Mirage? (⼤規模⾔語モデルの創発的な能⼒は幻想か︖) n ⼤規模⾔語モデルが持つとされる創発能⼒ (Emergent Abilities)がモデルの能⼒ではなく 評価指標によってもたらされている可能性を ⽰唆する論⽂ n Outstanding Main Track Papersに選定 https://blog.neurips.cc/2023/12/11/announcing-the-neurips-2023-paper-awards/
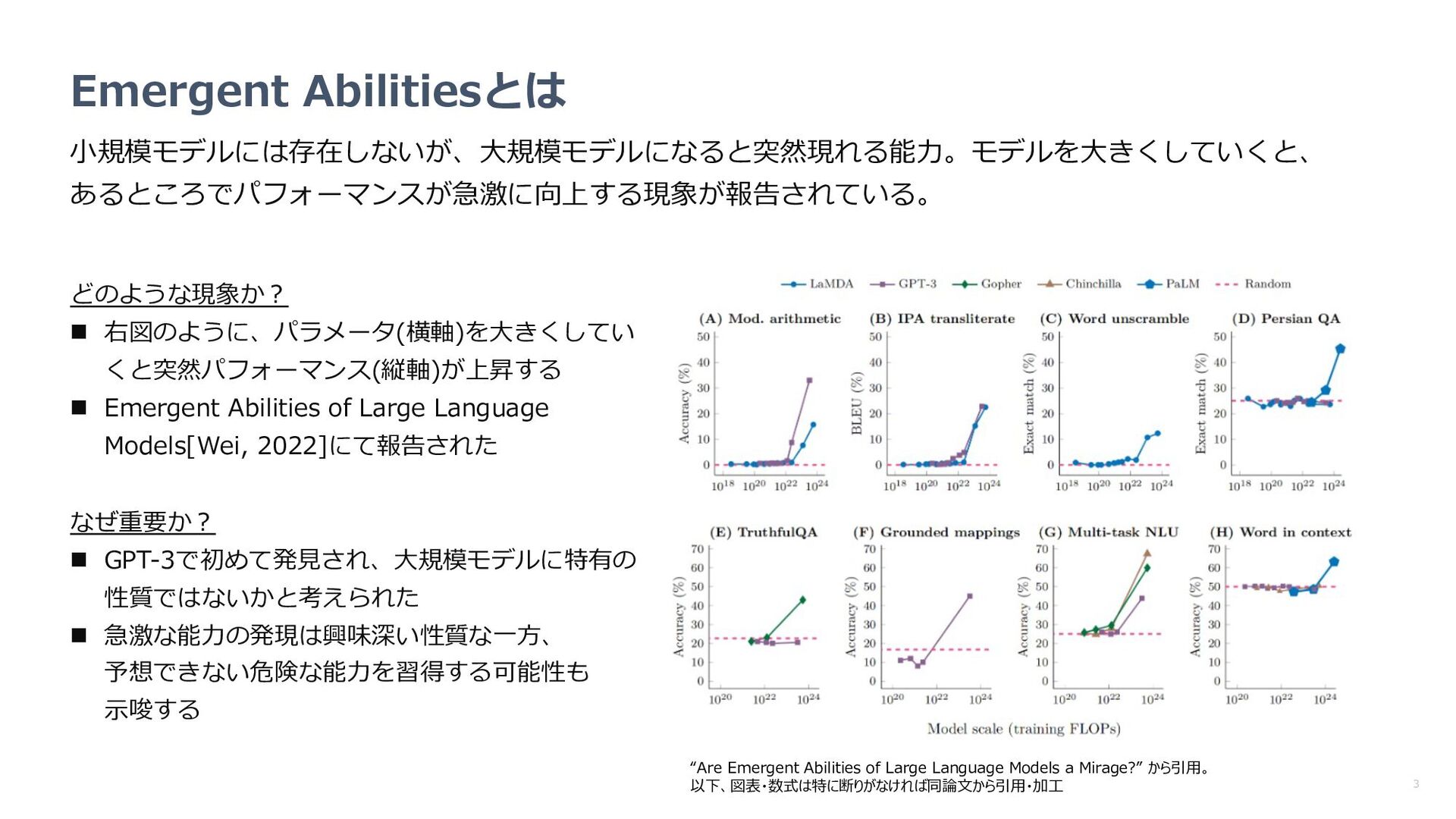
