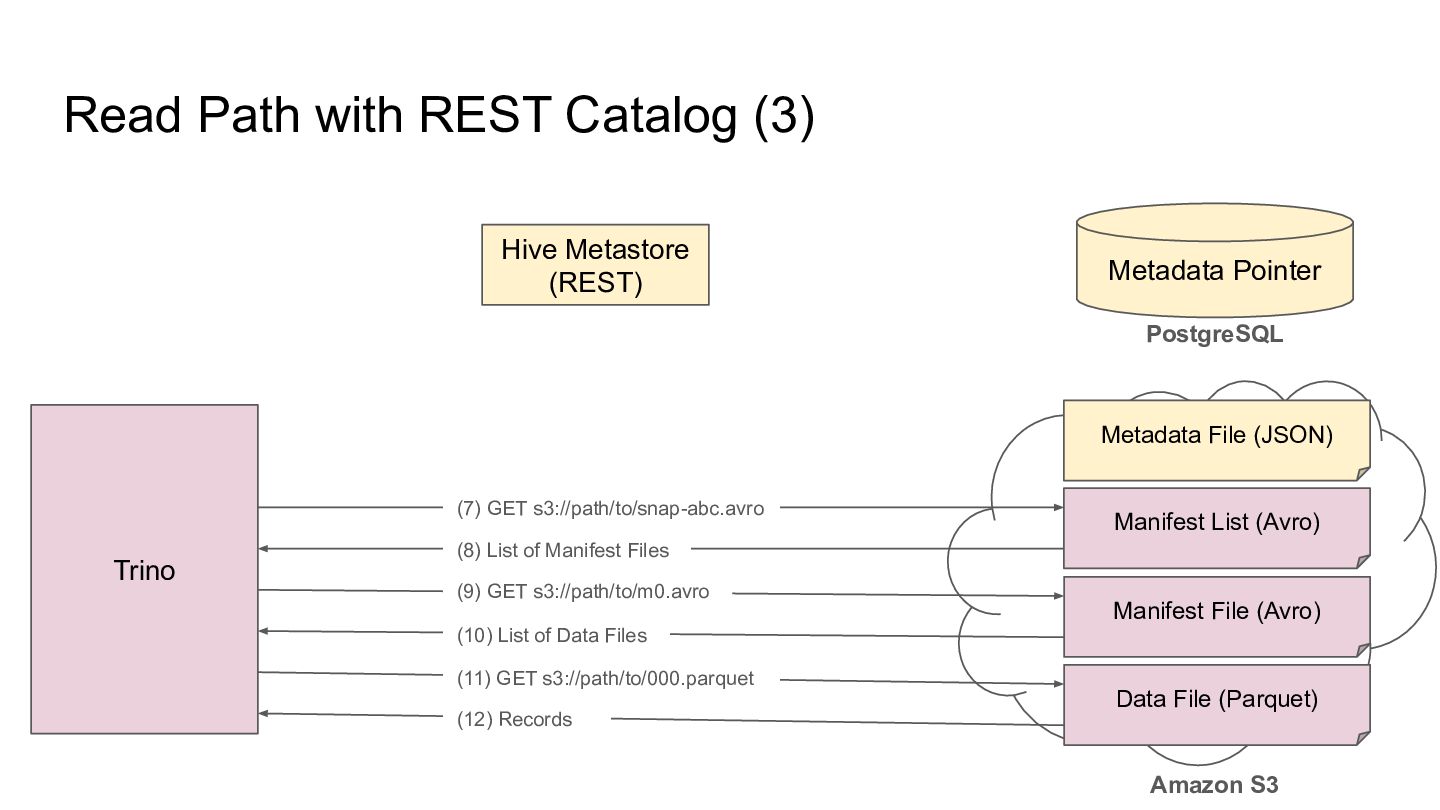
Pointer Metadata File (JSON) PostgreSQL Amazon S3 Trino Manifest List (Avro) Manifest File (Avro) Data File (Parquet) (7) GET s3://path/to/snap-abc.avro (8) List of Manifest Files (9) GET s3://path/to/m0.avro (10) List of Data Files (11) GET s3://path/to/000.parquet (12) Records
add a single row? Note: An Iceberg client makes a few of Load Table requests to know the current table status. In this slides, the part is omitted -- For simplicity SET