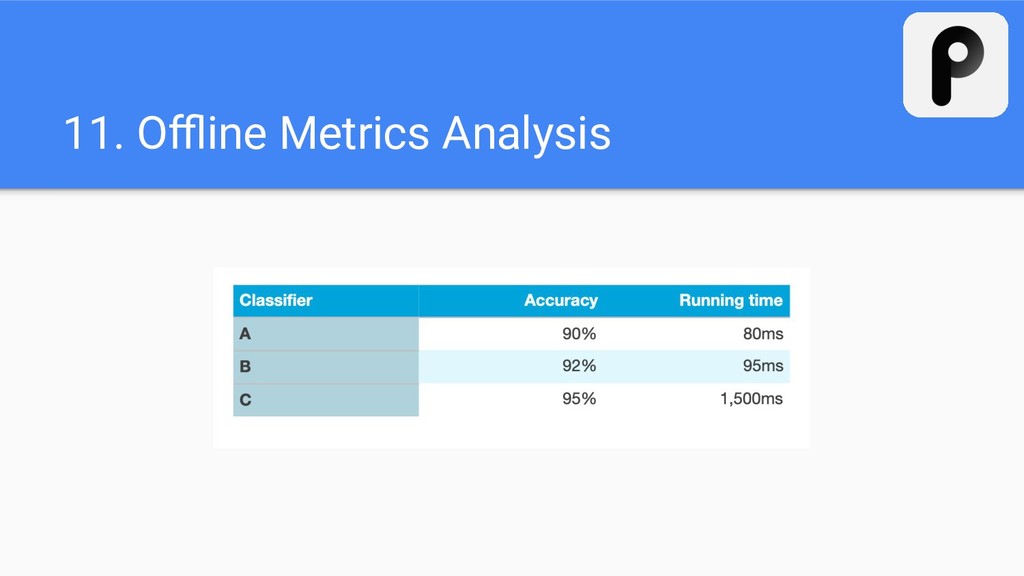
Metrics Analysis 12. Ablation and Error Analysis 13. Output Postprocessing 14. Model Explanation 15. A/B testing 16. Reproducible Research and Models 17. Model Deployment and Retraining Table of Contents
data generating process, user journey and business process (BP) in a company - You can create your ML services by automating any process in BP. - Verification process - Identification process - Scoring/estimation process - etc.
metrics for every ML service that you made - Be SKEPTICAL with your objective metrics - Every objective metrics needs to be correlated with business metrics
about top N recommendation - Change objective metrics to precision-recall as an information retrieval problem - Change objective metrics to top@K precision-recall - Decision-support metrics: - ROC AUC, Breese score, later precision/recall - Error meets decision-support/user experience: - “Reversals” - User-centered metrics: - Coverage, user retention, recommendation uptake, satisfaction
afraid to invest in fintech because they never had any experience in crises. - Bank Perkreditan Rakyat have data before and after the financial crises. - We need to build a Credit Scoring with 96-99 data to simulate a financial crises.
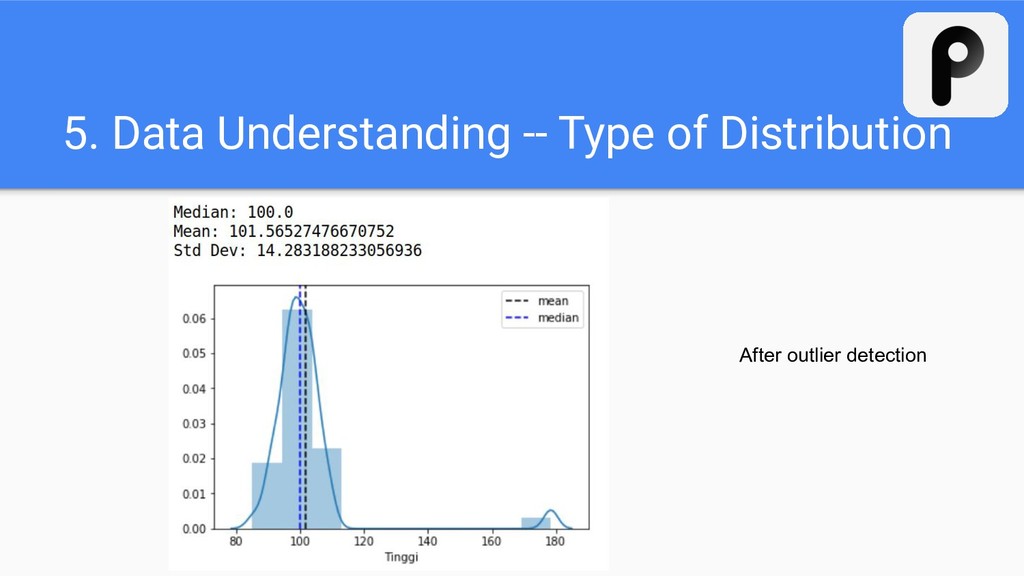
- We need to find patterns which might affect our model/objective metrics. - We need to find anomalies which will decrease our model accuracy. - In the next section, we can generate new variables from this understanding to ease our model to learn and fit.
more likely to post when they are Accepted. • They are likely to post results for multiple applications. • More successful candidates are likely to post their personal numbers. • Ostensibly, the quality of applicants who engage heavily with an online forum are far more serious about their application than the entirety of the test-taking pool, leading to better results/numbers. Sources: https://debarghyadas.com/writes/the-grad-school-statistics-we-never-had/
future data from our current dataset. - This simulation can help use to infer our model prediction power with future data. - Strictly speaking, it assumes a stable
fold as a validation set 2. Fit the model to the k-1 folds 3. Repeat those steps until you get k fitted models 4. Then, compute the CV Score as, 10. Cross Validation -- K-fold
model, with best combination of Hyperparam which has the best CV Score. 2. Then, build your final model by fitting the selected model into the whole training data. 10. Cross Validation
case: - We will focus on Diversity Metrics vs Accuracy Metrics. - More diverse recommendation will increase Netflix CTR - More accurate recommendation will increase Netflix CTR - Diversity and Accuracy are negatively correlated.
from classifier very often the result of ML classifier which not approximate probability in their model. For example, Random Forest calculate average class, SVM calculate distance from separator line.
are working with business stakeholders, you will be asked by business people the reasoning of model output. - This problem is related to ML Interpretability
learning model - Build preprocess and feature engineering which can be hitted by new data. - Deploy to your server as an API - Offline: - Train your model - Predict your data, write into DB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}