Priority 「どの Pod をより大事に扱うか」を数値で決める仕組み。優先度が高い Pod ほど、スケジューラーにとって “重要な Pod ” として扱われる。 1. PriorityClass という「優先度クラス」を作り、数値で優先度を決める。 2. Pod のマニフェストで priorityClassName を指定すると、その Pod に優先度がつく。 3. 数値が大きい Pod ほど優先されてスケジュールされる。 スケジューラーは、この優先度で Pod の配置を決める。
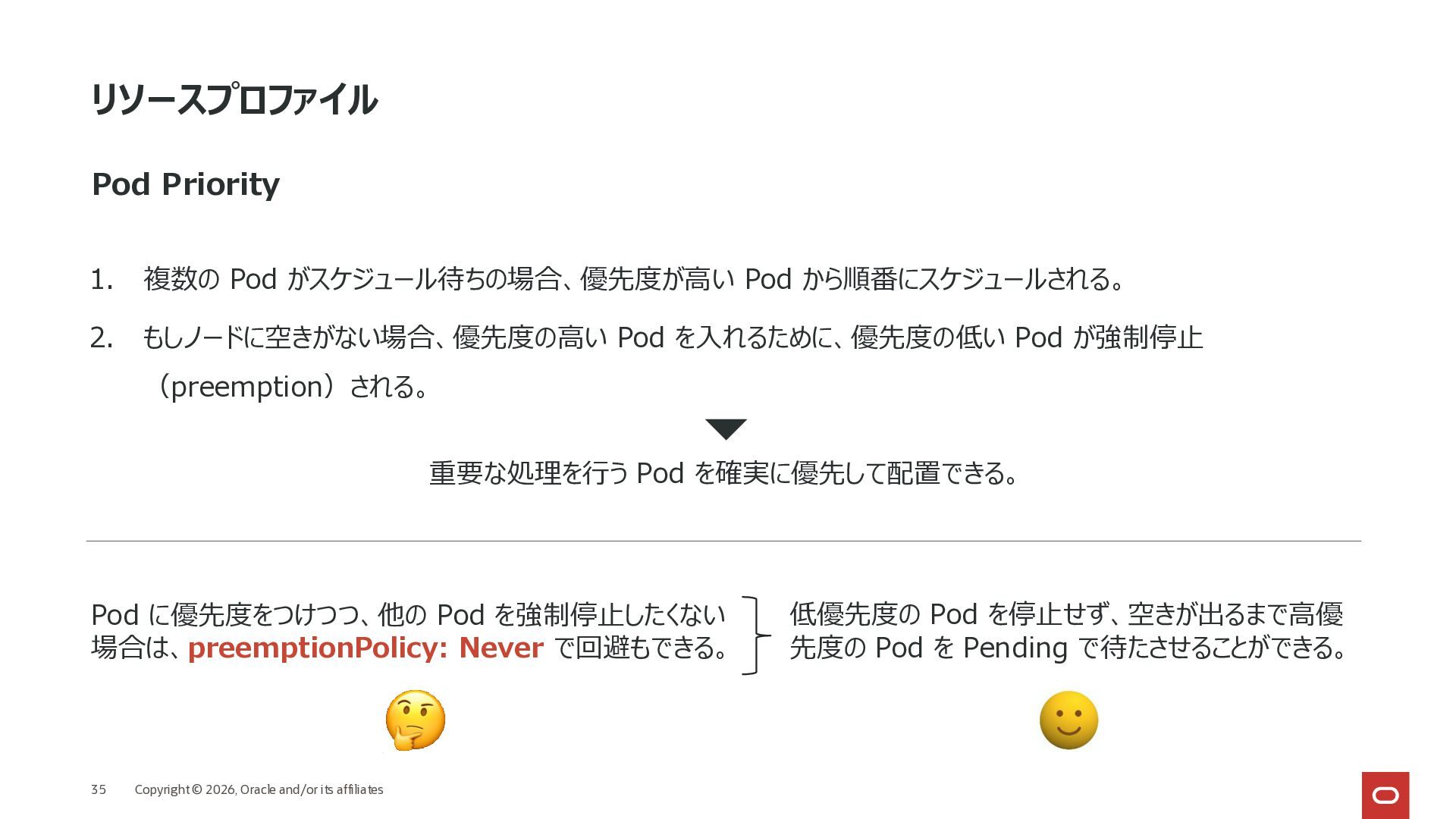
Priority 1. 複数の Pod がスケジュール待ちの場合、優先度が高い Pod から順番にスケジュールされる。 2. もしノードに空きがない場合、優先度の高い Pod を入れるために、優先度の低い Pod が強制停止 (preemption)される。 重要な処理を行う Pod を確実に優先して配置できる。 Pod に優先度をつけつつ、他の Pod を強制停止したくない 場合は、preemptionPolicy: Never で回避もできる。 低優先度の Pod を停止せず、空きが出るまで高優 先度の Pod を Pending で待たさせることができる。