SESSION <catalog>.merge_manifests_on_write = false; -- Query INSERT INTO test (name) VALUES ('Alice');
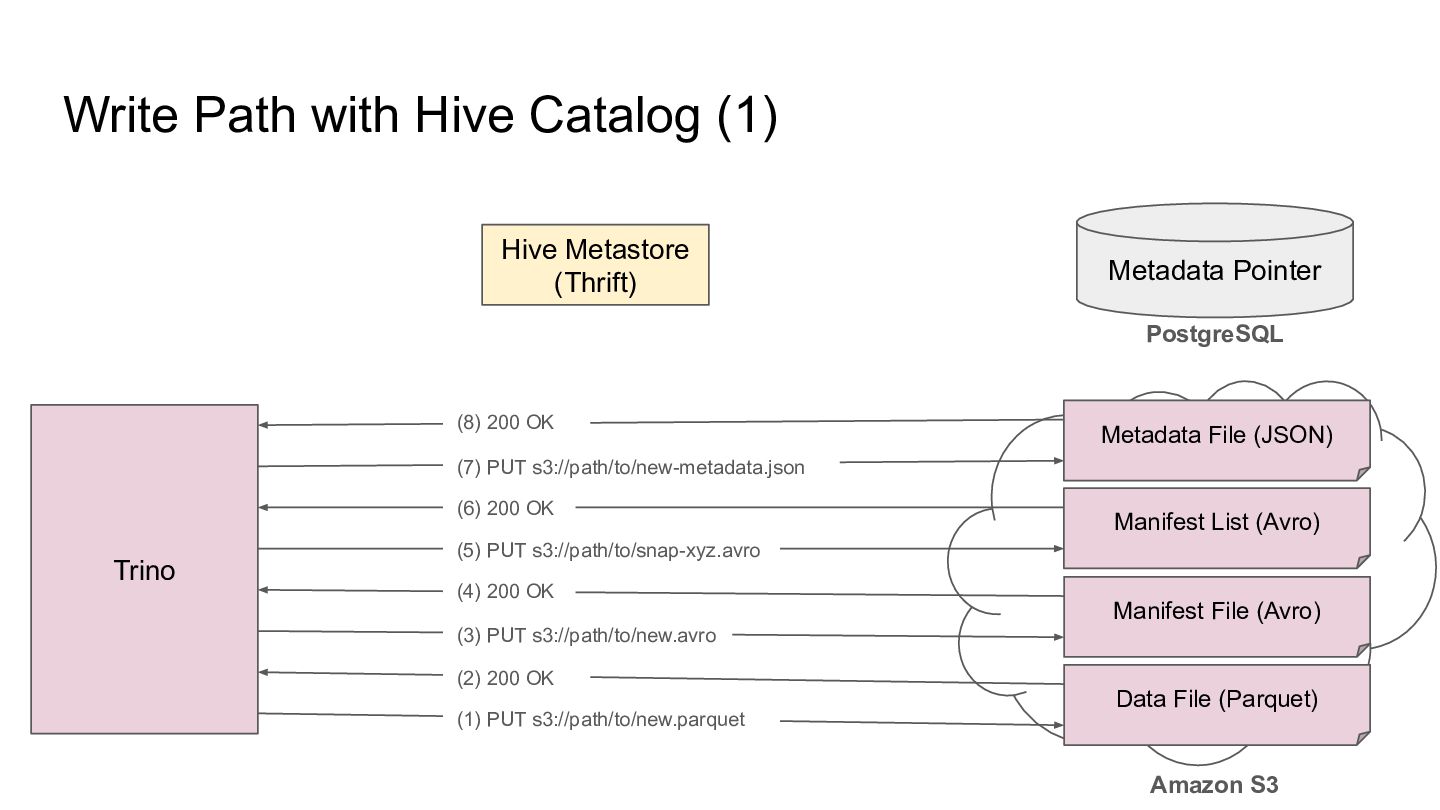
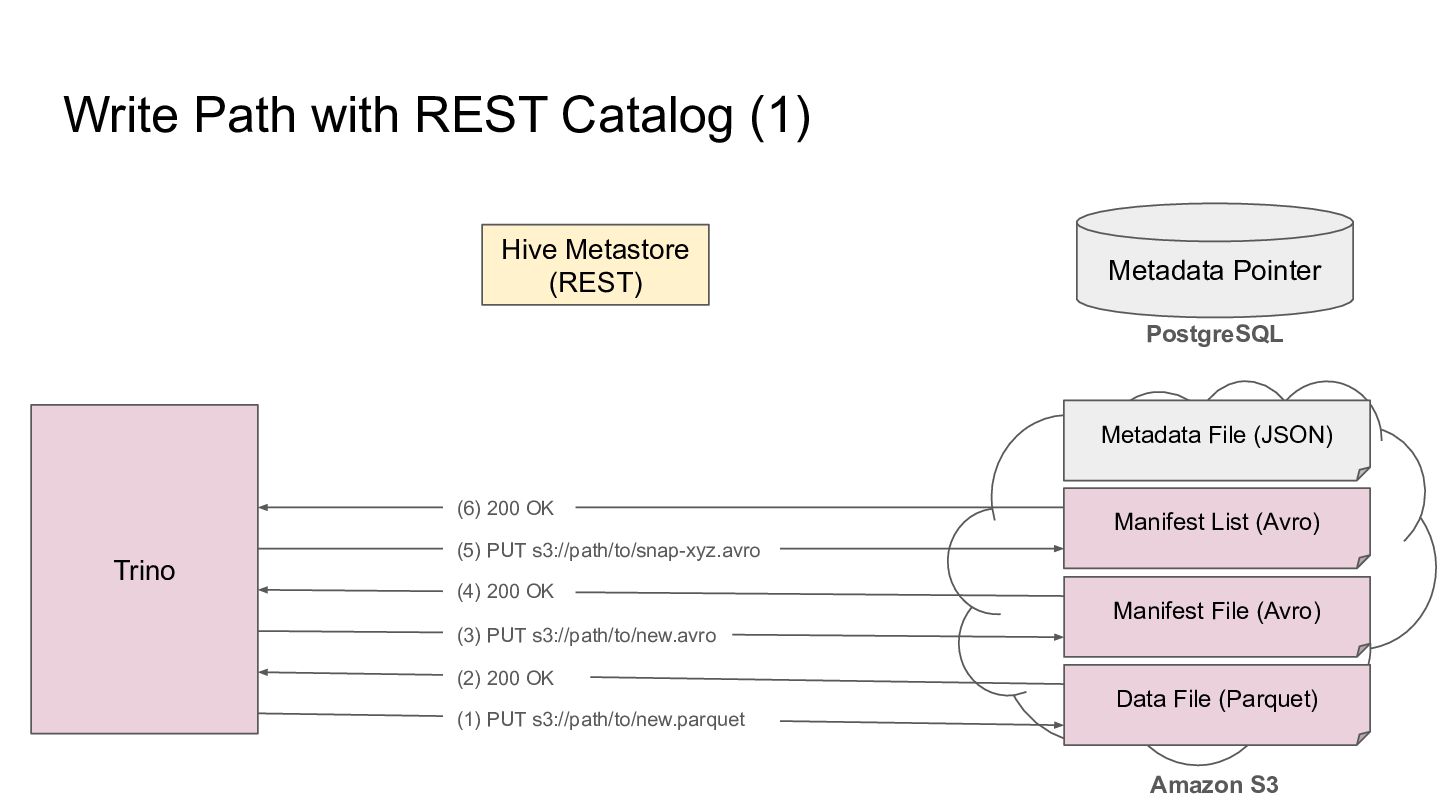
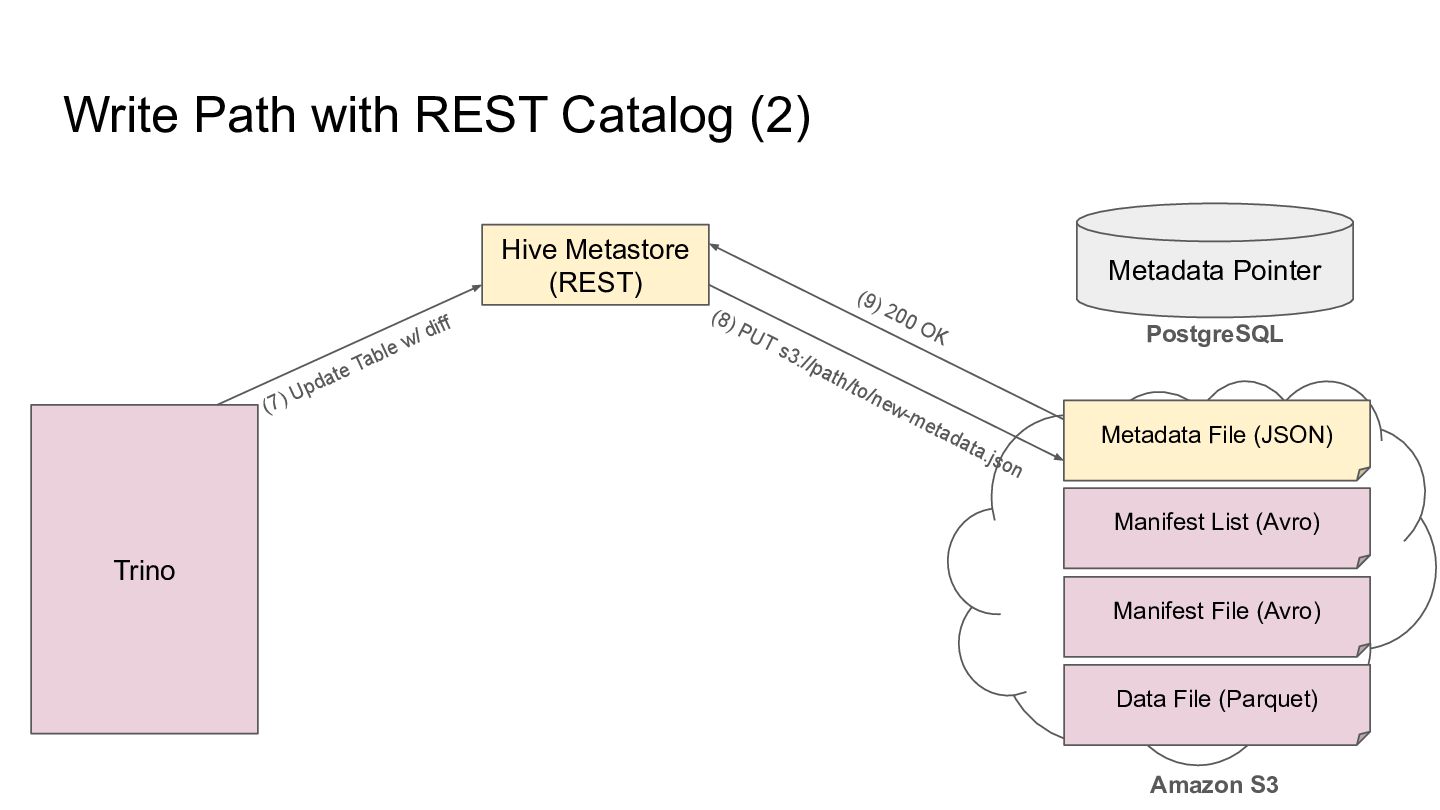
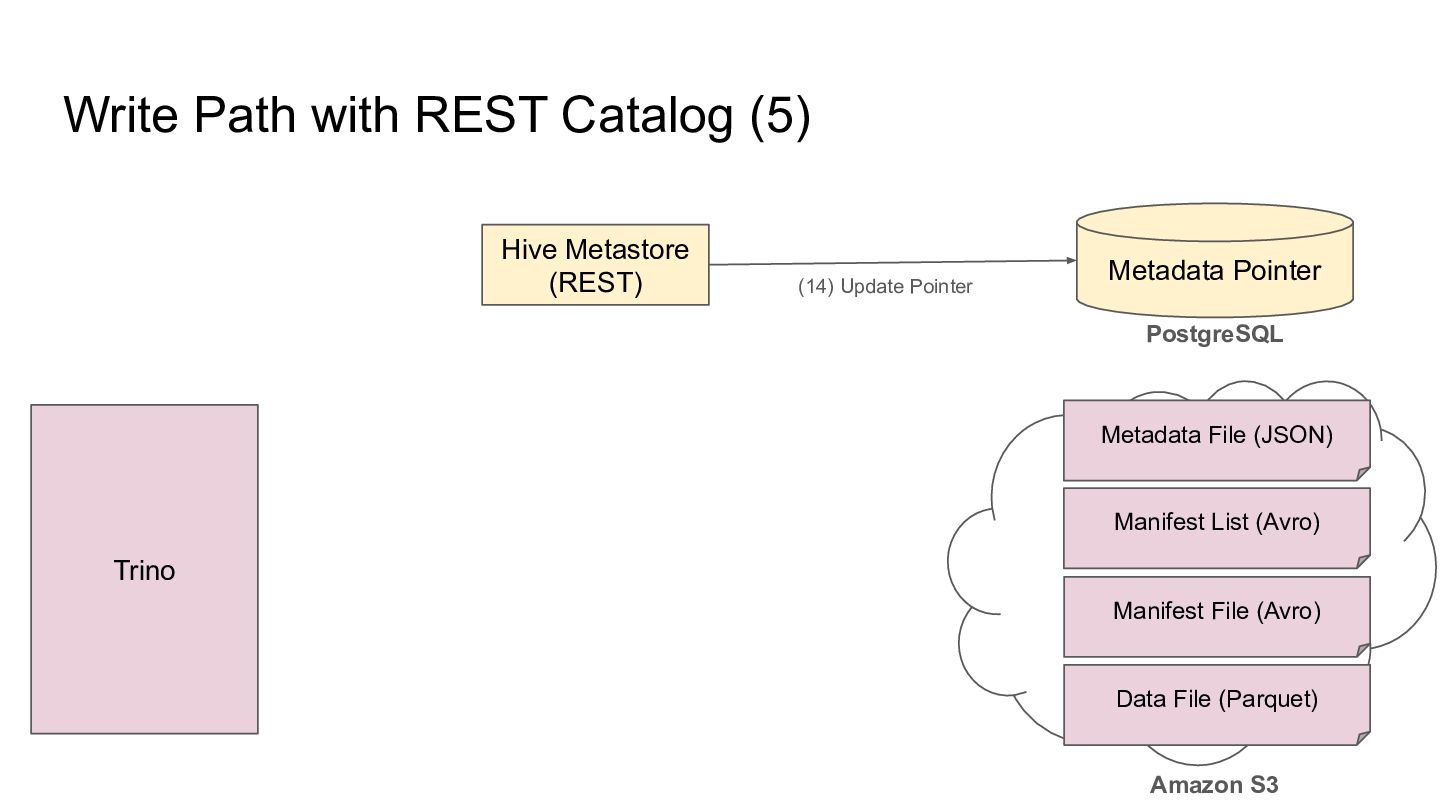
Pointer Metadata File (JSON) PostgreSQL Amazon S3 Trino Manifest List (Avro) Manifest File (Avro) Data File (Parquet) (8) 200 OK (7) PUT s3://path/to/new-metadata.json (6) 200 OK (5) PUT s3://path/to/snap-xyz.avro (4) 200 