Emergent Abilities of Large Language Models[Wei, 2022]にて報告された なぜ重要か︖ n GPT-3で初めて発⾒され、⼤規模モデルに特有の 性質ではないかと考えられた n 急激な能⼒の発現は興味深い性質な⼀⽅、 予想できない危険な能⼒を習得する可能性も ⽰唆する “Are Emergent Abilities of Large Language Models a Mirage?” から引⽤。 以下、図表・数式は特に断りがなければ同論⽂から引⽤・加⼯
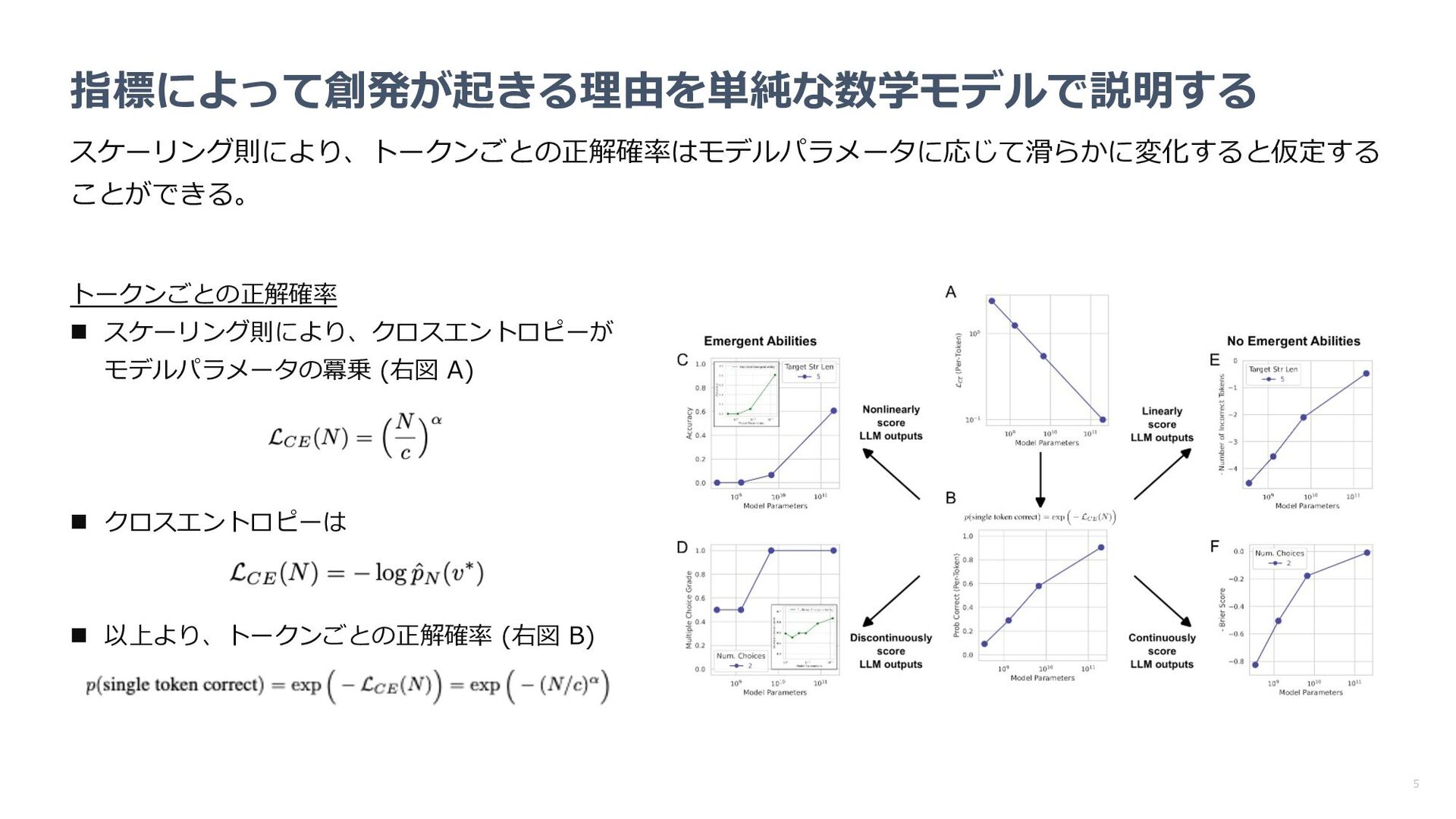
