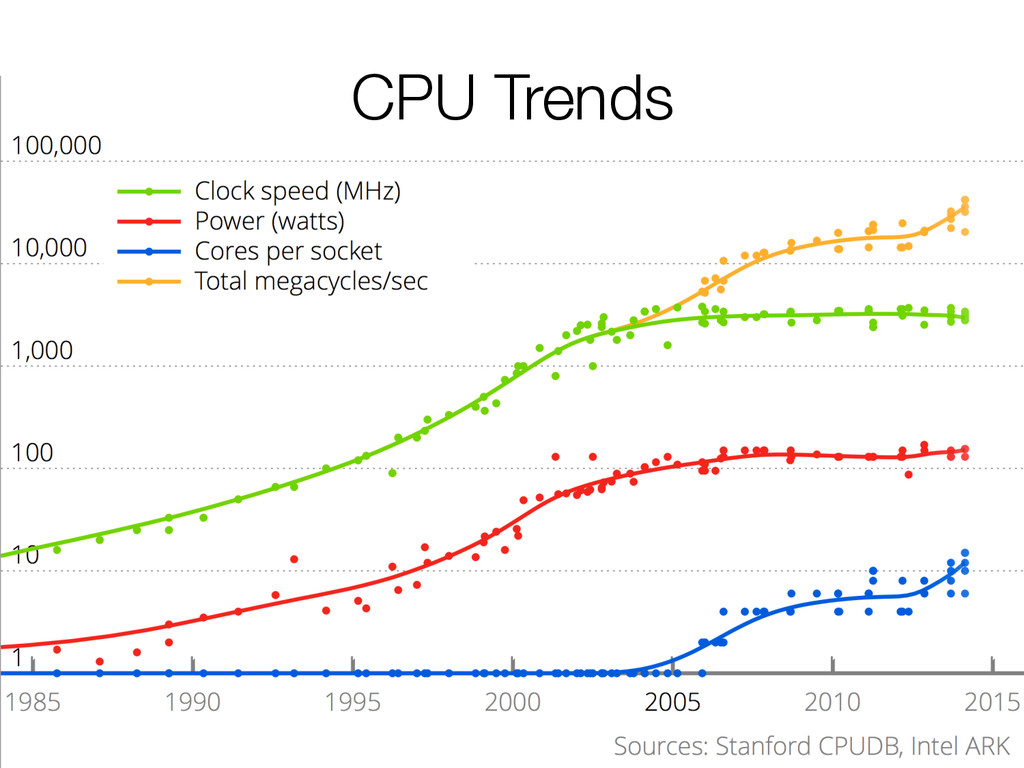
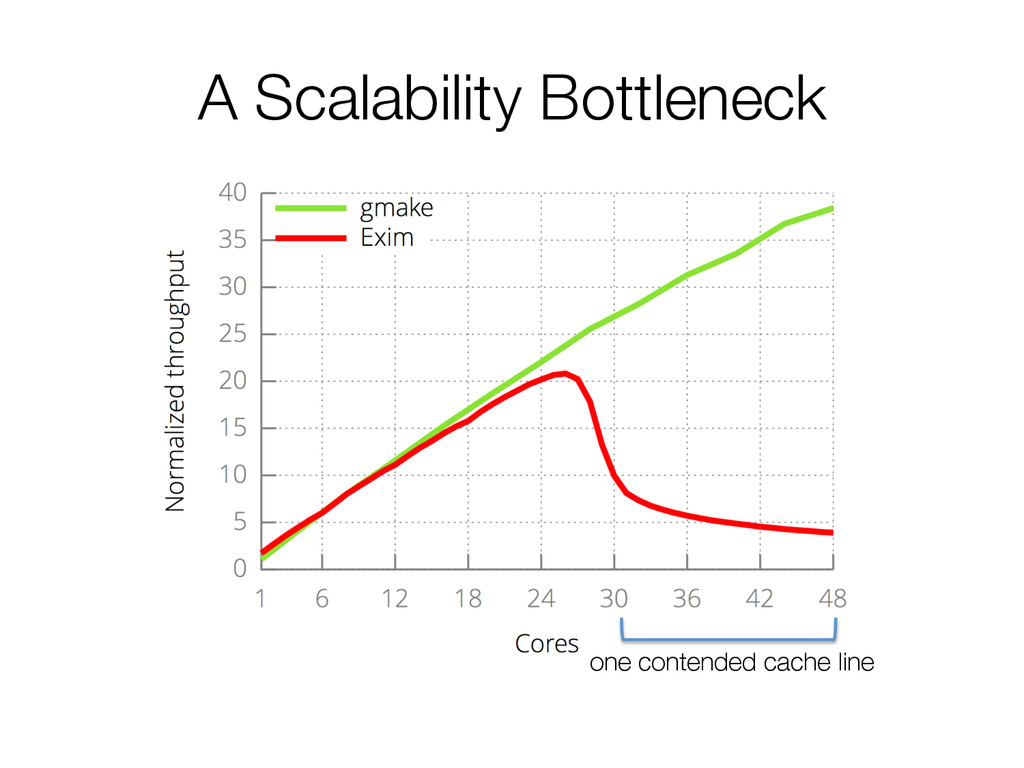
Moore's law is over, or at least, we won't be making programs go faster by running on faster processors, but instead by parallelizing our code to use more of them. Reasoning about concurrent code is difficult; but it's also very hard to understand whether your design has latent scalability bottlenecks until you can actually run it on many cores. And what if the problem is in your interface, instead of just the implementation?