OK (3) PUT s3://path/to/new.avro (2) 200 OK (1) PUT s3://path/to/new.parquet
Pointer Metadata File (JSON) PostgreSQL Amazon S3 Trino Manifest List (Avro) Manifest File (Avro) Data File (Parquet) (6) 200 OK (5) PUT s3://path/to/snap-xyz.avro (4) 200 OK (3) PUT s3://path/to/new.avro (2) 200 OK (1) PUT s3://path/to/new.parquet
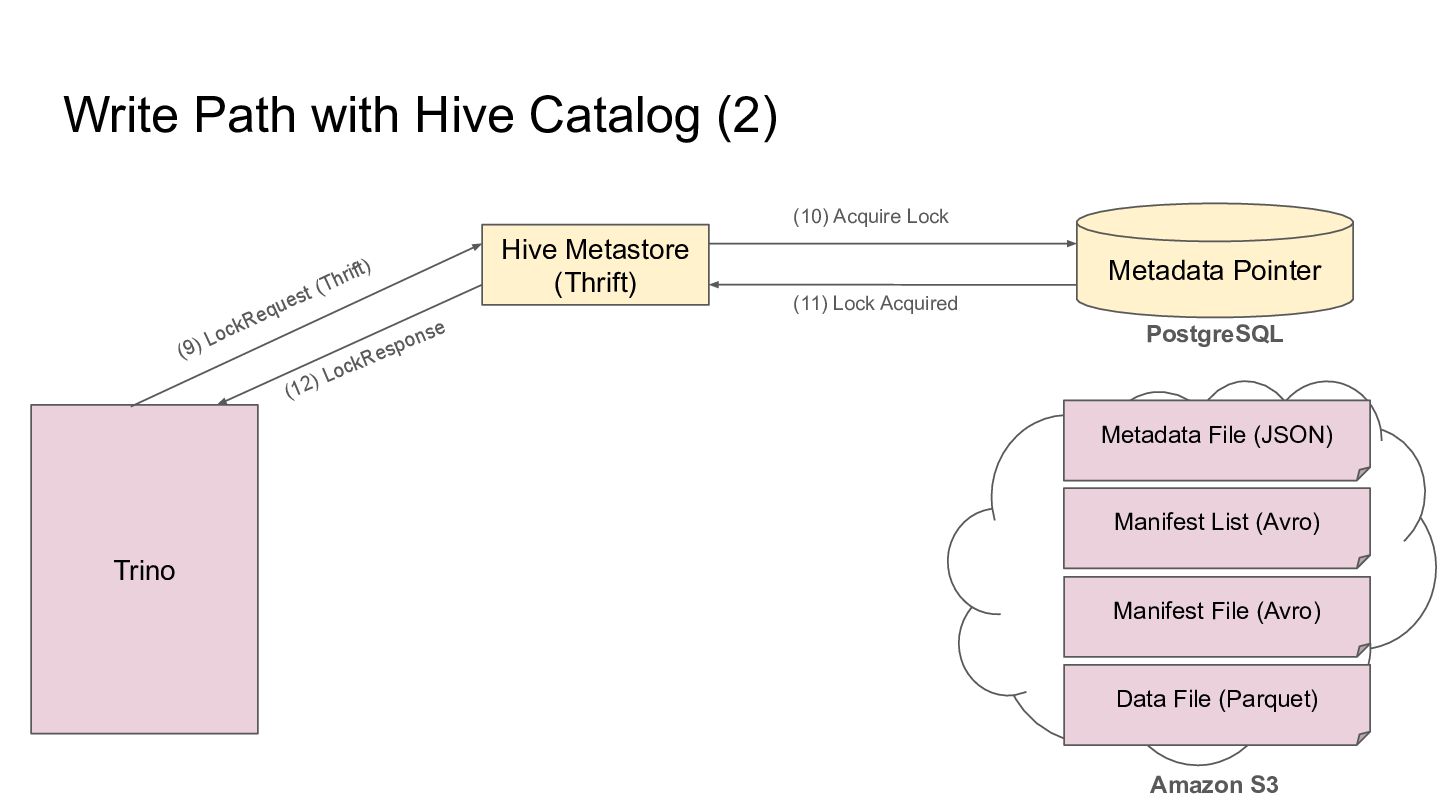
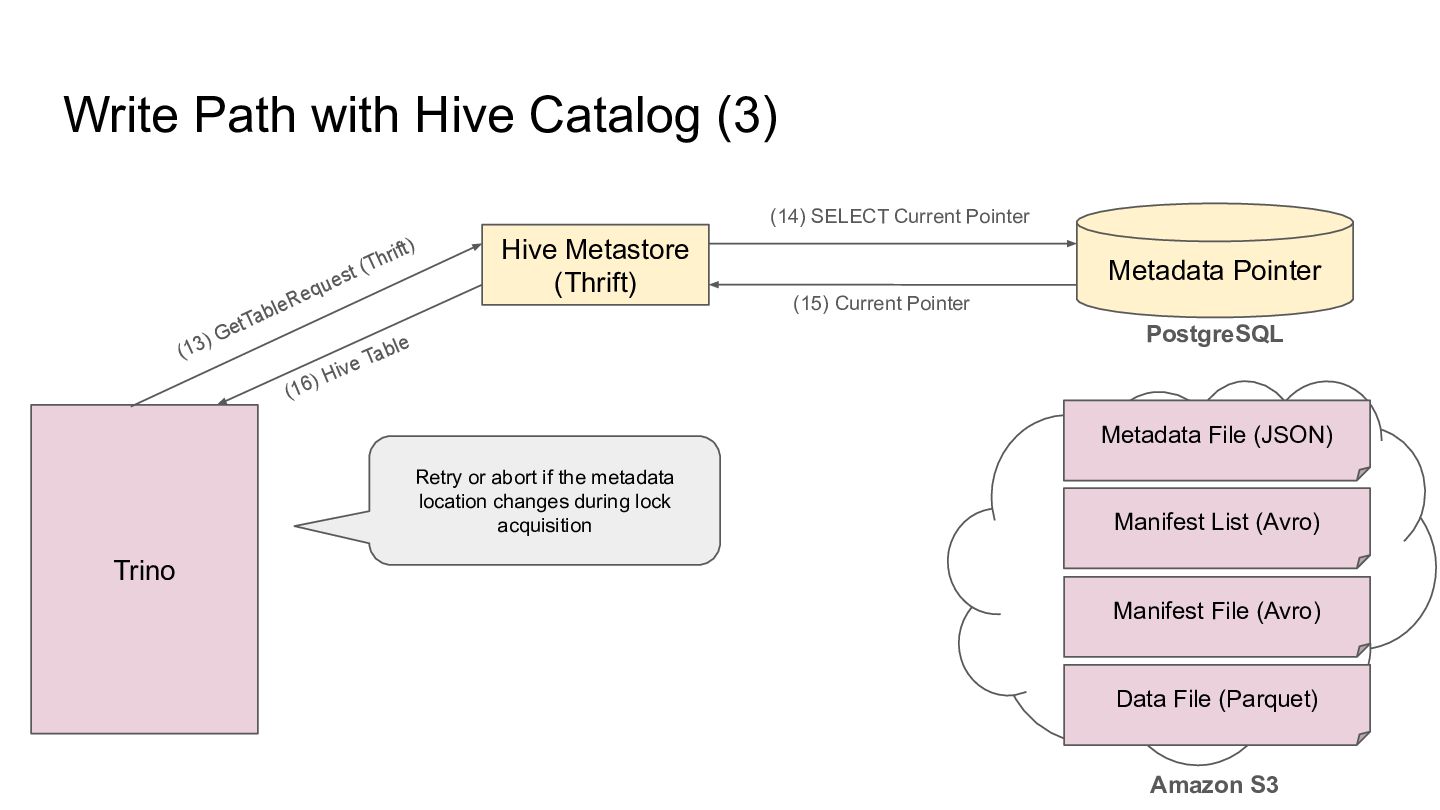
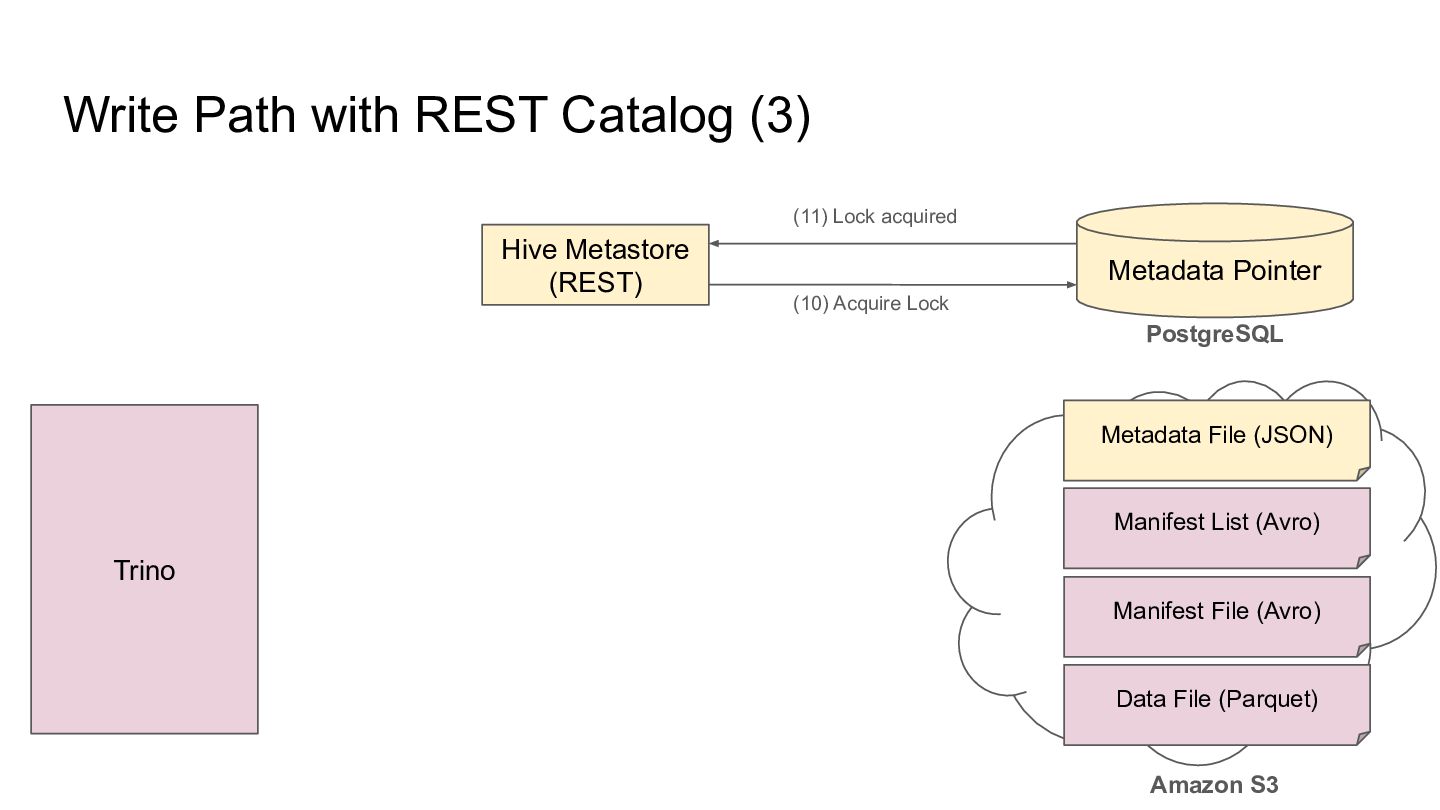
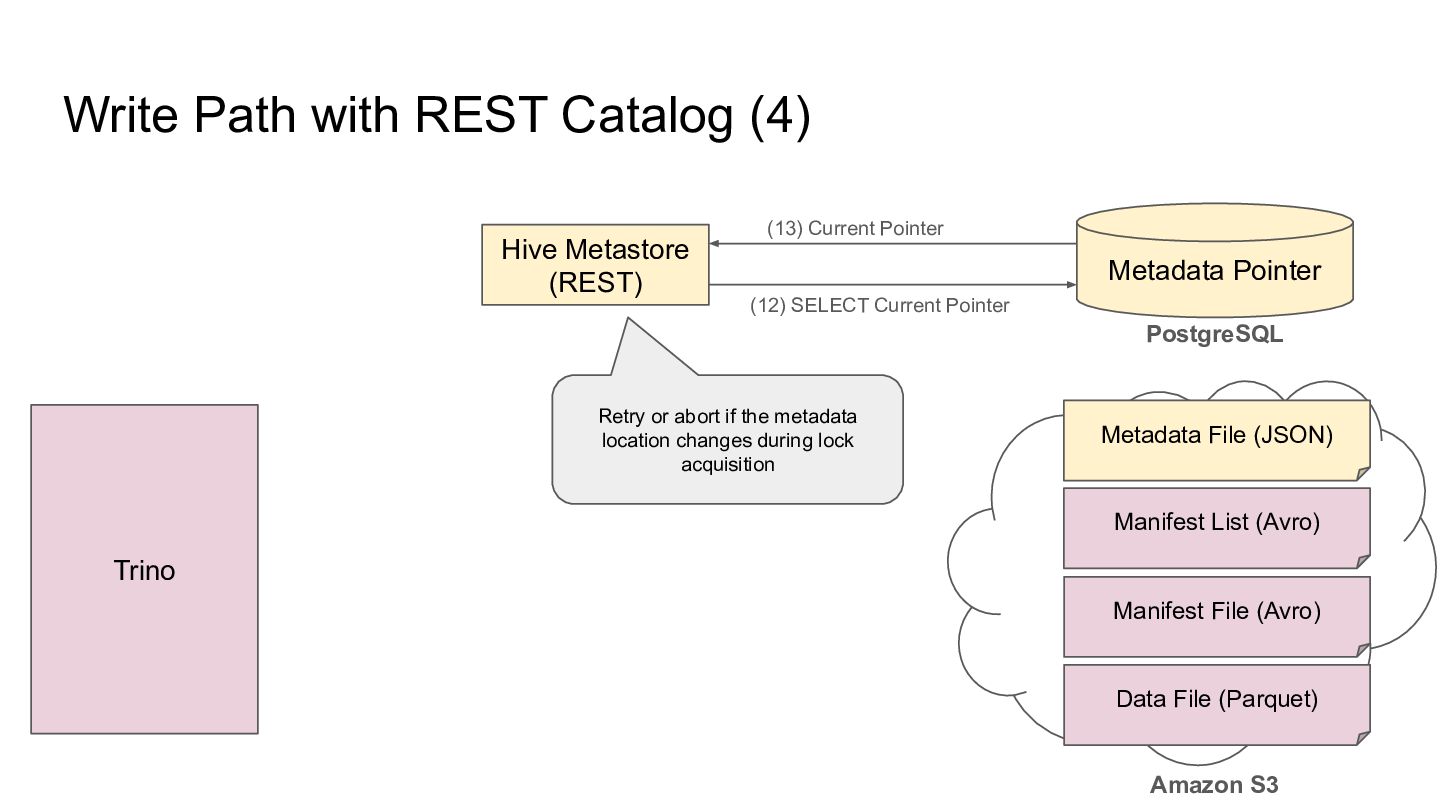
