Peeters Verd. 1 82 G. Mahlerplein 1082MA Amsterdam Nederland Nicolas Peeters Gustav Mahlerplein, nr. 82 1082 MA Amsterdam Nicolas Peeters infohubble Sevilla Building Gustav Mahlerplein 1082MA Amsterdam
★ meet minimum requirements (hours / days) ★ we have some analysis of the matched structure to ensure there is enough raw information ★ if we detect multiple OHs, check equivalence OPENING HOURS
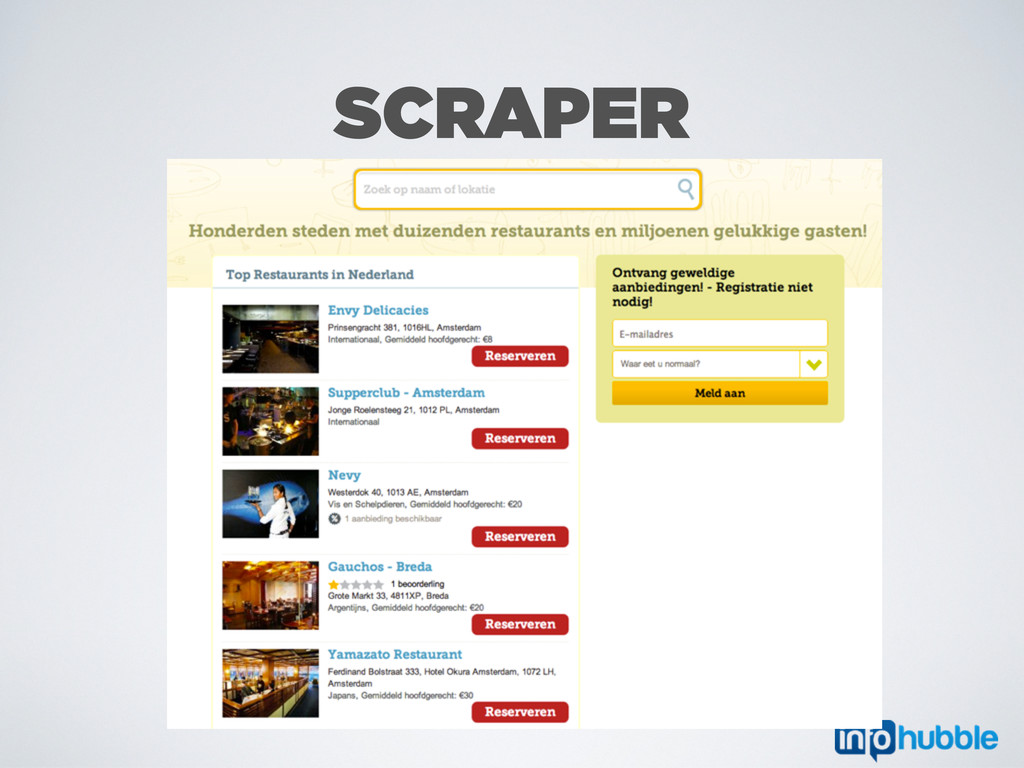
Mitte" • Generate brute-force the candidate URL http://www.pension-58-berlin-mitte.de, http://www.pension58berlinmitte.de, http://www.berlin-58- pension.de, http://www.berlin-pension-58.de, http://www.58-pension-berlin.de, http://www.pension- berlin-58.de, http://www.58-berlin-pension.de, http://www.pension-58-berlin.de, http:// www.berlin58pension.de, http://www.berlinpension58.de, http://www.pensionberlin58.de, http:// www.pension58berlin.de, http://www.58berlinpension.de, http://www.58pensionberlin.de, http:// www.pension-58-berlin-mitte.com ... • Verify that it belongs to the business by matching its base data
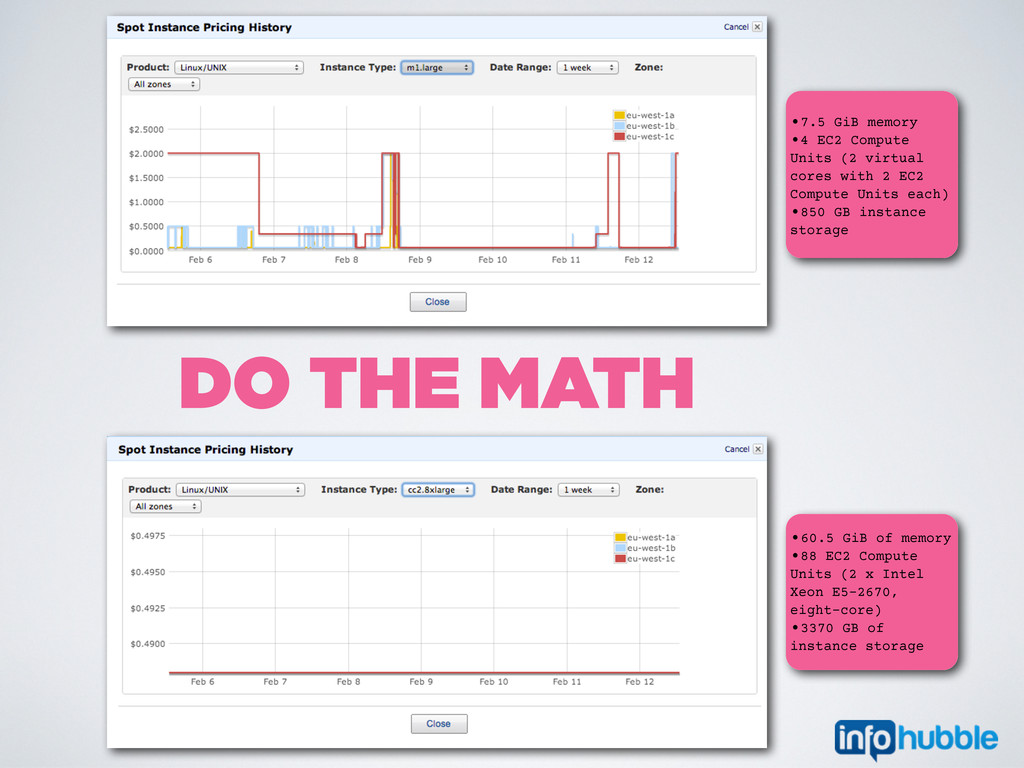
Intel Xeon E5-2670, eight-core) •3370 GB of instance storage •7.5 GiB memory •4 EC2 Compute Units (2 virtual cores with 2 EC2 Compute Units each) •850 GB instance storage DO THE MATH
up or down automatically • Checks if the number of server running matches your criteria, if not start or stop some • If an alarm is triggered (or cleared) it can automatically add extra nodes (or kill the exceeding ones) • It scales according to the defined policy • AS is ideal for failover or to handle (burst) spike load (TechCrunch effect)