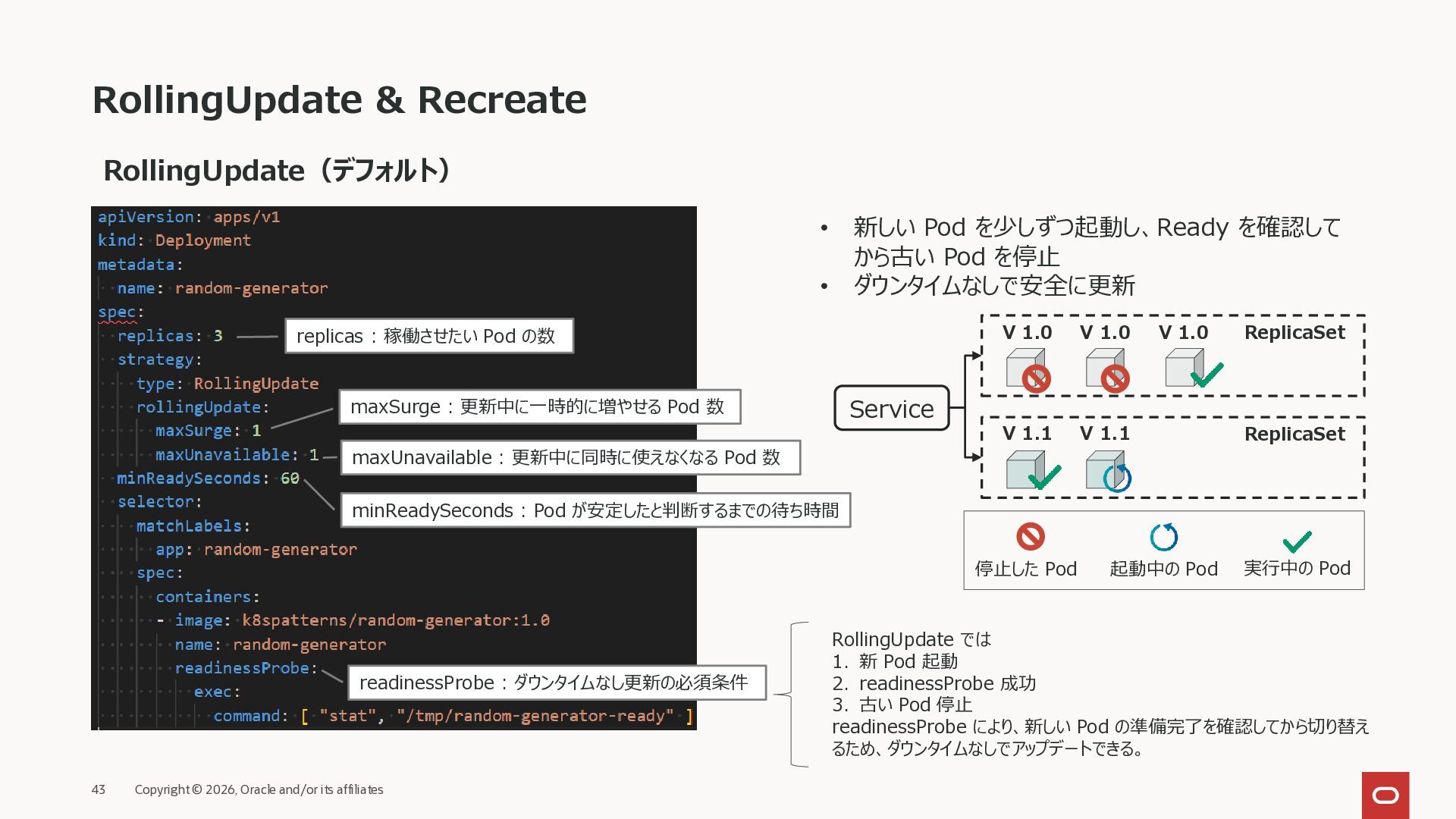
affiliates RollingUpdate(デフォルト) replicas : 稼働させたい Pod の数 maxSurge : 更新中に一時的に増やせる Pod 数 maxUnavailable : 更新中に同時に使えなくなる Pod 数 minReadySeconds : Pod が安定したと判断するまでの待ち時間 readinessProbe : ダウンタイムなし更新の必須条件 • 新しい Pod を少しずつ起動し、Ready を確認して から古い Pod を停止 • ダウンタイムなしで安全に更新 ReplicaSet ReplicaSet Service V 1.1 V 1.1 V 1.0 V 1.0 V 1.0 RollingUpdate では 1. 新 Pod 起動 2. readinessProbe 成功 3. 古い Pod 停止 readinessProbe により、新しい Pod の準備完了を確認してから切り替え るため、ダウンタイムなしでアップデートできる。 起動中の Pod 実行中の Pod 停止した Pod
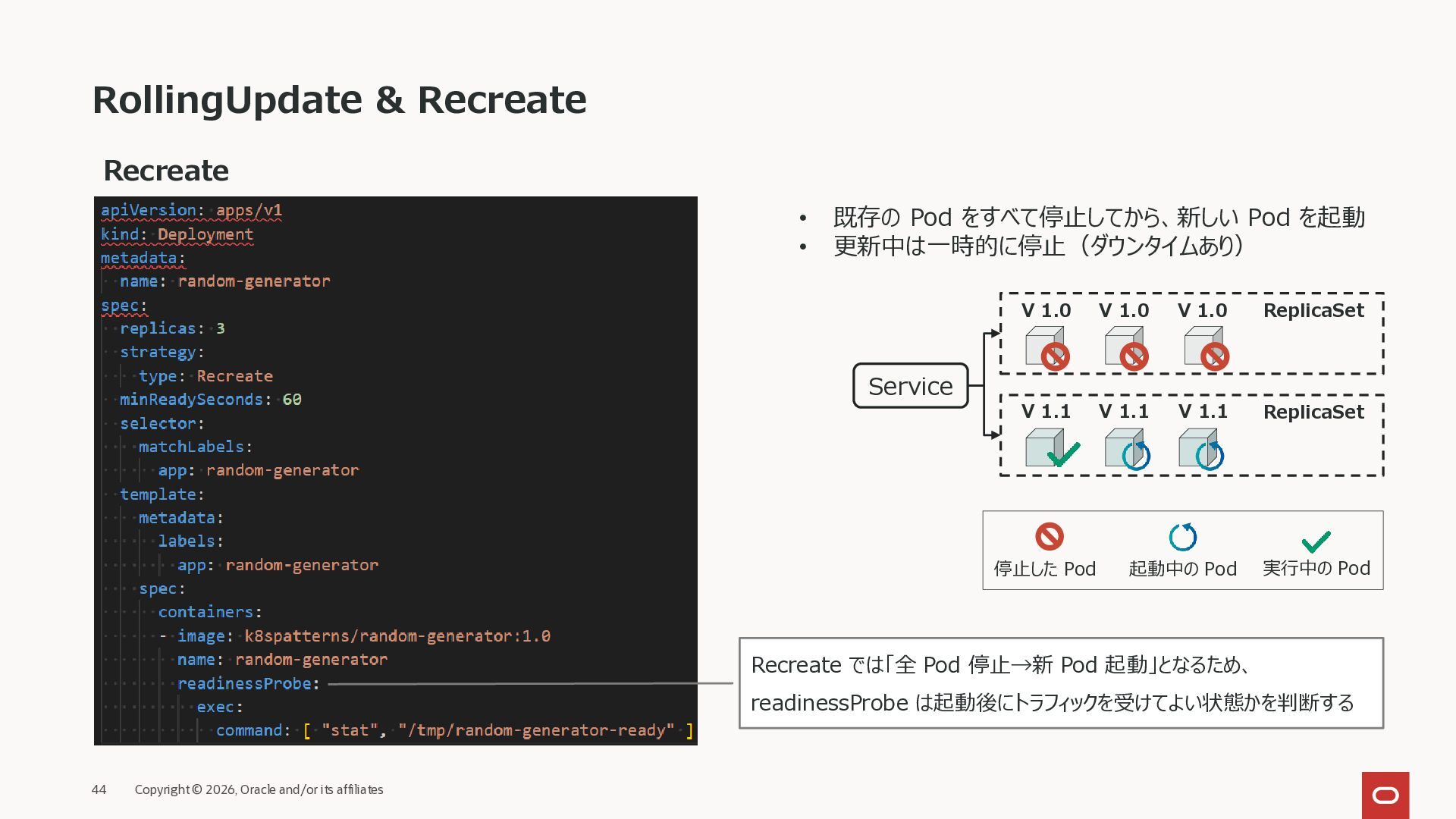