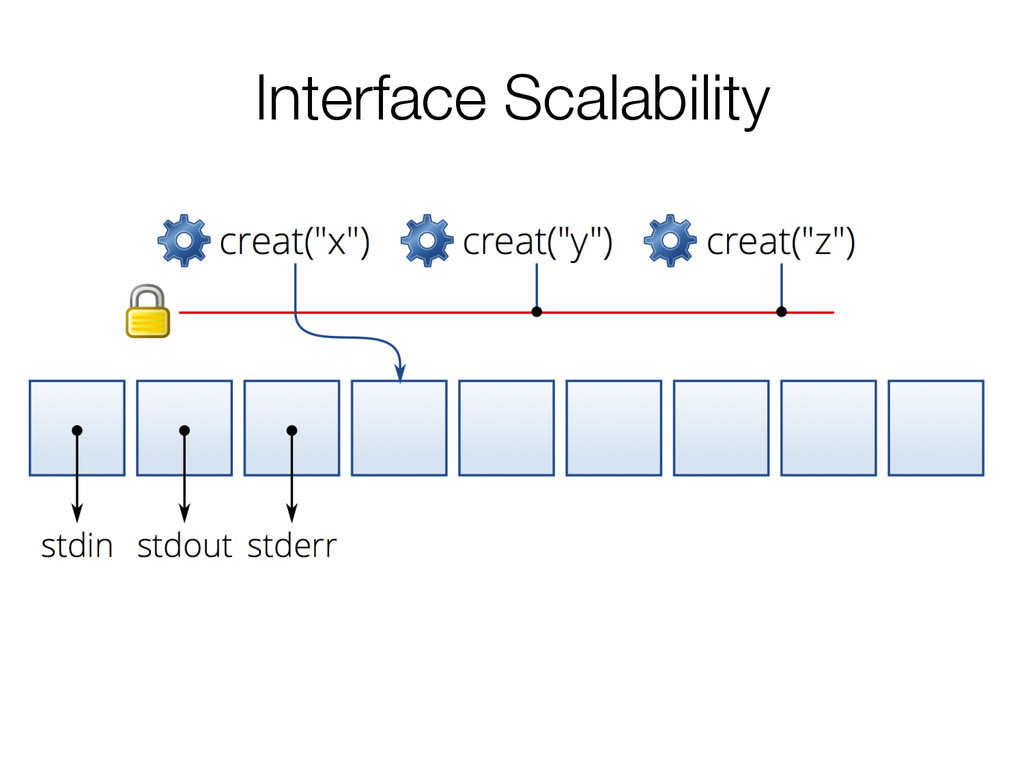
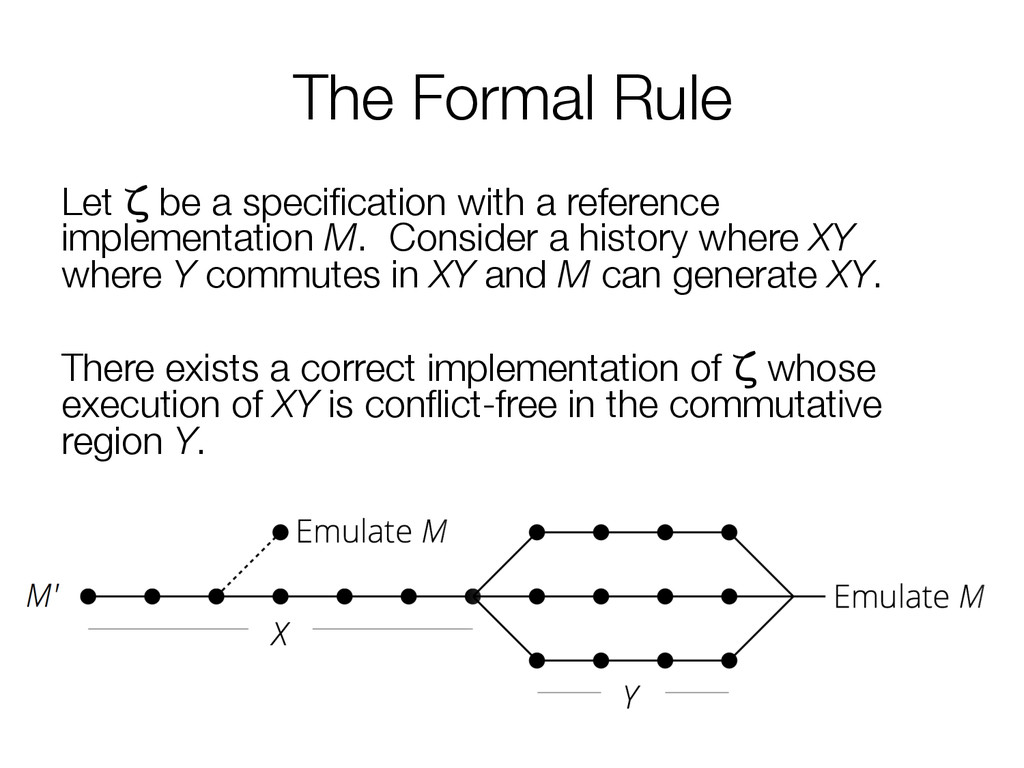
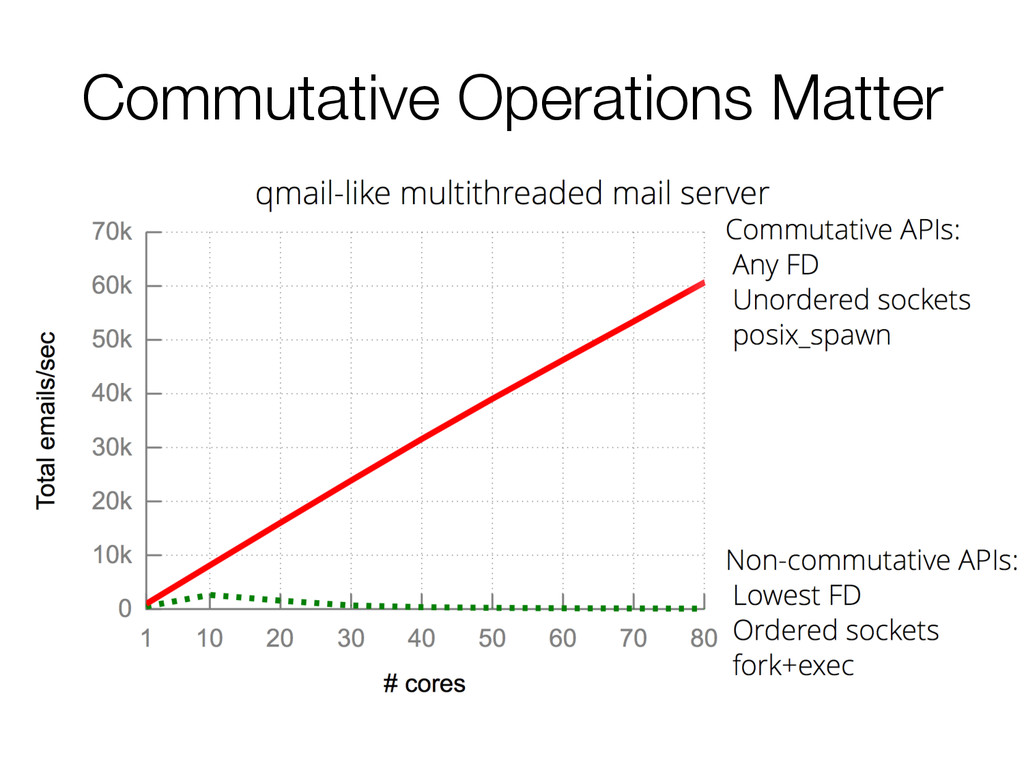
This paper presents a simple, elegant rule: whenever interface operations commute, they can be implemented in a way that scales.