Pointer Metadata File (JSON) PostgreSQL Amazon S3 Trino Manifest List (Avro) Manifest File (Avro) Data File (Parquet) (13) Current Pointer (12) SELECT Current Pointer Retry or abort if the metadata location changes during lock acquisition
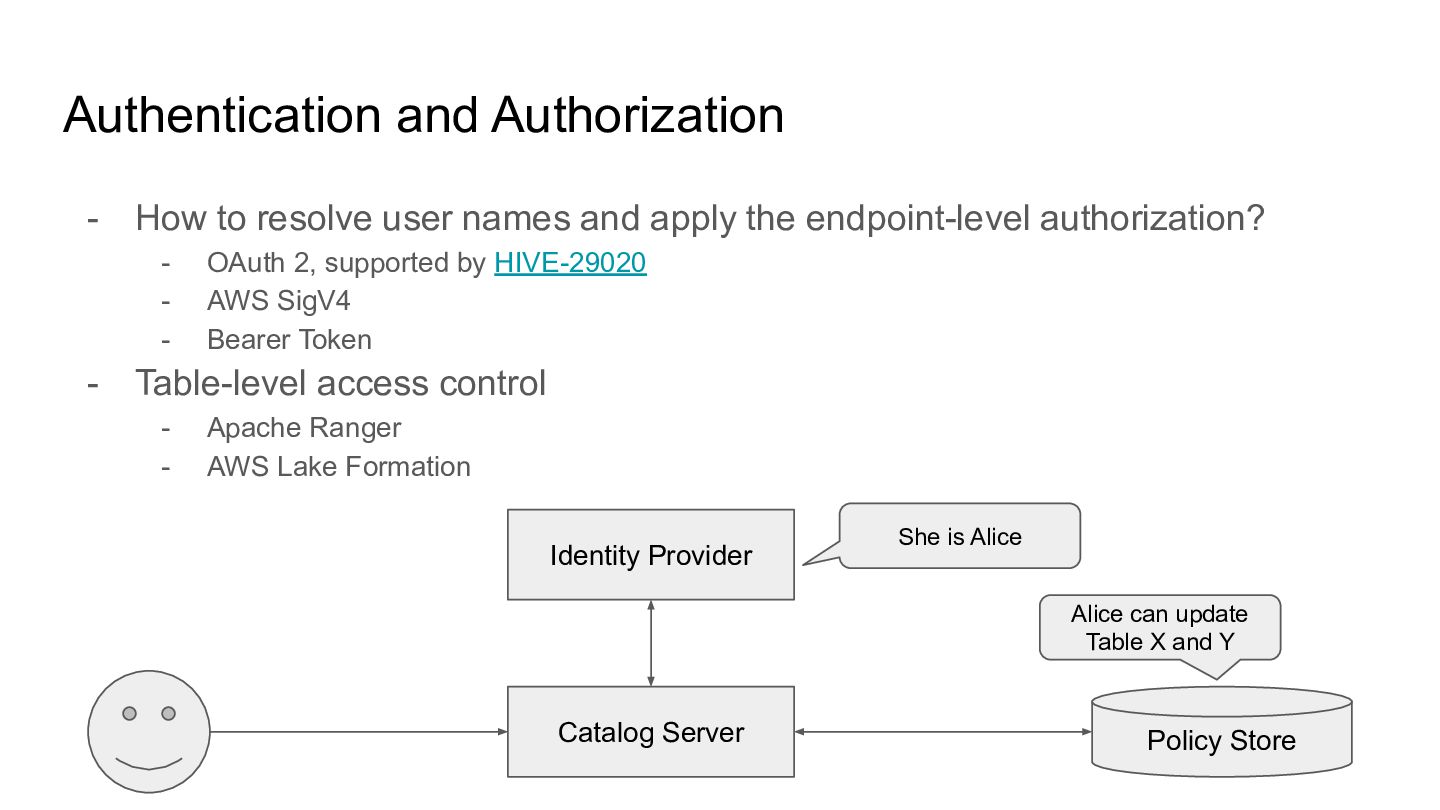
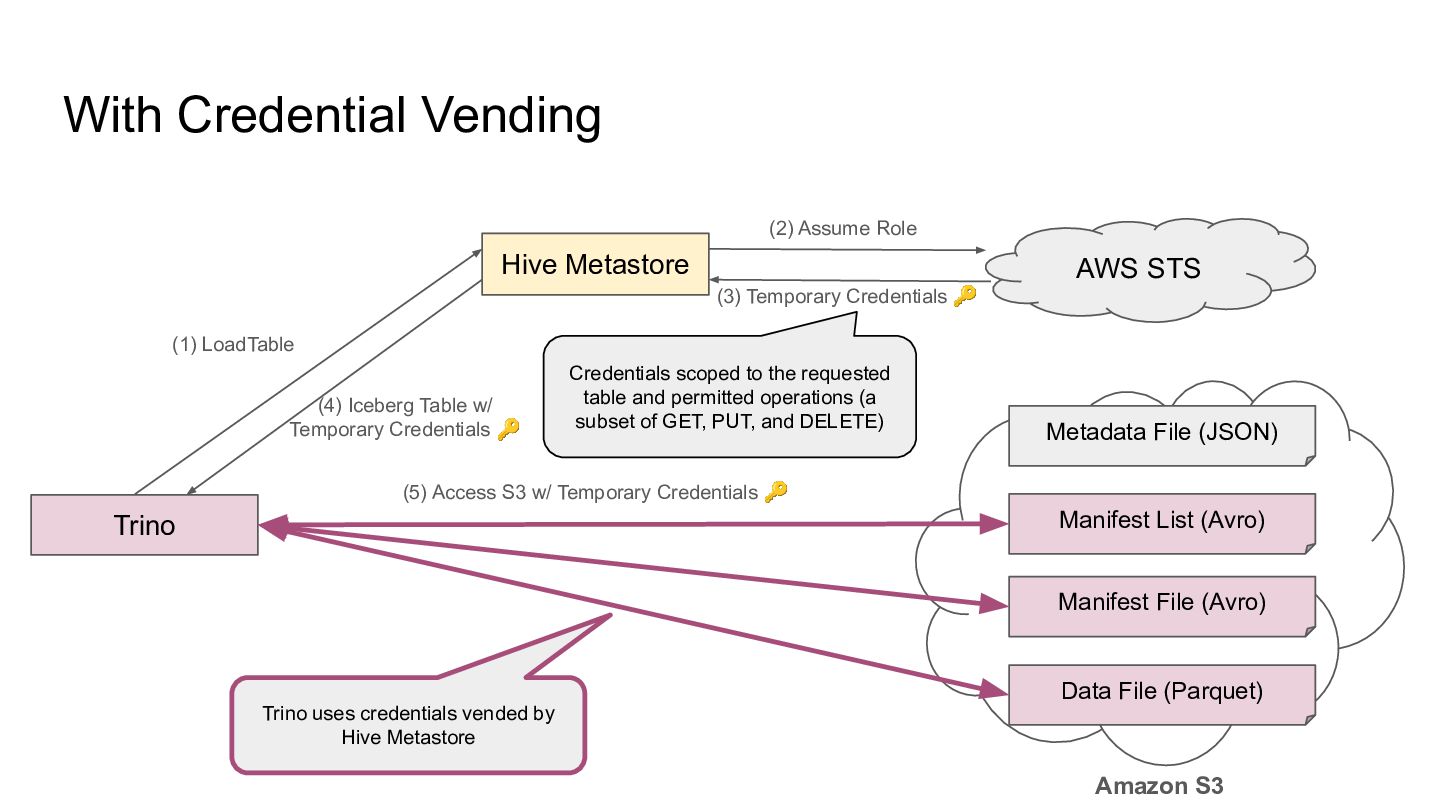
apply the endpoint-level authorization? - OAuth 2, supported by HIVE-29020 - AWS SigV4 - Bearer Token - Table-level access control - Apache Ranger - AWS Lake Formation