affiliates Recreate • 既存の Pod をすべて停止してから、新しい Pod を起動 • 更新中は一時的に停止(ダウンタイムあり) ReplicaSet ReplicaSet Service V 1.1 V 1.1 V 1.0 V 1.0 V 1.0 V 1.1 Recreate では「全 Pod 停止→新 Pod 起動」となるため、 readinessProbe は起動後にトラフィックを受けてよい状態かを判断する 起動中の Pod 実行中の Pod 停止した Pod
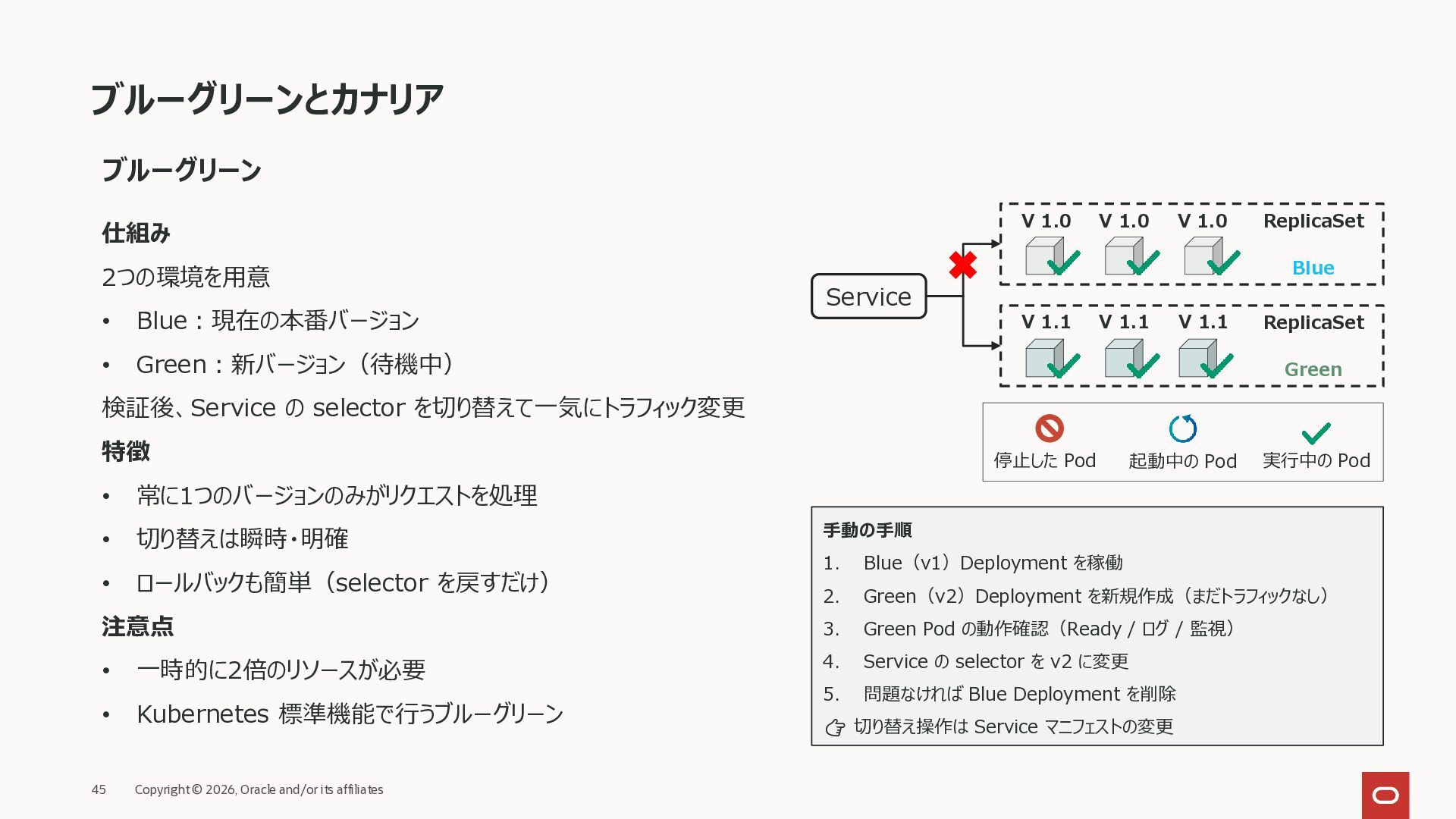
仕組み 2つの環境を用意 • Blue:現在の本番バージョン • Green:新バージョン(待機中) 検証後、Service の selector を切り替えて一気にトラフィック変更 特徴 • 常に1つのバージョンのみがリクエストを処理 • 切り替えは瞬時・明確 • ロールバックも簡単(selector を戻すだけ) 注意点 • 一時的に2倍のリソースが必要 • Kubernetes 標準機能で行うブルーグリーン ReplicaSet ReplicaSet Service V 1.1 V 1.1 V 1.0 V 1.0 V 1.0 V 1.1 起動中の Pod 実行中の Pod 停止した Pod 手動の手順 1. Blue(v1)Deployment