run ✓Define the lower- and upper-bound of instances you want to spawn ✓Define alarms (CPU, I/O, network latency...) used as trigger to scale up (or down) ✓associate alarm with the policy, (e.g. if you get the CPU alarm just start a new instance)
a clever way to resolve name: the hostname prod-scriptdriver-i6-master.infohubble.net is resolved as the local-IP address if queried from inside, and as the public one if done from outside AWS • Very handy for Security Group configuration
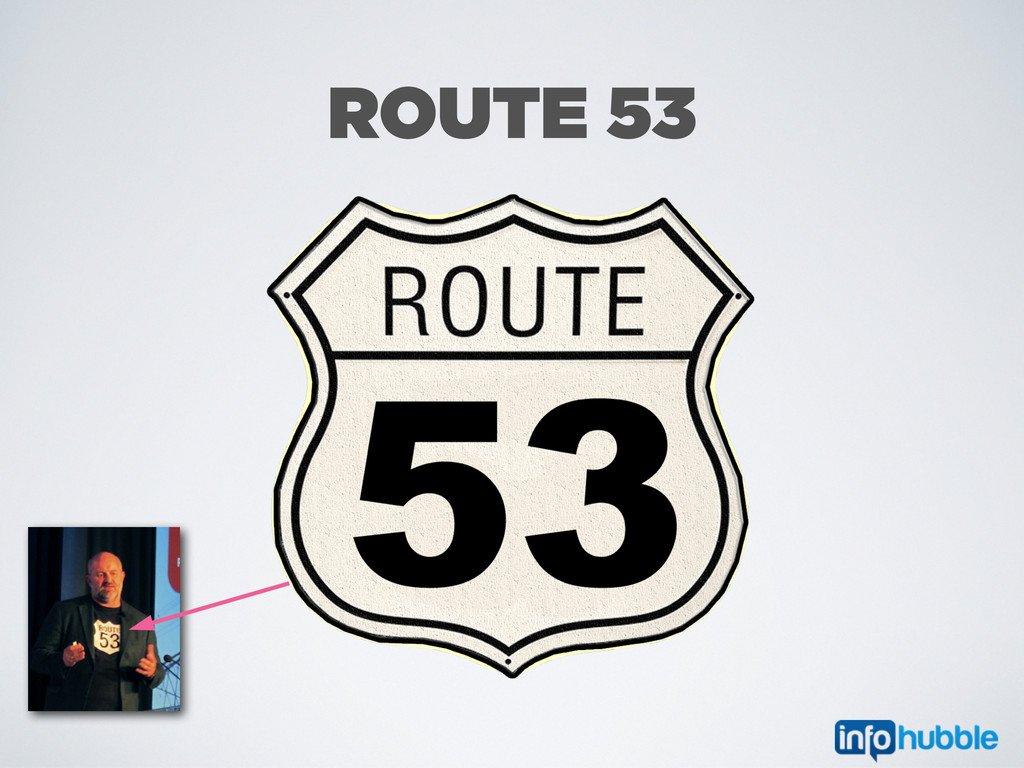
a way to uniquely reference an instance • custom script baked in the AMI • it extracts its own name from user-data • .... and update its own hostname (update the CNAME entry) using the Boto API at boot-time • delete Route 53 entry at shutdown
URLs from the common-crawl dataset (45TB of data) • Map task, get the file, extract and crunches the webpages in order to extract URL from links/anchors • Reduce task collects them and makes a bulk insert to CouchDB
disks ★ Custom settings: bags are nice but don't make your life easier ★ Idempotent recipes ★ Our limited understanding of Ruby ★ Limited set of "Resources" Where Chef is hard:
• Templates are replaced with tokens supplied in user-data user-data: _HOSTNAME=prod-finders- node5.infohubble.net&_BUCKET=infohubble-grid- v1.1231&_PORT=47500&_MAXJOBS=35 • Next steps?
{kind=link}
![Nicolas Peeters, Head of Development @peetersn [email protected] peetersn ABOUT ME](https://files.speakerdeck.com/presentations/c743d7a058b50130cac112313d2a3ab9/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@peetersn [email protected] 78](https://files.speakerdeck.com/presentations/c743d7a058b50130cac112313d2a3ab9/slide_77.jpg){kind=link}