The English version of "Hive Distributed Profiling System in Treasure Data".
Japanese version -> https://speakerdeck.com/okumin/hive-distributed-profiling-system-in-treasure-data-japanese-version-number-tdtechtalk
I made a presentation in TreasureData Tech Talk 2022.
https://techplay.jp/event/879660
{kind=link}
{kind=link}
{kind=link}
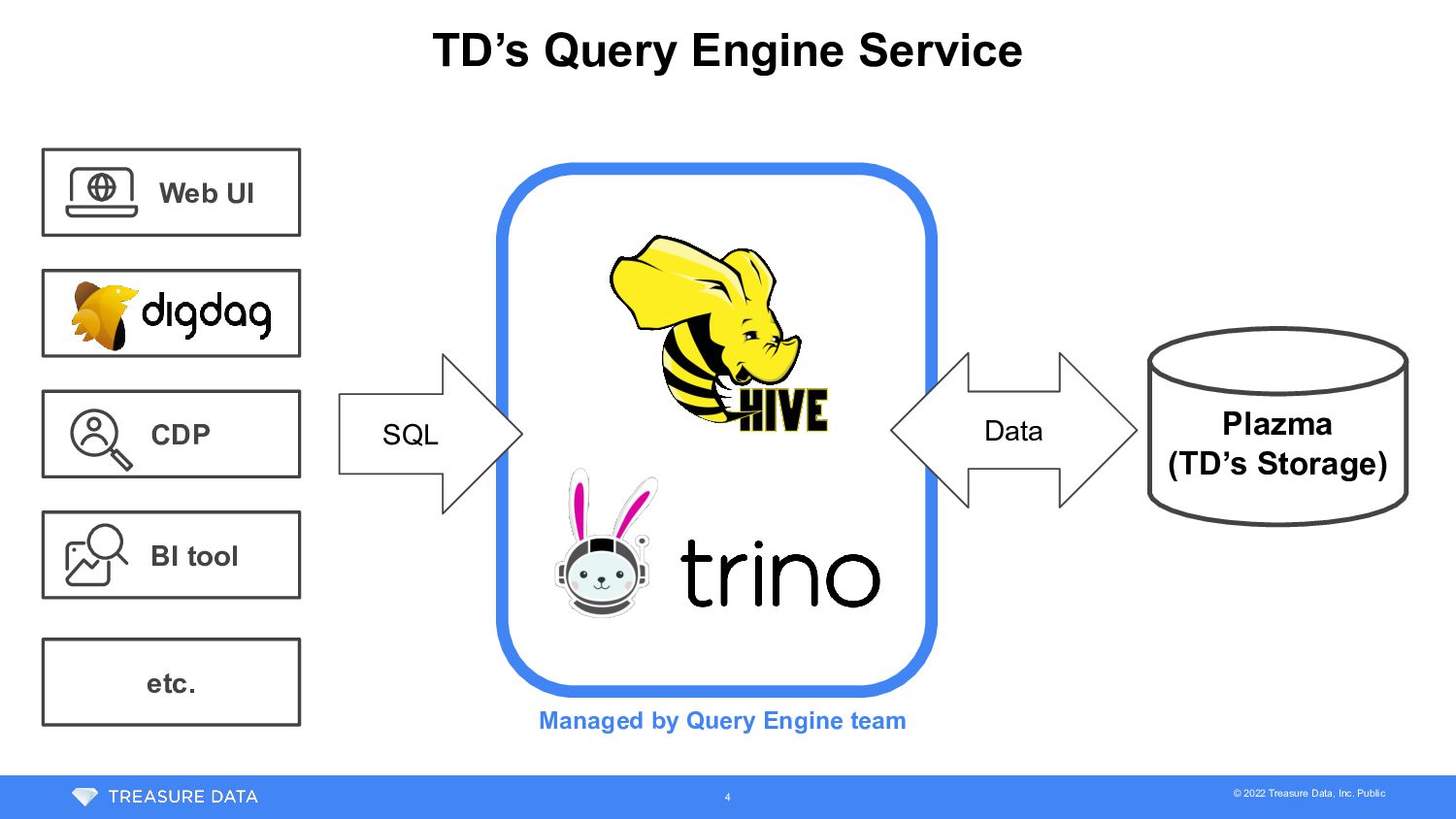{kind=link}
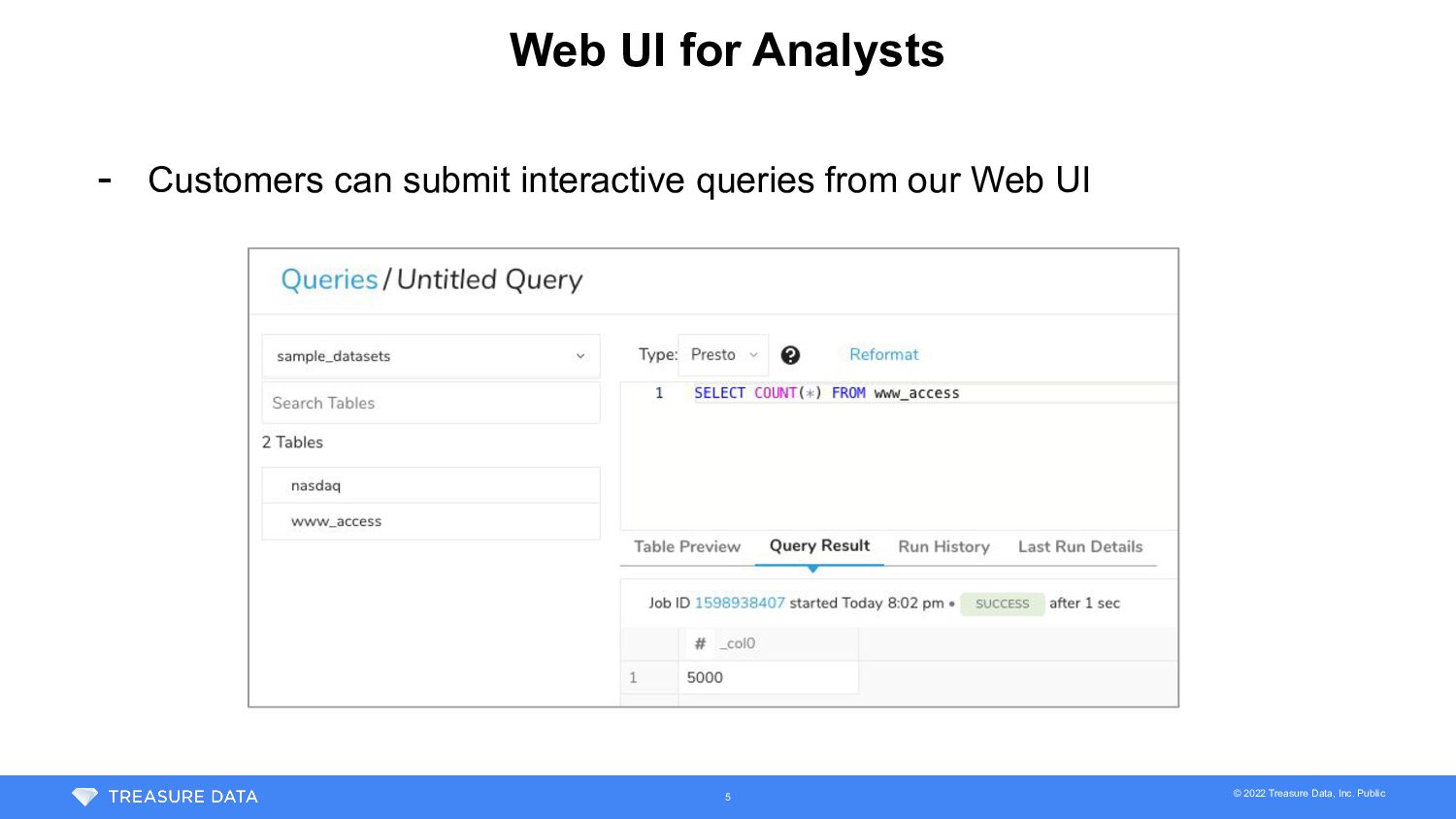{kind=link}