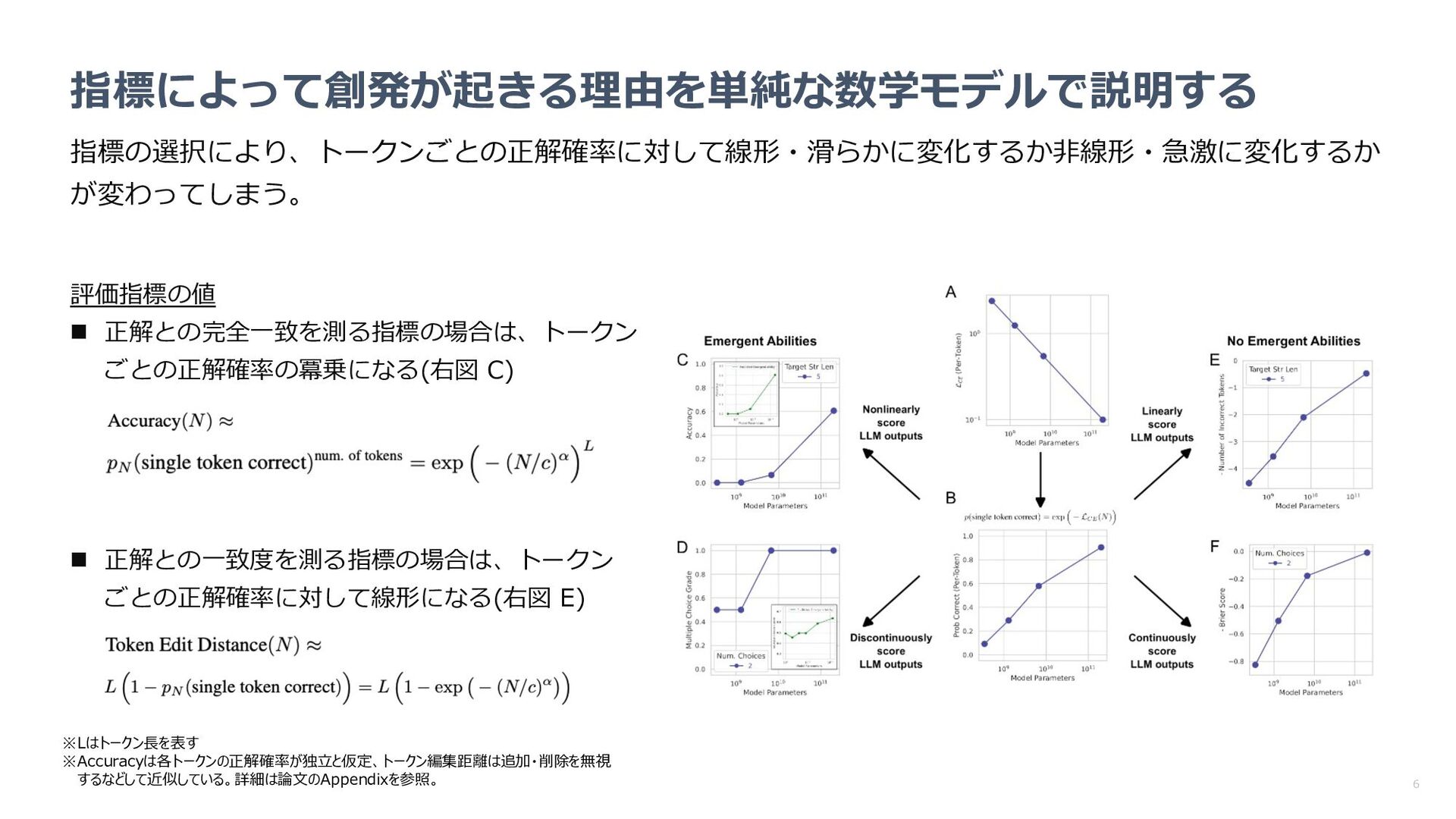
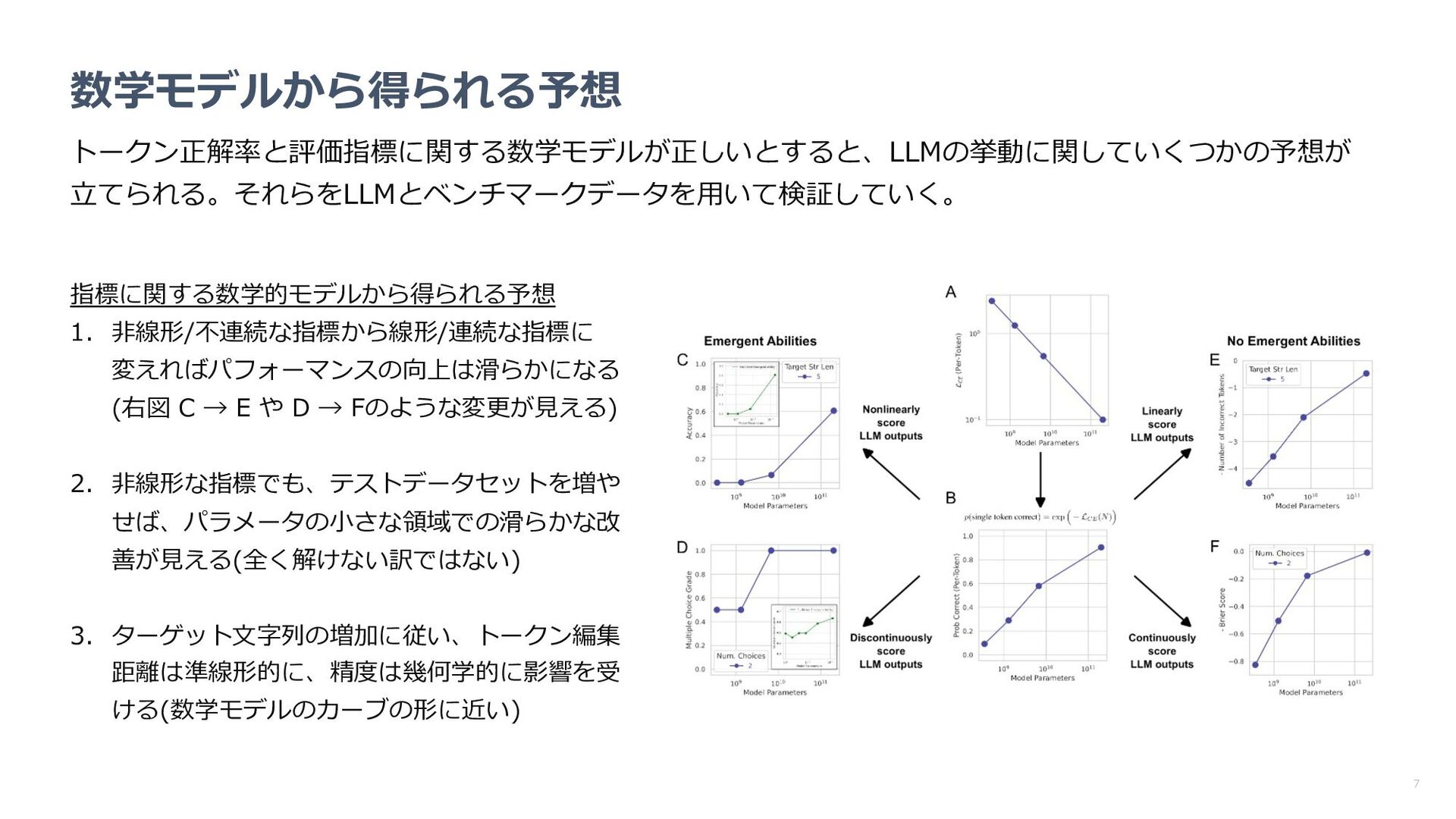
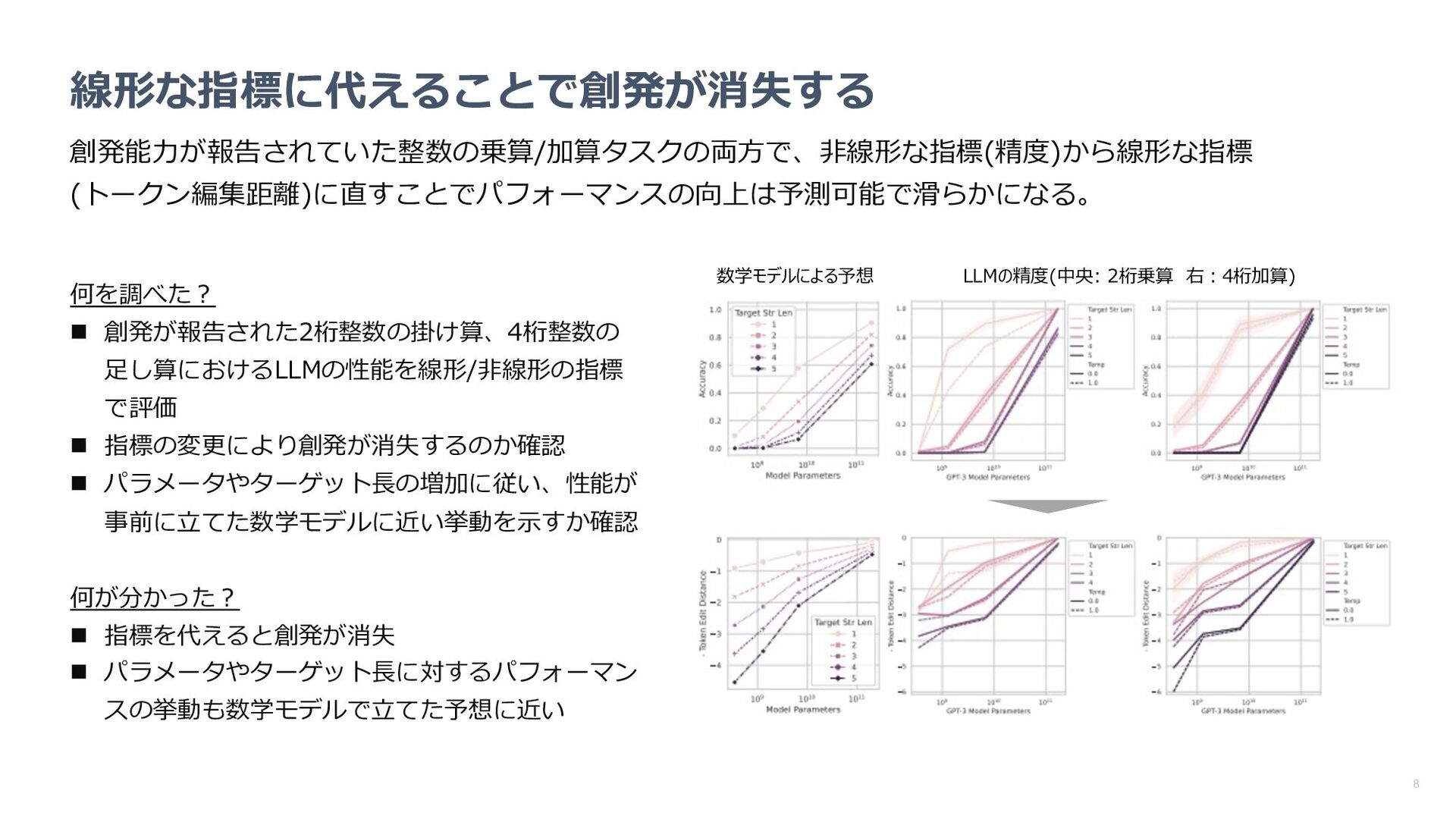