を稼働 2. Green(v2)Deployment を新規作成(まだトラフィックなし) 3. Green Pod の動作確認(Ready / ログ / 監視) 4. Service の selector を v2 に変更 5. 問題なければ Blue Deployment を削除 👉 切り替え操作は Service マニフェストの変更 Green Blue
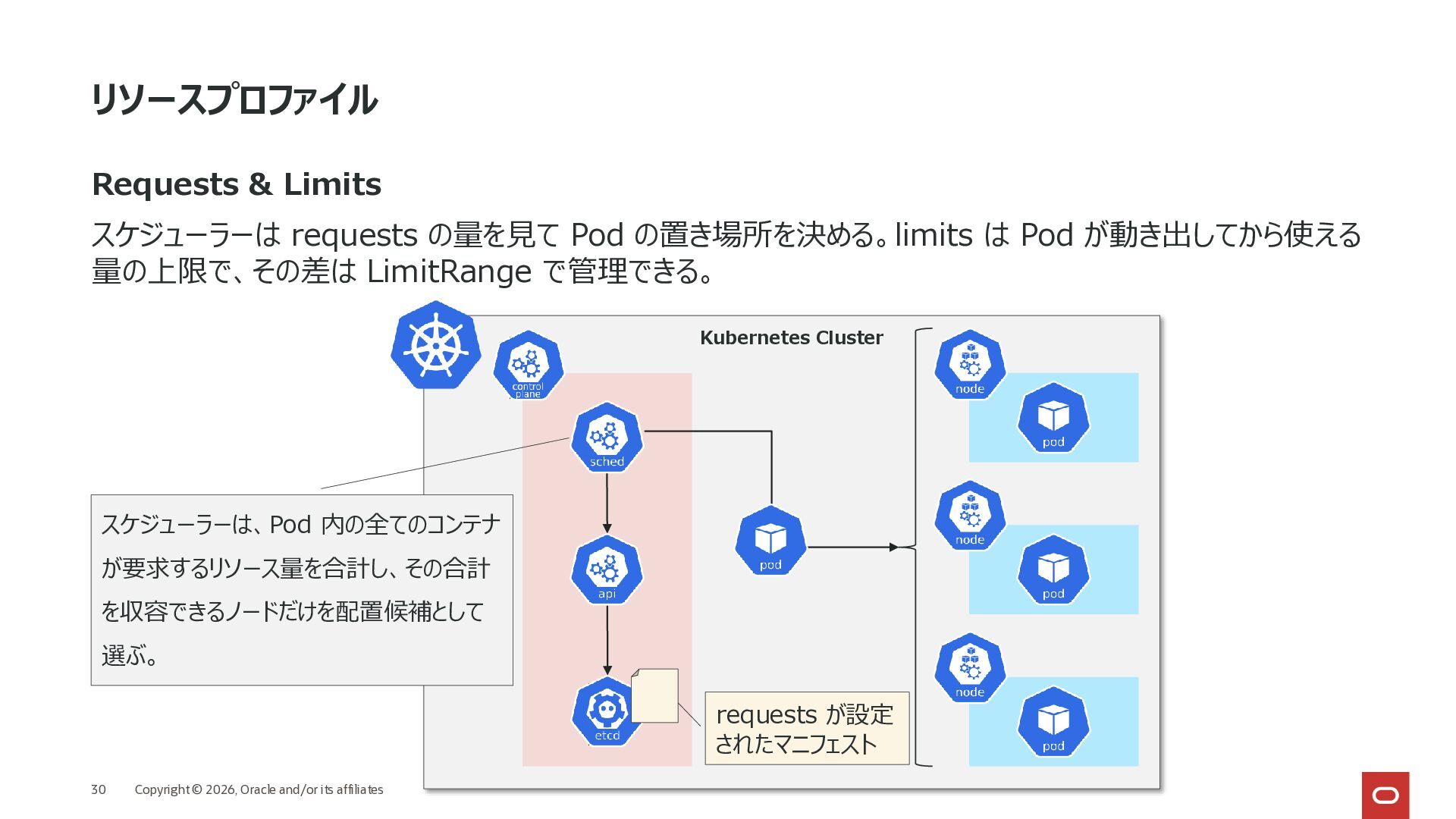
Pod を見て、「この Pod をどこに置くか」を決める必 須ルール。 「一緒に置きたい Pod」を見つけるためのラベル条件。 「confidential=high」の Pod が動いている ”特定のゾーン (security-zone)” と同じ場所に、この Pod も配置するルール。 「この Pod はここには置かないで」という配置しない場所のルール。 「confidential=none」 の Pod がいるノードには、できれば置かない (ただし、どうしても空きがなければ置かれることもある)というルール。
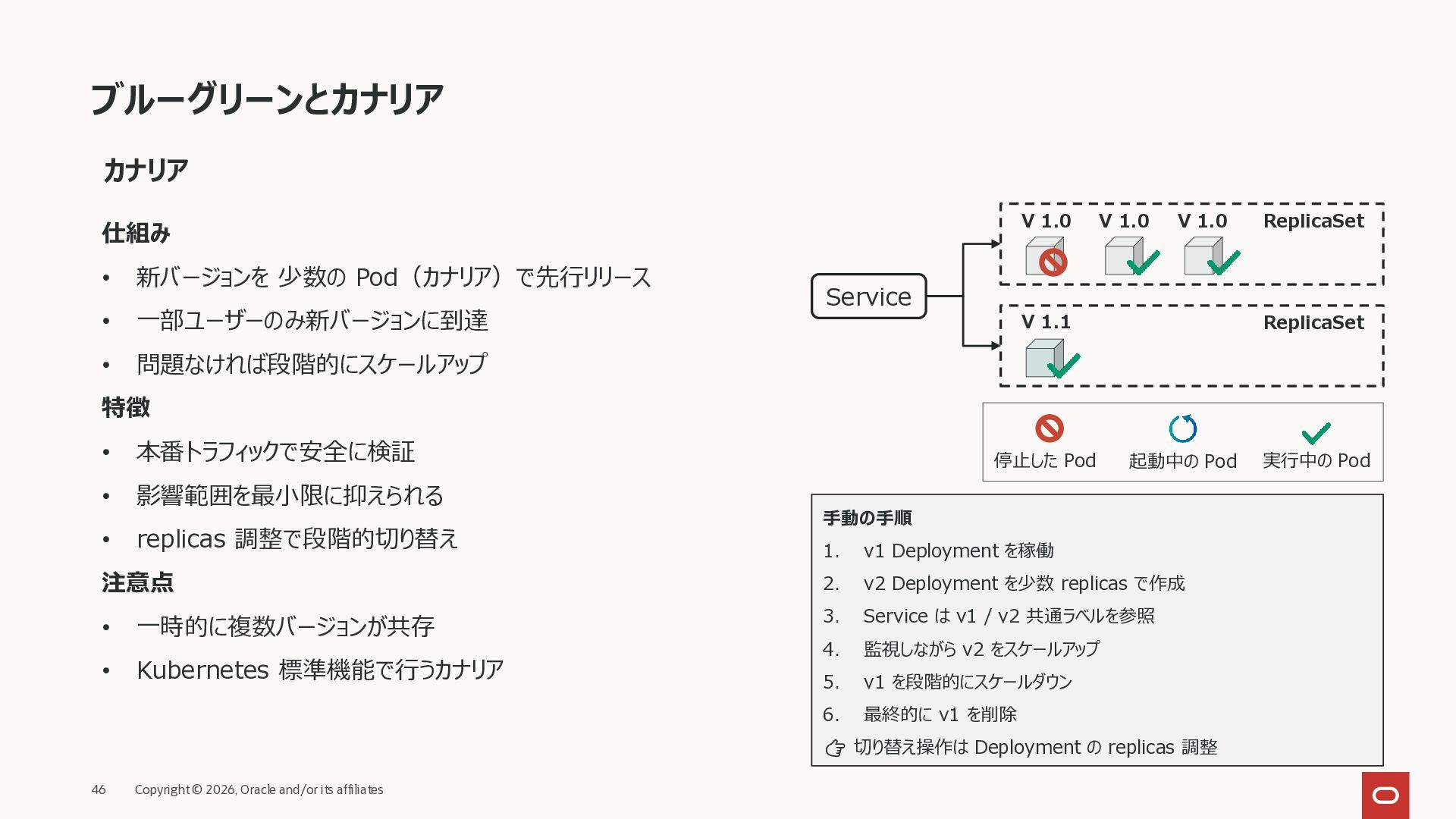