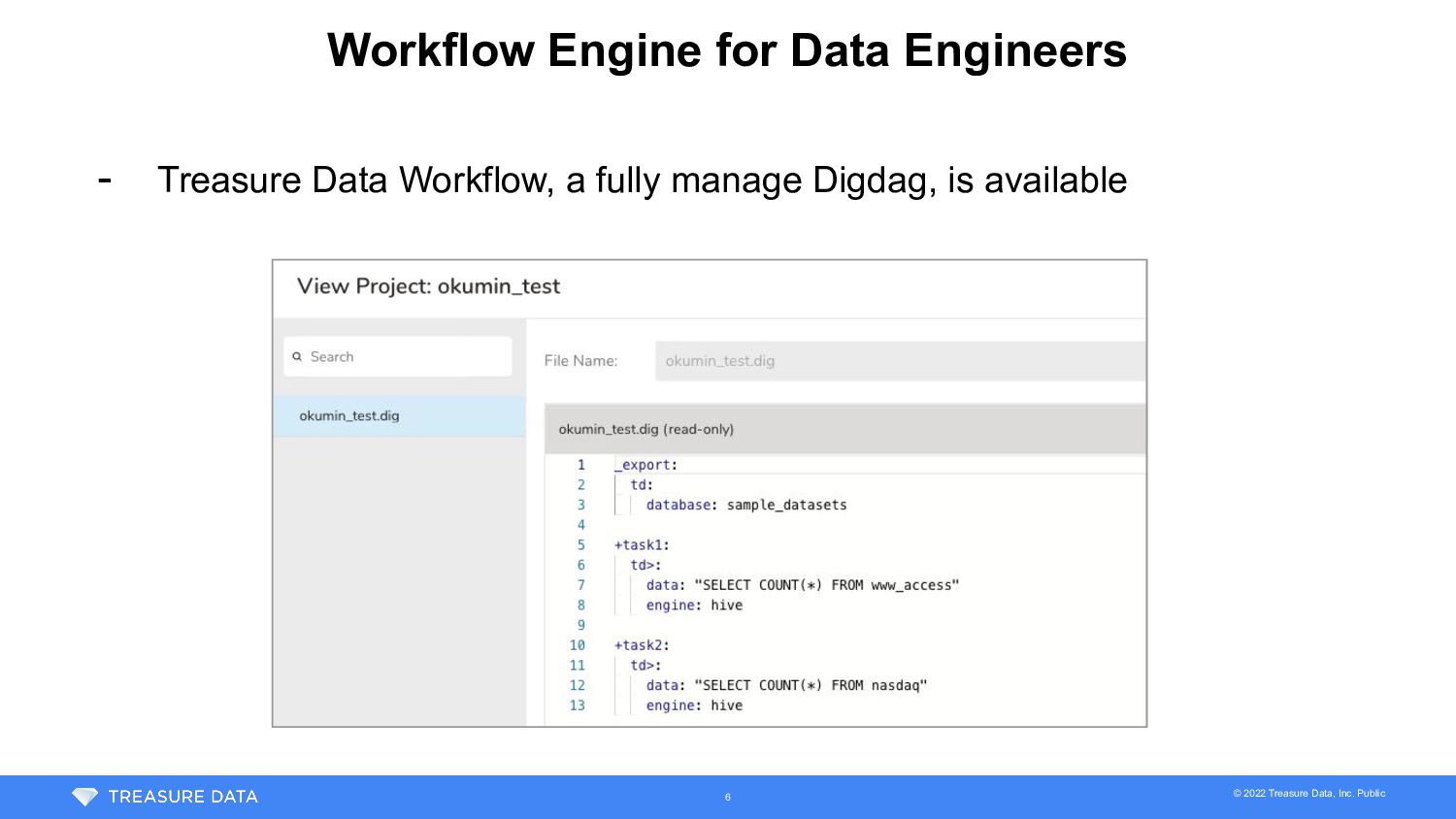{kind=link}
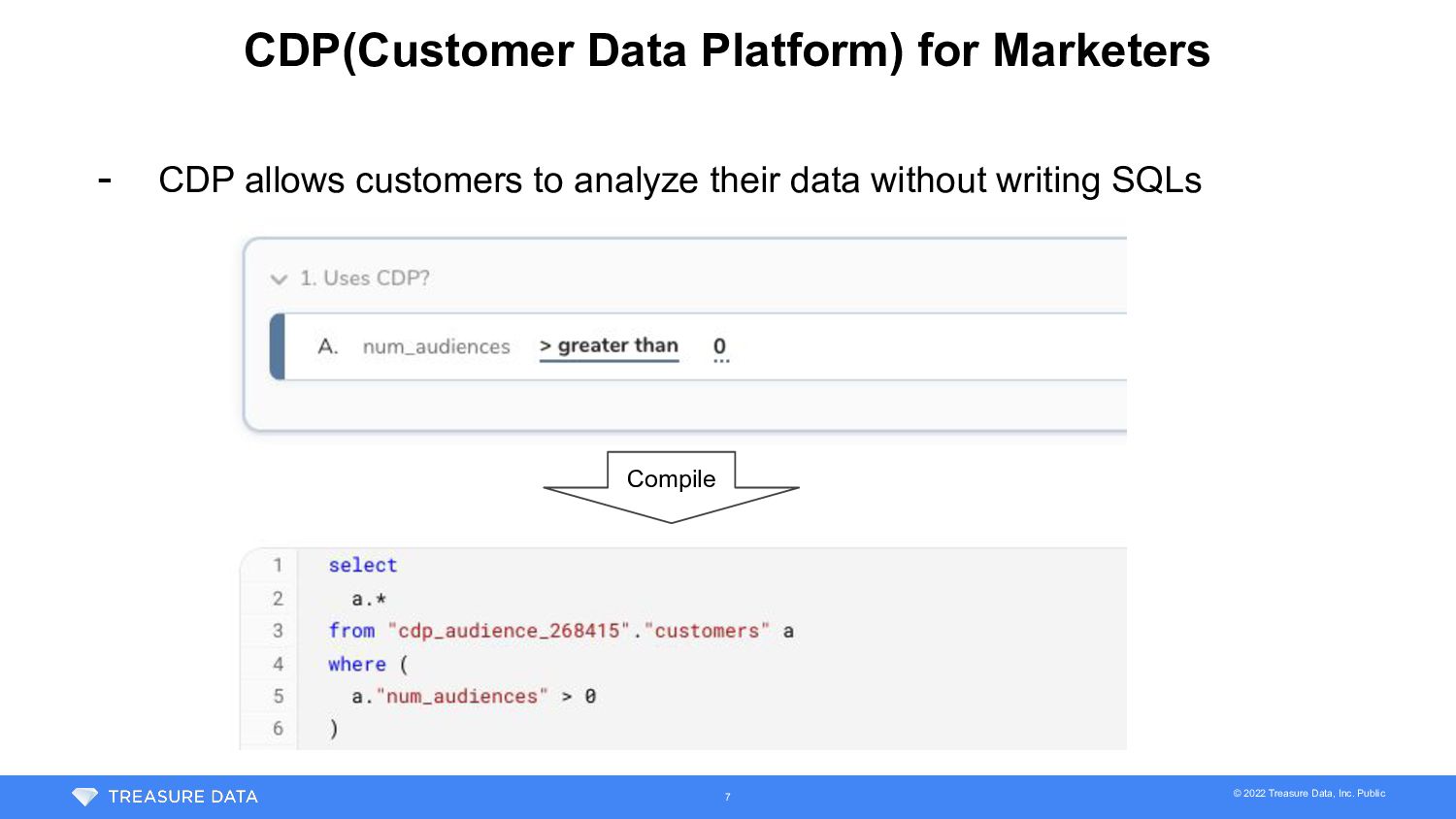