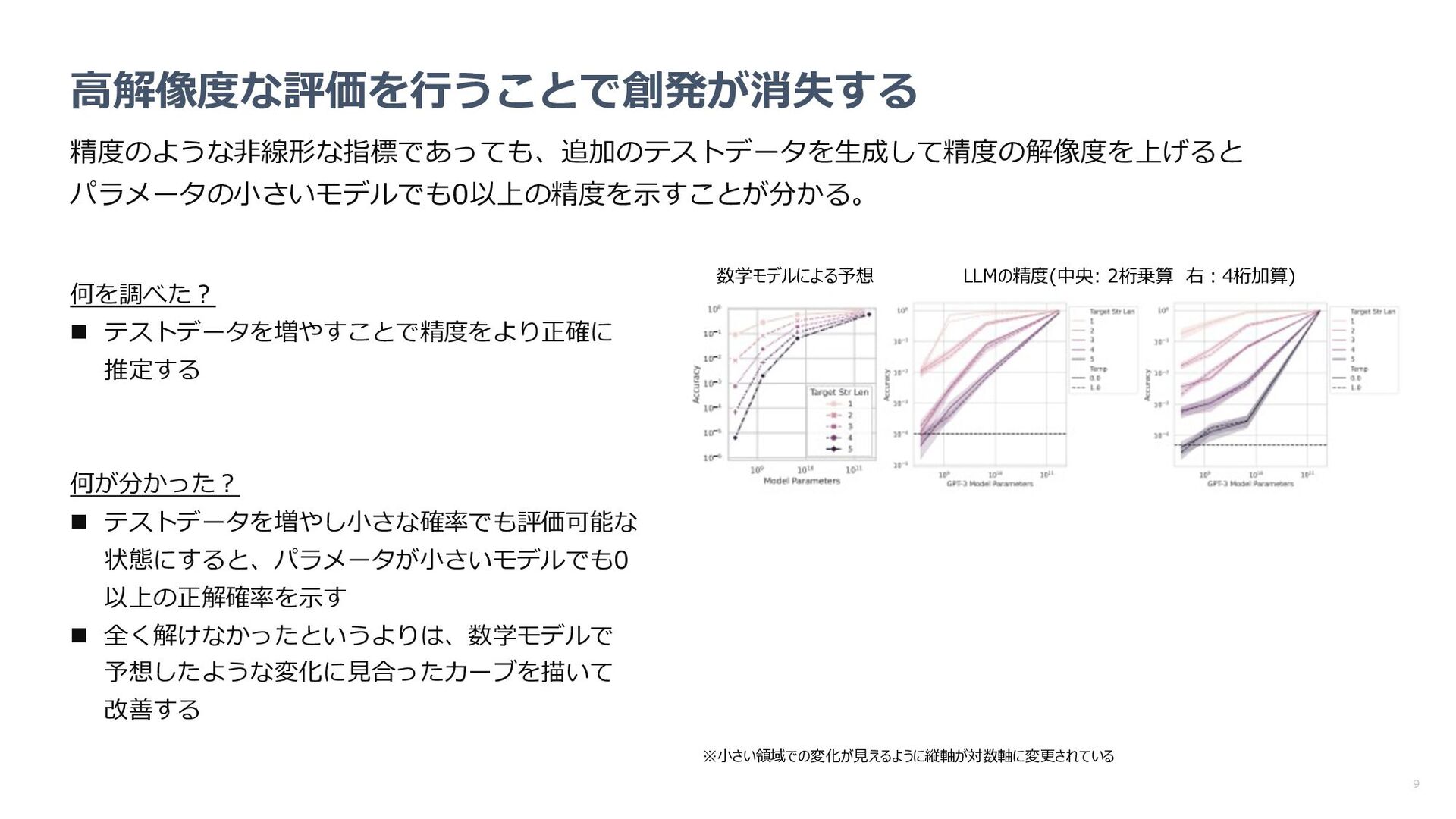
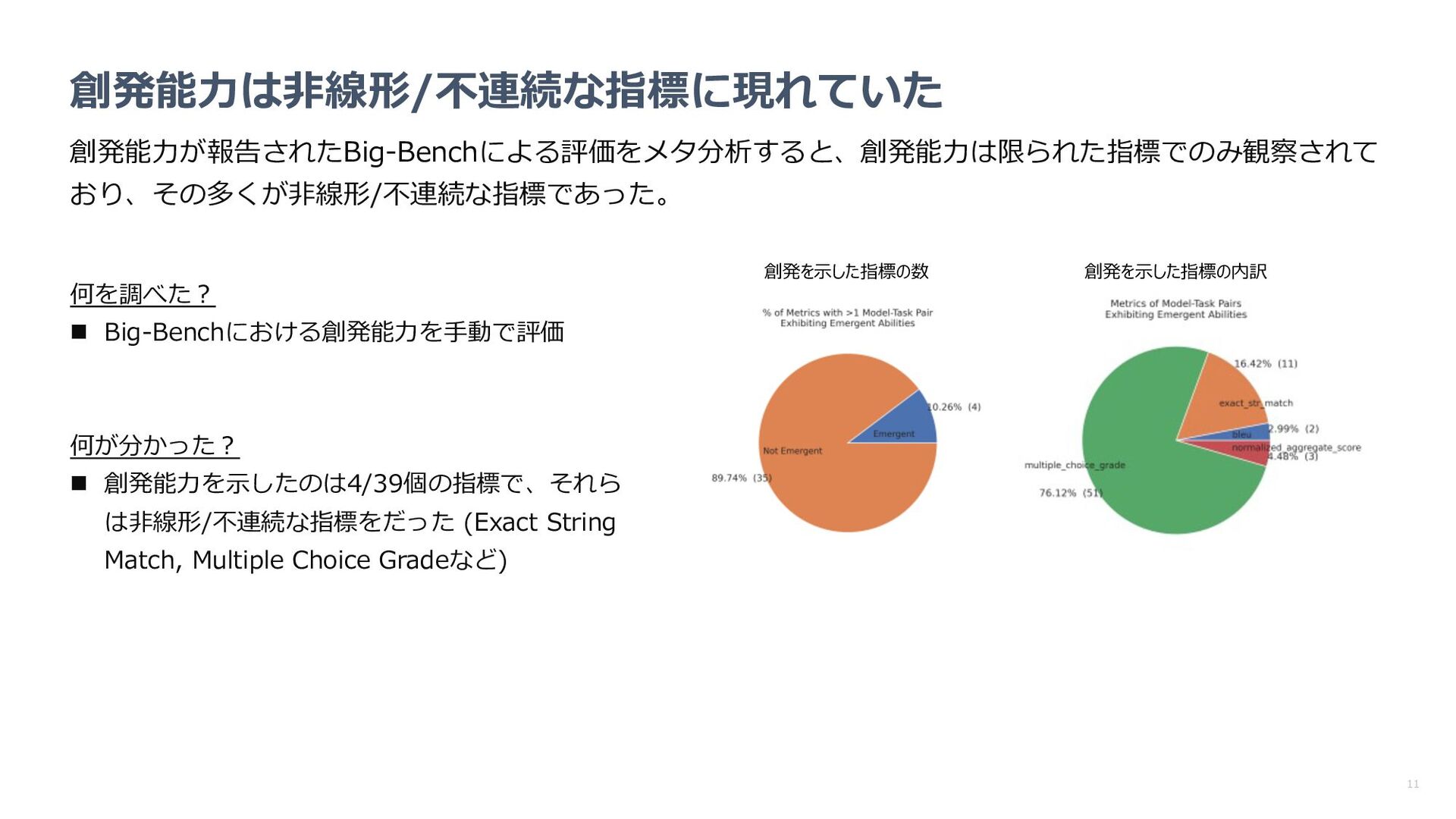
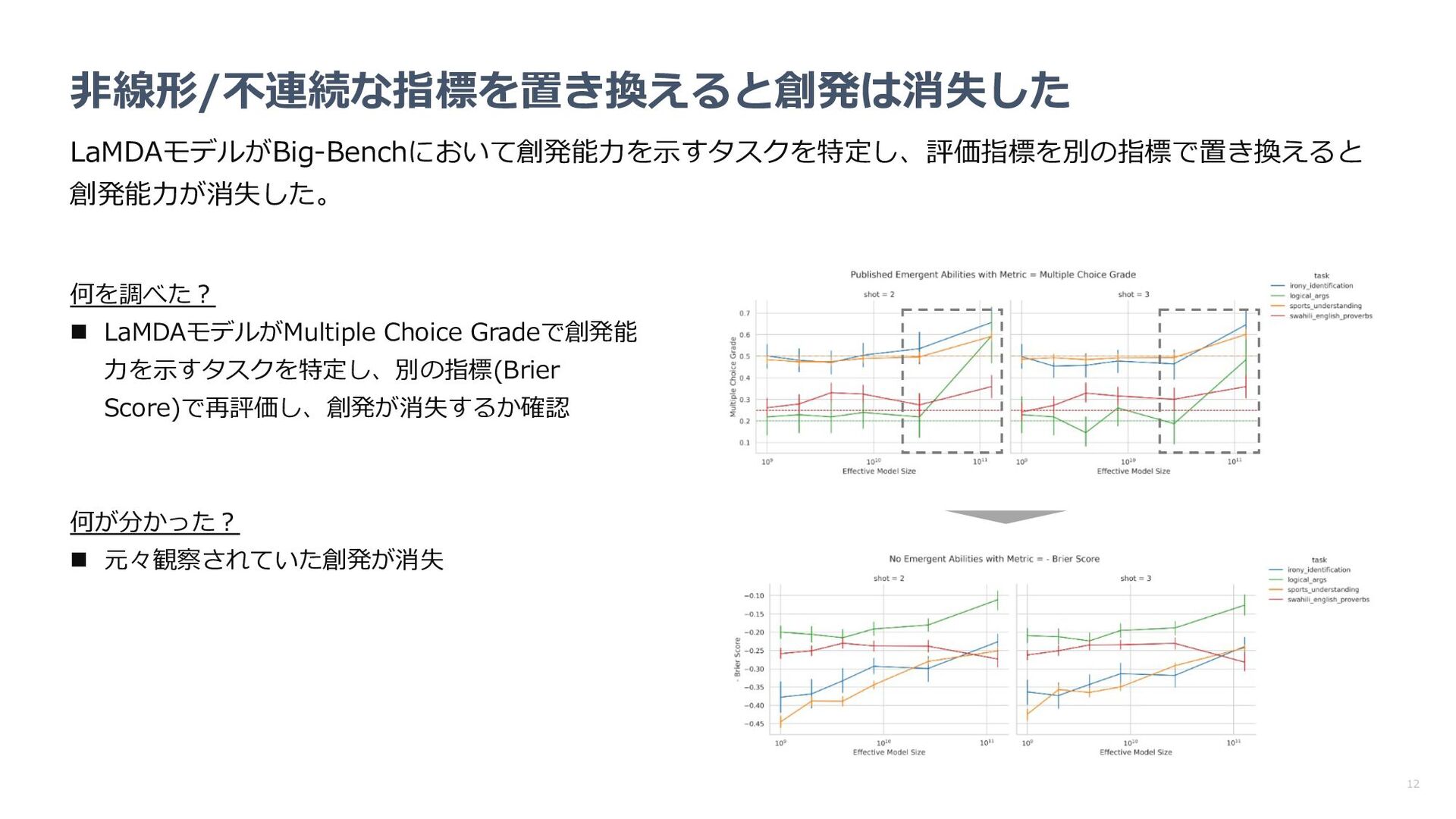
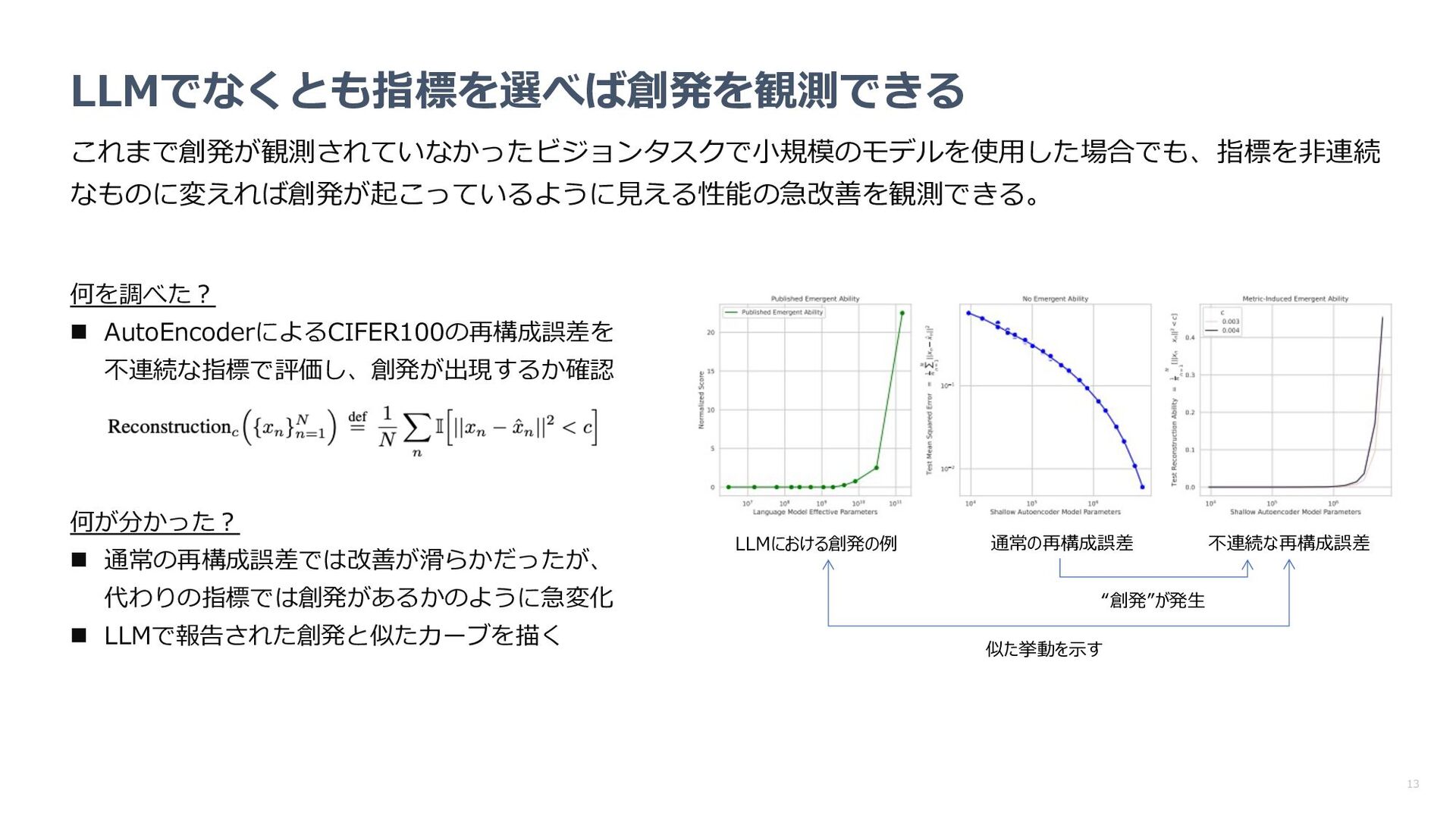