Spread Constraint • Pod をゾーン/ノードなどにできるだけ均等に分散 • 可用性向上(単一障害点の回避)+ リソース効率の改善 ローリングアップデート時に新 Pod の置き場がなくなる場合があり、Spread Constraint を利用して多少の偏りを許 容して配置 • Pod Affinity は、 Pod を「同じ場所(トポロジー)に無制限に置く」 • Pod Anti-Affinity は、Pod を「同じ場所(トポロジー)に置かない」
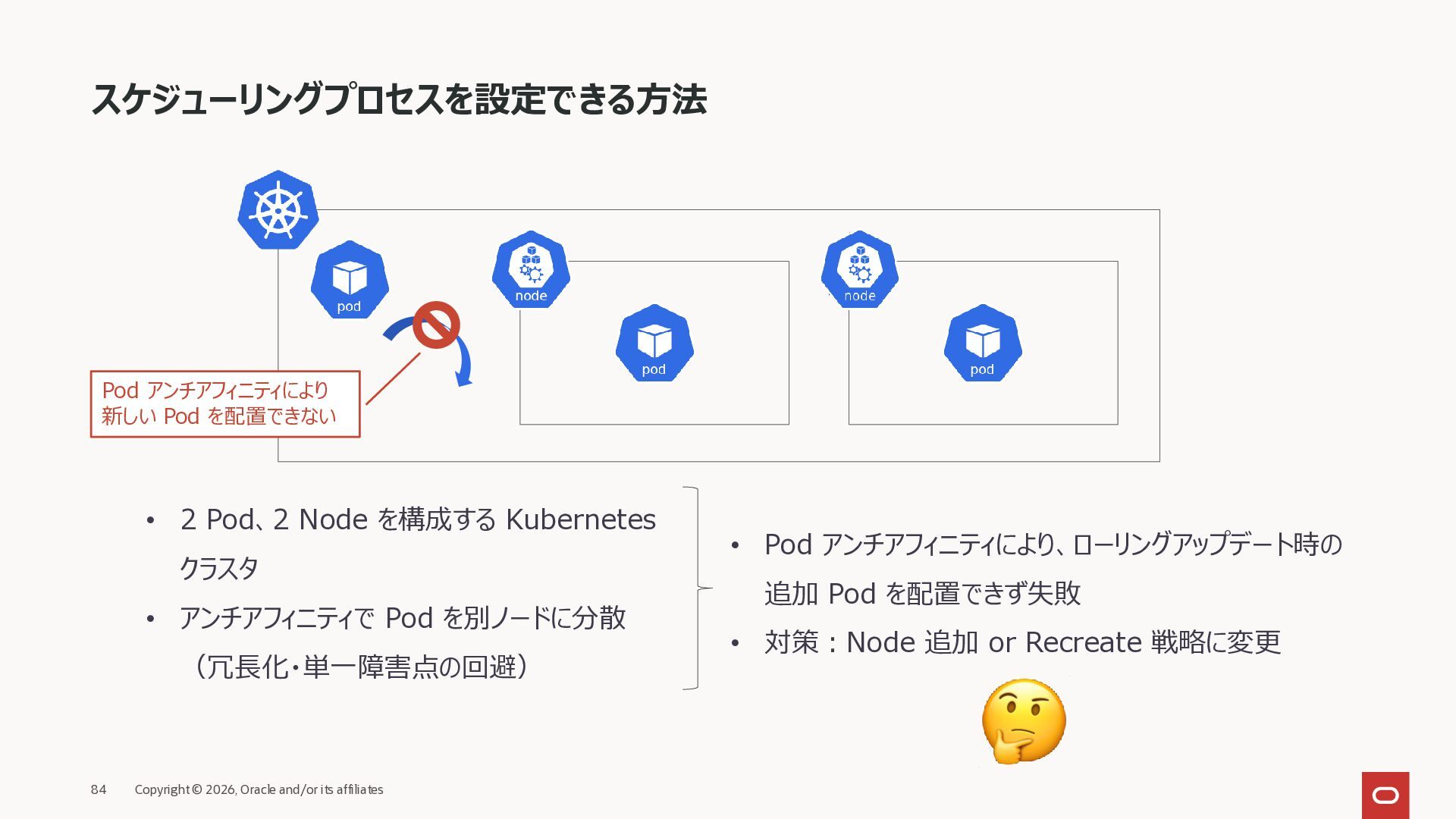
2 Pod、2 Node を構成する Kubernetes クラスタ • アンチアフィニティで Pod を別ノードに分散 (冗長化・単一障害点の回避) • Pod アンチアフィニティにより、ローリングアップデート時の 追加 Pod を配置できず失敗 • 対策:Node 追加 or Recreate 戦略に変更 Pod アンチアフィニティにより 新しい Pod を配置できない
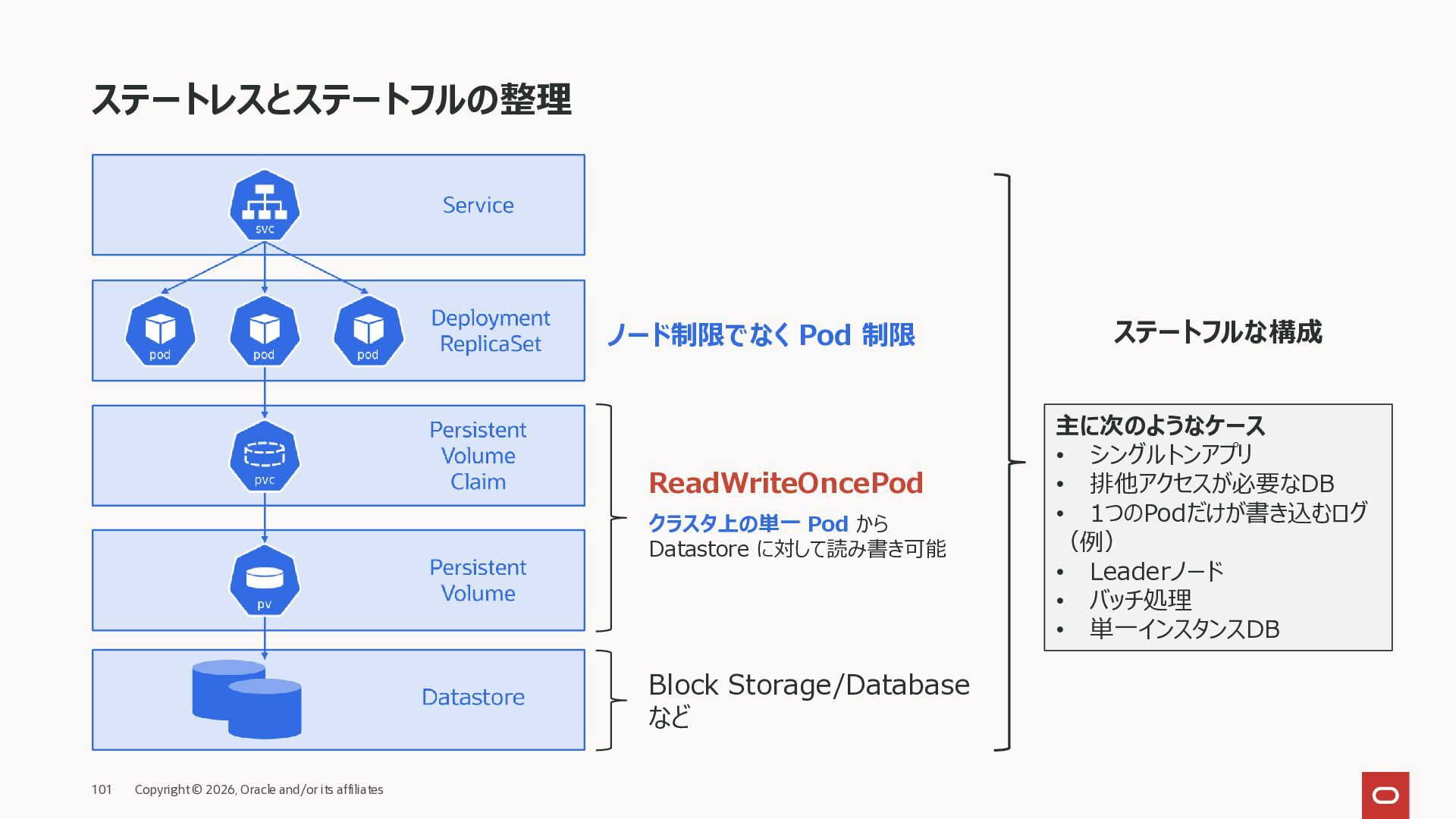
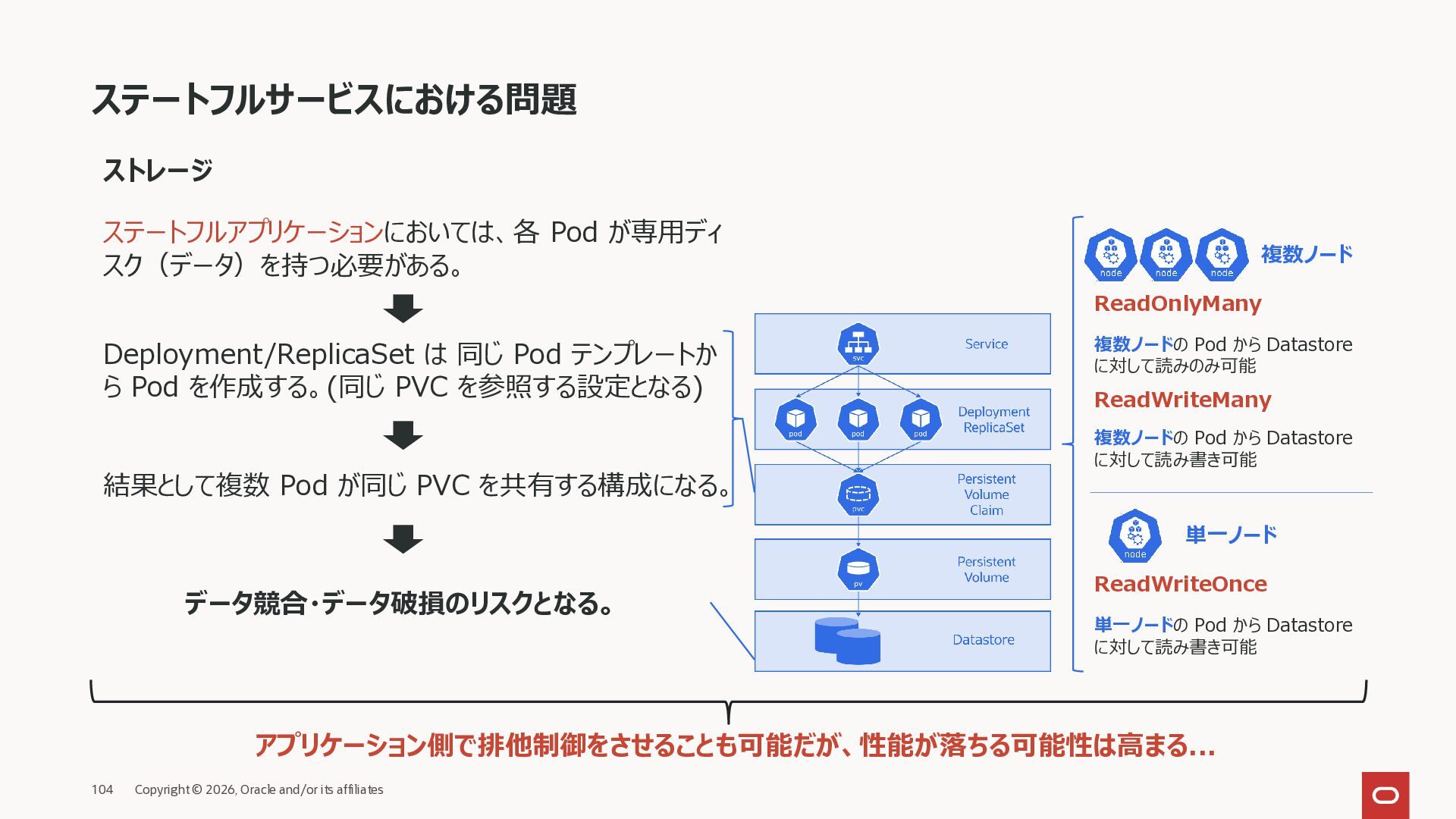
停止することがある • 新しく作り直される • 名前 • ホスト名 • IP アドレス ※ ReplicaSet 配下の Pod Pod 再作成時に変わる • 固定 IP(ClusterIP)を持つ • Pod が変わっても IP は変わらない • 複数の Pod へ自動で負荷分散する クライアント Service は、 通信を Pod に 振り分ける