{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
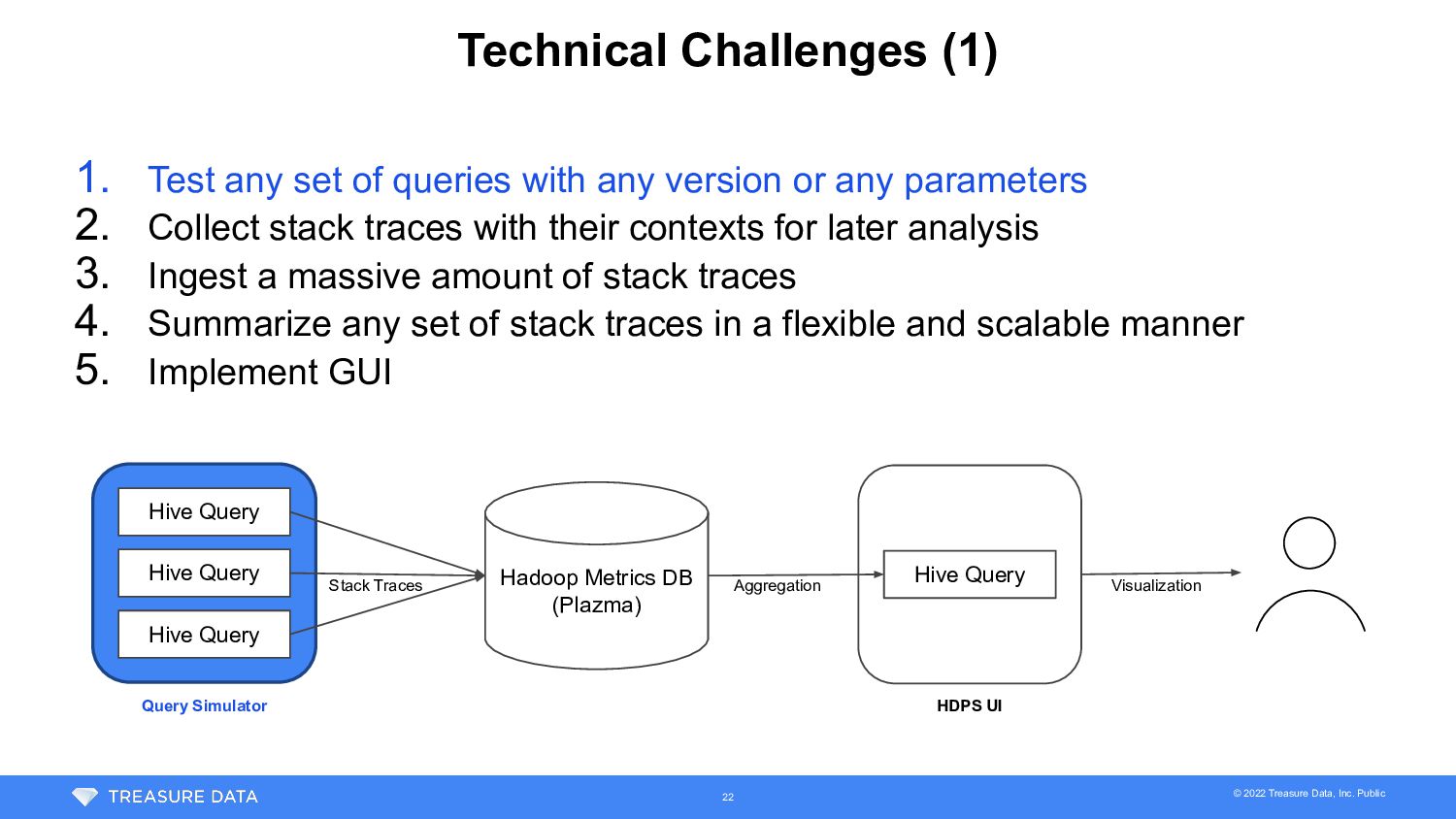{kind=link}