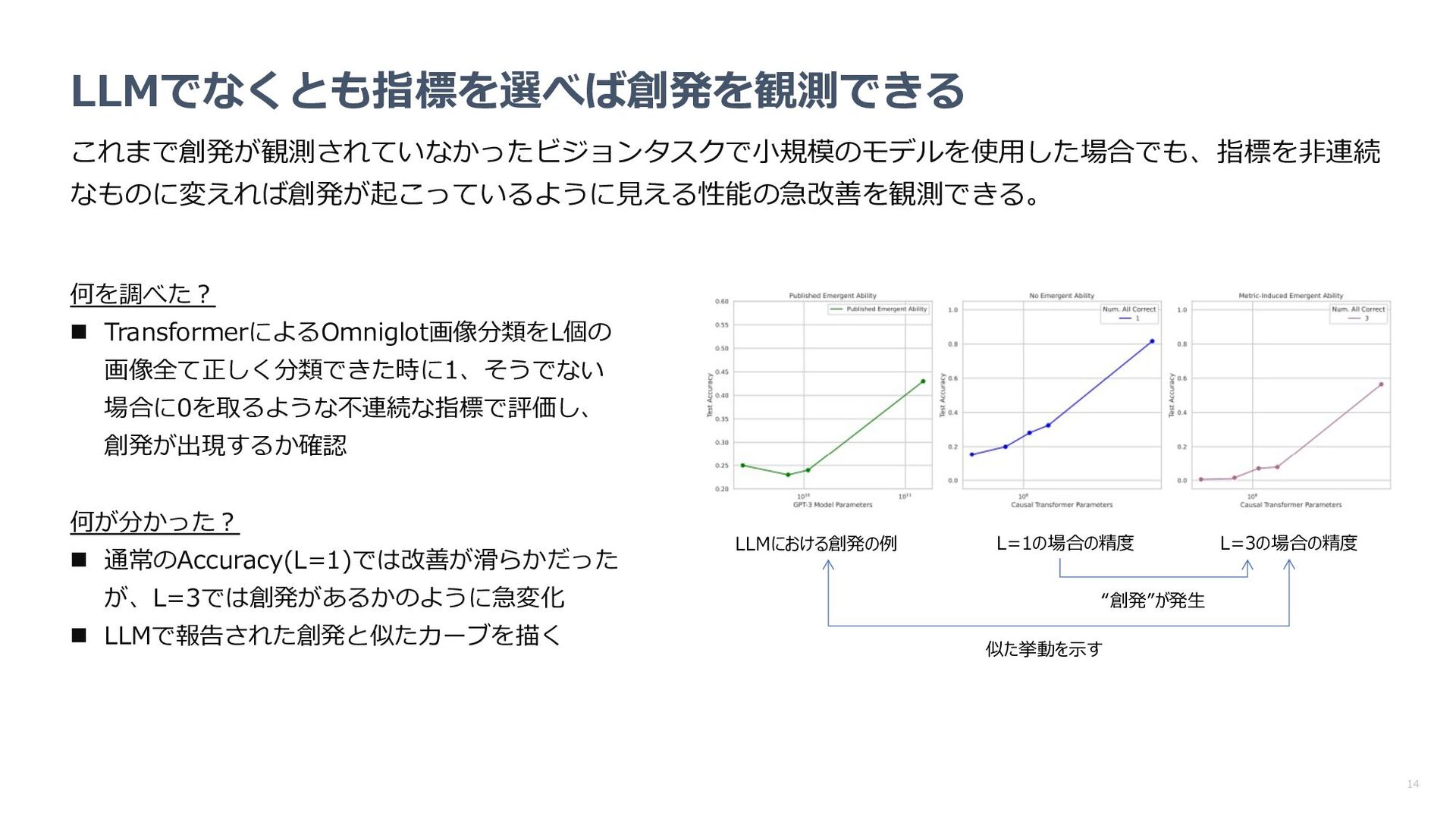
指標の変更により創発が消失するのか確認 n パラメータやターゲット⻑の増加に従い、性能が 事前に⽴てた数学モデルに近い挙動を⽰すか確認 何が分かった︖ n 指標を代えると創発が消失 n パラメータやターゲット⻑に対するパフォーマン スの挙動も数学モデルで⽴てた予想に近い 数学モデルによる予想 LLMの精度(中央: 2桁乗算 右︓4桁加算)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}