Catalog Server Policy Store Identity Provider She is Alice Alice can update Table X and Y
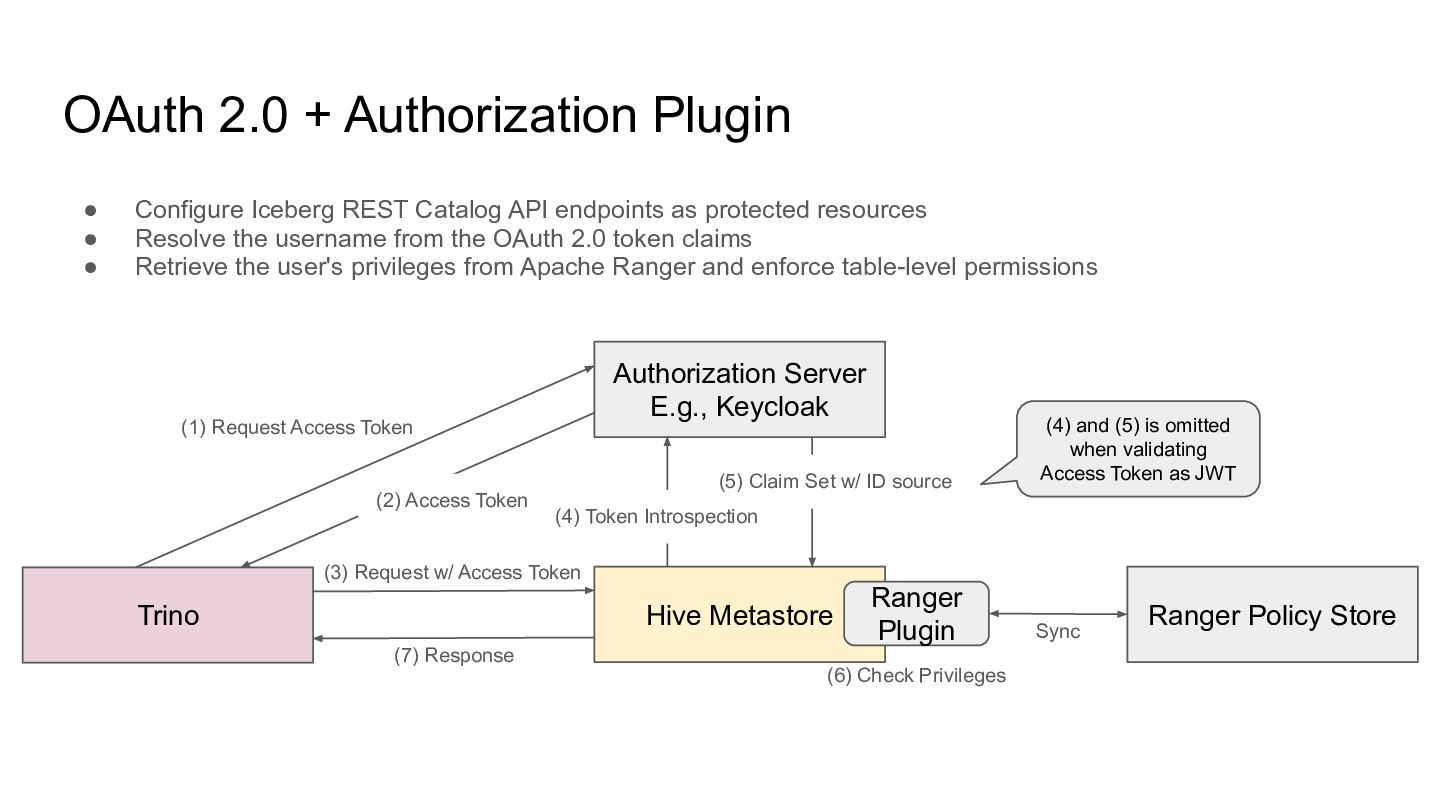
API endpoints as protected resources • Resolve the username from the OAuth 2.0 token claims • Retrieve the user's privileges from Apache Ranger and enforce table-level permissions Authorization Server E.g., Keycloak Hive Metastore Trino (1) Request Access Token Ranger Policy Store (2) Access Token (3) Request w/ Access Token (4) Token Introspection (5) Claim