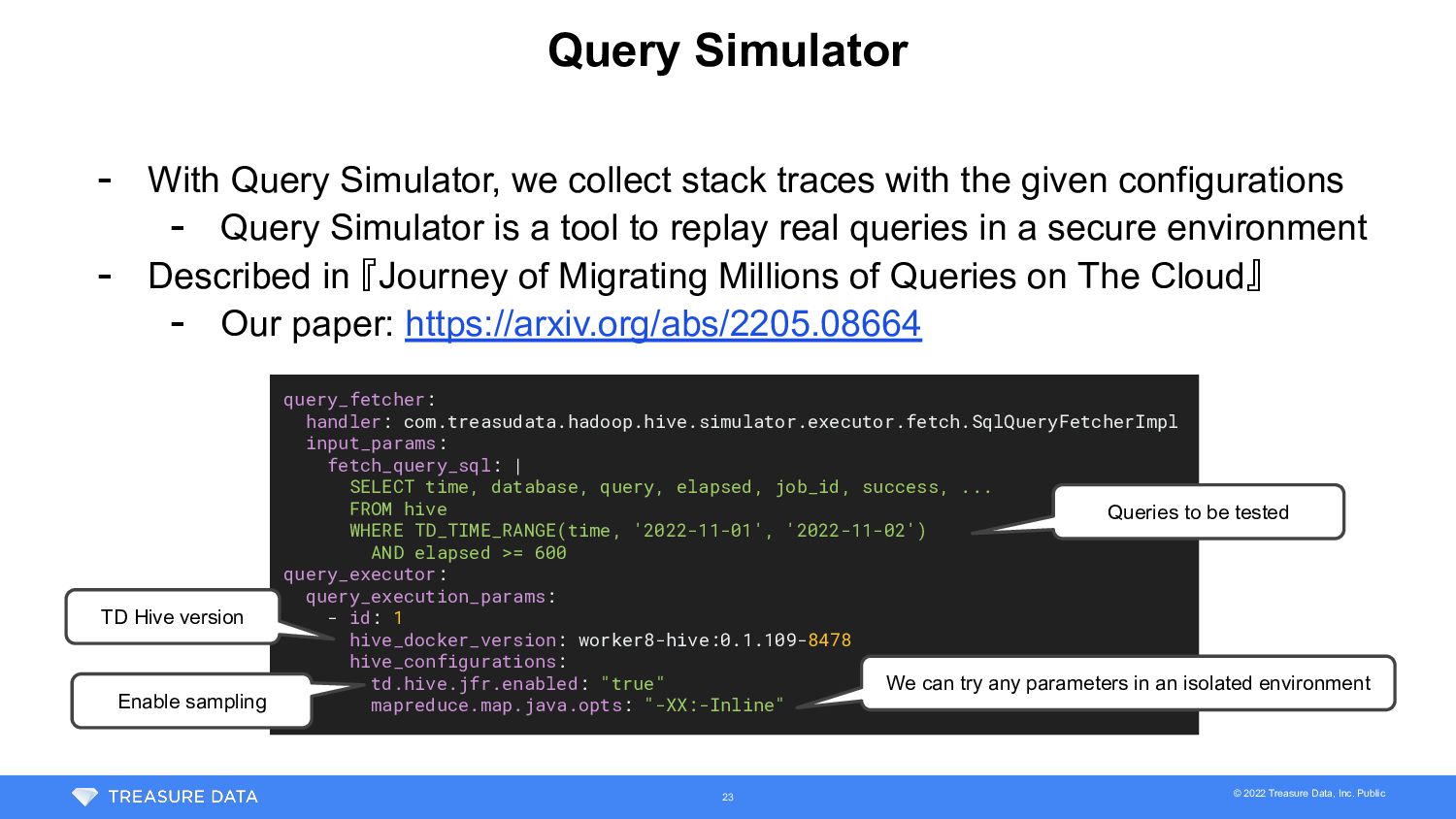{kind=link}
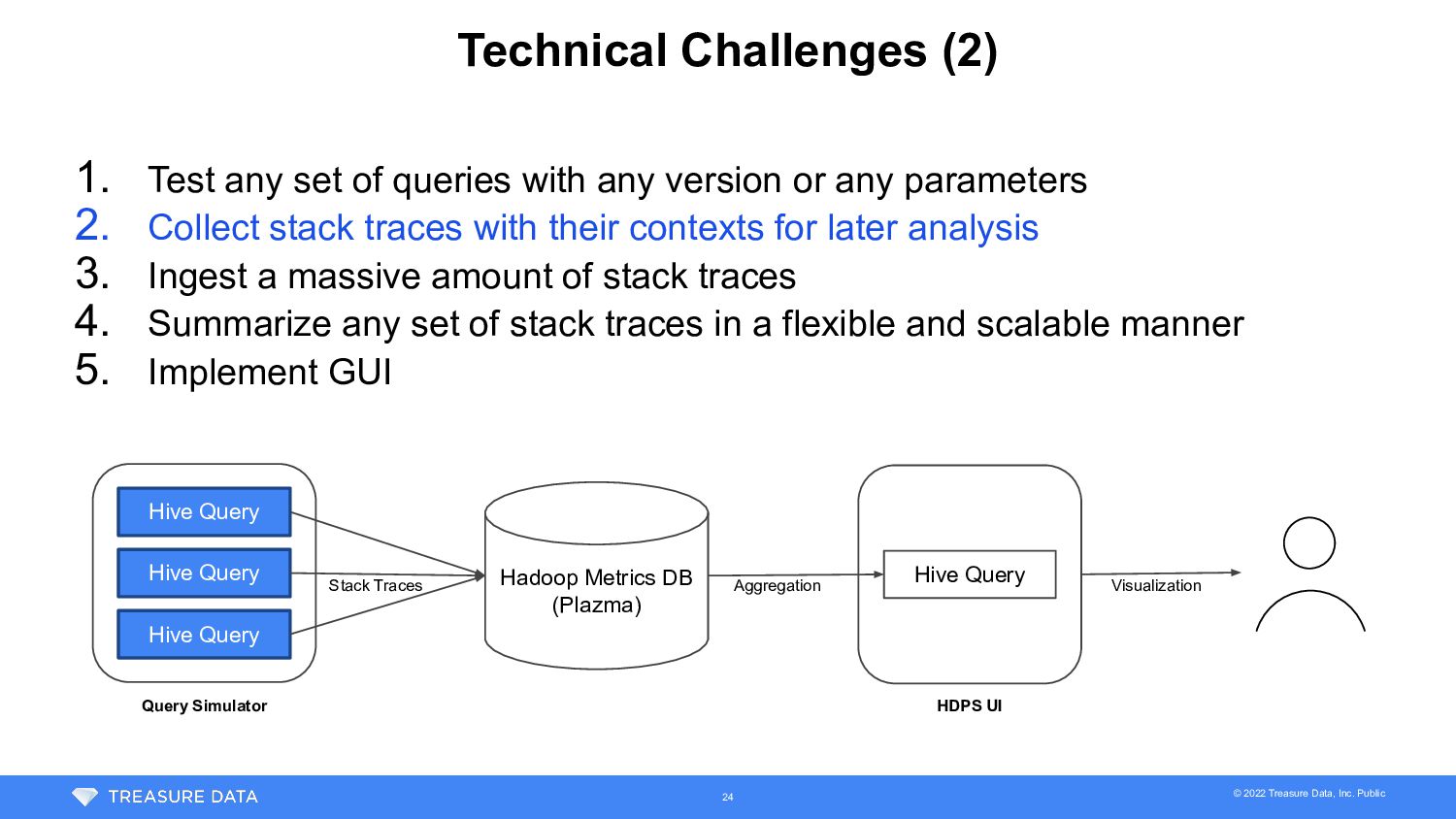{kind=link}