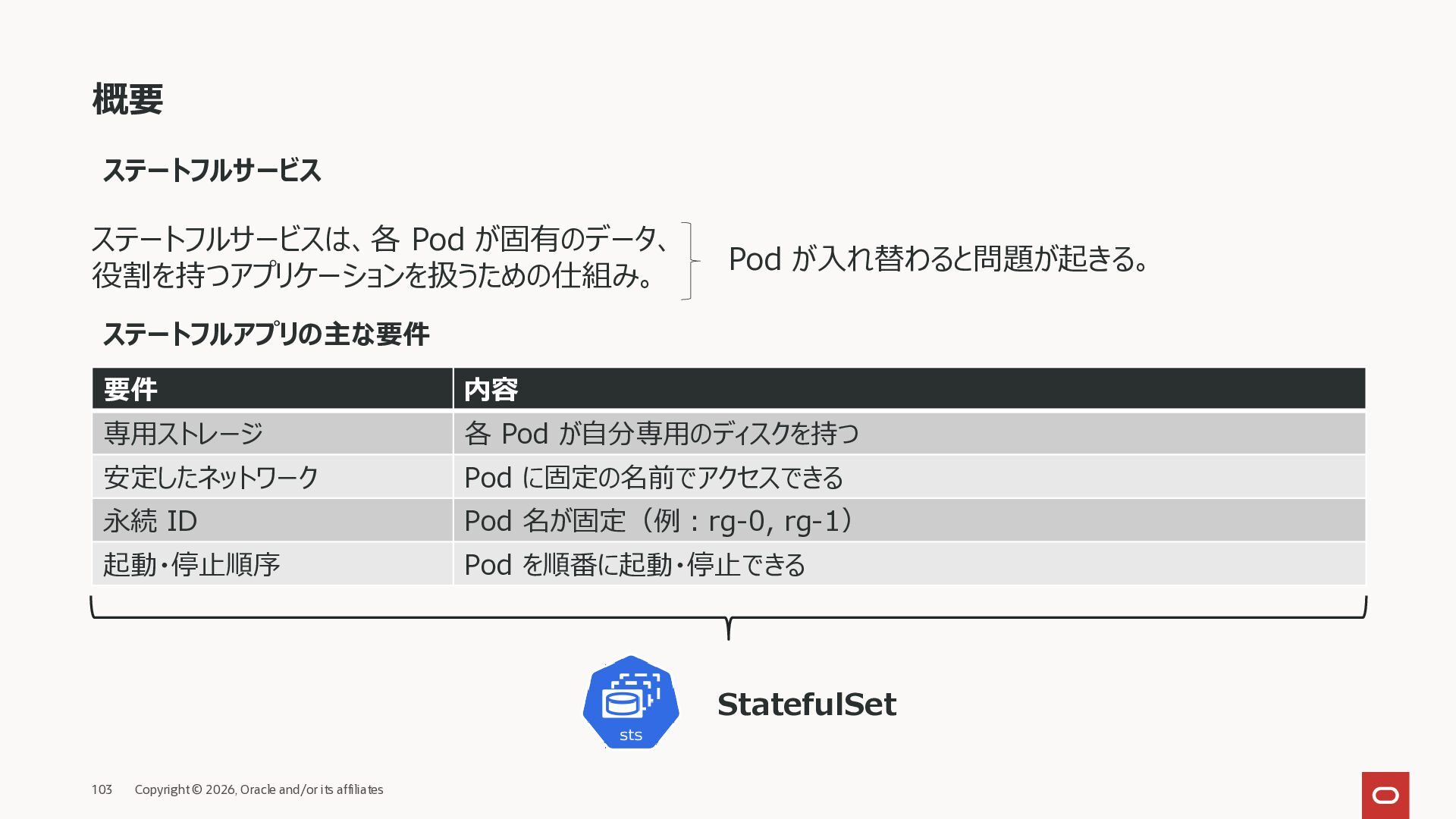
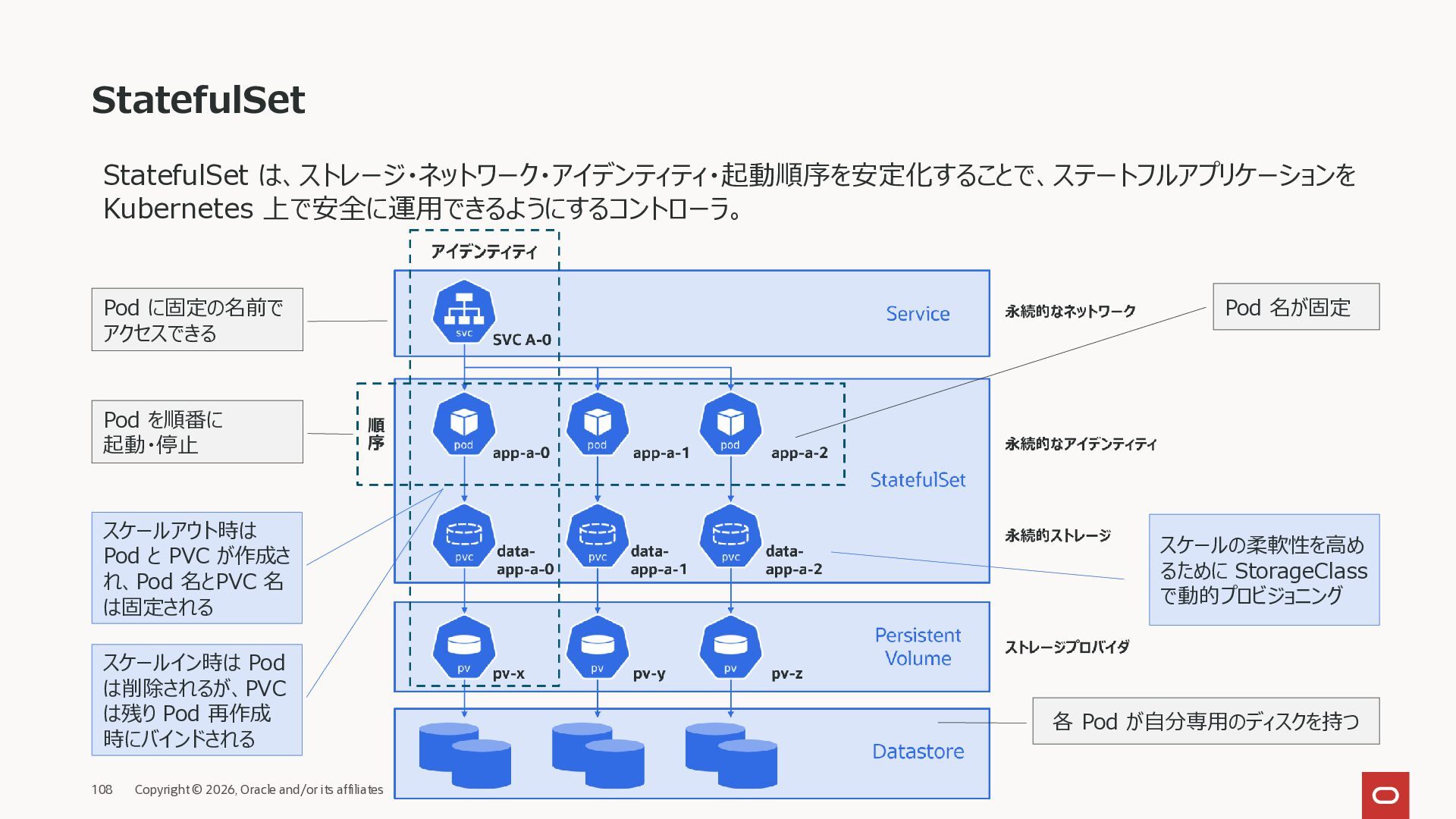
ステートフルサービスは、各 Pod が固有のデータ、 役割を持つアプリケーションを扱うための仕組み。 Pod が入れ替わると問題が起きる。 ステートフルアプリの主な要件 要件 内容 専用ストレージ 各 Pod が自分専用のディスクを持つ 安定したネットワーク Pod に固定の名前でアクセスできる 永続 ID Pod 名が固定(例:rg-0, rg-1) 起動・停止順序 Pod を順番に起動・停止できる StatefulSet
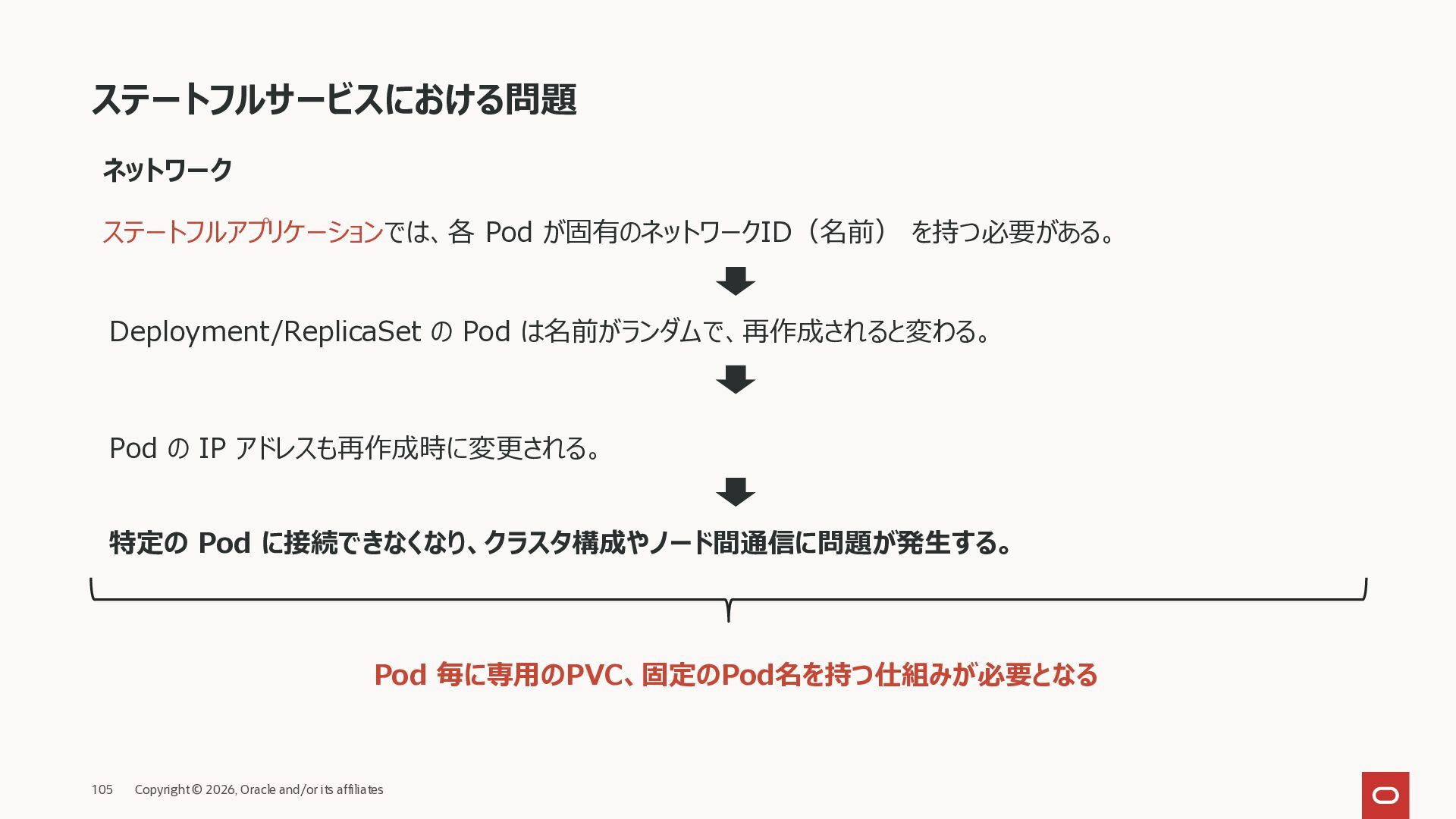
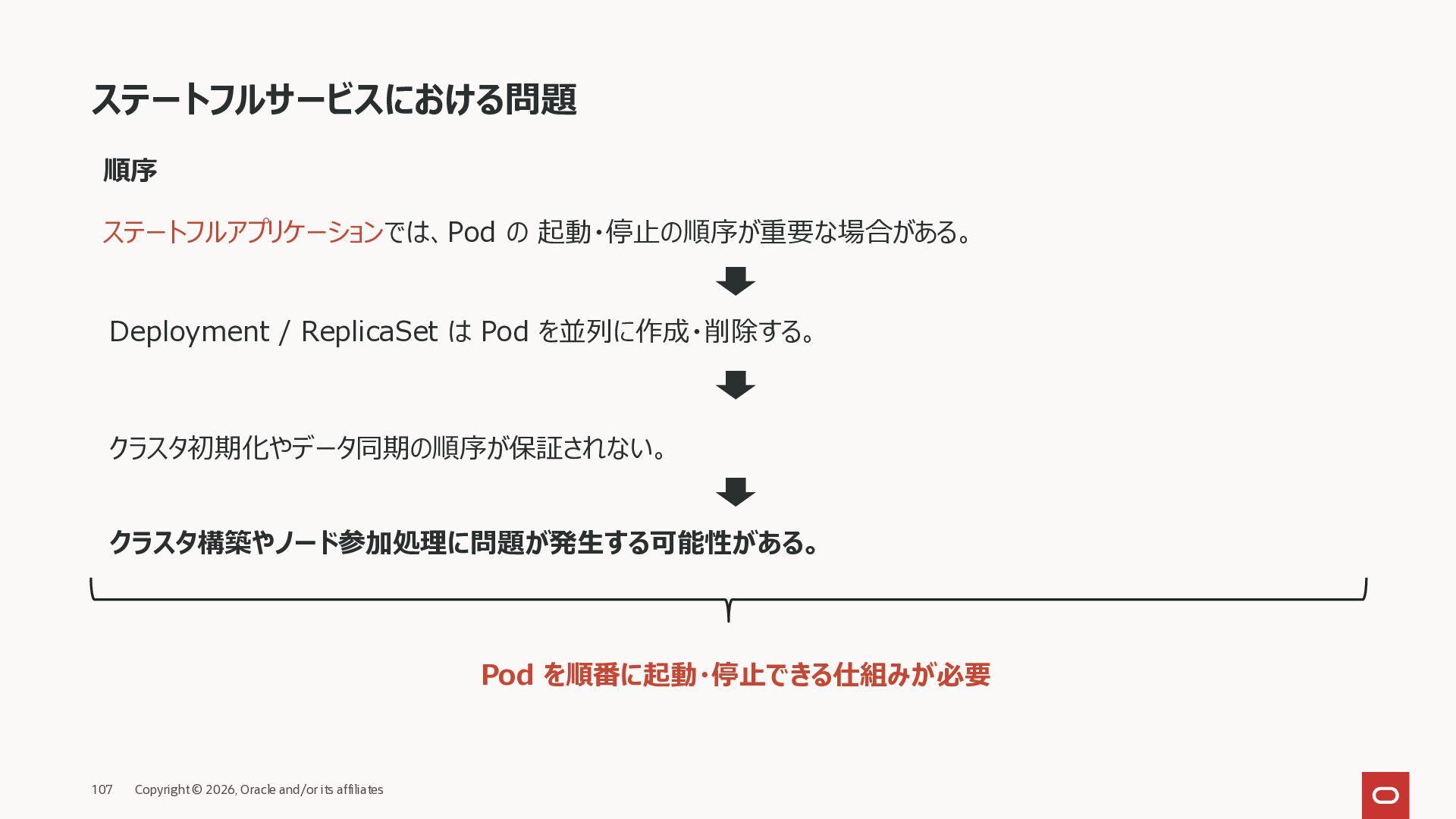
ステートフルアプリケーションでは、各 Pod が固有のネットワークID(名前) を持つ必要がある。 Deployment/ReplicaSet の Pod は名前がランダムで、再作成されると変わる。 Pod の IP アドレスも再作成時に変更される。 特定の Pod に接続できなくなり、クラスタ構成やノード間通信に問題が発生する。 Pod 毎に専用のPVC、固定のPod名を持つ仕組みが必要となる