Set w/ ID source (7) Response (4) and (5) is omitted when validating Access Token as JWT Ranger Plugin Sync (6) Check Privileges
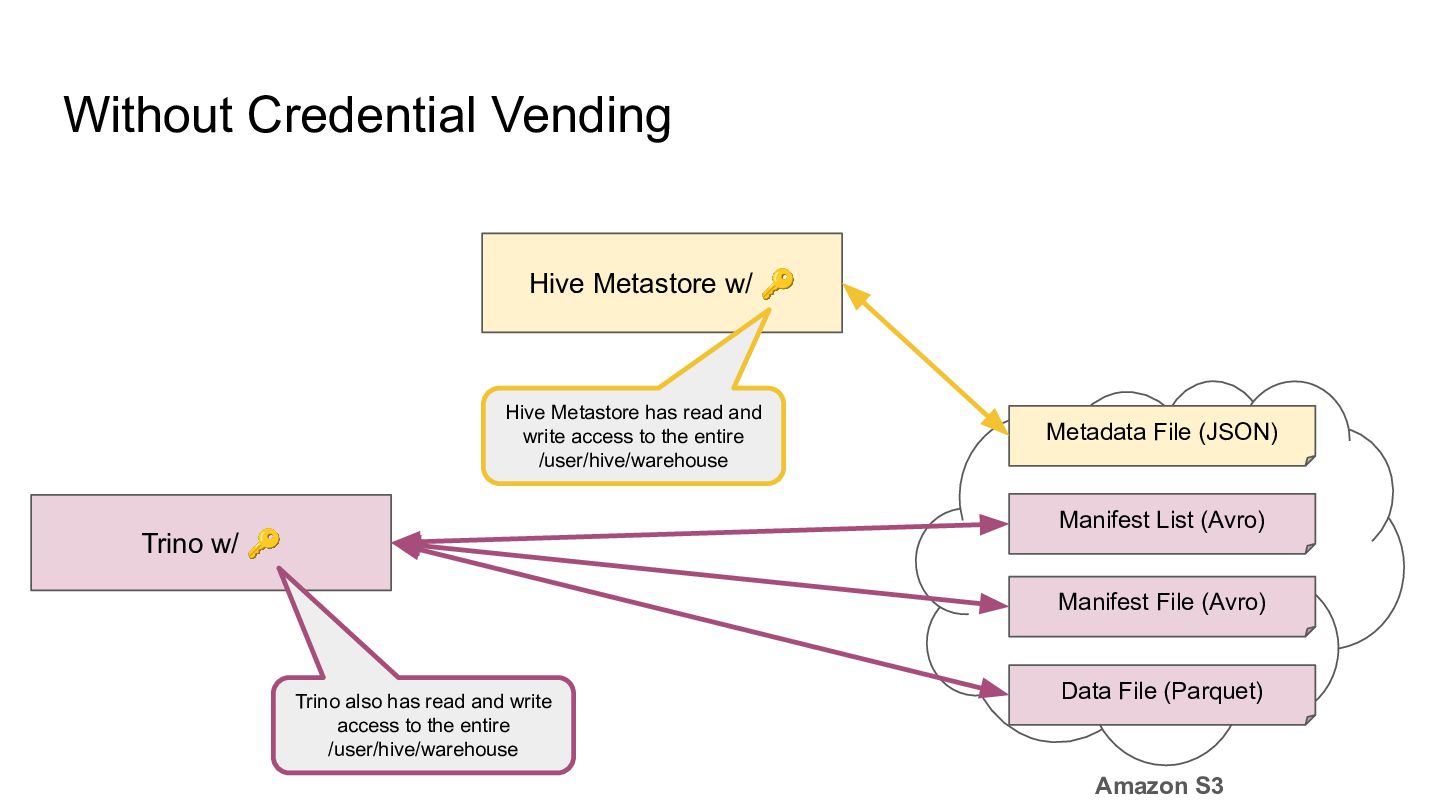
Manifest List (Avro) Manifest File (Avro) Data File (Parquet) Amazon S3 Trino w/ 🔑 Hive Metastore has read and write access to the entire /user/hive/warehouse Trino also has read and write access to the entire /user/hive/warehouse
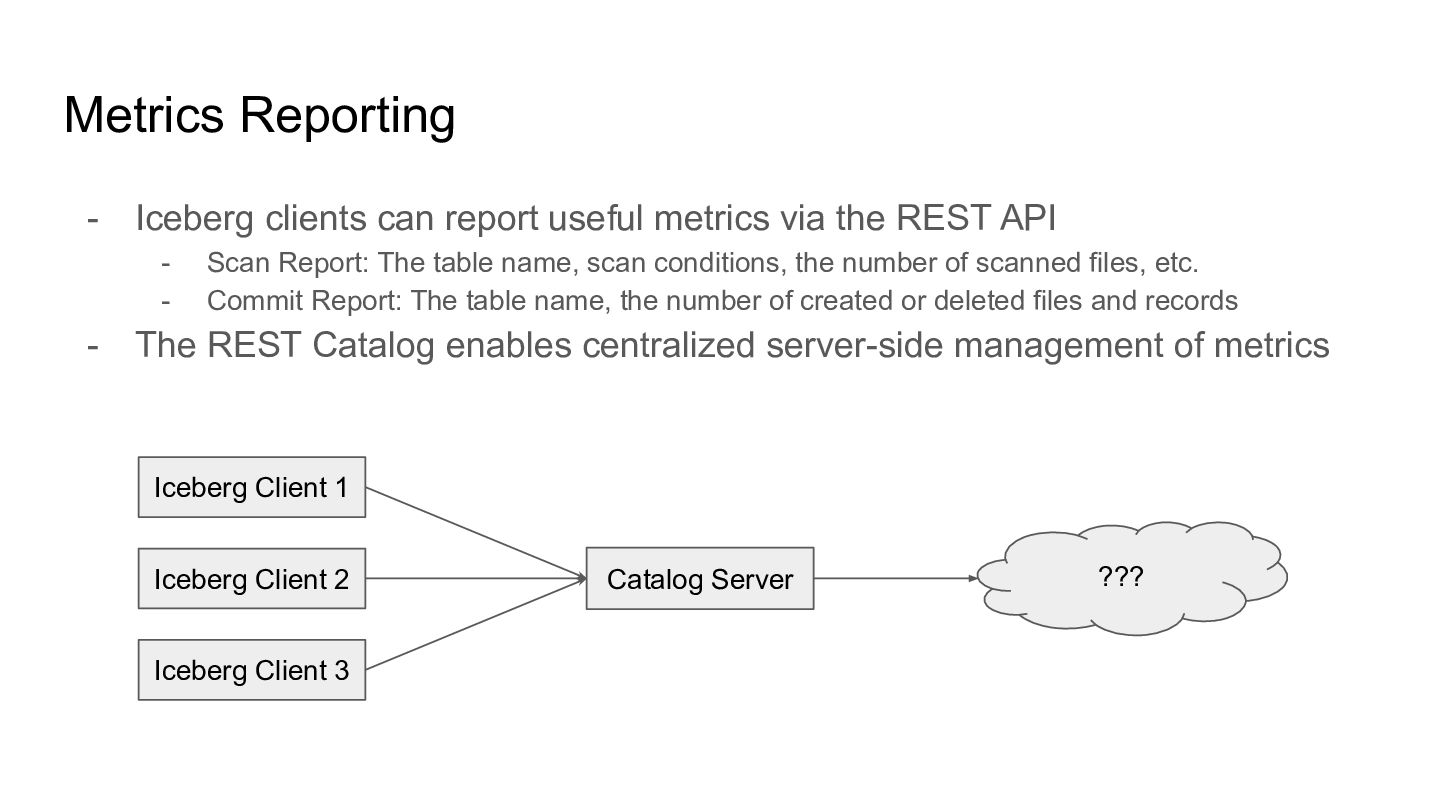
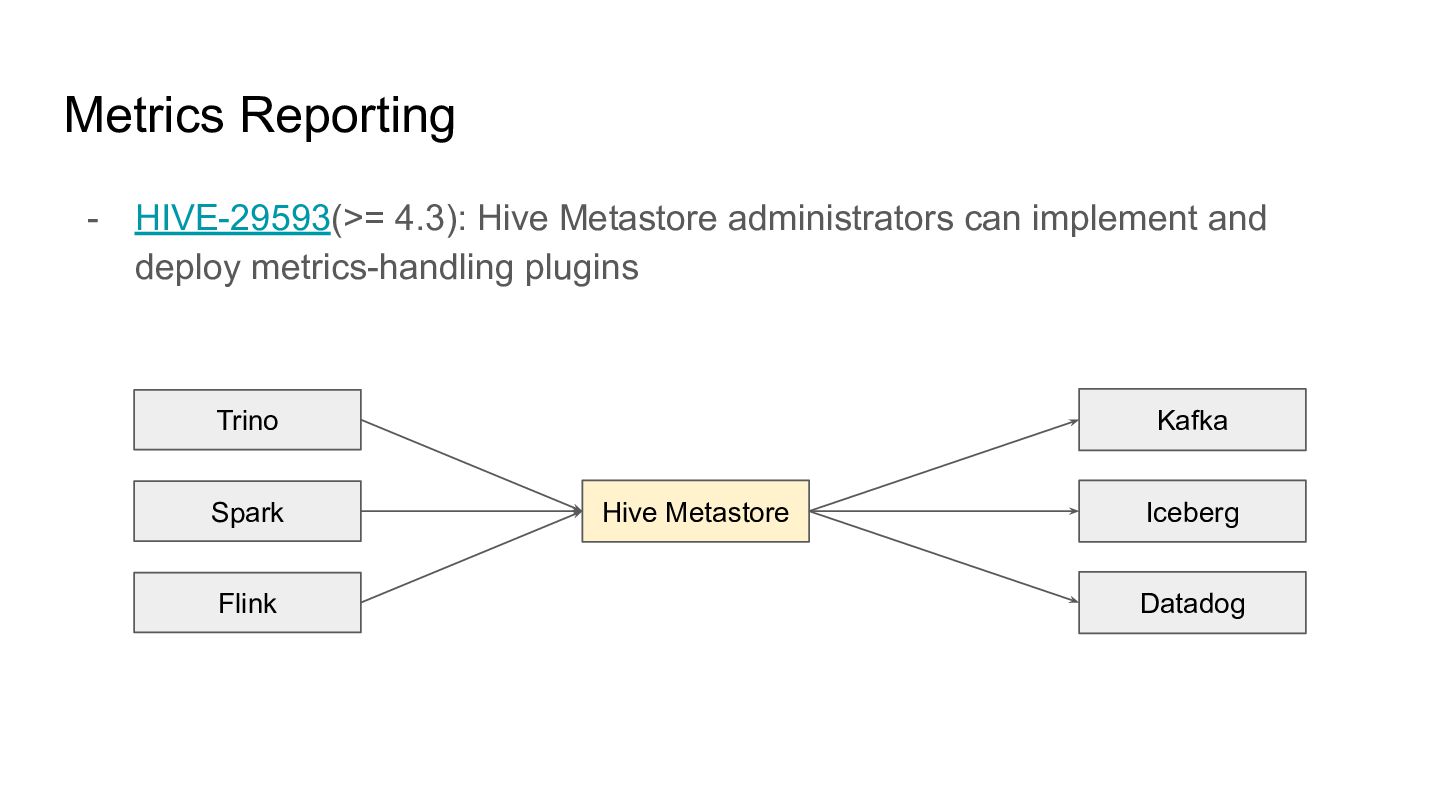