{kind=link}
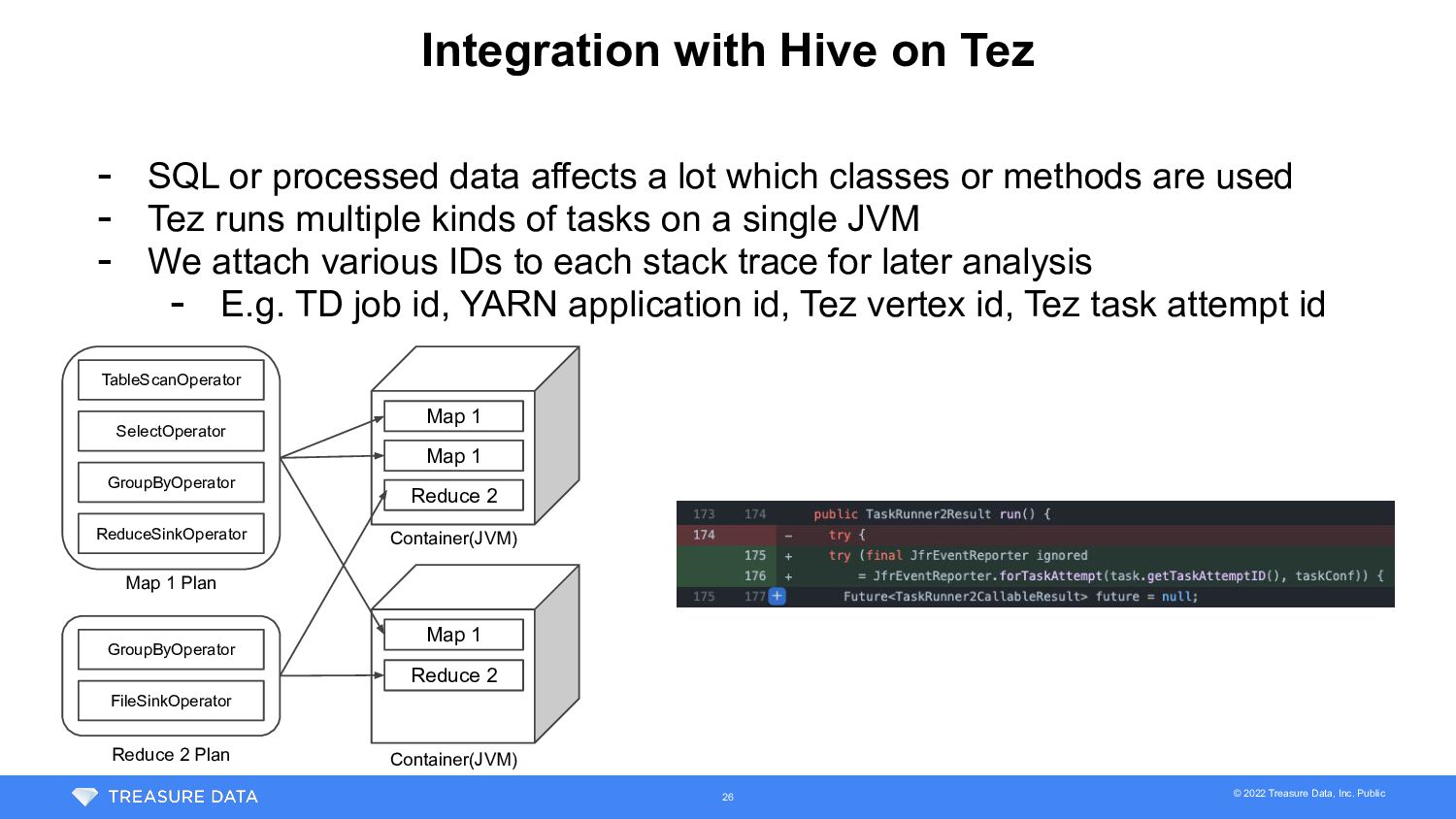{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}