ステートフルアプリケーションでは、各 Pod が 固定の識別子(ID) を持つ必要がある。 Deployment / ReplicaSet の Pod は再作成されると名前やインスタンスが入れ替わる。 Pod が入れ替わるとどの Pod がどの役割・データを持つのか識別できなくなる。 クラスタ構成・レプリケーション・ノード管理が破綻する可能性がある。 Pod に識別できる ID を付与する仕組みが必要
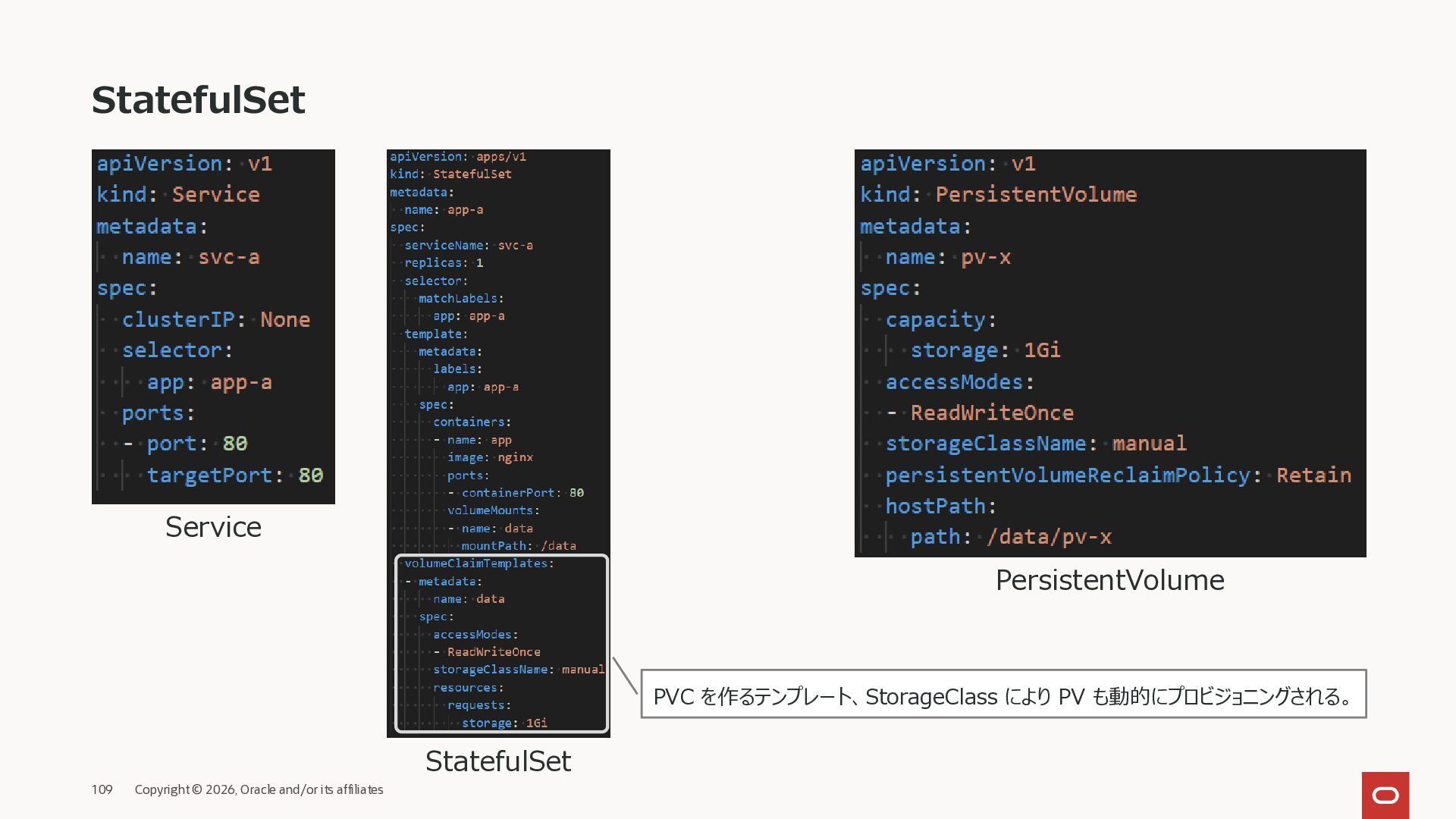
は、ストレージ・ネットワーク・アイデンティティ・起動順序を安定化することで、ステートフルアプリケーションを Kubernetes 上で安全に運用できるようにするコントローラ。 Pod に固定の名前で アクセスできる Pod を順番に 起動・停止 各 Pod が自分専用のディスクを持つ Pod 名が固定 スケールアウト時は Pod と PVC が作成さ れ、Pod 名とPVC 名 は固定される スケールイン時は Pod は削除されるが、PVC は残り Pod 再作成 時にバインドされる スケールの柔軟性を高め るために StorageClass で動的プロビジョニング