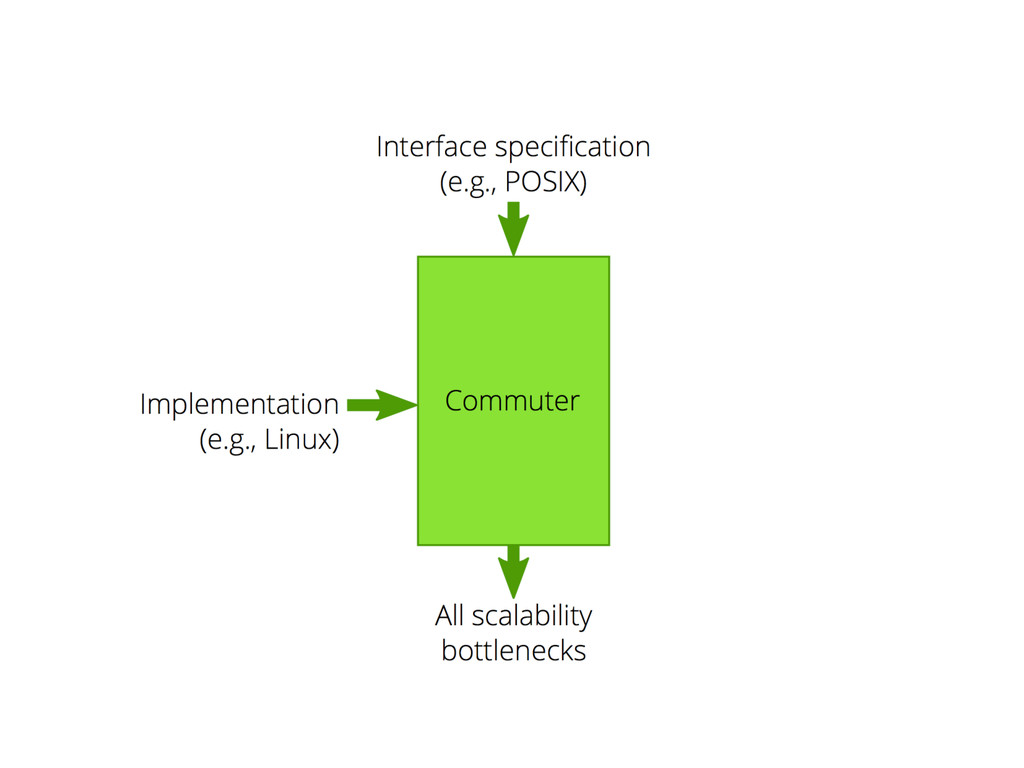
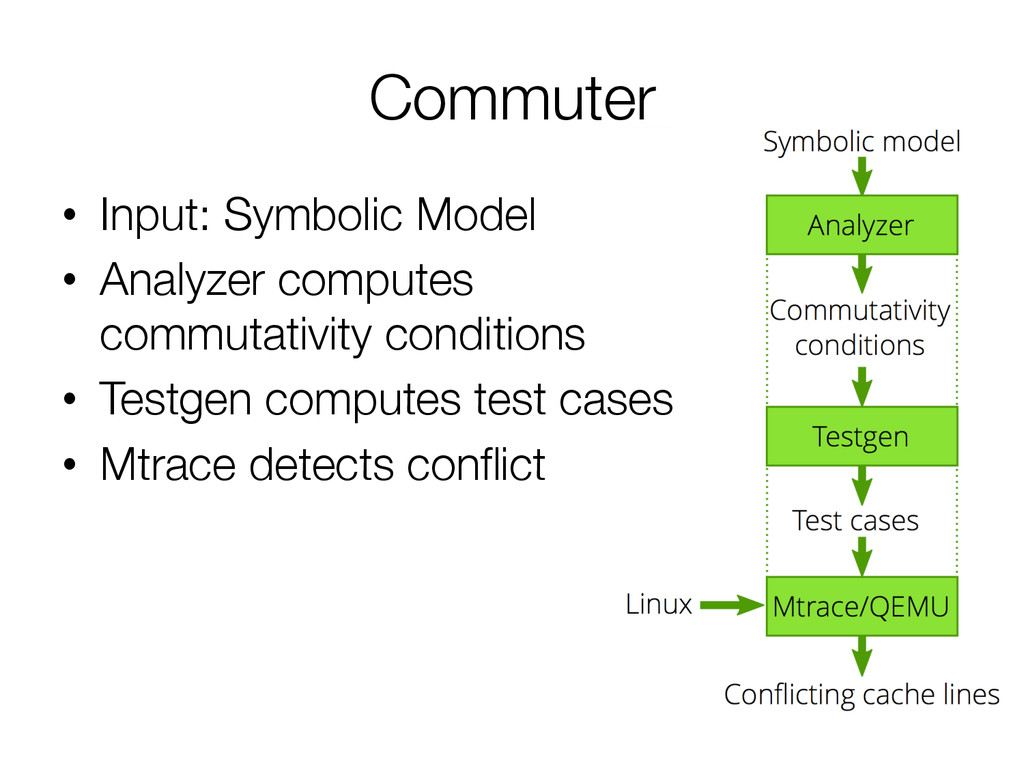
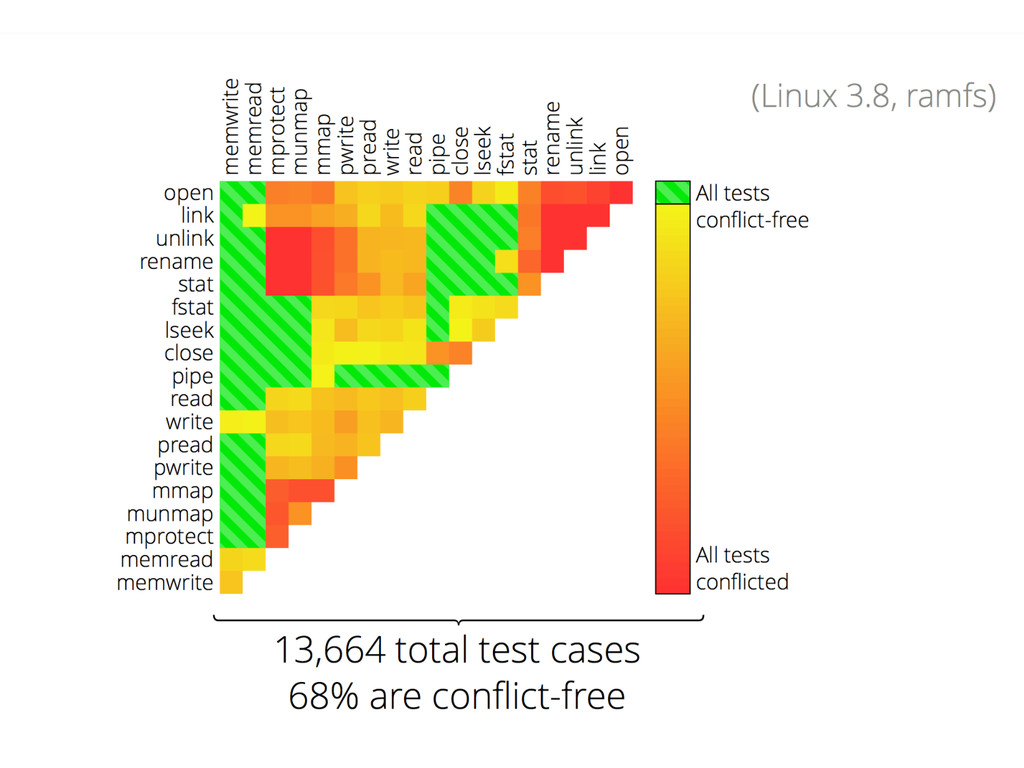
The authors apply this idea to Linux, and create a new operating system by using the rule, sv6. Their paper also comes with software, COMMUTER, which can help developers evaluate their interfaces to find opportunities for scaling.
This is a very powerful idea, and probably has applications in other areas like distributed systems. In this talk I'll present the paper, and speculate a bit about where else this research could be useful.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}