the REST API - Scan Report: The table name, scan conditions, the number of scanned files, etc. - Commit Report: The table name, the number of created or deleted files and records - The REST Catalog enables centralized server-side management of metrics Iceberg Client 1 Catalog Server Iceberg Client 2 Iceberg Client 3 ???
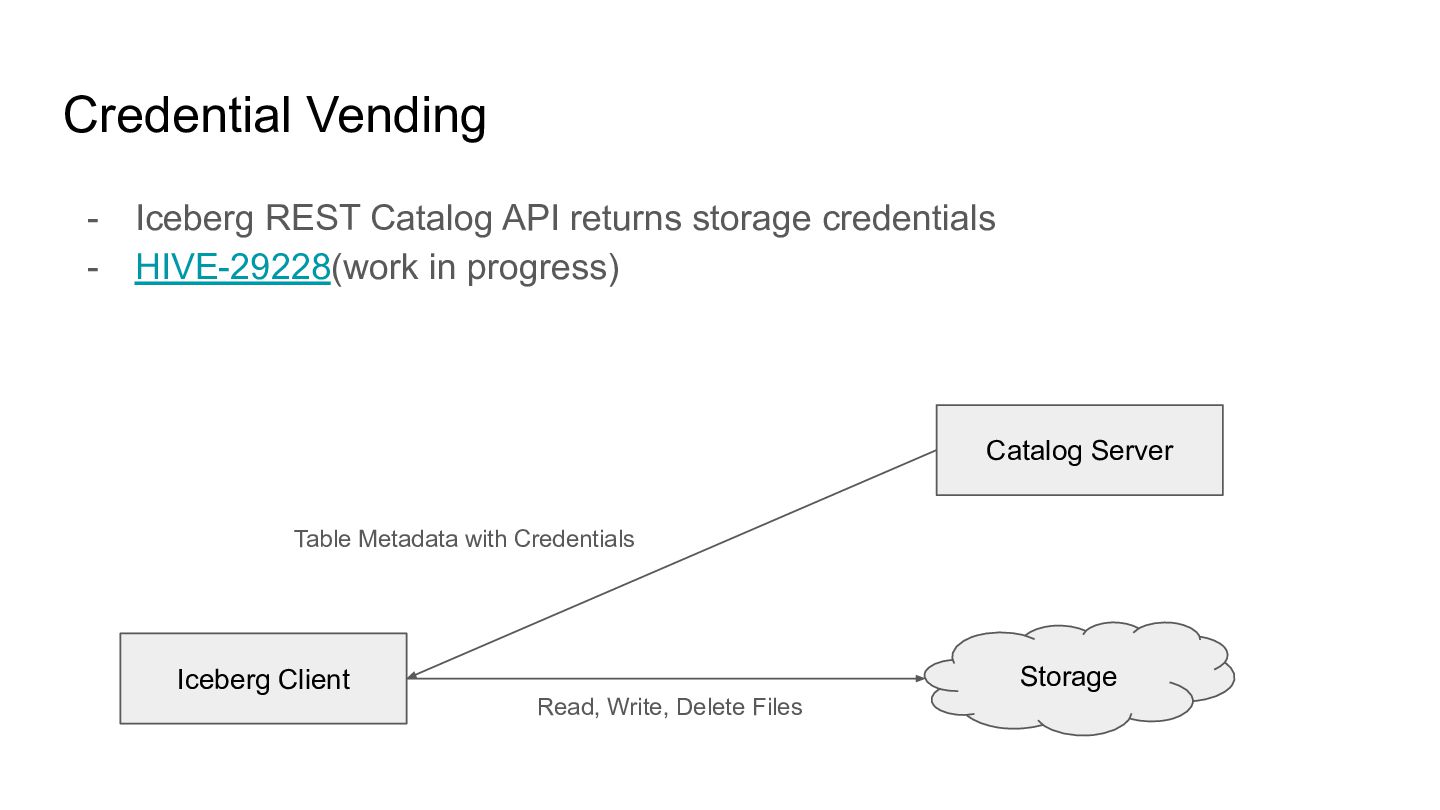
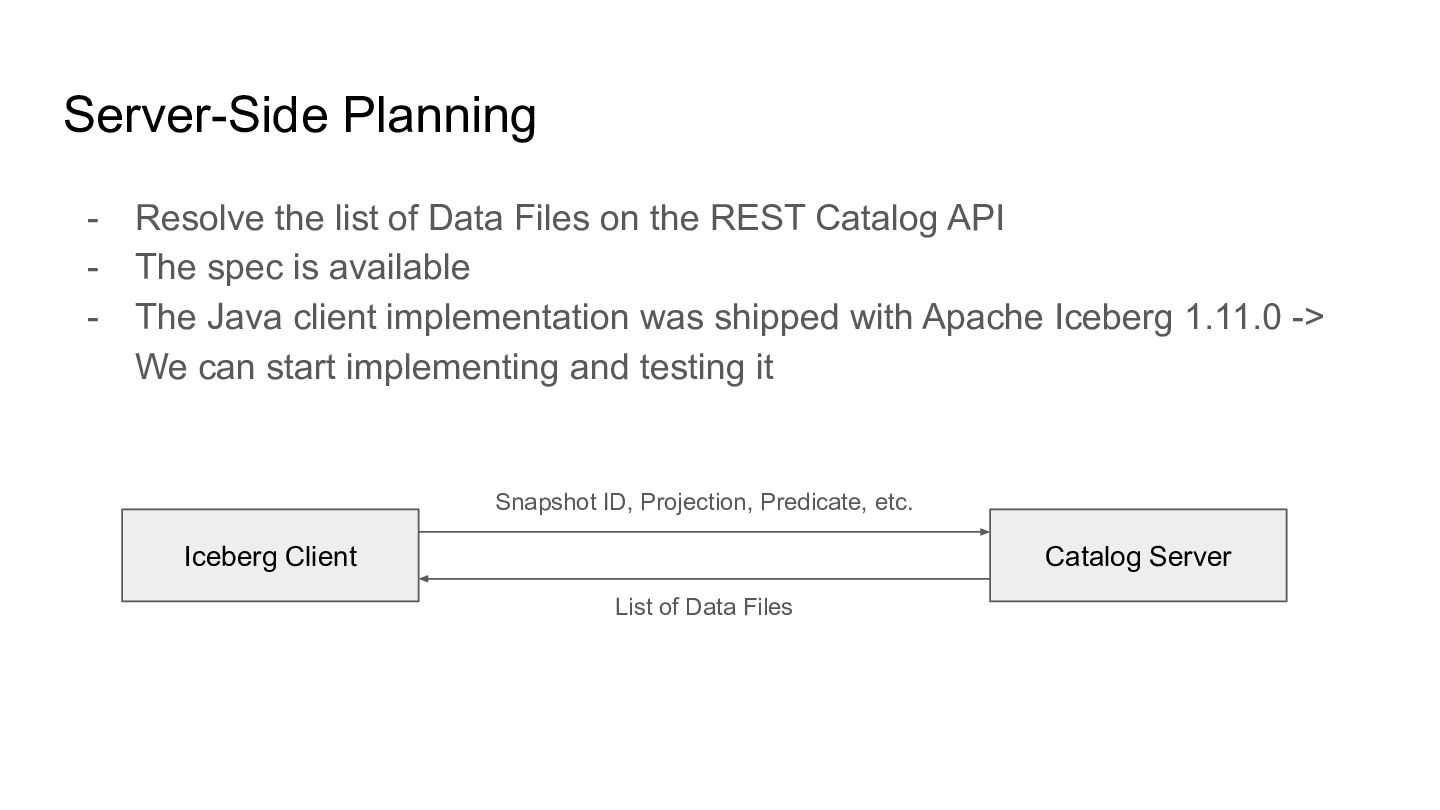
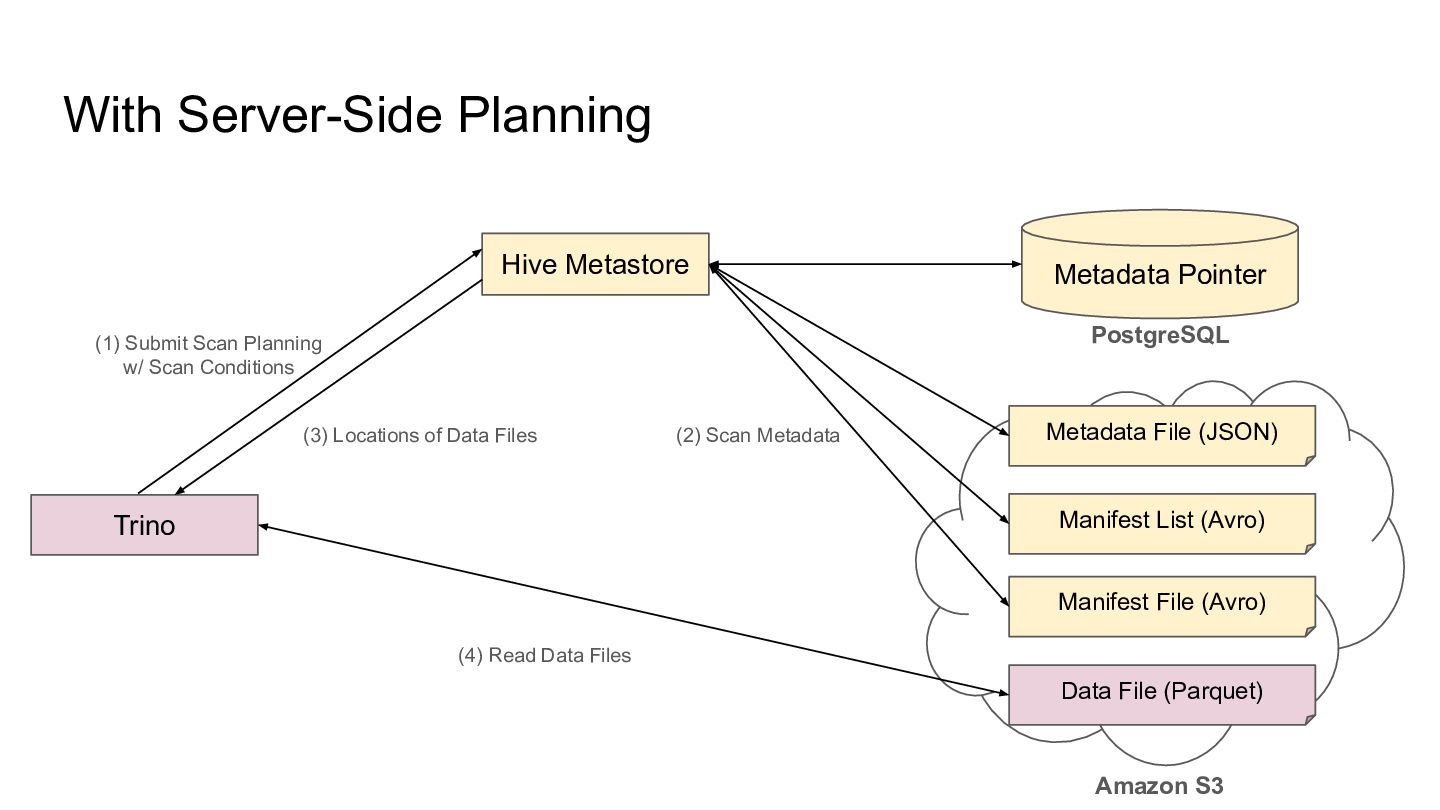
the REST Catalog API - The spec is available - The Java client implementation was shipped with Apache Iceberg 1.11.0 -> We can start implementing and testing it Iceberg Client Catalog Server Snapshot ID, Projection, Predicate, etc. List of Data Files
momentum - Hive Metastore is actively adding support for the Iceberg REST API - REST Catalog makes it easier to introduce advanced features - Special Thanks - Treasure AI colleagues for their review - Keisuke Suzuki, Masafumi Koba
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}