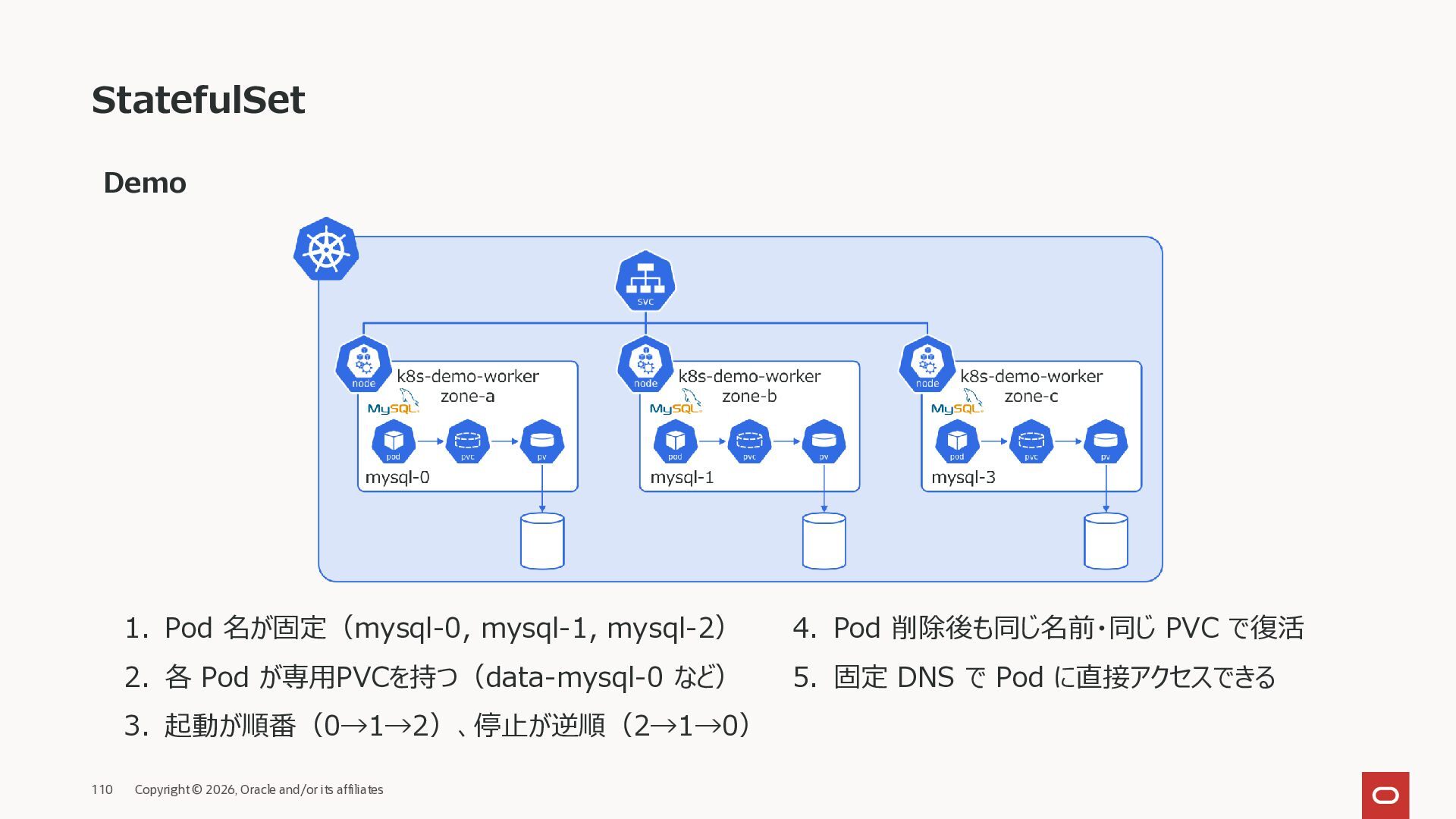
1. Pod 名が固定(mysql-0, mysql-1, mysql-2) 2. 各 Pod が専用PVCを持つ(data-mysql-0 など) 3. 起動が順番(0→1→2)、停止が逆順(2→1→0) 4. Pod 削除後も同じ名前・同じ PVC で復活 5. 固定 DNS で Pod に直接アクセスできる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
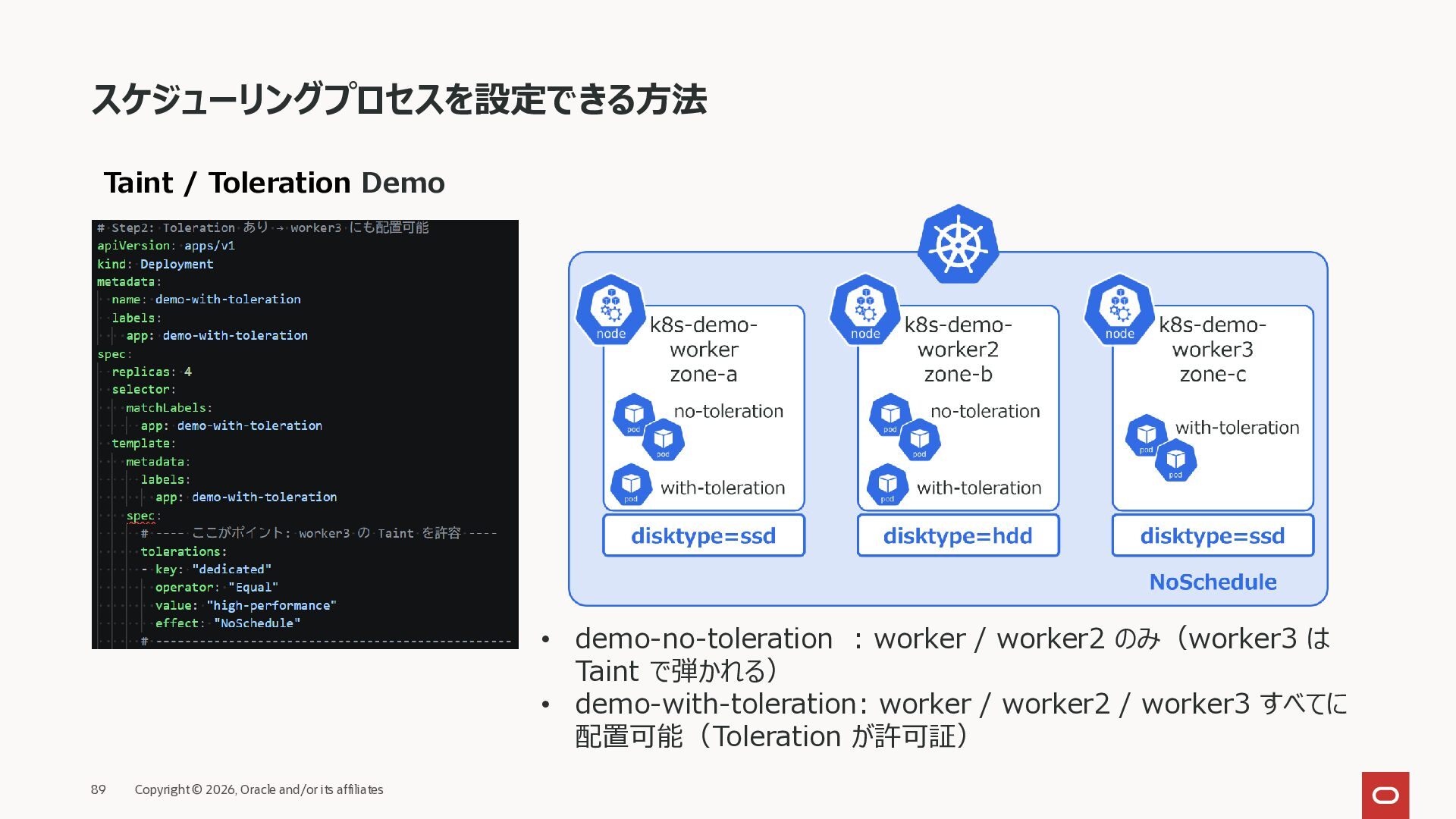{kind=link}
{kind=link}
{kind=link}
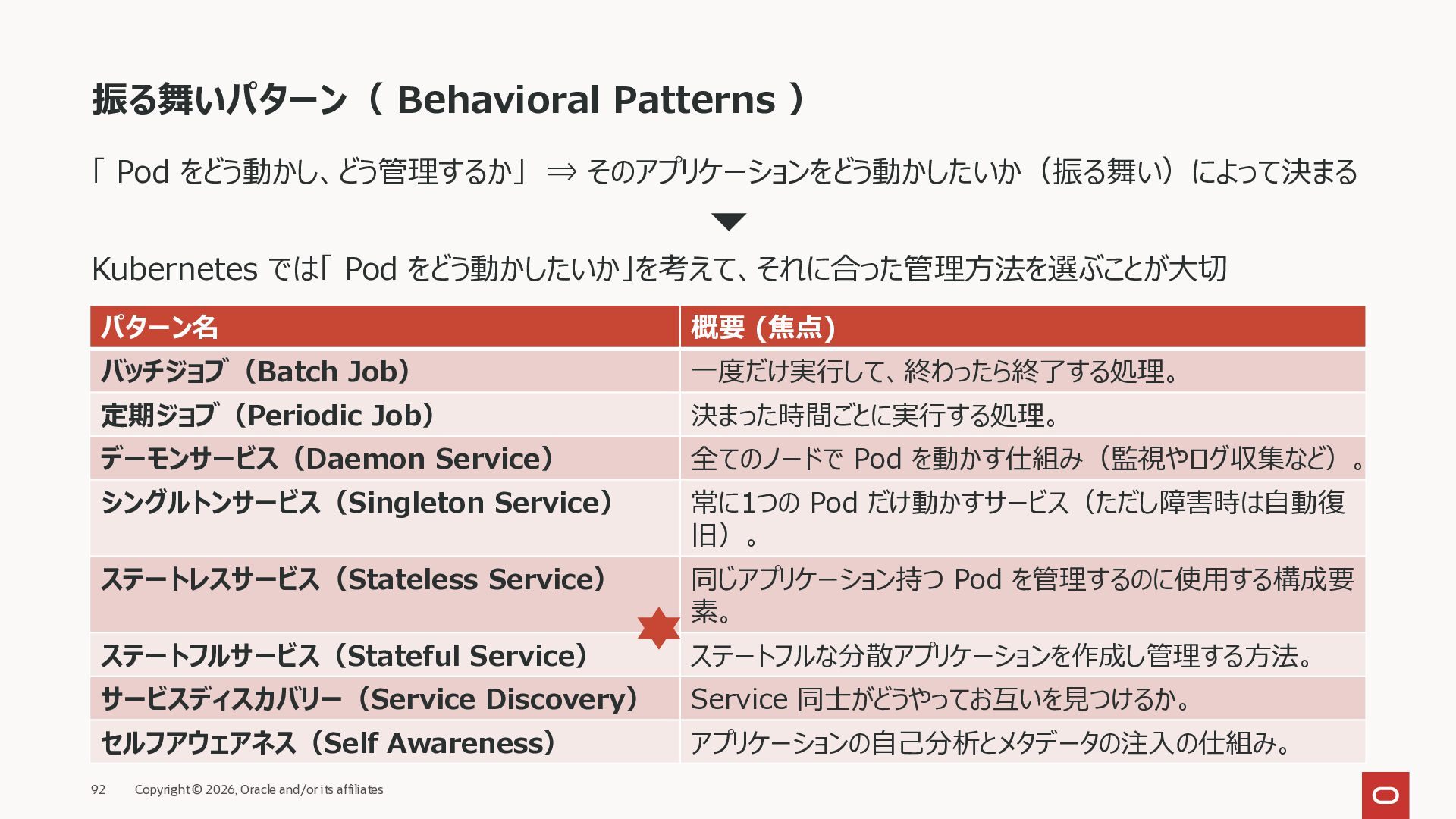{kind=link}
{kind=link}
{kind=link}
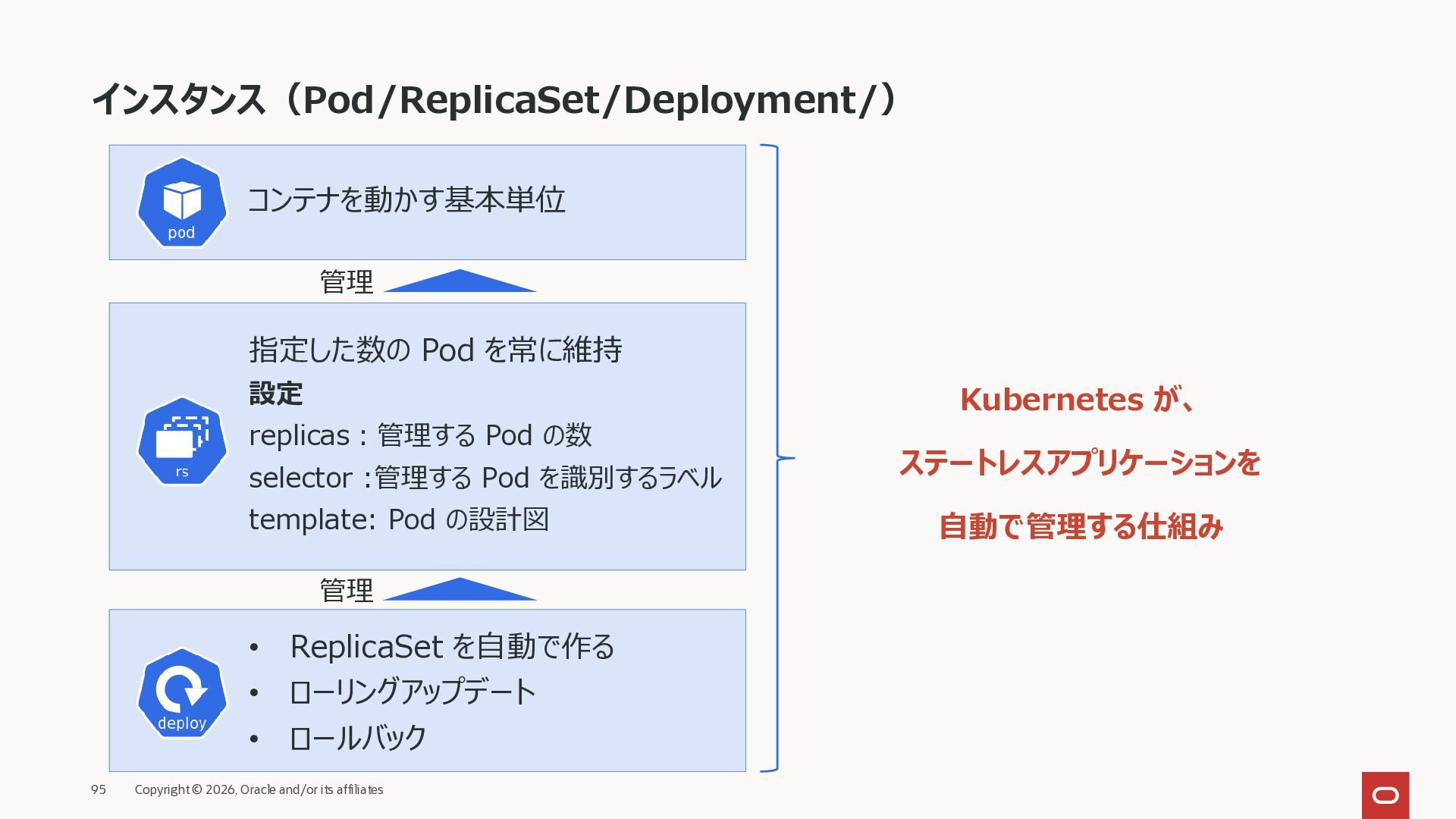{kind=link}
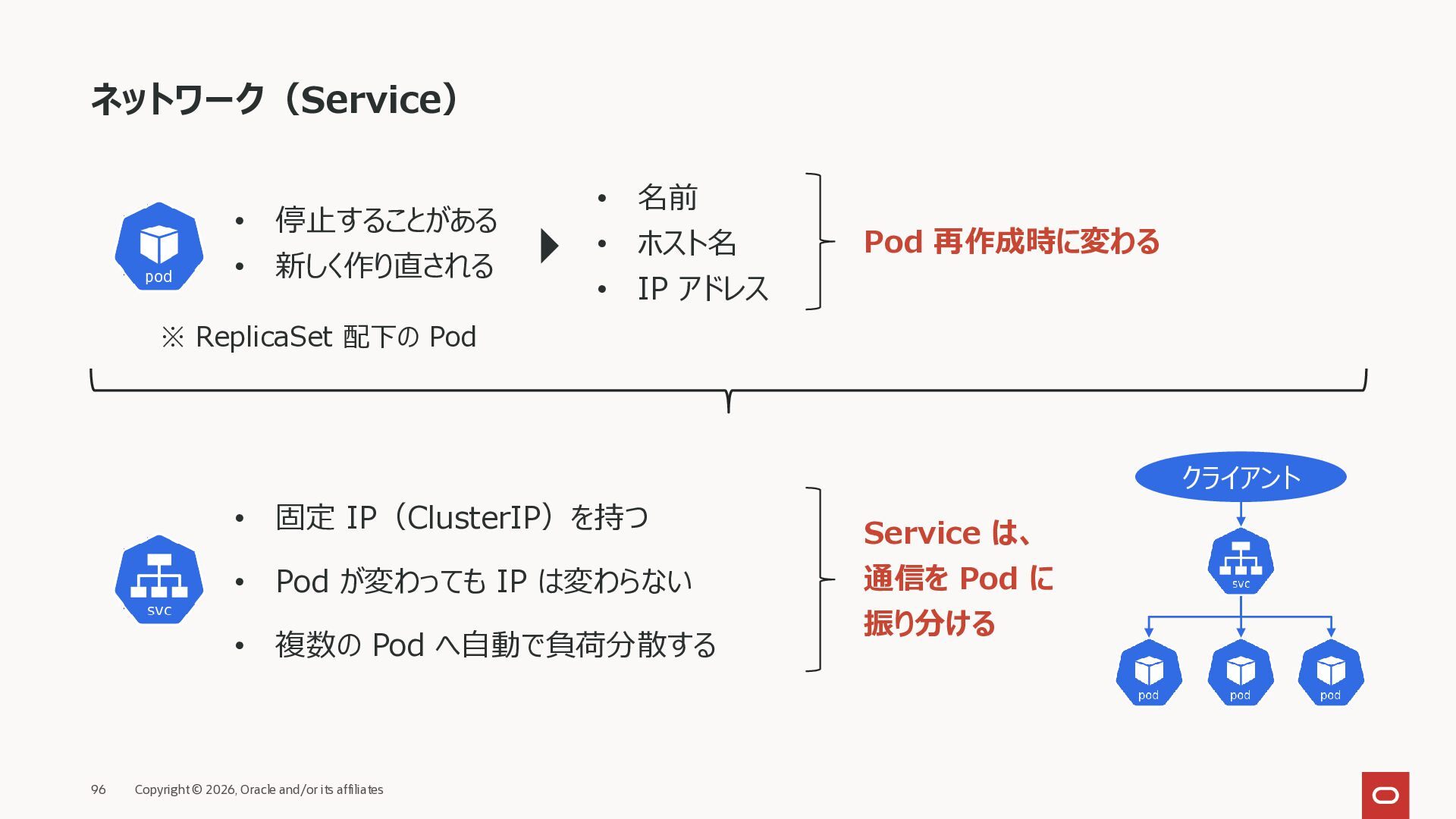{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}